

Схема компьютера CS-1 показывает, что большая часть отведена для питания и охлаждения гигантского «процессора-на-пластине» Wafer Scale Engine (WSE). Фото: Cerebras Systems
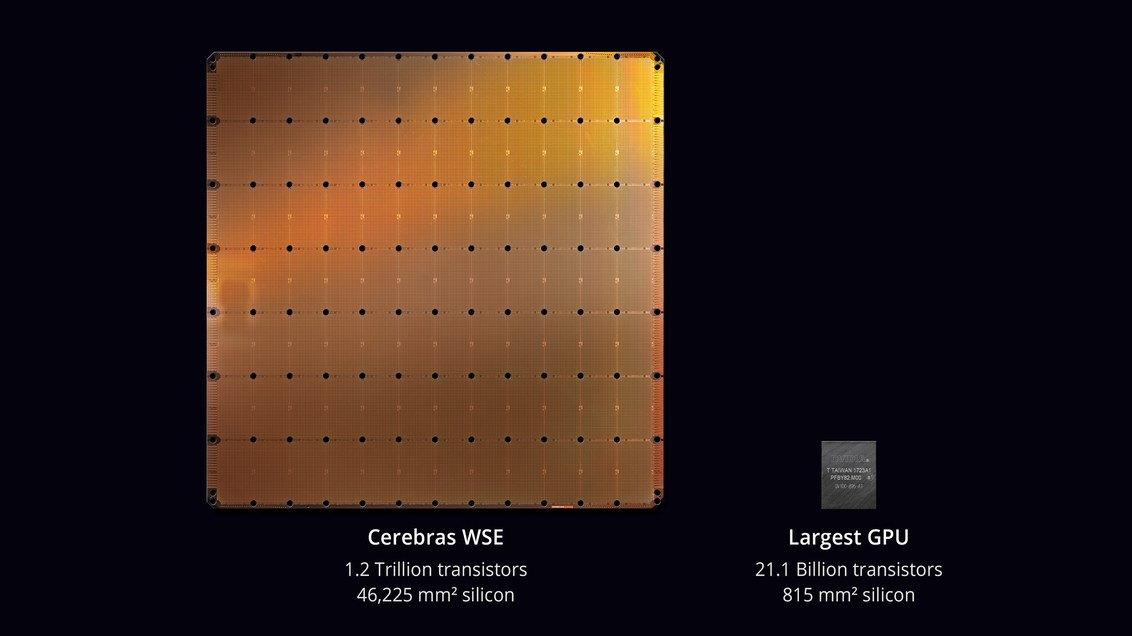
В августе 2019 года компания Cerebras Systems и её производственный партнер TSMC анонсировали крупнейшую микросхему в истории компьютерной техники. С площадью 46 225 мм? и 1,2 триллиона транзисторов микросхема Wafer Scale Engine (WSE) примерно в 56,7 раз больше, чем самый большой GPU (21,1 млрд транзисторов, 815 мм?).
Скептики говорили, что разработать процессор — не самая сложная задача. Но вот как он будет работать в реальном компьютере? Каков процент брака на производстве? Какое потребуется питание и охлаждение? Сколько будет стоить такая машина?
Похоже, инженерам Cerebras Systems и TSMC удалось решить эти проблемы. 18 ноября 2019 года на конференции Supercomputing 2019 они официально представили CS-1 — «самый быстрый в мире компьютер для расчётов в области машинного обучения и искусственного интеллекта».
Первые экземпляры CS-1 уже отправлены заказчикам. Один из них установлен в Аргоннской национальной лаборатории министерства энергетики США, той самой, в которой скоро начнётся сборка самого мощного в США суперкомпьютера из модулей Aurora на новой архитектуре GPU от Intel. Другим заказчиком стала Ливерморская национальная лаборатория.
Процессор с 400 000 вычислительными ядрами предназначен для дата-центров по обработке вычислений в области машинного обучения и искусственного интеллекта. Cerebras заявляет, что компьютер обучает системы AI на порядки эффективнее, чем существующее оборудование. CS-1 по производительности эквивалентен «сотням серверов на базе GPU», потребляющих сотни киловатт. В то же время он занимает всего 15 юнитов в серверной стойке и потребляет около 17 кВт.
Процессор WSE. Фото: Cerebras Systems
Генеральный директор и соучредитель Cerebras Systems Эндрю Фельдман (Andrew Feldman) говорит, что CS-1 является «самым быстрым в мире компьютером AI». Он сравнил его с кластерами TPU от Google и отмечает, что каждый из них «занимает 10 стоек и потребляет более 100 киловатт, чтобы обеспечить треть производительности одной установки CS-1».

Компьютер CS-1. Фото: Cerebras Systems
Обучение больших нейронных сетей может занимать недели на стандартном компьютере. Установка CS-1 с процессорным чипом из 400 000 ядер и 1,2 триллиона транзисторов выполняет эту задачу за минуты или даже секунды, пишет IEEE Spectrum. Однако Cerebras не представила реальные результаты тестов, чтобы проверить заявления о высокой производительности, например, тесты MLPerf. Вместо этого компания напрямую установила контакты с потенциальными клиентами — и позволила обучать собственные модели нейронных сетей на CS-1.
Такой подход не является чем-то необычным, считают аналитики: «Каждый управляет своими собственными моделями, которые они разработали для своего собственного бизнеса, — говорит Карл Фройнд (Karl Freund), аналитик по приложениям искусственного интеллекта в Moor Insights & Strategies. — Это единственное, что имеет значение для покупателей».
Разработкой специализированных чипов для AI занимаются многие компании, в том числе традиционные представители индустрии, такие как Intel, Qualcomm, а также различные стартапы в США, Великобритании и Китае. Google разработала чип специально для нейронных сетей — тензорный процессор, или TPU. Несколько других производителей последовали её примеру. Системы AI работают в многопоточном режиме, а узким местом становится перемещение данных между чипами: «Соединение микросхем на самом деле замедляет их — и требует много энергии, — объясняет Субраманьян Айер (Subramanian Iyer), профессор Калифорнийского университета в Лос-Анджелесе, который специализируется на разработке чипов для искусственного интеллекта. Производители оборудования изучают множество различных вариантов. Некоторые пытаются расширить межпроцессорные соединения.
Основанный три года назад стартап Cerebras, который получил более $200 млн венчурного финансирования, предложил новый подход. Идея в том, чтобы сохранить все данные на гигантском чипе — и тем самым ускорить вычисления.

Вся пластина-микросхема разделена на 400 000 более мелких секций (ядра), с учётом того, что некоторые из них не будут работать. Чип разработан с возможностью маршрутизации вокруг дефектных областей. Программируемые ядра SLAC (Sparse Linear Algebra Cores) оптимизированы для линейной алгебры, то есть для вычислений в векторном пространстве. Компания также разработала технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение. Векторы и матрицы в векторном пространстве обычно содержат множество нулевых элементов (от 50% до 98%), поэтому на традиционных GPU большая часть вычислений уходит впустую. В отличие от них, ядра SLAC предварительно отфильтровывают нулевые данные.
Коммуникации между ядрами обеспечивает система Swarm с пропускной способностью 100 петабит в секунду. Маршрутизация аппаратная, задержки измеряются в наносекундах.
Стоимость компьютера не называется. Независимые эксперты считают, что реальная цена зависит от процента брака. Также достоверно не известна производительность микросхемы и сколько ядер работоспособны в реальных образцах.
Программное обеспечение
Cerebras огласила некоторые подробности о программной части системы CS-1. Программное обеспечение даёт возможность пользователям создавать собственные модели машинного обучения с использованием стандартных фреймворков, таких как PyTorch и TensorFlow. Затем система распределяет 400 000 ядер и 18 гигабайт памяти SRAM на чипе по слоям нейронной сети таким образом, чтобы все слои завершали работу примерно в одно время со своими соседями (задача оптимизации). В результате информация обрабатывается всеми слоями без задержек. Благодаря подсистеме ввода-вывода из 12 линий 100-гигабитного Ethernet машина CS-1 может обрабатывать 1,2 терабита данных в секунду.
Преобразованием исходной нейросети в оптимизированную исполняемую репрезентацию (Cerebras Linear Algebra Intermediate Representation, CLAIR) занимается компилятор графов (Cerebras Graph Compiler, CGC). Компилятор выделяет вычислительные ресурсы и память для каждой части графа, а затем сопоставляет их с вычислительным массивом. Затем вычисляется путь коммуникации по внутренней структуре пластины, уникальный для каждой сети.
Распределение математических операций нейросети по ядрам процессора. Фото: Cerebras
Из-за огромного размера WSE все слои в нейронной сети одновременно размещаются на нём и работают параллельно. Этот подход уникален для WSE — ни у одного другого устройства недостаточно встроенной памяти, чтобы поместить все слои сразу на одном чипе, заявляет Cerebras. Такая архитектура с размещением сразу всей нейросети на чипе даёт огромные преимущества благодаря высокой пропускной способности и низкой задержке.
Программное обеспечение может выполнять задачу оптимизации для нескольких компьютерах, позволяя кластеру компьютеров действовать как одна большая машина. Кластер из 32 компьютеров CS-1 показывает примерно 32-кратное увеличение производительности, что свидетельствует об очень хорошей масштабируемости. Фельдман говорит, что это отличается от поведения кластеров на основе GPU: «Сегодня, когда вы составляете кластер из графических процессоров, он не ведёт себя как одна большая машина. Вы получаете множество маленьких машин».
В пресс-релизе сказано, что Аргоннская национальная лаборатория работает с Cerebras уже два года: «Развернув CS-1, мы резко увеличили скорость обучения нейронных сетей, что позволило повысить продуктивность наших исследований и добиться значительных успехов».
Одной из первых нагрузок для CS-1 станет нейросетевая симуляция столкновения чёрных дыр и гравитационных волн, которые создаются в результате этого столкновения. Предыдущая версия этой задачи работала на 1024 из 4392 узлов суперкомпьютера Theta.
DrunkBear
Темы подвода питания к процу, реальной скорости и охлаждения не раскрыты, жаль.
justhabrauser
Вот это да, кстати.
С одной стороны снимать 17 кВт тепла с такой пластины наверное можно (с того же интела снимается в 200 раз меньше (TDP 95 Вт) с площади еще намного меньше). Но как? 9 хороших утюгов в размере двух.
С другой стороны — ну пусть 3.3 В питание (это не точно) => 5 kA => 1700 mm^2 меди (это если одним куском)… И земли столько же. Яссе шина…
А так как не одним куском, то будет стоять эта пластина на венике из проводов питания, как столик.
И радиатор в сауну вывести.
ne_kotin
17 кВт — это подводимая мощность.
рассеиваемая явно меньше. киловатт 5 поди, а то и меньше. небольшой такой калорифер.
mpa4b
Подводимая электрическая 17кВт, рассеиваемая тепловая 5, куда остальные 12 киловатт деваются???
Wesha
— Кем у тебя папа работает?
— Трансформатором!
— Это как?
— Получает 220, домой приносит 110, на остальные гудит.
justhabrauser
В зарплату изобретателям ЕГЭ деваются.
Akon32
Но автор коммента как раз таки закончил школу до введения ЕГЭ...
justhabrauser
Точно закончил?..
Victor_koly
Согласен, не очень производит процессор «полезную работу».
Если не считать идеи, что остальное процессор испускает не в тепло, а в диапазоне своих гигагерц частоты (ядра свое ЭМИ, кэш — свое, граф. ядро — ещё на другой частоте).
MaximRV
всё это очень удачно поглощается радиатором с одной стороны и платой с контактами с другой (а за платой еще и прижимающая пластина как правило)
Victor_koly
Ну медный радиатор конечно поглотит излучение (или может отразит какое-то).
quwy
Вы реально считаете, что эта хреновина излучает 5 киловатт (или хотя бы 0.5 Кватт) в виде ЭМ-волн? Ну вот серьезно что ли?
Victor_koly
Ну хорошо. Часть мощности идет на деградацию кристалла.
greg123
«Деградация кристалла» это один из видов энергии, или что? Почти все, что получает процессор, он тратит на нагрев. Это просто довольно эффективный нагревательный элемент с побочным эффектов в виде изменения путей протекания тока в нем, что вы трактуете как вычисления.
Akon32
Какая часть из 17 кВт, по вашему, идёт на деградацию кристалла? Строительный перфоратор мощностью 1кВт бодро так бетон дробит. 17кВт — это как небольшой трактор, разрушения должны быть соответствующими (если аккуратно их не рассеивать).
VolodjaT
У вам какая то альтернативная физика
Tufed
ЭМИ? Навскидку по мощности нефиговая такая микроволновка. 12 киловат электромагнитными волнами убили бы всю живую электронику в радиусе полуметра или даже более. Стандартная домашняя микроволновка имеет мощности 700-1.2 Кватт и магнитрон от неё без защитного кожуха палит электронику уже в 20-30 см.
fougasse
Креосан подтвердил про магнетрон!
ne_kotin
Расходуются на полезную работу, не?
vedenin1980
Разумется, нет. Работа в понятии физики и в бытовом понятии очень сильно отличается.
Представьте, что вы засунули этот процессор в спутник, стенки которого экранируют любые излучения от процессора, и вывели его в космос. Куда может деться электрическая энергия? Очевидно не в кинетическую или потенциальную энергию, так как они не изменяются. Очевидно не в результаты вычислений, так как это лишь нули и единицы в постоянной памяти и энергия у них всегда (приблизительно) одинаковая.
По закону сохранения энергии, все энергия уйдет в тепловую энергию спутника и потом частично «уйдет» за счет инфракрасного излучения стенок спутника.
То есть вывод — любой процессор с точки зрения физики это просто нагревательный элемент, превращающий электроэнергию в тепло или излучение. А результаты вычислений это лишь побочный эффект, которые не является «работой» c точки зрения физики.
ne_kotin
Ага. На регенерацию емкостей в оперативной памяти — энергия не тратится?
На переключение затворов на транзисторах — не тратится?
На инжекцию в плавающие затворы (флэш-ячейки) — не тратится?
По закону сохранения — энергия, рассеянная выделением тепла — меньше, чем подведенная электрическая. Потому что часть ушла на полезную работу.
В статье написано, что вафля потребляет 17 кВт, очевидно, что рассеиваемое тепло меньше 17 кВт. Вопрос только в КПД схемы.
vedenin1980
Главный закон сохранения энергии — «суммарная энергия замкнутой системы всегда постоянна».
Следовательна на «регенерацию емкостей, инжекцию в плавающие затворы, переключение затворов на транзисторах» может тратиться не больше, чем она может накапливаться во внутреннем состоянии системы (например, при переходе электровой атомов в более энергетически эмкие орбиты, химические реакции с поглощением тепла и т.п.).
То есть это не «трата энергии», а аккумулирование и емкость даже если представить, что процессор самый лучший аккамулятор, очень ограничена и очень быстро энергию он должен будет отдать обратно.
Поэтому рассматривая работу такого спутника годами — 100% энергии будет превращено в тепловую энергию.
100% на превращение электроэнергии в тепло или излучение. Всегда 100%. Небольшое временное аккамулирование энергии за счет изменения внутреннего состояния не имеет значение, так как она в любом случае будет отдана обратно.
Ну вот представьте, что этот затвор вообще один в космосе, вы переключили затвор в одно положение, потратили энергию, потом в вернули обратно, но энергию не получили обратно, потом снова переключили затвор и так до бесконечности. Получается у вас энергия утекает в бездонную трубу и никогда не возвращается обратно, что полностью нарушает закон сохранения энергии.
Ну или иначе, при стремлении к бесконечности, затвор должен будет хранить всю энергию Вселенной где-то внутри себя.
ne_kotin
При чем тут замкнутая система? Она открытая. Единственный путь утечки — это потери на выделение тепла, да.
И эти потери всегда меньше, чем подводимая электрическая мощность.
vedenin1980
Спутник в космосе, единственный вид утечки тепло, вы сначала переключили завтор в одно положение, потом обратно. В какой вид энергии превратилась, потраченная на его переключения энергия?
ne_kotin
Ни в какой. Подали напряжение на затвор — часть заряда стоит на затворе в виде электрического поля, увеличился ток через канал транзистора.
Сняли напряжение с затвора — заряд стек. Частично рассеялся в виде тепла. Ровно туда же в тепло — потери, вызванные сопротивлением цепи. И этого тепла меньше, чем подвели энергии.
vedenin1980
Отлично, теперь назовите энергию, в которую ушла остальная часть. Виды энергий тут, полезной работы там нет.
ne_kotin
В электрическую, епт.
Отношение выделившейся тепловой к подведенной электрической есть коэффициент тепловых потерь.
vedenin1980
Если мы подвели к процессору 20Квт, на сдачу получили 3Квт, то значит мы потратили только 17Квт и все эти Квт'ы ушли в тепло.
Еще рассмотрим изолированную систему — спутник, летящий в космосе с стенками, изолирующими любые электромагнитные излучения, внутри лежит аккмулятор на определенное кол-во энергии и процессор, выполняющий любые вычисления.
Я утверждаю, что 100% энергии, запасенной в аккумуляторе, уйдет или в тепло/тепловое излучение или в увеличение внутренного состояния системы (по факту, сохранится в другом виде аккумулятора). Никаких трат «на полезную работу процессора» там не будет и быть не может по закону сохранения энергии.
Если не согласны, покажите энергию, в которую ушло все не потраченное на тепловую энергию.
ne_kotin
Вопрос — какими темпами. Ответ — зависит от энергоэффективности компьютера. А так — рано или поздно конечно уйдет в тепло.
Еще раз: траты на коммутацию цепей — не полезная работа?
Nuwen
amartology
Nuwen
Хотите сказать, что у такого процессора около 9 квт будет уходить в ближайший маршрутизатор? Или вы говорите о том, что на поддержание нужного напряжения в сетях ethernet или на поддержание приемлемой яркости лазера в ВОЛС будет больше чем 100 ватт от питания самого процессора уходить?
Так, стоп. Цепей, а не сетей? Коммутацию цепей внутри компьютера? Коммутация это работа? Что в результате этой работы изменяет энергию? Затворы транзисторов и паразитные RLC цепи заряжаются? И сколько они могут заряда сохранить?
amartology
Они сначала заряжаются, а потом разряжаются, и так миллиард-другой раз в секунду.
Nuwen
Сможете ли вы накопить тонну воды тысячу раз заполняя и опорожняя литровую банку?
Если продолжать аналогию с водой, то похоже что некоторые считают, что при пропускании воды через трубу, некоторое количество воды будет тратится на преодоление сопротивления стенок.
vap1977
Ну потратиться туда может все 17 киловатт. Но эти же 17 киловатт выйдут в виде тепла. Потом что заряженный конденсатор при перезарядке всю запасенную энергию отдаст обратно, и соответственно в сумме за долгий период времени (хотя бы за миллисекунду) безвозвратно на коммутацию цепей не будет потрачено _ничего_. Совершенно буквально ничего — даже микроватт туда не пойдет. Все поданные 17 киловатт выйдут в виде тепла. Ну ладно, десяток ватт выйдет в виде электромагнитного излучения в гигагерцовой области спектра (в радиоволны) и сколько-то нановатт пойдут на деградацию кристалла.
vedenin1980
Ответ известен — процессор потребляет 17Квт электроэнергии каждую секунду. То есть полностью потребляет, сдачу обратно в сеть он не дает.
КПД нам не важно, поменяет он триллион или десять триллионов ячеек за эти Квт'ы.Важно, что если у нас в аккумуляторе есть 17Квт * час энергии, то он полностью разрядится ровно через час.
И все эти 17Квт * час энергии, как вы заметили, уйдут в тепло, так как им больше некуда деваться.
Дальше возвращаемся на Землю, если у нас процессор потребляет 17Квт энергии каждую секунду, то какую полезную работу он бы не делал и с каким кпд эта работа не делалась, то на отводить нужно тоже около 17Квт тепловой энергии (так вся энергия потраченная на полезную работу все равно потом выйдет в виде тепловой, ну и небольшое кол-во в виде излучения) иначе рано или поздно процессор переегреется и сгорит.
То есть для процессора, который работает годами и постоянно каждую секунду потребялет 17 Квт, нужно так же постоянно каждую секунду отводить около 17 Квт тепловой энергии, по другому никак.
VolodjaT
Вы глубоко заблуждаетесь.
ne_kotin
Закон сохранения тоже?
VolodjaT
то что пошло на зарядку конденсатора потом апять в тепло превратится
99.99% пойдет в тепло. точка
Как и КПД электрического нагревателя — 99,99%
ne_kotin
То, что пошло на зарядку — уйдет обратно в цепь и стечет по паразитным цепям.
Вопрос в энергоэффективности схемы.
vap1977
Ушедшее обратно в цепь — остается на конденсаторах в цепи питания. И используется для питания схемы на следующем такте (но большая часть — все-таки в процессе переключений уходит в тепло и не доходит даже до металлизации планов питания).
Обратно в розетку не утечет — нет там такой возможности.
Nuwen
Закон сохранения как раз утверждает, что сколько вы энергии у системе привели, ровно столько и получите от неё обратно. Законы термодинамики утверждают, что часть энергии всегда уйдёт в тепло, а часть в совершаемую работу. Какую механическую работу совершает процессор?
vibornoff
<sarcasm>
Расширяется и сжимается под переменной вычислительной нагрузкой.
</sarcasm>
justhabrauser
.
Bedal
17квт — потребление не процессора, но компьютера в целом. Вряд ли там «обычной» памяти меньше гигабайт эдак 700, ну и остальная обвязка тоже греется.
Mad__Max
В нем нет обычной памяти — она не предусмотрена, как и шины и контроллера памяти как и многих других привычных для классических архитектур вещей.
Кроме собственно процессора, цепей питания к нему и системы охлаждения в нем особо ничего и нет. Вся дополнительная память (как оперативная, так и диски) в отдельном сервере/серверах, общение с которым(и) идет через многоканальную скоростную сеть. Отдельных сетевых контроллеров тоже нет, они тоже интегрированы в сам «процессор». В кавычках т.к. это SoC — вычислительные ядра равномерно перемешаны с локальной сверхбыстрой SRAM памятью (причем работающей именно как основная рабочая память, а не кэш для внешней памяти), с интегрированными внутренними сетевыми свичами и 12ю сетевыми контроллерами для общения с «внешним миром».
Mad__Max
Не успел дописать в предыдущий пост. Шина памяти формально есть, но не у процессора, а в каждом из 400 000 ядер своя собственная. Т.е. 400 тысяч независимо работающих шин памяти, каждая на очень коротких расстояниях, за счет чего можно добиться очень высоких скоростей и минимальных задержек.
Судя по всему они почти 1в1 повторили общую архитектуру/подход реализованную еще в самом первом серийно производившимся нейроморфном чипе SpiNNaker — apt.cs.manchester.ac.uk/projects/SpiNNaker/SpiNNchip
Где было 64 КБ SRAM TCM (tightly-coupled memory) памяти под данные и 32 КБ под код в каждом ядре, а общение между всеми ядрами шло уже не по классическим шинам, а через интегрированную в сам чип асинхронную, но сверхбыструю p2p сеть с минимальными задержками за счет аппаратных (так же интегрированных в чип) свичей/роутеров.
Только тут память в 2 раза порезали, до 32+16 КБ = 48 КБ на ядро (в сумме получается как раз заявленные ~18 ГБ на 400к ядер).
Но зато совершили гигантский скачок в количественном плане за счет использования современного технологического процесса (со 130 нм в SpiNNaker до 16 нм в WSE) и многократного наращивания площади чипа до полной пластины (с 102 мм? до 46 225 мм?)
В результате теперь в одном мега-чипе умещается аналог почти половины суперкомпьютера, который только недавно наконец-то собрали из тех самых SpiNNaker (подробнее про это — habr.com/ru/news/t/429200 )
Mad__Max
Про питание и охлаждение еще в прошлый раз в комментариях под предыдущей новостью об этом мегачипе выяснили. Начиная примерно вот с этого комментария: habr.com/ru/news/t/464271/#comment_20526237
И дальше по ветке
justhabrauser
DrunkBear
Спасибо!
Видимо, сработала одна из вариаций законов Мерфи: как только отписался от обновлений ветки в трекере, там началось самое интересное.
PS посмотрел на презентацию и комменты — всё равно не хватает фото водоблока с сотнями подводов охлаждающей жидкости, хтоническое должно быть зрелище.
VolodjaT
А почему сотни подводов?
у меня в доме котел на 34кВт выходной тепловой мощности — выдает по двух металопластиковых трубках с внутренним диаметром 24 мм. Совсем ничего хтонического
У воды огромная теплоемкость
DrunkBear
Было заявлено как фича, что температура блоков кристаллов мониторится и к более горячим блокам идёт больше воды, а к прохладным — меньше, ибо тепловое расширение может сломать кристалл.
Котёл нагрет более равномерно.
VolodjaT
ааа. ну тогда ИМХО логично делать радиатор с матрицей соленоидов с клапанами
на чпу несложно такое запилить
DrunkBear
И мониторингом с обвязкой каждого клапана?
1 сдохший соленоид может убить здоровенный процессор.
vap1977
У медной пластины очень неплохая теплоемкость. Так что только один соленоид ничего не поменяет. Вот если несколько сдохнут с одного края — тогда да.
Aberro
Что-то мне подсказывает, что это слишком интересные темы, чтобы их раскрывать. Иже — коммерческая тайна. Поскольку какому-нибудь гуглу тоже это может быть интересно.
ni-co
Благозвучней не " система распределяет 400 000 ядер и 18 гигабайт памяти SRAM на чипе по слоям нейронной сети", а "… системой слои нейронной сети распределяются на 400 000 ядер и 18 гигабайт памяти SRAM на чипе".
Arxitektor
На самом деле интересная реализация. Сколько нанометров? 7 или пока больше?
Сделать большую пластину с огромным количеством ядер. И пусть даже честь из них не работает. Но архитектура решения позволит это обойти.
И если я правильно понял компоновка транзисторов в 2D.
На пластине я вижу 84 отдельных чипа.
А если использовать технологию сквозных металлических соединений как в чипах памяти
И делать пирог из этих чипов. И столбики таких чипов располагать на интерпрозере как делает АМД. Использовать интерпрозер вместо обеднения в рамках 1 пластины.
Правда главный вопрос что делать с охлаждением…
Интересно как на данный момент обстоят дела с охлаждением чипов посредством микро каналов в кремни?
А можно ли с помощью такого чипа смоделировать мозг животного крысы например?
dzsysop
Такими темпами и инвестициями, я так чувствую, скоро сильный ИИ войдет в нашу жизнь также как вошел слабый.
amartology
Mad__Max
Больше, про это в прошлой статье было:
Разработка этого чипа еще 3-4 года назад началась — под имевшиеся тогда технологические нормы.
Это не отдельные чипы, а «отпечатки» фотолитографического шаблона, размер которого существенно ограничен имеющимся производственным оборудованием. Такой большой чип невозможно экспонировать при литографиии весь целиком за один раз, поэтому это делается такими вот сегментами по частям.
xsevenbeta
Rattus norvegicu, вся нервная система — 200к нейронов. Кора больших полушарий — 31млн.
Blue Brain Project — проект по компьютерному моделированию головного мозга человека. Начался в июле 2005 года. Над проектом совместно работают компания IBM и Швейцарский Федеральный Технический Институт Лозанны (Ecole Polytechnique Federale de Lausanne — EPFL). Проект планируется закончить к 2023 году.
Проект использует суперкомпьютер Blue Gene. В конце 2006 года удалось смоделировать одну колонку новой коры молодой крысы. При этом использовался один компьютер Blue Gene и было задействовано 8192 процессора для моделирования 10000 нейронов. То есть практически один процессор моделировал один нейрон. Для соединения нейронов было смоделировано порядка 3?107 синапсов.
Загрузка сознания
ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B0_%D1%81%D0%BE%D0%B7%D0%BD%D0%B0%D0%BD%D0%B8%D1%8F
В 2013 году для симуляции 1 секунды работы 1% человеческого мозга потребовалось 40 минут на кластере из 82 944 процессоров 10-петафлопсного K computer. Учёные попытались повторить работу 1,73 млрд нервных клеток и 10,4 трлн соединяющих их синапсов, на каждый из которых ушло 24 байта.
На хабре, вроде, описывался эксперимент где 15к ядер использовали для симуляции, но найти статью не смог.
Nuwen
Greendq
Водичкой, скорее всего. Но 17 кВт в таком объёме — это нехилая печка такая…
kalininmr
да в принципе то и жидкий азот штука дешевая.
opckSheff
У жидкого азота теплоёмкость низкая, водичкой эффективнее будет.
kalininmr
тогда уж масло
vanxant
Также интересно, как это планируется питаться. У таких печек питалово 5х0.4кВ минимум 10мм? толщиной каждый провод, т.е. 50мм?. Тут сделали PSU-на-чипе?
Cenzo
Помнится про АМД с открытым чипом было видео, как они пыхают без радиатора. Может и тут опубликуют...
drWhy
Если пыхнет, Cerebras сможет задорого показывать соответствующий видеоролик тонким ценителям, или выставить на торги самую дорогую в истории яичницу.
amarao
Всех интересует как подводить/отводить 17кВт. В целом, человечество умеет охлаждать фигулины до нескольких гигаватт (привет, реакторы).
А вот 1.2Тбит/с сетевого трафика с одной машины — это реально страшно.
drWhy
Жидким натрием охлаждать процессор всё же не получится.
Mad__Max
Почти все реакторы, за исключением нескольких штук экспериментальных моделей охлаждаются самой обычной водичкой, а не жидкими металлами. Ну или «тяжелой» водичкой, но там она используется не для улучшения охлаждения, а для улучшения протекания непосредственно ядерных реакций.
Victor_koly
Для замедления «быстрых» нейтронов, да.
Mad__Max
Самая обычная вода замедляет нейтроны не хуже (даже вроде получше). У «тяжелой» другое ядерное преимущество — по сравнению с обычной она почти не поглощает проходящих через нее нейтронов, а только замедляет их. Как следствие их больше остается для запуска ядерных реакций в топливе.
В результате можно либо снизить критическую массу и размеры реактора либо использовать менее обогащенное и за счет этого более дешевое ядерное топливо, которое к тому же более полно используется/вырабатывается в процессе работы.
Вплоть до того, что можно построить реактор, который будет способен работать на топливе вообще без дополнительного обогащения — прямо на природном уране.
Формально и на обычной воде это теоретически возможно, но на практике размеры и другие параметры подобного реактора оказываются неприемлемыми. А вот на тяжелой это не только возможно, но и такие модели существуют на практике (например CANDU ).
drWhy
У почти всех реакторов площадь теплообмена чуть выше 22*22 см.
А работы по тепловым трубкам на жидком натрии (для космических реакторов, где важна компактность и вес) ведутся как минимум лет тридцать. Эффективность таких ТТ значительно превышает таковую для водяных ТТ, да и диапазон рабочих температур заметно шире.
DrunkBear
Натрий + воздух = взрыв, к тому же, жидкий натрий — агрессивная штука.
В космосе это оправдано снижением веса, а на земле — вряд ли.
drWhy
Верно. Но натрий+вода значительно веселее. И, тем не менее, схема активно используется, т.к. Теплопроводность СО относительно таковой для воды значительно выше.
Mad__Max
Ну так и выделяющаяся тепловая мощность где-то в 200 000 раз выше однако.
А натриевые ТТ — по эффективность водяных ТТ может и превышает, а вот банальной трубочке аналогичного диаметра по которой вода прокачивается насосиком все-равно уступает.
Там натриевые ТТ тоже не для суперэффективности съема тепла, а ради высокой надежности, большого срока службы без каких либо ТО в процессе, ну и диапазона раб. температур.
drWhy
Вы же о проточной воде? Которую сливают после прохождения испарителя. Но её ведь не везде можно слить (скажем, первый контур на АЭС, или космос), придётся охлаждать и отправлять по кругу, т.е. городить второй контур.
Кроме того, вода имеет неприятную особенность закипать, резко увеличивая объём и повышая давление, налицо низкий температурный диапазон. ТТ на парах воды, по крайней мере, не порвутся при перегреве, но теплопроводность также потеряют.
ТТ на расплаве натрия спокойно продолжат качать энергию, увеличивая температуру конденсатора, а значит, и его излучение. Равновесное состояние будет достигнуто, хотя и при более высокой температуре.
Ну и компактность. И вес. Но если что, то всё.
dzsysop
Почему сразу сетевого трафика?
Если у меня графическая карта имеет пропускную способность 400GB/s это не значит что мне нужен такой же выход в сеть.
Paskin
Потому что для обучения сетей нужно «кормить» их предварительно классифицированными вручную данными — из-за обьема которых обычно довольно проблематично загрузить даже более-менее топовые GPU на «всю катушку». По той же причине для достижения приличной производительности распознавания, на edge-устройствах процессор ввода видео напрямую связан с GPU/DLA — их слабенькая шина между CPU и GPU просто не справляется с такими обьемами.
Mad__Max
Потому что 1.2 Тбит/с это именно внешний сетевой интерфейс для загрузки/выгрузки данных. А внутренняя ПС (аналогичная по смыслу вашим 400GB/s) при обработке этих данных тут до 100 Пбит/с, т.к. вся рабочая память тут интегрирована непосредственно в сам чип в виде SRAM.
amarao
У них же сказано — 12 100Гбит линков. Интернет не обязательно, но даже в режиме interconnect между локальными машинами всё равно пугает.
DaemonGloom
А что не так? Решения по 200 и 400 гбит сетевого трафика были представлены ещё в 2016. Бондинг трёх каналов возможен даже сейчас.
Cisco Nexus 9300-GX — 16 портов по 400гбит. Nexus 3432D-S — 32 порта. Стоимость у них, конечно, страшная. Но вполне терпимая, когда возникают потребности в таких компьютерах и полной утилизации их возможностей.
amarao
Вот стоит такая Cisco на 16 портов по 400Гбит и обслуживает локалочку из 5 компьютеров. Прям как хаб под столом.
Tufed
Если эта локалочка из компьютеров этой статьи, то все вместе они еще обогревают пару соседних офисных зданий.
amarao
Хорошо написанное приложение способно загрузить 400 000 ядер примерно на 200-500мс после нажатия пробела в IDE. Даже если на это потребуется 17кВт.
DrunkBear
Для 15юнитовой железки — почему нет?
В оракловых стойках вообще штатно стоит 3 свича (40Gb ib / 100GbE) — и ничего, удобно: сгорел один свич — трафик автоматом пошёл через другой.
sYB-Tyumen
Гудит, греет, лепота…
xsevenbeta
Охладить можно всё что угодно, но тут ведь ещё вопрос размера фигулины, и при этом как-то питание надо подводить и.т.д.
buratino
Старый совецкий анекдот о том, что у нас сделали самую передовую микросхему с 16 ножками и 2 ручками для удобства переноски заиграл новыми красками
deepform
Однако Cerebras не представила реальные результаты тестов, чтобы проверить заявления о высокой производительности
Bedal
потому, что им пока не важен массовый рынок, и нет смысла его заинтересовывать. Ливермор взял? Ну, ладно.
ZuOverture
Mad__Max
Почему не хватит? В интегрированной SRAM нужно хранить только веса обучаемой модели, все данные для тренировки тянутся с внешнего хранилища по мере надобности. В данном случае всего около 1.5 ГБ SRAM хватит для эффективной тренировки, т.к. вроде в GPT-2 используются 8 битные веса.
А в статье по ссылке как раз описывается метод, за счет которого можно эффективно тренировать сети, в которых даже один полный набор параметров модели не умещается в локальной памяти единичного устройства за счет сегментирования данных — для примера они там тестируют тренировку моделей от 40 до 100 миллиардов параметров на кластере из V100 в которых по 32 ГБ памяти максимум.
ZuOverture
Так в статье как раз и написано почему. Для обучения нужно хранить не только веса модели, для всех промежуточных вычислений надо в несколько раз больше памяти. Сам тоже такое наблюдал, когда пробовал дообучать модель 345М — процесс не 1500Мб на ГПУ кушал (там 32-битные веса), а все 6Гб и просил ещё. На 1080 с 11Гб заработало.
Mad__Max
А параграф на который сами же ссылалась (3) дочитать до конца? Там написано, что все кроме непосредственно самих весов по большому счету не обязательно для хранения и все это можно вычислять «на лету», теряя при этом меньше половины скорости вычислений, но в несколько раз сокращая объем используемой памяти.
Сейчас в стандартных фреймворках для обучения их хранят, просто потому что большинство используемых и тренируемых сеток на практике имеют размеры порядка 1-100 млн. параметров и памяти у железа даже «домашнего» класса в единицы ГБ более чем достаточно, поэтому ее «излишки» можно потратить для хранения вспомогательных и промежуточных параметров, позволяющих ускорять вычисления. По сути разновидность кэширования — вместо повторного вычисления чего-либо сохраняем полученный результат и в следующий раз извлекаем его из памяти вместо повторного расчета.
Для гигантских по кол-ву параметров моделей используют несколько другие подходы и фрейморки (и статья как раз предлагает способ как их можно дальше улучшать), в частности сравнивают уже существующий и использующийся для таких целей со своим вариантом на моделях от 8 до 100 миллиардов параметров прогоняемых на кластере GPU c 32 ГБ памяти:
ZuOverture
В мире авторов пдфки возможно промежуточные результаты уже не хранятся. В реальном мире — хранятся. Новый комбайн работает в реальном мире, с реальными фреймворками. Почему создатели процессора закладывались на какие-то будущие оптимизации, дав ему так мало памяти для такого количества ядер?
Mad__Max
Реальные фрейморки не хранящие промежуточные данные уже тоже существуют и их используют, когда надо работать с очень большими моделями для которых критичен именно объем памяти и размер модели, а не скорость ее обучения. С одним из таких (Megatron) авторы работы из ПДФки свое решение и сравнивают как раз как. Он тоже например способен крутить модели нейронок на 20 млдр. параметров на картах с 32 ГБ памяти — меньше 2 байт на параметр.
А памяти тут «мало», потому что это сверхбыстрая память типа SRAM, которая очень дорого обходится в плане расхода транзисторов — по 6 или 8 транзисторов на каждый бит емкости. На 18 ГБ это как минимум 870 миллиардов (18*8*6) транзисторов. При том что общий «бюджет» чипа ~1200 миллиардов транзисторов.
Т.е. в нем и так большая часть транзисторого бюджета и площади чипа отдана как раз под память — она занимает намного больше чем вычислительные ядра, внутреняя сверхскоростная сеть и все прочие интегрированные системы вместе взятые.
А обычной памяти (для хранения всего остального, кроме самого критичного по скорости доступа) если нужно не проблема накидать в виде внешнего банка обычной (DRAM) памяти — хоть террабайт подключай.
drWhy
Зато быстрая и рядом.
xsevenbeta
Я так понимаю, тут речь про «процессорную» память (кэш). У i9-9900X, например, она 20мб.
ZuOverture
del
Stas911
Эка невидаль — мы в универе на лабах проц метр на полтора собирали (на стенде, проводами в дырочки). А если серьезно — очень впечатляет такой размер пластины в одном изделии.
Dioxin
Скайнет и Матрица всё ближе.
gx2
Как я понимаю, это просто большая плата с множеством независимых частей? Иначе, как они обошли квантовые ограничения на такие расстояния?
ua30
Простите, что обошли?
Обычные процессоры испокон веков делаются на одном кристалле. А потом пластина режется на десятки / сотни кусков — отдельных процессоров. Суть в том, что на пластине могут появляться отдельные дефекты. По аналогии — как битые пиксели на мониторах. И они появляются там довольно часто. Если разрезать пластину с такими дефектами на куски — лишь некоторые процессоры будут непригодные, остальные будут полностью рабочими. Но чем больше площадь процессора — тем больше вероятность, что на нем окажется дефект. А это в свою очередь влияет на цену рабочих экземпляров. Грубо говоря, если на пластине есть 10 дефектов, и она режется на 1000 процессоров, мы получим не более 1% брака. А если она режется на 50 процессоров — получим до 20% брака. Если резать ее на 10 частей, у нас есть шанс не получить ни единого рабочего процессора. И так далее. Если я правильно понял суть вашего комментария.
Но по факту, ИМХО, это не более чем понты. Это будет жутко дорого и не практично. А выгода в чем? Сэкономить место?
amartology
Емкость соединения двух закорпусированных микросхем на плате — десяток пикофарад. Типовой диаметр такой линии — сотни микрон.
Какие линии вы предпочтете, если вам их нужно десять тысяч? Или миллион?
Вообще там скорее всего все процессоры будут нерабочими, если внутри каждого из них не заложены механизмы починки косяков. Совсем в помойку отправляется только то, где багов слишком много, чтобы их пофиксить.
ua30
amartology
Для того, чтобы зарядить емкость 100 фФ до напряжения 1В, нужно 100 фКл заряда. Для того, чтобы зарядить 10 пФ до напряжения 1В, нужно 10 пКл заряда.
Если вам нужно зарядить линию за фиксированное время, то во втором случае вам потребуется в сто тысяч раз больше мощности. Если, конечно, это вообще получится, потому что есть еще сопротивление и индуктивность линии.
Поэтому ответ про практическую пользу очень простой: соединения на кристалле вместо соединений на плате намного быстрее и расходуют на несколько порядков меньше энергии.
amartology
Какие квантовые ограничения вы имеете в виду?
kryvichh
В мозге человека 85 млрд. нейронов.
CS-1 — чип из 400 000 ядер и 1.2 триллиона транзисторов.
А сколько там получается нейронов на 1 ядро?
Чтобы прикинуть, сколько CS-1 в кластере сэмулируют мозг человека.
Можно ограничить сверху. Если взять 1 ядро = 1 нейрон, то получим кластер из 212500 CS-1. Но это конечно очень грубая оценка.
Mad__Max
Смотря какие параметры этих ядер, они их не назвали. Судя по количеству и размерам это что-то очень простое, на уровне «ядер» (самых мелких вычислительных блоков, иногда еще называемых шейдерами) GPU.
Но в одной из прошлый подобных попыток созданий нейроморфных чипов с очень похожим подходом (только в гораздо меньших масштабах — en.wikipedia.org/wiki/SpiNNaker), где тоже довольно слабенькие ядра (одна из простых версий ARM к тому же работающая на частоте всего 200 МГц) с интегрированной SRAM памятью в каждом и общением со всеми соседними ядрами по MESH-сети через встроенные же коммутаторы получалось моделировать работу до 1000 нейронов на каждое ядро.
В одном из более свежих попыток — чипах TrueNorth заложено моделирование 256 нейронов на 1 очень простое ядро (там по 4096 ядер в одном чипе, симуляция до 1 миллиона нейронов на чип).
toivo61
Транспьютеры наносят ответный удар!?
Так как никто специально ломать техпроцесс не станет, то похоже, что эти молодцы сделали процессор который масштабируется путем параллельного переноса. Давно ждал такого хода.
Вопрос не сколько в охлаждении. А вот как они питание в центр пластины подают?
amartology
DrunkBear
Нее, сверху у неё —
неонкаводянка.amartology
Тогда снизу
