
Введение
Цель этого проекта — создание клона движка DOOM, использующего ресурсы, выпущенные вместе с Ultimate DOOM (версия со Steam).
Он будет представлен в виде туториала — я не хочу добиваться в коде максимальной производительности, а просто создам работающую версию, и позже начну её улучшать и оптимизировать.
У меня нет опыта создания игр или игровых движков, и мало опыта в написании статей, поэтому можете предлагать свои изменения или даже полностью переписать код.
Вот список ресурсов и ссылок.
Книга Game Engine Black Book: DOOM Фабьена Санглара. Одна из лучших книг по внутреннему устройству DOOM.
Doom Wiki
Исходный код DOOM
Исходный код Chocolate Doom
Требования
- Visual Studio: подойдёт любой IDE; я буду работать в Visual Studio 2017.
- SDL2: библиотеки.
- DOOM: копия Steam-версии Ultimate DOOM, нам из неё понадобится только файл WAD.
Необязательное
- Slade3: хороший инструмент для проверки нашей работы.
Мысли
Не знаю, смогу и я завершить этот проект, но приложу для этого все силы.
Моей целевой платформой будет Windows, но поскольку я использую SDL, будет просто заставить движок работать под любой другой платформой.
А пока установим Visual Studio!
Проект был переименован из Handmade DOOM в Do It Yourself Doom with SLD (DIY Doom), чтобы его не путали с другими проектами под названием «Handmade». В туториале есть несколько скриншотов, на которых он всё ещё называется Handmade DOOM.
Файлы WAD
Прежде чем приступать к кодингу, давайте поставим перед собой цели и продумаем, чего мы хотим достигнуть.
Для начала давайте проверим, сможем ли мы считывать файлы ресурсов DOOM. Все ресурсы DOOM находятся в файле WAD.
Что такое файл WAD?
«Where is All my Data»? («Где все мои данные»?) Они в WAD! WAD — это архив всех ресурсов DOOM (и игр на основе DOOM), находящийся в одном файле.
Разработчики Doom придумали этот формат, чтобы упростить создание модификаций игры.
Анатомия файла WAD
Файл WAD состоит из трёх основных частей: заголовка (header), «кусков» (lumps), и каталогов (directories).
- Заголовок — содержит базовую информацию о файле WAD и смещении каталогов.
- Lumps — здесь хранятся ресурсы игры, данные карт, спрайтов, музыки и т.д.
- Каталоги — организационная структура для поиска данных в разделе lump.
<---- 32 bits ---->
/------------------\
---> 0x00 | ASCII WAD Type | 0X03
| |------------------|
Header -| 0x04 | # of directories | 0x07
| |------------------|
---> 0x08 | directory offset | 0x0B --
---> |------------------| <-- |
| 0x0C | Lump Data | | |
| |------------------| | |
Lumps - | | . | | |
| | . | | |
| | . | | |
---> | . | | |
---> |------------------| <--|---
| | Lump offset | |
| |------------------| |
Directory -| | directory offset | ---
List | |------------------|
| | Lump Name |
| |------------------|
| | . |
| | . |
| | . |
---> \------------------/
Формат заголовка
| Размер поля | Тип данных | Содержимое |
|---|---|---|
| 0x00-0x03 | 4 символа ASCII | Строка ASCII (со значениями «IWAD» или «PWAD»). |
| 0x04-0x07 | unsigned int | Номер элемента каталогов. |
| 0x08-0x0b | unsigned int | Значение смещения на каталог в файле WAD. |
Формат каталогов
| Размер поля | Тип данных | Содержимое |
|---|---|---|
| 0x00-0x03 | unsigned int | Значение смещения на начало lump-данных в файле WAD. |
| 0x04-0x07 | unsigned int | Размер «куска» (lump) в байтах. |
| 0x08-0x0f | 8 символов ASCII | ASCII, содержащие название «куска». |
Цели
- Создать проект.
- Открыть файл WAD.
- Прочитать заголовок.
- Прочитать все каталоги и вывести их на экран.
Архитектура
Давайте пока не будем ничего усложнять. Создадим класс, который просто будет открывать и загружать WAD, и назовём его WADLoader. Затем напишем класс, отвечающий за считывание данных в зависимости от их формата, и назовём его WADReader. Также нам потребуется простая функция
main, вызывающая эти классы.Примечание: такая архитектура может быть и неоптимальной, и при необходимости мы будем её изменять.
Приступаем к коду
Давайте начнём с создания пустого проекта C++. В Visual Studio нажимаем на File-> New -> Project. Давайте назовём его «DIYDoom».
Давайте добавим два новых класса: WADLoader и WADReader. Начнём с реализации WADLoader.
class WADLoader
{
public:
WADLoader(std::string sWADFilePath); // We always want to make sure a WAD file is passed
bool LoadWAD(); // Will call other helper functions to open and load the WAD file
~WADLoader(); // Clean up!
protected:
bool OpenAndLoad(); // Open the file and load it to memory
bool ReadDirectories(); // A function what will iterate though the directory section
std::string m_sWADFilePath; // Sore the file name passed to the constructor
std::ifstream m_WADFile; // The file stream that will pint to the WAD file.
uint8_t *m_WADData; // let's load the file and keep it in memory! It is just a few MBs!
std::vector<Directory> m_WADDirectories; //let's store all the directories in this vector.
};Реализовать конструктор будет просто: инициализируем указатель данных и храним копию передаваемого пути к файлу WAD.
WADLoader::WADLoader(string sWADFilePath) : m_WADData(NULL), m_sWADFilePath(sWADFilePath)
{
}Теперь давайте приступим к реализации вспомогательной функции загрузки
OpenAndLoad: просто попробуем файл открыть как двоичный и в случае неудачи выведем ошибку.m_WADFile.open(m_sWADFilePath, ifstream::binary);
if (!m_WADFile.is_open())
{
cout << "Error: Failed to open WAD file" << m_sWADFilePath << endl;
return false;
}Если всё будет хорошо, и мы сможем находить и открывать файл, то нам понадобится знать размер файла, чтобы выделить память для копирования в неё файла.
m_WADFile.seekg(0, m_WADFile.end);
size_t length = m_WADFile.tellg();Теперь мы знаем, сколько места занимает полный WAD, и выделим нужное количество памяти.
m_WADData = new uint8_t[length]; Скопируем содержимое файла в эту память.
// remember to know the file size we had to move the file pointer all the way to the end! We need to move it back to the beginning.
m_WADFile.seekg(ifstream::beg);
m_WADFile.read((char *)m_WADData, length); // read the file and place it in m_WADData
m_WADFile.close();Возможно, вы заметили, что я использовал в качестве типа данных для
m_WADData тип unint8_t. Это значит, что мне нужен точный массив из 1 байта (1 байт * длина). Использование unint8_t гарантирует, что размер будет равным байту (8 битам, что можно понять из названия типа). Если бы мы хотели выделить 2 байта (16 бит), то использовали бы unint16_t, о котором мы поговорим позже. Благодаря использованию таких типов код становится платформонезависимым. Объясню: если мы используем «int», то точный размер int в памяти будет зависеть от системы. Если скомпилировать «int» в 32-битной конфигурации, то мы получим размер памяти, равный 4 байтам (32 битам), а при компилировании того же кода в 64-битной конфигурации мы получим размер памяти 8 байт (64 бит)! Хуже того, если скомпилировать код на 16-битной платформе (возможно, вы фанат DOS), то это даст нам 2 байта (16 бит)!Давайте вкратце проверим код и убедимся, что всё работает. Но прежде нам нужно реализовать LoadWAD. Пока LoadWAD будет вызывать «OpenAndLoad»
bool WADLoader::LoadWAD()
{
if (!OpenAndLoad())
{
return false;
}
return true;
}И давайте добавим в функцию main код, создающий экземпляр класса и пытающийся загрузить WAD
int main()
{
WADLoader wadloader("D:\\SDKs\\Assets\\Doom\\DOOM.WAD");
wadloader.LoadWAD();
return 0;
}Нужно будет ввести правильный путь к вашему файлу WAD. Давайте запустим!
Ой! Мы получили консольное окно, которое просто открывается на несколько секунд! Особо ничего полезного… работает ли программа? Идея! Давайте взглянем на память, и посмотрим, что в ней! Возможно, там мы найдём что-нибудь особенное! Для начала разместим точку останова, дважды щёлкнув слева от номера строки. Вы должны увидеть нечто подобное:
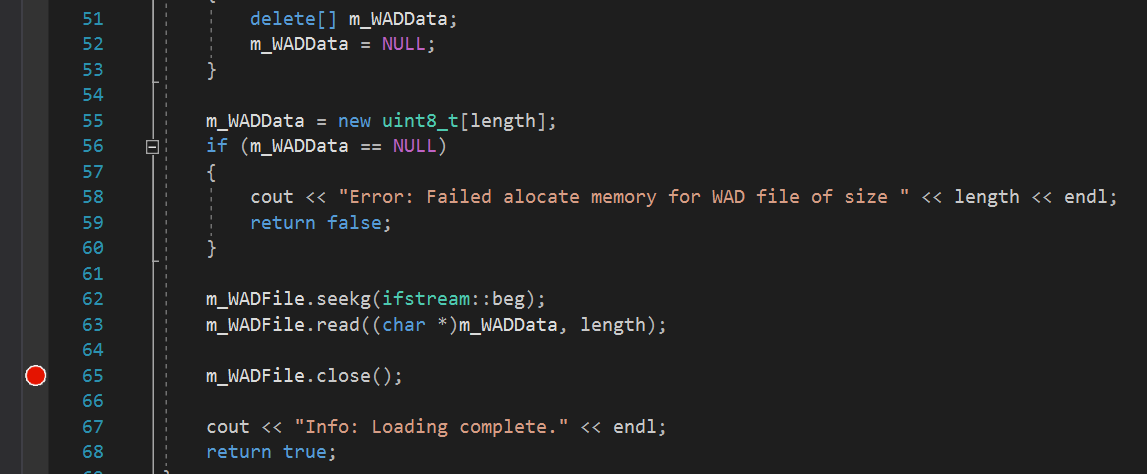
Я поместил точку останова сразу после чтения всех данных из файла, чтобы посмотреть на массив памяти и увидеть, что в него загружено. Теперь снова запустим код! В автоматическом окне я вижу несколько первых байтов. В первых 4 байтах написано «IWAD»! Отлично, работает! Никогда не думал, что этот день настанет! Так, ладно, нужно успокоиться, впереди ещё много работы!

Считывание заголовка
Общий размер заголовка составляет 12 байт (от 0x00 до 0x0b), эти 12 байт разделены на 3 группы. Первые 4 байта — это тип WAD, обычно «IWAD» или «PWAD». IWAD должен быть официальным WAD, выпущенным ID Software, «PWAD» должен использоваться для модов. Другими словами, это просто способ определить, является ли файл WAD официальным релизом, или выпущен моддерами. Заметьте, что строка не NULL terminated, поэтому внимательнее! Следующие 4 байта являются unsigned int, в котором содержится общее количество каталогов в конце файла. Следующие 4 байта обозначают смещение первого каталога.
Давайте добавим структуру, которая будет хранить информацию. Я добавлю новый файл заголовка и назову его «DataTypes.h». В нём мы будем описывать все нужные нам struct.
struct Header
{
char WADType[5]; // I added an extra character to add the NULL
uint32_t DirectoryCount; //uint32_t is 4 bytes (32 bits)
uint32_t DirectoryOffset; // The offset where the first directory is located.
};Теперь нам нужно реализовать класс WADReader, который будет считывать данные из загруженного массива байтов WAD. Ой! Тут есть хитрость — файлы WAD имеют формат big-endian, то есть нам нужно будет сдвинуть байты, чтобы сделать их little-endian (сегодня в большинстве систем используется little endian). Для этого мы добавим две функции, одну для обработки 2 байт (16 бит), другую — для обработки 4 байт (32 бит); если нам нужно считать только 1 байт, то делать ничего не надо.
uint16_t WADReader::bytesToShort(const uint8_t *pWADData, int offset)
{
return (pWADData[offset + 1] << 8) | pWADData[offset];
}
uint32_t WADReader::bytesToInteger(const uint8_t *pWADData, int offset)
{
return (pWADData[offset + 3] << 24) | (pWADData[offset + 2] << 16) | (pWADData[offset + 1] << 8) | pWADData[offset];
}Теперь мы готовы к считыванию заголовка: считаем первые четыре байта как char, а затем добавим к ним NULL, чтобы упростить себе работу. В случае с количеством каталогов и их смещением можно просто использовать вспомогательные функции для преобразования их в правильный формат.
void WADReader::ReadHeaderData(const uint8_t *pWADData, int offset, Header &header)
{
//0x00 to 0x03
header.WADType[0] = pWADData[offset];
header.WADType[1] = pWADData[offset + 1];
header.WADType[2] = pWADData[offset + 2];
header.WADType[3] = pWADData[offset + 3];
header.WADType[4] = '\0';
//0x04 to 0x07
header.DirectoryCount = bytesToInteger(pWADData, offset + 4);
//0x08 to 0x0b
header.DirectoryOffset = bytesToInteger(pWADData, offset + 8);
}Давайте соединим всё вместе, вызовем эти функции и выведем результаты
bool WADLoader::ReadDirectories()
{
WADReader reader;
Header header;
reader.ReadHeaderData(m_WADData, 0, header);
std::cout << header.WADType << std::endl;
std::cout << header.DirectoryCount << std::endl;
std::cout << header.DirectoryOffset << std::endl;
std::cout << std::endl << std::endl;
return true;
}Запустим программу и посмотрим, всё ли работает!
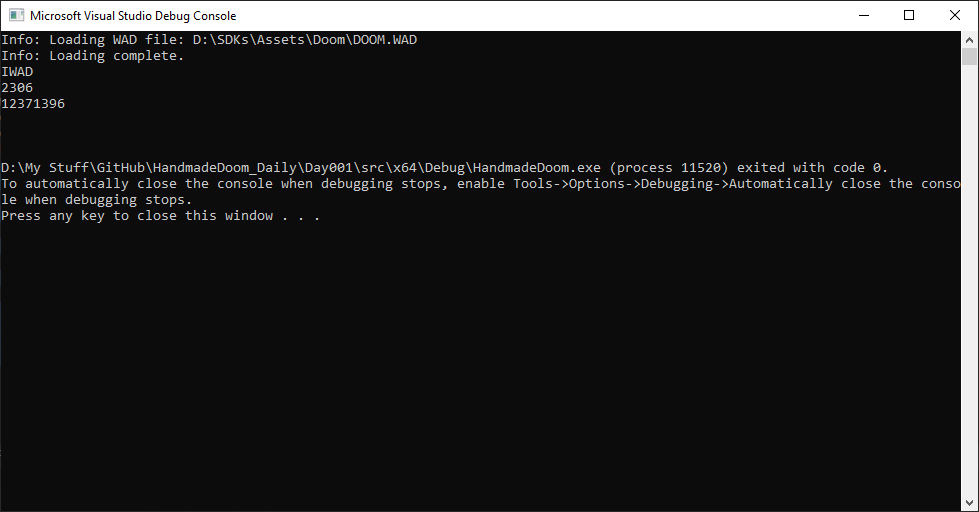
Отлично! Строку IWAD хорошо заметно, но правильны ли другие два числа? Попробуем считать каталоги при помощи этих смещений и посмотрим, получится ли!
Нам нужно добавить новую struct для обработки каталога, соответствующего представленным выше параметрам.
struct Directory
{
uint32_t LumpOffset;
uint32_t LumpSize;
char LumpName[9];
};Теперь давайте дополним функцию ReadDirectories: считаем смещение и выведем их!
В каждой итерации мы умножаем i * 16, чтобы перейти к инкременту смещения следующего каталога.
Directory directory;
for (unsigned int i = 0; i < header.DirectoryCount; ++i)
{
reader.ReadDirectoryData(m_WADData, header.DirectoryOffset + i * 16, directory);
m_WADDirectories.push_back(directory);
std::cout << directory.LumpOffset << std::endl;
std::cout << directory.LumpSize << std::endl;
std::cout << directory.LumpName << std::endl;
std::cout << std::endl;
}Запустим код и посмотрим, что получится. Ого! Большой список каталогов.
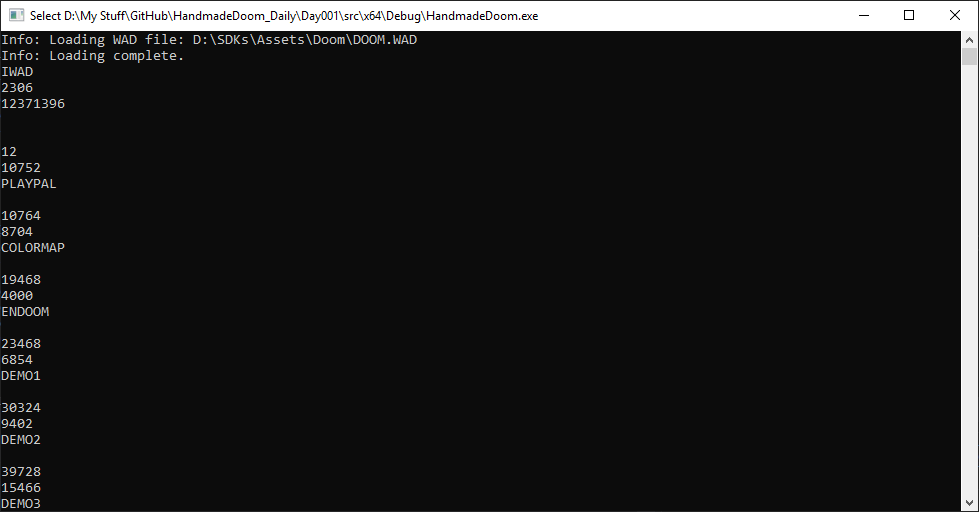
Судя по названию lump, можно предположить, что нам удалось правильно считать данные, но возможно есть способ получше, чтобы проверить это. Мы взглянем на записи WAD Directory при помощи Slade3.

Похоже, что название и размер lump соответствуют данным, полученным при помощи нашего кода. Сегодня мы проделали отличную работу!
Другие примечания
- На каком-то этапе я подумал, что хорошо будет использовать для хранения каталогов vector. А почему бы не использовать Map? Это будет быстрее, чем получение данных линейным поиском по вектору. Это плохая идея. При использовании map не будет отслеживаться порядок записей каталогов, а эта информация нам нужна для получения правильных данных.
И ещё одно ложное представление: Map в C++ реализованы как красно-чёрные деревья со временем поиска O(log N), и итерации по map всегда дают возрастающий порядок ключей. Если вам нужна структура данных, дающая среднее время O(1) и наихудшее время O(N), то придётся использовать неупорядоченную map. Загрузка всех файлов WAD в память — неоптимальный способ реализации. Будет логичнее просто считать в память заголовок каталоги, а затем возвращаться в файл WAD и загружать ресурсы с диска. Надеюсь, когда-нибудь мы больше узнаем о кэшировании.
DOOMReboot: полностью несогласен. 15 МБ ОЗУ в наши дни — совершенная мелочь, и считывание из памяти будет значительно быстрее, чем объёмные fseek, которые придётся использовать после загрузки всего, необходимого для уровня. Это увеличит время загрузки не меньше, чем на одну-две секунды (у меня всё время загрузки занимает меньше 20 мс). fseek задействуют ОС. У которой файл скорее всего находится в кэше ОЗУ, но может быть и нет. Но даже если он там, это большая трата ресурсов и эти операции запутают множество считываний WAD с точки зрения кэша ЦП. Самое лучшее, что можно создать гибридные методы загрузки и хранить данные WAD для уровня, которые помещаются в кэш L3 современных процессоров, где экономия окажется потрясающей.
Исходный код
Source code
Базовые данные карт
Научившись считывать файл WAD, давайте попробуем использовать прочитанные данные. Будет здорово научиться считывать данные миссии (мира/уровня) и применять их. «Куски» данных миссий (Mission Lumps) должны быть чем-то сложным и хитрым. Поэтому нам нужно будет двигаться и нарабатывать знания постепенно. В качестве первого небольшого шага давайте создадим нечто наподобие функции автокарты (Automap): двухмерного плана карты с видом сверху. Для начала посмотрим, что находится внутри Mission Lump.
Анатомия карты
Начнём сначала: описание уровней DOOM очень похоже на 2D-чертёж, на котором стены обозначены линиями. Однако для получения 3D-координат каждая стена берёт высоты пола и потолка (XY — это плоскость, по которой мы движемся горизонтально, а Z — это высота, позволяющая двигаться вверх и вниз, например, поднимаясь на лифте или спрыгнув вниз с платформы. Эти три компоненты координаты используются для рендеринга миссии как 3D-мира. Однако для обеспечения хорошей производительности движок имеет определённые ограничения: на уровнях нет расположенных одна над другой комнат и игрок не может смотреть вверх-вниз. Ещё одна интересная особенность: снаряды игрока, например, ракеты, поднимаются по вертикали, чтобы попасть в цель, расположенную на более высокой платформе.
Эти любопытные особенности стали причиной бесконечных холиваров по поводу того, является ли DOOM 2D- или 3D-движком. Постепенно был достигнут дипломатический компромисс, спасший множество жизней: стороны сошлись на приемлемом для обеих обозначении «2.5D».
Чтобы упростить задачу и вернуться к теме, давайте просто попробуем считать эти 2D-данные и посмотреть, можно ли их как-то использовать. Позже мы попробуем отрендерить их в 3D, а пока нам нужно разобраться в том, как работают совместно отдельные части движка.
Проведя исследования, я выяснил, что каждая миссия составлена из набора «кусков». Эти «куски» (Lumps) всегда представлены в файле WAD игры DOOM в одинаковом порядке.
- Вершины (VERTEXES): конечные точки стен в 2D. Две соединённые VERTEX образуют один LINEDEF. Три соединённые VERTEX образуют две стены /LINEDEF, и так далее. Их можно просто воспринимать как точки соединений двух или более стен. (Да, большинство людей предпочитает множественное число «Vertices», но Джону Кармаку оно не нравилось. По данным merriam-webster, применимы оба варианта.
- LINEDEFS: линии, образующие соединения между вершинами и формирующие стены. Не все линии (стены) ведут себя одинаково, существуют флаги, задающие поведение таких линий.
- SIDEDDEFS: в реальной жизни у стен есть две стороны — на одну мы смотрим, вторая находится с другой стороны. Эти две стороны могут иметь разные текстуры, и SIDEDEFS — это lump, содержащий информацию о текстуре для стены (LINEDEF).
- SECTORS: секторы — это «комнаты», получаемые соединением LINEDEF. Каждый сектор содержит такую информацию, как высота пола и потолка, текстуры, значение освещения, особые действия, например, подвижные полы/платформы/лифты. Некоторые из этих параметров также влияют на способ рендеринга стен, например, уровень освещённости и вычисление координат наложения текстур.
- SSECTORS: (подсекторы) образуют выпуклые области в пределах сектора, которые используются при рендеринге совместно с обходом BSP, и также помогают определять, где конкретно игрок находится на уровне. Они довольно полезны и часто используются для определения положения игрока по вертикали. Каждый SSECTOR состоит из соединённых частей сектора, например, из стен, образующих угол. Такие части стен, или «сегменты», хранятся в своём собственном Lump под названием...
- SEGS: части стены/LINEDEF; другими словами, это «сегменты» стены/LINEDEF. Мир рендерится обходом BSP-дерева для определения того, какие стены рисовать первыми (самые первые — ближайшие). Хотя система работает очень хорошо, она заставляет linedefs часто разделяться на два или более SEG. Такие SEG затем используются для рендеринга стен вместо LINEDEF. Геометрия каждого SSECTOR определяется содержащимися в нём segs.
- NODES: узел BSP — это узел структуры двоичного дерева, хранящий данные подсекторов. Он используется для быстрого определения того, какие SSECTOR (и SEG) находятся перед игроком. Устранение SEG, расположенных за игроком, а потому невидимых, позволяет движку сосредоточиться на потенциально видимых SEGs, что значительно снижает время рендеринга.
- THINGS: Lump под названием THINGS — это список декораций и акторов миссии (врагов, оружия и т.д.). Каждый элемент этого lump содержит информацию об одном экземпляре актора/декорации, например, тип объекта, точку создания, направление, и так далее.
- REJECT: этот lump содержит данные о том, какие секторы видимы из других секторов. Он используется для того, чтобы определять, когда монстр узнаёт о присутствии игрока. Также он используется для определения дальности распространения создаваемых игроком звуков, например, выстрелов. Когда такой звук способен передаться в сектор монстра, тот может узнать об игроке. Таблицу REJECT также можно использовать для ускорения распознавания коллизий снарядов оружия.
- BLOCKMAP: информация распознавания коллизий игрока и движения THING. Состоит из сетки, охватывающей геометрию всей миссии. Каждая ячейка сетки содержит список LINEDEF, которые находятся внутри или пересекают её. Используется для значительного ускорения распознавания коллизий: проверки коллизий требуются только для нескольких LINEDEF на каждого игрока/THING, что значительно экономит вычислительную мощь.
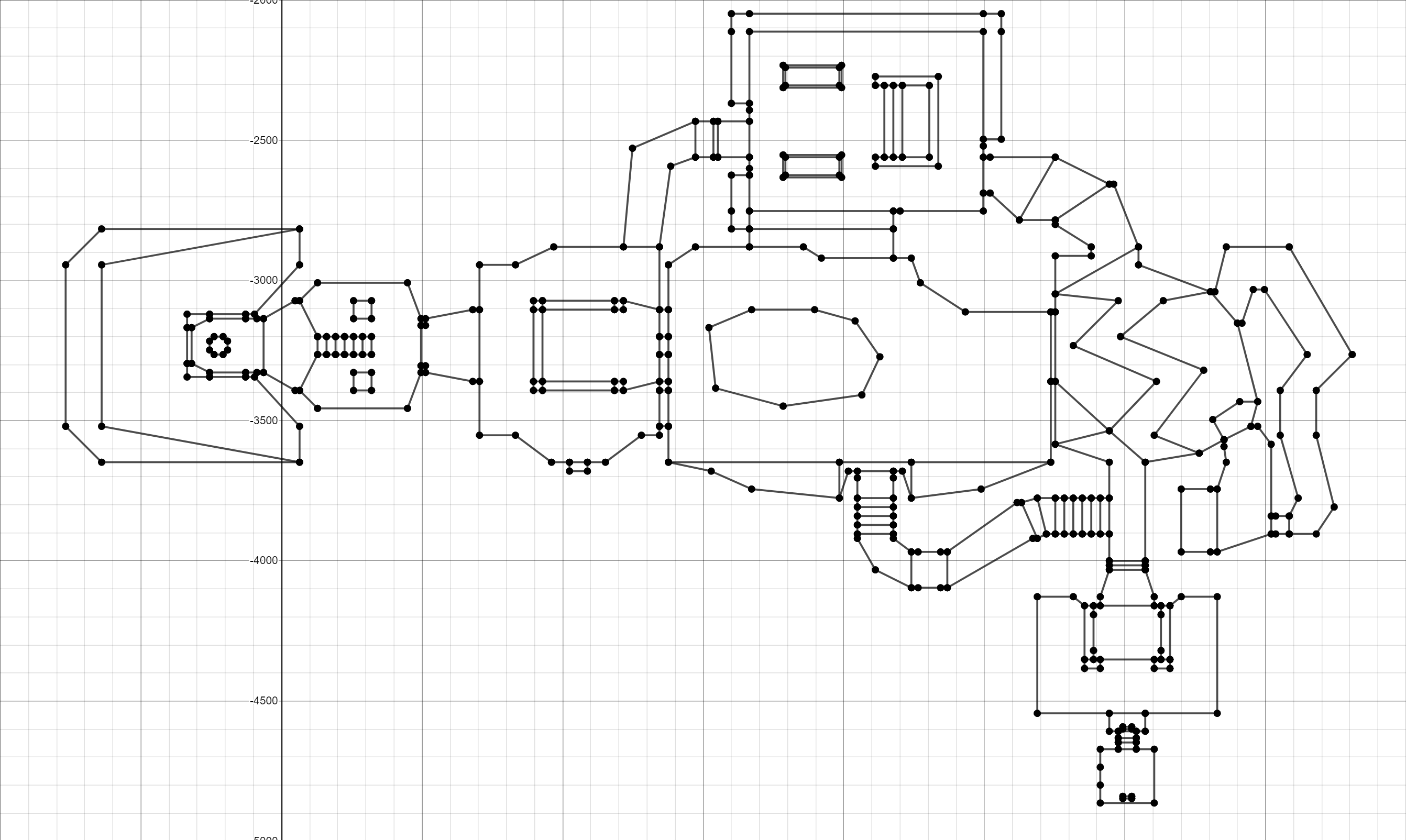
При генерации нашей 2D-карты мы сосредоточимся на VERTEXES и LINEDEFS. Если мы сможем отрисовать вершины и соединить их линиями, заданными linedef, то должны сгенерировать 2D-модель карты.
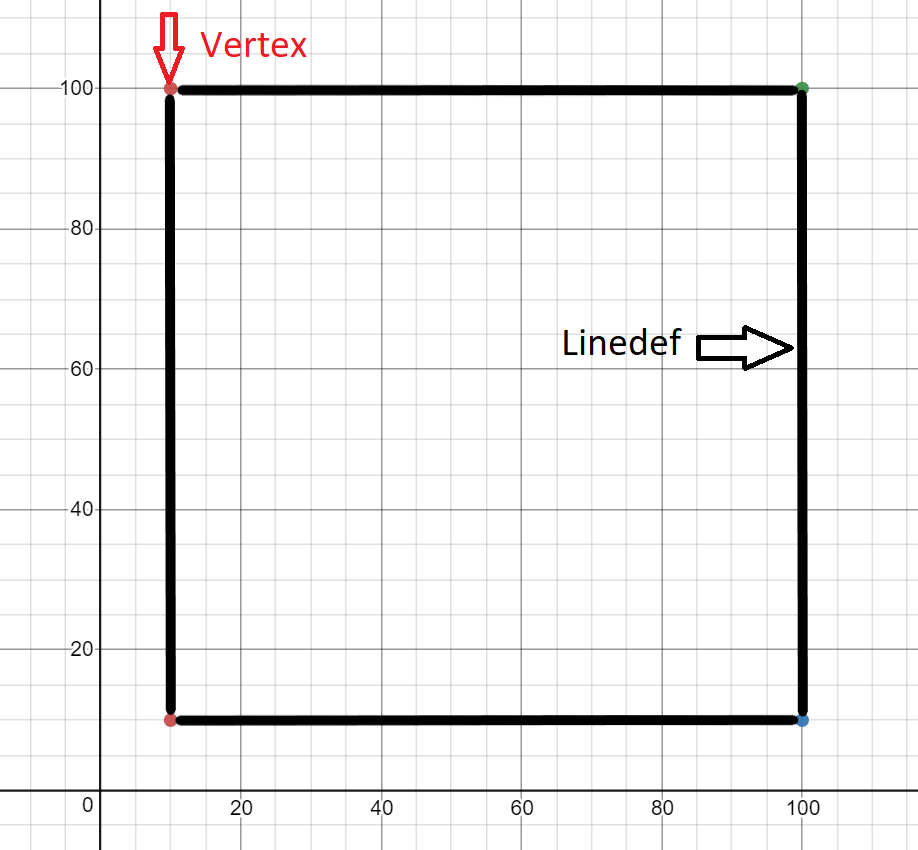
Показанная выше демо-карта имеет следующие характеристики:
- 4 вершины
- вершина 1 в (10,10)
- вершина 2 в (10,100)
- вершина 3 в (100, 10)
- вершина 4 в (100,100)
- 4 линии
- линия из вершины 1 в 2
- линия из вершины 1 в 3
- линия из вершины 2 в 4
- линия из вершины 3 в 4
Формат вершин
Как и можно ожидать, данные вершин очень просты — всего лишь x и y (точка) каких-то координат.
| Размер поля | Тип данных | Содержимое |
|---|---|---|
| 0x00-0x01 | Signed short | Позиция X |
| 0x02-0x03 | Signed short | Позиция Y |
Формат Linedef
В Linedef содержится больше информации, он описывает линию, соединяющую две вершины, и свойства этой линии (которая позже станет стеной).
| Размер поля | Тип данных | Содержимое |
|---|---|---|
| 0x00-0x01 | Unsigned short | Начальная вершина |
| 0x02-0x03 | Unsigned short | Конечная вершина |
| 0x04-0x05 | Unsigned short | Флаги (подробнее см. ниже) |
| 0x06-0x07 | Unsigned short | Тип линии/действие |
| 0x08-0x09 | Unsigned short | Метка сектора |
| 0x10-0x11 | Unsigned short | Передний sidedef (0xFFFF — стороны нет) |
| 0x12-0x13 | Unsigned short | Задний sidedef (0xFFFF — стороны нет) |
Значения флагов Linedef
Не все линии (стены) отрисовываются. Некоторые из них имеют особое поведение.
| Бит | Описание |
|---|---|
| 0 | Преграждает путь игрокам и монстрам |
| 1 | Преграждает путь монстрам |
| 2 | Двусторонняя |
| 3 | Верхняя текстура отключена (об этом мы поговорим позже) |
| 4 | Нижняя текстура отключена (об этом мы поговорим позже) |
| 5 | Секрет (на автокарте показывается как односторонняя стена) |
| 6 | Препятствует звуку |
| 7 | Никогда не показывается на автокарте |
| 8 | Всегда показывается на автокарте |
Цели
- Создать класс Map.
- Считать данные вершин.
- Считать данные linedef.
Архитектура
Для начала давайте создадим класс и назовём его map. В нём мы будем хранить все данные, связанные с картой.
Пока я планирую только хранить как вектор вершины и linedefs, чтобы применить их позже.
Также давайте дополним WADLoader и WADReader, чтобы мы могли считывать эти два новых элемента информации.
Кодинг
Код будет похож на на код чтения WAD, мы только добавим ещё несколько структур, а затем заполним их данными из WAD. Начнём с добавления нового класса и передачи названия карты.
class Map
{
public:
Map(std::string sName);
~Map();
std::string GetName(); // Incase someone need to know the map name
void AddVertex(Vertex &v); // Wrapper class to append to the vertexes vector
void AddLinedef(Linedef &l); // Wrapper class to append to the linedef vector
protected:
std::string m_sName;
std::vector<Vertex> m_Vertexes;
std::vector<Linedef> m_Linedef;
};Теперь добавим структуры, чтобы считывать эти новые поля. Поскольку мы уже несколько раз это делали, просто добавим их все сразу.
struct Vertex
{
int16_t XPosition;
int16_t YPosition;
};
struct Linedef
{
uint16_t StartVertex;
uint16_t EndVertex;
uint16_t Flags;
uint16_t LineType;
uint16_t SectorTag;
uint16_t FrontSidedef;
uint16_t BackSidedef;
};Далее нам понадобится функция для считывания их из WADReader, она будет близка к тому, что мы делали ранее.
void WADReader::ReadVertexData(const uint8_t *pWADData, int offset, Vertex &vertex)
{
vertex.XPosition = Read2Bytes(pWADData, offset);
vertex.YPosition = Read2Bytes(pWADData, offset + 2);
}
void WADReader::ReadLinedefData(const uint8_t *pWADData, int offset, Linedef &linedef)
{
linedef.StartVertex = Read2Bytes(pWADData, offset);
linedef.EndVertex = Read2Bytes(pWADData, offset + 2);
linedef.Flags = Read2Bytes(pWADData, offset + 4);
linedef.LineType = Read2Bytes(pWADData, offset + 6);
linedef.SectorTag = Read2Bytes(pWADData, offset + 8);
linedef.FrontSidedef = Read2Bytes(pWADData, offset + 10);
linedef.BackSidedef = Read2Bytes(pWADData, offset + 12);
}Думаю, для вас здесь нет ничего нового. А теперь нам нужно вызвать эти функции из класса WADLoader. Позвольте изложить факты: здесь важна последовательность lumps, мы найдём название карты в lump каталога, за которым в заданном порядке будут следовать все lumps, связанные с картами. Чтобы упростить себе задачу и не отслеживать индексы lumps по отдельности, мы добавим перечисление, позволяющее избавиться от магических чисел.
enum EMAPLUMPSINDEX
{
eTHINGS = 1,
eLINEDEFS,
eSIDEDDEFS,
eVERTEXES,
eSEAGS,
eSSECTORS,
eNODES,
eSECTORS,
eREJECT,
eBLOCKMAP,
eCOUNT
};Также я добавлю функцию для поиска карты по её названию в списке каталогов. Позже мы скорее всего повысим производительность этого шага, использовав структуру данных карт, потому что здесь присутствует значительное количество записей, и нам придётся довольно часто проходить по ним, особенно в начале загрузки таких ресурсов, как текстуры, спрайты, звуки и т.д.
int WADLoader::FindMapIndex(Map &map)
{
for (int i = 0; i < m_WADDirectories.size(); ++i)
{
if (m_WADDirectories[i].LumpName == map.GetName())
{
return i;
}
}
return -1;
}Ого, мы почти закончили! Теперь давайте просто считаем VERTEXES! Повторюсь, мы уже делали такое раньше, теперь вы должны разбираться в этом.
bool WADLoader::ReadMapVertex(Map &map)
{
int iMapIndex = FindMapIndex(map);
if (iMapIndex == -1)
{
return false;
}
iMapIndex += EMAPLUMPSINDEX::eVERTEXES;
if (strcmp(m_WADDirectories[iMapIndex].LumpName, "VERTEXES") != 0)
{
return false;
}
int iVertexSizeInBytes = sizeof(Vertex);
int iVertexesCount = m_WADDirectories[iMapIndex].LumpSize / iVertexSizeInBytes;
Vertex vertex;
for (int i = 0; i < iVertexesCount; ++i)
{
m_Reader.ReadVertexData(m_WADData, m_WADDirectories[iMapIndex].LumpOffset + i * iVertexSizeInBytes, vertex);
map.AddVertex(vertex);
cout << vertex.XPosition << endl;
cout << vertex.YPosition << endl;
std::cout << std::endl;
}
return true;
}Хм, похоже, что мы постоянно копипастим один и тот же код; возможно, в дальнейшем его придётся оптимизировать, но пока вы реализуете ReadMapLinedef самостоятельно (или посмотрите на исходный код по ссылке).
Финальные штрихи — нам нужно вызвать эту функцию и передать ей объект карты.
bool WADLoader::LoadMapData(Map &map)
{
if (!ReadMapVertex(map))
{
cout << "Error: Failed to load map vertex data MAP: " << map.GetName() << endl;
return false;
}
if (!ReadMapLinedef(map))
{
cout << "Error: Failed to load map linedef data MAP: " << map.GetName() << endl;
return false;
}
return true;
}Теперь давайте изменим функцию main и посмотрим, всё ли будет работать. Я хочу загрузить карту «E1M1», которую передам в объект карты.
Map map("E1M1");
wadloader.LoadMapData(map);Теперь давайте всё это запустим. Ого, куча интересных чисел, но верны ли они? Давайте проверим!
Посмотрим, сможет ли slade помочь нам и в этом.
Мы можем найти карту в меню slade и посмотреть на подробности lumps. Давайте сравним числа.
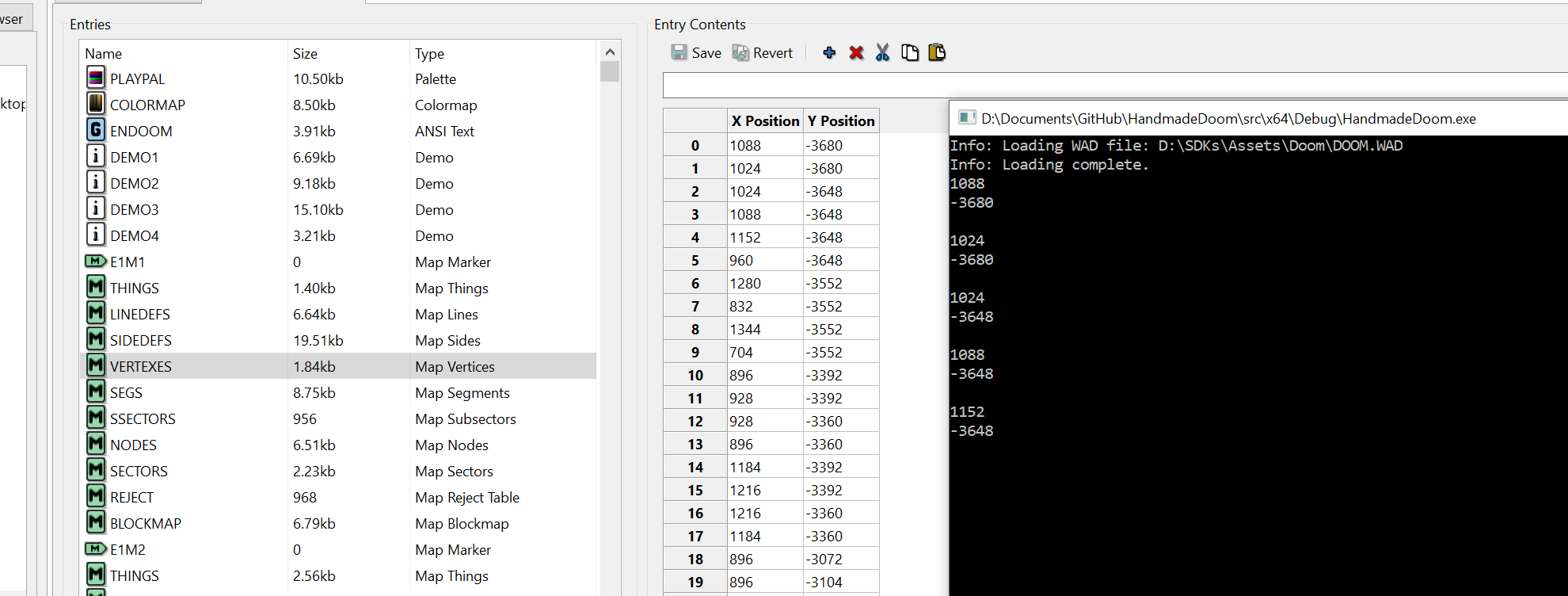
Отлично!
А как насчёт Linedef?
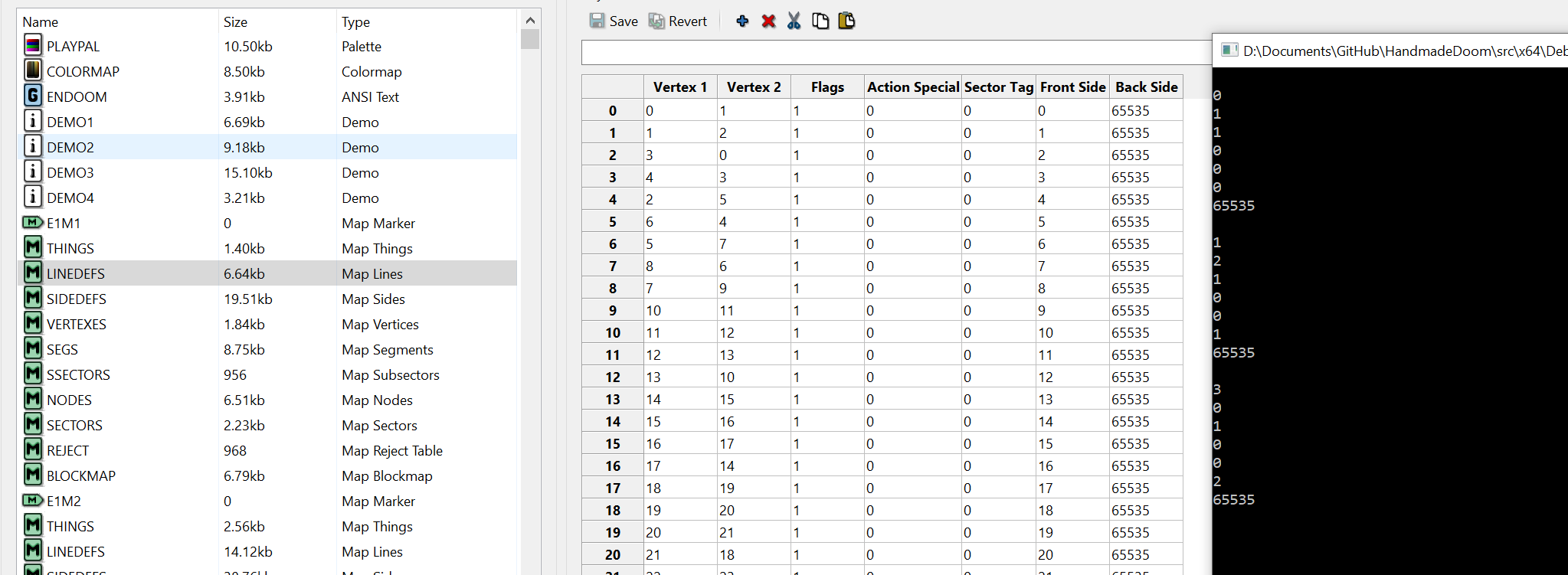
Также я добавил это перечисление, которое мы попробуем использовать при отрисовке карты.
enum ELINEDEFFLAGS
{
eBLOCKING = 0,
eBLOCKMONSTERS = 1,
eTWOSIDED = 2,
eDONTPEGTOP = 4,
eDONTPEGBOTTOM = 8,
eSECRET = 16,
eSOUNDBLOCK = 32,
eDONTDRAW = 64,
eDRAW = 128
};Другие примечания
В процессе написания кода я ошибочно считывал больше байтов, чем нужно, и получал неверные значения. Для отладки я начал смотреть на смещение WAD в памяти, чтобы понять, нахожусь ли я на нужном смещении. Это можно сделать при помощи окна памяти Visual Studio, которые оказываются очень полезным инструментом при отслеживании байтов или памяти (также в этом окне можно устанавливать точки останова).
Если вы не видите окно памяти, то перейдите в Debug > Memory > Memory.
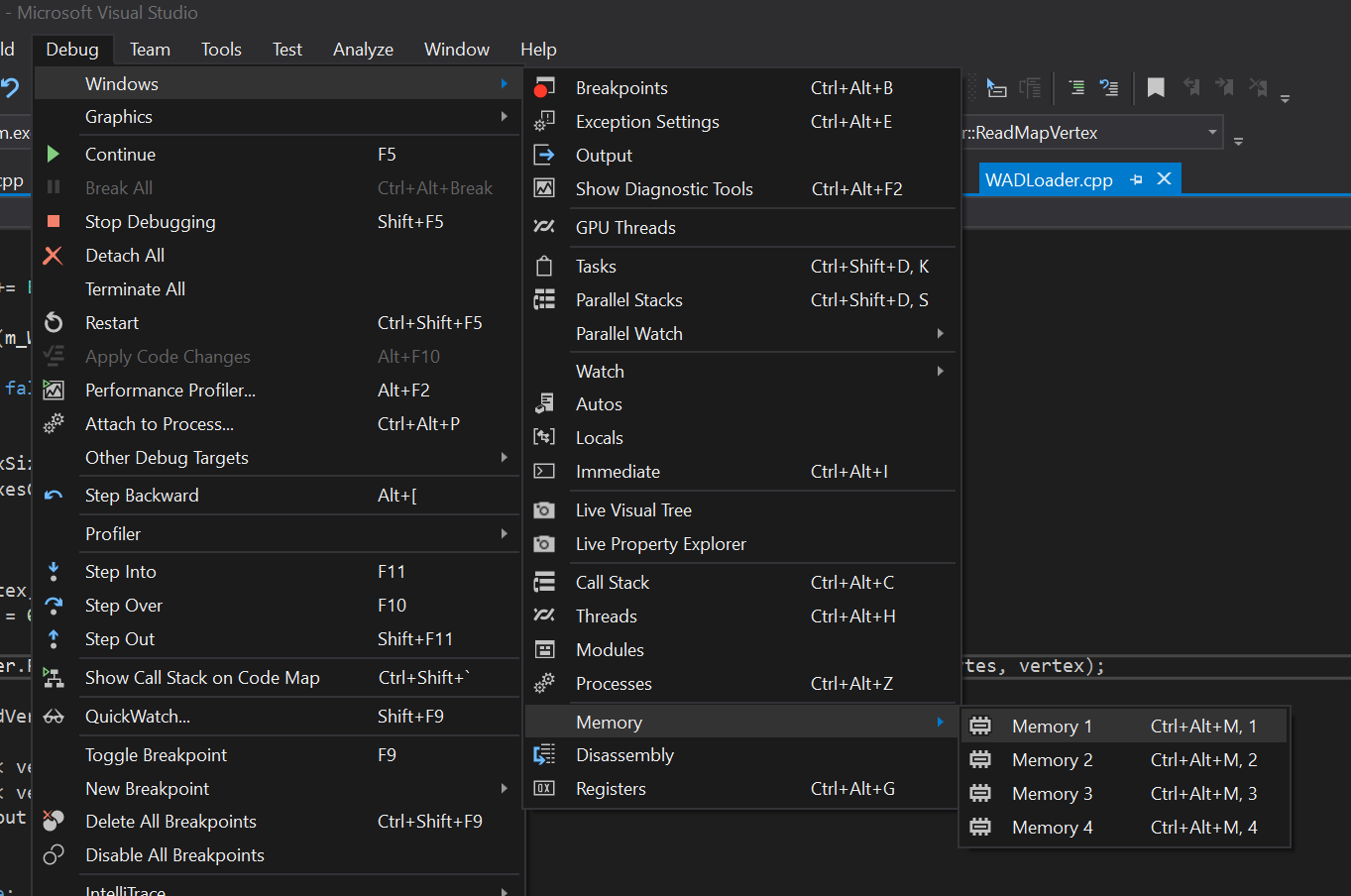
Теперь мы видим значения в памяти в шестнадцатеричном виде. Эти значения можно сравнить с hex-отображением в slade, нажав правой клавишей на любой lump и отобразив его как hex.
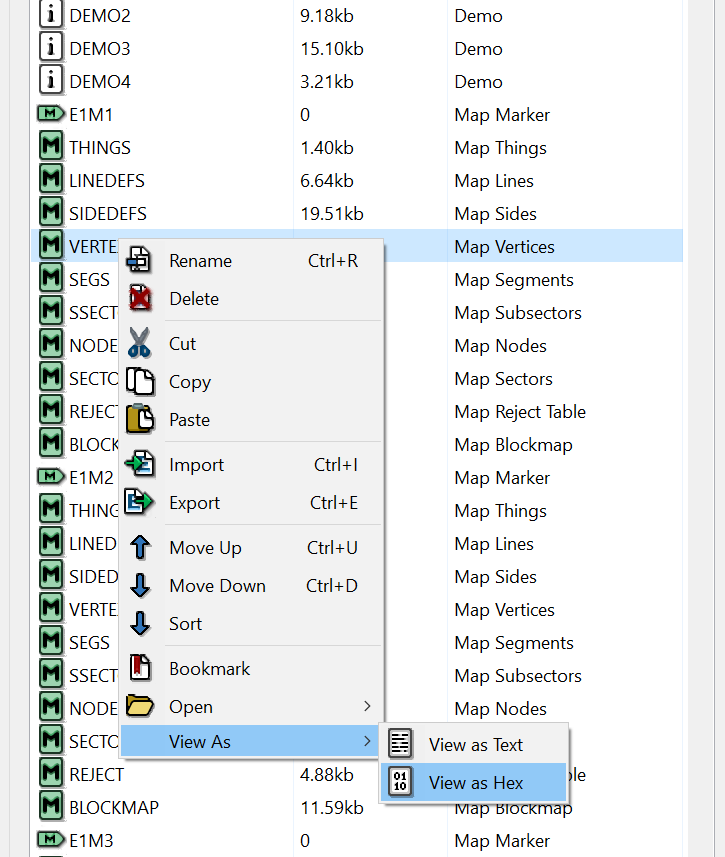
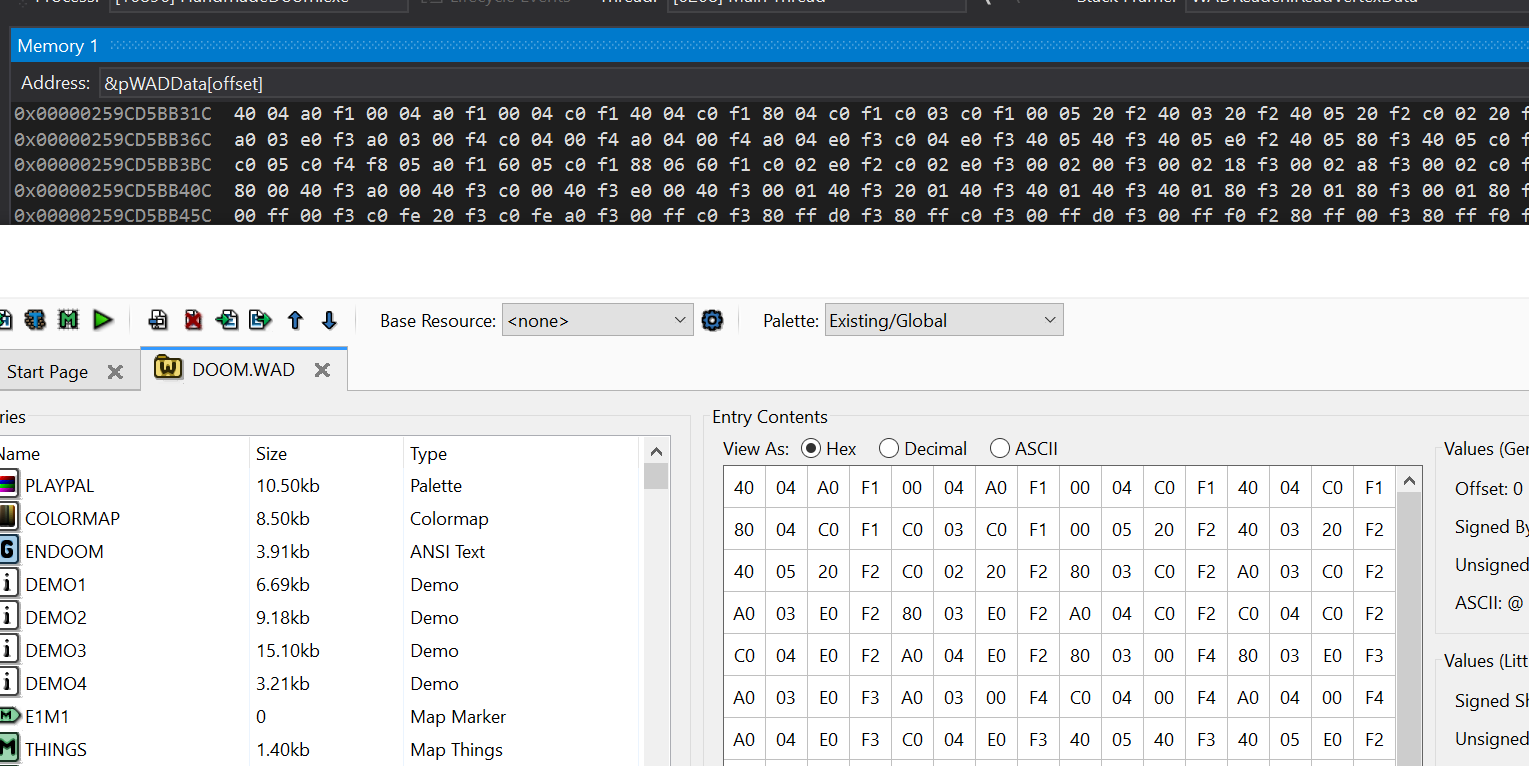
Сравниваем их с адресом загруженного в память WAD.
И последнее на сегодня: мы увидели все эти значения вершин, но есть ли простой способ визуализировать их без написания кода? Я не хочу тратить время на это, просто чтобы выяснить, что мы движемся не в том направлении.
Наверняка уже кто-то создал графопостроитель. Я загуглил «draw points on a graph» и первым результатом оказался веб-сайт Plot Points — Desmos. На нём можно вставить числа из буфера обмена, и он нарисует их. Они должны быть в формате "(x, y)". Чтобы получить его, достаточно немного изменить функцию вывода на экран.
cout << "(" << vertex.XPosition << "," << vertex.YPosition << ")" << endl;Ого! Это уже похоже на E1M1! Мы чего-то добились!
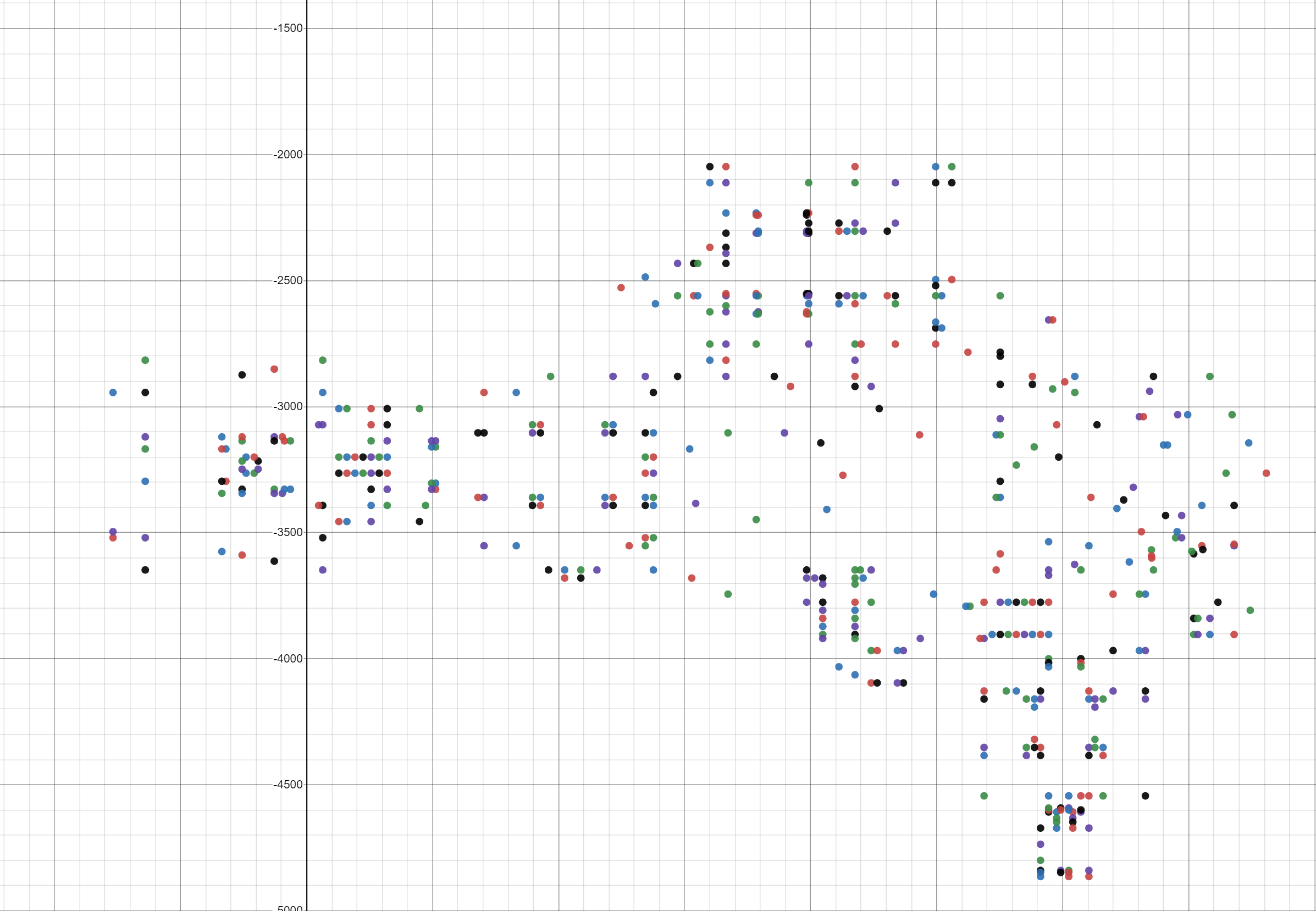
Если вам лениво это делать, то вот ссылка на заполненный точками график: Plot Vertex.
Но давайте сделаем ещё один шаг: немного потрудившись, мы можем соединить эти точки на основании linedefs.
Вот ссылка: E1M1 Plot Vertex
Исходный код
Source code
Справочные материалы
Doom Wiki
ZDoom Wiki


RinonNinqueon
Делал лет 7 назад распакователь/пакователь WAD файлов для своей проги автоматизации ZDoom скриптов и, соответственно, предпросмотр карты (вид сверху). Кажется, я даже в 3D потом умудрился сделать вывод. Вот, такой инфы на русском не хватало. Но проект всё равно был заброшен.
Спасибо за перевод.
AstarothAst
Самое время расчехлить и оживить!