
pprof — основной инструмент профилирования в Go. Профилировщик включен в стандартную библиотеку Go и про него, за годы, написано уже очень много. Чтобы подключить pprof в существующее приложение нужно просто добавить одну строчку кода:
import _ “net/http/pprof”В HTTP-сервере по-умолчанию — net/http.DefaultServeMux — по пути /debug/pprof/ будут зарегистрированы обработчики, отдающие результаты профилирования.
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile(подробнее см. https://godoc.org/net/http/pprof)
Но по опыту, не всегда все так просто и на практике с использованием pprof в бою, есть подводные камни.
Начнем с того, что мы совсем не хотим чтобы обработчики профилировщика «торчали» в интернет. Профилирование это дешево, с точки зрения накладных расходов, но не бесплатно, а сам профиль содержит информацию о внутреннем устройстве приложения, которую часто не желательно открывать для посторонних. Приходится позаботиться, чтобы путь /debug был недоступен для неавторизованных пользователей. Доступ можно ограничить на стороне прокси-сервера или вынести pprof-сервер на отдельный порт, доступ к которому будет открыт только через привилегированный хост.
Но что если приложение вообще не предполагает доступа по HTTP — например, это офлайн-обработчик очереди?
В зависимости от состояния инфраструктуры в компании, «внезапный» HTTP-сервер внутри процесса приложения может вызвать вопросы у отдела эксплуатации ;) Сервер дополнительно ограничивает возможности горизонтального масштабирования, т.к. не получится просто запустить несколько экземпляров приложения на одном хосте — процессы будут конфликтовать, пытаясь открыть один и тот же TCP-порт для pprof-сервера.
Это «просто» решить, изолировав каждый процесс приложения в контейнере (или запускать pprof-сервер на уникальном порту, или UNIX-сокете). Никого уже не удивишь сервисом горизонтально смасштабированным в сотни инстансов, «размазанным» по нескольким дата-центрам. В очень динамической инфраструктуре, контейнеры с приложением могут периодически появляться и исчезать. А нам все еще нужно как-то обращаться к профилировщику. И значит, независимо от выбранного способа масштабирования, нужны механизмы поиска конкретного экземпляра приложения и соответствующего для него порта pprof-сервера.
В зависимости от особенностей компании, само наличие возможности обращаться к чему-то, что не относится к основной продакшн-деятельности сервиса, может вызвать вопросы у отдела безопасности ;) Я работал в компании, где, по объективным причинам, доступ к чему угодно на стороне продакшна был исключительно у отдела эксплуатации. Единственный способ запустить профилировщик над работающим приложением было открыть задачу в баг-трекере эксплуатации, с описанием, какую curl-команду, в каком ДЦ, на каком сервере нужно запустить, какой ожидать результат и что с ним делать.
Или представьте ситуацию: рабочее утро. Вы открыли Slack и узнаете, что вечером, в одном из процессов продакшн-сервиса «что-то пошло не так», «где-то, что-то «задедлочилось», «начала течь память», «графики цпу поползли вверх» или приложение просто начало паниковать. Дежурные команды эксплуатации (или OOM Killer) не стали глубоко копать и просто перезапустили приложение или откатили последний релиз предыдущего дня.
Постфактум разбираться в таких ситуациях непросто. Здорово, если проблему получается воспроизвести в тестовом окружении (или в изолированной части продакшна, к которой есть доступ). Можно собрать нужные данные всеми инструментами, что есть под-рукой, а потом разбираться, в каком компоненте проблема.
Но если очевидного способа воспроизвести проблему нет — нам остаются только вчерашние логи и метрики? В таких ситуациях всегда обидно, что нельзя отмотать время на момент когда проблема была видна в продакшне и по быстрому собрать все нужные профили, чтобы потом, в спокойном режиме, заняться анализом.
Но если pprof это относительно дешево, почему бы не собирать данные профилирования автоматически, с некоторой периодичностью и хранить их где-то отдельно от продакшна, куда всем заинтересованным можно выдать доступы?
В 2010 г., Google опубликовали документ «Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers» описывающий подход к непрерывному профилированию систем компании. А спустя сколько-то лет, компания запустила сервис непрерывного профилирования — Stackdriver Profiler — доступный всем желающим.
Принцип работы прост: вместо pprof-сервера, в приложение подключается stackdriver-агент, который, используя напрямую API runtime/pprof, периодически собирает с приложения разные типы профилирования и отправляет профили в облако. Все, что нужно разработчику, используя панель управления Stackdriver, выбрать нужный инстанс приложения, в нужной AZ и можно, постфактум, анализировать работу приложения в любой момент в прошлом.
Похожую функциональность предоставляют и другие SaaS-провайдеры. Но, правила безопасности вашей компании могут запрещать экспортировать данные за пределы собственной инфраструктуры. И сервисов позволяющих развернуть систему непрерывного профилирования на собственных серверах, я не встречал.
Все описанные выше сложности и идеи далеко не новы и специфичны не только для Go. С ними, в том или ином виде, разработчики сталкивается практически во всех компаниях где я работал.
В какой-то момент, мне стало любопытно попробовать собрать аналог Stackdriver Profiler’а для произвольного Go-сервиса, который мог бы решить описанные проблемы. В качестве хобби-проекта, в свободное время, я работаю над profefe (https://github.com/profefe/profefe) — открытым сервисом непрерывного профилирования. Проект все еще находится в стадии экспериментов и периодических обсуждений, но уже пригоден для тестирования.
Задачи, которые я ставил перед проектом:
- Сервис будет разворачиваться на внутренней инфраструктуре компании.
- Сервис будет использоваться как внутренний инструмент компании. Поставщикам и потребителям данных можно доверять: на ранних этапах можно опустить вопросы авторизации запросов на запись/чтения и не пытаться заранее защищаться от злонамеренного использования.
- У сервиса не должно быть каких-то специальных ожиданий от инфраструктуры компании: все может жить в облаке или в собственных ДЦ; профилируемые приложения могут быть запущены внутри контейнеров («а все управляться кубернетесом») или могут работать на голом железе.
- Сервис должен быть прост в эксплуатации (кажется, до определенных масштабов, Prometheus — хороший пример).
- Стоит понимать, что выбранная архитектура может не удовлетворять условиям, в которых сервис будет использоваться. Скорее всего нужна будет возможность расширения /замены компонентов системы для масштабирования «на местах».
- В соответствии с (4), нужно постараться минимизировать обязательные внешние зависимости. Например, сервис должен как-то искать инстансы профилируемых приложений, но, по крайней мере на начальных этапах, хочется обойтись без явного сервис-дискавери.
- В сервисе будут хранить и каталогизировать профили Go-приложений. Ожидаем, что один pprof-файл занимает 100KB—2MB (heap-профили обычно сильно больше профилей CPU). От одного профилируемого инстанса, не имеет смысла слать больше N профилей в минуту (один агент Stackdriver’а шлет, в среднем, 2 профиля в минуту). Стоит сразу рассчитывать, что у одного приложения может быть от нескольких до нескольких сотен инстансов.
- Через сервис, пользователи будут искать разные типы профилей (cpu, heap, mutex, пр.) приложения или конкретного инстанса приложения, за некоторый промежуток времени.
- Из сервиса пользователь будет запрашивать отдельный pprof-профиль из результатов поиска.
Сейчас profefe состоит из двух компонентов:
profefe-collector — сервис-коллектор с простым RESTful API.
Задача коллектора получить pprof-файл и некоторые мета-данные и сохранить их в постоянное хранилище. API также позволяет клиентам искать профили по мета-данным в некотором временном окне или прочитать из хранилища конкретный профиль (или группу профилей одного типа).
agent — опциональная библиотека, которую следует подключить в приложение вместо pprof-сервера. Внутри приложения, в отдельной горутине, агент периодически запускает процесс профилирования (используя runtime/pprof), и отправляет полученные pprof-профили, вместе с мета-данными в коллектор.
Мета-данные это произвольный набор «ключ-значение», описывающий приложение или его отдельный инстанс. Например: имя сервиса, версия, дата-центр и хост где приложение запущено.

Схема взаимодействия компонентов profefe
Выше я упоминал, что агент — компонент опциональный. Если нет возможности подключить его в существующие приложение, но в приложении уже подключен net/http/pprof-сервер, профили можно снимать любыми внешними инструментами и отправлять pprof-файлы в коллектор через HTTP API.
Например, на хостах можно настроить cron-задачу, которая будет периодически собирать профили с запущенных инстансов и отправлять их в profefe на хранение ;)
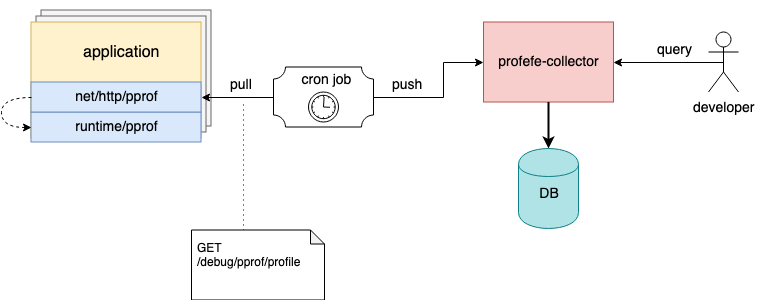
Cron-задача собирает и отправляет профили приложения в profefe-коллектор
Подробнее про API profefe можно прочитать в документации на GitHub.
Планы
Пока что, единственный способ взаимодействовать с profefe-коллектором, это HTTP API. Одна из задач на будущее — собрать отдельный UI-сервис, через который можно будет визуально показать хранимые данные: результаты поиска, общий обзор производительности кластера, пр.
Собирать и хранить данные профилирования это неплохо, но «без применения, данные бесполезны». В команде, где я работаю, есть набор экспериментальных инструментов для сбора базовой статистики по нескольким pprof-профилям с сервиса. Это очень помогает в анализе последствий обновления ключевых зависимостей приложения или результатов большого рефакторинга (к сожалению, не всегда производительность в продакшне соответствует ожиданиям на основе запусков изолированных бенчмарков и профилирования в тестовом окружении). Я хочу добавить похожую функциональность для сравнения и анализа хранимых профилей в API profefe.
Несмотря на то, что главный фокус profefe, непрерывное профилирование Go-сервисов, формат профилей pprof совсем не привязан к Go. Для Java, JavaScript, Python и пр. есть библиотеки позволяющие получить данные профилирования в этом формате. Возможно, profefe может стать полезным сервисов для приложений написанных на других языках.
Кроме прочего, в репозитории есть некоторое количество открытых вопросов описанных в трекере проекта на GitHub.
Заключение
В последние несколько лет в среде разработчиков закрепилась популярная идея, что для достижения «видимости» (observability) сервиса нужны три компонента: метрики, логи и трейсинг (“three pillars of observability”). Мне кажется, что видимость, это возможность эффективно отвечать на вопросы о работоспособности системы и ее составляющих. Метрики и трейсинг позволяют понять систему в целом. Логи охватывают заведомо-описанные части системы. Профилирование это еще один сигнал для достижения видимости, позволяющий понять систему на микроуровне. Непрерывное профилирования на протяжении периода времени, еще и помогает понять как отдельные составляющие и окружение влияли и влияют на работоспособность и производительность всей системы.
Berserkr
почему решили писать с нуля, а не помочь доработать одно из существующих решений?
https://github.com/conprof/conprof тут идея интересная
https://github.com/segmentio/pprof-server отличный, взрослый проект
Vii Автор
Про pprof-server я не слышал. Но, если не ошибаюсь, это сервис-дискавери для pprof-серверов. Это не решает проблему анализа постфактум, которую я описывал в статье.
conprof — больше похож на profefe. Но про него я узнал только летом (через полтора года после начала работы над profefe). Я успел немного пообщаться с разработчиками на летнем GopherCon. Не знаю как сейчас, но тогда там была очень «сильная любовь» к форку TSDB из prometheus. Были сомнения, сможет ли, на практике, TSDB эффективно индексировать и отдавать pprof-файлы (db заточена под временные ряды, где значение — просто число, метрика, а не блоб в несколько мегабайт; примерно это же обсуждают в https://github.com/conprof/conprof/issues/26).