
Во-первых, нигде не нашёл математическую формулу вычисления простых чисел по порядку. Но ведь если имеются алгоритмы, то наверняка можно составить и формулы, используя логические функции или операторы. Привожу ниже наиболее лаконичную формулу, которая получилась.
Для некоторой последовательности чисел введём оператор обнаружения первого числа, равного a:
Все простые числа, начиная с 5-ки, можно вычислить по формуле:
Оператор перебирает по остатки от деления каждого числа-кандидата на простоту с -м номером на уже найденные простые числа в диапазоне до . Числа-кандидаты выбираются по порядку из множества нечётных чисел, больших предыдущего простого числа . — это пи-функция, показывающая количество простых чисел .
Оператор перебирает по выходные значения оператора до тех пор, пока не обнаружит 0. Так как ряд простых чисел бесконечен, это рано или поздно произойдёт. На выходе оператора , таким образом, всегда будет некоторый номер . Нижняя граница определяется максимальной разностью соседних простых чисел, меньших искомого. Прирост такой разности происходит логарифмически. На графике ниже представлены зависимости максимального и среднего прироста от n для первых 100000 простых чисел. Выборка максимального значения и усреднение проводились для каждой тысячи чисел.

Максимальный прирост разности простых чисел к предыдущему максимальному значению равен 20 (для простых чисел 3312 и 3384). Он находится в области, где производная логарифма огибающей ещё достаточно велика, а простые числа уже не слишком малы. Исходя из этого значения получено условие для . График для первых 50000 простых чисел дан ниже. Значения вычислялись для каждой тысячи.
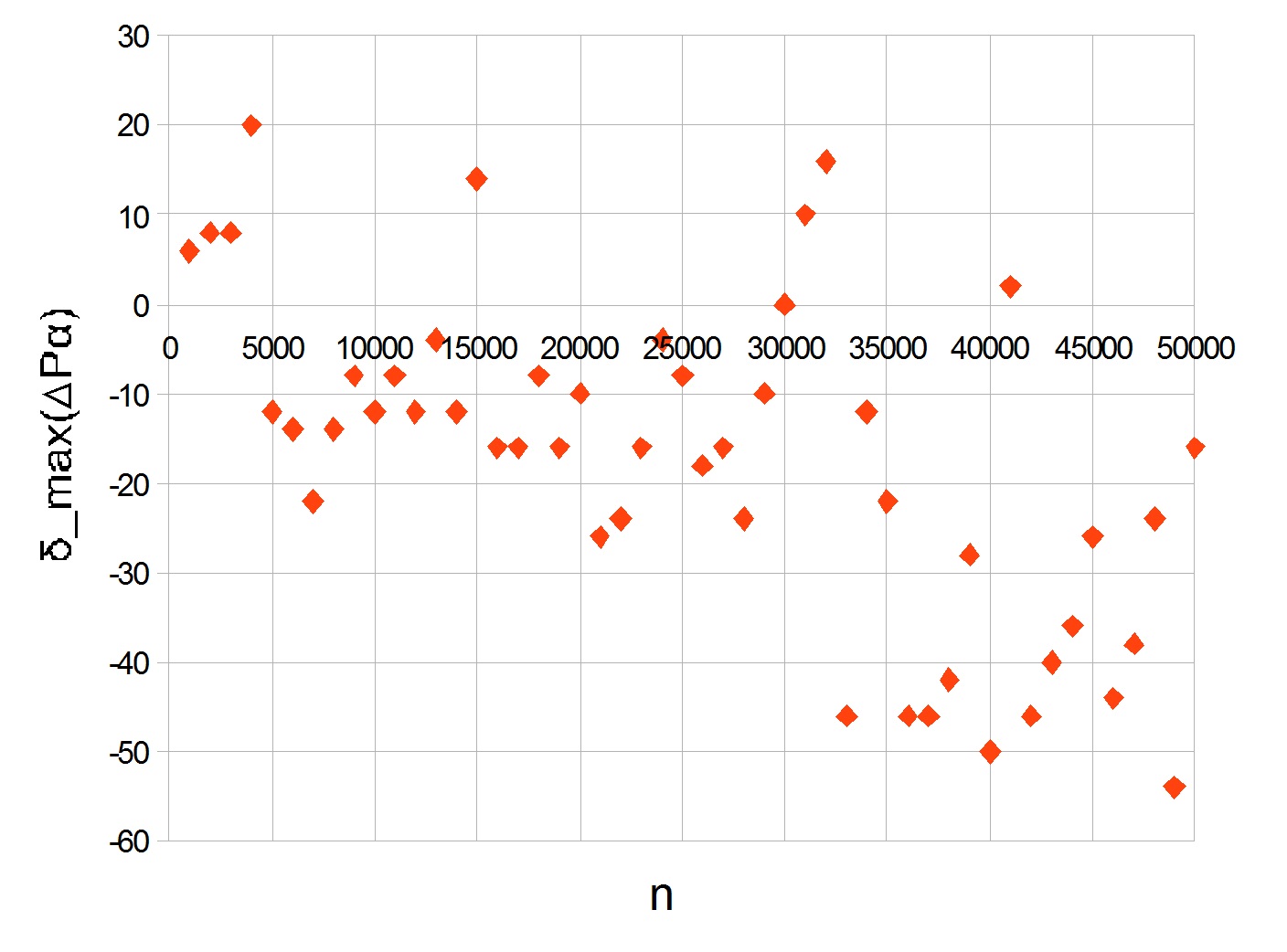
Виден пик на значении 20. С увеличением n график уходит в минус, показывая уменьшение скорости прироста больших простых чисел.
Второе соображение касается оптимизации вычисления последовательности простых чисел.
Алгоритм, заложенный в формуле выше- это улучшенный метод перебора делителей. Улучшения заключаются в исключении из рассмотрения чётных чисел и проверке делимости только на простые числа, меньшие кв. корней чисел-кандидатов. Самая сложная часть алгоритма- это вычисление множества функций взятия остатка mod. Уменьшить сложность можно путём оптимизации этой функции. Однако, есть ещё более эффективный способ. Пусть — это последовательность остатков от деления последнего найденного простого числа на простые числа от 3-ки до корня из него. Будем составлять последовательности вида по порядку, начиная с . Последний член вычисляется в случае, если . Когда на некотором шаге вычисления остаток становится равным 0, выполняется переход к следующей последовательности. Это делается до тех пор, пока не будет обнаружено i, при котором все остатки ненулевые. Это означает обнаружение очередного простого числа. Последовательность при этом необходимо сохранить до обнаружения следующего простого числа. Рекуррентная формула расчёта простых чисел таким способом преобразуется к виду:
В представленном алгоритме операция mod облегчена: делимые всего в раз больше делителей. Исключение составляют только случаи появления новых простых делителей. В памяти ЭВМ при реализации алгоритма необходимо хранить массив простых чисел до корня из искомого, а также переменный массив остатков. Сложность алгоритма в общем смысле (объём работы) может быть меньше, чем у других известных методов. Самые сложные операции в нём- это извлечение квадратного корня, вычисление остатков и умножение. Корень можно извлекать с точностью до целой части. Для получения остатков можно использовать эффективный алгоритм, основанный на общем правиле делимости. Умножение используется только на 2-ку относительно малых чисел i. Временную сложность алгоритма можно уменьшить, распределив работу по значениям i. Полученное таким путём сегментированное сито должно работать быстрее на многопоточных вычислителях. Однако, выполняемая работа будет больше ввиду увеличения делимых. Ещё к алгоритму можно «прикрутить» колёсную факторизацию. При оптимальном размере колёс это может уменьшить сложность в некотором диапазоне n — до тех пор, пока аппаратные «дебри» не затормозят его.
Возможно, кому-то мои соображения пригодятся.
Комментарии (45)


Victor_koly
18.10.2019 14:04Улучшения заключаются в исключении из рассмотрения чётных чисел и проверке делимости только на простые числа, меньшие кв. корней чисел-кандидатов.
Эту идею конечно давно придумали (может никто не публиковал на Хабре подобные статьи). Создать массив простых чисел до p <= N1/2.
Для создания этого массива делителей наверное нужно проверять делимость на 2 и дальше на непарные числа 3 < n <= N1/2.
oam2oam
18.10.2019 14:38+1решето Эратосфена, Аткина, Сундарама — нет, не слышал…
Просто поразительно, до чего был прав Достоевский — «Покажите вы русскому школьнику карту звездного неба, о которой он до тех пор не имел никакого понятия, и он завтра же возвратит вам эту карту исправленную. Никаких знаний и беззаветное самомнение».
Alexander_IK Автор
18.10.2019 14:46+1О данных алгоритмах Вы можете почитать в других постах. В этом речь не о них.

user_man
18.10.2019 15:03Интересно понять разницу представления алгоритма в виде формулы и просто словами. Вы привели оба варианта, поэтому разница весьма наглядна. Словами всё просто — перебираем все простые делители до корня из N. А вот формулой…
Мне кажется, что в данном случае представление алгоритма в виде формулы лишь запутывает читателя. Здесь уместно заметить, что языки программирования не зря получились именно такие, какими мы их знаем, и что важно — там нет возможностей для представления алгоритмов в виде подобных формул. Почему там нет таких возможностей? Наверное ваша статья даёт ответ — с формулами выходит ужасно сложно.
Хотя, возможно, я чего-то не понял. Тогда автор мог бы пояснить, в чём он видит преимущество представления выбранного алгоритма в виде формулы. Кроме того в заключении есть указания на оценку сложности алгоритма. Но неужели автор думает, что сложность переборного алгоритма до сих пор никто не оценил? Или в его алгоритме всё же есть какие-то отличия? Мне не хватило настойчивости на дешифрование алгоритма из предложенной формулы, а потому оставляю надежду на возможность выявления каких-то преимуществ предложенного подхода. И для этого надеюсь на комментарии автора.Alexander_IK Автор
18.10.2019 15:51В моём посте изложено 2 соображения, касающихся:
1. составления более-менее лаконичной математической формулы вычисления простых чисел. В ней заложен известный алгоритм перебора делителей с известными улучшениями.
2. оптимизации данного алгоритма (в формуле не представлена).
Формулу можете пропустить, если интересует только моя оптимизация алгоритма перебора делителей. Можно читать с «Однако, есть ещё более эффективный способ...»toyban
19.10.2019 15:29+3Вот только формулы Ваши означают совсем не то, что Вы полагаете. Так, возьмем Ваше определение функции
 . Вы говорите, что эта функция вернет индекс первого числа, равного a. А я говорю, что это не так.
. Вы говорите, что эта функция вернет индекс первого числа, равного a. А я говорю, что это не так.
Простейший контрпример — возьмем
 (специально для Вас взял простые числа, чтоб не подумали, будто я Вас обманываю) и посчитаем
(специально для Вас взял простые числа, чтоб не подумали, будто я Вас обманываю) и посчитаем  . К слову, почему последовательность
. К слову, почему последовательность  имеет индекс m, и как этот индекс связан с аргументом ?
имеет индекс m, и как этот индекс связан с аргументом ?
Так вот, согласно словесному описанию, Вы ожидаете получить
 , но по вашей формуле получается
, но по вашей формуле получается  .
.
Дальше в выражении

совсем какая-то жуть происходит. Вы определили функцию
для последовательностей, а подаете на вход число. Я так понимаю, там каким-то образом закодирована последовательность, но каким образом это сделано — совершенно непонятно. Плюс какие-то неизвестно откуда взявшиеся переменные i,j.
Математическую форму записи Вы, может, когда-то и видели, но сами ею не владеете. Пользуетесь ею довольно небрежно. Словесное описание не соответствует математическому описанию. Лучше занимайтесь тем, в чем Вы хороши. Право, не стоит на публике писать формулы, если не умеете это делаете, и у Вас нет соответствующего образования и подготовки.
Alexander_IK Автор
19.10.2019 16:091. Последовательность в математике обозначается скобками. Вы ставите равенство между членом последовательности x_m и последовательностью, это не корректно.
2. Обозначение оператора обнаружения Dt (сокращённо от detection) я ввёл таким образом, что в подписи снизу указывается искомое число, сверху- индекс членов последовательности, по которому ведётся поиск. Помимо этого индекса члены последовательности могут включать в себя другие индексы или переменные. В нашем случае члены последовательности по j включают в себя индекс i. Чтобы было понятно, по которому индексу работает оператор, я ввёл верхнюю подпись.
3. На входе оператора обнаружения последовательность, на выходе- число. Оператор- это отображение одного множества в другое. Их размерности могут быть разными. Оператор обнаружения обрабатывает только те члены последовательности, номера которых меньше либо равны номера искомого числа. Потом он заканчивает работу согласно его внутренней логике. В этом его преимущество над функцией поиска минимального значения, например. Последняя работает во всём заданном диапазоне.
4. В приведённом Вами «контрпримере» по моей формуле получится именно 3. Верхний индекс оператора нужно было написать m, других индексов члены указанной последовательности в себя не включают. Почему m? Используйте другую букву, сути это не изменит.
5. Я не претендую на математическую строгость обозначений, могут быть и более удачные.
6. Возможно, подобная формула уже где-то написана. Можете поискать. Я не нашёл.
lair
19.10.2019 16:50+1Оператор обнаружения обрабатывает только те члены последовательности, номера которых меньше либо равны номера искомого числа. Потом он заканчивает работу согласно его внутренней логике.
… так чем же это отличается от алгоритма?
toyban
20.10.2019 06:48+4Вы ставите равенство между членом последовательности x_m и последовательностью, это не корректно.
Нет, я говорю, что x_m — это последовательность чисел (2, 3, 5, 7, 11) (девятка там была лишней). Никакого соответствия члена последовательности и самой последовательности я не утверждал. Но теперь я понял смысл Вашего m тут.
В приведённом Вами «контрпримере» по моей формуле получится именно 3.
Боюсь, тут Вы заблуждаетесь. На самом деле и я ошибся, так как не понял, что параметр m в Dt не играет никакой роли. Поэтому после выяснения этой ошибки, я утверждаю, что оператор
 может вернуть не только 3, но любое число из множества {1,2,3}. Я даже не думаю, что в этом случае этот объект можно называть оператором или функцией. Какой-то этот Dt не шибко детерминирован. Никогда еще не встречал подобных "функций".
может вернуть не только 3, но любое число из множества {1,2,3}. Я даже не думаю, что в этом случае этот объект можно называть оператором или функцией. Какой-то этот Dt не шибко детерминирован. Никогда еще не встречал подобных "функций".
А теперь конкретно, почему последовательность
 является контрпримером для утверждения
является контрпримером для утверждения  . Все согласно Вашему определению
. Все согласно Вашему определению

Подставьте j = 1. И справа Вы получите правдивое утверждение, так как в последовательности (2, 3, 5, 7, 11) нет элемента, равного 5 на интервале индексов [1,1), но такой элемент найдется на интеpвале индексов [1,5]. Подставьте j = 2, и снова верное утверждение. Для j = 3 будет то же самое. Этот оператор может вернуть любое из вышеозначенных чисел! И независимо от входной последовательности, Dt всегда может вернуть 1!
NB: никто не пишет интервалы целых чисел как [a, b). Эта форма записи зарезервирована для действительных чисел. Если хотите указать, что элементы перебираются по какому-то интервалу целых чисел, то можно написать вот так [a...b]. И желательно никаких открытых или полуоткрытых интервалов. А иначе выглядит странно. Я записал этот интервал Вашим способом только для того, чтоб Вам было видней.
Вы размышляете о квантификаторах, как программист. Они ничего не перебирают, ничего не ищут. Они сразу возвращают ответ. Если в множестве или последовательности есть подходящий элемент — ответ моментально да, если нет — то нет. Не имеет смысла говорить о временной сложности формулы, поскольку формулы не обладают временной сложностью. Это понятия применимо только к алгоритмам. Поэтому Ваша ремарка, что Dt работает эффективней min абсолютно бессмысленна.
И да, формулы — это не алгоритмы. Тут я с Вами согласен. Можно составить формулу с невычислимыми функциями. И формула будет верна, но не существует алгоритма, который мог бы ее вычислить.
Возможно, подобная формула уже где-то написана. Можете поискать. Я не нашёл.
Я Вам могу сразу сказать, что такой формулы не существует, потому что она просто неверна (по причине, которую я показал выше) и записана как-то нелепо и непонятно.
Дальше еще одно слово о Вашей ремарке, будто Ваша реализация работает быстрей min. Тут я уже говорю о реализациях, то есть конкретных алгоритмах реализации Вашей функции и min. Так вот, даже не видя Вашей реализации или какой-нибудь реализации min, я могу смело утверждать, что их временная сложность одинаковая — линейная, если не дано каких-нибудь дополнительных данных о последовательности, на которой они работают. Очевидно, что Вы не очень хорошо понимаете, как проводится оценка временной сложности алгоритмов.
Ух, сколько написал.
Alexander_IK Автор
20.10.2019 18:03-3Нет, я говорю, что x_m — это последовательность чисел
x_m- это член последовательности с номером m, последовательность обозначается (x_m)
Боюсь, тут Вы заблуждаетесь...
Вы сами придумали новую формулу и сами её опровергли… Формула в посте имеет совсем другой вид.
никто не пишет интервалы целых чисел как [a, b)
Запись корректна, т. к. множество натуральных чисел входит во множество вещественных. Ваше обозначение- это набор, а не интервал.
Вы размышляете о квантификаторах, как программист.
Ни о каких квантификаторах я не размышлял.
Не имеет смысла говорить о временной сложности формулы, поскольку формулы не обладают временной сложностью.
Я не писал о временной сложности формулы. Речь была о преимуществе оператора обнаружения над функцией поиска минимального значения в заданном интервале. Приведённая формула с операторами позволяет более-менее кратко описать известный алгоритм перебора делителей на языке математики.
… И формула будет верна, но не существует алгоритма, который мог бы ее вычислить.
Алгоритмы, на мой взгляд, можно придумать и для т. н. «невычислимых функций». Пока их изучают люди, но ИИ активно разрабатывается.
Я Вам могу сразу сказать, что такой формулы не существует, потому что она просто неверна
Специально или нет, но Вы исказили мою формулу и доказываете неверность своего искаженного варианта.
Так вот, даже не видя Вашей реализации или какой-нибудь реализации min, я могу смело утверждать, что их временная сложность одинаковая — линейная,
Вы смело рассуждаете о том, чего не поняли. Алгоритм для оператора обнаружения заключается в переборе чисел из последовательности до первого искомого. Потом он останавливается (оставшаяся часть последовательности не обрабатывается). Алгоритм для функции минимума же будет перебирать все члены последовательности, в нём нет доп. логики остановки.
Ввиду того, что конструктив в вашем «писании» отсутствует, разъяснение Вам поста заканчиваю. Спасибо, до свидания.
Alexander_IK Автор
21.10.2019 11:37В формуле для оператора, действительно, была ошибка. Исправил. Коверкать её не стоило, но за мотивацию повторной проверки спасибо.

zagayevskiy
18.10.2019 16:23Сложность алгоритма в общем смысле (объём работы)
Это как?Alexander_IK Автор
18.10.2019 18:06-3Согласно общему определению вычислительной сложности. В первом приближении это суммарное количество элементарных арифметических операций, необходимых для выполнения задания. Они могут быть распределены по времени (одна рекуррентная формула) и в пространстве (сито).
zagayevskiy
18.10.2019 19:25Я чёт сомневаюсь, что вы действительно нашли алгоритм, который лучше существующий для этой задачи. Нужны доказательства.
Alexander_IK Автор
18.10.2019 20:28-2Я предполагаю, но не утверждаю этого. Был бы благодарен за помощь профессионального сообщества в прояснении этого вопроса!
zagayevskiy
18.10.2019 20:32Эээ, бремя доказательства лежит на утверждающем.
Alexander_IK Автор
18.10.2019 20:52-2А кто утверждает? Будут доказательства- будет утверждение. Пока могу только размышлять на эту тему.

dlinyj
18.10.2019 19:10elementy.ru/bookclub/chapters/431103/Prostaya_oderzhimost_Glavy_iz_knigi рекомендую к прочтению
Alexander_IK Автор
18.10.2019 19:58-3Спасибо за книгу. Одержимость задачей поиска простых чисел ни к чему хорошему не приведёт. В меру же занятие полезно. Гипотеза Римана, о которой речь в книге, к моему посту имеет слабое отношение. Пи-функции нужно знать точно, они получаются измерением длины массива найденных простых чисел до заданного корня. Аппроксимация данных на графиках логарифмами, вероятно, не лучшая, но в первом приближении этого достаточно.
azudem
19.10.2019 16:24+3Автор изобретает велосипеды, пытаясь задно убедить себя и других в наличии разницы между «алгоритмом» и «математической формулой». Это фейспалм, господа. Совершенно не представляю, кто и почему ставит таким бессодержательным статьям плюсы.
Alexander_IK Автор
19.10.2019 22:58-5Всем, кто не видит разницы между "математической формулой" и "алгоритмом" могу привести несколько аналогий: техническое задание- алгоритм, алгоритм- код, код на языке высокого уровня- код на ассемблере. Везде может содержаться одна и та же информация, но её представление разное! Более того, многие закономерности и алгоритмы существуют в природе, социальной сфере. Не стоит превышать значимость информатики, это всего лишь одна из областей знаний. Взгляд на известные алгоритмы под другим углом может быть полезен!
binpol
20.10.2019 18:11мне статья не понравилась, такая изящная тема, и такое скучное изложение, никаких тебе оценок алгортима, введение не нужного оператора, ни слова про библиотеку больших натуральных чисел или как вы собираетесь масштабировать ваш оператор.
Alexander_IK Автор
20.10.2019 18:14-3Это краткий пост, а не научная статья. Возможно, кому-то он понравится. Идеи можно развить.
Alexander_IK Автор
21.10.2019 16:32Добавил рекуррентную формулу расчёта простых чисел эффективным методом перебора делителей.
xi-tauw
Если исследование начать с википедии, то можно сразу увидеть пример формулы в виде полинома.
Alexander_IK Автор
Спасибо. Внёс правку: «нигде не нашёл математическую формулу вычисления последовательности простых чисел».
kkirsanov2
Но та же википедия даёт ссылку на https://oeis.org/A000040 где, как мне кажется, формул вычисления последовательности довольно много.
Alexander_IK Автор
Много алгоритмов вычисления последовательности. Математической формулы я не нашёл.
lair
В чем принципиальная разница между вашей "математической формулой" и алгоритмом?
(не по формальному определению, а по свойствам)
Alexander_IK Автор
См. определения «математическая формула» и «алгоритм» в википедии.
lair
По свойствам.
kkirsanov2
Чем соответствие карри-ховарда не устраивает?
Alexander_IK Автор
Прекрасное соответствие! Только речь в нём о доказательствах, а не о формулах. Впрочем, его можно расширить и на математические формулы, включающие логические элементы. Вкратце об этом написано в начале поста.
kkirsanov2
> Только речь в нём о доказательствах
Но доказательство можно представить в виде формулы.
Я по прежнему не понимаю почему было важно написать правило $P_n = P_(n-1)+$… на языке TeX, а не P n = P (n-1)+… на хаскеле или любом другом языке.
Alexander_IK Автор
Нельзя. Это разные понятия. Может быть только схожая символическая запись.
kkirsanov2
>Нельзя.
X = 1 и X = 1
В чем разница?
Alexander_IK Автор
Доказательство может включать в себя формулу. Формула может сама доказать что-то. Формула в отсутствии доказательства также будет иметь своё соответствие. Таким образом, принцип можно расширить как минимум на два "класса объектов": доказательства и формулы.
kkirsanov2
>Доказательство может включать в себя формулу.
А может и не включать?
Если доказательство без формулы будет переписано с формулой то означает ли это что исходно доказательство без формулы содержит формулу? Можно ли считать это одно и то же доказательство?
И ещё — расшифруйте пожалуйста «класс объектов» и опишите процедуру отнесения к ним на моем последнем примере — $X=1$ и X=1
Alexander_IK Автор
Это метафора на известные Вам термины. Флуд не поддерживаю. До свидания!
ov7a
https://en.wikipedia.org/wiki/Formula_for_primes
Alexander_IK Автор
Спасибо. Наиболее близкая формула из статьи- это формула по теореме Вильсона. Но она даёт последовательность простых чисел не по порядку, они перемежаются двойками без какой-либо закономерности. Внёс ещё уточнение: «нигде не нашёл математическую формулу вычисления простых чисел по порядку».
pavlushk0
Формулы, возвращающей n-ое простое число не существует.
Задание функции формулой и алгоритмом эквивалентны. Можно ещё таблицей функцию задавать.
Sirion
Формулы какого вида? В частично рекурсивных функциях формулу записать можно)