

Ученые из россйской ГК «Нейробиотикс» и Лаборатории нейробототехники МФТИ сумели воссоздать изображения по электрической активности мозга. Правда, речь идет только о работе с изображениями, на которые смотрит человек, чей мозг анализируется.
Собственно, восстанавливать геометрические фигуры, на которые смотрит человек в определенный момент времени, по электрической активности его нервных клеток — вовсе не самоцель. Главное — понять, как мозг шифрует информацию, которую мы затем храним многие годы (ну или минуты, что не менее важно).
Работа российских ученых пересекается с проектами зарубежных коллег. Но в большинстве случаев другие исследователи используют функциональную магнито-резонансную томографию или анализ электрических сигналов, которые получают с нейронов. У этих двух методов есть серьезные ограничения в использовании — в больнице или быту (не сейчас, конечно — в будущем).
Напротив, в работе отечественных специалистов используется электроэнцефалограмма, которая снимается с головы человека обычным образом. Затем полученные данные «скармливаются» специально обученной нейросети. В результате последняя определяет, на что сейчас смотрит испытуемый, и по конфигурации его электрического сигнала выстраивает геометрическую фигуру.
Эксперимент, который провели специалисты, состоял из двух частей. В первом использовались ролики из различных категорий, включая «абстракции», «водопады», «лица людей», «скорость». Так, ролики представляли собой видео, снятые от первого лица на снегоходах и других транспортных средствах. Продолжительность роликов составляла 10 секунд, сессия для каждого испытуемого продолжалась около 20 минут.
По итогу ученым удалось доказать, что конфигуация электрической активности мозга значительно отличается в зависимости от категории просматриваемых роликов.
После этого началась вторая стадия эксперимента. Для нее также были отобраны видео, уже не пяти, а трех категорий. Также во второй части эксперимента задействовали две нейросети. Одна из них формировала произвольные изображения из демонстрируемого «шума», вторая — генерировала «шум» из ЭЭГ. После этого обе нейросети объединили, обучив систему воспроизводить изображение по записанному прибором ЭЭГ.
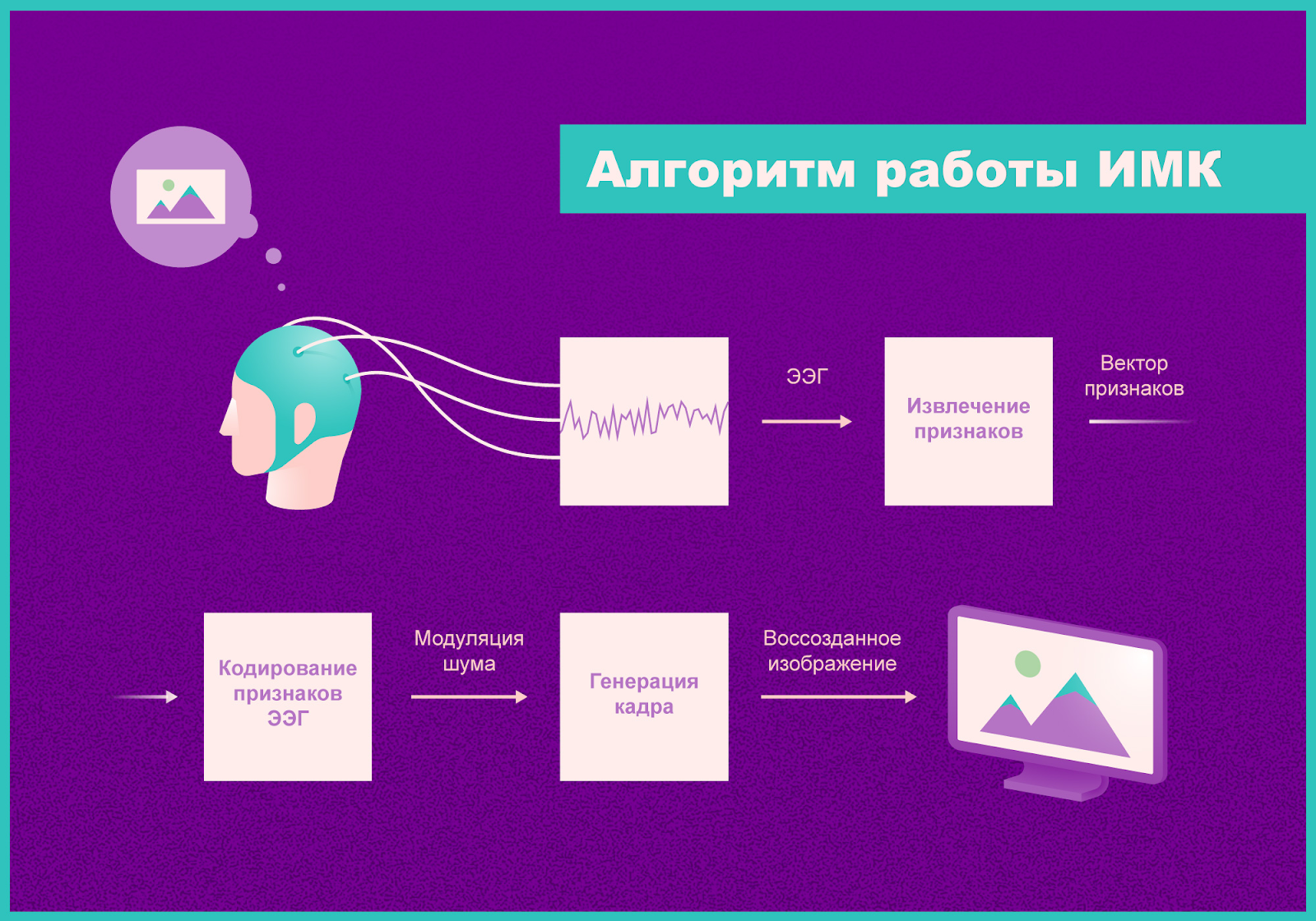
После этого добровольцам стали демонстрировать видео тех же категорий, записывая ЭЭГ. Сигнал в режиме реального времени отправлялся на обработку в двойную систему нейросетей. В итоге воспроизводилось изображение, которое в большинстве случаев относительно точно совпадало с оригиналом. В целом, задачей было не воспроизвести точно видео, а понять, к какой категории относится изображение, сгенерированное нейросетью. Это удалось сделать в 90% случаев.

«Энцефалограмма — следовой сигнал от работы нервных клеток, снимаемый с поверхности головы. Раньше считалось, что исследовать процессы в мозге по ЭЭГ — это все равно, что пытаться узнать устройство двигателя паровоза по его дыму. Мы не предполагали, что в ней содержится достаточно информации, чтобы хотя бы частично реконструировать изображение, которое видит человек. Однако оказалось, что такая реконструкция возможна и демонстрирует хорошие результаты. Более того, на ее основе даже можно создать работающий в реальном времени интерфейс “мозг — компьютер”. Это очень обнадеживает. Сейчас создание инвазивных нейроинтерфейсов, о которых говорит Илон Маск, упирается в сложность хирургической операции и то, что через несколько месяцев из-за окисления и естественных процессов они выходят из строя. Мы надеемся, что в будущем сможем сделать более доступные нейроинтерфейсы, не требующие имплантации» — заявил Григорий Рашков, один из авторов работы, младший научный сотрудник МФТИ и программист-математик компании «Нейроботикс».
Комментарии (34)


SADKO
18.10.2019 23:30-2Очередной приступ датасотонизма с натягиванием совы на глобус.
Речь не идёт о реконструкции изображения, а об определении его категории, причём не на основе самого изображения, а некоторых его свойств.
Ибо есть специфические отклики, на лица, на движение, контрастные линии, итд.
Кроме того, на низкочастотные колебания общей яркости, контраста, фокуса, так же регистрируются ВП.
И здесь интересно разве что применение генеративных методов, чтобы выявлять такие моменты.
Но реконструкция изображения, это знаете ли, как в том анекдоте про нейросеть неразличавшую танк и трактор, ибо критерием оказался цвет фона...

EndUser
18.10.2019 23:48+7На видеоиллюстрации забавны такие закономерности:
1.Гонки на любом устройстве в любой среде гражданином почти всегда воспринимаются через призму вождения автомобиля.
По-видимому, гражданин примеряет гонку на свой автомобиль.
2.Гражданин в этом автомобиле всегда ожидает увидеть зеркало заднего вида, хотя в исходном материале его нет.
По-видимому, гражданин редко в него смотрит, оно просто ему постоянно мешает чёрным пятном.
3.Всё незанятое время — когда гражданин отказывается воспринимать видеоряд — он увлечён «машиной Руди Голдберга» и сосредоточен на ней.
4.Если он обращает внимание на людей, то почему-то упорно думает о брюнетке с короткой стрижкой.
stranger_shaman
19.10.2019 02:03+9Не в гражданине дело. Сеть обучена по видео вождения автомобиля. Вот она и воспроизводит любой шум в категории «вождение» как то, что ей показывали.
Это не гражданин примеряет гонку на свой автомобиль, а нейросетка.
Тоже самое и с брюнеткой.

o-ranger
19.10.2019 19:52Для чистоты эксперимента картинку следовало бы показывать посредством VR-шлема, чтобы энцефалограмма не забивалась «шумом» от периферического зрения, в поле которого попадают лишние объекты возле монитора. Человек при этом должен лежать на удобной кушетке в расслабленном состоянии.

redpax
19.10.2019 00:21+24Хорошо, что на ютуб зашел почитать комментарии о том, что видео не соответствует реконструкции. Оказывается нейросеть определяет на какое из 5 видео похожа энцефалограмма и подставляет любое. Если хотите это можно назвать обманом ну или очень серьезной недоговоркой.

v1000
19.10.2019 11:34вот это больше похоже на правду. напоминает старый прикол с показом в браузере локальной директории на компе, который выдавался за хакерский взлом
DROS
19.10.2019 11:59+4дык это и без комментариев ютуба видно, что сетку гоняли на тех же видеороликах, что и показывают испытуемому. А дальше просто подгон категорий.
Короче — расходимся!
ThePretender
19.10.2019 12:01+5Правду лучше искать не на ютубе, а в оригинальной статье: www.biorxiv.org/content/biorxiv/early/2019/10/16/787101.full.pdf.
Чуваки обучили автоэнкодер и сетку, которая мапит выход ЭЭГ в пространство декодера. Да, декодер обучали на ограниченном датасете. Но и ЭЭГ, по словам авторов, может выдать максимум 6 категорий. Подход совершенно масштабируемый в двух направлениях:
1. Нужно обучать более сложную генеративную модель, пространство параметров которой сожет кодировать более широкий спектр «концепций» из реального мира.
2. Нужно создавать девайсы, которые будут получать от мозга данные в большем «разрешении».
При наличии новых достижений по этим двум направлениям подход из статьи с большой долей вероятности будет отлично масштабироваться вплоть до настоящего «восстановления» изображений из «мыслей».I-denis
19.10.2019 12:15+5Подход совершенно не масштабируемый, хотя бы по тому, что единственный способ повышение разрешения — насверлить дырок в черепе и разместить электроды непосредственно на зрительной коре. Что в принципе многократно и успешно делалось и позволило более менее разобраться в принципах работы именно зрительного участка коры.
По сути, примерно тоже самое — разместить антену вблизи разъема pci-express и попробовать восстановить поток видеоизображения индицируемого на монитореni-co
19.10.2019 12:30+1Хорошее сравнение. От себя добавлю, что в нем мы ещё не знаем где находится сам монитор. :)

uterr
20.10.2019 20:15На видео видно, что один и тот же видеоряд показывается для разных изображений, значит он так и делает, определяет, какое из видео наиболее похоже (я бы сказал, что это большой такой обман). Но не понятно тогда, почему выходное изображение такое артефактное — просто обработали вручную для большей правдоподобности? ну тогда вообще стыдно такое показывать

OtshelnikFm
19.10.2019 11:01Много раз ловил себя на мысли что нельзя оцифровать обрывки памяти из детства и круто было бы иметь подобную технологию. Это сейчас фотографировать можно на что угодно и это доступно.
Дожить бы до появления подобной технологии. Уж я бы отсканировал ))
thauquoo
19.10.2019 12:00+6Это далеко не восстановление образов. Эти образы были заранее известны нейросетке, которую обучали на них. То есть, если человек увидел что-то новое, то нейросетка не может это показать, она просто подбирает наиболее подходящее из того, что ей известно.
Сама идея исследования мне нравится, но вот подача результата похожа на кликбейт. Технически это можно с натяжкой назвать «восстановлением образов из мыслей», но это совсем не то, что подразумевают обычные читатели.
mapron
19.10.2019 13:32+1«Российские ученые обучили нейросеть классификации данных ЭЭГ в одну из 5 категорий. „
Да, тоже неплохо, но уже не так кликбейтно звучит =)
И я вообще не понимаю тех кто говорит что это масштабируется до реального зрения.
kvazimoda24
19.10.2019 14:11Меня одного смущает, что подопытному демонстрировали реконструированное нейросетью изображение? Не оказывало ли это изображение влияние на результаты эксперимента?

Alex_ME
19.10.2019 14:43В своей работе они делают акцент на то, что у них closed-loop. Но я просмотрел статью подиагонали, так что не понял, зачем.
Alex_ME
19.10.2019 14:42+3Как я понял, сначала они натренировали автоэнкодер, потом натренировали вторую сеть переводить ЭЭГ в latent space автоэнкодера. А автоэнкодер, в свою очередь, генерирует какое-то изображение.

palexisru
19.10.2019 20:58В развитие темы — можно синтезировать случайные демонстрируемые изображения и на них тренировать распознавание ЭЭГ. Тогда количество образов должно повыситься и останется наращивать качество.
Psionic
19.10.2019 22:08+1А нейросеть-опознавальщик натягивается на конкретного испытуемого? Или в принципе переносима на других без проблем? Энцефалит или атеросклероз влияют на результат?

Vsevo10d
19.10.2019 22:55Могу рассказать, как работала моя собственная нейросеть, с минимумом исходных данных — я практически сразу полез смотреть видео, глянув текст по диагонали:
— Хмм, ну и лаги.
— Картинка с ралли показывает, что ЭЭГ видит отличие светлых областей от темных, пожалуй и все.
— Машина Голдберга показана в правильных цветах, но пятна совсем хаотичные. Интересно, при таких ФПС, как у этой картинки в реальном времени, учитываются саккадные движения глаза для построения изображения? Может, фреймы выхватываются в неудачные моменты, когда глаз направлен не в центр изображения, и суммарное изображение такое грязное?
— Лицо — ну да, как и ралли. Светлое отличается от темного. Стоп, что?? Один фрейм выглядит как реалистичное женское лицо! Так, подождите! Смена усатого мужика на блондинку не дала вообще никакой разницы, а при этом один из кадров лица был очень детализированным! Что-то нечисто…
— Водный мотоцикл лагает картинкой лица, а потом четко переключается на ралли! Нет, это не распознавание ЭЭГ в реальном времени, это распознавание заданного пресета из видеороликов. Наверное, нейросеть генерирует их на основе входных пресетов-роликов и данных ЭЭГ?
— Ну да, снегоход — это ралли, машина Голдберга — тоже. Кликбейт такой кликбейт.
*дропнул видео на 1:50*
*полез в каменты — с облегчением увидел, что люди это тоже поняли*

stalinets
20.10.2019 02:24А я помню, лет 5 назад была такая новость, делали то же самое. И даже реалтайм-видео из глаз удавалось снимать, конечно, очень плохого качества.
Всегда интересовало, какой же там «протокол». Какая «модуляция».
Как электрически сформировать сигнал и подать его на глазной нерв, чтобы мозг увидел видео?
Подавать, видимо, придётся сразу по каждому нерву из пучка, идущего от глаза, свой кусочек общей картины.
А что передаётся по каждому из нервов пучка? Там аплитудная модуляция по яркости? Тогда почему мы не видим световые шумы от электромагнитных полей и не слышим радиоволны, они же должны наводиться на нервы?agat000
20.10.2019 05:28подавать на нерв не получится, там идёт шлейф из 1М каналов, от каждого пиксела. Плюс — глаз собирает картинку сканированием, в движении. В недавней статье про глаза и мегапиксели очень хорошо описан весь наворот наших гляделок.
Получается, что подавать изображение можно только после блока первичной обработки изображения, где оно используется в понятном виде.

eksamind
20.10.2019 15:56Надеюсь, что технология никогда не стрельнет, а то придется медитировать при виде встрече с копами) и так это осталось единственным местом, где, принекоторой сноровке, можно остатся без назойливого внимания корпораций и государств.

ProgrammerForever
20.10.2019 17:27Это же не реконструкция, это пока классификация.
1) Взять 100 фраз
2) Посчитать md5
3) Взять один из md5
4) Добавить шума и искажений
5) Посмотреть на какой из 100 он похож больше всего
6) Сделать вывод, что мы теперь можем расшифровывать md5
Идея классная, но нужен датасет пожирнее
brrr
Если честно, то это офигенно! Вот оно будущее, а ни эти ваши айфоны. Надеюсь, что такие технологии пойдут для развития человечества, а не его дрессировки.
gotch
Так первая потребительская технология и появится в айфоне. Будете подтверждать операции интенсивно думая "оплатить".
Psychosynthesis
«Чёрт, я же имел ввиду отменить! Отменить, отменить, пожалуйста отмените!»
fireSparrow
Технология не взлетит. Современная система потребления наоборот всячески старается избежать того, чтобы клиент интенсивно думал в момент оплаты.
Keynessian
Перелогиньтесь товарищ майор!
Xtray, вы хотели сказать психопаспорт?