
Статья состоит из двух частей:
- Краткое описание некоторых архитектур сетей по обнаружению объектов на изображении и сегментации изображений с самыми понятными для меня ссылками на ресурсы. Старался выбирать видео пояснения и желательно на русском языке.
- Вторая часть состоит в попытке осознать направление развития архитектур нейронных сетей. И технологий на их основе.

Рисунок 1 – Понимать архитектуры нейросетей непросто
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- Back-end demo, когда данные обрабатываются на сервере и передаются на телефон. Классификация изображений (image classification) трех типов медведей: бурого, черного и плюшевого.
- Front-end demo, когда данные обрабатываются на самом телефоне. Обнаружение объектов (object detection) трех типов: фундук, инжир и финик.
Есть разница между задачами по классификации изображений, обнаружению объектов на изображении и сегментацией изображений. Поэтому появилась необходимость узнать, какие архитектуры нейросетей обнаруживают объекты на изображениях и какие могут сегментировать. Нашел следующие примеры архитектур с самыми понятными для меня ссылками на ресурсы:
- Серия архитектур на основе R-CNN (Regions with Convolution Neural Networks features): R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN. Для обнаружения объекта на изображении с помощью механизма Region Proposal Network (RPN) выделяются ограниченные регионы (bounding boxes). Первоначально вместо RPN применялся более медленный механизм Selective Search. Затем выделенные ограниченные регионы подаются на вход обычной нейросети для классификации. В архитектуре R-CNN есть явные циклы «for» перебора по ограниченным регионам, всего до 2000 прогонов через внутреннюю сеть AlexNet. Из-за явных циклов «for» замедляется скорость обработки изображений. Количество явных циклов, прогонов через внутреннюю нейросеть, уменьшается с каждой новой версией архитектуры, а также проводятся десятки других изменений для увеличения скорости и для замены задачи обнаружения объектов на сегментацию объектов в Mask R-CNN.
- YOLO (You Only Look Once) – первая нейронная сеть, которая распознавала объекты в реальном времени на мобильных устройствах. Отличительная особенность: различение объектов за один прогон (достаточно один раз посмотреть). То есть в архитектуре YOLO нет явных циклов «for», из-за чего сеть работает быстро. Например, такая аналогия: в NumPy при операциях с матрицами тоже нет явных циклов «for», которые в NumPy реализуются на более низких уровнях архитектуры через язык программирования С. YOLO использует сетку из заранее заданных окон. Чтобы один и тот же объект не определялся многократно, используется коэффициент перекрытия окон (IoU, Intersection over Union). Данная архитектура работает в широком диапазоне и обладает высокой робастностью: модель может быть обучена на фотографиях, но при этом хорошо работать на рисованных картинах.
- SSD (Single Shot MultiBox Detector) – используются наиболее удачные «хаки» архитектуры YOLO (например, non-maximum suppression) и добавляются новые, чтобы нейросеть быстрее и точнее работала. Отличительная особенность: различение объектов за один прогон с помощью заданной сетки окон (default box) на пирамиде изображений. Пирамида изображений закодирована в сверточных тензорах при последовательных операциях свертки и пулинга (при операции max-pooling пространственная размерность убывает). Таким образом определяются как большие, так и маленькие объекты за один прогон сети.
- MobileSSD (MobileNetV2 + SSD) – комбинация из двух архитектур нейросетей. Первая сеть MobileNetV2 работает быстро и увеличивает точность распознавания. MobileNetV2 применяется вместо VGG-16, которая первоначально использовалась в оригинальной статье. Вторая сеть SSD определяет местоположение объектов на изображении.
- SqueezeNet – очень маленькая, но точная нейросеть. Сама по себе не решает задачу обнаружения объектов. Однако может применяться при комбинации различных архитектур. И использоваться в мобильных устройствах. Отличительной особенностью является то, что сначала данные сжимаются до четырех 1?1 сверточных фильтров, а затем расширяются до четырех 1?1 и четырех 3?3 сверточных фильтров. Одна такая итерация сжатия-расширения данных называется «Fire Module».
- DeepLab (Semantic Image Segmentation with Deep Convolutional Nets) – сегментация объектов на изображении. Отличительной особенностью архитектуры является разряженная (dilated convolution) свертка, которая сохраняет пространственное разрешение. Затем следует стадия постобработки результатов с использованием графической вероятностной модели (conditional random field), что позволяет убрать небольшие шумы в сегментации и улучшить качество отсегментированного изображения. За грозным названием «графическая вероятностная модель» скрывается обычный фильтр Гаусса, который аппроксимирован по пяти точкам.
- Пытался разобраться в устройстве RefineDet (Single-Shot Refinement Neural Network for Object Detection), но мало чего понял.
- Также посмотрел, как работает технология «внимание» (attention): видео1, видео2, видео3. Отличительной особенностью архитектуры «внимание» является автоматическое выделение регионов повышенного внимания на изображении (RoI, Regions of Interest) с помощью нейросети под названием Attention Unit. Регионы повышенного внимания похожи на ограниченные регионы (bounding boxes), но в отличие от них не зафиксированы на изображении и могут иметь размытые границы. Затем из регионов повышенного внимания выделяются признаки (фичи), которые «скармливаются» рекуррентным нейросетям с архитектурами LSDM, GRU или Vanilla RNN. Рекуррентные нейросети умеют анализировать взаимоотношение признаков в последовательности. Рекуррентные нейросети изначально применялись для переводов текста на другие языки, а теперь и для перевода изображения в текст и текста в изображение.
По мере изучения этих архитектур я понял, что ничего не понимаю. И дело не в том, что у моей нейросети есть проблемы с механизмом внимания. Создание всех этих архитектур похоже на какой-то огромный хакатон, где авторы соревнуются в хаках. Хак (hack) – быстрое решение трудной программной задачи. То есть между всеми этими архитектурами нет видимой и понятной логической связи. Все, что их объединяет – это набор наиболее удачных хаков, которые они заимствуют друг у друга, плюс общая для всех операция свертки с обратной связью (обратное распространение ошибки, backpropagation). Нет системного мышления! Не понятно, что менять и как оптимизировать имеющиеся достижения.
Как результат отсутствия логической связи между хаками, их чрезвычайно трудно запомнить и применить на практике. Это фрагментированные знания. В лучшем случае запоминаются несколько интересных и неожиданных моментов, но большинство из понятого и непонятного исчезает из памяти уже через несколько дней. Будет хорошо, если через неделю вспомнится хотя бы название архитектуры. А ведь на чтение статей и просмотр обзорных видео было потрачено несколько часов и даже дней рабочего времени!
Рисунок 2 – Зоопарк нейронных сетей
Большинство авторов научных статей, по моему личному мнению, делают все возможное, чтобы даже эти фрагментированные знания были не поняты читателем. Но деепричастные обороты в десяти строковых предложениях с формулами, которые взяты «с потолка» – это тема для отдельной статьи (проблема publish or perish).
По этой причине появилась необходимость систематизировать информацию по нейросетям и, таким образом, увеличить качество понимания и запоминания. Поэтому основной темой разбора отдельных технологий и архитектур искусственных нейронных сетей стала следующая задача: узнать, куда это все движется, а не устройство какой-то конкретной нейросети в отдельности.
Куда все это движется. Основные результаты:
- Число стартапов в области машинного обучения в последние два года резко упало. Возможная причина: «нейронные сети перестали быть чем-то новым».
- Каждый сможет создать работающую нейросеть для решения простой задачи. Для этого возьмет готовую модель из «зоопарка моделей» (model zoo) и натренирует последний слой нейросети (transfer learning) на готовых данных из Google Dataset Search или из 25-ти тысяч датасетов Kaggle в бесплатном облаке Jupyter Notebook.
- Крупные производители нейросетей начали создавать «зоопарки моделей» (model zoo). С помощью них можно быстро сделать коммерческое приложение: TF Hub для TensorFlow, MMDetection для PyTorch, Detectron для Caffe2, chainer-modelzoo для Chainer и другие.
- Нейросети, работающие в реальном времени (real-time) на мобильных устройствах. От 10 до 50 кадров в секунду.
- Применение нейросетей в телефонах (TF Lite), в браузерах (TF.js) и в бытовых предметах (IoT, Internet of Things). Особенно в телефонах, которые уже поддерживают нейросети на уровне «железа» (нейроакселераторы).
- «Каждое устройство, предметы одежды и, возможно, даже пища будут иметь IP-v6 адрес и сообщаться между собой» – Себастьян Трун.
- Рост количества публикаций по машинному обучению начал превышать закон Мура (удвоение каждые два года) с 2015 года. Очевидно, нужны нейросети по анализу статей.
- Набирают популярность следующие технологии:
- PyTorch – популярность растет стремительно и, похоже, обгоняет TensorFlow.
- Автоматический подбор гиперпараметров AutoML – популярность растет плавно.
- Постепенное уменьшение точности и увеличение скорости вычислений: нечеткая логика, алгоритмы бустинга, неточные (приближенные) вычисления, квантизация (когда веса нейросети переводятся в целые числа и квантуются), нейроакселераторы.
- Перевод изображения в текст и текста в изображение.
- Создание трехмерных объектов по видео, теперь уже в реальном времени.
- Основное в DL – это много данных, но собрать и разметить их непросто. Поэтому развивается автоматизация разметки (automated annotation) для нейросетей с помощью нейросетей.
- С нейросетями Computer Science внезапно стала экспериментальной наукой и возник кризис воспроизводимости.
- ИТ-деньги и популярность нейросетей возникли одновременно, когда вычисления стали рыночной ценностью. Экономика из золотовалютной становится золото-валютно-вычислительной. Смотрите мою статью по эконофизике и причине появления IT-денег.
Постепенно появляется новая методология программирования ML/DL (Machine Learning & Deep Learning), которая основана на представлении программы, как совокупности обученных нейросетевых моделей.
Рисунок 3 – ML/DL как новая методология программирования
Однако так и не появилось «теории нейросетей», в рамках которой можно думать и работать системно. Что сейчас называется «теорией» на самом деле экспериментальные, эвристические алгоритмы.
Ссылки на мои и не только ресурсы:
- Рассылка новостей по Data Science. В основном, по обработке изображений. Кто хочет получать, пусть присылает e-mail (foobar167<гаф-гаф>gmail<точка>com). Ссылки на статьи и видео рассылаю по мере накопления материала.
- Общий список курсов и статей, которые прошел и которые хотел бы пройти.
- Курсы и видео для начинающих, с которых стоит начинать изучать нейросети. Плюс брошюра «Введение в машинное обучение и искусственные нейронные сети».
- Полезные инструменты, где каждый найдет что-то интересное для себя.
- Крайне полезными оказались видеоканалы по разбору научных статей по Data Science. Находите, подписывайтесь на них и передавайте ссылки своим коллегам и мне тоже. Примеры:
- Two Minute Papers
- Henry AI Labs
- Yannic Kilcher
- CodeEmporium
- Блог Chengwei Zhang ака Tony607 с пошаговыми инструкциями и открытым исходным кодом.
Спасибо за внимание!
Комментарии (28)

aivazovski
04.01.2020 02:12+1по поводу задач в быту… недавно видел материал, где человек с помощью ML отучал кота таскать в дом добычу. автоматическая дверей для кота не открывалась, когда кот был с птицей в зубах.

FooBar167 Автор
04.01.2020 02:30Да. Я тоже читал. Это было уже лет 6 назад реализовано. Целая эпоха для нейросетей, если честно. Как-то быстро они развиваются, не поспеваю следить за новинками. Не говоря уже о «глубоком» понимании.

SADKO
04.01.2020 03:31Какая эпоха, функциональные преобразования ещё на специальных лампах делались, а классификаторы, ладно а то вдруг там до сих пор какая тайна, не суть…
… если копнуть в глубь, то свойства элементов составляющих зоопарки станут очевидны, как и свойства "топологий" и уже ничего не будет новым даже казаться, разве что биология будет ещё подбрасывать массу интересных идей, но юпитером их не проверить
Прогресса в паблике нет и не будет, снизили порог вхождения, получили тонны публикаций соответствующего уровня.
FooBar167 Автор
04.01.2020 13:40Первая документально подтвержденная публикация по искусственным нейронным сетям — это 1943 год, статья Уоррена Мак-Каллока и Уолтера Питтса «Логическое исчисление идей, относящихся к нервной активности». Читал, совсем не понятно.
Под «эпохой» имеются ввиду скорее технические новинки, чем теоретические выкладки математиков. Уверен, у математиков есть методы покруче, чем метод обратного распространения ошибки, но у них как-то времени нет объяснить мне, программисту, как это запрограммировать, чтобы работало.
Есть притча о глиняных горшках:
Однажды преподаватель гончарного дела провёл любопытный эксперимент. Он разделил студентов на две части и дал им разные задания. Первой половине студентов гончар поручил сделать всего один горшок. Он сказал, что будет оценивать их труд по качеству этого горшка: чем лучше у них выйдет горшок, тем выше будет оценка.
Второй половине студентов гончар сказал «гнать вал»: сделать по 50 горшков на человека. Дескать, сдаёте 50 неказистых горшков, и пять баллов у вас в кармане.
По окончании семестра внезапно выяснилось, что горшки «халтурщиков» получились гораздо качественнее, чем горшки «перфекционистов». Так как халтурщики учились на ошибках, и каждый следующий горшок получался у них лучше предыдущего.

JTG
04.01.2020 04:34– Страшноватые штуки эти гели. Ты знаешь, что один из них задушил кучу народа в Лондоне пару лет назад? Нет, серьезно. Он там управлял системой подземки – никаких нареканий, идеальный работник, а потом однажды эта штука просто забыла запустить вентиляторы, когда было надо. Поезд заезжает на пятнадцать метров под землю, пассажиры выходят, воздуха нет, бум!
Джоэл уже слышал эту историю. Коронная фраза как-то связана со сломанными часами, если он все помнит точно.
– Эти штуки вроде как учатся на собственном опыте, правильно? – продолжает Джарвис. – Ну и все думали, что зельц научился запускать вентиляторы по какому-то очевидному признаку. Жару тела, движению, уровню углекислого газа, ну ты понимаешь. В результате выяснилось, что эта хрень просто смотрела за часами на стене. Прибытие поезда совпадало с предсказуемым набором паттернов на цифровом дисплее, поэтому она включала вертушки, когда видела один из них.
– Ага. Точно. – Джоэл качает головой. – А какие-то вандалы часы разбили.
(«Морские звёзды», Питер Уоттс)FooBar167 Автор
04.01.2020 13:46Убийственная простота.
По мнению специалистов опасность ИИ не в том, что он нас всех поработит, а в убийственной простоте. В общем, это стремление к простоте является проблемой всех нейросетей, в том числе и биологических.
Akon32
04.01.2020 15:36+2Это примерно как обвинить цемент в том, что мост упал.
Если распространённая технология обычно хорошо работает, а в конкретном редком случае всё закончилось факапом, это наводит на мысли, что всё-таки не технология виновата, а проектировщики, неправильно её применившие.
DesertFlow
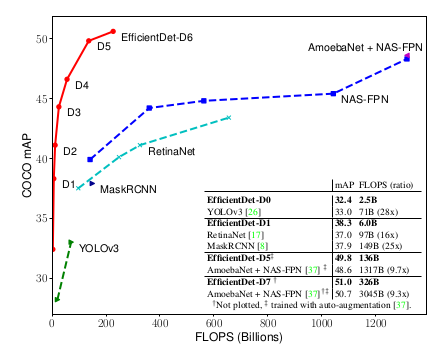
04.01.2020 11:44+2Yolo (включая последнюю третью версию YOLO3) и SSD, не говоря о древних R-CNN и аналогах, уже устарели. Их имеет смысл использовать только если есть ограничения, например запуск на мобильной платформе очень упрощённые версии этих сетей. Они могут распознавать только крупные объекты и работают с маленькими разрешениями от 224х224 до 300-600 максимум. После них появилась архитектура RetinaNet, которая сразу нормально работает с разрешениями под 1300х800 и распознает мелкие объекты размером с десяток пикселей. Однако и она уже устарела. Ей на смену пришли более новые CenterNet и EfficientDet, которые так же хорошо распознают мелкие детали, но работают точнее и быстрее. Эти нейросети снова вернули времена, когда на одном GPU за пару дней можно было обучить state-of-the-art распознавалку на конкурс. Из старых сетей разве что Faster R-CNN и пара AutoML моделей от гугла ещё удерживают позиции, но они очень медленные (хотя FasterRCNN и была в свое время самая быстрая из своего семейства).
Просто смотрите графики

FooBar167 Автор
04.01.2020 14:02Спасибо! Я постараюсь узнать о CenterNet и EfficientDet. Если пойму, то сделаю статью на русском языке.
DesertFlow
04.01.2020 17:13+1Уточнение: под CenterNet я имел ввиду CenterNet: Objects as Points, потому что есть ещё с таким же названием CenterNet: Keypoint Triplets for Object Detection. Они вроде вышли с разницей в пару дней, поэтому получилась путаница с названиями. Первая лучше. Вторая является развитием предыдущего поколения CornerNet, и скорее всего повлияла на последние тенденции отказа от регионов при поиске объектов, но судя по результатам, уступает по скорости и точности той что Objects as Points.

enclis
05.01.2020 13:10+1Немного печально, что SpineNet от гугла даже не упомянул про EfficientDet (тоже от гугла, но лучше) хоть и был опубликован почти через 3 недели после. Видимо, это уже привычная практика для подобной ситуации даже за пределами ML-сообщества. Вот сравнение SpineNet и EfficientDet (ну и до кучи другие сетки):

Сюда конечно не вошли ещё много других интересных статей, которые сравнивают по inference time. Данные поэтому далеко неполные и возможно не очень точные, но какое-то представление о более-менее быстрых вариантах даёт. В частности, может быть кому-то будет интересно посмотреть на SM-NAS и DetNASNet, который даже в чём-то лучше чем EfficientDet.
enclis
04.01.2020 13:06+1Поэтому появилась необходимость узнать, какие архитектуры нейросетей обнаруживают объекты на изображениях…
Object Detection in 20 Years: A Survey — хорошая обзорная статья. В частности, отвечает на вопрос «куда это все движется» в отношении object detection. Из последних достижений, не отмеченных в этой обзорной статье, можно добавить: EfficientDet, SpineNet, CSPNet…
По мере изучения этих архитектур я понял, что ничего не понимаю… Нет системного мышления! Не понятно, что менять и как оптимизировать имеющиеся достижения… Постепенное уменьшение точности и увеличение скорости вычислений: нечеткая логика, алгоритмы бустинга ...
Вы за какое время попытались изучить имеющиеся достижения? Не похоже, что вы этим уже давно занимаетесь.FooBar167 Автор
04.01.2020 14:07Относительно недолго. Если отнять время на изучение Python и алгоритмов обработки изображений, то где-то полтора года.
Спасибо за ссылки!
serega374
04.01.2020 13:47+1Сам не программист, только увлекаюсь C# (пишу небольшие приложения для автоматизации проектирования для AutoCad). Работаю проектировщиком (сотовая связь). В мыслях написать программу которая по фотографиям объекта составит список оборудования. Но в какую сторону смотреть ни знаю, глаза разбегаются, инфы много, но очень сложно для понимания.
FooBar167 Автор
04.01.2020 13:58Начните с простой задачи. Например, классификация одного объекта на изображении. Пример с предметами одежды. Воспользуйтесь сервисом Kaggle. Пройдите курс по TensorFlow.
Машинное обучение — это прикладная область знания. Только решением задач можно научиться чему-то конкретному.

user_man
04.01.2020 14:42+1>> Краткое описание некоторых архитектур сетей по обнаружению объектов на изображении
А почему только нейросети? Собственно свёртка вообще никак к нейросетям не относится. То же самое можно сказать о куче других алгоритмов. И вот эта «куча» осталась вне поля зрения.
Хотя понятно, что шума вокруг сетей гораздо больше, чем вокруг несетевых алгоритмов, но сдаётся мне, что всё разнообразие сетей во многом основано именно на разнообразии этих других алгоритмов. То есть прикручивают сеть к ранее полученному алгоритму (как вот к свёртке прикрутили) и получают новую возможность для очередной рекламной кампании, мол новейшая технология, мега-супер-вундер-достижения и т.д. Пилить венчурные инвестиции — самое оно.FooBar167 Автор
04.01.2020 15:09Нейросеть реализует принцип коннекционизма. Все профессионалы стоят на плечах гигантов: 99,9% старого + 0,1% нового.

IvanTamerlan
05.01.2020 12:46Ожидал чего-то нового и прорывного, ибо у нейросетей проблемы остались те же, например:
— обучение чему-то новому требует огромных массивов информации, т.е. не одна условная фотка, а целые размеченные датасеты
— обучение новому приводит к стиранию старой памяти. Нейросеть либо «цементируется» и не может обучатся, либо обучается новому ценой потери старой модели
Первая проблема решалась с помощью более мощного железа. Вторая проблема решается либо добавлением старого датасета к новому, либо что-то новое должна узнавать уже новая нейросеть, которая подсоединяется к старой.
Мои ожидания? Смена концепции на что-то более оригинальное, например, идеи Редозубова "Логика сознания"
И даже неплохая реализация на распознавании автомобильных номеров. Обычные нейросети натравливают сразу на цифры и из-за шума/грязи будет множество ложных срабатываний. Но если вначале определить границы самого автомобильного номера, а потом натравливать на конкретные зоны, то «вот эта грязь на самом деле цифра».
Преимущества:
1) память отделена от сверточной нейросети
2) учет множества искажений, кроме сдвига еще и наклоны
Общим недостатком для прорывных идей является ее закрытость, т.е. если новые модели изобретены сейчас, то они станут доступны широкой общественности только через условные 10-20 лет. Как с 3D принтерами, которые долгое время были под патентами и крайне дорогими.FooBar167 Автор
06.01.2020 08:23Рассказал все, что узнал за 4 недели. Уже появились новые, более эффективные архитектуры. Постараюсь разобрать, как они работают и сделать краткий обзор на них.
Со времени написания первой статьи прошло 3.5 года, а воз и ныне там. Моя позиция проще: не пытаться заменить мозг технологией, а дополнить его и усилить при помощи технологии. По этой причине, хотелось бы узнать, на каких принципах конструировать новые архитектуры? Этого я пока не нашел нигде. Все только и делают, что конструируют на основе каких-то своих догадок и инсайтов. Если для этого придется отказаться от «нейрона бабушки», то откажусь без колебаний: мы же не секта какая-то :-)
При просмотре двенадцати статей «Логики сознания» пришла идея, что необходимо оперировать не только весами синапсов, но и их положением и, возможно, даже количеством синапсов в свертке. Так в классической конволюционной сети оперируют девятью синапсами в свертке, расположенными в виде квадрата 3?3. Затем появилась операция выбрасывания части синапсов при обучении (dropout). Затем перешли к пространственной свертке (dilated convolution). Вполне возможно, что все это движется в сторону оперирования положением и количеством синапсов в свертке.
Итак, добавляем пространственную организацию синапсов при свертке (сворачиваем не только квадратиком, но и более сложными двумерными фигурами). Пока не понятно, как добавить «динамическую перестройку контекстных карт». Каким образом синапсы будут перемещаться по предыдущему слою? Каким образом будет выбираться их количество?
Во второй статье узнал, что, вообще, можно отказаться от сверток, а использовать другие математические операции. Но какие, пока не понял.IvanTamerlan
06.01.2020 13:09не пытаться заменить мозг технологией, а дополнить его и усилить при помощи технологии
Моя еще проще — избавится от рутинных операций. Например:
— распознавание автомобильных номеров, чтобы их данные ввести в некую базу данных; аналогично для бейджиков или бирок;
— пройтись с видеокамерой по торговому ряду и из видео потом извлечь данные по всем ценам вместе с изображением товара
— сделать десяток фотографий и получить полноценную 3D модель вообще без редактирования
— сделаны фото страниц на телефон, выровнять ориентацию страниц и распознать текст с них
— распознование неких стандартных бланков
и т.д.
Для перечисленных задач не требуется вся мощность мозга. Особенно, когда приходит новый тип идентификатора и чтобы не обучать заново нейросеть на распознавание этого типа в течении нескольких часов, а достаточно одной фото идентификатора, т.е. условного бейджика нового образца или даже разметить вручную где какие области находятся, а дальше ИИ сам извлекает данные.
Сейчас обученный ИИ не готов к серьезному изменению распознаваемого образа для обычного пользователя. Если есть готовый ИИ, который распознает собачек, то если пользователь распознавание кошечек, то не достаточно одной фотографии, нужны:
— специалист по ИИ-обучению
— целый датасет с кошечками
— мощный ПК с хорошими видеокартами для обучения нейросети
и т.д.
Соответственно, ИИ не готов для практического использования для новых задач для обычных пользователей. Мне уже сообщали, что можно скачать и самому настроить, но это не совсем верно, т.к. нужно еще и научится самому настраивать. Т.е. граничные условия в виде условного неопытного пользователя, который ничего не знает в ИТ, данный метод провалит из-за сложности.
Вывод: нейросети далеки от Plug&play для аналогичных задач, но уже могут использоваться в таком режиме для конкретных узких задач со множеством ограничений, дабы избежать промахи ИИ.
На примере Excel — это как можно редактировать таблицы 4х5 с обязательным заголовком, но нельзя редактировать таблицы 5х6 или даже 4х5 без заголовка.
NeoCode
Вот интересный вопрос — а где простой «продвинутый юзер» может применить их в быту (и тем более в смартфоне)? Кроме распознавания капч, ничего в голову не приходит. Для самодельного машинного перевода все-таки знаний простого юзера будет недостаточно. А что еще?
Ладно бы еще была инфраструктура автоматического поиска сложноформализуемой информации — т.е. я даю нейросети подборку картинок и говорю «найди мне все похожие в инете», и оставляю компьютер на ночь — ну так ведь тут именно инфраструктура нужна. И картинки — самое примитивное (с чем современные нейросети вероятно справятся), а если нужны более сложные задачи — поиск и подборка текстовой информации на определенную тему?
FooBar167 Автор
Распознавание штампов на документах, распознавание каптч, распознавание и решение математических уравнений, подсказка хода в шахматах (для шахматистов-читеров). Есть приложения для распознавания видов грибов, но несоветую )). На СТО по звуку автомобиля делать предварительную диагностику поломки. Многие используют для наблюдения за домашними животными (впустить-выпустить из дома). Камеры, которые фотографируют не просто движение, а определенный вид птиц или диких животных. Системы домашнего наблюдения: кто-то стоит около дома, сразу идет СМС и фото хозяину дома. Поднятие шлагбаума только для номеров авто из жильцов дома. Подсчет людей в толпе. Мгновенный подсчет многих предметов (гороха какого-нибудь). На конвейере отсеивание гнилых яблок и картошки. Изменение стиля фотографии «под старину» или под картину знаменитого художника. Помощь фотошоперу: продвинутые фильтры, устранение заднего фона и т.д. Фактически все современные смартфоны ретушируют фотографии с помощью нейросетей и классических алгоритмов, убирают шум, делают фото ярче (все).
Постепенно ведутся работы по преобразованию текста в изображение: вы пишете текст, а нейросеть рисует картинку.
У меня есть идея сделать регулярные публикации по новинкам машинного обучения. Там даю разные идеи по применению нейросетей. Я уже сделал 5 рассылок, а шестую и далее планирую публиковать на Хабре.
muhaa
salkat
Очень не хватает нейросети, которая бы просматривала статьи новостной ленты и собирала из каждой статьи суть. Например, в виде тегов
alkneu
Спасибо за подборку.
Можно ещё делать binning: лучшие яблоки продаём как 1ый сорт, хорошие — как 2ой сорт, средние — в компот/варенье, худшие — на биомассу.
Наверное, используя такое можно оптимизировать/корректировать цену закупки у поставщиков.
Aberro
Набор на клавиатуре, особенно свайп-метод. Было бы очень полезно предсказывать, что хотел сказать пользователь и что из предсказанного лучше всего соответствует свайпу.