

Несколько лет назад мы в Badoo начали использовать MVI-подход к Android-разработке. Он был призван упростить сложную кодовую базу и избежать проблемы некорректных состояний: в простых сценариях это легко, но чем сложнее система, тем сложнее поддерживать её в корректном виде и тем проще пропустить баг.
В Badoo все приложения асинхронны — не только из-за обширного функционала, доступного пользователю через UI, но и из-за возможности односторонней отправки данных сервером. При использовании старого подхода в нашем чат-модуле нам попалось несколько странных трудновоспроизводимых багов, на устранение которых пришлось потратить довольно много времени.
Наш коллега Zsolt Kocsi (Medium, Twitter) из лондонского офиса рассказал, каким образом с помощью MVI мы строим независимые компоненты, которые легко переиспользовать, какие преимущества мы получаем и с какими недостатками нам пришлось столкнуться при использовании этого подхода.
Это третья статья из серии публикаций об Android-архитектуре Badoo. Ссылки на первые две:
Нe останавливайтесь на слабой связности компонентов
Считается, что слабая связность лучше, чем сильная. Если вы полагаетесь только на интерфейсы, а не на конкретные реализации, то вам будет проще заменять компоненты, проще переключаться на другие реализации, не переписывая большую часть кода, что упрощает в том числе и модульное тестирование.
На этом мы обычно заканчиваем и говорим, что сделали всё возможное с точки зрения связности.
Однако этот подход неоптимален. Допустим, у вас есть класс А, которому нужно использовать возможности трёх других классов: B, C и D. Даже если ссылаться на них через интерфейсы, класс A становится тяжелее с каждым из этих классов:
- он знает все методы во всех интерфейсах, их имена и возвращаемые типы, даже если не использует их;
- при тестировании А нужно настраивать больше моков (mock object);
- сложнее многократно использовать А в других контекстах, в которых мы не имеем или не хотим иметь B, C и D.
Конечно, именно класс А должен определять минимально необходимый для него набор интерфейсов (interface segregation principle из SOLID). Однако на практике нам всем приходилось сталкиваться с ситуациями, когда ради удобства применялся иной подход: брали существующий класс, реализующий некую функциональность, извлекали в интерфейс все его публичные методы, а затем использовали этот интерфейс там, где нужен был упомянутый класс. То есть интерфейс использовался не исходя из того, что этому компоненту требуется, а исходя из того, что другой компонент может предложить.
При таком подходе со временем ситуация усугубляется. Каждый раз, когда мы добавляем новую функциональность, наши классы увязают в паутине новых интерфейсов, о которых им нужно знать. Классы увеличиваются в размерах, а тестировать становится всё труднее.
В итоге, когда потребуется использовать их в другом контексте, переместить их без всего этого клубка, с которым они связаны, пусть и через интерфейсы, будет практически невозможно. Можно провести аналогию: вы хотите использовать банан, а он в руках обезьяны, которая висит на дереве, так что в результате в нагрузку к банану вам достанется целый кусок джунглей. Словом, процесс переноса занимает кучу времени, и вскоре вы начинаете спрашивать себя, почему на практике так сложно переиспользовать код.
Компоненты в виде чёрных ящиков
Если мы хотим, чтобы компонент можно было легко и многократно использовать, то для этого нам не нужно знать о двух вещах:
- о том, где ещё он используется;
- о других компонентах, которые не относятся к его внутренней реализации.
Причина понятна: если не знать о внешнем мире, то не будешь с ним связан.
Что мы действительно хотим от компонента:
- определить его собственные входные (input) и выходные (output) данные;
- не думать о том, откуда эти данные приходят и куда уходят;
- он должен быть самодостаточным, чтобы нам не нужно было знать внутреннее устройство компонента для его использования.
Можно считать компонент чёрным ящиком, или интегрированной микросхемой. У неё есть входные и выходные контакты. Ты их припаиваешь — и микросхема становится частью системы, о которой она ничего не знает.

До сих пор подразумевалось, что мы говорим о двунаправленных потоках данных: если классу А что-то нужно, он через интерфейс B извлекает метод и получает результат в виде возвращаемого функцией значения.

Но тогда А знает о B, а мы хотим этого избежать.
Конечно, такая схема имеет смысл для низкоуровневых особенностей реализации. Но если нам нужен многократно используемый компонент, который работает как самодостаточный чёрный ящик, то нужно удостовериться, что он ничего не знает о внешних интерфейсах, именах методов или возвращаемых значениях.
Переходим к однонаправленности
Но без имён интерфейсов и методов мы ничего не сможем вызвать! Остаётся лишь использовать однонаправленный поток данных, при котором мы просто получаем input и генерируем output:

Поначалу это может выглядеть ограничением, но у такого решения много преимуществ, о которых речь пойдёт ниже.
Из первой статьи мы знаем, что фичи (Feature) определяют собственные входные данные (Wish) и собственные выходные данные (State). Поэтому для них не имеет значения, откуда берется Wish и куда уходит State.
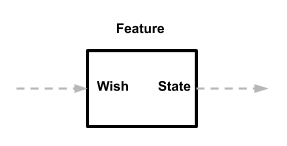
Именно это нам и нужно! Фичи можно использовать везде, где вы можете подавать им входные данные, а с выходными данными вы можете делать всё, что заблагорассудится. И поскольку фичи не общаются напрямую с другими компонентами, они являются самодостаточными и несвязанными модулями.
Теперь возьмём View и спроектируем его так, чтобы оно тоже было самодостаточным модулем.
Во-первых, View должно быть настолько простым, насколько это возможно, чтобы оно могло обрабатывать только свои внутренние задачи.
Что за задачи? Их две:
- отрисовка ViewModel (input);
- инициирование ViewEvents в зависимости от действий пользователя (output).
Зачем использовать ViewModel? Почему бы напрямую не отрисовать состояние (State) фичи?
- (Не)отображение на экране той или иной фичи не является деталью реализации. View должно уметь отрисовывать себя, если данные поступают из нескольких источников.
- Не нужно отражать во View сложности состояния. ViewModel должна содержать только готовую к показу информацию, которая нужна, чтобы оно оставалось простым.
Также View не должно интересовать следующее:
- откуда берутся все эти ViewModels;
- что происходит при инициировании ViewEvent;
- любая бизнес-логика;
- аналитическое отслеживание;
- журналирование;
- прочие задачи.
Всё это внешние задачи, и View не должно быть с ними связано. Давайте остановимся и подытожим простоту View:
interface FooView : Consumer<ViewModel>, ObservableSource<Event> {
data class ViewModel(
val title: String,
val bgColor: Int
)
sealed class Event {
object ButtonClicked : Event()
data class TextFocusChanged(val hasFocus: Boolean) : Event()
}
}
Реализация под Android должна:
- Находить Android views по их ID.
- Реализовывать принимающий метод (accept method) принимающего интерфейса (consumer interface) посредством настройки значения из ViewModel.
- Устанавливать слушателей (ClickListeners), чтобы взаимодействие с UI сгенерировало определённые события.
Пример:
class FooViewImpl @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyle: Int = 0,
private val events: PublishRelay<Event> = PublishRelay.create<Event>()
) : LinearLayout(context, attrs, defStyle),
FooView,
// delegate implementing ObservableSource to our Relay
ObservableSource<Event> by events {
// 1. find the views
private val title: TextView by lazy { findViewById<TextView>(R.id.title)}
private val panel: ViewGroup by lazy { findViewById<ViewGroup>(R.id.panel)}
private val button: Button by lazy { findViewById<Button>(R.id.button)}
private val editText: EditText by lazy { findViewById<EditText>(R.id.editText)}
// 2. set listeners to trigger Events
override fun onFinishInflate() {
super.onFinishInflate()
button.setOnClickListener { events.accept(Event.ButtonClicked) }
editText.setOnFocusChangeListener { _, hasFocus -> events.accept(Event.TextFocusChanged(hasFocus)) }
}
// 3. render the ViewModel
override fun accept(vm: ViewModel) {
title.text = vm.title
panel.setBackgroundColor(ContextCompat.getColor(context, vm.bgColor))
}
}
Если не ограничиваться Feature и View, то вот как будет выглядеть любой другой компонент при таком подходе:
interface GenericBlackBoxComponent : Consumer<Input>, ObservableSource<Output> {
sealed class Input
sealed class Output
}
Теперь с паттерном всё понятно!

Соединяй, соединяй, соединяй!
А что делать, если у нас есть разные компоненты и у каждого из них свои входные и выходные данные? Мы соединим их!
К счастью, это можно легко сделать с помощью Binder, который ещё и помогает создавать правильные области видимости, как мы знаем из второй статьи:
// will automatically dispose of the created rx subscriptions when the lifecycle ends:
val binder = Binder(lifecycle)
// connect some observable sources to some consumers with element transformation:
binder.bind(outputA to inputB using transformer1)
binder.bind(outputB to inputA using transformer2)
Первое преимущество: легко расширять без модификаций
Использование несвязанных компонентов в виде чёрных ящиков, которые подсоединены лишь временно, позволяет нам добавлять новую функциональность, не модифицируя существующие компоненты.
Возьмём простой пример:

Здесь просто соединённые друг с другом фича (F) и View (V).
Соответствующие привязки (bindings) будут такими:
bind(feature to view using stateToViewModelTransformer)
bind(view to feature using uiEventToWishTransformer)Допустим, мы хотим добавить в эту систему отслеживание каких-то UI-событий.
internal object AnalyticsTracker : Consumer<AnalyticsTracker.Event> {
sealed class Event {
object ProfileImageClicked: Event()
object EditButtonClicked : Event()
}
override fun accept(event: AnalyticsTracker.Event) {
// TODO Implement actual tracking
}
}
Хорошая новость заключается в том, что мы можем это сделать, просто заново используя существующий выходной канал представления:

В коде это выглядит так:
bind(feature to view using stateToViewModelTransformer)
bind(view to feature using uiEventToWishTransformer)
// +1 line, nothing else changed:
bind(view to analyticsTracker using uiEventToAnalyticsEventTransformer)
Новую функциональность можно добавить всего одной строкой дополнительной привязки. Теперь нам не только можно не менять ни строки кода View, но оно даже не знает о том, что выходные данные используются для решения новой задачи.
Очевидно, что теперь нам проще избежать дополнительных забот и излишнего усложнения компонентов. Они остаются простыми. Добавлять в систему функциональность можно, всего лишь подключая компоненты к уже существующим.
Второе преимущество: легко использовать многократно
На примере Feature и View хорошо видно, что мы можем всего лишь одной строкой с привязкой добавить новый источник входных данных или потребитель выходных данных. Это заметно облегчает многократное использование компонентов в разных частях приложения.
Однако этот подход не ограничивается классами. Такой способ применения интерфейсов позволяет описывать самодостаточные реактивные компоненты любого размера.
Ограничивая себя определёнными входными и выходными данными, мы избавляемся от необходимости знать, как всё устроено под капотом, и поэтому легко избегаем случайного связывания внутренностей компонентов с другими частям системы. А без связывания можно легко и просто использовать компоненты многократно.
Мы ещё вернёмся к этому в одной из следующих статей и рассмотрим примеры использования этой методики для соединения более высокоуровневых компонентов.
Первый вопрос: куда класть привязки?
- Выберите уровень абстракции. В зависимости от архитектуры это может быть Activity, фрагмент или какой-нибудь ViewController. Надеюсь, у вас ещё остался какой-то уровень абстракции в тех частях, где нет UI. Например, в какой-нибудь из областей видимости контекстного дерева DI.
- Создайте для привязки отдельный класс на том же уровне, что и эта часть UI. Если это FooActivity, FooFragment или FooViewController, то вы можете положить FooBindings рядом с ним.
- Убедитесь, что вы внедряете FooBindings в те же инстансы компонентов, которые вы используете в Activity, фрагменте и т. д.
- Для формирования области видимости привязок используйте жизненный цикл Activity или фрагмента. Если этот цикл не привязан к Android, то вы можете создавать триггеры вручную, например при создании или уничтожении DI-скоупа. Другие примеры областей видимости описаны во второй статье.
Второй вопрос: тестирование
Поскольку наш компонент ничего не знает о других, то обычно нам не требуются вместо них заглушки. Тесты упрощаются до проверки правильности реакции компонента на входные данные и выдачи ожидаемых результатов.
В случае с Feature это означает:
- возможность тестировать, генерируют ли определённые входные данные ожидаемое состояние (выходные данные).
А в случае с View:
- мы можем тестировать, приводит ли определённая ViewModel (входные данные) к ожидаемому состоянию UI;
- мы можем тестировать, приводит ли симуляция взаимодействия с UI к инициализации в ожидаемом ViewEvent (выходные данные).
Конечно, взаимодействия между компонентами не исчезают волшебным образом. Мы лишь извлекли эти задачи из самих компонентов. Их по-прежнему нужно тестировать. Но где?
В нашем случае за соединение компонентов отвечают Binders:
// this is wherever you put your bindings, depending on your architecture
class BindingEnvironment(
private val component1: Component1,
private val component2: Component2
) {
fun createBindings(lifecycle: Lifecycle) {
val binder = Binder(lifecycle)
binder.bind(component1 to component2 using Transformer())
}
}
Наши тесты должны подтверждать следующее:
1. Трансформеры (мапперы).
У некоторых соединений есть мапперы, и нужно удостовериться, что они корректно преобразуют элементы. В большинстве случаев для этого достаточно очень простого модульного теста, поскольку мапперы обычно также очень просты:
@Test
fun testCase1() {
val transformer = Transformer()
val testInput = TODO()
val actualOutput = transformer.invoke(testInput)
val expectedOutput = TODO()
assertEquals(expectedOutput, actualOutput)
}
2. Связи.
Нужно удостовериться, что связи настроены правильно. Какой смысл в работе отдельных компонентов и мапперов, если по какой-то причине связь между ними не была установлена? Всё это можно протестировать, настроив среду привязки с заглушками, источниками инициализации и проверкой получения ожидаемых результатов на клиентской стороне:
class BindingEnvironmentTest {
lateinit var component1: ObservableSource<Component1.Output>
lateinit var component2: Consumer<Component2.Input>
lateinit var bindings: BindingEnvironment
@Before
fun setUp() {
val component1 = PublishRelay.create()
val component2 = mock()
val bindings = BindingEnvironment(component1, component2)
}
@Test
fun testBindings() {
val simulatedOutputOnLeftSide = TODO()
val expectedInputOnRightSide = TODO()
component1.accept(simulatedOutputOnLeftSide)
verify(component2).accept(expectedInputOnRightSide)
}
}
И хотя для тестирования придётся написать примерно такое же количество кода, как и при других подходах, однако самодостаточные компоненты облегчают тестирование отдельных частей, поскольку задачи явно разделены.
Пища для размышления
Хотя описание нашей системы в виде графа из чёрных ящиков хорошо для общего понимания, это работает лишь до тех пор, пока размер системы относительно мал.
Пять-восемь строк привязок — это приемлемо. Но, связав больше, понять, что происходит, будет довольно сложно:
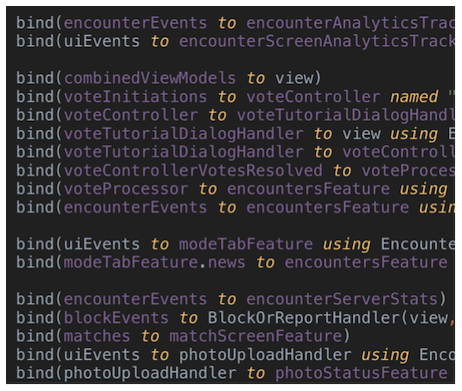

Мы столкнулись с тем, что при увеличении количества связей (их было ещё больше, чем в представленном фрагменте кода) ситуация становилась ещё более сложной. Причина была не только в количестве строк — какие-то привязки можно группировать и извлекать их для разных методов, — но и в том, что становилось всё труднее удерживать в поле зрения всё происходящее. А это всегда плохой знак. Если на одном уровне расположены десятки разных компонентов, то невозможно представить все возможные взаимодействия.
Причина кроется в использовании компонентов — чёрных ящиков или в чём-то другом?
Очевидно, что если описываемая вами область видимости изначально сложна, то никакой подход не спасёт вас от упомянутой проблемы, пока вы не разделите систему на более мелкие части. Она будет сложна даже без огромного списка привязок, просто это будет не так очевидно. Кроме того, гораздо лучше, если сложность выражена явно, а не скрыта. Лучше видеть растущий список однострочных соединений, который напоминает о том, сколько у вас отдельных компонентов, чем не знать об этих связях, скрытых внутри классов в разных вызовах методов.
Поскольку сами по себе компоненты просты (это чёрные ящики и в них не протекают дополнительные процессы), их проще разделить, а значит, это шаг в верном направлении. Мы перенесли сложность в одно место — в список привязок, один взгляд на который позволяет оценить общую ситуацию и начать размышлять над тем, как выбраться из этого бардака.
Поиск решения занял у нас немало времени, и он всё ещё продолжается. О том, как справиться с этой проблемой, мы планируем рассказать в следующих статьях. Оставайтесь на связи!
Комментарии (13)

Evgenij_Popovich
16.08.2019 10:06Спасибо за статью.
Похоже, у вас получился EventBus с ручной маршрутизацией. Как вы решаете вопрос, если какому-то событию нужен колбек?ANublo Автор
16.08.2019 13:47Я не совсем понял ваш комментарий про EventBus, если распишите подробнее свою мысль, постараюсь ответить.
На счёт коллбэков.
Это как раз достигается с помощью input/output подхода. Сейчас приведу упрощённый пример.
У вас есть компонент, который логинит юзера в приложение.
В обычном сценарии, вы вызываете метод и либо регистрируете заранее коллбэк, либо через rx цепочку получаете результат.
В подходе с компонентами в виде input/output выглядит примерно следующим образом:
interface LoginComponent { interface Dependency { fun input(): ObservableSource<Input> fun output(): Consumer<Output> } sealed class Input { object Login: Input() } sealed class Output { object Success: Output() object Failed: Output() } }
И вы просто подписываетесь на output, который этот компонент возвращает.
Тогда после отправки события Login вы получите результаты через output.
Компоненты такого уровня мы не делаем, это упрощённый пример, чтобы ответить на вопрос.Evgenij_Popovich
16.08.2019 14:36> Я не совсем понял ваш комментарий про EventBus, если распишите подробнее свою мысль, постараюсь ответить.
Имел в виду, что концепция input/output потоков напоминает шаблон EventBus. Но у вас отличие, что не все компоненты слушают абсолютно все события от любых компонентов, а только отфильтрованные с помощью заданных вручную биндингов.
Спасибо за пример. Сам я использую местами похожий на ваше решение «велосипед» основанный на RxJava, позволяющий как отправлять события так и получать колбеки на них. Поэтому было интересно, как вы решили эту проблему.
У меня же в Output сваливаются не события, а нечто вроде Pair<Event, Maybe>, где первый аргумент изначальное событие а второй результат его обработки. После результат передается в том место, откуда поступил запрос. Это позволяет делать цепочки вида
class Login extends RequestMessage<Boolean>{} .... request(new Login()) .flatMap(result -> result ? request(new Operation1()) : request(new Operation2()) ....ANublo Автор
18.08.2019 13:09В этом решении есть сильные отличия от EventBus за счёт чётких контрактов по которым работает компонент. Так ведь можно и концепцию коллбэков описать как EventBus)

Master255
16.08.2019 13:55По настоящему сложные и нужные проекты имеют слабое разделение на объекты. Так как связей очень много между объектами.
Ещё иногда теряется производительность при разделении на объекты — всегда был противником потери производительности, даже теоретической и миллисекундной.
ООП — это круто, но надо соблюдать меру пропорционально сложности проекта.
Нужно помнить о том, что программы, которые мы пишем — не всегда должны быть красивы для нас — людей. Они в первую очередь должны быть красивы для компьютеров и эту красоту нужно, просто понимать.ANublo Автор
18.08.2019 12:56Стоит избегать преждевременных оптимизаций. Иначе с таким подходом стоит не использовать никакие библиотеки наподобие rxJava и потом не найти разработчиков на поддержку данного проекта.
Так что мы пользуемся подходом написания приложения в едином стиле и переписываем какие-то куски кода, когда профайлер демонстрирует проблемы.

Revertis
16.08.2019 14:56Если вы полагаетесь только на интерфейсы, а не на конкретные реализации, то вам будет проще заменять компоненты, проще переключаться на другие реализации, не переписывая большую часть кода, что упрощает в том числе и модульное тестирование.
Я работаю в проекте уже почти пять лет. У нас изначально каждый «сервис» (не в терминах Андроид) сделан имплементацией своего интерфейса. Именно по той причине, что вы написали. Но знаете, что? За пять лет только один сервис был переписан с нуля, и мы этим воспользовались. И воспользовались только формально, в этом совершенно не было необходимости. Потом было больше проблем с вырезанием ненужной старой версии сервиса и переименовывание нового в старый, ибо нафиг он теперь нужен?
Проект развивается постепенно. Каждое изменение «атомарно» в терминах мерджа в master, и зачем эти техники тогда?ANublo Автор
18.08.2019 13:04Есть дополнительные плюсы у использования интерфейсов, кроме простоты подмены.
Чёткий контракт, по которому видно каким образом работает компонент.
Гарантированное отсутствие проблем в тестах, когда будем мокать эту зависимость.
Но ваше замечание тоже валидно и имеет право на жизнь.Revertis
18.08.2019 13:08Ну вот разве что для мока и подойдёт, да. А для разработки даже «чёткий контракт» не нужен, ибо всегда можно посмотреть какие паблики у класса-имплементации есть.
jevius
У вас онлайны отображаются некорректно и приложение почти не работает, если телефон в режиме энергосбережения. Иногда карточки в разделе свайпов не подгружаются и я смотрю на красивые прелоадеры. Кстати, почему если на ком-то остановиться, то не факт, что через 10 минут этот же человек будет наверху стопки карточек? Может я отложил
Напоминает ситуацию со Сбербанком, где машинное обучение и big data, но — где карточку открывали, туда и идите
zhannazhanna
Напишите, пожалуйста, мне в личные сообщения подробнее: какая платформа и версия приложения. Попробуем разобраться, из-за чего может тормозить.