

Сначала кратко поясним, почему рассчитывать на Intel GPU стоит. Конечно же, производительность CPU в системе почти всегда значительно превышает GPU, на то он и Центральный Процессор.
Но интересно заметить, что производительность интегрированных GPU Intel за последнее десятилетие в процентном отношении выросла гораздо больше, чем у CPU, и эта тенденция обязательно продолжится с появлением новых дискретных видеокарт Intel. Кроме того, GPU в силу своей архитектуры (множество векторных исполнительных устройств) гораздо лучше приспособлен к исполнению определенного типа задач – обработке изображений, то есть, фактически, к проведению любых однотипных операций над массивами данных. GPU делает это с полным внутренним распараллеливанием, тратит на это меньше энергии, чем CPU, и в некоторых случаях даже превосходит его по абсолютной скорости. Наконец, GPU и CPU могут работать в параллель, каждый над своими задачами, обеспечивая максимальную производительность и/или минимальное энергопотребление всей системы в целом.
— Ок, Intel. Мы решили использовать Intel GPU для расчетов общего назначения, как это сделать?
— Простейший путь, не требующий никаких специальных знаний в графике (шейдеров Direct3D и OpenGL) — это OpenCL.
Ядра OpenCL платформонезависимы и автоматически выполнятся на всех доступных в системе вычислительных устройствах – CPU, GPU, FPGA и т.д. Но плата за такую универсальность – далеко не максимальная возможная производительность на каждом типе устройств, и особенно — на интегрированном Intel GPU. Здесь можно привести такой пример: при исполнении на любом Intel GPU кода, транспонирующего матрицу байтовых значений 16х16, преимущество в производительности «прямого программирования» Intel GPU в сравнении c OpenCL версией будет 8 раз!
Кроме того, некоторую функциональность, требуемую для реализации распространенных алгоритмов (например, «широких фильтров», использующих в одном преобразовании данные большой группы пикселей), OpenCL просто не поддерживает.
Поэтому, если вам требуется максимальная скорость на GPU и\или что-то более сложное, чем независимая работа с каждым элементом массива и его ближайшими соседями, то вам поможет Intel C for Metal (ICM)– инструмент для разработки приложений, исполняемых на Intel Graphics.
ICM – добро пожаловать в кузницу!
С точки зрения производительности и функциональности ICM можно считать «ассемблером для графических карт Intel», а с точки зрения схемы и удобства использования – «аналогом OpenCL для графических карт Intel».
Много лет ICM использовался внутри Intel в разработке продуктов для обработки медиа на Intel GPU. Но в 2018 ICM был выпущен в публичный доступ, да еще и с открытым кодом!
Свое текущее имя Intel C for Metal получил несколько месяцев назад, до этого он именовался Intel C for Media (тот же акроним ICM или просто CM или даже Cm), а еще раньше — Media Development Framework (MDF). Так что, если где-то в названии компонент, в документации или в комментариях открытого кода встретятся старые названия — не пугайтесь, перед вами историческая ценность.
Итак, код ICM приложения, точно также, как в OpenCL, содержит две части: «административную», выполняемую на процессоре, и ядра, исполняемые на GPU. Неудивительно, что первая часть называется хост (host), а вторая – кернел (kernel).
Кернелы представляют собой функцию обработки заданного блока пикселей (или просто данных), пишутся на языке Intel C for Metal и компилируются в набор инструкций (ISA) Intel GPU с помощью компилятора ICM.
Хост — это своеобразный «менеджер команды кернелов», он администрирует процесс передачи данных между CPU и GPU и выполняет другую «менеджерскую работу» посредством библиотеки времени исполнения ICM Runtime и медиа-драйвера Intel GPU.
Подробная схема работы ICM выглядит так:
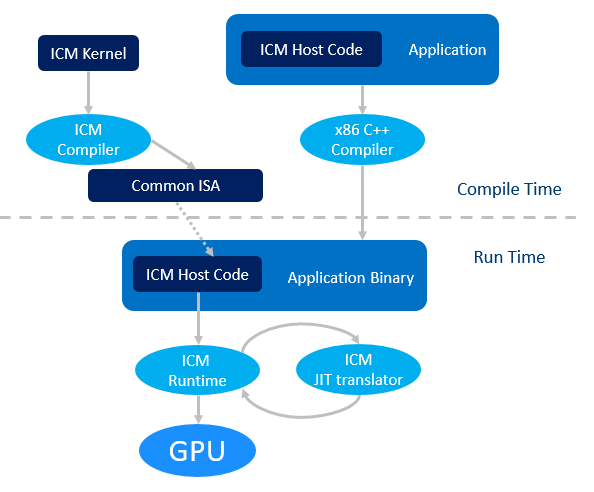
- ICM код хоста компилируется любым x86 C/C++ компилятором вместе со всем приложением;
- ICM код кернелов компилируется компилятором ICM в бинарный файл с некоторым общим набором инструкций (Common ISA);
- Во время исполнения этот общий набор инструкций JIT транслируется под конкретный Intel GPU;
- ICM хост вызывет ICM библиотеку времени исполнения для коммуникации с GPU и операционной системой.
Еще пара важных и полезных моментов:
- Используемые в ICM для представления\хранения данных поверхности могут разделяться с DirectX 11 и 9 (DXVA в Linux).
- GPU может брать и записывать данные как из видео-памяти, так и из системной памяти, разделяемой с CPU. В состав ICM входят специальные функции для обоих случаев передачи данных в обе стороны. При этом, системная память именно разделяемая, и реальное копирование в ней не потребуется – для этого в ICM предусмотрено так называемое нулевое копирование (zero copy).
ICM – в жерле вулкана!
Уже из самого названия «Си для железа» следует, что устройство языка соответствует внутреннему устройству графики Intel. То есть, учитывается тот факт, что код будет выполняться на нескольких десятках исполнительных устройств (Execution Unit) графической карты, каждое из которых представляет собой полностью векторный процессор, способный исполнять несколько потоков одновременно.
Сам язык ICM – это C++ с некоторыми ограничениями и расширениями. По сравнению с C++ в ICM отсутствуют … указатели, выделение памяти и статические переменные. Под запретом также рекурсивные функции. Зато присутствует явная модель векторного (SIMD) программирования: векторные типы данных – вектор, матрица и поверхность; векторные операции на этих типах данных, векторные условия if/else, независимо выполняемые для каждого элемента вектора; а также встроенные функции для доступа к хардверной фиксированной функциональности Intel GPU.
Работу с векторами, матрицами и поверхностями в реальных задачах облегчают объекты «подмножеств» – из cоответствующих базовых объектов вы можете выбирать только интересующие вас, «референсные» блоки или, как частный случай, отдельные элементы по маске.
Например, давайте посмотрим на ICM код, реализующий линейный фильтр – замену значения
RGB цвета каждого пикселя усредненным значением его и 8 соседей по картинке:
 |
I(x,y) = [I(x-1, y-1) + I(x-1, y) + I(x-1, y+1) + I(x, y-1) + + I (x, y) + I(x, y+1) + I(x+1, y-1) + I(x+1, y) + I(x+1, y+1)] / 9 |
Если цвета (данные) в матрице расположены как R8G8B8, то вычисление с разбиением входного изображения на блоки размером 6х8 пикселей (6х24 байтовых элемента данных) будет таким:
_GENX_MAIN_ void linear(SurfaceIndex inBuf, SurfaceIndex outBuf,
uint h_pos, uint v_pos){
// объявляем входную матрицу 8x32
matrix<uchar, 8, 32> in;
// матрица результата 6x24
matrix<uchar, 6, 24> out;
matrix<float, 6, 24> m;
// считываем входную матрицу
read(inBuf h_pos*24, v_pos*6, in);
// считаем сумму элементов - соседей
m = in.select<6,1,24,1>(1,3);
m += in.select<6,1,24,1>(0,0); m += in.select<6,1,24,1>(0,3); m += in.select<6,1,24,1>(0,6);
m += in.select<6,1,24,1>(1,0); m += in.select<6,1,24,1>(1,6);
m += in.select<6,1,24,1>(2,0); m += in.select<6,1,24,1>(2,3); m += in.select<6,1,24,1>(2,6);
// считаем среднее- деление на 9 примерно соответствует * 0.111f;
out = m * 0.111f;
// сохраняем результат
write(outBuf, h_pos*24, v_pos*6, out); }- Размер матриц задается в виде <тип данных, высота, ширина>;
- оператор select<v_size, v_stride, h_size, h_stride>(i, j) возвращает подматрицу начинающуюся с элемента (i, j), v_size показывает количество выбранных рядов, v_stride – расстояние между выбранными рядами h_size – количество выбранных столбцов, h_stride — расстояние между ними.
Обратите внимание, что размер входной матрицы 8х32 выбран потому, что хотя для вычислений значений всех пикселей в блоке 6х24 алгоритмически достаточно блока 8х30, чтение блока данных в ICM происходит не по байтам, а по 32-битным dword-элементам.
Вышеприведенный код — это, фактически, полноценный ICM-кернел. Как было сказано, он будет скомпилирован компилятором ICM в две стадии (предкомпиляция и последующая JIT трансляция). Компилятор ICM построен на основе LLVM и, при желании, может быть изучен в исходниках и собран вами самостоятельно.
А что же делает ICM-хост? Вызывает функции библиотеки времени исполнения ICM Runtime, которые:
- Создают, инициализируют и удаляют после использования GPU устройство (CmDevice), а также поверхности, содержащие пользовательские данные, используемые в кернелах (CmSurface);
- Работают с кернелами – загружают их из предкомпилированных .isa файлов, подготавливают их аргументы, указывающие на часть данных, с которыми будет работать каждый кернел;
- Создают и управляют очередью выполнения кернелов;
- Управляют схемой работы потоков, выполняющих каждый кернел на GPU;
- Управляют событиями (CmEvent ) — объектами синхронизации работы GPU и CPU;
- Передают данные между GPU и CPU, а точнее – между системной и видеопамятью;
- Сообщают об ошибках, измеряют время работы кернелов.
Простейший код хоста схематично выглядит так:
// Создаем CmDevice
cm_result_check(::CreateCmDevice(p_cm_device, version));
// Загружаем hello_world_genx.isa
std::string isa_code = isa::loadFile("hello_world_genx.isa");
// Создаем из кода isa объект CmProgram
CmProgram *p_program = nullptr;
cm_result_check(p_cm_device->LoadProgram(const_cast<char* >(isa_code.data()),isa_code.size(), p_program));
// Создаем hello_world кернел.
CmKernel *p_kernel = nullptr;
cm_result_check(p_cm_device->CreateKernel(p_program,
"hello_world",
p_kernel));
// Создаем схему потоков для исполнения каждого CmKernel
CmThreadSpace *p_thread_space = nullptr;
cm_result_check(p_cm_device->CreateThreadSpace(thread_width,
thread_height,
p_thread_space));
// Устанавливаем аргументы кернелов.
cm_result_check(p_kernel->SetKernelArg(0,
sizeof(thread_width),
&thread_width));
// Создаем CmTask – контейнер для указателей на кернелы
// Он требуется для постановки кернелов в очередь исполнения
// и добавляем в него кернелы.
CmTask *p_task = nullptr;
cm_result_check(p_cm_device->CreateTask(p_task));
cm_result_check(p_task->AddKernel(p_kernel));
// Создаем очередь
CmQueue *p_queue = nullptr;
cm_result_check(p_cm_device->CreateQueue(p_queue));
// Запускаем исполнение задачи GPU (ставим в очередь на исполнение).
CmEvent *p_event = nullptr;
cm_result_check(p_queue->Enqueue(p_task, p_event, p_thread_space));
// Ждём завершения исполнения.
cm_result_check(p_event->WaitForTaskFinished());Как видите, ничего сложного в создании и использовании кернелов и хоста нет. Всё просто!
Единственная сложность, о которой стоит предупредить, чтобы вернуться в реальный мир: в настоящее время в доступной публично версии ICM единственная возможность отладки кернелов – это printf сообщения. Как ими корректно пользоваться, можно посмотреть в примере Hello, World.
ICM – не heavy metal!
Теперь посмотрим, как это работает на практике. Пакет разработчика ICM доступен для Windows и Linux, и для обеих операционных систем содержит Компилятор ICM, документацию и обучающие примеры использования. Подробное описание этих обучающих примеров скачивается отдельно.
Для Linux в пакет дополнительно включен Media Driver пользовательского режима для VAAPI со встроенной в него библиотекой времени исполнения ICM Runtime. Для Windows же работу с ICM выполнит обычный Intel Graphics Driver для Windows. Библиотека времени исполнения ICM Runtime включена в набор dll этого драйвера. В пакет ICM входит только линковочный .lib файл для неё. Если драйвер по какой-то причине отсутствует на вашей системе, то он загружается с сайта Intel, при этом гарантируется корректная работа ICM в драйверах, начиная с версии 15.60 — 2017 года выпуска).
Исходный код компонент можно найти здесь:
- Intel Media Driver for VAAPI and Intel C for Media Runtime: github.com/intel/media-driver
- Intel C for Media Compiler and examples: github.com/intel/cm-compiler
- Intel Graphics Compiler: github.com/intel/intel-graphics-compiler
Дальнейшее содержание этого раздела относится исключительно к Windows, но общие принципы работы c ICM применимы и под Linux.
Для «штатной» работы с ICM-пакетом потребуется Visual Studio начиная с 2015 и Cmake начиная с версии 3.2. При этом, конфигурационные и скриптовые файлы учебных примеров рассчитаны на VS 2015, для использования более новых версий VS файлы придется изучать и править пути к компонентам VS самостоятельно.
Итак, знакомимся с ICM для Windows:
- Загружаем архив;
- Распаковываем его;
- Запускаем (желательно в командной строке VS) скрипт конфигурирования окружения setupenv.bat с тремя параметрами — поколением Intel GPU (соответствующим процессору, в который встроен GPU, его можно оставить по-умолчанию: gen9), платформой компиляции: x86\x64 и версией DirectX для совместного использования с ICM: dx9/dx11.
После чего можно просто построить все обучающие примеры – в папке examples это сделает скрипт build_all.bat или сгенерировать проекты для Microsoft Visual Studio – это сделает скрипт create_vs.bat с именем конкретного примера в качестве параметра.
Как можно видеть, ICМ-приложение будет представлять собой .exe файл с хостовой частью и .isa файл с соответствующей предкомпилированной GPU-частью.
В пакет ICM включены различные примеры – от простейшего Hello, World, показывающего основные принципы работы ICM, до достаточно сложного – реализации алгоритма поиска «максимального потока – минимального разреза» графа (max-flow min-cut problem), используемого в сегментации и сшивке изображений.
Все учебные примеры ICM хорошо документированы прямо в коде и уже упомянутом отдельном описании. Вникать в ICM рекомендуется именно по нему – последовательно изучая и запуская примеры, а далее – модифицируя их под свои нужды.
Для общего понимания всех существующих возможностей ICM настоятельно рекомендуется изучить «спецификацию» — описание ICM cmlangspec.html в папке \documents\compiler\html\cmlangspec.
В частности, там описан API реализованных в железе функций ICM – доступ к так называемым текстурным сэмплерам (Sampler) – механизму фильтрации изображений разного формата, а также к оценке движения (Motion Estimation) между видеокадрами и некоторым возможностям видео-аналитики.
ICM – куй железо, пока горячо!
Говоря о производительности ICM приложений, надо обязательно отметить, что учебные примеры включают в себя измерение времени своей работы, так что, запустив их на целевой системе и сравнив со своими задачами, вы можете оценить целесообразность использования для них ICM.
А общие соображения насчет производительности ICM достаточно простые:
- При выгрузке вычислений на GPU следует помнить о накладных расходах на передачу данных CPU<-> GPU и синхронизацию этих устройств. Поэтому пример типа Hello, World — не лучший кандидат на ICM-реализацию. Зато алгоритмы компьютерного зрения, AI и любой нетривиальной обработки массивов данных, особенно с изменением порядка этих данных в процессе или на выходе – это то, что надо для ICM.
- Кроме того, при проектировании ICM–кода надо обязательно учитывать внутреннее устройство GPU, то есть, желательно создавать достаточное количество (>1000) GPU потоков и загружать их все работой. При этом, хорошей идеей будет разделять изображения для обработки на небольшие блоки. Но конкретный способ разбиения, также как и выбор конкретного алгоритма обработки для достижения максимальной производительности – задача нетривиальная. Впрочем, это относится к любому способу работы с любым GPU (и CPU).
У вас есть OpenCL-код, но его производительность вас не радует? Или CUDA-код, но вы хотите работать на гораздо большем числе платформ? Тогда стоит посмотреть на ICM.
ICM – это живой и развивающийся продукт. Вы можете поучаствовать как в его использовании, так и его развитии – соответствующие репозитории на github ждут ваших коммитов. Вся необходимая для обоих процессов информация есть в данной статье и файлах readme на github. А если чего-то нет, то появится после ваших вопросов в комментариях.
Комментарии (26)

xFFFF
10.09.2019 12:14Будет ли версия для C#?

vikky13 Автор
10.09.2019 12:16Со стороны Intel таких планов пока нет, но всё же открыто — может, кто-то и напишет.

eldog
11.09.2019 10:08Импортировать библиотеку и сделать managed оболочку для хоста должно быть не так уж сложно, даже не творческая задача. Но будет иметь свою цену, хотя и небольшую. Интереснее было бы расковырять, что внутри хостовых классов и реализовать напрямую. Конечно, это будет unsafe код.
Boroda1
10.09.2019 12:38+2Как считаете, если завтра AMD, Imagination Technologies, ARM и другие производители собственных GPU скажут «OpenCL не очень, мы выкатываем свой API», разумно ли это будет?
Откуда отличия в производительности c OpenCL версией в 8 раз?
Если это фундаментальные ограничения OpenCL (в чём я крайне сомневаюсь), не лучше ли участвовать в развитии открытого стандарта и сделать так, чтобы в следующей версии отличий в производительности не было?
Что касается NVidia — они очень любят пилить своё собственное, но при этом исправно реализуют уже принятые стандарты. Да, CUDA лично мне кажется удобнее OpenCL. Но я не встречал, чтобы отличия в производительности с OpenCL выходили за 15-20%. Как же у Intel получилось 700% разницы?
IgorPie
10.09.2019 13:43Выкатывают, потому что он уже есть, и стоит им $0.
Вероятно, дальше посмотрят чего хорошего придумает сообщество и портируют к себе в закрытую часть.
vikky13 Автор
10.09.2019 16:16Вы задаете отличный вопрос… для тех, кто не читал этот пост. Для тех, кто читал, увы — ответ в посте есть. Честное интеловское :) К нему можно добавить, что да — производительность OpenCL постоянно улучшается, да и oneAPI виден на горизонте. C for Metal нисколько этим усилиям не противоречит.
Boroda1
10.09.2019 18:32Вопросов было несколько, а ответа не получил ни одного.
Вместо ответов — только поучение в стиле «Сам дурак, читай пока не поймёшь». Так себе техническое обсуждение.
Что же касается «C for Metal нисколько этим усилиям не противоречит» — если инженеры занимаются этим бесплатно в свободное от работы время, то я согласен.
Если это их основная оплачиваемая работа, то всё-таки сначала хорошо бы разобраться с Intel'овской реализацией OpenCL, а затем уже предлагать свой велосипед, который быстрее/выше/сильнее.vikky13 Автор
10.09.2019 21:27Я вам открою секрет. В Intel — достаточно инженеров для разных задач. Ну и еще один секрет не открою, а повторю — скопирую из текста поста — «Много лет ICM использовался внутри Intel в разработке продуктов для обработки медиа на Intel GPU»
rPman
11.09.2019 06:14Откуда отличия в производительности c OpenCL версией в 8 раз?
транспонирующего матрицу битовых значений 16х16, преимущество в производительности «прямого программирования» Intel GPU в сравнении c OpenCL версией будет 8 раз!
почти наверняка в opencl (а скорее всего в компиляторе) нет оптимально реализованных битовых операндов
p.s. полагаю такой пример выбран не зря как наихудший, но впечатление у читателя остается именно как основной недостаток opencl, классических подход рекламщиковvikky13 Автор
11.09.2019 11:19Спасибо, что нашли опечатку. Я не заметила :( Конечно же, значения не битовые, а байтовые. Поправила… И я честно пишу, что это максимальный эффект — когда происходит изменение порядка данных.
rPman
11.09.2019 16:03у меня была мысль что транспонировать битовую матрицу — странно но не стал писать что это ошибка
говорите разница реализаций нативно и на opencl по перестановке значений в восемь раз хуже? можно посмотреть исходники?vikky13 Автор
11.09.2019 17:23Исходников OpenCL у меня нет, но их легко найти. Исходники ICM для матрицы 8х8 — можно посмотреть в примере gaussian_blur_test из ICM пакета. Там нет абсолютно никаких хитростей — все очень просто и наивно.
matrix<uint, 8, 8> out; for( int i = 0; i < height; i += 8 ) { read( INBUF, id * 32, i, in ); out.row(0) = in.column(0); out.row(1) = in.column(1); out.row(2) = in.column(2); out.row(3) = in.column(3); out.row(4) = in.column(4); out.row(5) = in.column(5); out.row(6) = in.column(6); out.row(7) = in.column(7); write( OUTBUF, i * 4, id * 8, out );</source>
ktod
10.09.2019 20:17Поясните для особо одаренных, которые не понимают даже после повторного прочтения статьи: зачем нужен «велосипед»? Какая магия позволяют icm быть быстрее ocl на стандартных алгоритмах? Что это за «некоторая функциональность для распространенных алгоритмов», которую ocl не поддерживает?
Или смысл в том, что используется отличная от ocl абстракция при описании данных, которая позволяет проще выполнить оптимизацию для конкретного железа?
Напустили туману так, что остается только гадать.vikky13 Автор
10.09.2019 21:20Тут два момента, явно отмеченных в статье. Первый — OpenCL — не векторный по своей природе. Компилятор пытается его векторизовать внутри, но никакая автовекторизация по эффективности не может сравниться с ручной, которая лежит в основе C for Metal. Но главное — OpenCL работает с элементами поэлементно (хотя там и есть векторы фиксированной длины и рабочие группы, но это не сильно меняет дело), а в основе C for Metal — именно работа с группой элементов, причем, нефиксированного размера). Именно поэтому такой выигрыш именно в транспонировании — любом переупорядочивании этих элементов.
lieff
10.09.2019 21:38То-есть по сути это си с векторными интринзиками и типами? Типа как __m128/float32x4_t _mm_shuffle_ps/vcombine_f32? Но что мешает тогда использовать их в OpenCL? В nvidia драйвере полно таких вендорных расширений, их только проверить надо перед использованием, более того, можно ptx asm вставку сделать.
vikky13 Автор
10.09.2019 21:48Если всё очень сильно упростить (на порядок), то да. Что мешает? Мешает архитектура OpenCL, явно созданная для скалярной работы by design. Хотя появление расширений там неизбежно, скорость нужна всем.
berez
11.09.2019 22:15Простите, но в OpenCL есть векторые типы (например, int2/int4/int8/int16) и поддерживаются операции над ними. Чем это отличается от CM?
vikky13 Автор
12.09.2019 11:30В CM векторы могут иметь произвольную длину, а также существуют матрицы и поверхности. Это значительно влияет на производительность и возможности для целого ряда алгоритмов. Кроме того, в CM вся обработка — векторная, а в OpenCL это векторные фрагменты — именно о них можно думать как о векторных intinsic вставках в скалярный код.
ktod
11.09.2019 04:09С каких это пор ocl «не векторный»? Да, во многом «векторизация» задачи лежит на программисте. Но, это даже лучше, чем любая «внутренняя» векторизация компилятора.
Что значит «работает поэлементно»? Когда пишешь ядро, ты программируешь конкретный элемент комп. юнита, да, но следишь и реализовываешь решение так, чтоб суперпозиция доступа к памяти из разных элементов как раз и представляла собою вектор в том или ином виде. Это основнейшая основа разработки эффективных ядер ocl. В этом плане, ocl позволяет «выстрелить себе в ногу», да. Но, это признак определенной гибкости инструмента.
Я как то даже и не припомню задач в своей практике, быстродействие которых, по итогу оптимизации, не уперлась бы в пропускную способность памяти. И дизасм ядра под конкретную архитектуру gpu каждый раз выглядел вполне эффективно. Так что, с моей точки зрения, утверждения вида «ocl не векторный» выглядят ну очень странно, вы уж меня простите.vikky13 Автор
11.09.2019 11:30Задача — транспонирование матрицы :)) Но вообще — в посте описано как потратив около 10 минут времени запустить на вашей системе уже реализованный пример, например, линейного фильтра (или еще десяток варантов), увидеть скорость его работы и сравнить с самой эффективной реализацией OpenCL.
tumbler
Нет чтобы производительность в OpenCL улучшить, они свою CUDA пилить начали. Ну удачи в догонялках.
esrd
Как написала vikky13, CM действительно долгое время разрабатывался в Intel, но не был публично анонсирован и задокументирован. Например, давайте возьмем официальный GPU драйвер от 2015 года, найдем там библиотеку igfxcmrt32.dll и если посмотрим список экспортируемых ей функций, то найдем упоминавшуюся в статье CreateCmDevice. Да, эта библиотека CM runtime от 2015 года. Т.е. CM ведет свою историю, как минимум, со времен Sandy Bridge / Ivy Bridge процессоров, для встроенной графики которых, этот драйвер и предназначен. Сейчас Intel вывела эту технологию в свет, предоставив кроссплатформенное решение, документацию и даже код, что не может не радовать.
Если же проводить аналогии, то CM очень похож на CUDA от Intel и похоже, что позиционируется точно также. Он не вместо OpenCL, который Intel тоже развивает, а вместе. Если необходима универсальность и переносимость, используется OpenCL, если необходимо выжать из железки максимум, тогда CM.