
Что такое End2End-распознавание речи, и зачем же оно нужно? В чем его отличие от классического подхода? И почему для обучения хорошей модели на основе End2End нам потребуется огромное количество данных — в нашем сегодняшнем посте.
Прежде чем рассказать про End2End-подход, стоит сначала поговорить про классический подход к распознаванию речи. Что он из себя представляет?

На самом деле, это не совсем линейная последовательность действий-блоков. Давайте остановимся на каждом блоке поподробнее. У нас есть некая входная речь, она попадает на первый блок — Feature Extraction. Это блок, который вытаскивает признаки из речи. Нужно иметь в виду, что речь сама по себе довольно сложная штука. Нужно как-то уметь с ней работать, поэтому есть стандартные методы вычленения признаков из теории обработки сигналов. Например, Мел-кепстральные коэффициенты (MFCC) и так далее.
Следующий компонент — акустическая модель. Она может быть как на основе глубоких нейронных сетей, так и на основе смесей гауссовых распределений и скрытых марковских моделей. Главная ее цель — получение из одного участка акустического сигнала распределения вероятностей различных фонем на этом участке.
Далее идет декодер, который ищет наиболее вероятный путь в графе на основе полученного результата из прошлого шага. Rescoring – финальный штрих в распознавании, основной задачей которого является перевзвешивание гипотез и выдача окончательного результата.
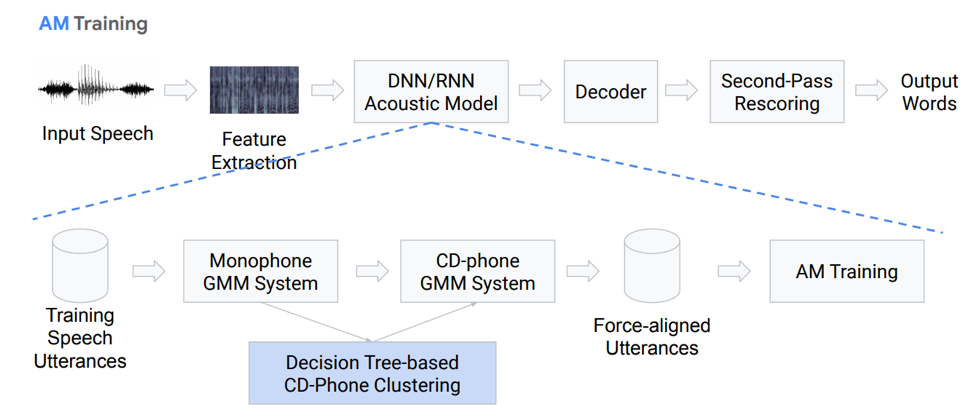
Давайте чуть подробнее остановимся на акустической модели. Что она из себя представляет? У нас есть некие голосовые записи, которые поступают в некую систему на основе GMM (монофонные гаусовыве смеси) или HMM. То есть у нас есть представления в виде фонем, мы используем именно монофоны, то есть контекстно-независимые фонемы. Дальше из них мы делаем смеси гауссовых распределений на основе контекстно-зависимых фонем. Здесь применяется кластеризация на основе деревьев принятия решений.
Потом пытаемся построить выравнивание. Такой совсем нетривиальный способ позволяет нам получить акустическую модель. Звучит не очень просто, на деле – еще сложнее, много нюансов, особенностей. Но в качестве результата модель, обученная на сотнях часах, очень хорошо способна моделировать акустику.

Что представляет из себя декодер? Это модуль, выбирающий наиболее вероятный путь перехода по HCLG-графу, который состоит из 4 частей:
H модуль на базе HMM
C модуль контекстной зависимости
L модуль произношения
G модуль языковой модели
Выстраиваем на этих четырех компонентах граф, на основе которого у нас будет осуществляться декодирование наших акустических признаков в некие словесные конструкции.
Плюс-минус понятно, что классический подход довольно громоздкий и тяжелый, его сложно обучать, так как он состоит из большого количество отдельных частей, для каждой из которых нужно готовить свои данные для обучения.
Так что же такое End2End-распознавание речи и зачем же оно нужно? Это некая система, которая предназначена для того, чтобы напрямую отражать последовательность акустических признаков в последовательности графем(букв) или слов. Также можно сказать, что это система, которая оптимизирует критерии, напрямую влияющие на финальную метрику оценки качества. На примере нашей задачи это конкретно word error rate. Как я уже сказал, мотивация одна – представить вот эти сложные многоэтапные компоненты в виде одного простого компонента, который будет напрямую отображать, выдавать слова или графемы из входной речи.
У нас тут возникает сразу проблема: звуковая речь – это последовательность, и на выходе нам тоже нужно выдать последовательность. И до 2006 года не существовало адекватного способа это моделировать. В чем проблема моделирования? Была необходимость на каждую запись создавать сложную разметку, которая подразумевает, в какую секунду мы произносим конкретный звук или букву. Это очень громоздкая сложная разметка и поэтому большого количества исследований на эту тематику не проводилось. В 2006 году вышла интересная статья Алекса Грейвса «Connectionist temporal classification» (CTC), в которой эта проблема, в принципе, решается. Но статья вышла, а вычислительных мощностей на тот момент не хватало. И реальные рабочие алгоритмы распознавания речи появились значительно позже.
Итого мы имеем: алгоритм CTC был предложен Алексом Грейвсом тринадцать лет назад, как инструмент, который позволяет тренировать/обучать акустические модели без необходимости этой сложной разметки – выравнивания по фреймам входной и выходной последовательности. На базе этого алгоритма изначально появились работы, которые не были полным end2end, в качестве результата выдавали фонемы. Стоит отметить, что контекстно-зависимые фонемы, основанные на СТС, достигают одних из самых лучших результатов в качестве распознавания свободной речи. Но также стоит отметить, что этот алгоритм, примененный непосредственно к словам, остается где-то позади на текущий момент.

Сейчас мы поговорим немного подробней о том, что такое СТС, и зачем он нужен, какую функцию выполняет. СТС необходим для того, чтобы тренировать акустическую модель без необходимости пофреймового выравнивания между звуком и транскрипцией. Пофреймовое выравнивание – это когда мы говорим, что какой-то конкретный фрейм из звука соответствует вот такому фрейму из транскрипции. У нас есть обычный энкодер, который принимает на вход акустические признаки – выдает некие скрытие состояния, на основе которых с помощью softmax мы получаем условные вероятности. Encoder обычно из себя представляет несколько слоев LSTMs или других вариаций RNNs. Стоит отметить, что СТС оперирует помимо обычных символов еще специальным символом, который называется пустой символ или blank-символ. Для того чтобы решить проблему, которая возникает из-за того, что не каждый акустический фреймс имеет фрейм в транскрипции и наоборот (то есть у нас есть буквы или звуки, которые звучат намного дольше, и есть коротенькие звуки, повторяющиеся звуки), и существует этот blank-символ.
Сам же СТС предназначен для того, чтобы максимизировать итоговую вероятность последовательностей символов и обобщать возможное выравнивание. Так как мы хотим использовать этот алгоритм в нейронных сетях, то подразумевается, что мы должны понимать, как работает его forward и backward режимы работы. На математическом обосновании и особенностях работы этого алгоритма останавливаться не будем, иначе это займет очень много времени.
Что же мы имеем: первый ASR на основе СТС-алгоритма появляется в 2014 году. Опять же Алекс Грейвс представил публикацию, в основе которой был посимвольный СТС, напрямую отображающий входную речь в последовательность слов. Одно из замечаний, которое они указали в этой статье, – важно использование внешней звуковой модели для получения хорошего результата.
Существует много разных вариаций и улучшений вышеописанного алгоритма. Вот, например, пять самых популярных за последнее время.
• Языковая модель включена в декодирование на этапе первого прохода
o [Hannun et al., 2014] [Maas et al., 2015]: Direct first-pass decoding with an LM as opposed to rescoring as in [Graves & Jaitly, 2014]
o [Miao et al., 2015]: EESEN framework for decoding with WFSTs, open source toolkit
• Масштабное обучение на GPU; аугментация данных; несколько языков
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: Large scale GPU training; Data Augmentation; Mandarin and English
• Использование длинных единиц измерения: слова вместо символов
o [Soltau et al., 2017]: Word-level CTC targets, trained on 125,000 hours of speech. Performance close to or better than a conventional system, even without using an LM!
o [Audhkhasi et al., 2017]: Direct Acoustics-to-Word Models on Switchboard
Стоит обратить внимание на реализацию DeepSpeach как на хороший пример end2end CTC решения и на вариацию, которая использует именно словесный уровень. Но здесь есть один нюанс: для обучения такой модели нужно 125 тыс. часов размеченных данных, что на самом деле довольно много в суровых реалиях.
Какая же у нас есть альтернатива этому СТС? Наверное, ни для кого не секрет, что есть такая штука как Attention или «Внимание», которая совершила переворот в какой-то степени и напрямую пошла из задач машинного перевода. И сейчас большинство всех решений моделирования последовательность-последовательность основано на этом механизме. Что же он представляет из себя? Попробуем разобраться. Впервые про Attention в задачах распознавания речи публикации появились в 2015 году. Некто Чен и Черовски выпустили две похожие и непохожие одновременно публикации.
Остановимся на первой – она называется Listen, attend and spell. В наше классическое моделирование в последовательность, где у нас есть энкодер и декодер, добавляется еще один элемент, который называется attention. Экнодер у нас будет выполнять функции, которые раньше выполняла акустическая модель. Его задача превращать входной спич в высокоуровневые акустические признаки. Декодер у нас будет выполнять задачи, которые у нас раньше выполняли языковая модель и модель произношений (лексикон), она будет авторегрессивно предсказывать каждый выходной токен, как функцию из предыдущих. И непосредственно сам attention будет говорить, какой именно входной фрейм наиболее релевантен/важен для того, чтобы предсказать данный выход.
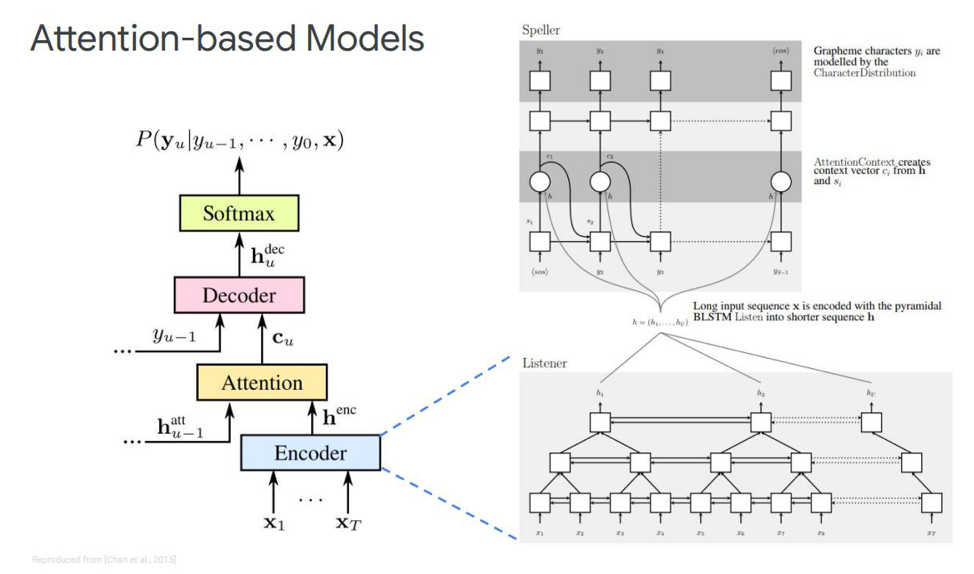
Что же из себя представляют эти блоки? Экнодер в статье описан как listener, это классическая bi-directional RNNs на основе LSTMs или чего-то еще. В общем ничего нового – система просто моделирует входную последовательность в сложные признаки.
Attention же создает некий контекстный вектор С из этих векторов, который будет помогать правильно декодировать декодеру непосредственно сам декодер, являющийся, например, тоже какой-нибудь LSTMs, который будет на входную последовательность с этого attention слоя, уже выделившего наиболее важные признаки состояния, декодировать в некую выходную последовательность символов.
Также существуют разные представления этого самого Attention — чем и отличаются вот эти две выпущенные Ченом и Чаровски публикации. Они используют разный Attention. Чен использует dot-product Attention, а Чаровски — Additive Attention.

Это плюс-минус все основные достижения, полученные на сегодняшний день в вопросах не online-распознавания речи. Какие здесь возможны улучшения? Куда двигаться дальше? Самое очевидное, это использование модели на кусочках слов вместо того, чтобы использовать напрямую графемы. Это могут быть какие-то отдельные морфемы или что-то еще.
Какая мотивация использования кусочков слов? Обычно языковые модели словесного уровня имеют намного меньше перплексию по сравнению с графемным уровнем. Моделирование кусочков слов позволяет построить более сильный декодер языковой модели. И моделирование более длинных элементов позволяет улучшить эффективность использования памяти в декодере на основе LSTMs. Также это позволяет потенциально запоминать встречаемость для частотных слов. Более длинные элементы позволяют декодироваться за меньшее количество шагов, что непосредственно так же ускоряет inference этой модели.
Также модель на кусочках слов позволяет решить проблему c OOV (out of vocabulary) словами, которые возникают в языковой модели, так как мы можем смоделировать любое слово с помощью кусочков слов. И стоит отметить, что такие модели тренируются для максимизации правдоподобия языковой модели над обучающим дата-сетом. Эти модели являются зависимыми от позиции, и мы можем использовать жадный алгоритм при декодировании.
Какие еще могут быть улучшения кроме модели кусочков слов? Есть такой механизм, который называется multi-head attention. Он впервые описан в 2017 году для машинного перевода. Multi-head attention подразумевает механизм, у которых есть несколько так называемых голов, которые позволяют генерировать разное распределение этого самого внимания, что улучшает непосредственно результаты.
Переходим к самой интересной части — это онлайновые модели. Важно отметить, что LAS — это не стриминг. То есть эта модель не может работать в режиме онлайн-декодирования. Мы рассмотрим две самые популярные на сегодняшний день онлайн-модели. RNN Transducer и Neural Transducer.
RNN Transducer предложен Грейвсом в 2012-2017 годах. Основная идея — немного усложнить нашу СТС-модель с помощью рекурентной модели.
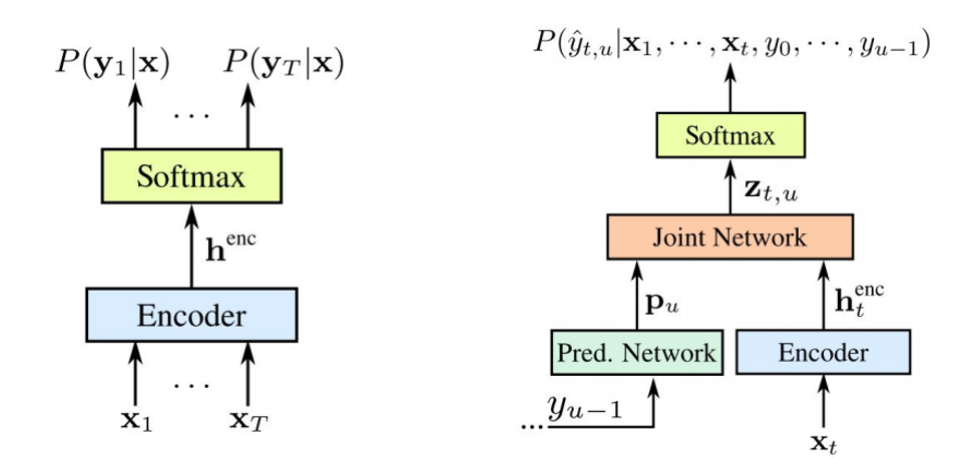
Стоит отметить, что оба компонента обучаются совместно на доступных акустических данных. Так же как и СТС данный подход не требует разметки на фреймовое выравнивание в обучающем data-сете. Как мы видим на картинке: слева наш классический СТС, а справа — RNN Transducer. И у нас появляются два новых элемента – это Predicted Network и Join Network.
СТС-энкодер точно такой же – это входной уровень RNN, который определяет распределение по всем выравниваниям со всеми выходными последовательностями, не превышающими длину входной последовательности – так было описано Грейвсом в 2006 году. Однако также исключается задача таких преобразований текста в речь, где входная последовательность длиннее входной последовательности СТС не моделирует взаимосвязи между выходами. Transducer расширяет этот самый СТС, определяя распределение по выходным последовательностям всех длин и совместно моделируя зависимостью входа-выхода и выхода-выхода.
Получается, наша модель в итоге умеет оперировать зависимостями выхода от входа и выхода от выхода прошлого шага.
Так что же такое Predicted Network или прогнозная сеть? Она пытается смоделировать каждый элемент с учетом предыдущих, поэтому похожа на стандартный RNN с прогнозированием следующего шага. Только с добавленной возможностью делать нулевые гипотизы.
Как мы видим на картинке, у нас есть Predicted Network, который получает на вход предыдущее значение выхода, и есть Encoder, который получает на вход текущее значение входа. И на выходе мы опять-такие имеет текущее значение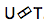 .
.
Neural Transducer. Это некое усложнение классического seq-2seq-подхода. Входная акустическая последовательность обрабатывается энкордером для создания скрытых векторов состояния на каждом временном шаге. Это все вроде бы как обычно. Но существует дополнительный элемент Transducer, который получает блок входов на каждом шаге и генерирует до M-выходных токенов, используя модель на основе seq-2seq над этим входом. Transducer поддерживает свое состояние в блоках путем использования периодических соединений с предыдущими временными шагами.
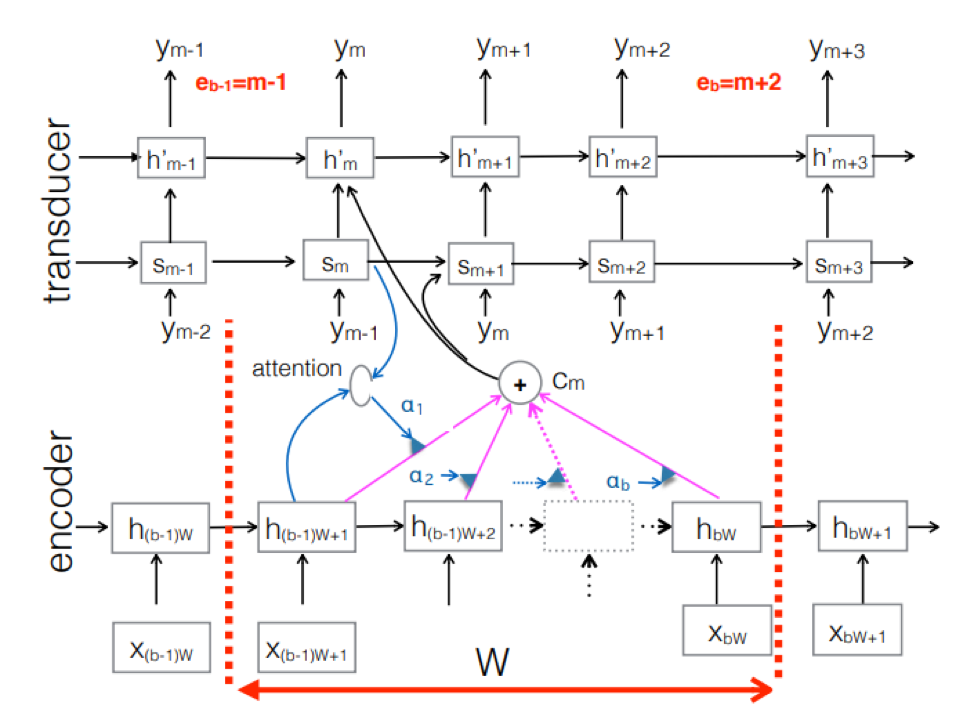
На рисунке представлен Transducer, производящий токины для блока под последовательность, используемого в блоке соответственного Ym.
Итак, мы рассмотрели текущее состояние распознавания речи на основе End2End-подхода. Стоит сказать, что, к сожалению, данные подходы сегодня требуют большое количество данных. И реальные результаты, которые достигаются классическим подходом, требующим от 200 до 500 часов звуковых записей, размеченных для обучения хорошей модели на основе End2End, потребуют в разы, а может быть и в десятки раз больше данных. Сейчас это самая большая проблема данных подходов. Но, возможно, скоро все поменяется.
Ведущий разработчик центра AI МТС Никита Семенов.
Классический подход к распознаванию речи
Прежде чем рассказать про End2End-подход, стоит сначала поговорить про классический подход к распознаванию речи. Что он из себя представляет?
Feature Extraction
На самом деле, это не совсем линейная последовательность действий-блоков. Давайте остановимся на каждом блоке поподробнее. У нас есть некая входная речь, она попадает на первый блок — Feature Extraction. Это блок, который вытаскивает признаки из речи. Нужно иметь в виду, что речь сама по себе довольно сложная штука. Нужно как-то уметь с ней работать, поэтому есть стандартные методы вычленения признаков из теории обработки сигналов. Например, Мел-кепстральные коэффициенты (MFCC) и так далее.
Акустическая модель
Следующий компонент — акустическая модель. Она может быть как на основе глубоких нейронных сетей, так и на основе смесей гауссовых распределений и скрытых марковских моделей. Главная ее цель — получение из одного участка акустического сигнала распределения вероятностей различных фонем на этом участке.
Далее идет декодер, который ищет наиболее вероятный путь в графе на основе полученного результата из прошлого шага. Rescoring – финальный штрих в распознавании, основной задачей которого является перевзвешивание гипотез и выдача окончательного результата.
Давайте чуть подробнее остановимся на акустической модели. Что она из себя представляет? У нас есть некие голосовые записи, которые поступают в некую систему на основе GMM (монофонные гаусовыве смеси) или HMM. То есть у нас есть представления в виде фонем, мы используем именно монофоны, то есть контекстно-независимые фонемы. Дальше из них мы делаем смеси гауссовых распределений на основе контекстно-зависимых фонем. Здесь применяется кластеризация на основе деревьев принятия решений.
Потом пытаемся построить выравнивание. Такой совсем нетривиальный способ позволяет нам получить акустическую модель. Звучит не очень просто, на деле – еще сложнее, много нюансов, особенностей. Но в качестве результата модель, обученная на сотнях часах, очень хорошо способна моделировать акустику.
Декодер
Что представляет из себя декодер? Это модуль, выбирающий наиболее вероятный путь перехода по HCLG-графу, который состоит из 4 частей:
H модуль на базе HMM
C модуль контекстной зависимости
L модуль произношения
G модуль языковой модели
Выстраиваем на этих четырех компонентах граф, на основе которого у нас будет осуществляться декодирование наших акустических признаков в некие словесные конструкции.
Плюс-минус понятно, что классический подход довольно громоздкий и тяжелый, его сложно обучать, так как он состоит из большого количество отдельных частей, для каждой из которых нужно готовить свои данные для обучения.
II End2End-подход
Так что же такое End2End-распознавание речи и зачем же оно нужно? Это некая система, которая предназначена для того, чтобы напрямую отражать последовательность акустических признаков в последовательности графем(букв) или слов. Также можно сказать, что это система, которая оптимизирует критерии, напрямую влияющие на финальную метрику оценки качества. На примере нашей задачи это конкретно word error rate. Как я уже сказал, мотивация одна – представить вот эти сложные многоэтапные компоненты в виде одного простого компонента, который будет напрямую отображать, выдавать слова или графемы из входной речи.
Проблема моделирования
У нас тут возникает сразу проблема: звуковая речь – это последовательность, и на выходе нам тоже нужно выдать последовательность. И до 2006 года не существовало адекватного способа это моделировать. В чем проблема моделирования? Была необходимость на каждую запись создавать сложную разметку, которая подразумевает, в какую секунду мы произносим конкретный звук или букву. Это очень громоздкая сложная разметка и поэтому большого количества исследований на эту тематику не проводилось. В 2006 году вышла интересная статья Алекса Грейвса «Connectionist temporal classification» (CTC), в которой эта проблема, в принципе, решается. Но статья вышла, а вычислительных мощностей на тот момент не хватало. И реальные рабочие алгоритмы распознавания речи появились значительно позже.
Итого мы имеем: алгоритм CTC был предложен Алексом Грейвсом тринадцать лет назад, как инструмент, который позволяет тренировать/обучать акустические модели без необходимости этой сложной разметки – выравнивания по фреймам входной и выходной последовательности. На базе этого алгоритма изначально появились работы, которые не были полным end2end, в качестве результата выдавали фонемы. Стоит отметить, что контекстно-зависимые фонемы, основанные на СТС, достигают одних из самых лучших результатов в качестве распознавания свободной речи. Но также стоит отметить, что этот алгоритм, примененный непосредственно к словам, остается где-то позади на текущий момент.
Что такое СТС
Сейчас мы поговорим немного подробней о том, что такое СТС, и зачем он нужен, какую функцию выполняет. СТС необходим для того, чтобы тренировать акустическую модель без необходимости пофреймового выравнивания между звуком и транскрипцией. Пофреймовое выравнивание – это когда мы говорим, что какой-то конкретный фрейм из звука соответствует вот такому фрейму из транскрипции. У нас есть обычный энкодер, который принимает на вход акустические признаки – выдает некие скрытие состояния, на основе которых с помощью softmax мы получаем условные вероятности. Encoder обычно из себя представляет несколько слоев LSTMs или других вариаций RNNs. Стоит отметить, что СТС оперирует помимо обычных символов еще специальным символом, который называется пустой символ или blank-символ. Для того чтобы решить проблему, которая возникает из-за того, что не каждый акустический фреймс имеет фрейм в транскрипции и наоборот (то есть у нас есть буквы или звуки, которые звучат намного дольше, и есть коротенькие звуки, повторяющиеся звуки), и существует этот blank-символ.
Сам же СТС предназначен для того, чтобы максимизировать итоговую вероятность последовательностей символов и обобщать возможное выравнивание. Так как мы хотим использовать этот алгоритм в нейронных сетях, то подразумевается, что мы должны понимать, как работает его forward и backward режимы работы. На математическом обосновании и особенностях работы этого алгоритма останавливаться не будем, иначе это займет очень много времени.
Что же мы имеем: первый ASR на основе СТС-алгоритма появляется в 2014 году. Опять же Алекс Грейвс представил публикацию, в основе которой был посимвольный СТС, напрямую отображающий входную речь в последовательность слов. Одно из замечаний, которое они указали в этой статье, – важно использование внешней звуковой модели для получения хорошего результата.
5 способов улучшить алгоритм
Существует много разных вариаций и улучшений вышеописанного алгоритма. Вот, например, пять самых популярных за последнее время.
• Языковая модель включена в декодирование на этапе первого прохода
o [Hannun et al., 2014] [Maas et al., 2015]: Direct first-pass decoding with an LM as opposed to rescoring as in [Graves & Jaitly, 2014]
o [Miao et al., 2015]: EESEN framework for decoding with WFSTs, open source toolkit
• Масштабное обучение на GPU; аугментация данных; несколько языков
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: Large scale GPU training; Data Augmentation; Mandarin and English
• Использование длинных единиц измерения: слова вместо символов
o [Soltau et al., 2017]: Word-level CTC targets, trained on 125,000 hours of speech. Performance close to or better than a conventional system, even without using an LM!
o [Audhkhasi et al., 2017]: Direct Acoustics-to-Word Models on Switchboard
Стоит обратить внимание на реализацию DeepSpeach как на хороший пример end2end CTC решения и на вариацию, которая использует именно словесный уровень. Но здесь есть один нюанс: для обучения такой модели нужно 125 тыс. часов размеченных данных, что на самом деле довольно много в суровых реалиях.
Что важно отметить об СТС
- Проблематика или упущения. Для эффективности важно делать предположения о независимости. То есть СТС предполагает, что выходные данные сети в разных фреймах условно независимые, что на самом деле является неверным. Но это предположение делается для упрощения, без него все становится намного сложнее.
- Для достижения хорошей производительности из модели СТС требуется использование внешней языковой модели, так как прямое жадное декодирование не очень хорошо работает.
Attention
Какая же у нас есть альтернатива этому СТС? Наверное, ни для кого не секрет, что есть такая штука как Attention или «Внимание», которая совершила переворот в какой-то степени и напрямую пошла из задач машинного перевода. И сейчас большинство всех решений моделирования последовательность-последовательность основано на этом механизме. Что же он представляет из себя? Попробуем разобраться. Впервые про Attention в задачах распознавания речи публикации появились в 2015 году. Некто Чен и Черовски выпустили две похожие и непохожие одновременно публикации.
Остановимся на первой – она называется Listen, attend and spell. В наше классическое моделирование в последовательность, где у нас есть энкодер и декодер, добавляется еще один элемент, который называется attention. Экнодер у нас будет выполнять функции, которые раньше выполняла акустическая модель. Его задача превращать входной спич в высокоуровневые акустические признаки. Декодер у нас будет выполнять задачи, которые у нас раньше выполняли языковая модель и модель произношений (лексикон), она будет авторегрессивно предсказывать каждый выходной токен, как функцию из предыдущих. И непосредственно сам attention будет говорить, какой именно входной фрейм наиболее релевантен/важен для того, чтобы предсказать данный выход.
Что же из себя представляют эти блоки? Экнодер в статье описан как listener, это классическая bi-directional RNNs на основе LSTMs или чего-то еще. В общем ничего нового – система просто моделирует входную последовательность в сложные признаки.
Attention же создает некий контекстный вектор С из этих векторов, который будет помогать правильно декодировать декодеру непосредственно сам декодер, являющийся, например, тоже какой-нибудь LSTMs, который будет на входную последовательность с этого attention слоя, уже выделившего наиболее важные признаки состояния, декодировать в некую выходную последовательность символов.
Также существуют разные представления этого самого Attention — чем и отличаются вот эти две выпущенные Ченом и Чаровски публикации. Они используют разный Attention. Чен использует dot-product Attention, а Чаровски — Additive Attention.
Куда двигаться дальше?
Это плюс-минус все основные достижения, полученные на сегодняшний день в вопросах не online-распознавания речи. Какие здесь возможны улучшения? Куда двигаться дальше? Самое очевидное, это использование модели на кусочках слов вместо того, чтобы использовать напрямую графемы. Это могут быть какие-то отдельные морфемы или что-то еще.
Какая мотивация использования кусочков слов? Обычно языковые модели словесного уровня имеют намного меньше перплексию по сравнению с графемным уровнем. Моделирование кусочков слов позволяет построить более сильный декодер языковой модели. И моделирование более длинных элементов позволяет улучшить эффективность использования памяти в декодере на основе LSTMs. Также это позволяет потенциально запоминать встречаемость для частотных слов. Более длинные элементы позволяют декодироваться за меньшее количество шагов, что непосредственно так же ускоряет inference этой модели.
Также модель на кусочках слов позволяет решить проблему c OOV (out of vocabulary) словами, которые возникают в языковой модели, так как мы можем смоделировать любое слово с помощью кусочков слов. И стоит отметить, что такие модели тренируются для максимизации правдоподобия языковой модели над обучающим дата-сетом. Эти модели являются зависимыми от позиции, и мы можем использовать жадный алгоритм при декодировании.
Какие еще могут быть улучшения кроме модели кусочков слов? Есть такой механизм, который называется multi-head attention. Он впервые описан в 2017 году для машинного перевода. Multi-head attention подразумевает механизм, у которых есть несколько так называемых голов, которые позволяют генерировать разное распределение этого самого внимания, что улучшает непосредственно результаты.
Онлайновые модели
Переходим к самой интересной части — это онлайновые модели. Важно отметить, что LAS — это не стриминг. То есть эта модель не может работать в режиме онлайн-декодирования. Мы рассмотрим две самые популярные на сегодняшний день онлайн-модели. RNN Transducer и Neural Transducer.
RNN Transducer предложен Грейвсом в 2012-2017 годах. Основная идея — немного усложнить нашу СТС-модель с помощью рекурентной модели.
Стоит отметить, что оба компонента обучаются совместно на доступных акустических данных. Так же как и СТС данный подход не требует разметки на фреймовое выравнивание в обучающем data-сете. Как мы видим на картинке: слева наш классический СТС, а справа — RNN Transducer. И у нас появляются два новых элемента – это Predicted Network и Join Network.
СТС-энкодер точно такой же – это входной уровень RNN, который определяет распределение по всем выравниваниям со всеми выходными последовательностями, не превышающими длину входной последовательности – так было описано Грейвсом в 2006 году. Однако также исключается задача таких преобразований текста в речь, где входная последовательность длиннее входной последовательности СТС не моделирует взаимосвязи между выходами. Transducer расширяет этот самый СТС, определяя распределение по выходным последовательностям всех длин и совместно моделируя зависимостью входа-выхода и выхода-выхода.
Получается, наша модель в итоге умеет оперировать зависимостями выхода от входа и выхода от выхода прошлого шага.
Так что же такое Predicted Network или прогнозная сеть? Она пытается смоделировать каждый элемент с учетом предыдущих, поэтому похожа на стандартный RNN с прогнозированием следующего шага. Только с добавленной возможностью делать нулевые гипотизы.
Как мы видим на картинке, у нас есть Predicted Network, который получает на вход предыдущее значение выхода, и есть Encoder, который получает на вход текущее значение входа. И на выходе мы опять-такие имеет текущее значение
. Neural Transducer. Это некое усложнение классического seq-2seq-подхода. Входная акустическая последовательность обрабатывается энкордером для создания скрытых векторов состояния на каждом временном шаге. Это все вроде бы как обычно. Но существует дополнительный элемент Transducer, который получает блок входов на каждом шаге и генерирует до M-выходных токенов, используя модель на основе seq-2seq над этим входом. Transducer поддерживает свое состояние в блоках путем использования периодических соединений с предыдущими временными шагами.
На рисунке представлен Transducer, производящий токины для блока под последовательность, используемого в блоке соответственного Ym.
Итак, мы рассмотрели текущее состояние распознавания речи на основе End2End-подхода. Стоит сказать, что, к сожалению, данные подходы сегодня требуют большое количество данных. И реальные результаты, которые достигаются классическим подходом, требующим от 200 до 500 часов звуковых записей, размеченных для обучения хорошей модели на основе End2End, потребуют в разы, а может быть и в десятки раз больше данных. Сейчас это самая большая проблема данных подходов. Но, возможно, скоро все поменяется.
Ведущий разработчик центра AI МТС Никита Семенов.
DnAp
Как-то стремновато видеть статью про распознавание голоса в блоге MTS.
vassabi
Где в облаках её сын пролетает.
С дружеской лаской, нежной любовью
Алыми звёздами башен московских,
Башен кремлёвских
Смотрит она за тобою,
Смотрит она за тобою.
(музыка Д.Шостаковича на слова Е.Долматовского)
vladkorotnev
Для подключения пакета улучшенного качества связи, просто произнесите фразу "бомба бомба президент" во время разговора. Каждому подключившему — путёвка в лофт-апартаменты на две недели с трёхразовым питанием в подарок!