
Умение работать внутри системы контроля версий — навык, который требуется каждому программисту. Зачастую может показаться, что закапываться в Git и разбираться в его внутренностях — лишняя потеря времени и основные задачи можно решить через базовый набор команд.
Команде AppsCast, конечно, захотелось узнать больше, и за консультацией по практическому применению всех возможностей Git ребята обратились к Егору Андреевичу из Square.
Даниил Попов: Всем привет. Сегодня к нам присоединился Егор Андреевич из Square.
Егор Андреевич: Всем привет. Я живу в Канаде и работаю в компании Square, которая занимается разработкой software и hardware для финансовой индустрии. Начинали с терминалов для приема платежей кредитными картами, сейчас же делаем сервисы для владельцев бизнесов. Я работаю над продуктом Cash App. Это мобильный банк, который позволяет обмениваться деньгами с друзьями, заказывать дебетовую карту для оплаты в магазинах. У компании множество офисов по всему миру, а в канадском офисе порядка 60 программистов.
Даниил Попов: В среде андроид-разработчиков Square известна благодаря своим open-source проектам, которые стали стандартами индустрии: OkHttp, Picasso, Retrofit. Логично, что разрабатывая такие открытые для всех инструменты, вы много работаете с Git. Об этом мы бы и хотели поговорить.
Егор Андреевич: Я давно использую Git как инструмент, и в какой-то момент мне стало интересно узнать о нем больше.
Git позволяет сохранять файлы в определенном формате. Каждый раз при записи файла Git возвращает ключ к вашему объекту — hash.
Даниил Попов: Многие замечали, что в репозитории есть магическая скрытая директория .git. Зачем она нужна? Могу ли я ее удалить или переименовать?
Егор Андреевич: Создание репозитория возможно через команду git init. Она создает директорию .git, которую Git использует для контроля файлов. В .git хранится все, что вы делаете в своем проекте, только в сжатом формате. Поэтому из этой директории можно восстановить репозиторий.
Алексей Кудрявцев: Получается, что твоя папка с проектом — это одна из версий разжатой папки Git?
Егор Андреевич: В зависимости от того, на какой ветке ты находишься, git восстанавливает проект, с которым можно работать.
Алексей Кудрявцев: Что лежит внутри папки?
Егор Андреевич: Git создает специфические папки и файлы. Самая важная папка — .git/objects, где хранятся все объекты. Самый простой объект — это blob, по сути то же самое, что и файл, но в формате, который понимает git. Когда вы хотите сохранить текстовый файл в репозитории, Git его обжимает, архивирует, добавляет данные и создает blob.
Есть директории — этакие папки с подпапками, т.е. у Git есть тип объекта tree, который содержит ссылки на blob, на другие trees.
При создании коммита (commit) фиксируется ссылка на рабочую директорию — tree.
Коммит — это ссылка на tree с информацией о том, кто его создал: email, имя, время создания, ссылка на parent (родительскую ветку) и сообщение. Коммиты Git также сжимает и записывает в директорию object.
Для того чтобы посмотреть, как это все устроено, надо с командной строки вывести список поддиректорий.
Даниил Попов: Как Git работает? Почему алгоритм действий такой сложный?
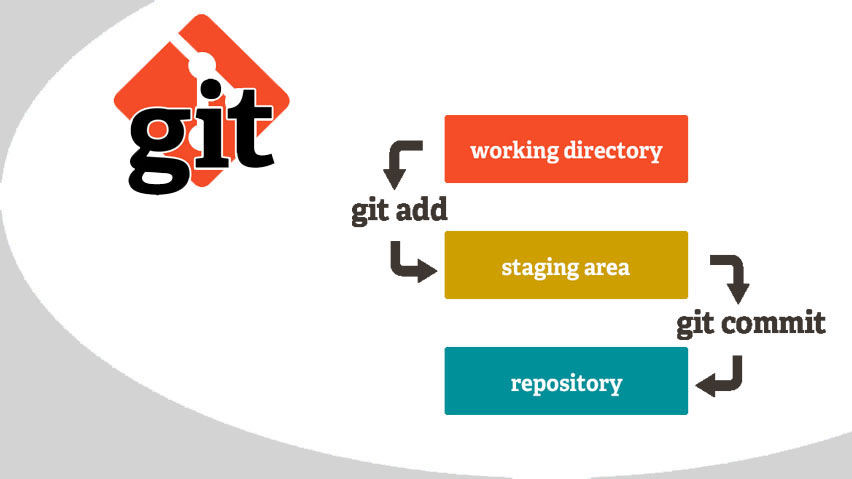
Егор Андреевич: Если сравнивать Git с Subversion (SVN), то в первой системе есть ряд функций, которые нужно понимать. Начну с staging area, которую не стоит считать ограничением Git, а скорее фичей.
Прекрасно известно, что при работе с кодом не все сразу идет по маслу: где-то надо поменять layout, где-то пофиксить баги. В итоге после сессии работы появляется ряд затронутых файлов, которые между собой не связаны. Если все изменения занести в один коммит, то это будет неудобно, так как изменения разные по характеру. Тогда на выход приходит серия коммитов, которую можно создать как раз благодаря staging area. В одну серию, например, отправляются все изменения layout-файла, в другую — фикс unit-тестов. Мы берем несколько файлов, перемещаем в staging area и создаем коммит только с их участием. Остальные файлы из рабочей директории в него не попадают. Таким образом, вы разбиваете всю работу, проведенную в рабочей директории, на несколько коммитов, каждый из которых представляет определенную работу.
Алексей Кудрявцев: Чем Git отличается от других систем контроля версий?
Егор Андреевич: Лично я начинал с SVN и после сразу перешел на Git. Важно, что Git — децентрализованная система контроля версий. Все копии репозитория Git абсолютно одинаковы. В каждой компании есть сервер, где лежит основная версия, но она ничем не отличается от той, что лежит у разработчика на компьютере.
SVN имеет центральный репозиторий и локальные копии. Значит, любой разработчик может в одиночку сломать центральный репозиторий.
В Git такого не произойдет. Если центральный сервер потеряет данные репозитория, его можно будет восстановить с любой локальной копии. Git по-другому устроен, и это дает преимущества скорости работы.
Даниил Попов: Git славится своим ветвлением, которое работает заметно быстрее чем SVN. Как ему это удается?
Егор Андреевич: В SVN ветка (branch) — это полная копия предыдущей ветки. В Git физического представления ветки нет. Это ссылка на последний коммит в определенной линии разработки. Когда Git сохраняет объекты, при создании коммита он создает файл с определенной информацией о коммите. Git создает символический файл — symlink со ссылкой на другой файл. Когда у вас много веток, то вы ссылаетесь на разные коммиты в репозитории. Чтобы отследить историю ветки, нужно переходить из каждого коммита по ссылке назад на родительский коммит.
Даниил Попов: Есть два способа как слить две ветки в одну — это merge и rebase. Как вы ими пользуетесь?
Егор Андреевич: У каждого способа свои преимущества и недостатки. Merge — самый простой вариант. Например, есть две ветки: master и выделенная из нее feature.
Для merge можно использовать fast forward. Это возможно, если с того момента, как была начата работа в feature-ветке, в master не было сделано новых коммитов. То есть первый коммит в feature — это последний коммит в master.
В таком случае указатель фиксируется на ветке master и перемещается на самый последний коммит в ветке feature. Таким образом ветвление устраняется через соединение feature-ветки с основным потоком master и удаление ненужной ветки. Получается линейная история, где все коммиты следуют друг за другом. На практике такой вариант случается нечасто, так как постоянно кто-то сливает коммиты в master.
Можно иначе. Git создает новый коммит — merge commit, у которого две ссылки на родительские коммиты: один в master, другой в feature. С помощью нового коммита происходит соединение двух веток и feature снова можно удалять.
После merge commit можно посмотреть историю и увидеть, что она раздвоилась. Если вы используете tool, который графически рендерит коммиты, то визуально это будет похоже на «ёлочку». Это не ломает Git, но разработчику смотреть такую историю сложно.
Другой инструмент — rebase. Концептуально вы берете все изменения с feature-ветки и перебрасываете поверх ветки master. Первый коммит feature становится новым коммитом поверх наиболее позднего коммита master.
Тут есть загвоздка — Git не может менять коммиты. Был коммит в feature и мы не можем просто перенести поверх master, так как в каждом коммите есть time stamp.
В случае с rebase Git считывает все коммиты в feature, временно сохраняет, а затем пересоздает в том же порядке в master. После rebase изначальные коммиты пропадают, а поверх master появляются новые коммиты с тем же контентом. Тут возникают проблемы. При попытке сделать rebase ветки, с которой работают другие люди, можно поломать репозиторий. Например, если кто-то начал свою ветку из коммита, который был в feature, а вы этот коммит уничтожили и пересоздали. Rebase подходит больше для локальных веток.
Даниил Попов: Если ввести ограничения, что над одной feature-веткой работает строго один человек, договориться, что нельзя отпочковывать одну feature-ветку от другой, то такой проблемы не возникает. Но какой подход практикуете вы?
Егор Андреевич: Мы не используем feature-ветки в прямом понимании этого термина. Каждый раз, когда мы производим изменение, создаем новую ветку, работаем в ней и сразу вливаем в master. Нет долгоиграющих веток.
Это решает большое количество проблем с merge и rebase, особенно конфликты. Ветки существуют один час и высока вероятность использования fast forward, так как никто ничего не добавил в master. Когда же мы делаем merge в pull request, то только merge c созданием merge commit
Даниил Попов: Как вы не боитесь сливать master неработающую фичу, ведь декомпозировать задачу на часовые интервалы часто нереально?
Егор Андреевич: Мы используем подход feature flags. Это динамические флаги, определенная фича с разными состояниями. Например, функция отправлять платежи друг другу либо включена, либо выключена. У нас есть сервис, который динамически доставляет это состояние клиентам. Вы с сервера получаете значение выключена фича или нет. Это значение вы можете использовать в коде — выключить кнопку, которая идет в скрин. Сам код есть в приложении, и его можно зарелизить, но доступа в этот функционал нет, потому что он за feature flag.
Даниил Попов: Часто новичкам в Git говорят, чтобы после rebase нужно делать push с force. Откуда это?
Егор Андреевич: Когда вы делаете просто push, другой репозиторий может выкинуть ошибку: вы пытаетесь запушить ветку, но у вас на этой ветке абсолютно другие коммиты. Git проверяет всю информацию, чтобы вы случайно не поломали репозиторий. Когда вы говорите git push force, то выключаете этот чекинг, считая, что знаете лучше него, и требуете переписать ветку.
Почему это нужно после rebase? Rebase пересоздает коммиты. Получается, что ветка называется также, но коммиты в ней с другими хэшами, и Git на вас ругается. В этой ситуации абсолютно нормально сделать force push, так как вы контролируете ситуацию.
Даниил Попов: Еще есть понятие interactive rebase, и многие его боятся.
Егор Андреевич: Страшного ничего нет. За счет того, что Git пересоздает историю при rebase, он временно ее хранит перед тем как перекинуть. Когда у него есть временный storage, он может с коммитами делать все, что угодно.
Rebase в интерактивном режиме предполагает, что Git перед rebase выкидывает окошко текстового редактора, в котором можно указать, что надо сделать с каждым отдельным коммитом. Это выглядит как несколько линий текста, где каждая линия — один из коммитов, которые есть в ветке. Перед каждым коммитом есть указание операции, которую стоит выполнить. Самая простая операция по умолчанию — pick, т.е. взять и включить в rebase. Самая распространенная — squash, тогда Git возьмет изменения из этого коммита и объединит с изменениями предыдущего.
Часто встречается такой сценарий. Вы работали локально в своей ветке и создавали коммиты для сейва. Получилась длинная история коммитов, которая для вас интересна, но в таком же варианте ее в основную историю не стоит заливать. Тогда вы даете squash для переименования в общий коммит.
Список команд длинный. Можно выбросить коммит — drop и он исчезнет, можно поменять сообщение коммита и т.д.
Алексей Кудрявцев: Когда у тебя появляются конфликты в интерактивном rebase, ты проходишь через все круги ада.
Егор Андреевич: Я очень далек от того, чтобы постичь всю мудрость интерактивного rebase, но это мощный инструмент и сложный.
Даниил Попов: Перейдем к практике. На собеседовании я часто спрашиваю: «У тебя есть тысяча коммитов. На первом все хорошо, на тысячном сломался тест. Как с помощью гита можно найти изменение, которое к этому привело?»
Егор Андреевич: В этой ситуации нужно использовать bisect, хотя проще брать blame.
Начнем с интересного. Git bisect применим к ситуации, когда у вас есть regression — был функционал, работал, но вдруг перестал. Чтобы найти, когда сломался функционал, можно теоретически наугад откатиться на предыдущую версию приложения, посмотреть в код, но есть инструмент, который позволит структурировано подойти к проблеме.
Git bisect — интерактивный инструмент. Есть команда git bisect bad, через которую вы сообщаете о наличии поломанного коммита и git bisect good — для рабочего коммита. Каждый раз при релизе приложения мы запоминаем hash коммита, с которого сделан релиз. Этот hash также можно использовать для указания плохих и хороших коммитов. Bisect получает информацию о промежутке, где какой-то из коммитов поломал функционал, и запускает сессию binary search, где постепенно выдает коммиты на проверку, работают они или нет.
Вы запустили сессию, Git переключается на один из коммитов в промежутке, сообщает об этом. В случае с тысячью коммитов будет не так много итераций.
Проверку придется выполнять вручную: через юнит-тесты или запустить приложение и прокликать мануально. Git bisect удобно скриптить. Каждый раз, когда он выдает коммит, даете ему скрипт проверки работоспособности кода.
Blame — это более простой инструмент, который исходя из своего названия позволяет найти «виновника» поломки функционала. За счет этого негативного определения многие в коммьюнити blame недолюбливают.
Что он делает? Если вы даете git blame определенный файл, то он полинейно в этом файле покажет, какой коммит менял ту или иную линию. Я никогда не использовал git blame с командной строки. Как правило это делают в IDEA или Android Studio — кликаете и видите, кто какую линию файла поменял и в каком коммите.
Даниил Попов: Кстати в Android Studio это назвали Annotate. Убрали негативную коннотацию blame.
Алексей Кудрявцев: Точно, в xCode они переименовали его в Authors.
Егор Андреевич: Еще я читал, что есть утилита git praise — найти того, кто написал этот отличный код.
Даниил Попов: Нужно заметить что по blame работают предложения ревьюеров на pull request. Он смотрит, кто больше всего трогал тот или иной файл, и предполагает, что этот человек сможет хорошо поревьюить ваш код.
В случае с примером про тысячу коммитов blame в 99% случаев покажет, что пошло не так. Bisect — это уже last resort.
Егор Андреевич: Да, к bisect я прибегаю крайне редко, а вот annotate использую регулярно. Хотя иногда по линии кода нельзя понять, почему там null checked, зато по всему коммиту ясно, что хотел сделать автор.
Даниил Попов: Я слышал, что в Square применяется Stacked pull requests (PRs).
Егор Андреевич: Как минимум в нашей андроид-команде мы часто их используем.
Мы очень много времени уделяем тому, чтобы каждый pull request было легко ревьюить. Иногда есть соблазн накодить, быстро закоммить, и пусть ревьюеры разбираются. Мы стараемся создавать небольшие pull request’ы и краткое описание — код должен говорить сам за себя. Когда pull request’ы маленькие — их легко и быстро заревьюить.
Здесь возникает проблема. Вы работаете над функционалом, который потребует большого количества изменений в code base. Что вы можете сделать? Можно положить в один pull request, но тогда он будет огромным. Можно работать постепенно создавая pull request, но тогда проблема будет в том, что вы создали branch, добавили несколько изменений и засабмитили pull request, вернулись на master и тот код, который был у вас в pull request, недоступен в master до того момента, пока не произойдет merge. Если вы зависите от изменений в этих файлах, то сложно продолжать работу, потому что этого кода нет.
Как мы это обходим? После того, как мы создали первый pull request, продолжаем работу, создаем новую ветку из существующей ветки, которую мы использовали до pull request. Каждая ветка идет не из master, а из предыдущей ветки. Когда заканчиваем работу над этим куском функционала, сабмитим еще один pull request и опять же указываем, что при merge он мержится не в master, а в предыдущий branch. Получается такая цепочка pull request’ов — stacked prs. Когда человек ревьюит, он видит изменения, которые были внесены только этой фичей, но не предыдущей.
Задача в том, чтобы каждый pull request был как можно меньше и понятней, чтобы не возникало необходимости изменять. Потому что если придется менять код в ветках, которые находятся в середине stacked, все, что сверху, поломается, так как придется делать rebase. Если pull request’ы маленькие, мы стараемся как можно быстрее из замержить, тогда весь stacked пошагово сливается в master.
Даниил Попов: Правильно я понимаю, что в итоге будет какой-то последний pull request, который содержит в себе все маленькие pull request’ы. Вы эту ветку не глядя вливаете?
Егор Андреевич: Merge происходит из истока stacked: сначала в master мержится самый первый pull request, в следующем меняется base из ветки в master и, соответственно, Git вычисляет, что в master уже какие-то изменения есть, snapshot получается меньше.
Алексей Кудрявцев: Бывают ли у вас состояния гонок, когда первая ветка уже замерджилась, а только после этого вторая в первую замержилась, потому что ей не поменяли таргет на master?
Егор Андреевич: Мы мержим вручную, поэтому таких ситуаций не бывает. Я открываю pull request, отмечаю коллег, от которых я хочу получить ревью и, когда они заапрувили, иду на bitbucket, нажимаю merge.
Алексей Кудрявцев: А как же проверки на CI, что ничего не сломано?
Егор Андреевич: Такого мы не делаем. CI работает на ветке, которая является базой для pull request и после проверки мы меняем base. Технически он не меняется, так как таргетишь тоже количество изменений.
Даниил Попов: А вы прямо в master пушите или все же develop? И при релизе явно указываете коммит, с которого собирать?
Егор Андреевич: У нас нет develop, только master. Мы обязательно релизим каждые две недели. Когда мы начинаем готовить релиз, открываем релиз-ветку и какие-то последние фиксы идут и в master, и в эту ветку. Используем tags — перманентные ссылки на определенный коммит опционально с какой-то информацией. Если какой-то коммит — это релиз-коммит, то хорошо бы сохранить в истории, что с этого коммита мы сделали релиз. Создается тэг, Git сохраняет информацию с версией, и позже к нему можно вернуться.
Алексей Кудрявцев: Где поучить Git, что почитать?
Егор Андреевич: У Git есть официальная книга. Мне нравится, как она написана, есть хорошие примеры. Есть глава про внутренности, можно ее досконально изучить. На StackOverflow можно найти множество эзотерических ситуаций и решений. Ими тоже можно пользоваться.
Команде AppsCast, конечно, захотелось узнать больше, и за консультацией по практическому применению всех возможностей Git ребята обратились к Егору Андреевичу из Square.
Даниил Попов: Всем привет. Сегодня к нам присоединился Егор Андреевич из Square.
Егор Андреевич: Всем привет. Я живу в Канаде и работаю в компании Square, которая занимается разработкой software и hardware для финансовой индустрии. Начинали с терминалов для приема платежей кредитными картами, сейчас же делаем сервисы для владельцев бизнесов. Я работаю над продуктом Cash App. Это мобильный банк, который позволяет обмениваться деньгами с друзьями, заказывать дебетовую карту для оплаты в магазинах. У компании множество офисов по всему миру, а в канадском офисе порядка 60 программистов.
Даниил Попов: В среде андроид-разработчиков Square известна благодаря своим open-source проектам, которые стали стандартами индустрии: OkHttp, Picasso, Retrofit. Логично, что разрабатывая такие открытые для всех инструменты, вы много работаете с Git. Об этом мы бы и хотели поговорить.
Что такое Git
Егор Андреевич: Я давно использую Git как инструмент, и в какой-то момент мне стало интересно узнать о нем больше.
Git — это упрощенная файловая система, поверх которой находится набор операций для работы с контролем версий.
Git позволяет сохранять файлы в определенном формате. Каждый раз при записи файла Git возвращает ключ к вашему объекту — hash.
Даниил Попов: Многие замечали, что в репозитории есть магическая скрытая директория .git. Зачем она нужна? Могу ли я ее удалить или переименовать?
Егор Андреевич: Создание репозитория возможно через команду git init. Она создает директорию .git, которую Git использует для контроля файлов. В .git хранится все, что вы делаете в своем проекте, только в сжатом формате. Поэтому из этой директории можно восстановить репозиторий.
Алексей Кудрявцев: Получается, что твоя папка с проектом — это одна из версий разжатой папки Git?
Егор Андреевич: В зависимости от того, на какой ветке ты находишься, git восстанавливает проект, с которым можно работать.
Алексей Кудрявцев: Что лежит внутри папки?
Егор Андреевич: Git создает специфические папки и файлы. Самая важная папка — .git/objects, где хранятся все объекты. Самый простой объект — это blob, по сути то же самое, что и файл, но в формате, который понимает git. Когда вы хотите сохранить текстовый файл в репозитории, Git его обжимает, архивирует, добавляет данные и создает blob.
Есть директории — этакие папки с подпапками, т.е. у Git есть тип объекта tree, который содержит ссылки на blob, на другие trees.
В принципе, один tree — это snapshot, описывающий состояние вашей директории на определенный момент.
При создании коммита (commit) фиксируется ссылка на рабочую директорию — tree.
Коммит — это ссылка на tree с информацией о том, кто его создал: email, имя, время создания, ссылка на parent (родительскую ветку) и сообщение. Коммиты Git также сжимает и записывает в директорию object.
Для того чтобы посмотреть, как это все устроено, надо с командной строки вывести список поддиректорий.
Преимущества работы с Git
Даниил Попов: Как Git работает? Почему алгоритм действий такой сложный?
Егор Андреевич: Если сравнивать Git с Subversion (SVN), то в первой системе есть ряд функций, которые нужно понимать. Начну с staging area, которую не стоит считать ограничением Git, а скорее фичей.
Прекрасно известно, что при работе с кодом не все сразу идет по маслу: где-то надо поменять layout, где-то пофиксить баги. В итоге после сессии работы появляется ряд затронутых файлов, которые между собой не связаны. Если все изменения занести в один коммит, то это будет неудобно, так как изменения разные по характеру. Тогда на выход приходит серия коммитов, которую можно создать как раз благодаря staging area. В одну серию, например, отправляются все изменения layout-файла, в другую — фикс unit-тестов. Мы берем несколько файлов, перемещаем в staging area и создаем коммит только с их участием. Остальные файлы из рабочей директории в него не попадают. Таким образом, вы разбиваете всю работу, проведенную в рабочей директории, на несколько коммитов, каждый из которых представляет определенную работу.
Алексей Кудрявцев: Чем Git отличается от других систем контроля версий?
Егор Андреевич: Лично я начинал с SVN и после сразу перешел на Git. Важно, что Git — децентрализованная система контроля версий. Все копии репозитория Git абсолютно одинаковы. В каждой компании есть сервер, где лежит основная версия, но она ничем не отличается от той, что лежит у разработчика на компьютере.
SVN имеет центральный репозиторий и локальные копии. Значит, любой разработчик может в одиночку сломать центральный репозиторий.
В Git такого не произойдет. Если центральный сервер потеряет данные репозитория, его можно будет восстановить с любой локальной копии. Git по-другому устроен, и это дает преимущества скорости работы.
Даниил Попов: Git славится своим ветвлением, которое работает заметно быстрее чем SVN. Как ему это удается?
Егор Андреевич: В SVN ветка (branch) — это полная копия предыдущей ветки. В Git физического представления ветки нет. Это ссылка на последний коммит в определенной линии разработки. Когда Git сохраняет объекты, при создании коммита он создает файл с определенной информацией о коммите. Git создает символический файл — symlink со ссылкой на другой файл. Когда у вас много веток, то вы ссылаетесь на разные коммиты в репозитории. Чтобы отследить историю ветки, нужно переходить из каждого коммита по ссылке назад на родительский коммит.
Мерджим ветки
Даниил Попов: Есть два способа как слить две ветки в одну — это merge и rebase. Как вы ими пользуетесь?
Егор Андреевич: У каждого способа свои преимущества и недостатки. Merge — самый простой вариант. Например, есть две ветки: master и выделенная из нее feature.
Для merge можно использовать fast forward. Это возможно, если с того момента, как была начата работа в feature-ветке, в master не было сделано новых коммитов. То есть первый коммит в feature — это последний коммит в master.
В таком случае указатель фиксируется на ветке master и перемещается на самый последний коммит в ветке feature. Таким образом ветвление устраняется через соединение feature-ветки с основным потоком master и удаление ненужной ветки. Получается линейная история, где все коммиты следуют друг за другом. На практике такой вариант случается нечасто, так как постоянно кто-то сливает коммиты в master.
Можно иначе. Git создает новый коммит — merge commit, у которого две ссылки на родительские коммиты: один в master, другой в feature. С помощью нового коммита происходит соединение двух веток и feature снова можно удалять.
После merge commit можно посмотреть историю и увидеть, что она раздвоилась. Если вы используете tool, который графически рендерит коммиты, то визуально это будет похоже на «ёлочку». Это не ломает Git, но разработчику смотреть такую историю сложно.
Другой инструмент — rebase. Концептуально вы берете все изменения с feature-ветки и перебрасываете поверх ветки master. Первый коммит feature становится новым коммитом поверх наиболее позднего коммита master.
Тут есть загвоздка — Git не может менять коммиты. Был коммит в feature и мы не можем просто перенести поверх master, так как в каждом коммите есть time stamp.
В случае с rebase Git считывает все коммиты в feature, временно сохраняет, а затем пересоздает в том же порядке в master. После rebase изначальные коммиты пропадают, а поверх master появляются новые коммиты с тем же контентом. Тут возникают проблемы. При попытке сделать rebase ветки, с которой работают другие люди, можно поломать репозиторий. Например, если кто-то начал свою ветку из коммита, который был в feature, а вы этот коммит уничтожили и пересоздали. Rebase подходит больше для локальных веток.
Даниил Попов: Если ввести ограничения, что над одной feature-веткой работает строго один человек, договориться, что нельзя отпочковывать одну feature-ветку от другой, то такой проблемы не возникает. Но какой подход практикуете вы?
Егор Андреевич: Мы не используем feature-ветки в прямом понимании этого термина. Каждый раз, когда мы производим изменение, создаем новую ветку, работаем в ней и сразу вливаем в master. Нет долгоиграющих веток.
Это решает большое количество проблем с merge и rebase, особенно конфликты. Ветки существуют один час и высока вероятность использования fast forward, так как никто ничего не добавил в master. Когда же мы делаем merge в pull request, то только merge c созданием merge commit
Даниил Попов: Как вы не боитесь сливать master неработающую фичу, ведь декомпозировать задачу на часовые интервалы часто нереально?
Егор Андреевич: Мы используем подход feature flags. Это динамические флаги, определенная фича с разными состояниями. Например, функция отправлять платежи друг другу либо включена, либо выключена. У нас есть сервис, который динамически доставляет это состояние клиентам. Вы с сервера получаете значение выключена фича или нет. Это значение вы можете использовать в коде — выключить кнопку, которая идет в скрин. Сам код есть в приложении, и его можно зарелизить, но доступа в этот функционал нет, потому что он за feature flag.
Даниил Попов: Часто новичкам в Git говорят, чтобы после rebase нужно делать push с force. Откуда это?
Егор Андреевич: Когда вы делаете просто push, другой репозиторий может выкинуть ошибку: вы пытаетесь запушить ветку, но у вас на этой ветке абсолютно другие коммиты. Git проверяет всю информацию, чтобы вы случайно не поломали репозиторий. Когда вы говорите git push force, то выключаете этот чекинг, считая, что знаете лучше него, и требуете переписать ветку.
Почему это нужно после rebase? Rebase пересоздает коммиты. Получается, что ветка называется также, но коммиты в ней с другими хэшами, и Git на вас ругается. В этой ситуации абсолютно нормально сделать force push, так как вы контролируете ситуацию.
Даниил Попов: Еще есть понятие interactive rebase, и многие его боятся.
Егор Андреевич: Страшного ничего нет. За счет того, что Git пересоздает историю при rebase, он временно ее хранит перед тем как перекинуть. Когда у него есть временный storage, он может с коммитами делать все, что угодно.
Rebase в интерактивном режиме предполагает, что Git перед rebase выкидывает окошко текстового редактора, в котором можно указать, что надо сделать с каждым отдельным коммитом. Это выглядит как несколько линий текста, где каждая линия — один из коммитов, которые есть в ветке. Перед каждым коммитом есть указание операции, которую стоит выполнить. Самая простая операция по умолчанию — pick, т.е. взять и включить в rebase. Самая распространенная — squash, тогда Git возьмет изменения из этого коммита и объединит с изменениями предыдущего.
Часто встречается такой сценарий. Вы работали локально в своей ветке и создавали коммиты для сейва. Получилась длинная история коммитов, которая для вас интересна, но в таком же варианте ее в основную историю не стоит заливать. Тогда вы даете squash для переименования в общий коммит.
Список команд длинный. Можно выбросить коммит — drop и он исчезнет, можно поменять сообщение коммита и т.д.
Алексей Кудрявцев: Когда у тебя появляются конфликты в интерактивном rebase, ты проходишь через все круги ада.
Егор Андреевич: Я очень далек от того, чтобы постичь всю мудрость интерактивного rebase, но это мощный инструмент и сложный.
Практическое применение Git
Даниил Попов: Перейдем к практике. На собеседовании я часто спрашиваю: «У тебя есть тысяча коммитов. На первом все хорошо, на тысячном сломался тест. Как с помощью гита можно найти изменение, которое к этому привело?»
Егор Андреевич: В этой ситуации нужно использовать bisect, хотя проще брать blame.
Начнем с интересного. Git bisect применим к ситуации, когда у вас есть regression — был функционал, работал, но вдруг перестал. Чтобы найти, когда сломался функционал, можно теоретически наугад откатиться на предыдущую версию приложения, посмотреть в код, но есть инструмент, который позволит структурировано подойти к проблеме.
Git bisect — интерактивный инструмент. Есть команда git bisect bad, через которую вы сообщаете о наличии поломанного коммита и git bisect good — для рабочего коммита. Каждый раз при релизе приложения мы запоминаем hash коммита, с которого сделан релиз. Этот hash также можно использовать для указания плохих и хороших коммитов. Bisect получает информацию о промежутке, где какой-то из коммитов поломал функционал, и запускает сессию binary search, где постепенно выдает коммиты на проверку, работают они или нет.
Вы запустили сессию, Git переключается на один из коммитов в промежутке, сообщает об этом. В случае с тысячью коммитов будет не так много итераций.
Проверку придется выполнять вручную: через юнит-тесты или запустить приложение и прокликать мануально. Git bisect удобно скриптить. Каждый раз, когда он выдает коммит, даете ему скрипт проверки работоспособности кода.
Blame — это более простой инструмент, который исходя из своего названия позволяет найти «виновника» поломки функционала. За счет этого негативного определения многие в коммьюнити blame недолюбливают.
Что он делает? Если вы даете git blame определенный файл, то он полинейно в этом файле покажет, какой коммит менял ту или иную линию. Я никогда не использовал git blame с командной строки. Как правило это делают в IDEA или Android Studio — кликаете и видите, кто какую линию файла поменял и в каком коммите.
Даниил Попов: Кстати в Android Studio это назвали Annotate. Убрали негативную коннотацию blame.
Алексей Кудрявцев: Точно, в xCode они переименовали его в Authors.
Егор Андреевич: Еще я читал, что есть утилита git praise — найти того, кто написал этот отличный код.
Даниил Попов: Нужно заметить что по blame работают предложения ревьюеров на pull request. Он смотрит, кто больше всего трогал тот или иной файл, и предполагает, что этот человек сможет хорошо поревьюить ваш код.
В случае с примером про тысячу коммитов blame в 99% случаев покажет, что пошло не так. Bisect — это уже last resort.
Егор Андреевич: Да, к bisect я прибегаю крайне редко, а вот annotate использую регулярно. Хотя иногда по линии кода нельзя понять, почему там null checked, зато по всему коммиту ясно, что хотел сделать автор.
Как правильно работать с Stacked PRs?
Даниил Попов: Я слышал, что в Square применяется Stacked pull requests (PRs).
Егор Андреевич: Как минимум в нашей андроид-команде мы часто их используем.
Мы очень много времени уделяем тому, чтобы каждый pull request было легко ревьюить. Иногда есть соблазн накодить, быстро закоммить, и пусть ревьюеры разбираются. Мы стараемся создавать небольшие pull request’ы и краткое описание — код должен говорить сам за себя. Когда pull request’ы маленькие — их легко и быстро заревьюить.
Здесь возникает проблема. Вы работаете над функционалом, который потребует большого количества изменений в code base. Что вы можете сделать? Можно положить в один pull request, но тогда он будет огромным. Можно работать постепенно создавая pull request, но тогда проблема будет в том, что вы создали branch, добавили несколько изменений и засабмитили pull request, вернулись на master и тот код, который был у вас в pull request, недоступен в master до того момента, пока не произойдет merge. Если вы зависите от изменений в этих файлах, то сложно продолжать работу, потому что этого кода нет.
Как мы это обходим? После того, как мы создали первый pull request, продолжаем работу, создаем новую ветку из существующей ветки, которую мы использовали до pull request. Каждая ветка идет не из master, а из предыдущей ветки. Когда заканчиваем работу над этим куском функционала, сабмитим еще один pull request и опять же указываем, что при merge он мержится не в master, а в предыдущий branch. Получается такая цепочка pull request’ов — stacked prs. Когда человек ревьюит, он видит изменения, которые были внесены только этой фичей, но не предыдущей.
Задача в том, чтобы каждый pull request был как можно меньше и понятней, чтобы не возникало необходимости изменять. Потому что если придется менять код в ветках, которые находятся в середине stacked, все, что сверху, поломается, так как придется делать rebase. Если pull request’ы маленькие, мы стараемся как можно быстрее из замержить, тогда весь stacked пошагово сливается в master.
Даниил Попов: Правильно я понимаю, что в итоге будет какой-то последний pull request, который содержит в себе все маленькие pull request’ы. Вы эту ветку не глядя вливаете?
Егор Андреевич: Merge происходит из истока stacked: сначала в master мержится самый первый pull request, в следующем меняется base из ветки в master и, соответственно, Git вычисляет, что в master уже какие-то изменения есть, snapshot получается меньше.
Алексей Кудрявцев: Бывают ли у вас состояния гонок, когда первая ветка уже замерджилась, а только после этого вторая в первую замержилась, потому что ей не поменяли таргет на master?
Егор Андреевич: Мы мержим вручную, поэтому таких ситуаций не бывает. Я открываю pull request, отмечаю коллег, от которых я хочу получить ревью и, когда они заапрувили, иду на bitbucket, нажимаю merge.
Алексей Кудрявцев: А как же проверки на CI, что ничего не сломано?
Егор Андреевич: Такого мы не делаем. CI работает на ветке, которая является базой для pull request и после проверки мы меняем base. Технически он не меняется, так как таргетишь тоже количество изменений.
Даниил Попов: А вы прямо в master пушите или все же develop? И при релизе явно указываете коммит, с которого собирать?
Егор Андреевич: У нас нет develop, только master. Мы обязательно релизим каждые две недели. Когда мы начинаем готовить релиз, открываем релиз-ветку и какие-то последние фиксы идут и в master, и в эту ветку. Используем tags — перманентные ссылки на определенный коммит опционально с какой-то информацией. Если какой-то коммит — это релиз-коммит, то хорошо бы сохранить в истории, что с этого коммита мы сделали релиз. Создается тэг, Git сохраняет информацию с версией, и позже к нему можно вернуться.
Алексей Кудрявцев: Где поучить Git, что почитать?
Егор Андреевич: У Git есть официальная книга. Мне нравится, как она написана, есть хорошие примеры. Есть глава про внутренности, можно ее досконально изучить. На StackOverflow можно найти множество эзотерических ситуаций и решений. Ими тоже можно пользоваться.
На предстоящей Saint AppsConf про Git говорить не собираемся. Но зато мы решились на эксперимент и добавили в плотную программу конференции доклады из серии Introductory, в которых спикеры из смежных отраслей разработки делятся знаниями для расширения кругозора мобильного разработчика. Советуем обратить внимание на выступление Николая Голова из Avito про базы данных: как не ошибиться и выбрать правильную базу, как подготовиться к росту и что актуально в 2019 году.
Выпуски AppsCast выходят раз в две недели по средам и, если звуковая версия вам привычнее текстовой, то подписывайтесь на нас в SoundCloud, ставьте лайки и обсуждайте темы в нашем чате.
Fyret
С этого надо было начинать. Такой ручной режим использования гита подходит, наверное, только небольшим сплоченным командам.
int02h Автор
Так они же гоняют проверки на CI. Просто в другой момент.