
В VK есть группа со следующим описанием:
Одна и та же фотография каждый день вручную сохраняется на компьютер и снова заливается, постепенно теряя в качестве.
Слева исходная картинка, загруженная 7 июня 2012, справа — какая она сейчас.
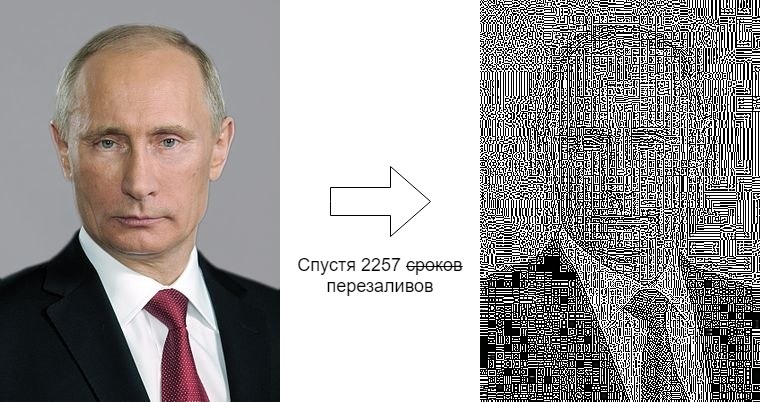
Такая разница очень подозрительна. Попробуем разобраться, что происходило в течение этих 7 лет. Для ознакомления есть статья на Медузе про эту группу, но нас будет интересовать только техническая сторона.
Почему и на каком этапе JPEG сжимает с потерями
Рассмотрим сильно упрощенную схему кодирования и декодирования JPEG. Показаны только те операции, которые иллюстрируют основные принципы алгоритма JPEG.

Итак, 4 операции:
- DCT — дискретное косинусное преобразование.
- Квантование — округление каждого значения до ближайшей величины, кратной шагу квантования: y = [x/h]*h, где h — шаг.
- IDCT — обратное дискретное косинусное преобразование.
- Округление — обычное округление. Этот этап можно было не показывать на схеме, так как он очевиден. Но далее будет продемонстрирована его важность.
Зеленым цветом выделены операции, сохраняющие всю информацию (не принимая во внимание потери при работе с числами с плавающей запятой), розовым — теряющими. То есть, потери и артефакты появляются не из-за косинусного преобразования, а из-за простого квантования. В статье не будет рассматриваться важный этап — кодирование Хаффмана, так как оно выполняется без потерь.
Рассмотрим эти шаги подробнее.
DCT
Так как существует несколько вариаций DCT, то на всякий случай уточню, что JPEG использует DCT второго типа с нормализацией. При кодировании каждое изображение разбивается на квадраты 8x8 (для каждого канала). Каждый такой квадрат можно представить в виде 64-мерного вектора. Косинусное преобразование заключается в нахождении координат этого вектора в другом ортонормированном базисе. Сложно визуализировать 64-мерное пространство, поэтому далее будут приведены 2-мерные аналогии. Можете представлять, что картинка разбивается на блоки 2x1. На графиках, которые будут продемонстрированы далее, оси x соответствуют значения первого пикселя блока, оси y — второго.
Продолжая аналогию на конкретном примере, допустим, что значения двух пикселей из исходного изображения — 3 и 4. Нарисуем вектор (3, 4) в исходном базисе, как показано на рисунке ниже. Исходный базис отмечен синим цветом. Координаты вектора в некотором новом базисе — (4.8, 1.4).
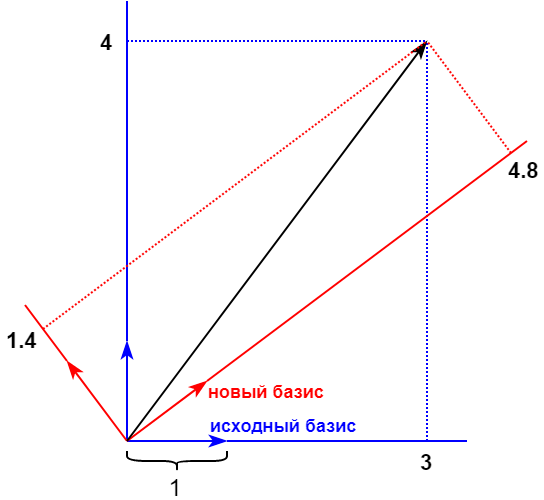
В рассмотренном примере новый базис был выбран случайно. DCT же предлагает вполне конкретный 64-мерный фиксированный базис. Обоснование того, почему в JPEG используется именно он, очень интересно, и описывалось мной в другой статье. Затронем лишь суть. В целом значения всех пикселей равноценны. Но если преобразовать их с помощью DCT, то из получившихся 64 координат в новом базисе (называемых коэффициентами DCT-преобразования) мы можем смело обнулить или грубо округлить их некоторую часть, получив минимальные потери. Это возможно благодаря особенностям сжимаемых изображений.
Квантование
В файле нельзя сохранить дробные значения. Поэтому, в зависимости от шага квантования, значения 4.8, 1.4 будут сохранены так:
- при шаге 1 (самый щадящий вариант): 5 и 1,
- при шаге 2: 4 и 2,
- при шаге 3: 6 и 0.
Обычно шаг выбирается разный для каждого значения. В JPEG-файле есть как минимум один массив, называемый таблицей квантования, хранящий 64 шага квантования. Эта таблица зависит от качества сжатия, задаваемое в любом графическом редакторе.
IDCT
То же самое, что DCT, но с транспонированным базисом. Математически, x = IDCT(DCT(x)), поэтому если бы не было квантования, то можно было бы восстанавливать без потерь. Но не было бы и сжатия. Из-за использования квантования исходный вектор не всегда можно вычислить точно. На следующем рисунке представлены 2 примера с точным и неточным восстановлением. Наклонной сетке соответствует новый базис, прямой — исходный.
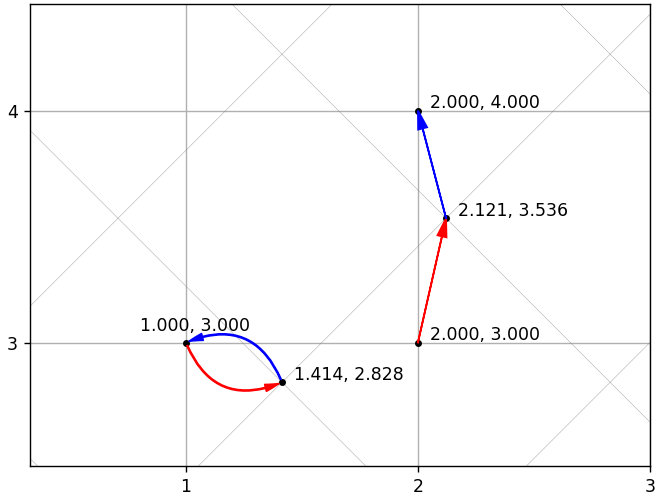
Возникает очевидный вопрос: может ли последовательность перекодирований привести к вектору, сильно отличающегося от исходного? Может.

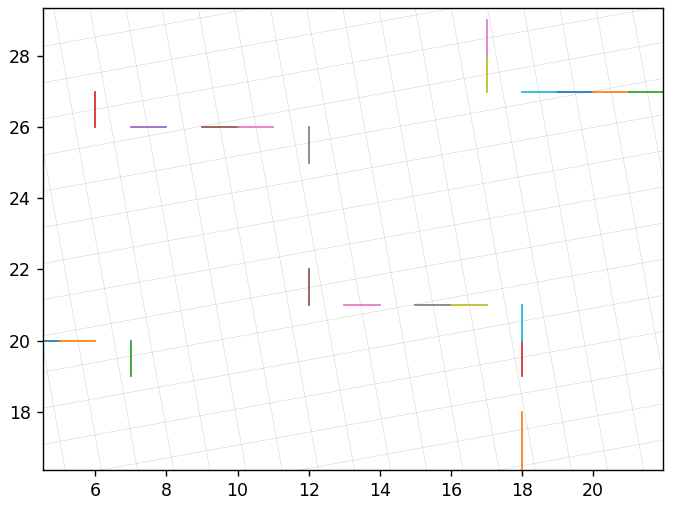
Интересно было бы перебрать все целочисленные векторы и посмотреть, к чему приведет их перекодирование. Для уменьшения информационного шума, уберем сетку исходного базиса и будем напрямую соединять отрезками исходные и восстановленные векторы (без промежуточного шага). Сначала рассмотрим шаг квантования равный 1 для всех координат. Новый базис на следующем рисунке повернут на 45 градусов и для него имеем 17.1% неточных восстановлений. Цвета отрезков ничего не означают, но они будут полезны для предотвращения их визуального слияния.

Этот базис — на 10.3 градусов с 7.4% неточных восстановлений:

Вблизи:
А этот — на 10.4 с 6.4%:

19 градусов с 12.5%:

А вот если задать шаг квантования больше 1, то восстановленные векторы начинают явно концентрироваться близко к узлам сетки. Это шаг 5:
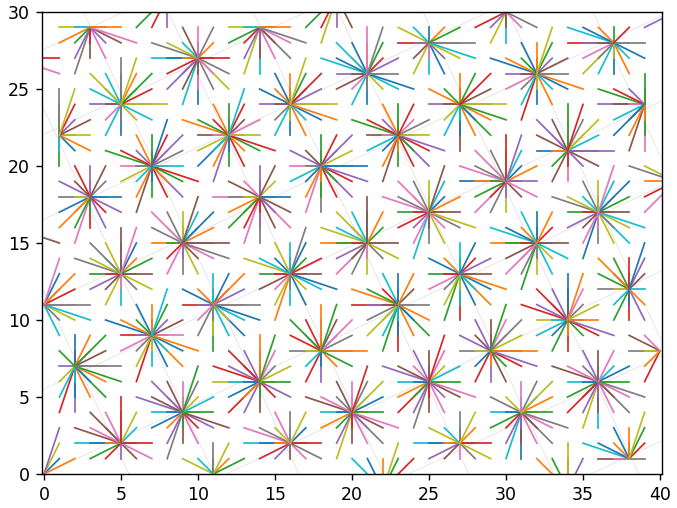
Это 2:

Если изображение перекодировать несколько раз, но с одинаковым шагом, то почти ничего не произойдет по сравнению с однократным перекодированием. Значения как бы «застревают» в узлах сетки и уже не могут «выпрыгнуть» оттуда в другие узлы. Если же шаг разный, то вектор будет «скакать» из одного узла сетки в другой. Это может завести его как угодно далеко. На следующем рисунке показан результат 4 перекодирований с шагами 1, 2, 3, 4. Можно разглядеть крупную сетку с шагом 12. Это значение — наименьшее общее кратное 1, 2, 3, 4.

А на этом — с шагами от 1 до 7. Визуализация показана только для части исходных векторов, чтобы улучшить наглядность.
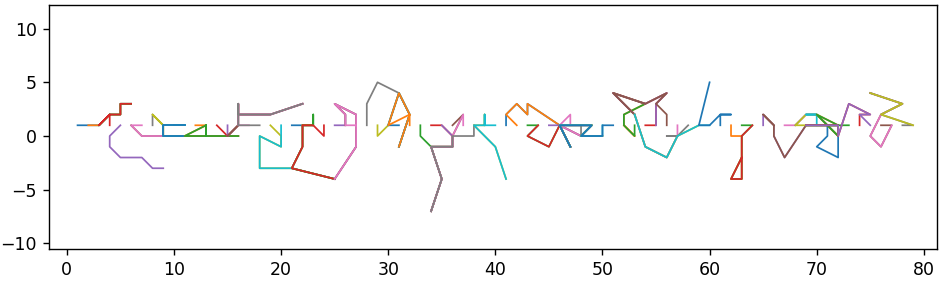
Округление
А зачем округлять значения после IDCT? Ведь если избавиться от этого этапа, то восстанавливаемое изображение будет представлено дробными значениями, и мы ничего не потеряем при повторном кодировании. С математической точки зрения, мы будем просто переходить от одного базиса к другому без потерь. Здесь необходимо упомянуть о преобразовании цветовых пространств. Хотя JPEG не регламентирует цветовое пространство и позволяет сохранять непосредственно в исходном RGB, но в подавляющем количестве случаев используется предварительная конвертация в YCbCr. Особенности глаза и все такое. А такая конвертация тоже приводит к потерям.
Предположим, мы получили JPEG-файл, сжатый с максимальным качеством, то есть с шагом квантования 1 для всех коэффициентов. Мы не знаем, какой кодек был использован, но обычно кодеки выполняют округление после преобразования RGB -> YCbCr. Так как качество максимально, то после IDCT мы получим дробные, но довольно близкие значения к исходным в пространстве YCbCr. Если округлим, то большинство из них восстановятся в точности.
Но если не округлим, то из-за таких небольших отличий преобразование YCbCr -> RGB может еще больше отдалить их от исходных значений. При последующих перекодированиях разрыв будет увеличиваться все больше. Чтобы хоть как-то визуализировать этот процесс, воспользуемся методом главных компонент для проецирования 64-мерных векторов на плоскость. Тогда для 1000 перекодирований получим примерно такую последовательность изменений:

Абсолютные значения осей здесь не имеют особого смысла, но по относительным можно оценить существенность искажений.
Примеры многократного перекодирования
Исходный кот:

После одного пересохранения с качеством 50:

После любого последующего количества перекодирований с тем же качеством картинка не меняется. Теперь будем плавно снижать качество с 90 до 50 через 1:

Произошло примерно то же, что и на уже приводимом графике:
После одного пересохранения с качеством 20:

Плавно с 90 до 20:

Теперь 1000 раз со случайным качеством от 80 до 90:

10000 раз:

Анализ картинок группы VK
Приступим к анализу более 2000 картинок из группы VK. Сначала проверим среднее абсолютное отклонение от самой первой. По оси x — номер картинки (или день), по y — отклонение.
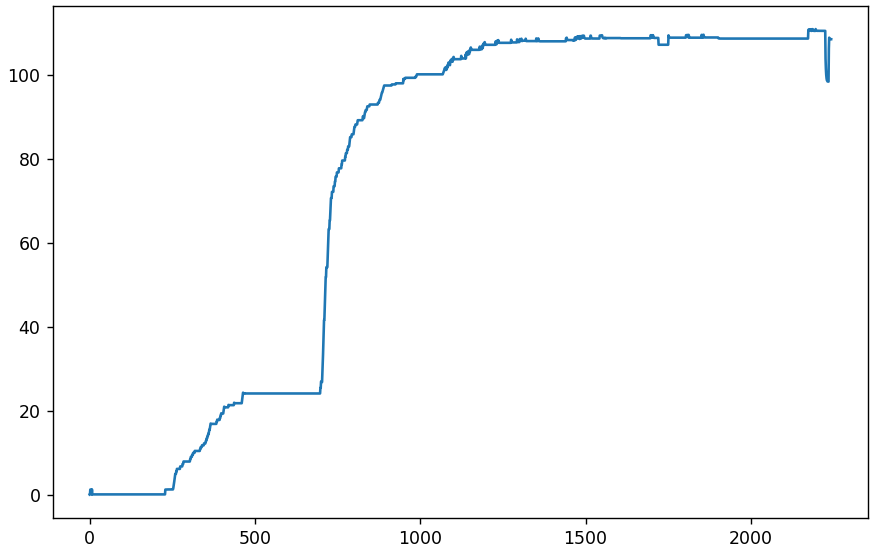
Перейдем к дифференциальному графику, показывающему среднее абсолютное отклонение соседних картинок.

Небольшие колебания в начале — нормальное явление. До 232-й все идет хорошо, картинки полностью идентичны. А 233-я внезапно отличается в среднем на 1.23 для каждого пикселя (по шкале от 0 до 255). Это много. Возможно просто изменились таблицы квантования. Проверим. А заодно сравним с размером получаемых файлов.
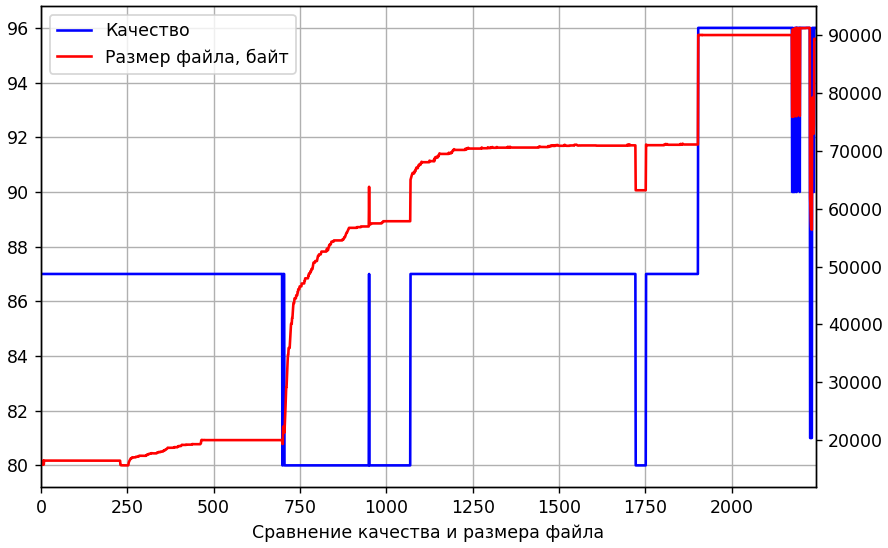
Да таблицы менялись. Но не раньше чем у 700-х. Тогда, возможно, происходило промежуточное скрытое перекодирование с низким качеством. Попробуем дважды перекодировать 232-ю. Для первого раза будем перебирать различные уровни качества, а для второго используем ту же таблицу квантования, что и для всех от 1-й до 700-х. Наша цель — получить картинку максимально похожую на 233-ю. На следующем рисунке по оси x — качество промежуточного перекодирования, по y — среднее абсолютное отклонение от 233-й.
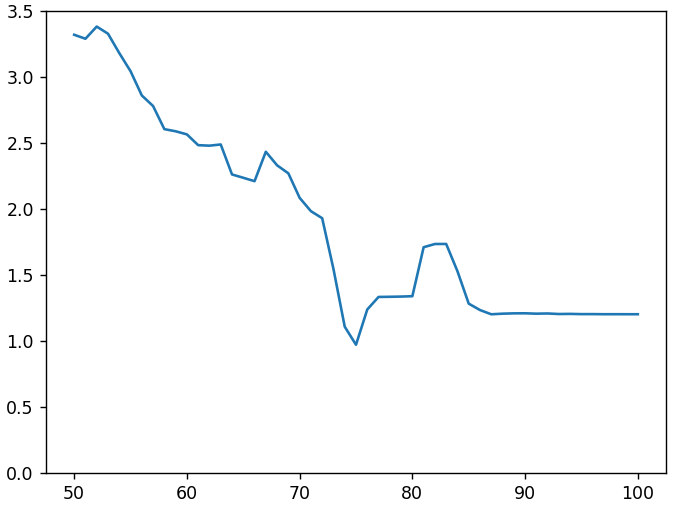
Хотя на графике и есть провал при качестве 75%, примерно равный 1, но все еще далеко от желаемого нуля. Добавление 2-го промежуточного этапа и изменение параметров субдискретизации (subsampling) не улучшило ситуацию.
С остальными картинками все примерно то же самое, плюс еще накладывается изменение таблиц квантования. То есть, в какой-то момент картинка резко меняется, затем за несколько дней стабилизируется, но только до тех пор, пока не происходит новый всплеск. Возможно, происходит изменение самого изображения на серверах. Не могу полностью исключить и причастность администратора группы.
К сожалению, я так и не выяснил, что же действительно происходило с изображением. По крайней мере, теперь уверен, что это было не просто пересохранение. Но, самое важное, стал лучше представлять происходящие процессы при кодировании и декодировании. Надеюсь, что и вы тоже.
Архив с картинками, для самостоятельного исследования.
Комментарии (91)

alkoro
29.10.2019 13:48Знакомый
Тимурспрашивает: Есть видео с 2257-ю кадрами преобразования сабжа?
ice2heart
29.10.2019 13:56+2https://ice2heart.com/doomguy.mp4
Тут что-то около тысячи преобразований.
GCU
29.10.2019 15:00Progressive JPEG «наоборот».
Прикольно что даже на макроблоках потеряли цвет.ice2heart
29.10.2019 15:32Я немножко с читерил я изменял размер изображения. gist.github.com/ice2heart/7206ce3771ac3dcf95f6c4d071c0e4a0 так оно «зашакливается» лучше.
Dim0v
29.10.2019 17:46Если была цель скомпенсировать изменения размера, то вместо умножения на 0.8 стоило делить на 1.2. Сейчас там изображение становится в среднем на 2% меньше с каждым преобразованием (1.2 * 0.8 = 0.96).
Ну и по видео очень заметно, что разрешение очень быстро упало за первые секунд 5 и причина явно не в jpeg.
ice2heart
29.10.2019 17:54С размерами я и правда лопухнулся. Но насчет того что качество упало не из-за jpeg, моей целью было ухудшить изображение, так что алгоритм работает достаточно хорошо.



slg
29.10.2019 15:15+2А если Чака Норриса перезаливать?

vlreshet
29.10.2019 15:18+8То качество будет улучшаться, а в конце получится 3D модель с огромным dpi

sumanai
29.10.2019 19:40Боюсь, на 9000 шаге пользователю не удастся скачать файл, не хватит места.
solovetski
31.10.2019 20:59>Боюсь, на 9000 шаге пользователю не удастся скачать файл, потому что файл с Чаком сам скачает пользователя.
fixed!
denisshabr
29.10.2019 15:28Интересно, что будет, если после распаковки Jpeg использовать различные алгоритмы улучшения Jpeg, deblock и прочее?
Наприемр Topaz JPEG to RAW AI. Ведь была даже идея встроить такие штуки в стандарт декодера, и что-то похожее на это реализовали в h264, in-loop deblocking, и ещё что-то более сильное в h265.Arqwer
29.10.2019 16:03Хм, некоторая информация будет теряться, но потерянную информацию будут додумывать алгоритмы улучшения. Я подозреваю, что если восстанавливать будет нейронка, то после миллиона итераций будет качественное, фотореалистичное лицо, но другого человека.



moth-in-relay
29.10.2019 15:33Что станет с видео, если его перезаписать 20 раз на видеокассетах:
www.youtube.com/watch?v=G8GOcB6H0uQ
bodqhrohro
30.10.2019 16:37Плохой пример, тут то ли видак плохо трекинг держит, либо исходная кассета уже изношенная — из-за раздваивания контуров видео быстро в кашу превратилось. Вот перезаписи покачественнее, тут долго издевались:
PAL (если не открывается из-за копирастов — дубль)

dka700
29.10.2019 15:39+1Вот забугорный блогер перезаливает видео на YouTube 1000 раз.
https://youtu.be/JR4KHfqw-oE

Keynessian
29.10.2019 15:44А mp3 после многократного перекодирования как звучит?

S-trace
29.10.2019 15:46Иллюстрация к пункту «Почему и на каком этапе JPEG сжимает с потерями» не совсем правильная. «Восстановленное» изображение должно быть покрыто JPEG-артефактами.
BkmzSpb
29.10.2019 16:02Минутка наркомании, не судите строго: я не смог быстрым поиском найти информацию о JPEG-инвариантных изображениях (изображения, которые не меняются в результате однократного сжатия/восстановления). Если предположить, что таковые существуют, то для них верно (примерно) следующее:
I = JPEG-1(JPEG (I))
Можно пойти дальше: ПустьI0 — исходное изображение. Строим последовательностьIn= JPEG-1(JPEG(In-1)). Существует ли такое неотрицательное конечноеN, что для любогоn > N:In+1= In= J, гдеJ— инвариантный JPEG-образ исходного изображения? Единственнен ли такой образ если он существует? Является ли он нетривиальным (отличается ли от равномерно-залитого прямоугольника, например). Можно ли найти простое преобразование изI0 вJи использоватьJкак исходное изображение, которое не будет меняться при сжатии/восстановлении JPEG (хотя бы при каком-то фиксированном наборе параметров), но при этом для человека будет слабо отличаться от исходного?
sim31r
30.10.2019 00:53(отличается ли от равномерно-залитого прямоугольника, например)
Предположу что это любая сетка пикселей 8*8 пикселей с однородной заливкой, которые являются неким базисом для сжатия. В том числе прямоугольники кратные 8 пикселям, и с привязкой к сетке пикселей кратным 8.
Norno
31.10.2019 16:49Вообще в JPG применяется дискретное косинусное преобразование, фактически раскалывается на следующие паттерны с коэффицентами
Заголовок спойлера

VasikAlexey
29.10.2019 16:25Так и как заставить камеру смартфона и клиент ВК пользоваться форматами и алгоритмами сжатия без потерь? На первое ответ raw, на второе не нашёл пока)
FTOH
29.10.2019 17:11+1Вк все фотографии конвертирует в jpeg. Только через документы можно отправить без сжатия.
sim2q
29.10.2019 16:47Спасибо!
Теперь кажется понятно, почему фотошоп настойчиво предлагает сохранить «в том же качестве» по умолчанию. Надеюсь, что именно для уменьшения ошибок.
ps отдельное спасибо и за статью по ссылке, пришлось предварительно тоже прочитать. Интересуюсь давно, но так и не осилил разобраться. Хотелось на основе готовых таблиц из jpeg файла извлекать какой-нибудь pHash без декодирования всей картинки.
EviGL
29.10.2019 17:38+1Я разочарован, что внутри статьи какие-то фотки кота, вместо Путина.
По крайней мере нижнюю часть статьи, где анализируется вкшный феномен, стоило бы проиллюстрировать получившимся у вас результатом и результатом, получившимся в группе.
А круче видео сделать, да.
Fil Автор
29.10.2019 18:50Добавил видео под КДПВ. Кот, потому что не хотел еще больше триггеров. Да и это не так уж важно. Если пересохранять с тем же качеством, что и у картинок Путина, то визуально не будет заметно разницы от исходной. А в группе VK есть почему-то.
EviGL
29.10.2019 18:56Спасибо, с видео и графики понятнее, график отклонения явно читается на видео.
А на вопрос причин, я ставлю на то, что администратор группы просто решил разнообразить контент. Даже видны конкретные моменты, когда он внёс одно искажение в алгоритм и когда внёс второе.
P.S. Осталось сопоставить даты внесения искажений и проверить, не проходило ли в те дни каких-либо [минутка заботы НЛО].

Gamliel_Fishkin
29.10.2019 23:13+1

gnomeby
29.10.2019 18:45+1К сожалению, я так и не выяснил, что же действительно происходило с изображением.
Может быть это был просто PrintScreen области экрана с последующим сохранением?
Don_Koton
30.10.2019 06:40Кстати такой эффект часто бывает когда картинке в каком-нибудь простейшем графическом редакторе выкручивают показатель «чёткость» на максимум
ClearAirTurbulence
30.10.2019 15:02Ну это потому что имеющиеся артефакты этой самой четкостью делаются очевиднее.

NP447
29.10.2019 19:31+1К сожалению, я так и не выяснил, что же действительно происходило с изображением
возможно, происходит изменение самого изображения на серверах
Именно происходит изменение изображения на vk-сервере. При приёме изображения от пользователя его немного ужимают с потерей качества, а также преобразуют PNG и GIF в JPEG и уменьшают размер изображения до 2048 по большей стороне, если таковой был превышен. Именно по причине обработки изображения на сервере в vk не работает такая вещь, как rarjpeg.
Но это всё если загружать картинку в раздел фотографий. Если же загружать картинку как документ, то её обработки не происходит, можно загружать картинки размером больше чем 2048х2048, rarjpeg работает.
S-trace
29.10.2019 20:00Немного напомнило, кстати, видео «What I saw before the darkness».
Хотя, конечно, не настолько жесть…
we1
29.10.2019 20:02Давно мучает вопрос: есть ли в JPEG-файле запись с каким качеством было сделано сжатие или это вычисляется на основе каких-то данных при декодировании? И если это просто записанное число, то какой стандарт описывает какое число нужно сохранять, чтобы все остальные поняли как было сделано сжатие?
Fil Автор
29.10.2019 20:08Да, есть, это таблицы квантования. Если упрощенно, то если исходный коэффициент был 13, а шаг квантования 5, то в файле сохранится шаг и число 3 (потому что [13/5] = 3). Декодер умножит 3 на 5 и получит 15 (а не 13).
aleksandros
29.10.2019 21:54Во всём этом самое непонятное — зачем ВК пережимает и без того маленькую по разрешению и по размеру фотку?
andreishe
29.10.2019 23:54Я думаю, они пережимают просто все фотки без разбора. Вероятно, не в последнюю очередь, чтобы гарантированно избавиться от всякого лишнего (типа rarjpg), что может быть добавлено в нагрузку к картинке.
akhkmed
30.10.2019 00:49+1Потрясающая эта и предыдущая статья про jpeg.
Подскажите, существует ли простой способ поместить в jpeg обратное кусочное DC- преобразование произвольного бинарного файла так, чтобы оно пережило несколько пересохранений подряд с возможностью восстановления содержимого файла? И как мог бы выглядеть такой "рисунок"?sim31r
30.10.2019 00:56+2QR код например?
tbl
30.10.2019 11:57Уже пробовали так стеганографировать: Хватало 5-7%-маски по обоим цветоразностным каналам (глаз острее воспринимает изменение яркости, чем цвета), и ресайзить так, чтобы 1 «пиксель» qr-маски покрывал кратные 8x8-блоки изображения (8х8, 8х16, 16х16, ...). Исходная информация восстанавливалась, имея оригинал изображения, даже со скриншота экрана монитора на телефон. Двойное слепое тестирование показало: человек не видит, что в картинке хранится какая-то другая информация.
DistortNeo
30.10.2019 13:42В случае бесконечного числа пережатий это невозможно. Можно подобрать такую последовательность коэффициентов сжатия, что последовательные округления занулят любые значения.
xDimaRus
30.10.2019 00:50+3Когда я услышал про этот эксперимент с фоткой пу думал вот оно пробитие дна. А нет, сейчас понял что ошибался )))
tbl
30.10.2019 01:07+1Хм, интересное представление процесса DCT, спасибо. В институте мы изучали его только со стороны преобразования Фурье как оператора свертки, где в 2-мерном случае можно выкинуть синусы и оставить только косинусы (ну или наоборот синусы, просто с косинусами работать проще). Ни разу не задумывался, что DCT/IDCT можно представить, как оператор трансляции базиса в 64-мерном пространстве.
Miritvorech
30.10.2019 07:30+1Потрясающе! Вашу бы энергию да на благое дело!)))
А статья действительно интересная, продолжай!)

SantaCluster
30.10.2019 14:40продолжайте пересохранять дальше. примерно через тыщщи полторы пересохранений фотка начнёт улучшаться. как и вся жизнь в этой стране. :)
А если серьёзно, продолжайте писать о новых экспериментах с изображениями (с точки зрения работы алгоритмов), очень интересно







token
А почему в подвале топика нет блока со словами "Минутка заботы об нло?"
Fil Автор
Надеюсь, не понадобится :) Поставить плашку может только редакция, кажется
vlreshet
Сейчас пойдёт по всем жёлтым СМИ «ШОК! Айтишники попытались сжать путина!»
tvr
Nikoobraz
elenagra
В котика же!
RiseOfDeath
Видимо имеется ввиду измерение степени сжатия JPEG в @бучих шакалах.
edwardspec
И внесут «Законопроект о запрете применения формата JPEG к фотографиям представителей власти»
NetBUG
Бедные дурналисты…
timoteo_cirkla
Вы эту приставку не к тем применили. Не журналисты у нас принимают дурные законы, предварительно нюхнув кокса.
tbl
Независимые журналисты у нас не являются 5-ой ветвью власти (в отличие от дурналистов, которые срастились с остальными ветвями), а 5-ой колонной (бьющей в набат), которую пытаются всеми силами выдавить с информационного поля, т.е. все выглядит ровно наоборот.
token
Мне кажется сабж — типа гидрашки. Плотность сильно большая, не сжимается.
Nalivai
И немедленно двушечка
tvr
Наверное потому, что НЛО в заботе не нуждается — оно само есть воплощенная забота.