
Всем привет! Меня зовут Людмила, я занимаюсь нагрузочным тестированием, хочу поделиться тем, как мы выполнили автоматизацию сравнительного анализа регрессионного профиля нагрузочного тестирования системы с БД под СУБД Oracle вместе с одним из наших заказчиков.
Целью статьи является не открытие «нового» подхода к сравнению производительности БД, а описание нашего опыта и попытка автоматизировать сравнение полученных результатов и
снизить количество обращений к DBA Oracle.

Проводя нагрузочное тестирование любой базы данных, нас в первую очередь интересует:
Для достижения поставленных целей сравнения только AWR-отчетов недостаточно.
Хорошей практикой является еще и централизованное хранение AWR-дампов. В AWR-дампах сохраняются все исторические представления (dba_hist).
Эта практика уже применялась у нашего клиента.
После очередной сессии нагрузочного тестирования мы сравниваем результаты:
Зачем это нужно?
Цели бывают разные:
Чтобы достичь всех эти целей, мы часто решаем задачу сравнения между собой разных дампов. Сроки обычно очень сжаты, когда должны были внедриться еще вчера! Времени полноценно проверять каждый регрессионный тест катастрофически не хватает. А если запускается тест надежности на сутки, то можно потратить уйму времени на анализ результата…
Безусловно, можно смотреть всё онлайн в Enterprise Manager (или запросами в представления gv$) во время теста: не ходить курить, есть и спать…

Возможно, у вас тоже есть свой кастомный инструмент, сделанный под себя? Можете поделиться в комментариях. А мы поделимся тем, что мы используем для своих задач.
В AWR-отчетах есть много полезной информации:

Тут есть полезная информация, например: сколько выполняется запрос, sql_id, модуль и сокращенный текст. Хоть и текст есть, он урезан и полный вариант можно взять из параграфа Complete List of SQL Text.
Что касается минусов: в AWR-отчете не понятно, когда эти запросы происходили, в какой момент их было больше, а в какой меньше… Ведь для анализа результатов тестирования понимание того, что происходило и в какой приблизительно момент, является важным: равномерно за весь тест или пиком/всплеском как будто по расписанию. Также мы тут увидим только ограниченный топ. Посмотреть это можно проще с помощью запросов в исторические таблицы.
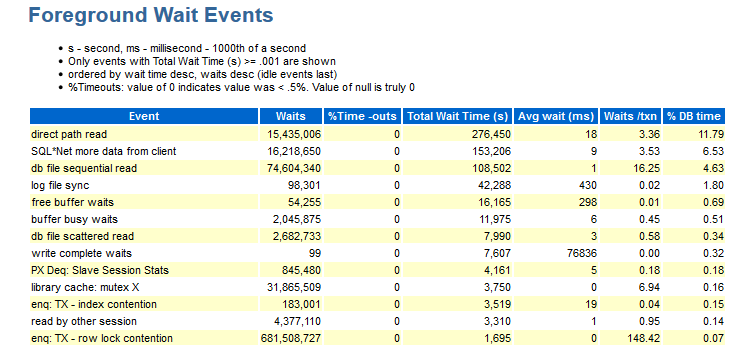
Здесь видно, какие события были во время теста. Данные в этом разделе упорядочены по DB time.
Для меня в этом разделе не хватает следующей инфы:
Для сравнения двух тестов можно воспользоваться сравнением AWR-отчетов:
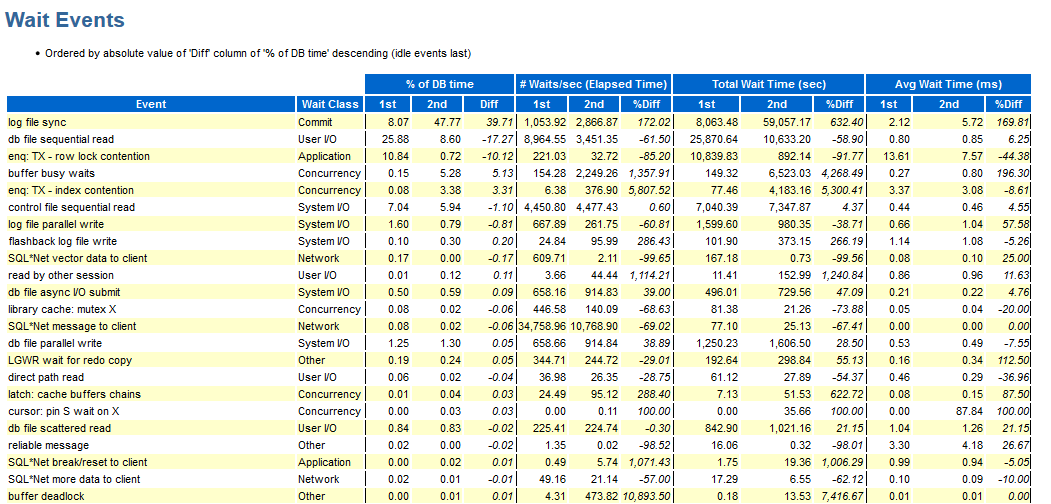
Ура, тут у нас выводится wait_class в остальном минусы те же описанные выше.
Иногда на проектах не бывает Enterprise Manager, и можно, например, использовать Enterprise Manager Express или ASH Viewer. В Enterprise Manager многие пользуются Top Activity по историческим данным, но для меня многие вещи проще смотреть самой запросами. Всё вышесказанное надо сравнивать с другими тестами/промышленной нагрузкой. Кастомное сравнение по времени выполнения у нас уже было, а вот по событиям нет, и мы проверяли вручную запросами по историческим таблицам.
Приходилось после каждого регрессионного теста сравнивать результаты в исторических таблицах запросами в базу, просматривать AWR-отчеты, локализовать проблемное ожидание (на каком модуле оно происходит, в какие времена происходило, на каком объекте висело), чтобы в итоге завести баг на нужную команду разработчиков.
База данных у заказчика достигла 190 Тб, в системе обрабатывается огромное количество запросов: количество параллельных модулей – 16237.
И тут у меня возникла идея, как упростить процесс сравнения дампов AWR. С этой идеей я пошла к Фреду. Совместными усилиями мы создали удобный портал.
Вначале постановка задачи от меня выглядела так:

Потом я все же решила систематизировать для начала то, какими запросами к историческим таблицам я чаще всего пользуюсь… Фред начал это прикручивать к порталу и дальше понеслось…
В первую очередь меня интересовало сравнение по событиям, так как сравнение по скорости выполнения запросов в каком-то виде уже существовало. Следующим этапом мне была необходима подробная информация о каждом событии: например, если событие index contention, то необходимо понимание, на каком мы собственно индексе висим.
Далее меня интересовало, в какие моменты времени этих событий было больше всего, так как в реализации было много задач (jobs), которые выполнялись по расписанию и надо было понимать, в какой приблизительно момент времени все затрещало по швам.
В общем, вот что я хотела получить:
Мы с Фредом сделали удобный для своего использования портал для сравнения AWR-дампов нагрузочного тестирования, о нем я подробней расскажу ниже.
Итак, в системе создаются AWR-дампы, которые заливаются в базу и на портале сравниваются между собой.
Мы использовали следующий стек:
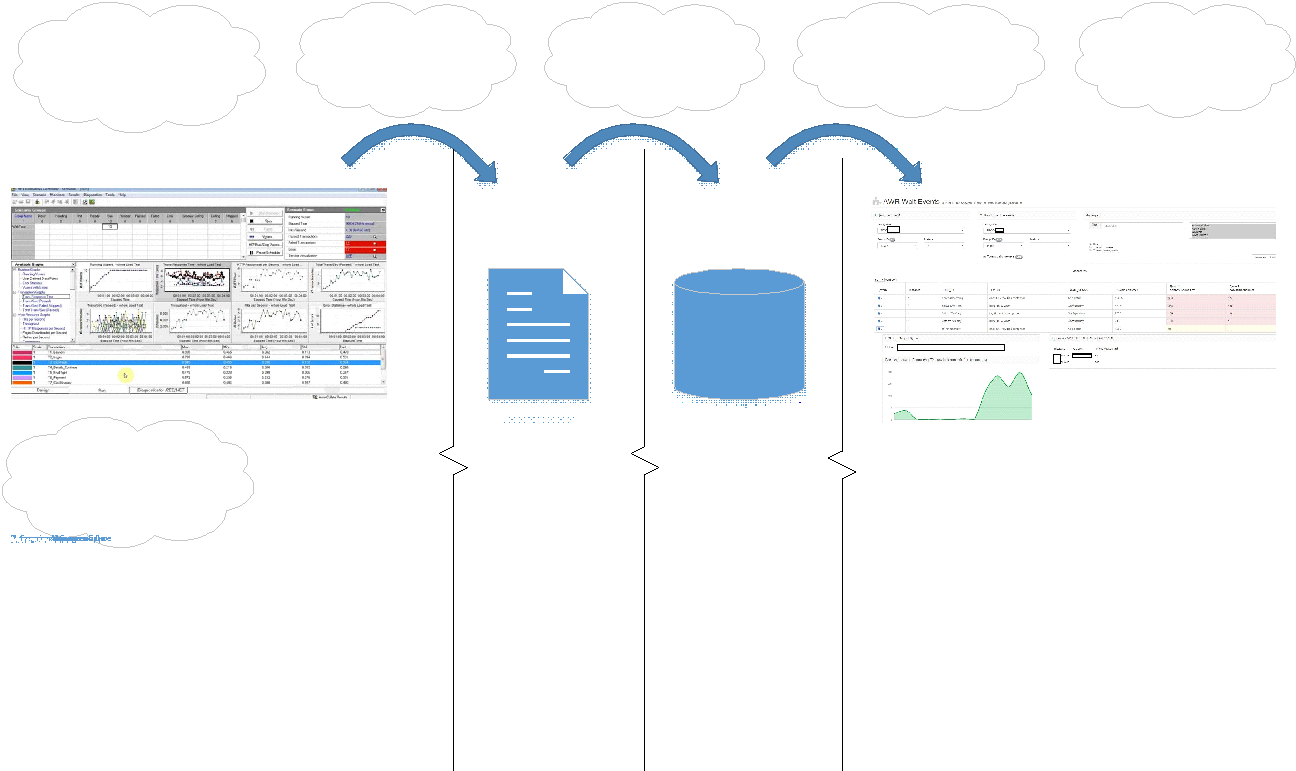
Интерфейс портала выглядит так:

На портале можно выбирать типы сравниваемых дампов, тест-тест или тест-пром.
Каждый дамп имеет свой уникальный идентификатор – DBID.
Можно отфильтровать так же по следующим параметрам:
Слева вверху выбираешь дампы, а справа можно задать необходимые фильтры, чтобы сразу выбирать нужный модуль — это позволяет точечно вылавливать проблемы в функционале, который был изменен/доработан, чтобы не было проблем с деградацией в предыдущей версии.
Таблица в середине — это результат сравнения дампов. По заголовкам столбцов сразу понятно, какие данные выводятся. В двух правых столбцах отображаются различия между двумя дампами:
Сразу видно, насколько правильное тестирование мы провели. Если событие происходило очень часто, то, скорее всего:
Если у нас появилось новое событие — жёлтое, — то это свидетельствует о каком-то изменении в системе, и нужно проанализировать его последствия. Тут же можно посмотреть распределение событий по снэпшотам и вывести подробную информацию об ожидании.
Однажды был случай: обнаружилось новое событие, которое было достаточно редким и не входило в топ событий, однако из-за него происходили замедления в функционале, у которого были критичные SLA. Анализ только топа запросов в AWR-отчете не смог этого выявить.
По каждому запросу можно получить более подробную информацию:
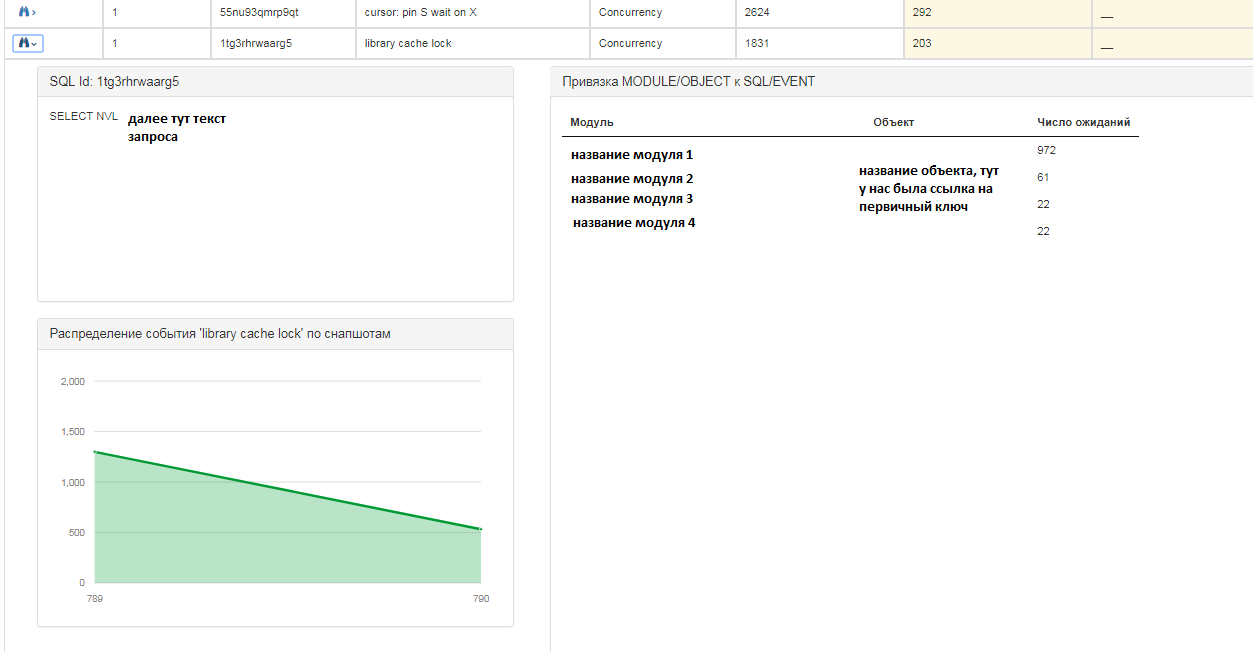
По каждой записи можно так же посмотреть следующую информацию:
В сравнении результатов участвуют системные представления Oracle:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED – своя служебная таблица (уже была реализована средствами заказчика), в ней информация об загруженных дампах.
Несколько запросов:
Распределение событий на снимки:
Группировка по модулю (модули, которые являются единой логической группой, объединяются в нее), блокируемому объекту:
Портал позволил нам сэкономить время на сравнение AWR-дампов. На ручное сравнение уходило 4-6 часов, а сейчас мы тратим 2-3 часа. У нас всегда под рукой есть возможность быстро сравнивать результаты разных тестов как между собой, так и с промышленным дампом, а также задавать нужные нам сейчас фильтры. То есть мы можем удобно сравнивать между собой исторические данные, а не только смотреть текущий результат в онлайн-режиме.
Раньше приходилось после каждого регресса сравнивать результаты в исторических таблицах запросами в базу, просматривать AWR-отчеты, локализовывать проблемное ожидание (на каком модуле оно происходит, в какие времена происходило, на каком объекте висело), чтобы в итоге завести дефект на нужную команду разработчиков. А теперь достаточно выбрать дампы для сравнения, задать фильтры — и сразу готовы результаты сравнения. Можно также отправлять разработчикам ссылку на портал с указанием DBID тестового дампа, и они сами отфильтруются по своему модулю.
На создание портала ушло всего две недели, потому что уже была готова одна его часть: загрузка дампов в базу данных. Конечно, такое портальное решение не нужно любому проекту с базой Oracle. Оно полезно для продуктов, которые разбиты на многочисленные модули с разными именами. Для простых систем или для систем, в которых не придавали значению заполнять module, портал будет избыточен.
Так как портал анализирует снимки, которые делаются раз в некоторый период, портал не освобождает полностью от онлайн-мониторинга работы базы данных, так как некоторые события могут не успеть попасть в снимок.
Это удобный инструмент для анализа исторических данных по итогам тестирования, но он может быть полезен и в других ситуациях, когда создаётся много снимков и нужно проверять большие объёмы данных. Благодаря сочетанию фильтров и графиков можно сразу увидеть всплески событий, которые в обычных AWR-отчётах (не путать с дампами) будут скрыты в сгруппированной информации. Достаточно выбрать дампы для сравнения, задать фильтры — и сразу готовы результаты сравнения, либо можно отправлять ссылку разработчикам на портал с указанием DBID тестового дампа, они сами отфильтруются по своему модулю.
Если надумаете разработать для своего проекта аналогичный портал, то подбирайте тот набор фильтров, который подходит именно вам. Если вы каждый раз фильтруете по разным условиям, то гораздо проще будет сделать для этого соответствующий фильтр.
Получившееся решение ещё можно доработать, например:
Или вообще указать порталу подключение к тестируемой базе данных, чтобы он построил онлайн подобные картинки по in-memory views, а не только по историческим данным. И сохранять их в свою БД.
Порталом мы пользуемся уже больше года. Фред, спасибо тебе большое!
Автор Людмила Мацкус,
«Инфосистемы Джет»
Целью статьи является не открытие «нового» подхода к сравнению производительности БД, а описание нашего опыта и попытка автоматизировать сравнение полученных результатов и
снизить количество обращений к DBA Oracle.
Проводя нагрузочное тестирование любой базы данных, нас в первую очередь интересует:
- А не сломалось ли что-нибудь после установки новой сборки?
- Динамика работы БД во время теста.
Для достижения поставленных целей сравнения только AWR-отчетов недостаточно.
Хорошей практикой является еще и централизованное хранение AWR-дампов. В AWR-дампах сохраняются все исторические представления (dba_hist).
Эта практика уже применялась у нашего клиента.
После очередной сессии нагрузочного тестирования мы сравниваем результаты:
- текущего тест-дампа с промышленным-дампом;
- текущего тест-дампа с предыдущим тест-дампом.
Зачем это нужно?
Цели бывают разные:
- Иногда наполнение самой базы в тестовой среде отличается от эксплуатационной, а значит будут отличия, которые мешают анализу («помехи» для ответа на основной вопрос «сломалось ли у нас что-нибудь?»). Эти отличия и хочется выявить;
- Сравнение текущего теста с работой промышленной базы помогает понять, насколько правильны текущие нагрузочные тесты (где-то мы нагружаем слишком сильно, а про что-то вообще забыли);
- Сравнение текущего теста с предыдущим тестом помогает понять, является ли нормальным текущее поведение системы? Изменилось ли что-то в поведении системы по сравнению с предыдущем тестом.
Чтобы достичь всех эти целей, мы часто решаем задачу сравнения между собой разных дампов. Сроки обычно очень сжаты, когда должны были внедриться еще вчера! Времени полноценно проверять каждый регрессионный тест катастрофически не хватает. А если запускается тест надежности на сутки, то можно потратить уйму времени на анализ результата…
Безусловно, можно смотреть всё онлайн в Enterprise Manager (или запросами в представления gv$) во время теста: не ходить курить, есть и спать…
Возможно, у вас тоже есть свой кастомный инструмент, сделанный под себя? Можете поделиться в комментариях. А мы поделимся тем, что мы используем для своих задач.
В AWR-отчетах есть много полезной информации:
Тут есть полезная информация, например: сколько выполняется запрос, sql_id, модуль и сокращенный текст. Хоть и текст есть, он урезан и полный вариант можно взять из параграфа Complete List of SQL Text.
Что касается минусов: в AWR-отчете не понятно, когда эти запросы происходили, в какой момент их было больше, а в какой меньше… Ведь для анализа результатов тестирования понимание того, что происходило и в какой приблизительно момент, является важным: равномерно за весь тест или пиком/всплеском как будто по расписанию. Также мы тут увидим только ограниченный топ. Посмотреть это можно проще с помощью запросов в исторические таблицы.
Здесь видно, какие события были во время теста. Данные в этом разделе упорядочены по DB time.
Для меня в этом разделе не хватает следующей инфы:
- Wait_class (да, с опытом запоминаешь, к какому типу ожиданий относится данное событие).
- Распределения по модулям (если я вижу, например, ожидание enq: TX — row lock contention: нужна информация, под каким модулем это происходило).
Встречаются джобы, в которых есть цифры, не несущие смысловой части, то есть надо сгруппировать одинаковые модули и получить ответ по группе, например: модуль_A_1, модуль_A_2, модуль_A_3 и модуль_B_1, модуль_ B_2, модуль_ B_3. То есть смысловых модуля было два, но имена у них у всех разные.
- Объект, на который ссылаемся (CURRENT_OBJ# – если, например, происходит событие enq: TX — index contention, было бы неплохо знать, какой индекс виновен).
- Sql_id – какой запрос пытались выполнить и текст этого запроса.
- Информация по распределению количества на снэпшот (как описывалось выше…).
Для сравнения двух тестов можно воспользоваться сравнением AWR-отчетов:
Ура, тут у нас выводится wait_class в остальном минусы те же описанные выше.
Иногда на проектах не бывает Enterprise Manager, и можно, например, использовать Enterprise Manager Express или ASH Viewer. В Enterprise Manager многие пользуются Top Activity по историческим данным, но для меня многие вещи проще смотреть самой запросами. Всё вышесказанное надо сравнивать с другими тестами/промышленной нагрузкой. Кастомное сравнение по времени выполнения у нас уже было, а вот по событиям нет, и мы проверяли вручную запросами по историческим таблицам.
Приходилось после каждого регрессионного теста сравнивать результаты в исторических таблицах запросами в базу, просматривать AWR-отчеты, локализовать проблемное ожидание (на каком модуле оно происходит, в какие времена происходило, на каком объекте висело), чтобы в итоге завести баг на нужную команду разработчиков.
База данных у заказчика достигла 190 Тб, в системе обрабатывается огромное количество запросов: количество параллельных модулей – 16237.
И тут у меня возникла идея, как упростить процесс сравнения дампов AWR. С этой идеей я пошла к Фреду. Совместными усилиями мы создали удобный портал.
Вначале постановка задачи от меня выглядела так:
Потом я все же решила систематизировать для начала то, какими запросами к историческим таблицам я чаще всего пользуюсь… Фред начал это прикручивать к порталу и дальше понеслось…
В первую очередь меня интересовало сравнение по событиям, так как сравнение по скорости выполнения запросов в каком-то виде уже существовало. Следующим этапом мне была необходима подробная информация о каждом событии: например, если событие index contention, то необходимо понимание, на каком мы собственно индексе висим.
Далее меня интересовало, в какие моменты времени этих событий было больше всего, так как в реализации было много задач (jobs), которые выполнялись по расписанию и надо было понимать, в какой приблизительно момент времени все затрещало по швам.
В общем, вот что я хотела получить:
- количественное сравнение событий между разными тестами (без дополнительных приседаний);
- всю необходимую мне для анализа сопутствующую информацию: sql_id, текст запроса, распределение во время теста, на какой объект ссылались сессии, модуль;
- удобные для себя фильтры, чтобы посмотреть то, что меняли;
- GUI GUI, все такое цветное, чтобы сразу было наглядно видно (можно скринить заинтересованным лицам со стороны разработки)
- группировку модулей: как описывалось ранее, модулей 16237, но, с точки зрения выполняемых функций, в разы меньше.
Мы с Фредом сделали удобный для своего использования портал для сравнения AWR-дампов нагрузочного тестирования, о нем я подробней расскажу ниже.
О портале
Итак, в системе создаются AWR-дампы, которые заливаются в базу и на портале сравниваются между собой.
Мы использовали следующий стек:
- Oracle DB – для хранения AWR-дампов
- Python 2 +
Интерфейс портала выглядит так:
На портале можно выбирать типы сравниваемых дампов, тест-тест или тест-пром.
Каждый дамп имеет свой уникальный идентификатор – DBID.
Можно отфильтровать так же по следующим параметрам:
- Инстанс (instance) – у нас была кластерная база данных;
- Запрос (Sql_id);
- Тип ожидания (Wait_Class);
- Событие (event).
Слева вверху выбираешь дампы, а справа можно задать необходимые фильтры, чтобы сразу выбирать нужный модуль — это позволяет точечно вылавливать проблемы в функционале, который был изменен/доработан, чтобы не было проблем с деградацией в предыдущей версии.
Таблица в середине — это результат сравнения дампов. По заголовкам столбцов сразу понятно, какие данные выводятся. В двух правых столбцах отображаются различия между двумя дампами:
- красным цветом выделены события, которых стало больше по сравнению со сравнительным дампом за снепшот;
- жёлтым — новые события;
- зелёным — события, которые уже были в исходном дампе.
Сразу видно, насколько правильное тестирование мы провели. Если событие происходило очень часто, то, скорее всего:
- избыточно нагрузили систему;
- либо условия выполнения фоновых джобов изменилось и событие стало воспроизводиться чаще. Однажды таким образом была найдена ошибка в коде: событие происходило постоянно, а не по нужной ветке условия.
Если у нас появилось новое событие — жёлтое, — то это свидетельствует о каком-то изменении в системе, и нужно проанализировать его последствия. Тут же можно посмотреть распределение событий по снэпшотам и вывести подробную информацию об ожидании.
Однажды был случай: обнаружилось новое событие, которое было достаточно редким и не входило в топ событий, однако из-за него происходили замедления в функционале, у которого были критичные SLA. Анализ только топа запросов в AWR-отчете не смог этого выявить.
По каждому запросу можно получить более подробную информацию:
По каждой записи можно так же посмотреть следующую информацию:
- текст sql запроса;
- распределение событий на snapshot в количественном соотношении, т.е. в какой момент времени событий было больше/меньше;
- на каких модулях и объектах «висело» ожидание.
В сравнении результатов участвуют системные представления Oracle:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED – своя служебная таблица (уже была реализована средствами заказчика), в ней информация об загруженных дампах.
Несколько запросов:
Распределение событий на снимки:
SELECT S.SNAP_ID, COUNT(*) RCOUNT
FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V.
WHERE V.ID = :1
AND S.DBID = V.DBID
AND S.INSTANCE_NUMBER = :2
AND S.SQL_ID = :3
AND S.EVENT_ID = :4
GROUP BY S.SNAP_ID
ORDER BY S.SNAP_ID ASC
Группировка по модулю (модули, которые являются единой логической группой, объединяются в нее), блокируемому объекту:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT
(SELECT CASE (WHEN INSTR(S.MODULE, ‘ТУТ МОДУЛИ ГРУППЫ 1’)>0 THEN ‘МОДУЛЬ ГРУППЫ 1’
WHEN INSTR(S.MODULE, ‘ТУТ МОДУЛИ ГРУППЫ 2’)>0 THEN ‘МОДУЛЬ ГРУППЫ 2’
…
ELSE S.MODULE END) MODULE, O.OBJECT_NAME
FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O
WHERE V.ID = :1
AND S.DBID = V.DBID
AND S.INSTANCE_NUMBER = :2
AND S.SQL_ID = :3
AND S.EVENT_ID = :4
AND S.CURRENT_OBJ# = O. OBJ# (+) AND V. DBID = O.DBID
)
GROUP BY MODULE, OBJECT_NAME
ORDER BY RCOUNT DESC
Что получили в итоге?
Портал позволил нам сэкономить время на сравнение AWR-дампов. На ручное сравнение уходило 4-6 часов, а сейчас мы тратим 2-3 часа. У нас всегда под рукой есть возможность быстро сравнивать результаты разных тестов как между собой, так и с промышленным дампом, а также задавать нужные нам сейчас фильтры. То есть мы можем удобно сравнивать между собой исторические данные, а не только смотреть текущий результат в онлайн-режиме.
Раньше приходилось после каждого регресса сравнивать результаты в исторических таблицах запросами в базу, просматривать AWR-отчеты, локализовывать проблемное ожидание (на каком модуле оно происходит, в какие времена происходило, на каком объекте висело), чтобы в итоге завести дефект на нужную команду разработчиков. А теперь достаточно выбрать дампы для сравнения, задать фильтры — и сразу готовы результаты сравнения. Можно также отправлять разработчикам ссылку на портал с указанием DBID тестового дампа, и они сами отфильтруются по своему модулю.
На создание портала ушло всего две недели, потому что уже была готова одна его часть: загрузка дампов в базу данных. Конечно, такое портальное решение не нужно любому проекту с базой Oracle. Оно полезно для продуктов, которые разбиты на многочисленные модули с разными именами. Для простых систем или для систем, в которых не придавали значению заполнять module, портал будет избыточен.
Так как портал анализирует снимки, которые делаются раз в некоторый период, портал не освобождает полностью от онлайн-мониторинга работы базы данных, так как некоторые события могут не успеть попасть в снимок.
Это удобный инструмент для анализа исторических данных по итогам тестирования, но он может быть полезен и в других ситуациях, когда создаётся много снимков и нужно проверять большие объёмы данных. Благодаря сочетанию фильтров и графиков можно сразу увидеть всплески событий, которые в обычных AWR-отчётах (не путать с дампами) будут скрыты в сгруппированной информации. Достаточно выбрать дампы для сравнения, задать фильтры — и сразу готовы результаты сравнения, либо можно отправлять ссылку разработчикам на портал с указанием DBID тестового дампа, они сами отфильтруются по своему модулю.
Если надумаете разработать для своего проекта аналогичный портал, то подбирайте тот набор фильтров, который подходит именно вам. Если вы каждый раз фильтруете по разным условиям, то гораздо проще будет сделать для этого соответствующий фильтр.
Получившееся решение ещё можно доработать, например:
- сравнением длительности выполнения запроса;
- сравнением планов запроса;
- сравнением запросов с одинаковым планом, но разным текстом;
- выгрузкой в отчеты по тестированию (оформление в виде документа Word/Exel).
Или вообще указать порталу подключение к тестируемой базе данных, чтобы он построил онлайн подобные картинки по in-memory views, а не только по историческим данным. И сохранять их в свою БД.
Порталом мы пользуемся уже больше года. Фред, спасибо тебе большое!
Автор Людмила Мацкус,
«Инфосистемы Джет»
Комментарии (6)

Ask-dba
10.10.2019 12:17+1Я такую идею давно выращивал, но нужна система выявления аномалий. Как по одному параметру, так и групповое изменение их баланса, а также аномалии и последовательности событтй = план исполнения. Тогда такая система сама укажет на проблему.
JetHabr Автор
10.10.2019 16:05Спасибо. Это как раз то, к чему надо стремиться, но экспертную оценку мы проводим пока сами… Хотя идея по машинленингу в данном вопросе интересна
AnotherAnkor
Я либо чего-то не понял, либо информации для воспроизведения вашего опыта в статье недостаточно.
Brain_Overload
а какой опыт вы хотите воспроизвести? тут же описана чисто концепция подхода, а реализация явно заточена под конкретный проект.