
 Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?
Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?Это одна из ключевых и классических задач Natural Language Processing (NLP). Она заключается в создании алгоритма, который принимает на вход текст и на выходе выдаёт его сокращённую версию. Причем в ней сохраняется корректная структура (соответствующая нормам языка) и правильно передается основная мысль текста.
Такие алгоритмы широко используются в индустрии. Например, они полезны для поисковых движков: с помощью сокращения текста можно легко понять, коррелирует ли основная мысль сайта или документа с поисковым запросом. Их применяют для поиска релевантной информации в большом потоке медиаданных и для отсеивания информационного мусора. Сокращение текста помогает в финансовых исследованиях, при анализе юридических договоров, аннотировании научных работ и многом другом. Кстати, алгоритм саммаризации сгенерировал и все подзаголовки для этого поста.
К моему удивлению, на Хабре оказалось совсем немного статей о саммаризации, поэтому я решил поделиться своими исследованиями и результатами в этом направлении. В этом году я участвовал в соревновательной дорожке на конференции «Диалог» и ставил эксперименты над генераторами заголовков для новостных заметок и для стихов с помощью нейронных сетей. В этом посте я вначале вкратце пробегусь по теоретической части саммаризации, а затем приведу примеры с генерацией заголовков, расскажу, какие трудности возникают у моделей при сокращении текста и как можно эти модели улучшить, чтобы добиться выдачи более качественных заголовков.
Ниже — пример новости и ее оригинального эталонного заголовка. Модели, о которых я буду рассказывать, будут тренироваться генерировать заголовки на этом примере:

Секреты сокращения текста архитектуры seq2seq
Выделяют два типа методов сокращения текста:
- Извлекающий. Он заключается в нахождении наиболее информативных частей текста и конструировании из них корректной для данного языка аннотации. Эта группа методов использует только те слова, которые есть в исходном тексте.
- Абстрактный. Заключается в извлечении смысловых связей из текста, при этом учитываются языковые зависимости. При абстрактной саммаризации слова аннотации выбираются не из сокращаемого текста, а из словаря (списка слов для данного языка) — тем самым происходит перефразирование основной мысли.
Второй подход подразумевает, что алгоритм должен учитывать языковые зависимости, перефразировать и обобщать. Ещё ему желательно иметь какие-то знания о реальном мире, чтобы не допускать фактических ошибок. Долгое время это считалось сложной задачей, и исследователи не могли получить качественного решения — грамматически верного текста с сохранением основной мысли. Именно поэтому в прошлом большинство алгоритмов основывалось на извлекающем подходе, так как выделение цельных кусков текста и перенос их в результат позволяет сохранить тот же уровень грамотности, что и у источника.
Но так было до бума нейронных сетей и его неминуемого проникновения в NLP. В 2014 году была представлена архитектура seq2seq с механизмом внимания, способная читать одни текстовые последовательности и генерировать другие (какие именно – зависит от того, что училась выводить модель) (статья от Sutskever et al.). В 2016 году такую архитектуру применили непосредственно к решению задачи саммаризации, тем самым реализовав абстрактный подход и получив результат, сравнимый с тем, что мог бы написать грамотный человек (статья от Nallapati et al., 2016; статья от Rush et al., 2015;). Как же устроена эта архитектура?
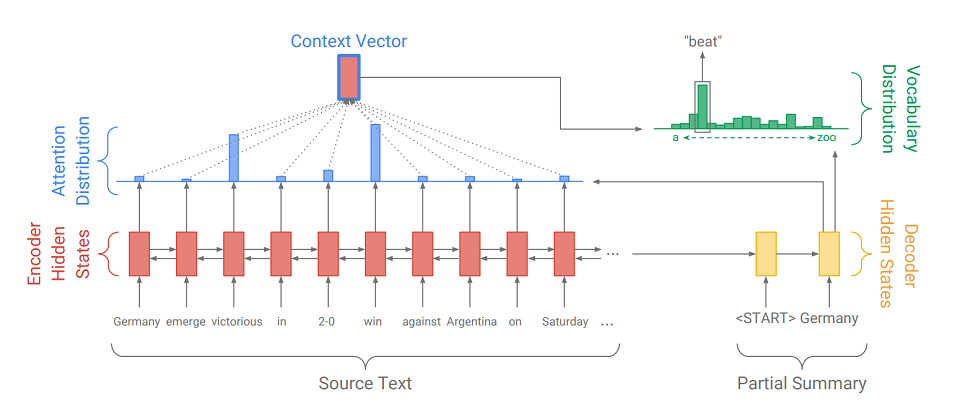
Seq2Seq состоит из двух частей:
- кодировщика (Encoder) – это двухсторонний RNN, который используется для чтения входной последовательности, то есть последовательно обрабатывает элементы входа одновременно слева направо и справа налево для лучшего учёта контекста.
- декодировщика (Decoder) – односторонний RNN, который последовательно и поэлементно выдаёт выходную последовательность.
Сначала входная последовательность переводится в последовательность эмбеддингов (если вкратце, то эмбеддинг — сжатое представление о слове в виде вектора). Затем эмбеддинги проходят через рекуррентную сеть кодировщика. Так мы на каждое слово получаем скрытые состояния кодировщика (обозначены на схеме красными прямоугольниками), а они содержат в себе информацию как о самом токене, так и о его контексте, позволяя учитывать языковые связи между словами.
Обработав вход, кодировщик передаёт своё последнее скрытое состояние (которое содержит сжатую информацию обо всём тексте) декодировщику, который принимает на вход специальный токен
 и создаёт первое слово выходной последовательности (на картинке это «Germany»). Затем он циклично берёт свой предыдущий выход, подаёт его себе на вход и снова выводит очередной элемент выхода (так после «Germany» идёт «beat», а после «beat» идёт следующее слово и т.д.). Так повторяется до тех пор, пока не выдастся специальный токен
и создаёт первое слово выходной последовательности (на картинке это «Germany»). Затем он циклично берёт свой предыдущий выход, подаёт его себе на вход и снова выводит очередной элемент выхода (так после «Germany» идёт «beat», а после «beat» идёт следующее слово и т.д.). Так повторяется до тех пор, пока не выдастся специальный токен 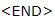 . Это означает окончание генерации.
. Это означает окончание генерации.Чтобы вывести очередной элемент, декодировщик точно так же, как и кодировщик, преобразует входной токен в эмбеддинг, делает шаг рекуррентной сети и получает очередное скрытое состояние декодировщика (жёлтые прямоугольники на схеме). Затем из него при использовании полносвязного слоя получается распределение вероятности по всем словам из заранее составленного словаря модели. Наиболее вероятные слова и будут выведены моделью.
Добавление механизма внимания помогает декодировщику лучше использовать информацию о входном тексте. Механизм на каждом шаге генерации определяет так называемое распределение внимания (синие прямоугольники на рисунке — множество весов, соответствующих элементам исходной последовательности, сумма весов равна 1, все веса >= 0), а из него получает взвешенную сумму всех скрытых состояний кодировщика, тем самым образуя вектор контекста (на схеме — красный прямоугольник с синей обводкой). Этот вектор конкатенируется с эмбеддингом входного слова декодировщика на этапе вычисления скрытого состояния и с самим скрытым состоянием на этапе определения следующего слова. Так на каждом шаге вывода модель может определить, какие состояния кодировщика ей важнее всего на данный момент. Иначе говоря, решает, контекст каких слов входа нужно учитывать больше всего (например, на картинке, выводя слово «beat», механизм внимания даёт большие веса токенам «victorious» и «win», а остальным – близкие нулю).
Так как генерация заголовков тоже одна из задач саммаризации, только с минимально возможным выводом (1-12 слов), то я решил применить seq2seq с механизмом внимания и для нашего случая. Обучаем такую систему на текстах с заголовками, например, на новостях. Причём желательно на этапе обучения подавать на вход декодировщику не его собственный выход, а слова реального заголовка (приём teacher forcing), облегчая жизнь себе и модели. В качестве функции ошибки используем стандартную кросс-энтропийную функцию потерь, показывающую, насколько близки вероятностные распределения выходного слова и слова из реального заголовка:
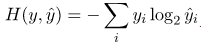
При использовании обученной модели применяем лучевой поиск для нахождения более вероятной последовательности слов, чем при использовании жадного алгоритма. Для этого на каждом шаге генерации выводим не самое вероятное слово, а одновременно смотрим на beam_size наиболее вероятных последовательностей слов. Когда они закончатся (каждый из них окончится на
), выведем самую вероятную последовательность.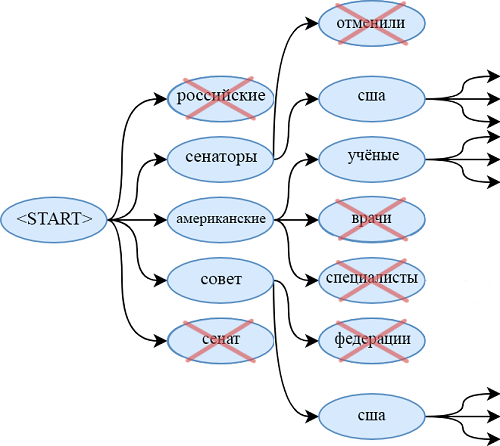
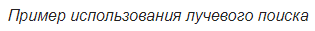


Эволюция модели
Одна из проблем модели на seq2seq – это невозможность привести слова, которых нет в словаре. Например, у модели нет никаких шансов вывести «obamacare» из статьи выше. То же самое касается:
- редких фамилий и имён,
- новых терминов,
- слов на других языках,
- различных пар слов, соединённых дефисом (как «сенатор-республиканец»)
- и прочих конструкций.
Конечно, можно расширить словарь, но это сильно увеличивает количество обучаемых параметров. Кроме того, нужно обеспечить большое количество документов, в которых встречаются эти редкие слова, чтобы генератор научился качественно их использовать.
Другое и более элегантное решение данной проблемы было представлено в статье 2017 года – «Get To The Point: Summarization with Pointer-Generator Networks» (Abigail See et al.). Она добавляет новый механизм в нашу модель – механизм указывания (pointer), который умеет выбирать слова из исходного текста и непосредственно вставлять в генерируемую последовательность. Если в тексте встречается OOV (out of vocabulary – слово, отсутствующее в словаре), то модель, если она посчитает это нужным, может вычленить OOV и вставить его на выходе. Такая система называется «указыватель-генератор» (pointer-generator или pg) и представляет собой синтез сразу двух подходов к саммаризации. Она сама может решать, на каком шаге ей быть абстрактной, а на каком – извлекающей. Как она это делает, мы сейчас и разберемся.
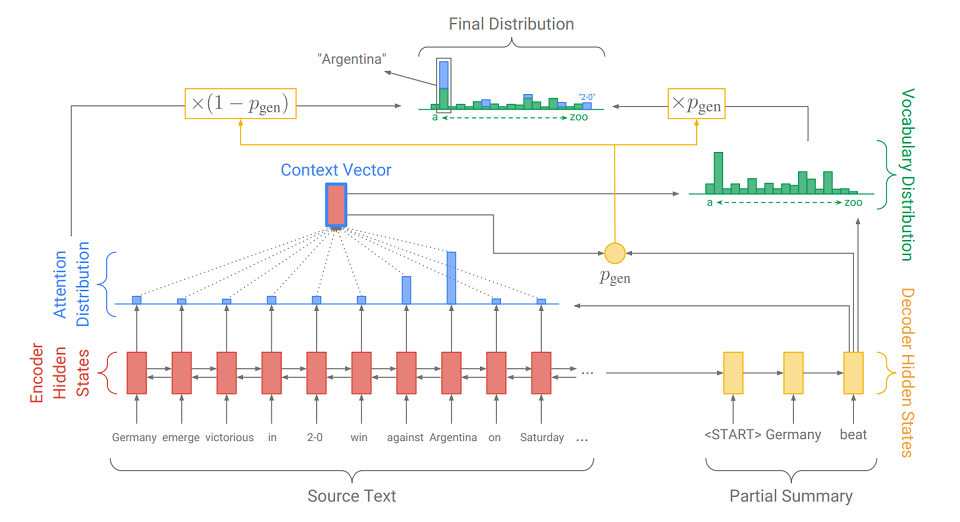
Основное отличие от модели на обычном seq2seq заключается в дополнительном действии, на котором вычисляется pgen – вероятность генерации. Это делается с использованием скрытого состояния декодера и контекстного вектора. Смысл дополнительного действия прост. Чем ближе pgen к 1, тем более вероятно, что модель выдаст слово из своего словаря, используя абстрактную генерацию. Чем ближе pgen к 0, тем более вероятно, что генератор извлечёт слово из текста, руководствуясь полученным ранее распределением внимания. Итоговое распределение вероятности выдачи слов складывается из сгенерированного распределения вероятности по словам (в котором нет OOV), домноженного на pgen, и распределения внимания (в котором OOV есть, например, «2-0» на картинке), домноженного на (1 — pgen).

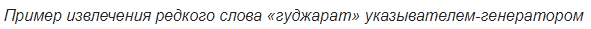
Кроме механизма указывания в статье вводится механизм покрытия (coverage), который помогает избежать повторения слов. Я также проводил эксперименты с ним, но не заметил значительных улучшений в качестве заголовков – он не очень-то и нужен. Скорее всего, это происходит из-за специфики задачи: так как выводить надо небольшое количество слов, генератор просто не успевает повторить себя самого. Зато для других задач саммаризации, например, аннотирования, он может пригодиться. Если интересно, то можете прочесть о нём в оригинальной статье.


Великое многообразие русских слов
Ещё один способ улучшить качество выдаваемых заголовков — это правильный препроцессинг входной последовательности. Кроме очевидного избавления от прописных символов, я также пробовал преобразовывать слова из исходного текста в пары стем и флексий (т.е. основ и окончаний). Для разбиения используем стеммер Портера.

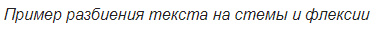
Помечаем все флексии символом «+» в начале, чтобы отличать их от других токенов. Рассматриваем каждую стему и флексию как отдельное слово и обучаемся на них точно так же, как и на словах. То есть получаем из них эмбеддинги и выводим последовательность (так же разбитую на основы и окончания), которую можно легко превратить в слова.
Такое преобразование очень полезно в случае работы с морфологически богатыми языками, как русский. Вместо того чтобы составлять огромные словари с великим многообразием русских словоформ, можно ограничиться большим количеством основ этих слов (их в несколько раз меньше, чем количество словоформ) и совсем маленьким набором окончаний (у меня получилось множество из 450 флексий). Тем самым мы облегчаем модели работу с этим «богатством» и при этом не повышаем сложность архитектуры и количество параметров.

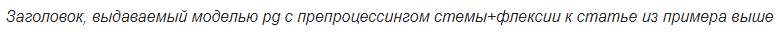
Также я пробовал использовать преобразование лемма+граммемы. То есть из каждого слова перед обработкой можно получить его начальную форму и грамматическое значение с помощью пакета pymorphy (например, «была»
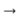 «быть» и «VERB|impf|past|sing|femn»). Таким образом я получил пару параллельных последовательностей (в одной – начальные формы, в другой – грамматические значения). Для каждого типа последовательности я составлял свои эмбеддинги, которые затем конкатенировал и уже подавал на описанный ранее пайплайн. В нем декодировщик учился выдавать не слово, а лемму и граммемы. Но такая система не принесла видимых улучшений по сравнению с pg на стемах. Возможно, дело было в излишне простой архитектуре для работы с грамматическими значениями, и стоило создать отдельный классификатор для каждой грамматической категории на выходе. Но я не проводил экспериментов с такими или более сложными моделями.
«быть» и «VERB|impf|past|sing|femn»). Таким образом я получил пару параллельных последовательностей (в одной – начальные формы, в другой – грамматические значения). Для каждого типа последовательности я составлял свои эмбеддинги, которые затем конкатенировал и уже подавал на описанный ранее пайплайн. В нем декодировщик учился выдавать не слово, а лемму и граммемы. Но такая система не принесла видимых улучшений по сравнению с pg на стемах. Возможно, дело было в излишне простой архитектуре для работы с грамматическими значениями, и стоило создать отдельный классификатор для каждой грамматической категории на выходе. Но я не проводил экспериментов с такими или более сложными моделями.Я экспериментировал с еще одним добавлением в оригинальную архитектуру указывателя-генератора, которое, правда, не относится к препроцессингу. Это увеличение количества слоёв (до 3-х) рекуррентных сетей кодировщика и декодировщика. Увеличение глубины рекуррентной сети может повысить качество выдаваемых результатов, так как скрытое состояние последних слоёв может содержать информацию о гораздо более длинной подпоследовательности входа, чем скрытое состояние однослойного RNN. Это способствует учёту сложных протяжённых смысловых связей между элементами входной последовательности. Правда, это обходится значительным увеличением числа параметров модели и усложняет обучение.

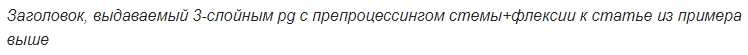
Эксперименты с генераторами заголовков
Все мои эксперименты над генераторами заголовков можно разделить на два типа: эксперименты с новостными статьями и со стихами. Расскажу о них по порядку.
Эксперименты с новостями
При работе с новостями я применял такие модели, как seq2seq, pg, pg со стемами и флексиями – однослойный и трёхслойный. Я также рассматривал модели, работающие с граммемами, но всё, что я хотел о них поведать, я уже описал выше. Сразу оговорюсь, что все описываемые в этом разделе pg использовали механизм покрытия, хотя его влияние на результат сомнительно (так как без него было не намного хуже).
Тренировался я на датасете РИА «Новости», который предоставило новостное агентство «Россия сегодня» для проведения дорожки по генерации заголовков на конференции «Диалог». Датасет содержит 1 003 869 новостных статей, опубликованных с января 2010 года по декабрь 2014-го.
Все исследуемые модели использовали один и тот же размер эмбеддингов (128), словаря (100k) и скрытого состояния (256) и тренировались в течение одинакового количество эпох. Поэтому повлиять на результат могли лишь качественные изменения в архитектуре либо в препроцессинге.
Модели, заточенные на работу с предобработанным текстом, дают более хорошие результаты, чем модели, работающие со словами. Лучше всего справляется трёхслойный pg, использующий информацию о стемах и флексиях. При использовании любого pg также проявляется ожидаемое улучшение качества заголовков по сравнению с seq2seq, что намекает нам на предпочтительное использование указателя при генерации заголовков. Вот и пример работы всех моделей:

Глядя на генерируемые заголовки, можно выделить у исследуемых моделей такие проблемы:
- Модели часто используют неправильные формы слов. От этого недостатка в большей степени избавлены модели со стемами (как в примере выше);
- Все модели, кроме тех что работают со стемами, могут выдавать заголовки, которые кажутся незаконченными, либо странные конструкции, которых нет в языке (как в примере выше);
- Все исследуемые модели часто путают описываемых персон, подставляют неправильные даты или используют не совсем подходящие слова.


Эксперименты со стихами
Так как у трехслойного pg со стемами меньше всего неточностей в генерируемых заголовках, именно эту модель я выбрал для экспериментов со стихами. Я обучал её на корпусе, составленном из 6 миллионов русских стихотворений с сайта «stihi.ru». Они включают любовную (этой теме посвящены примерно половина стихов), гражданскую (примерно четверть), городскую и пейзажную поэзию. Период написания: январь 2014 — май 2019. Приведу примеры генерируемых заголовков для стихов:



Модель получилась в основном извлекающей: почти все заголовки представляют собой одну строку, зачастую извлечённую из первой или последней строфы. В исключительных случаях модель может сгенерировать слова, которых в стихотворении нет. Это объясняется тем, что очень большое количество текстов в корпусе действительно имеют в качестве названия одну из строк.
В качестве заключения скажу, что указыватель-генератор, работающий на стемах и использующий однослойные декодировщик и кодировщик, занял второе место на соревновательной дорожке по генерации заголовков для новостных статей на научной конференции по компьютерной лингвистике «Диалог». Основной организатор этой конференции — ABBYY, компания занимается исследованиями практически по всем современным направлениям Natural Language Processing.
Напоследок, предлагаю вам небольшой интерактив: присылайте в комментарии новости, и посмотрим, какие заголовки для них сгенерирует нейросеть.
Матвей, разработчик в NLP Group в ABBYY
Комментарии (8)

mjmartmail
13.12.2019 17:56А можно ли этот алгоритм прикрутить к форуму? Чтобы все комментарии просеивались через такую "сетку", а на выходе иметь, например, 3 уровня детализации: "сокращённо", "средне", "подробно". Чтобы не было необходимости перечитывать всю ленту. Чтобы можно было сразу увидеть тезисно основные мысли озвученные комментаторами. Чтобы повторяющиеся и близкие по содержанию комментарии группировались. К чтобы наиболее важные, уникальное и интересные мысли поднимались вверх, в начало текста, а глупые и неинтересные опускались вниз ленты или удалялись. Думаю это значительно приблизило бы нас к краудсорсинговым социальным сетям. Будущее за коллективным мышлением онлайн усиленным искусственным интеллектом.

ABBYYTeam Автор
13.12.2019 17:56У форума структура сложная, там в общем случае, нет какого-то одного повествования, а куча разных мнений. Не говоря уже о том, что в одном форуме может одновременно вестись несколько разговоров параллельно между несколькими группами людей, а также могут быть просто высказывания в пустоту — короче, хаос. Чтобы такое сокращать, нужно заранее определять, какие сообщения к чему и к кому относятся (для чего нужна отдельная программа, а по-хорошему тоже нейросеть — только как её сделать?), затем сложить из этих сообщений что-то похожее на пьесу в нескольких явлениях (одно явление — общение между определённой группой людей), а затем попробовать пройтись описанным в статье алгоритмом. Либо сразу обучать генератор заголовков (можно описанный, а можно на трансформерах, используя BERT) на форумном тексте (желательно, чтобы в нём до подачи на сеть особым образом выделялись лица разговора, цитирования и прочие форумные штуки).
Для каждого уровня обобщения нужно найти соответствующую обучающую выборку на 100k+ текстов (может, и меньше, я не проводил экспериментов, как ухудшается качество от размера обучающей выборки) и попробовать запустить сетку.
В этом ещё одна проблема. Нужны не просто тексты форумов, а также сокращения текстов форумов, которые я, например, никогда не видел. Значит, их придётся составлять самому, что очень дорого.
TiesP
Я вот слышал, что сейчас практически «во всех задача NLP» лучшие результаты показывают модели, основанные на BERT, только дополнительно дообучающиеся под специфику задачи. Вы не пробовали использовать для решения этой задачи BERT?
Ещё не совсем понятен этот момент:
Имеется в виду, что тестовые данные содержат новые слова, которых не было в тренировочных?
ABBYYTeam Автор
Нет, к сожалению, BERT не пробовал.
Насчёт момента с невозможностью вывода несловарных слов. Имеется в виду, что абстрактные модели составляют заголовок только из слов, взятых из заранее заданного множества (собственно, словаря). Если в исходном тексте будет важное слово, которого не будет в словаре, то абстрактная модель его подставить в заголовок его не сможет. Это касается и тренировочных данных, и тестовых.
TiesP
Тогда уточню ещё, чтобы до конца понять, что это за обрезанный словарь)
Видимо, словарь образуется из всего массива данных, но за исключением редких слов (и «obamacare» как раз отбросился)?
Или же он берётся из какой-то pretrained модели (из другого массива текстов)?
ABBYYTeam Автор
Словарь я готовил отдельно, он не зависит от данных, на которых проходит обучение.
Если быть точнее, то для своих экспериментов я просто находил какие-нибудь предобученные эмбеддинги (например, отсюда http://docs.deeppavlov.ai/en/master/features/pretrained_vectors.html), смотрел для каких слов они были составлены, брал первые 100k (можно больше, но от этого усложняется модель). Сами предобученные эмбеддинги, кстати, не использовал.
Судя по происхождению файла с эмбеддингами, откуда я брал слова, можно сказать, что я составил словарь из 100k самых частотных слов Википедии и корпуса Ленты, расположенных в порядке частотности.
TiesP
Теперь ясно, спасибо