
В некоторых случаях (частично от незнания возможностей БД, частично от преждевременных оптимизаций) такой подход приводит к появлению «франкенштейнов».
Сначала приведу пример такого запроса:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Чтобы предметно оценивать качество запроса, давайте создадим некий произвольный набор данных:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
Оказывается, само чтение данных заняло меньше четверти всего времени выполнения запроса:
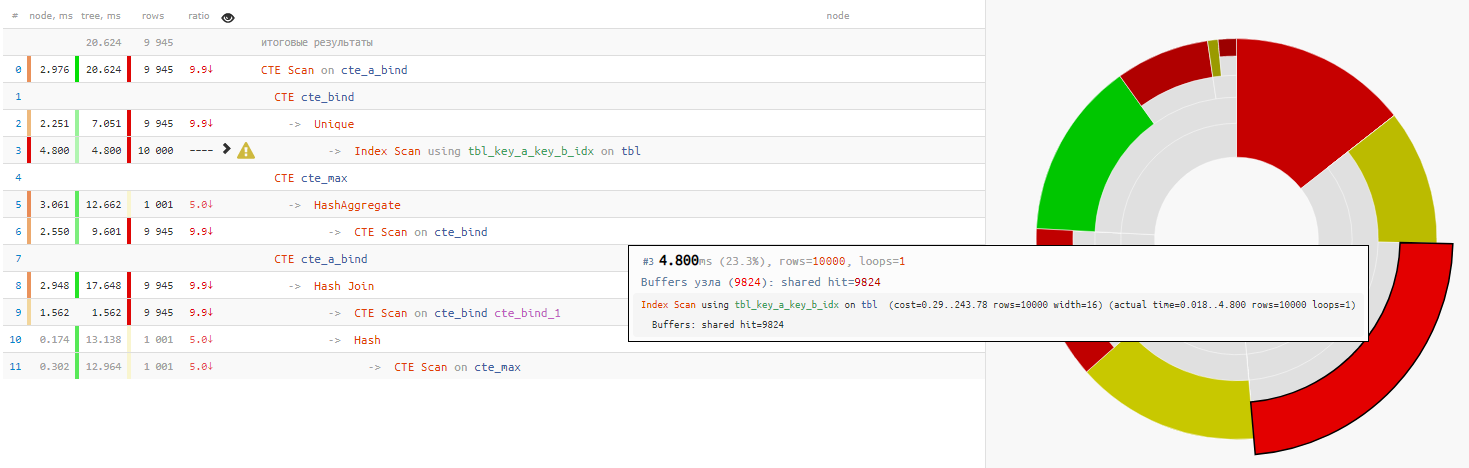 [посмотреть на explain.tensor.ru]
[посмотреть на explain.tensor.ru]Разбираем по косточкам
Пристально посмотрим на запрос, и озадачимся:
- Зачем тут WITH RECURSIVE, если никаких рекурсивных CTE — нету?
- Зачем группировать min/max-значения в отдельной CTE, если потом они все равно привязываются к оригинальной выборке?
+25% времени - Зачем использовать в конце повторную начитку из предыдущей CTE через безусловный 'SELECT * FROM'?
+14% времени
В данном случае нам еще сильно повезло, что для соединения был выбран Hash Join, а не Nested Loop, поскольку тогда мы получили бы не один-единственный проход CTE Scan, а 10K!
Собственно, а что хотели получить-то в результате? Ага, обычно именно такой вопрос и посещает где-то на 5й минуте разбора «трехэтажных» запросов.
Мы хотели для каждой уникальной ключевой пары вывести min/max из группы по key_a.
Так воспользуемся же для этого оконными функциями:
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a);
[посмотреть на explain.tensor.ru]
Поскольку чтение данных в обоих вариантах занимает одинаково примерно 4-5ms, то весь наш выигрыш по времени -32% — это в чистом виде нагрузка, убранная с CPU базы, если такой запрос выполняется достаточно часто.
В общем, не стоит базу заставлять «круглое — носить, квадратное — катать».
Комментарии (13)

a1888877
09.12.2019 13:12+1Ну ничего себе вредные советы…
Во первый CTE в Oracle, MS SQL Server и PostgreSQL разный. И в первых двух ничего подобного множеству «CTE Scan» не будет — они прекрасно буферизируют результаты CTE запросов. Поэтому для Oracle и SQL Server, в некоторых кейсах наоборот выгодно вынести подзапрос в CTE выражение, чтобы избежать множества повторных чтений данных.
Во вторых, хотя бы версию PostgreSQL указали — может в следующей работу с CTE подправят, и таких «особенностей» уже не будет.
Ну и вообще причина такого поведения базы не в том, что она ваш запрос обработать не может, а в индивидуальных особенностях PostgreSQL. А там эти особенности от того, что её Enterprise вариации хвастают фичами прикрывающими эти проблемы — и переносить их в upstream не очень выгодно, хотя кое-что и просачивается.
Kilor Автор
09.12.2019 13:15Я не говорил, что использовать CTE — плохо. Но вот джойнить их при больших размерах (конкретно в PG, конкретно во всех известных на данный момент версиях) — дорого. И если есть способ этого не делать, то лучше им воспользоваться.
a1888877
09.12.2019 13:34+1Я согласен, что джоинить, при больших размерах — дорого. Но придти к этому выводу по вашей статье очень сложно. Заголовок и текст посвящены CTE, вывод общий, без упоминания джионов. Да и проблема с множественным «CTE Scan» операции Join все-же ну совсем ортогональна.
И вторая проблема в другом — если не считать упоминания блога PostgreSQL, то СУБД больше нигде не упомянута. Т.е., как-бы, по отдельному плану выполнения запросов (без указания СУБД и версии) Вы делаете обобщенный вывод про все БД в целом. И получается, что Ваша статья может легко ввести в заблуждение, если человек не обладает достаточным опытом.
На самом деле у Вас могла бы выйти очень хорошая статья. Нужно только немного конкретики — более явно указать СУБД и написать про её версии, сравнить с другими и написать, что это особенность PostgreSQL, указать, что может эту особенность исправят. В выводе отметить, что CTE x CTE в PostgreSQL может привести к такому эффекту, и вообще джоинить до фильтрации данных — плохо. Это и не вводило бы неопытных/невнимательных разработчиков в заблуждение и было бы хорошей отсылкой к Вашему https://explain.tensor.ru.Kilor Автор
09.12.2019 14:57Заголовок и проблематика посвящены декартову произведению CTE. И такое положение дел сохранится, как минимум, следующие пару мажорных версий PG, а пока они доберутся до прода — то и на все лет 5 тема актуальна. Ну и я не делал выводов относительно "всех СУБД", пост же в профильный блог включен, и планы вполне конкретные.
А где было про джойн раньше фильтрации?a1888877
09.12.2019 19:37Здесь есть статьи, которым больше пяти лет. Все же, укажите Вы в тексте статьи версии PostgreSQL на которых это проверяли и было бы более информативно. Насчет выводов «всех СУБД» — пока вы не исправили заголовок и не появились комментарии на PostgreSQL указывала только одна маленькая ссылка под большим заголовком, которую просто пропустить. А для идентификации СУБД по планам, все же нужен опыт. Отсюда и вывод, что легко запутать неопытных/невнимательных читателей.
Насчет слов про фильтрацию — это отсылка к «джойнить их при больших размерах — плохо». Даже такой CTE x CTE в текущем PostgreSQL совсем не плох, если фильтрует данные и возвращает условный десяток строк. И это относится к любому join, не важно, чем он оперирует.Kilor Автор
09.12.2019 20:59Проблема ровно в том, что CTE Scan из 10k записей будет гораздо медленнее, чем Index Scan из таблицы того же размера. А при 100 записях они будут занимать примерно одинаковый объем в памяти, и доступ к CTE тоже не будет быстрее. В силу того факта, что является неиндексированной структурой.
- видимо, после каждой фразы нужно добавлять дисклеймер, что речь только про PostgreSQL версий вплоть до 13, и, возможно, дальше :)
dss_kalika
Ну, это, на самом деле, не проблема CTE.
Люди очень любят в любого рода подзапросах джоинить таблицу на саму себя с какими то расчитанными значениями…
Основной посыл — если таблица джоинится на себя по ключу — значит что то пошло не так. (ну это в общем случае)
Kilor Автор
Джойнить таблицу — это не всегда плохо, для нее хотя бы возможен Index [Only] Scan. А вот для CTE ничего такого нет, и на обозримом горизонте не предвидится.
dss_kalika
Ну, кстати, в MS SQL второй вариант даже немного дольше выполняется )
Kilor Автор
Кстати, это интересно — так хорошо сделан CTE Scan или так плохо PARTITION BY?
dss_kalika
«CTE scan» нормально разобран. План запроса вообще примерно одинаковый )
Но это просто из-за того что природа CTE в MS и Postgre разная. Так что и проблемы такой нет )