
Привет, Хабр!
Несколько месяцев назад я выступал на конференции FrontendConf 2019 с докладом Docker для фронтендера и хотел бы сделать небольшую расшифровку доклада для тех, кто больше любит читать, а не слушать.
Приглашаю под кат всех веб-разработчиков, особенно фронтендеров.
Восхождение Docker
Docker инструмент не новый, он впервые был опубликован ещё в марте 2013 года и с тех пор его популярность только растёт.
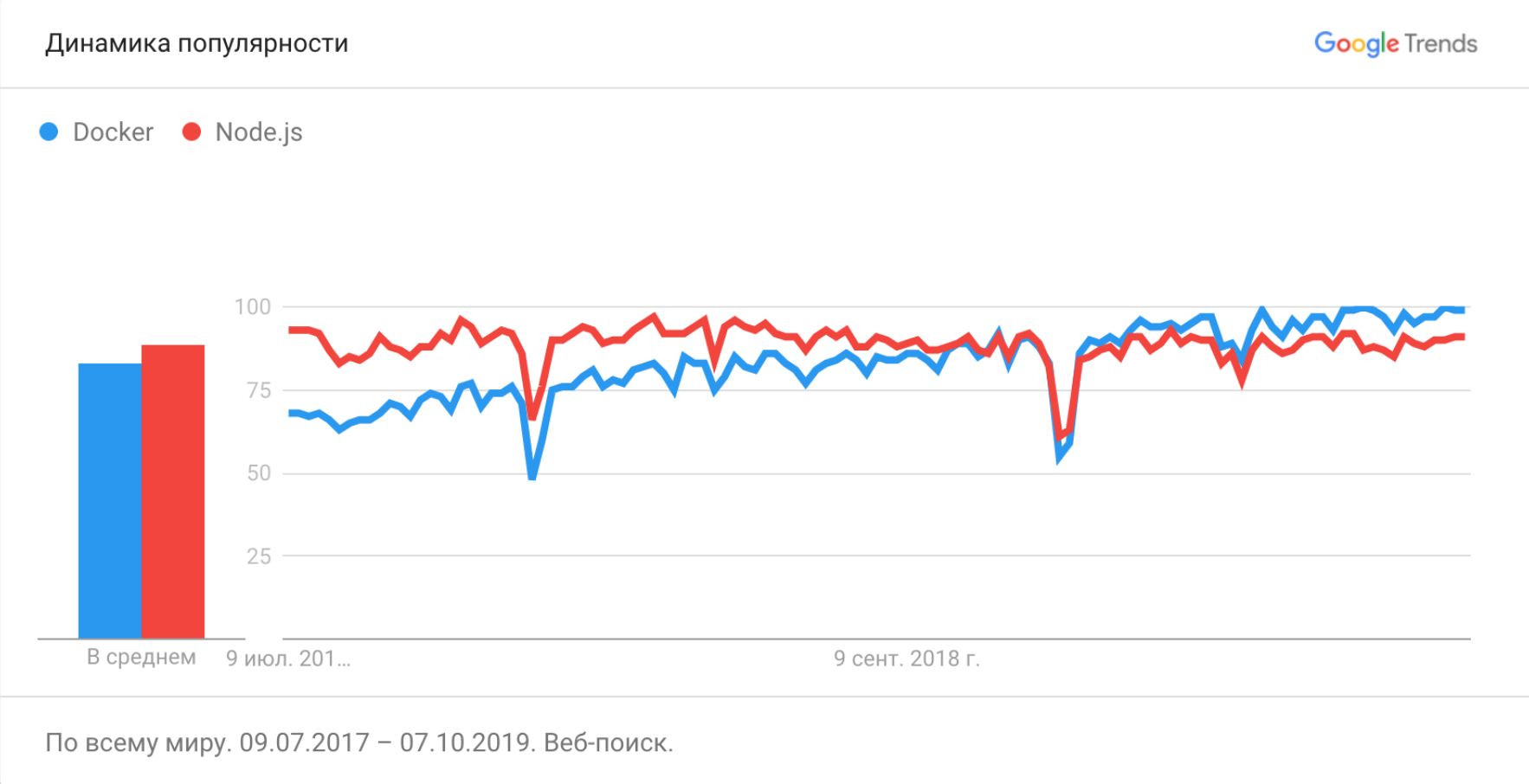
Тут мы видим, что частота запросов по Node.js достигла плато и никуда не двигается, а запросов про Docker продолжает увеличиваться.

Вот такая игрушка была на конференции РИТ++ 2019 в рамках DevOps-секции. И по моему опыту ни одна конференция по DevOps не проходит без докладов про Docker, так же, как и фронтендерские конференции не проходят без докладов про сравнение фреймворков, настройку вебпака и профессиональное выгорание.
Давайте и мы во фронтенд-тусовке тоже начнём говорить про эту технологию.
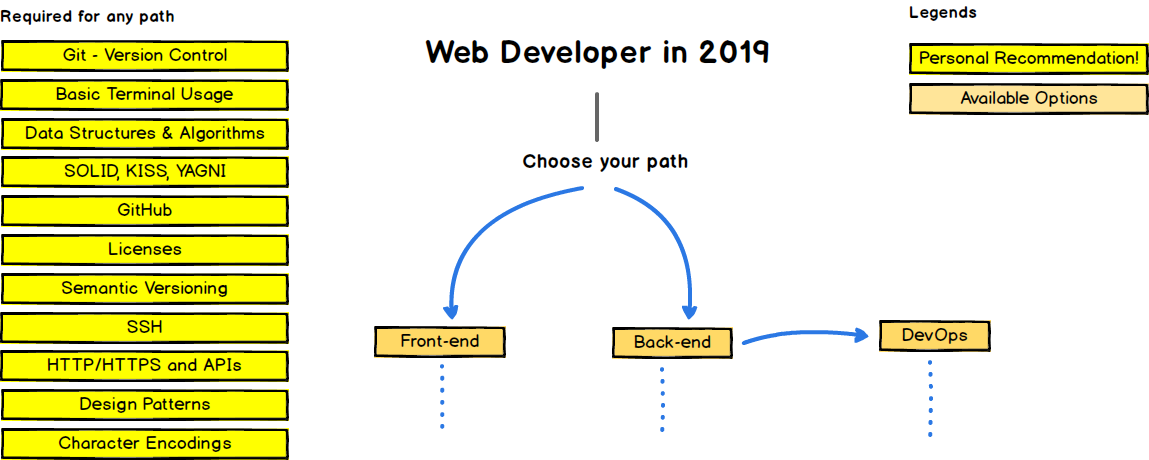
Это дорожная карта веб-разработчика. Слева изображены навыки, обязательные для любого пути развития. Действительно, сложно представить хорошего веб-разработчика, который не умеет в Git, терминал или не знает HTTP.
Docker тут тоже присутствует, но где в недрах ветки развития DevOps'а в блоке Infrastructure as a code -> Containers.
Но мы знаем, что Docker — это ещё и отличный инструмент для разработки, а не только для эксплуатации. И, по моему мнению, он имеет все шансы через некоторое время попасть в секцию Required for any path и стать обязательным требованием во многих вакансиях фронтенд-разработчиков.
Можно сказать, что мы сейчас живём в Эру Docker. Поэтому, если вы фронтенд-разработчик и ещё с ним не познакомились, то я расскажу, почему это стОит сделать.
Зачем?
Кейс 1. Поднимаем backend
Первый и самый полезный кейс, который мы можем рассмотреть — это запуск API на своём уютном макбуке. Да, мы отлично знаем наши технологии, но разворачивать что-то стороннее всегда испытание не из лёгких.
На одном из наших проектов фронтенд-разработчику нужно было поставить на компьютер вот такой набор, чтобы API заработал:
* go1.11
* MySQL
* Redis
* Elasticsearch
* Capistrano
* syslog
* PostgreSQLК счастью, у нас были инструкции по развёртыванию проекта в README-файлах. Они выглядели примерно так:
1. Установить GVM (https://github.com/moovweb/gvm)
2. `gvm install go1.11.13 --binary`
3. `gvm use go1.11.13 --default`
4. В папке с проектом создать ссылку на golang (`gvm linkthis`)
5. Установить `gb` `go get github.com/constabulary/gb/...`
6. Настроить авторизацию `git config --global url."git@git.example.com:".insteadOf "https://git.example.com/"`
7. Установить зависимости `gb vendor restore`
8. Поднять БД
9. Собрать ассеты `npm run build` (`npm run build:dev` для разработки)
10. Запустить сервер `npm start`И вот так:
## Elasticsearch
1. Скачать и установить Elasticsearch `brew install elasticsearch` - macOS (предложит установить дистрибутив java)
2. Установка плагина
* выбери в https://github.com/imotov/elasticsearch-analysis-morphology из списка подходящий к твоей версии плагин, и запусти
`/usr/local/Cellar/elasticsearch/2.3.3/libexec/bin/plugin install http://dl.bintray.com/content/imotov/elasticsearch-plugins/org/elasticsearch/elasticsearch-analysis-morphology/2.3.3/elasticsearch-analysis-morphology-2.3.3.zip` - пример
* потом перезапусти эластик `brew services restart elasticsearch`
3. в проекте админки
`rake environment elasticsearch:import:model CLASS='Tag' FORCE=y `
`rake environment elasticsearch:import:model CLASS='Post' FORCE=y`
индексировать будет долго, но пользоваться можно сразу
## Postgres comments db
1. `psql -U postgres -h localhost`
2. `create database comments_dev;`
## Redis install and start
1. `brew install redis`
2. Перед запуском `brew services start redis`Как вы думаете, сколько времени требовалось начинающему разработчику, чтобы развернуть у себя проект и начать делать задачи?
Около недели.
Естественно, не все команды терминала проходили с первого раза, довольно часто инструкция устаревала.
Это считалось нормальным и всех устраивало. То есть, чтобы сделать фичу в 1 час работы, требовалось сначала потратить 40 часов на разворачивание всех компонент локально.
Сейчас разворачивание проекта со всеми сервисами для разработки выглядит вот так и при холодном старте занимает около 10 минут.
$ docker-compose up api
...
Listening localhost:8080Все команды разворачивания сервисов выполняются во время сборки Docker образов. Они автоматизированы и не могут устареть.
Кейс 2. Устойчивость
Второй кейс — устойчивость системы нашего рабочего компьютера.
Кому нравится ставить на свой любимый компьютер какой-то сторонний софт? Кому нравится устанавливать несколько разных баз данных, новые компиляторы, интерпретаторы?
А это приходится делать, когда мы разворачивает локально сторонний API.
Более того, вы можете сломать вашу систему и потратить несколько часов на её восстановление.

Использование Docker для разработки достаточно хорошо справляет с этой проблемой. Весь сторонний софт крутится в изолированных контейнерах и при необходимости легко удаляется.
$ docker rm --volumes api
$ docker system prune --allКейс 3. Контролируем эксплуатацию
И третий кейс, про который бы я хотел рассказать — это возможность фронтенд-разработчику контролировать эксплуатацию своего сервиса. Самому решать, как его сервис будет работать в продакшене.
Я знаю, что передача проекта в эксплуатация довольно часто выглядит следующим образом.
Фронт: Ребят, я всё сделал. Код в репе. Выкатите, плиз!
Админ: Как оно выкатывается?
Фронт: Собираешь нодой и раздаёшь статику веб-сервером из папки /build
Админ: Какой версией ноды собирать? Какая команда сборки? Каким веб-сервером раздавать?
В итоге для админа развёртывание вашего проекта превращается в не менее увлекательный квест, как для вас развёртывание API на локальной машине из предыдущих кейсов.
Даже если проект будет работать у вас на компьютере, совсем не обязательно, что всё так же будет работать на продакшене. И мы получаем классическую проблему "это работает на моей машине".

Docker помогает нам и с этим. Решение простое, если мы запаковали наш проект в Docker, тем самым автоматизировав его сборку и настроив запуск, то он будет одинаково работать на всех серверах, которые поддерживают Docker.

А инструкция для админов сведётся к:
Фронт: Ребят, я всё сделал. Собрал для вас Docker-образ. Выкатите, плиз!
Админ: Ок
Уж с чем, а с Docker-образами админы точно должны уметь работать. Не то, что с нашей нодой.
Что же такое Docker?
Надеюсь, я смог объяснить, почему стоит присмотреться к этой технологии, если вы фронтенд-разработчик и до сих пор её не знаете. Но я так и не рассказал, что это такое.

Планирую написать про это в следующих частях статьи и дать немного полезных рецептов для фронтенд-разработчиков.
Содержание
- Docker для фронтендера. Часть 1. Зачем?
- Docker для фронтендера. Часть 2. Что ты такое?
- Docker для фронтендера. Часть 3. Немного рецептов
Комментарии (25)

inoyakaigor
05.12.2019 20:54+3На прошлой работе также было, дерьма с этим хлебнул знатно. Сейчас же все запросы к апи проксирую через Nginx на стейджовый сервер, проблем не знаю и рекомендую всем сделать также и закопать, наконец, эту стюардессу

Avdeev Автор
06.12.2019 12:02+1После доклада меня спрашивали несколько раз про этот подход, когда фронтенд-разработчик всё запускает не локально, а использует отдельный staging- или dev-сервер для разработки.
Этот способ работает и имеет свои плюсы, но не лишен и недостатков.
Вот некоторые из них:
- Невозможность работать офлайн или при плохом Интернете. Многие любят работать из дома, деревни или в дороге.
- Необходимость делить один и тот же ресурс с другими разработчиками и тестировщиками. У нас были случаи, когда приходилось создавать необходимую для разработки сущность новости с названием «НЕ УДАЛЯТЬ!», чтобы кто-то её случайно не грохнул. Но, всё равно это периодически случалось.
- Такой сервер достаточно хрупкий. Было несколько ситуаций, когда бекенд-разработчики или эскплуатация начинали шатать сервак. Или, к примеру, накатывали туда какие-нибудь ломающие изменения. Это останавливало разработку у всей команды.
musuk
06.12.2019 13:31+1Работаем в распредёлнной команде по такой схеме.
Невозможность работать офлайн или при плохом Интернете.
Хороший интернет в наше время must have. Без него вообще плохо.
Необходимость делить один и тот же ресурс с другими разработчиками и тестировщиками.
Почти никогда у нас это не проблема, но зависит от проекта, конечно.
Такой сервер достаточно хрупкий.
Да, он хрупкий (хотя перед выкладкой прогоняются тесты), но понять почему у фронта упало бекендерам сильно проще, потому что обший сервер пишет логи.
Есть более важная проблема при таком подходе: очень сложно иметь по серверу на фиче-ветку. Можно сделать front-ветку на каждого фронта и если фронту нужно переключиться на какую-то фиче ветку, то то эту ветку мерджат в front-ветку и CI/CD её строит. Однако это запарано, потому народ всё льёт в master.Avdeev Автор
06.12.2019 14:41Да, кстати, об это я не подумал. Хороший кейс.
Локальное разворачивание позволяет развернуть у себя любую ветку API.
Например, вот так:
cd api git checkout feature/branch docker-compose build api make migrate docker-compose up apimusuk
06.12.2019 15:02Мы в итоге, к тому же и пришли. Только у нас не make migrate, а большой скрипт, который инициализирует окружение. Только вот для запуска этого скрипта надо локально установить кучу всего, например, чтобы сделать mongorestore нужно поставить mongo-tools, чтобы проиндексировать эластик, надо собрать соответствующий кусок приложухи, для сборки которого нужно поставить SDK. Так что да, вынести сервера бд в отдельные контейнеры можно, но SDK всё равно надо будет ставить и настраивать.
Avdeev Автор
06.12.2019 15:32Не уверен, но, думаю, можно попробовать сделать образ с SDK, который при старте инициализирует окружение.

vasyapivo
05.12.2019 21:02* go1.11
* MySQL
* Redis
* Elasticsearch
* Capistrano
* syslog
* PostgreSQL
Сколько памяти отъест виртуалка на MacOS/windows чтобы гонять это всё в контейнерах?

lasc
06.12.2019 06:17на 16 можно жить.

TheRaven
06.12.2019 11:23+1Нельзя. Буквально вчера развернул себе бекенд на 12 (!) контейнерах, запустил фронт, IDE, Skype, Firefox, AIMP… и память всё, кончилась. Хорошо что вся эта требуха докерная сама спрятана в виртуалку, сегодня буду её на отдельную тачку выносить.
Avdeev Автор
06.12.2019 11:47Оно всё достаточно легковесное, в этом и прелесть Docker. Вот пример вывода
docker stats.
CONTAINER ID NAME MEM USAGE e4941ea92ce7 nginx_1 3.16MiB 1b023bfff38f api_1 351.5MiB e07c6958e378 pg_1 18.64MiB 1fa783f5fdbc terminal-front_1 14.89MiB 72e9dfa0805a adminer_1 11.19MiB e9ce9f965867 admin-front_1 1.312MiB 3edacc59a77b certbot_1 1.547MiB
Видим, что БД заняла 19 МБ, а API на Java — 352 МБ.
У нас у разработчиков от 8 до 16 ГБ оперативной памяти. Обычно, этого хватает.
По личному опыту, большую часть оперативной памяти во время разработки съедает IDE, Chrome, Telegram, Slack, а не запущенные docker-контейнеры.vasyapivo
06.12.2019 11:53Но ведь вопрос не в том, сколько памяти потребляет контейнер, вопрос в том, сколько ест виртуалка без которой вы на MacOS или Win ничего не сможете сделать. Docker build выполняется именно на виртуалке, и если сама апа ест 14 мегабайт, то вопрос в том, сколько будет жрать ресурсов docker build.




musuk
Как просто!
Кроме API нужно ещё поднять конейнер с elastic, mongo запихать данные в mongo и проиндексировать их эластиком. Причём пихать данные нужно только когда у вас подымутся Mongo и эластик. А их ещё надо и сконфигурить.
usego
Делается преднастроеный докерок эластика с данными и всё вместе линкуется одним компоузом. И индексировать эластиком монго… Это как?
musuk
docker-compose не ждёт когда подымется mongo или elastic, он знает только запущен конейнер или нет. docker-compose для такой цели можно написать и решить всё через, но он будет довольно сложной штукой с кучей логики в entrypoint.sh
Для таких целей должно быть что-то более умное, чем docker-compose.
usego
ну так и апликуха не должна насмерть валиться от кратковременного офлайна эластика
musuk
Это да, но чтобы заполнить эластик вам нужны данные в монге, те дождаться, когда отработают все mongorestore.
Чтобы начать заполнять монгу через mongorstore вам нужно знать, что mongo поднялась (ей на это время нужно). Чтобы заполнять эластик вам нужно тоже дождаться, пока подымется эластик. Сам docker-compose всё это не умеет. Те поднять всё одной командой docker-compose up api без вороха sh-скриптов не выйдет.
Это использовать эластик как полнотекстовый поиск, а документы хранить в mongo/postgresql.
usego
Зачем весь этот рестор, если можно иметь докера с уже проиндексированными данными? Оно ведь для разработки. Достаточно иметь плюс минус актуальный снэпшот.
musuk
Так для разработки и нужно, чтобы каждое добавление поля в базу бэкендером сразу же было доступно фронтам. Причём чем интенсивнее разработка, тем быстрее должно обновляться API и база.
Иметь образа с данными можно, но строить такие образы намного сложнее. По мне пока самый простой способ, это делать образ уже запущенного и модифицированного контейнера. Те я не знаю, как описать рестор данных в рамках Dockerfile.
Потом для автоматического построения всех этих образов нужна инфраструктура, причём она должна куда-то публиковать образа. А образа должны быть специфичны для веток в которых идёт разработка. Ведь в разных ветках могут быть разные поля в базе. Ну и операция переключения между ветками для фронта будет тоже не такой тривиальной.
usego
Мы используем локальный гитлаб, там вся необходимая инфраструктура встроена. Да, время вложить в «поразбираться» придётся, но где это сейчас не требуется? Я это к тому, что проблемы как таковой нет, при наличии правильного инструментария и процессов.
Avdeev Автор
Отличное замечание, я про это не рассказал.
Действительно, полностью избавиться от инструкций и команд не получается.
Мы делаем вот так:
1. docker-compose up api собирает связанные через depends_on образы и запускает их.
2. Все команды на запущенных контейнерах стараемся убирать в Makefile.
Что-то вроде:
Stormwalker
depends_on не делает liveness-readiness проверок, просто проверяет состояние контейнера. Лучше уж сказать, чтобы сделал
и увидел заветную запись в логах, если надо что-то сделать. Еще есть костыли типа wait-for-it.sh.Команды в Makefile поддерживаю, главное чтобы они не расползались по другим местам :)