
Подход IaC (Infrastructure as Code) состоит не только из кода, который хранится в репозитории, но еще людей и процессов, которые этот код окружают. Можно ли переиспользовать подходы из разработки ПО в управление и описание инфраструктуры? Будет не лишним держать в голове эту идею, пока будете читать статью.
Это расшифровка моего выступления на DevopsConf 2019-05-28.
Infrastructure as bash history

Предположим приходите вы на новый проект, а вам говорят: "у нас Infrastructure as Code". В реальности оказывается, Infrastructure as bash history или например Documentation as bash history. Это вполне реальная ситуация, например, подобный случай описывал Денис Лысенко в выступление Как заменить всю инфраструктуру и начать спать спокойно, он рассказал как из bash history они получили стройную инфраструктуру на проекте.
При некотором желание, можно сказать, что Infrastructure as bash history это как код:
- воспроизводимость: вы можете взять bash history, выполнить команды оттуда, возможно, кстати, вы получите рабочую конфигурацию на выходе.
- версионирование: вы знаете кто заходил и что делал, опять же не факт, что это вас приведет к рабочей конфигурации на выходе.
- история: история кто и что сделал. только вы не сможете ей пользоваться, если потеряете сервер.
Что же делать?
Infrastructure as Code
Даже такой странный случай как Infrastructure as bash history можно притянуть за уши к Infrastructure as Code, но когда мы захотим сделать что-нибудь посложнее чем старый добрый LAMPовый сервер, мы прийдем к тому, что этот код необходимо как-то модифицировать, изменять, дорабатывать. Далее хотелось мы будем рассматривать параллели между Infrastructure as Code и разработкой ПО.
D.R.Y.
На проекте по разработке СХД, была подзадача периодически настраивать SDS: выпускаем новый релиз — его необходимо раскатать, для дальнейшего тестирования. Задача предельно простая:
- сюда зайди по ssh и выполни команду.
- туда скопируй файлик.
- здесь подправь конфиг.
- там запусти сервис
- ...
- PROFIT!
Для описанной логики более чем достаточно bash, особенно на ранних стадиях проекта, когда он только стартует. Это не плохо что вы используете bash, но со временем появляются запросы развернуть нечто похожее, но чуть-чуть отличающиеся. Первое что приходит в голову: copy-paste. И вот у нас уже два очень похожих скрипта, которые делают почти тоже самое. Со временем кол-во скриптов выросло, и мы столкнулись с тем, что есть некая бизнес логика развертывания инсталляции, которую необходимо синхронизировать между разными скриптами, это достаточно сложно.
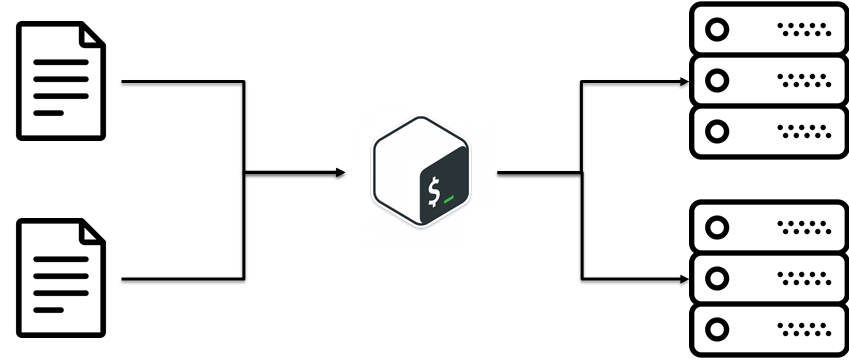
Оказывается, есть такая практика D.R.Y. (Do not Repeat Yourself). Идея в том, чтобы переиспользовать существующий код. Звучит просто, но пришли к этому не сразу. В нашем случае это была банальная идея: отделить конфиги от скриптов. Т.е. бизнес логика как разворачивается инсталляция отдельно, конфиги отдельно.
S.O.L.I.D. for CFM

Со временем проект рос и естественным продолжением стало появление Ansible. Основная причина появления его это наличие экспертизы в команде и что bash не предназначен для сложной логики. Ansible тоже стал содержать сложную логику. Для того что бы сложная логика не превращалась в хаос, в разработке ПО существуют принципы организации кода S.O.L.I.D. Так же, например, Григория Петров в докладе "Зачем айтишнику личный бренд" затронул вопрос, что человек, так устроен, что ему проще оперировать какими-то социальными сущностями, в разработке ПО это объекты. Если объединить эти две идеи продолжить развивать их, то можно заметить, что в описании инфраструктуры тоже можно использовать S.O.L.I.D. что бы в дальнейшем было проще поддерживать и модифицировать эту логику.
The Single Responsibility Principle

Каждый класс выполняет лишь одну задачу.
Не надо смешивать код и делать монолитные божественные макаронные монстры. Инфраструктура должна состоять из простых кирпичиков. Оказывается, что если раздробить Ansible playbook на небольшие кусочки, читай Ansible роли, то их проще поддерживать.
The Open Closed Principle
Принцип открытости/закрытости.
- Открыты для расширения: означает, что поведение сущности может быть расширено путём создания новых типов сущностей.
- Закрыты для изменения: в результате расширения поведения сущности, не должны вноситься изменения в код, который эти сущности использует.
Изначально мы разворачивали тестовую инфраструктуру на виртуальных машинах, но за счет того, что бизнес логика разворачивания была отдельно от реализации, мы без проблем добавили раскатку на baremetall.
The Liskov Substitution Principle

Принцип подстановки Барбары Лисков. объекты в программе должны быть заменяемыми на экземпляры их подтипов без изменения правильности выполнения программы
Если посмотреть шире, то не особенность какого-то конкретного проекта, что там можно применить S.O.L.I.D., оно в целом про CFM, например, на другом проекте необходимо разворачивать коробочное Java приложение поверх различных Java, серверов приложений, баз данных, OS, итд. На это примере я буду рассматривать дальнейшие принципы S.O.L.I.D.
В нашем случае в рамках инфраструктурной команды есть договоренность, что если мы установили роль imbjava или oraclejava, то у нас есть бинарный исполняймый файл java. Это нужно т.к. вышестоящее роли зависят от этого поведения, они ожидают наличие java. В тоже время это нам позволяет заменять одну реализацию/версию java на другую при этом не изменяя логику развертывания приложения.
Проблема здесь кроется в том, что в Ansible нельзя реализовать такое, как следствие в рамках команды появляются какие-то договоренности.
The Interface Segregation Principle
Принцип разделения интерфейса «много интерфейсов, специально предназначенных для клиентов, лучше, чем один интерфейс общего назначения.
Изначально мы пробовали складывать всю вариативность разворачивания приложения в один Ansible playbook, но это было сложно поддерживать, а подход, когда у нас специфицирован интерфейс наружу (клиент ожидает 443 порт) то под конкретную реализацию можно компоновать инфраструктуру из отдельных кирпичиков.
The Dependency Inversion Principle

Принцип инверсии зависимостей. Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Здесь пример будет основан на антипаттерне.
- У одного из заказчиков было приватное облако.
- Внутри облака мы заказывали виртуальные машины.
- Но в виду особенностей облака, развертывание приложения было привязано к тому, на какой гипервизор попала ВМ.
Т.е. высокоуровневая логика развертывания приложения, зависимостями протекала на нижележащие уровни гипервизора, и это означало проблемы при переиспользование этой логики. Не надо так.
Interaction

Инфраструктура как код — это не только про код, но ещё и про отношения между кодом и человеком, про взаимодействия между разработчиками инфраструктуры.
Bus factor
Предположим, что у вас на проекте есть Вася. Вася всё знает про вашу инфраструктуру, что будет если Вася вдруг пропадет? Это вполне реальная ситуация, ведь его может сбить автобус. Иногда такое случается. Если такое случится и знание об коде, его структуре, как он работает, явках и паролях, не распределены в команде, то можно столкнуться с рядом неприятных ситуаций. Что бы минимизировать эти риски и распределить знание в рамках команды можно использовать различные подходы
Pair Devopsing

Это не как в шутке, что админы пили пиво, пароли меняли, а аналог парного программирования. Т.е. два инженера садятся за один компьютер, одну клавиатуру и начинают вместе настраивать вашу инфраструктуру: сервер настраивать, Ansible роль писать, итд. Звучит красиво, но у нас не сработало. Но вот частные случаи этой практики работали. Пришел новый сотрудник, его наставник вместе с ним берет реальную задачу, работает — передает знание.
Другой частный случай, это incident call. Во время проблемы собирается группа дежурных и причастных, назначается один ведущий, который расшаривает свой экран и озвучивает ход мысли. Другие участники следуют за мыслью ведущего, подсматривают трюки из консоли, проверяют что не пропустил строчку в логе, узнают новое об системе. Такой подход скорее работал, чем нет.
Code Review
Субьективно, более эффективно распространение знаний об инфраструктуре и том как она устроена проходило при помощи code review:
- Инфраструктура описана кодом в репозитории.
- Изменения происходят в отдельной ветке.
- При мердже реквесте можно увидеть дельту изменений инфраструктуру.
Изюминкой здесь было, то что ревьюверы выбирались по очереди, по графику, т.е. с некоторой долей вероятности ты залезешь в новый участок инфраструктуры.
Code Style

Со временем стали появляться склоки во время ревью, т.к. у ревьюверов был свой стиль и ротируемости ревьюверов стакивала их с разными стилями: 2 пробела или 4, camelCase или snake_case. Внедрить это получилось не сразу.
- Первой идей было рекомендательно посоветовать использовать linter, ведь все же инженеры, все умные. Но разные редакторы, ОС, не удобно
- Это эволюционировало в бота, который по каждому коммиту проблемному писал в slack, и прикладывал вывод linter. Но в большинстве случаев находились более важные дела и код оставался не исправленным.
Green Build Master
Время идет, и пришли к тому что нельзя пускать в мастер коммиты, которые не проходят некие тесты. Вуаля! мы изобрели Green Build Master который уже давным-давно практикуется в разработке ПО:
- Разработка идет в отдельной ветке.
- По этой ветке гоняются тесты.
- Если тесты не проходят, то код не попадет в мастер.
Принятие этого решения было весьма болезненным, т.к. вызвало множество споров, но оно того стоило, т.к. на ревью стали приходить запросы на слияние без разногласий по стилю и со временем кол-во проблемных мест стало уменьшаться.
IaC Testing

Кроме проверки стиля можно использовать и другие вещи, например, проверять что ваша инфраструктура действительно может развернуться. Или проверять что изменения в инфраструктуре не приведут к потере денег. Зачем это может понадобиться? Вопрос сложный и философский, ответить лучше байкой, что как-то был auto-scaler на Powershell который, не проверял пограничные условия => создалось больше ВМ чем надо => клиент потратил денег больше чем планировал. Приятного мало, но эту ошибку вполне реально было бы отловить на более ранних стадиях.
Можно спросить, а зачем делать сложную инфраструктуру еще сложнее? Тесты для инфраструктуры, так же, как и для кода, это не про упрощение, а про знание как ваша инфраструктура должна работать.
IaC Testing Pyramid

IaC Testing: Static Analysis
Если сразу разворачивать всю инфраструктуру и проверять, что она работает, то может оказаться, что это занимает уйму времени и требует кучу времени. Поэтому в основе должно быть что-то быстро работающее, его много, и оно покрывают множество примтивных мест.
Bash is tricky
Вот рассмотрим банальный пример. выбрать все файлы в текущей директории и скопировать в другое место. Первое что приходит в голову:
for i in * ; do
cp $i /some/path/$i.bak
doneА что если в имени файла пробел есть? Ну ок, мы же умные, умеем пользоваться кавычками:
for i in * ; do cp "$i" "/some/path/$i.bak" ; doneМолодцы? нет! Что если в директории нет ничего, т.е. глобинг не сработает.
find . -type f -exec mv -v {} dst/{}.bak \;Теперь то молодцы? неа… Забыли что в имени файла может быть \n.
touch x
mv x "$(printf "foo\nbar")"
find . -type f -print0 | xargs -0 mv -t /path/to/target-dirStatic analysis tools
Проблему из предыдущего шага можно было отловить когда мы забыли кавычки, для это в природе существует множество средство Shellcheck, вообще их много, и скорей всего вы сможете найти под свою IDE линтер для вашего стэка.
| Language | Tool |
|---|---|
| bash | Shellcheck |
| Ruby | RuboCop |
| python | Pylint |
| ansible | Ansible Lint |
IaC Testing: Unit Tests
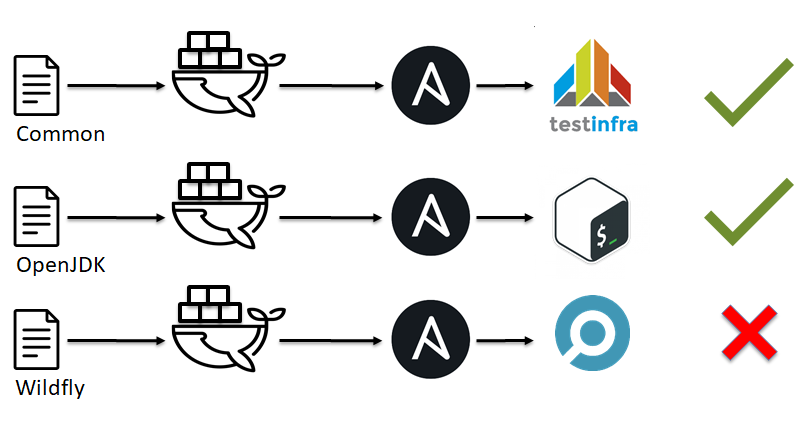
Как мы убедились из предыдущего примера, линтеры не всемогущие и не могут указать на все проблемные места. Дальше по аналогии с тестированием в разработке ПО можно вспомнить про unit tests. Тут сразу на ум приходят shunit, junit, rspec, pytest. Но что делать с ansible, chef, saltstack и иже с ними?
В самом начале мы говорили про S.O.L.I.D. и то что наша инфраструктура должна состоять из маленьких кирпичиков. Пришло их время.
- Инфраструктура дробится на маленькие кирпичики, например, Ansible роли.
- Разворачивается какое-то окружение, будь то docker или ВМ.
- На это тестовое окружение применяем нашу Ansible роль.
- Проверяем что все отработало как мы ожидаем (прогоняем тесты).
- Решаем ок или не ок.
IaC Testing: Unit Testing tools
Вопрос, а что такое тесты для CFM? можно банально запускать скрипт, а можно использовать готовые решения для этого:
| CFM | Tool |
|---|---|
| Ansible | Testinfra |
| Chef | Inspec |
| Chef | Serverspec |
| saltstack | Goss |
Пример для testinfra, проверяем что пользователи test1, test2 существуют и состоят в группе sshusers:
def test_default_users(host):
users = ['test1', 'test2' ]
for login in users:
assert host.user(login).exists
assert 'sshusers' in host.user(login).groupsЧто выбрать? вопрос сложный и не однозначный, вот пример изменения в проектах на github за 2018-2019 года:

IaC Testing frameworks
Возникает как это все собрать вместе и запустить? Можно взять и сделать всё самому при наличии достаточного кол-во инженеров. А можно взять готовые решения, правда их не очень-то и много:
| CFM | Tool |
|---|---|
| Ansible | Molecule |
| Chef | Test Kitchen |
| Terraform | Terratest |
Пример изменения в проектах на github за 2018-2019 года:

Molecule vs. Testkitchen

Изначально мы пробовали использовать testkitchen:
- Создать ВМ в параллель.
- Применить Ansible роли.
- Прогонять inspec.
Для 25-35 ролей это работало 40-70 минут, что было долго.
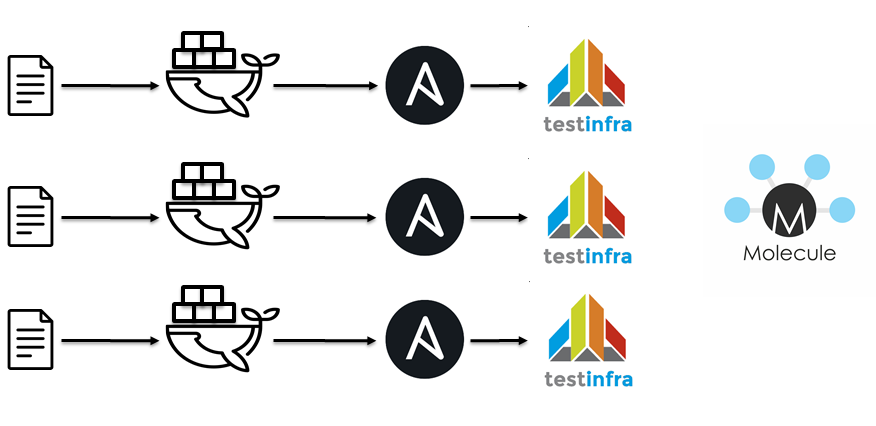
Следующим шагом стал переход на jenkins / docker / ansible / molecule. Идиологически все тоже самое
- Пролинтовать плэйбуки.
- Пролинтовать роли.
- Запустить контейнер
- Применить Ansible роли.
- Прогонять testinfra.
- Проверить идемпотентность.
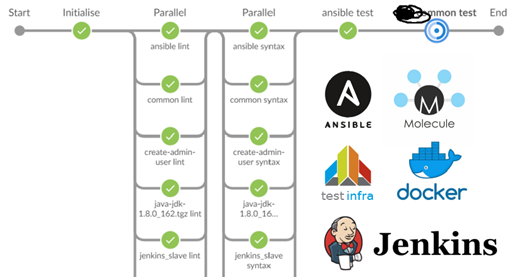
Линтовка для 40 ролей и тесты для десятка стали занимать порядка 15 минут.

Что выбрать зависит от множества факторов, как то используемый стэк, экспертиза в команде итд. тут каждый решает сам как закрывать вопрос Unit тестирования
IaC Testing: Integration Tests
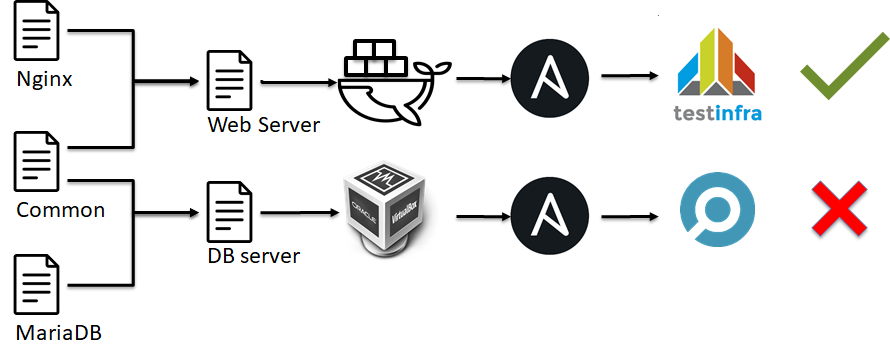
На следующей ступени пирамиды тестирования инфраструктуры появлются интеграционные тесты. Они похожи на Unit тесты:
- Инфраструктура дробится на маленькие кирпичики, например Ansible роли.
- Разворачивается какое-то окружение, будь то docker или ВМ.
- На это тестовое окружение применяется множество Ansible ролей.
- Проверяем что все отработало как мы ожидаем(прогоняем тесты).
- Решаем ок или не ок.
Грубо говоря, мы не проверяем работоспособность отдельного элемента системы как в unit тестах, мы проверяем как сервер сконфигурирован в целом.
IaC Testing: End to End Tests
На вершине пирамиды нас встречают End to End тесты. Т.е. мы не проверяем работоспособность отдельного сервера, отдельного скрипта, отдельного кирпичика нашей инфраструктуры. Мы проверяем что множество серверов, объединенных воедино, наша инфраструктура работает, как мы этого ожидаем. К сожалению готовых коробочных решений, мне не доводилось видеть, наверно т.к. инфраструктура за частую уникальная и ее сложно шаблонизировать и сделать фрэймворк для ее тестирования. Как итог все создают свои собственные решению. Спрос есть, а вот ответа нет. Поэтому, расскажу что есть, чтобы натолкнуть других на здравые мысли или ткнуть меня носом, что всё давно изобретено до нас.
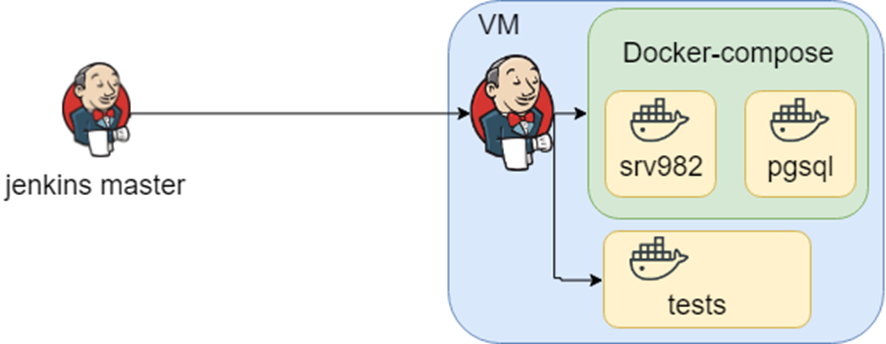
Проект с богатой историей. Используется в больших организациях и вероятно каждый из вас косвенно пересекался. Приложение поддерживает множество баз данных, интеграций итд итп. Знание о том, как инфраструктура может выглядеть это множество docker-compose файлов, а знание того, какие тесты в каком окружение запускать — это jenkins.
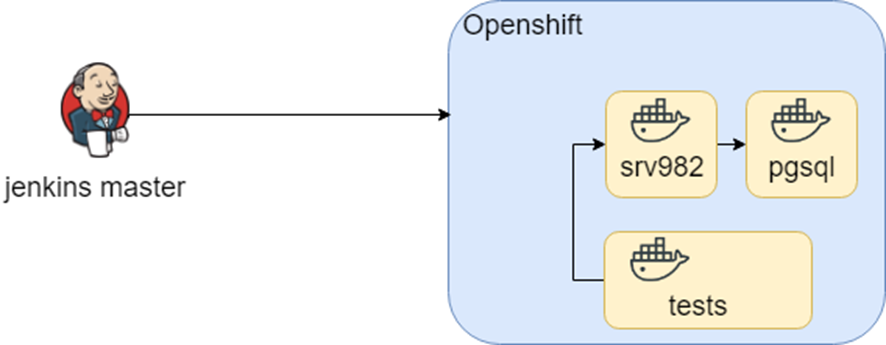
Эта схема достаточно долго работала, пока в рамках исследования мы не попробовали это перенести в Openshift. Контейнеры остались теже, а вот среда запуска сменилась (привет D.R.Y. опять).
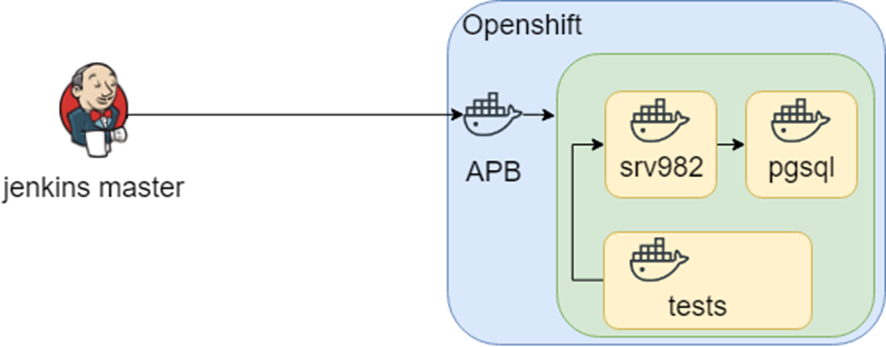
Мысль исследования пошла дальше, и в openshift нашлась такая штука APB (Ansible Playbook Bundle), которая позволяет в контейнер запаковать знание как разворачивать инфраструктуру. Т.е. есть воспроизводимая, тестируемая точка знания, как развернуть инфраструктуру.

Всё это звучало хорошо, пока не уткнулись в гетерогенную инфраструктуру: нам для тестов нужна Windows. В итоге знание о том что, где как развернуть, и протестировать сидит в jenkins.
Conclusion
Infrastructure as Code это
- Код в репозитории.
- Взаимодействие людей.
- Тестирование инфраструктуры.
- English Version
- Cross post из личного блога
- Dry run 2019-04-24 SpbLUG
- Video(RU) from DevopsConf 2019-05-28
- Video(RU) from DINS DevOps EVENING 2019-06-20
- Lessons Learned From Writing Over 300,000 Lines of Infrastructure Code & text version
- Integrating Infrastructure as Code into a Continuous Delivery Pipeline
- Тестируем инфраструктуру как код
- Эффективная разработка и сопровождение Ansible-ролей
- Ansible — это вам не bash!
TheStarOf
По человечески о девопсе.
Спасибо!