
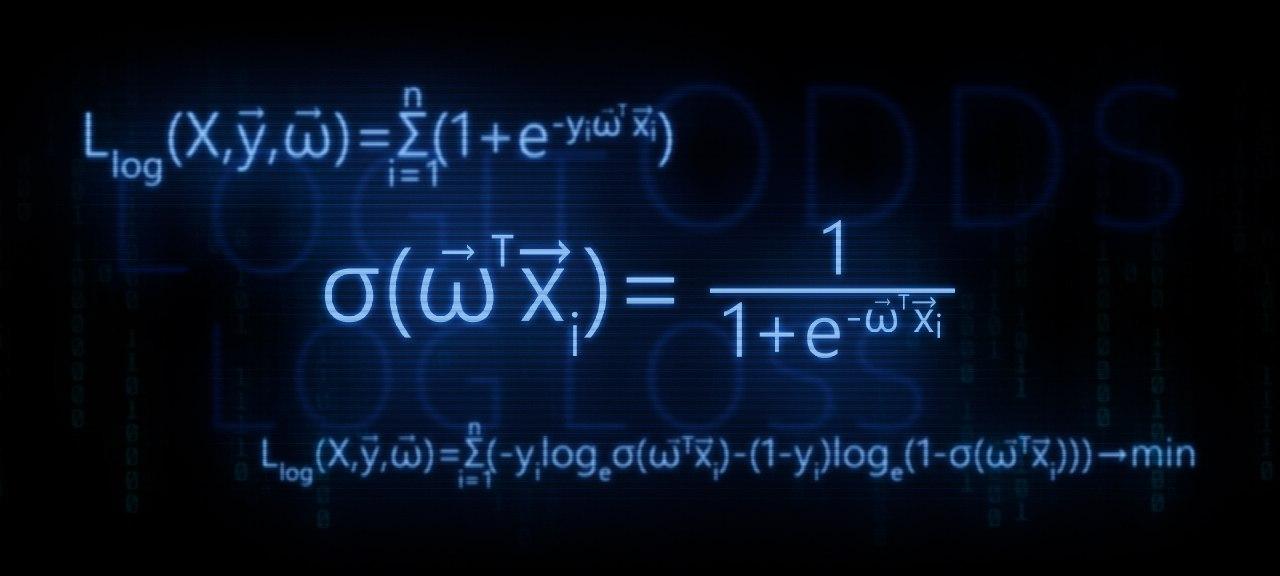
В этой статье, мы будем разбирать теоретические выкладки преобразования функции линейной регрессии в функцию обратного логит-преобразования (иначе говорят, функцию логистического отклика). Затем, воспользовавшись арсеналом метода максимального правдоподобия, в соответствии с моделью логистической регрессии, выведем функцию потерь Logistic Loss, или другими словами, мы определим функцию, с помощью которой в модели логистической регрессии подбираются параметры вектора весов .
План статьи:
- Повторим о прямолинейной зависимости между двумя переменными
- Выявим необходимость преобразования функции линейной регрессии в функцию логистического отклика
- Проведем преобразования и выведем функцию логистического отклика
- Попытаемся понять, чем плох метод наименьших квадратов при подборе параметров функции Logistic Loss
- Используем метод максимального правдоподобия для определения функции подбора параметров :
5.1. Случай 1: функция Logistic Loss для объектов с обозначением классов 0 и 1:
5.2. Случай 2: функция Logistic Loss для объектов с обозначением классов -1 и +1:
Статья изобилует простыми примерами, в которых все расчеты легко произвести устно или на бумаге, в некоторых случаях может потребоваться калькулятор. Так что подготовьтесь :)
Данная статья в большей мере рассчитана на датасайнтистов с начальным уровнем познаний в основах машинного обучения.
В статье также будет приведен код для отрисовки графиков и расчетов. Весь код написан на языке python 2.7. Заранее поясню о «новизне» используемой версии — таково одно из условий прохождения известного курса от Яндекса на не менее известной интернет-площадке онлайн образования Coursera, и, как можно предположить, материал подготовлен по мотивам этого курса.
01. Прямолинейная зависимость
Вполне резонно задать вопрос — причем здесь прямолинейная зависимость и логистическая регрессия?
Все просто! Логистическая регрессия представляет собой одну из моделей, которые относятся к линейному классификатору. Простыми словами, задачей линейного классификатора является предсказание целевых значений от переменных (регрессоров) . При этом считается, что зависимость между признаками и целевыми значениями линейная. Отсюда собственно и название классификатора — линейный. Если очень грубо обобщить, то в основе модели логистической регрессии лежит предположение о наличии линейной зависимости между признаками и целевыми значениями . Вот она — связь.
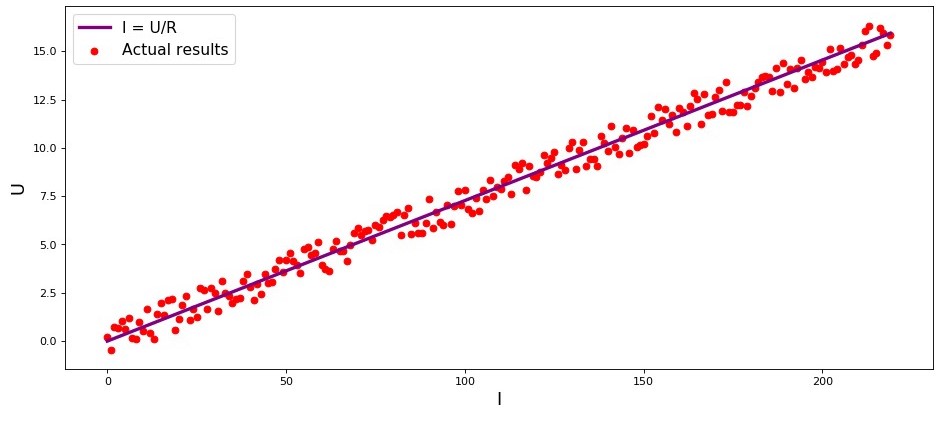
В студии первый пример, и он, правильно, о прямолинейной зависимости исследуемых величин. В процессе подготовки статьи наткнулся на пример, набивший уже многим оскомину — зависимость силы тока от напряжения («Прикладной регрессионный анализ», Н.Дрейпер, Г.Смит). Здесь мы его тоже рассмотрим.
В соответствии с законом Ома:
, где — сила тока, — напряжение, — сопротивление.
Если бы мы не знали закон Ома, то могли бы найти зависимость эмпирически, изменяя и измеряя , поддерживая при этом фиксированным. Тогда мы бы увидели, что график зависимости от дает более или менее прямую линию, проходящую через начало координат. Мы сказали «более или менее», так как, хотя зависимость фактически точная, наши измерения могут содержать малые ошибки, и поэтому точки на графике, возможно не попадут строго на линию, а будут разбросаны вокруг нее случайным образом.
График 1 «Зависимость от »
Код отрисовки графика
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import random
R = 13.75
x_line = np.arange(0,220,1)
y_line = []
for i in x_line:
y_line.append(i/R)
y_dot = []
for i in y_line:
y_dot.append(i+random.uniform(-0.9,0.9))
fig, axes = plt.subplots(figsize = (14,6), dpi = 80)
plt.plot(x_line,y_line,color = 'purple',lw = 3, label = 'I = U/R')
plt.scatter(x_line,y_dot,color = 'red', label = 'Actual results')
plt.xlabel('I', size = 16)
plt.ylabel('U', size = 16)
plt.legend(prop = {'size': 14})
plt.show()02. Необходимость преобразований уравнения линейной регрессии
Рассмотрим очередной пример. Представим, что мы работаем в банке и перед нами задача определить вероятность возврата кредита заемщиком в зависимости от некоторых факторов. Для упрощения задачи, рассмотрим только два фактора: месячная зарплата заемщика и месячный размер платежа на погашение кредита.
Задача очень условная, но на этом примере мы сможем понять, почему для ее решения недостаточно применения функции линейной регрессии, а также узнаем какие преобразования с функцией требуется провести.
Возвращаемся к примеру. Понято, что чем выше зарплата, тем больше заемщик сможет ежемесячно направлять на погашение кредита. При этом, для определенного диапазона зарплат эта зависимость будет вполне себе линейная. Например, возьмем диапазон зарплат от 60.000Р до 200.000Р и предположим, что в указанном диапазоне заработных плат, зависимость размера ежемесячного платежа от размера заработной платы — линейная. Допустим, для указанного диапазона размера заработных плат было выявлено, что соотношение зарплаты к платежу не может опускаться ниже 3 и еще у заемщика должно оставаться в запасе 5.000Р. И только в таком случае, мы будем считать, что заемщик вернет кредит банку. Тогда, уравнение линейной регрессии примет вид:
где , , , — зарплата -го заемщика, — платеж по кредиту -го заемщика.
Подставляя в уравнение зарплату и платеж по кредиту с фиксированными параметрами можно принять решение о выдаче или отказе кредита.
Забегая вперед, отметим, что, при заданных параметрах функция линейной регрессии, применяемая в функции логистичиеского отклика будет выдавать большие значения, которые затруднят проведение расчетов по определению вероятностей погашения кредита. Поэтому, предлагается уменьшить наши коэффициенты, скажем так, в 25.000 раз. От этого преобразования в коэффициентах, решение о выдачи кредита не изменится. Запомним этот момент на будущее, а сейчас чтобы было еще понятнее, о чем речь, рассмотрим ситуация с тремя потенциальными заемщиками.
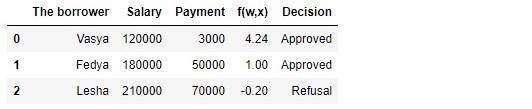
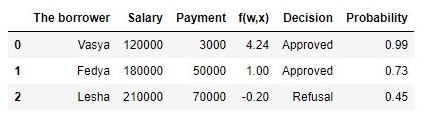
Таблица 1 «Потенциальные заемщики»
Код для формирования таблицы
import pandas as pd
r = 25000.0
w_0 = -5000.0/r
w_1 = 1.0/r
w_2 = -3.0/r
data = {'The borrower':np.array(['Vasya', 'Fedya', 'Lesha']),
'Salary':np.array([120000,180000,210000]),
'Payment':np.array([3000,50000,70000])}
df = pd.DataFrame(data)
df['f(w,x)'] = w_0 + df['Salary']*w_1 + df['Payment']*w_2
decision = []
for i in df['f(w,x)']:
if i > 0:
dec = 'Approved'
decision.append(dec)
else:
dec = 'Refusal'
decision.append(dec)
df['Decision'] = decision
df[['The borrower', 'Salary', 'Payment', 'f(w,x)', 'Decision']]В соответствии с данными таблицы, Вася при зарплате в 120.000Р хочет получить такой кредит, чтобы ежемесячного гасить его по 3.000Р. Нами было определено, что для одобрения кредита, размер заработной платы Васи должен превышать в три раза размер платежа, и чтобы еще оставалось 5.000Р. Этому требованию Вася удовлетворяет: . Остается даже 106.000Р. Несмотря на то, что при расчете мы уменьшили коэффициенты в 25.000 раз, результат получили тот же — кредит может быть одобрен. Федя тоже получит кредит, а вот Леше, несмотря на то, что он получает больше всех, придется поумерить свои аппетиты.
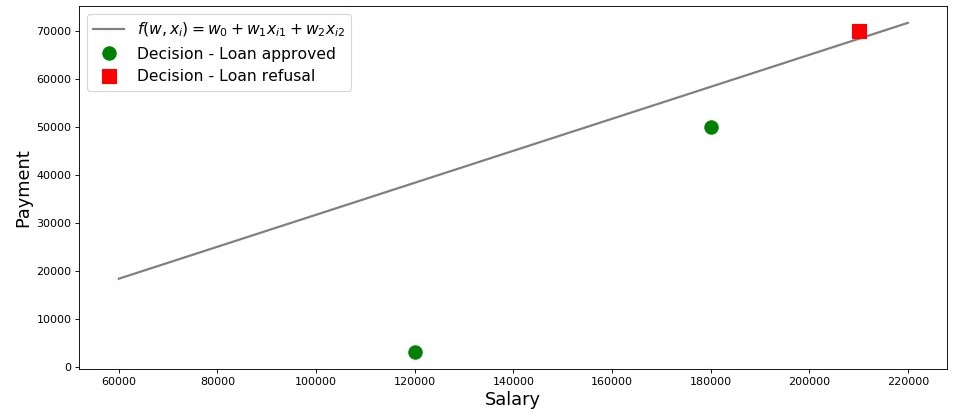
Нарисуем график по такому случаю.
График 2 «Классификация заемщиков»
Код для отрисовки графика
salary = np.arange(60000,240000,20000)
payment = (-w_0-w_1*salary)/w_2
fig, axes = plt.subplots(figsize = (14,6), dpi = 80)
plt.plot(salary, payment, color = 'grey', lw = 2, label = '$f(w,x_i)=w_0 + w_1x_{i1} + w_2x_{i2}$')
plt.plot(df[df['Decision'] == 'Approved']['Salary'], df[df['Decision'] == 'Approved']['Payment'],
'o', color ='green', markersize = 12, label = 'Decision - Loan approved')
plt.plot(df[df['Decision'] == 'Refusal']['Salary'], df[df['Decision'] == 'Refusal']['Payment'],
's', color = 'red', markersize = 12, label = 'Decision - Loan refusal')
plt.xlabel('Salary', size = 16)
plt.ylabel('Payment', size = 16)
plt.legend(prop = {'size': 14})
plt.show()Итак, наша прямая, построенная в соответствии с функцией , отделяет «плохих» заемщиков от «хороших». Те заемщики, у кого желания не совпадают с возможностями находятся выше прямой (Леша), те же, кто способен согласно параметрам нашей модели, вернуть кредит, находятся под прямой (Вася и Федя). Иначе можно сказать так — наша прямая разделяет заемщиков на два класса. Обозначим их следующим образом: к классу отнесем тех заемщиков, которые скорее всего вернут кредит, к классу или отнесем тех заемщиков, которые скорее всего не смогут вернуть кредит.
Обобщим выводы из этого простенького примера. Возьмем точку и, подставляя координаты точки в соответствующее уравнение прямой , рассмотрим три варианта:
- Если точка находится под прямой, и мы относим ее к классу , то значение функции будет положительным от до . Значит мы можем считать, что вероятность погашения кредита, находится в пределах . Чем больше значение функции, тем выше вероятность.
- Если точка находится над прямой и мы относим ее к классу или , то значение функции будет отрицательным от до . Тогда мы будем считать, что вероятность погашения задолженности находится в пределах и, чем больше по модулю значение функции, тем выше наша уверенность.
- Точка находится на прямой, на границе между двумя классами. В таком случае значение функции будет равно и вероятность погашения кредита равна .
Теперь, представим, что у нас не два фактора, а десятки, заемщиков не три, а тысячи. Тогда вместо прямой у нас будет m-мерная плоскость и коэффициенты у нас будут взяты не с потолка, а выведены по всем правилам, да на основе накопленных данных о заемщиках, вернувших или не вернувших кредит. И действительно, заметьте, мы сейчас отбираем заемщиков при уже известных коэффициентах . На самом же деле, задача модели логистической регрессии как раз и состоит в том, чтобы определить параметры , при которых значение функции потерь Logistic Loss будет стремиться к минимальному. Но о том, как рассчитывается вектор , мы еще узнаем в 5-м разделе статьи. А пока возвращаемся на землю обетованную — к нашему банкиру и трем его клиентам.
Благодаря функции мы знаем кому можно дать кредит, а кому нужно отказать. Но с такой информацией к директору идти нельзя, ведь от нас хотели получить вероятность возврата кредита каждым заемщиком. Что делать? Ответ простой — нам нужно как-то преобразовать функцию , значения которой лежат в диапазоне на функцию, значения которой будут лежать в диапазоне . И такая функция существует, ее называют функцией логистического отклика или обратного-логит преобразования. Знакомьтесь:
Посмотрим по шагам как получается функция логистического отклика. Отметим, что шагать мы будем в обратную сторону, т.е. мы предположим, что нам известно значение вероятности, которое лежит в пределах от до и далее мы будем «раскручивать» это значение на всю область чисел от до .
03. Выводим функцию логистического отклика
Шаг 1. Переведем значения вероятности в диапазон
На время трансформации функции в функцию логистического отклика мы оставим в покое нашего кредитного аналитика, а вместо этого пройдемся по букмекерским конторам. Нет, конечно, ставки делать мы не будем, все что нас там интересует, так это смысл выражения, например, шанс 4 к 1. Шансы, знакомые всем делающим ставки игрокам, являются соотношением «успехов» к «неуспехам». С точки зрения вероятностей, шансы — это вероятность наступления события, деленная на вероятность того, что событие не произойдет. Запишем формулу шанса наступления события :
, где — вероятность наступления события, — вероятность НЕ наступления события
Например, если вероятность того, что молодой, сильный и резвый конь по прозвищу «Ветерок» обойдет на скачках старую и дряблую старушку по кличке «Матильда» равняется , то шансы на успех «Ветерка» составят к и наоборот, зная шансы, нам не составит труда вычислить вероятность :
Таким образом, мы научились «переводить» вероятность в шансы, которые принимают значения от до . Сделаем еще один шаг и научимся «переводить» вероятность на всю числовую прямую от до .
Шаг 2. Переведем значения вероятности в диапазон
Шаг этот очень простой — прологарифмируем шансы по основанию числа Эйлера и получим:
Теперь мы знаем, что если , то вычислить значение будет очень просто и, более того, оно должно быть положительным: . Так и есть.
Ради любопытства проверим, что если , тогда мы ожидаем увидеть отрицательное значение . Проверяем: . Все верно.
Теперь мы знаем как перевести значение вероятности от до на всю числовую прямую от до . В следующем шаге сделаем все наоборот.
А пока, отметим, что в соответствии с правилами логарифмирования, зная значение функции , можно вычислить шансы:
Этот способ определения шансов нам пригодится на следующем шаге.
Шаг 3. Выведем формулу для определения
Итак, мы научились, зная , находить значения функции . Однако, на самом деле нам нужно все с точностью до наоборот — зная значение находить . Для этого обратимся к такому понятию как обратная функция шансов, в соответствии с которой:
В статье мы не будем выводить вышеобозначенную формулу, но проверим на цифрах из примера выше. Мы знаем, что при шансах равными 4 к 1 (), вероятность наступления события равна 0.8 (). Сделаем подстановку: . Это совпадает с нашими вычислениями, проведенными ранее. Двигаемся далее.
На прошлом шаге мы вывели, что , а значит можно сделать замену в обратной функции шансов. Получим:
Разделим и числитель и знаменатель на , тогда:
На всякий пожарный, дабы убедиться, что мы нигде не ошиблись, сделаем еще одну небольшую проверку. На шаге 2, мы для определили, что . Тогда, подставив значение в функцию логистического отклика, мы ожидаем получить . Подставляем и получаем:
Поздравляю вас, уважаемый читатель, мы только что вывели и протестировали функцию логистического отклика. Давайте посмотрим на график функции.
График 3 «Функция логистического отклика»

Код для отрисовки графика
import math
def logit (f):
return 1/(1+math.exp(-f))
f = np.arange(-7,7,0.05)
p = []
for i in f:
p.append(logit(i))
fig, axes = plt.subplots(figsize = (14,6), dpi = 80)
plt.plot(f, p, color = 'grey', label = '$ 1 / (1+e^{-w^Tx_i})$')
plt.xlabel('$f(w,x_i) = w^Tx_i$', size = 16)
plt.ylabel('$p_{i+}$', size = 16)
plt.legend(prop = {'size': 14})
plt.show()В литературе также можно встретить название данной функции как сигмоид-функция. По графику хорошо заметно, что основное изменение вероятности принадлежности объекта к классу происходит на относительно небольшом диапазоне , где-то от до .
Предлагаю вернуться к нашему кредитному аналитику и помочь ему с вычислением вероятности погашения кредитов, иначе он рискует остаться без премии :)
Таблица 2 «Потенциальные заемщики»
Код для формирования таблицы
proba = []
for i in df['f(w,x)']:
proba.append(round(logit(i),2))
df['Probability'] = proba
df[['The borrower', 'Salary', 'Payment', 'f(w,x)', 'Decision', 'Probability']]Итак, вероятность возврата кредита мы определили. В целом, это похоже на правду.
Действительно, вероятность того что Вася при зарплате в 120.000Р сможет ежемесячно отдавать в банк 3.000Р близка к 100%. Кстати, мы должны понимать, что банк может выдать кредит и Леше в том случае, если политикой банка предусмотрено, например, кредитовать клиентов с вероятностью возврата кредита более, ну скажем, 0.3. Просто в таком случае банк сформирует больший резерв под возможные потери.
Также следует отметить, что соотношение зарплаты к платежу не менее 3 и с запасом в 5.000Р было взято с потолка. Поэтому нам нельзя было использовать в первоначальном виде вектор весов . Нам требовалось сильно уменьшить коэффициенты и в таком случае мы разделили каждый коэффициент на 25.000, то есть по сути мы подогнали результат. Но это сделано было специально, чтобы упростить понимание материала на начальном этапе. В жизни, же нам потребуется не выдумывать и подгонять коэффициенты, а находить их. Как раз в следующих разделах статьи мы выведем уравнения, с помощью которых подбираются параметры .
04. Метод наименьших квадратов при определении вектора весов в функции логистического отклика
Нам уже известен такой метод подбора вектора весов , как метод наименьших квадратов (МНК) и собственно, почему бы нам тогда не использовать его в задачах бинарной классификации? Действительно, ничто не мешает использовать МНК, только вот данный способ в задачах классификации дает результаты менее точные, нежели Logistic Loss. Этому есть теоретическое обоснование. Давайте для начала посмотрим на один простой пример.
Предположим, что наши модели (использующие MSE и Logistic Loss) уже начали подбор вектора весов и мы остановили расчет на каком-то шаге. Неважно, в середине, в конце или в начале, главное, что у нас уже есть какие-то значения вектора весов и допустим, что на этом шаге, вектора весов для обеих моделей не имеют различий. Тогда возьмем полученные веса и подставим их в функцию логистического отклика () для какого-нибудь объекта, который относится к классу . Исследуем два случая, когда в соответствии с подобранным вектором весов наша модель сильно ошибается и наоборот — модель сильно уверена в том, что объект относится к классу . Посмотрим какие штрафы будут «выписаны» при использовании МНК и Logistic Loss.
Код для расчета штрафов в зависимости от используемой функции потерь
# класс объекта
y = 1
# вероятность отнесения объекта к классу в соответствии с параметрами w
proba_1 = 0.01
MSE_1 = (y - proba_1)**2
print 'Штраф MSE при грубой ошибке =', MSE_1
# напишем функцию для вычисления f(w,x) при известной вероятности отнесения объекта к классу +1 (f(w,x)=ln(odds+))
def f_w_x(proba):
return math.log(proba/(1-proba))
LogLoss_1 = math.log(1+math.exp(-y*f_w_x(proba_1)))
print 'Штраф Log Loss при грубой ошибке =', LogLoss_1
proba_2 = 0.99
MSE_2 = (y - proba_2)**2
LogLoss_2 = math.log(1+math.exp(-y*f_w_x(proba_2)))
print '**************************************************************'
print 'Штраф MSE при сильной уверенности =', MSE_2
print 'Штраф Log Loss при сильной уверенности =', LogLoss_2Случай с грубой ошибкой — модель относит объект к классу с вероятностью в 0,01
Штраф при использовании МНК составит:
Штраф при использовании Logistic Loss составит:
Случай с сильной уверенностью — модель относит объект к классу с вероятностью в 0,99
Штраф при использовании МНК составит:
Штраф при использовании Logistic Loss составит:
Этот пример хорошо иллюстрирует, что при грубой ошибке функция потерь Log Loss штрафует модель значительно сильнее, чем MSE. Давайте теперь разберемся, каковы теоретические предпосылки использования функции потерь Log Loss в задачах классификации.
05. Метод максимального правдоподобия и логистическая регрессия
Как и было обещано в начале, статья изобилует простыми примерами. В студии очередной пример и старые гости — заемщики банка: Вася, Федя и Леша.
На всякий пожарный, перед тем как развивать пример, напомню, что в жизни мы имеем дело с обучающей выборкой из тысяч или миллионов объектов с десятками или сотнями признаков. Однако здесь цифры взяты так, чтобы они легко укладывались в голове начинающего датасайнтеста.
Возвращаемся к примеру. Представим, что директор банка решил выдать кредит всем нуждающимся, несмотря на то, что алгоритм подсказывал не выдавать его Леше. И вот прошло достаточно времени и нам стало известно кто из трех героев погасил кредит, а кто нет. Что и следовало ожидать: Вася и Федя погасили кредит, а Леша — нет. Теперь давайте представим, что этот результат будет для нас новой обучающей выборкой и, при этом у нас как будто исчезли все данные о факторах, влияющих на вероятность погашения кредита (зарплата заемщика, размер ежемесячного платежа). Тогда интуитивно мы можем полагать, что каждый третий заемщик не возвращает банку кредит или другими словами вероятность возврата кредита следующим заемщиком . Этому интуитивному предположению есть теоретическое подтверждение и основывается оно на методе максимального правдоподобия, часто в литературе его называют принципом максимального правдоподобия.
Для начала познакомимся с понятийным аппаратом.
Правдоподобие выборки — это вероятность получения именно такой выборки, получения именно таких наблюдений / результатов, т.е. произведение вероятностей получения каждого из результатов выборки (например, погашен или не погашен кредит Васей, Федей и Лешей одновременно).
Функция правдоподобия связывает правдоподобие выборки со значениями параметров распределения.
В нашем случае, обучающая выборка представляет собой обобщённую схему Бернулли, в которой случайная величина принимает всего два значения: или . Следовательно, правдоподобие выборки можно записать как функцию правдоподобия от параметра следующим образом:
Вышеуказанную запись можно интерпретировать так. Совместная вероятность того, что Вася и Федя погасят кредит равна , вероятность того что Леша НЕ погасит кредит равна (так как имело место именно НЕ погашение кредита), следовательно совместная вероятность всех трех событий равна .
Метод максимального правдоподобия — это метод оценки неизвестного параметра путём максимизации функции правдоподобия. В нашем случае требуется найти такое значение , при котором достигает максимума.
Откуда собственно идея – искать значение неизвестного параметра, при котором функция правдоподобия достигает максимума? Истоки идеи проистекают из представления о том, что выборка – это единственный, доступный нам, источник знания о генеральной совокупности. Все, что нам известно о генеральной совокупности, представлено в выборке. Поэтому, все, что мы можем сказать, так это то, что выборка – это наиболее точное отражение генеральной совокупности, доступное нам. Следовательно, нам требуется найти такой параметр, при котором имеющаяся выборка становится наиболее вероятной.
Очевидно, мы имеем дело с оптимизационной задачей, в которой требуется найти точку экстремума функции. Для нахождения точки экстремума необходимо рассмотреть условие первого порядка, то есть приравнять производную функции к нулю и решить уравнение относительно искомого параметра. Однако поиски производной произведения большого количества множителей могут оказаться делом затяжным, чтобы этого избежать существует специальный прием — переход к логарифму функции правдоподобия. Почему возможен такой переход? Обратим внимание на то, что мы ищем не сам экстремум функции, а точку экстремума, то есть то значение неизвестного параметра , при котором достигает максимума. При переходе к логарифму точка экстремума не меняется (хотя сам экстремум будет отличаться), так как логарифм — монотонная функция.
Давайте, в соответствии с вышеизложенным, продолжим развивать наш пример с кредитами у Васи, Феди и Леши. Для начала перейдем к логарифму функции правдоподобия:
Теперь мы можем с легкостью продифференцировать выражение по :
И наконец, рассмотрим условие первого порядка — приравняем производную функции к нулю:
Таким образом, наша интуитивная оценка вероятности погашения кредита была теоретически обоснована.
Отлично, но что нам теперь делать с такой информацией? Если мы будем считать, что каждый третий заемщик не вернет банку деньги, то последний неизбежно разорится. Так-то оно так, да только при оценке вероятности погашения кредита равной мы не учли факторы, влияющие на возврат кредита: заработная плата заемщика и размер ежемесячного платежа. Вспомним, что ранее мы рассчитали вероятность возврата кредита каждым клиентом с учетом этих самых факторов. Логично, что и вероятности у нас получились отличные от константы равной .
Давайте определим правдоподобие выборок:
Код для расчетов правдоподобий выборок
from functools import reduce
def likelihood(y,p):
line_true_proba = []
for i in range(len(y)):
ltp_i = p[i]**y[i]*(1-p[i])**(1-y[i])
line_true_proba.append(ltp_i)
likelihood = []
return reduce(lambda a, b: a*b, line_true_proba)
y = [1.0,1.0,0.0]
p_log_response = df['Probability']
const = 2.0/3.0
p_const = [const, const, const]
print 'Правдоподобие выборки при константном значении p=2/3:', round(likelihood(y,p_const),3)
print '****************************************************************************************************'
print 'Правдоподобие выборки при расчетном значении p:', round(likelihood(y,p_log_response),3)Правдоподобие выборки при константном значении :
Правдоподобие выборки при расчете вероятности погашения кредита с учетом факторов :
Правдоподобие выборки с вероятностью, посчитанной в зависимости от факторов оказалось выше правдоподобия при константном значении вероятности. О чем это говорит? Это говорит о том, что знания о факторах позволили подобрать более точно вероятность погашения кредита для каждого клиента. Поэтому, при выдаче очередного кредита, правильнее будет использовать, предложенную в конце 3-го раздела статьи, модель оценки вероятности погашения задолженности.
Но тогда, если нам требуется максимизировать функцию правдоподобия выборки, то почему бы не использовать какой-нибудь алгоритм, который будет выдавать вероятности для Васи, Феди и Леши, например, равными 0.99, 0.99 и 0.01 соответственно. Возможно такой алгоритм и хорошо себя проявит на обучающей выборке, так как приблизит значение правдоподобия выборки к , но, во-первых, у такого алгоритма будут, скорее всего трудности с обобщающей способностью, во-вторых, этот алгоритм будет точно не линейным. И если, методы борьбы с переобучением (равно слабая обобщающая способность) явно не входят в план этой статьи, то по второму пункту давайте пройдемся подробнее. Для этого, достаточно ответить на простой вопрос. Может ли вероятность погашения кредита Васей и Федей быть одинаковой с учетом известных нам факторов? С точки зрения здравой логики конечно же нет, не может. Так на погашение кредита Вася будет отдавать 2.5% своей зарплаты в месяц, а Федя — почти 27,8%. Также на графике 2 «Классификация клиентов» мы видим, что Вася находится значительно дальше от линии, разделяющей классы, чем Федя. Ну и наконец, мы знаем, что функция для Васи и Феди принимает различные значения: 4.24 для Васи и 1.0 для Феди. Вот если бы Федя, например, зарабатывал на порядок больше или кредит поменьше просил, то тогда вероятности погашения кредита у Васи и Феди были бы схожими. Другими словами, линейную зависимость не обманешь. И если бы мы действительно рассчитали коэффициенты , а не взяли их с потолка, то могли бы смело заявить, что наши значения лучше всего позволяют оценить вероятность погашения кредита каждым заемщиком, но так как мы условились считать, что определение коэффициентов было проведено по всем правилам, то мы так и будем считать — наши коэффициенты позволяют дать лучшую оценку вероятности :)
Однако мы отвлеклись. В этом разделе нам надо разобраться как определяется вектор весов , который необходим для оценки вероятности возврата кредита каждым заемщиком.
Кратко резюмируем, с каким арсеналом мы выступаем на поиски коэффициентов :
1. Мы предполагаем, что зависимость между целевой переменной (прогнозным значением) и фактором, оказывающим влияние на результат — линейная. По этой причине применяется функция линейной регрессии вида , линия которого делит объекты (клиентов) на классы и или (клиенты, способные погасить кредит и не способные). В нашем случае уравнение имеет вид .
2. Мы используем функцию обратного логит-преобразования вида для определения вероятности принадлежности объекта к классу .
3. Мы рассматриваем нашу обучающую выборку как реализацию обобщенной схемы Бернулли, то есть для каждого объекта генерируется случайная величина, которая с вероятностью (своей для каждого объекта) принимает значение 1 и с вероятностью – 0.
4. Мы знаем, что нам требуется максимизировать функцию правдоподобия выборки с учетом принятых факторов для того, чтобы имеющаяся выборка стала наиболее правдоподобной. Другими словами, нам нужно подобрать такие параметры, при которых выборка будет наиболее правдоподобной. В нашем случае подбираемый параметр — это вероятность погашения кредита , которая в свою очередь зависит от неизвестных коэффициентов . Значит нам требуется найти такой вектор весов , при котором правдоподобие выборки будет максимальным.
5. Мы знаем, что для максимизации функции правдоподобия выборки можно использовать метод максимального правдоподобия. И мы знаем все хитрые приемы для работы с этим методом.
Вот такая многоходовочка получается :)
А теперь вспомним, что в самом начале статьи мы хотели вывести два вида функции потерь Logistic Loss в зависимости от того как обозначаются классы объектов. Так повелось, что в задачах классификации с двумя классами, классы обозначают как и или . В зависимости от обозначения, на выходе будет соответствующая функция потерь.
Случай 1. Классификация объектов на и
Раннее, при определении правдоподобия выборки, в котором вероятность погашения задолженности заемщиком рассчитывалась исходя из факторов и заданных коэффициентов , мы применили формулу:
На самом деле — это значение функции логистического отклика при заданном векторе весов
Тогда нам ничто не мешает записать функцию правдоподобия выборки так:
Бывает так, что иногда, некоторым начинающим аналитикам сложно сходу понять, как эта функция работает. Давайте рассмотрим 4 коротких примера, которые все прояснят:
1. Если (т.е. в соответствии с обучающей выборкой объект относится к классу +1), а наш алгоритм определяет вероятность отнесения объекта к классу равной 0.9, то вот этот кусочек правдоподобия выборки будет рассчитываться так:
2. Если , а , то расчет будет таким:
3. Если , а , то расчет будет таким:
4. Если , а , то расчет будет таким:
Очевидно, что функция правдоподобия будет максимизироваться в случаях 1 и 3 или в общем случае — при правильно отгаданных значениях вероятностей отнесения объекта к классу .
В связи с тем, что при определении вероятности отнесения объекта к классу нам не известны только коэффициенты , то мы их и будем искать. Как и говорилось выше, это задача оптимизации, в которой для начала нам требуется найти производную от функции правдоподобия по вектору весов . Однако предварительно имеет смысл упростить себе задачу: производную будем искать от логарифма функции правдоподобия.
Почему после логарифмирования, в функции логистической ошибки, мы поменяли знак с на . Все просто, так как в задачах оценки качества модели принято минимизировать значение функции, то мы умножили правую часть выражения на и соответственно вместо максимизации, теперь минимизируем функцию.
Собственно, сейчас, на ваших глазах была много страдальчески выведена функция потерь — Logistic Loss для обучающей выборки с двумя классами: и .
Теперь, для нахождения коэффициентов, нам потребуется всего лишь найти производную функции логистической ошибки и далее, используя численные методы оптимизации, такие как градиентный спуск или стохастический градиентный спуск, подобрать наиболее оптимальные коэффициенты . Но, учитывая, уже не малый объем статьи, предлагается провести дифференцирование самостоятельно или, быть может, это будет темой для следующей статьи с большим количеством арифметики без столь подробных примеров.
Случай 2. Классификация объектов на и
Подход здесь будет такой же, как и с классами и , но сама дорожка к выводу функции потерь Logistic Loss, будет более витиеватой. Приступаем. Будем для функции правдоподобия использовать оператор «если..., то...». То есть, если -ый объект относится к классу , то для расчета правдоподобия выборки используем вероятность , если объект относится к классу , то в правдоподобие подставляем . Вот так выглядит функция правдоподобия:
На пальцах распишем как это работает. Рассмотрим 4 случая:
1. Если и , то в правдоподобие выборки «пойдет»
2. Если и , то в правдоподобие выборки «пойдет»
3. Если и , то в правдоподобие выборки «пойдет»
4. Если и , то в правдоподобие выборки «пойдет»
Очевидно, что в 1 и 3 случае, когда вероятности были правильно определены алгоритмом, функция правдоподобия будет максимизироваться, то есть именно это мы и хотели получить. Однако, такой подход достаточно громоздок и далее мы рассмотрим более компактную запись. Но для начала, логарифмируем функцию правдоподобия с заменой знака, так как теперь мы будем минимизировать ее.
Подставим вместо выражение :
Упростим правое слагаемое под логарифмом, используя простые арифметические приемы и получим:
А теперь настало время избавиться от оператора «если..., то...». Заметим, что когда объект относится к классу , то в выражении под логарифмом, в знаменателе, возводится в степень , если объект относится к классу , то $e$ возводится в степень . Следовательно запись степени можно упростить — объединить оба случая в один: . Тогда функция логистической ошибки примет вид:
В соответствии с правилами логарифмирования, перевернем дробь и вынесем знак "" (минус) за логарифм, получим:
Перед вами функция потерь logistic Loss, которая применяется в обучающей выборке с объектами относимых к классам: и .
Что ж, на этом моменте я откланиваюсь и мы завершаем статью.
Предыдущая работа автора — «Приводим уравнение линейной регрессии в матричный вид»
Вспомогательные материалы
1. Литература
1) Прикладной регрессионный анализ / Н. Дрейпер, Г. Смит – 2-е изд. – М.: Финансы и статистика, 1986 (перевод с английского)
2) Теория вероятностей и математическая статистика / В.Е. Гмурман — 9-е изд. — М.: Высшая школа, 2003
3) Теория вероятностей / Н.И. Чернова — Новосибирск: Новосибирский государственный университет, 2007
4) Бизнес-аналитика: от данных к знаниям / Паклин Н. Б., Орешков В. И. — 2-е изд. — Санкт-Петербург: Питер, 2013
5) Data Science Наука о данных с нуля / Джоэл Грас — Санкт-Петербург: БХВ Петербург, 2017
6) Практическая статистика для специалистов Data Science / П.Брюс, Э.Брюс — Санкт-Петербург: БХВ Петербург, 2018
2. Лекции, курсы (видео)
1) Суть метода максимального правдоподобия, Борис Демешев
2) Метод максимального правдоподобия в непрерывном случае, Борис Демешев
3) Логистическая регрессия. Открытый курс ODS, Yury Kashnitsky
4) Лекция 4, Евгений Соколов (с 47 минуты видео)
5) Логистическая регрессия, Вячеслав Воронцов
3. Интернет-источники
1) Линейные модели классификации и регрессии
2) Как легко понять логистическую регрессию
3) Логистическая функция ошибки
4) Независимые испытания и формула Бернули
5) Баллада о ММП
6) Метод максимального правдоподобия
7) Формулы и свойства логарифмов
8) Почему число ?
9) Линейный классификатор


commanderxo
В конце шага 02 для отображения всей числовой прямой на отрезок [0; 1] предлагается использовать функцию логистического отклика. Почему именно её? Например арктангенс тоже непрерывно и монотонно отображает все числа на отрезок. Чем обратное-логит преобразование лучше?
AlexanderPetrenko Автор
Если я правильно понял вопрос, то он хороший и с подвохом :) даже хотел поставить лайк, но не хватает кармы))
Правильно ли я понимаю, что Вы предлагаете вместо выражения log(odds) использовать arctg(odds)?
Если так, то наша функция обратного отклика будет уже называться не логит-отклика, а как-то арктангенс-отклика)) и в соответствии с ней вероятность принадлежности объекта к классу будет определяться следующим образом:
p = 1 / (1+tg(w^Tx)^(-1)).
Эта формула получается посредством несложных математических выкладок. И все бы хорошо, но эта функция будет приводить нас к тому, что вероятность сможет принимать отрицательные значения, а некоторые значения w^Tx (при которых tg(w^Tx)^(-1) будет равен минус 1) будут недопустимы, так как делить на ноль нельзя.
Полагаю, что именно по этим причинам используется логарифмирование шансов, а не заведение их под арктангенс.
commanderxo
Переместить интервал (-Pi/2; +Pi/2) в (0;1) можно простым умножением и прибавлением константы, это не проблема. Вопрос без подвоха, действительно интересно почему выбрана именно функция с экспонентой, а не какая-либо другая.
chersanya
Ничем принципиальным logloss от арктангенса не отличается на самом деле, и иногда таки используется арктангенс. Основные причины, почему всё-таки логлосс на первом месте, как я понимаю — это связь с кросс-энтропией и т.п. из теорвера, что иногда удобнее для теоретических выкладок; и то что арктангенс медленее приближается к +-1, чем логлосс — тоже иногда удобнее.
Disclaimer — я этими вещами давно не занимаюсь, может есть и другие причины/различия.
AlexanderPetrenko Автор
Спасибо, за комментарий. Для меня пока остается не ясным механизм применения арктангенса. Сделал небольшие математические выкладки на этот счет. Прошу обратить внимание, что в п.3 арктангенс заменяется на тангенс и с этого собственно все беды и выходят. Если не затруднит, укажите, где ошибка.

chersanya
Вообще не понял вашего подхода. С чего вдруг логарифм заменяется на арктангенс, они же вообще не похожи друг на друга? Надо менять 1/(1+exp(kx)) на atan(kx).
AlexanderPetrenko Автор
По начальному вопросу, я именно так и понял, что спрашивают о возможной замене логарифма на арктангенс. Поэтому такие выкладки и сделал.
В вашем же случае, предлагается полностью заменить сигмойду. Я правда не очень улавливаю тогда теоретических предпосылок к этому. Ведь функция обратного логит-отклика выводилась из определения шансов, и соответственно имеет лучшую связь с вероятностями. Использование же арктангенса как функции активации рушит эту связь. Результаты будут скорее всего хуже.
А может Вы знаете случаи когда и для чего в линейных классификаторах применяют такую функцию?
chersanya
Замена сигмоиды на тангенс абсолютно эквивалентна замене логарифма на некую фунцию — легко арифметическими действиями вывести, какую именно. Поэтому интерпретация с шансами никуда не девается.
Из головы не знаю, но статьи и реализации различных методов, включая бустинг и нейросети, гуглятся по запросу в духе logloss vs arctan. Так что где-то да используется.
AlexanderPetrenko Автор
Пока не понял как сохраняется связь с шансами, так как мы их просто не используем в arctg, но на досуге попробую разобраться
Спасибо за обсуждение
coolemza
Если разберешься напиши сюда плз.
Спасибо.
AlexanderPetrenko Автор
Обязательно
chersanya
Ну смотрите, вы берёте odds = exp(-wx) и получаете p = 1/(1 + odds) = 1/(1+exp(-wx)). Давайте возьмём теперь odds = 1/atan*(wx) — 1, тогда получим p = 1/(1 + odds) = atan*(wx), вот и всё. Здесь за atan* я обозначил atan / pi + 0.5 для нормировки.
AlexanderPetrenko Автор
Да, интересно получается :)
спасибо за разъяснения
commanderxo
Вопрос был к абзацу:
Я это интерпретировал как «нам нужна функция, отображающая всю числовую прямую на отрезок [0;1]». Таких функций можно придумать много и разных, например 0,5+1/2*sin(x). Даже если дополнительно потребовать непрерывности, монотонности и как следствие существования обратной функции, то кандидатов тоже можно измыслить предостаточно, например 0,5+arctg(x)/Pi.
Вопрос был почему из всего многообразия вариантов было решено использовать именно логит.
Upd: выше уже назвали аргументы в пользу logloss. Спасибо!
AlexanderPetrenko Автор
Прошу посмотреть выкладки, которые я записал на бумаге. Мы об одном и том же говорим? Или Вы по другому видите применение арктангенса?
