
В докладе представлены некоторые подходы, которые позволяют следить за производительностью SQL-запросов, когда их миллионы в сутки, а контролируемых серверов PostgreSQL — сотни.
Какие технические решения позволяют нам эффективно обрабатывать такой объем информации, и как это облегчает жизнь обычного разработчика.
Кому интересен разбор конкретных проблем и разные техники оптимизаций SQL-запросов и решения типовых DBA-задач в PostgreSQL — можно также ознакомиться с серией статей на эту тему.
Меня зовут Кирилл Боровиков, я представляю компанию «Тензор». Конкретно я специализируюсь на работе с базами данных в нашей компании.
Сегодня я вам расскажу, как мы занимаемся оптимизацией запросов, когда вам надо не «расковырять» производительность какого-то одного запроса, а решить проблему массово. Когда запросов миллионы, и вам надо найти какие-то подходы к решению этой большой проблемы.
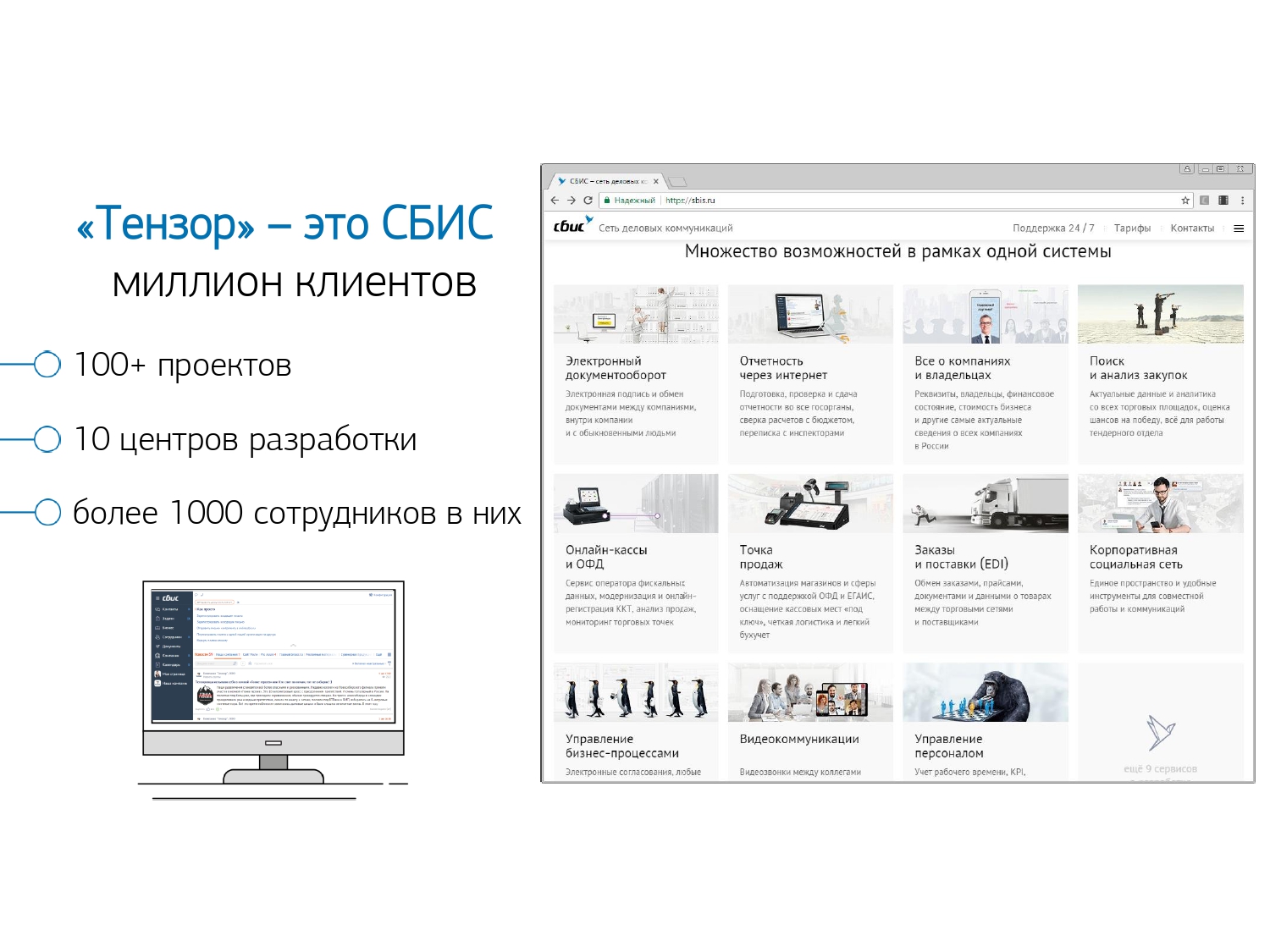
Вообще, «Тензор» для миллиона наших клиентов — это СБИС — наше приложение: корпоративная социальная сеть, решения для видеосвязи, для документооборота внутреннего и внешнего, учетные системы для бухгалтерии и склада,… То есть такой «мегакомбайн» для комплексного управления бизнесом, в котором больше 100 различных внутренних проектов.
Чтобы все они нормально работали и развивались — у нас 10 центров разработки по всей стране, в них — больше 1000 разработчиков.
С PostgreSQL мы работаем с 2008 года и накопили большой объем того, что мы обрабатываем — это клиентские данные, статистические, аналитические, данные из внешних информационных систем — больше 400TB. Только «в продакшене» около 250 серверов, а суммарно БД-серверов, которые мы мониторим — около 1000.

SQL — декларативный язык. Вы описываете не «как» что-то должно работать, а «что» вы хотите получить. СУБД лучше знает как сделать JOIN — как соединить ваши таблички, какие условия наложить, что пойдет по индексу, что нет…
Некоторые СУБД принимают подсказки: «Нет, вот эти две таблички соединяй в такой-то очереди», но PostgreSQL так не умеет. Это осознанная позиция ведущих разработчиков: «Лучше мы допилим оптимизатор запроса, чем разрешим разработчикам пользоваться какими-то хинтами».
Но, несмотря на то, что PostgreSQL не дает «снаружи» управлять собой, он отлично позволяет увидеть, что происходит у него «внутри», когда вы выполняете свой запрос, и где возникают у него проблемы.

Вообще, с какими классическими проблемами приходит разработчик [к DBA] обычно? «Вот мы тут выполнили запрос, и у нас все медленно, все повисло, что-то происходит… Беда какая-то!»
Причины почти всегда одни и те же:
… А для всего остального нам нужен план! Нам нужно видеть, что происходит внутри сервера.

План выполнения запроса для PostgreSQL — это дерево алгоритма выполнения запроса в текстовом представлении. Именно того алгоритма, который в результате анализа планировщиком был признан наиболее эффективным.
Каждый узел дерева — операция: извлечение данных из таблицы или индекса, построение битовой карты, соединение двух таблиц, объединение, пересечение или исключение выборок. Выполнение запроса — проход по узлам этого дерева.
Чтобы получить план запроса, самый простой способ — выполнить оператор
Плохой момент: когда вы его выполняете, это происходит «здесь и сейчас», поэтому подходит только для локальной отладки. Если же вы берете какой-то высоконагруженный сервер, который стоит под сильным потоком изменений данных, и видите: «Ай! Вот тут у нас медленно выполнялся запрос.» Полчаса, час назад — пока вы бегали и доставали этот запрос из логов, несли его снова на сервер, у вас весь датасет и статистика изменились. Вы его выполняете, чтобы отладить — а он выполняется быстро! И вы не можете понять «почему», почему было медленно.

Для того, чтобы понять, что было ровно в тот момент, когда запрос выполняется на сервере, умные люди написали модуль auto_explain. Он присутствует практически во всех наиболее распространенных дистрибутивах PostgreSQL, и его можно просто активировать в конфиг-файле.
Если он понимает, что какой-то запрос выполняется дольше той границы, которую вы ему сказали, он делает «снимок» плана этого запроса и пишет их вместе в лог.

Вроде все теперь хорошо, идем в лог и видим там… [портянка текста]. Но сказать ничего про него не можем, кроме того факта, что это отличный план, потому что выполнялся 11мс.
Вроде все хорошо — но ничего не понятно, что на самом деле происходило. Кроме общего времени особо ничего и не видим. Потому что смотреть на такую «латуху» plain text вообще ненаглядно.
Но даже пусть ненаглядно, пусть неудобно, но есть более капитальные проблемы:
При таких раскладах понять «Кто самое слабое звено?» практически нереально. Поэтому даже сами разработчики в «мануале» пишут, что «Понимание плана — это искусство, которому надо учиться, опыт...».
Но у нас 1000 разработчиков, и каждому из них этот опыт не передашь в голову. Я, ты, он — знают, а кто-то вон там — уже нет. Может, он научится, а может и нет, но работать ему надо уже сейчас — а откуда бы ему взять этот опыт.
Поэтому мы поняли — чтобы разбираться с этими проблемами, нам нужна хорошая визуализация плана. [статья]
Мы пошли сначала «по рынку» — давайте-ка в интернете поищем, что вообще существует.
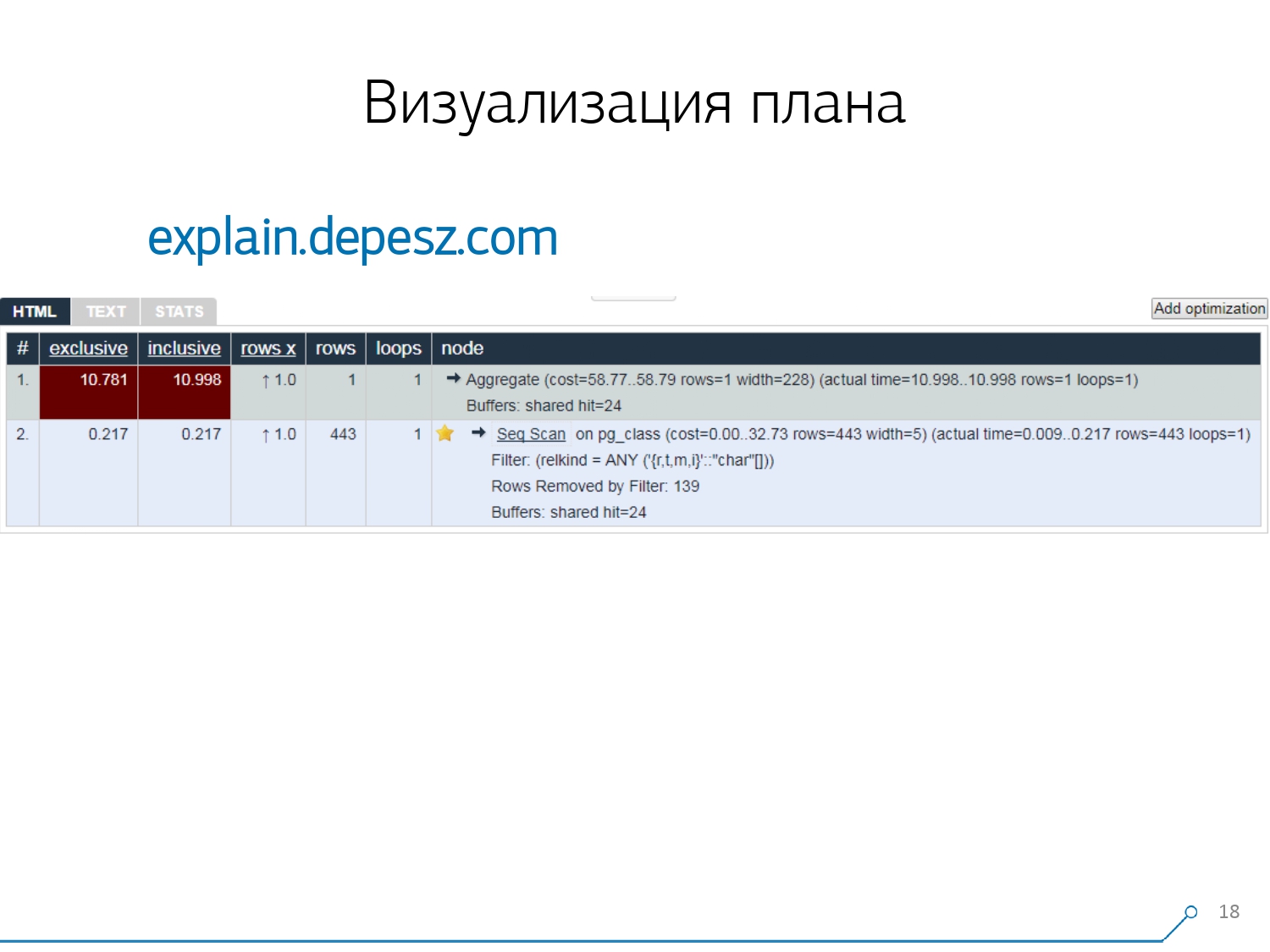
Но, оказалось, что относительно «живых» решений, которые более-менее развиваются, совсем мало — буквально, одно: explain.depesz.com от Hubert Lubaczewski. На вход в поле «скармливаешь» текстовое представление плана, он тебе показывает табличку с разобранными данными:
Также у этого сервиса есть возможность делиться архивом ссылок. Ты кинул туда свой план и говоришь: «Эй, Вася, вот тебе ссылка, там что-то не так».

Но есть и небольшие проблемы.
Во-первых, громадное количество «копипасты». Ты берешь кусок лога, засовываешь туда, и снова, и снова.
Во-вторых, нет анализа количества прочитанных данных — тех самых buffers, которые выводит
Третий отрицательный момент — очень слабое развитие этого проекта. Коммиты очень мелкие, хорошо если раз в полгода, и код на Perl'е.
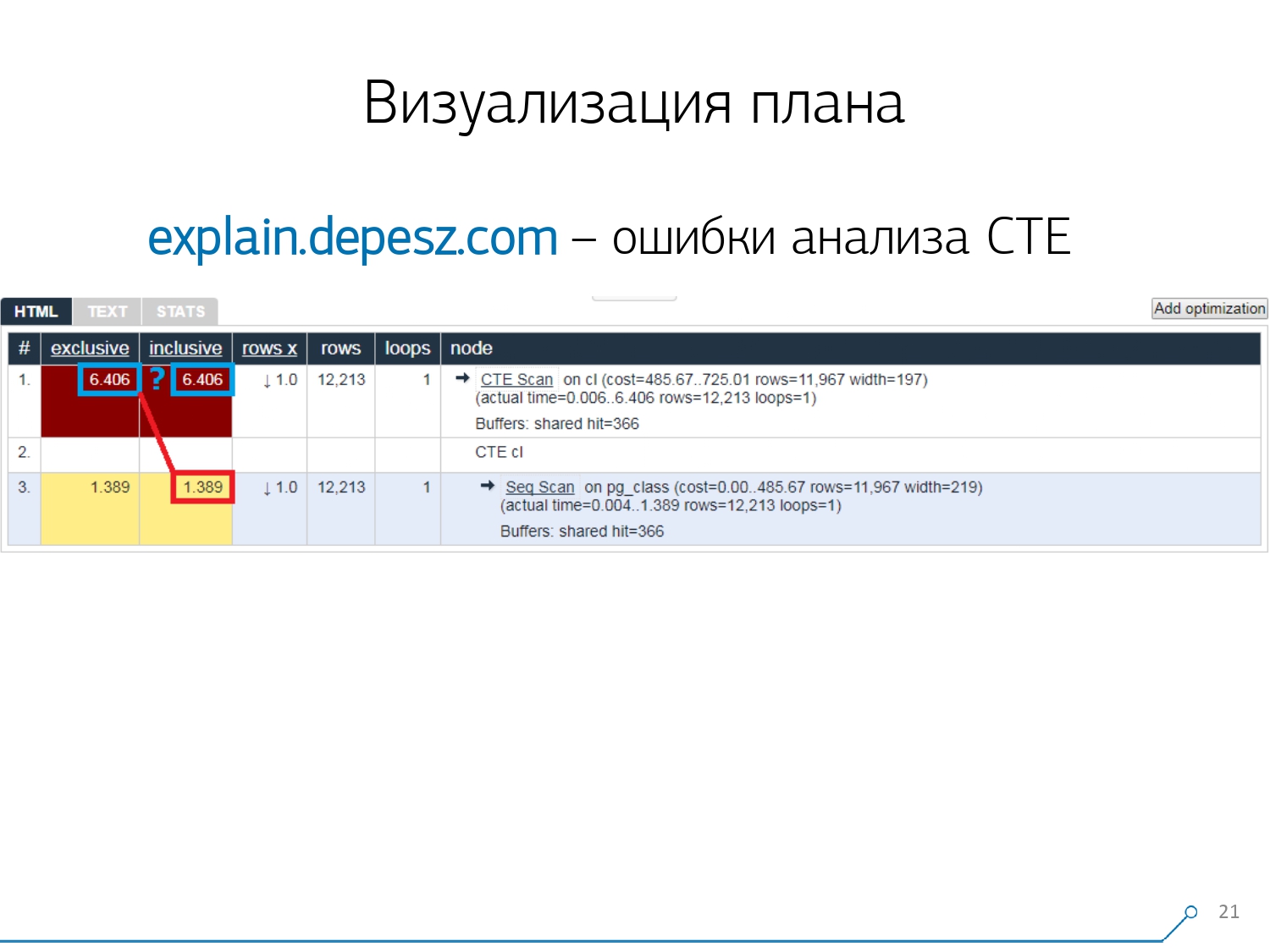
Но это все «лирика», с этим можно было бы как-то жить, но есть одна вещь, которая нас сильно отвернула от этого сервиса. Это ошибки анализа Common Table Expression (CTE) и разных динамических узлов вроде InitPlan/SubPlan.
Если верить этой картинке, то у нас суммарное время выполнения каждого отдельного узла больше, чем общее время выполнения всего запроса. Все просто — из узла CTE Scan не вычли время генерации этой CTE. Поэтому мы уже не знаем правильного ответа, сколько же заняло само сканирование CTE.

Тут мы поняли, что пора писать свое — ура-ура! Каждый разработчик говорит: «Сейчас мы свое напишем, супер просто будет!»
Взяли типичный для web-сервисов стек: ядро на Node.js + Express, натянули Bootstrap и для диаграммок красивых — D3.js. И наши ожидания вполне оправдались — первый прототип мы получили за 2 недели:
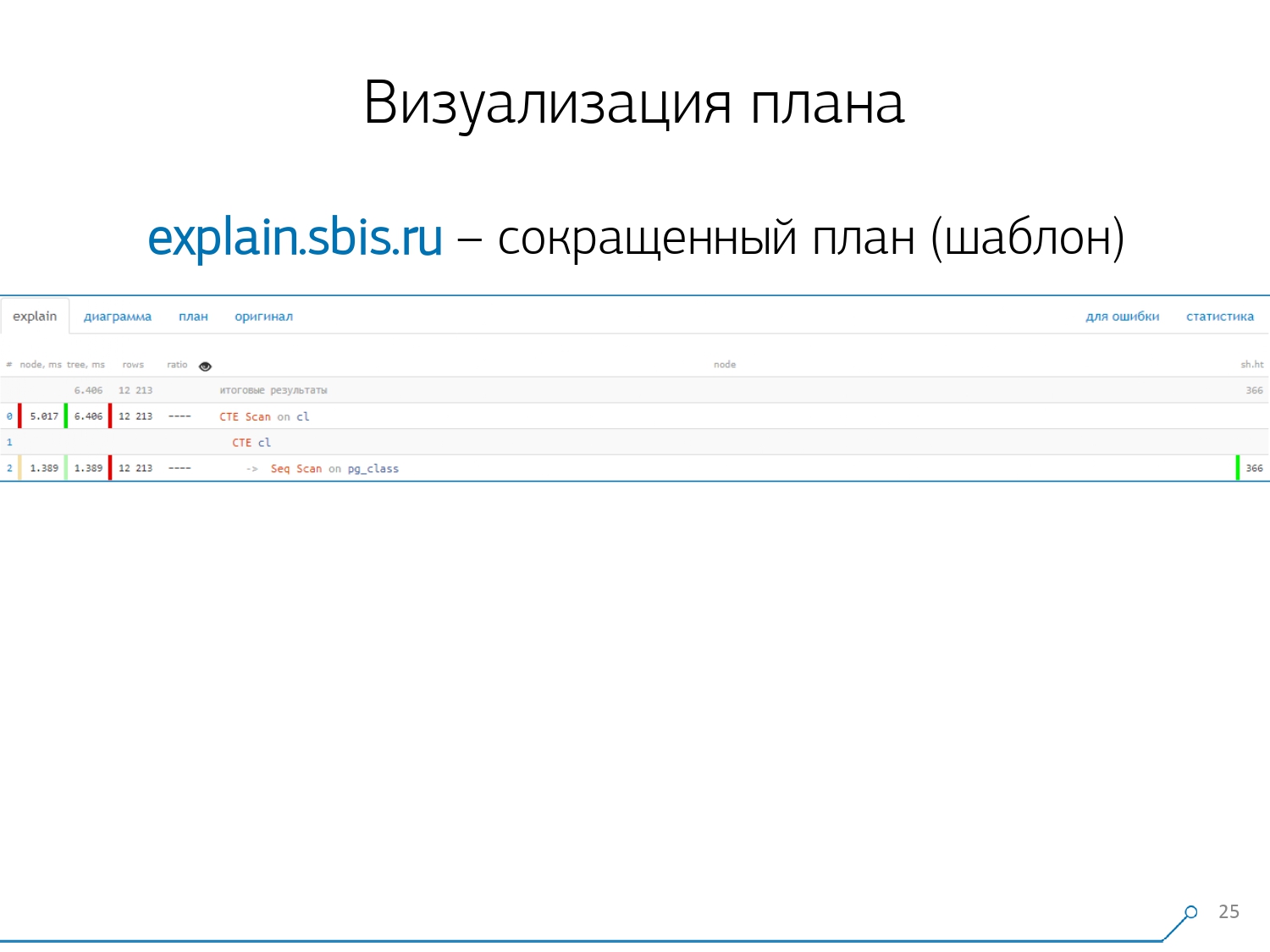
Мы получили примерно такую картинку — сразу с подсветкой синтаксиса. Но обычно наши разработчики работают уже не с полным представлением плана, а с тем, что покороче. Ведь все циферки мы уже распарсили и в сторону их налево-направо закинули, а посередине оставили только первую строчку, что это за узел: CTE Scan, генерация CTE или Seq Scan по какой-то табличке.
Вот это представление сокращенное мы называем шаблоном плана.
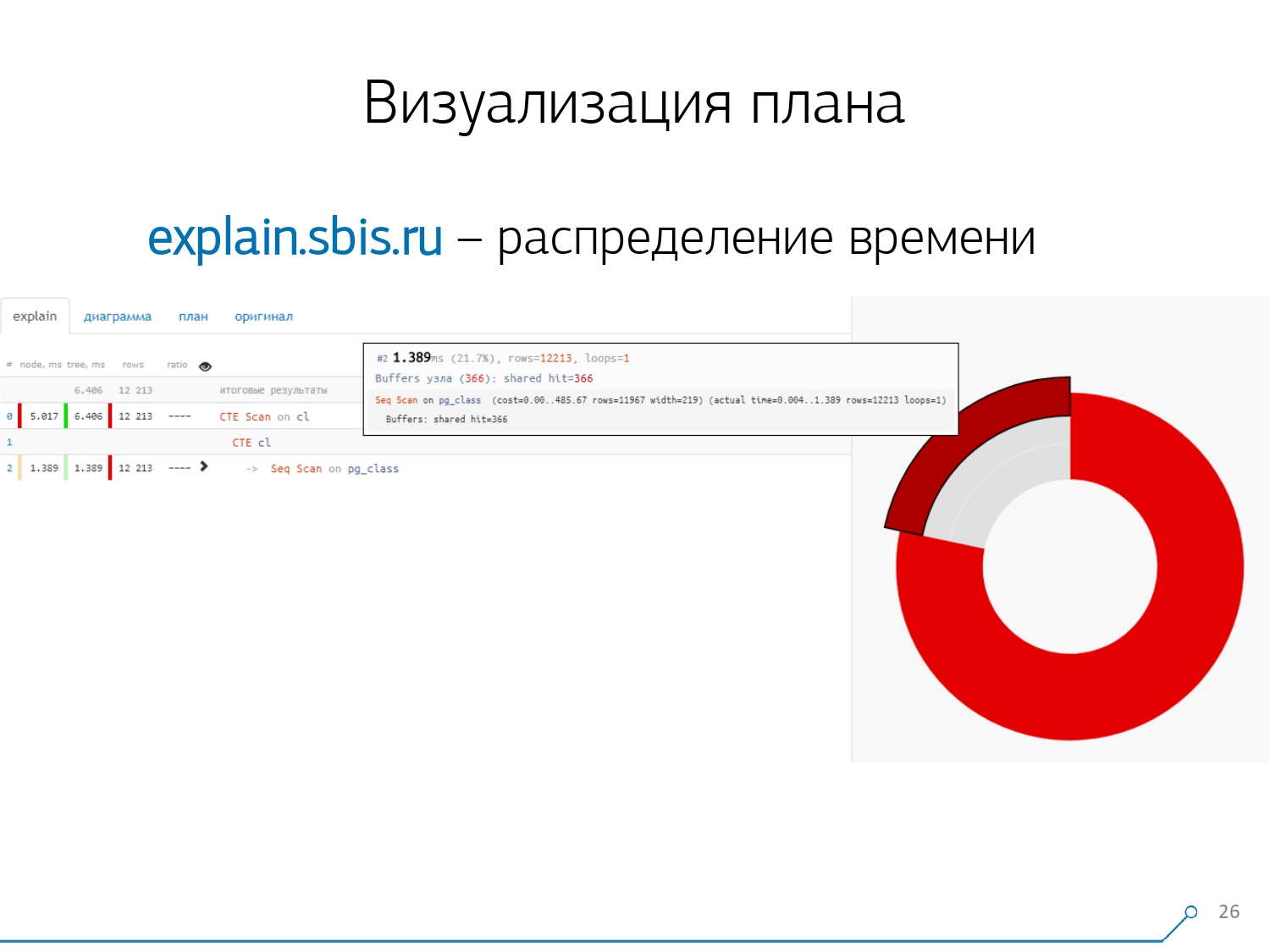
Что еще было бы удобно? Было бы удобно видеть, какая доля на какой узел от общего времени у нас распределяется — и просто «приклеили» сбоку pie chart.
Наводим на узел и видим — у нас, оказывается Seq Scan от всего времени занял меньше четверти, а остальные 3/4 у нас занял CTE Scan. Ужас! Это маленькое замечание по поводу «скорострельности» CTE Scan, если вы их активно используете в своих запросах. Они не очень быстрые — они проигрывают даже обычному табличному сканированию. [статья] [статья]
Но обычно такие диаграммы бывают поинтереснее, посложнее, когда мы сразу наводим на сегмент, и видим, например, что больше половины всего времени какой-то Seq Scan «съел». Да еще внутри там какой-то Filter был, куча записей отброшено по нему… Можно вот эту картинку прямо кидать разработчику и говорить: «Вася, у тебя тут вообще все плохо! Разберись, посмотри — что-то не так!»

Естественно, без «граблей» не обошлось.
Первое на что «наступили» — это проблема округления. Время узла каждого отдельного в плане указывается с точностью до 1мкс. И когда количество циклов узла превышает, например, 1000 — после выполнения PostgreSQL поделил «с точностью до», то при обратном расчете мы получаем общее время «где-то между 0.95мс и 1.05мс». Когда счет идет на микросекунды — еще ничего, а вот когда уже на [милли]секунды — приходится при «развязывании» ресурсов по узлам плана «кто у кого сколько потребил» эту информацию учитывать.

Второй момент, более сложный, это распределение ресурсов (тех самых buffers) по динамическим узлам. Это стоило нам к первым 2 неделям на прототип еще плюсом недели 4.
Проблему такую получить достаточно просто — делаем CTE и в ней что-то якобы читаем. На самом деле, PostgreSQL «умный» и ничего прямо там читать не будет. Потом мы из нее берем первую запись, а к ней — сто первую из той же самой CTE.
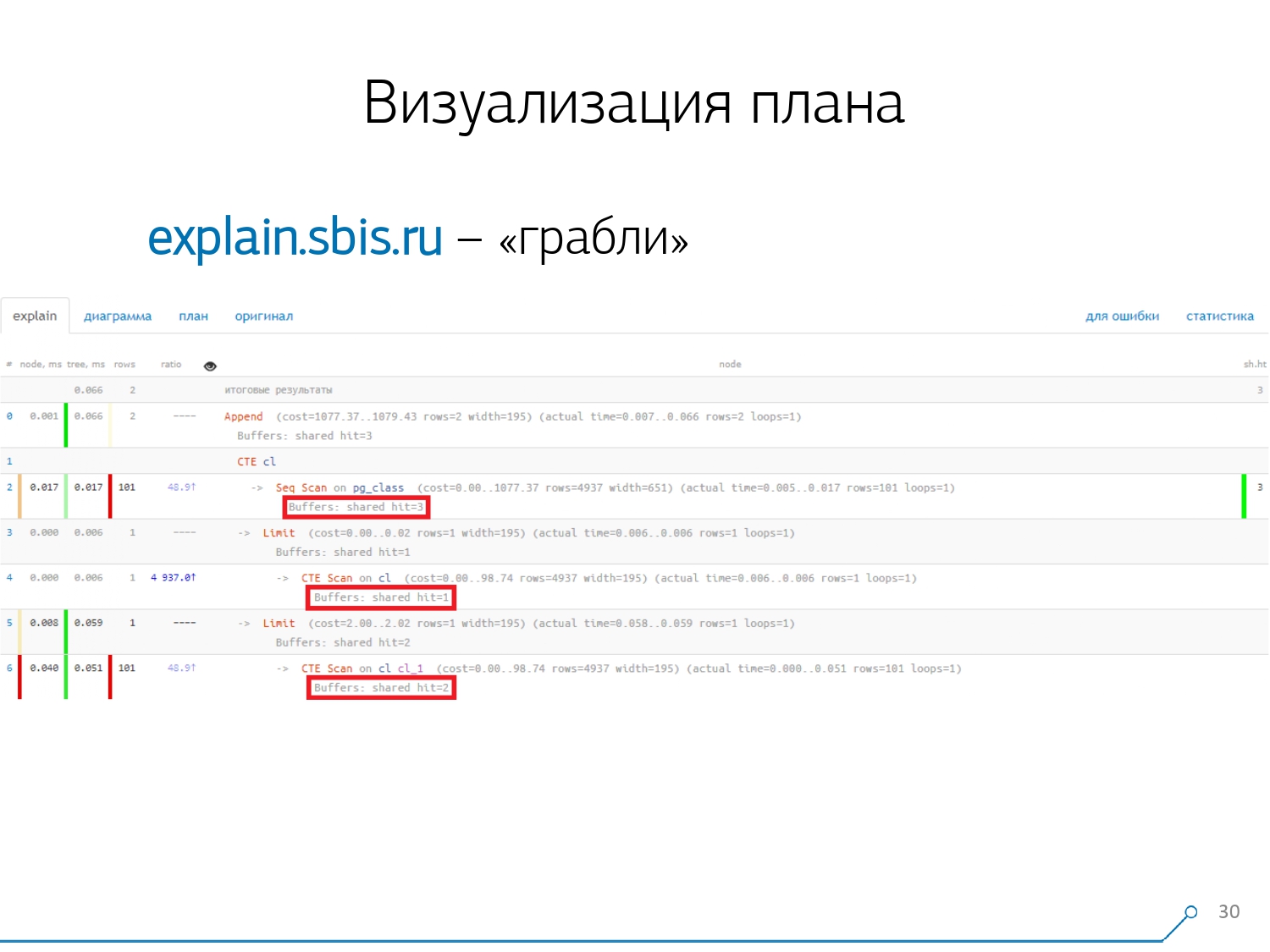
Смотрим план и понимаем — странно, у нас 3 buffers (страницы данных) были «потреблены» в Seq Scan, еще 1 в CTE Scan, и еще 2 во втором CTE Scan. То есть если все просто просуммировать, у нас получится 6, но из таблички-то мы прочитали всего 3! CTE Scan ведь ничего ниоткуда не читает, а работает прямо с памятью процесса. То есть здесь явно что-то не так!
На самом-то деле получается, что здесь все те 3 страницы данных, которые были запрошены у Seq Scan, сначала 1 попросил 1-й CTE Scan, а потом 2-й, и ему дочитали еще 2. То есть всего было прочитано 3 страницы данных, а не 6.
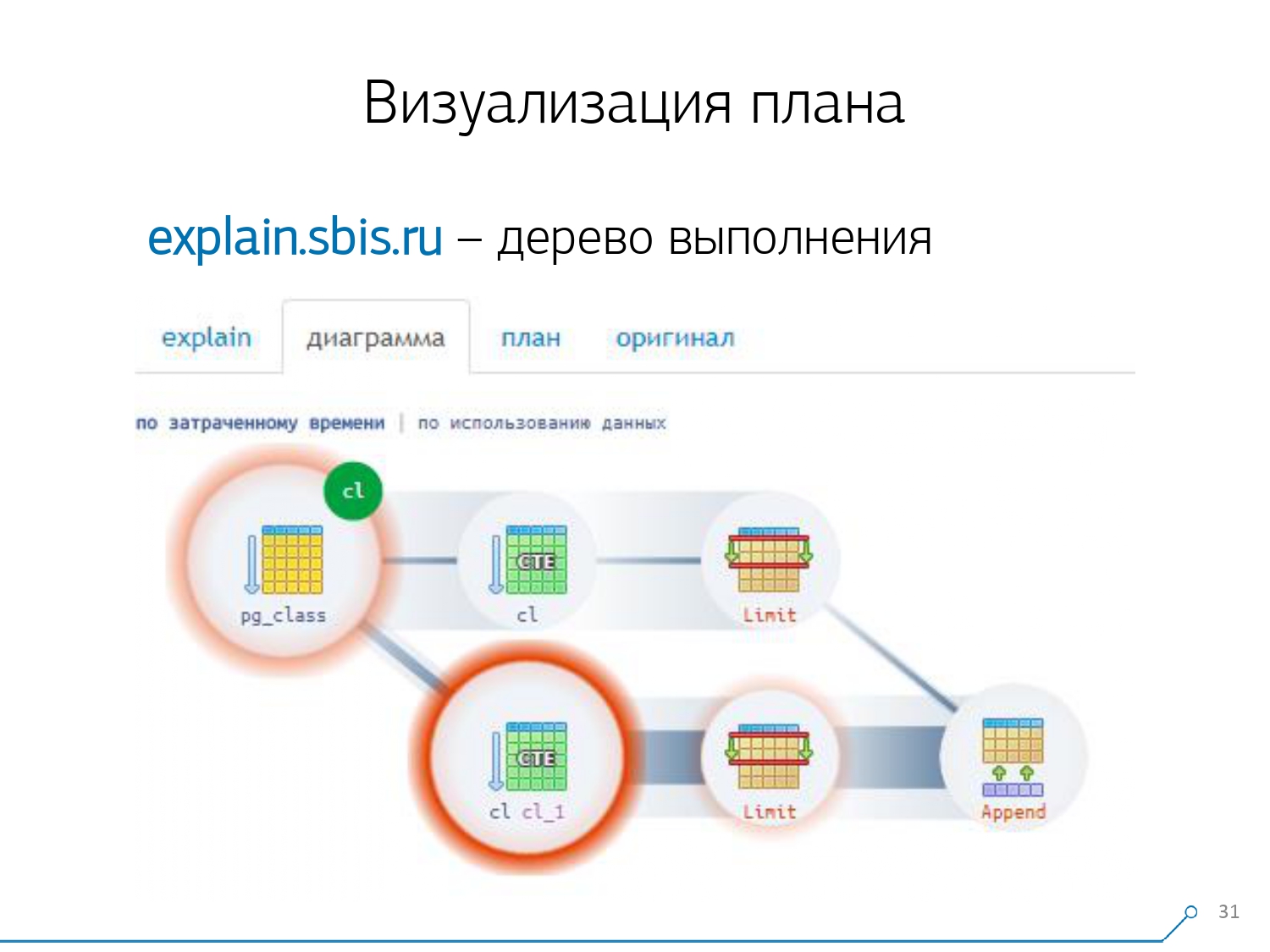
И эта картинка привела нас к пониманию, что выполнение плана — это уже не дерево, а просто какой-то ациклический граф. И у нас получилась вот такая примерно диаграмма, чтобы мы понимали «что-откуда вообще пришло». То есть вот здесь мы создали CTE из pg_class, и два раза ее попросили, и практически все время у нас ушло по ветке, когда мы просили ее 2й раз. Понятно, что прочитать 101-ю запись — это намного дороже, чем просто 1-ю из таблички.

Мы на какое-то время выдохнули. Сказали: «Теперь, Нео, ты знаешь кунг-фу! Теперь наш опыт у тебя прямо на экране. Теперь ты можешь им пользоваться.» [статья]
Наши 1000 разработчиков облегченно вздохнули. Но мы-то понимали, что у нас только «боевых» серверов сотни, и весь этот «копипаст» со стороны разработчиков совсем не удобен. Мы поняли, что надо это самим собирать.

Вообще, есть штатный модуль, который умеет собирать статистику, правда, его так же нужно в конфиге активировать — это модуль pg_stat_statements. Но он нас не устроил.
Во-первых, одним и тем же запросам по разным схемам в рамках одной базы он присваивает разные QueryId. То есть если сначала сделать
Второй момент, который нам помешал его использовать — отсутствие планов. То есть плана — нет, есть только сам запрос. Мы видим что тормозило, но не понимаем, почему. И тут мы возвращаемся к проблеме быстроизменяемого датасета.
И последний момент — отсутствие «фактов». То есть нельзя адресоваться к конкретному экземпляру выполнения запроса — его нет, есть только агрегированная статистика. С этим хоть и можно работать, просто очень сложно.
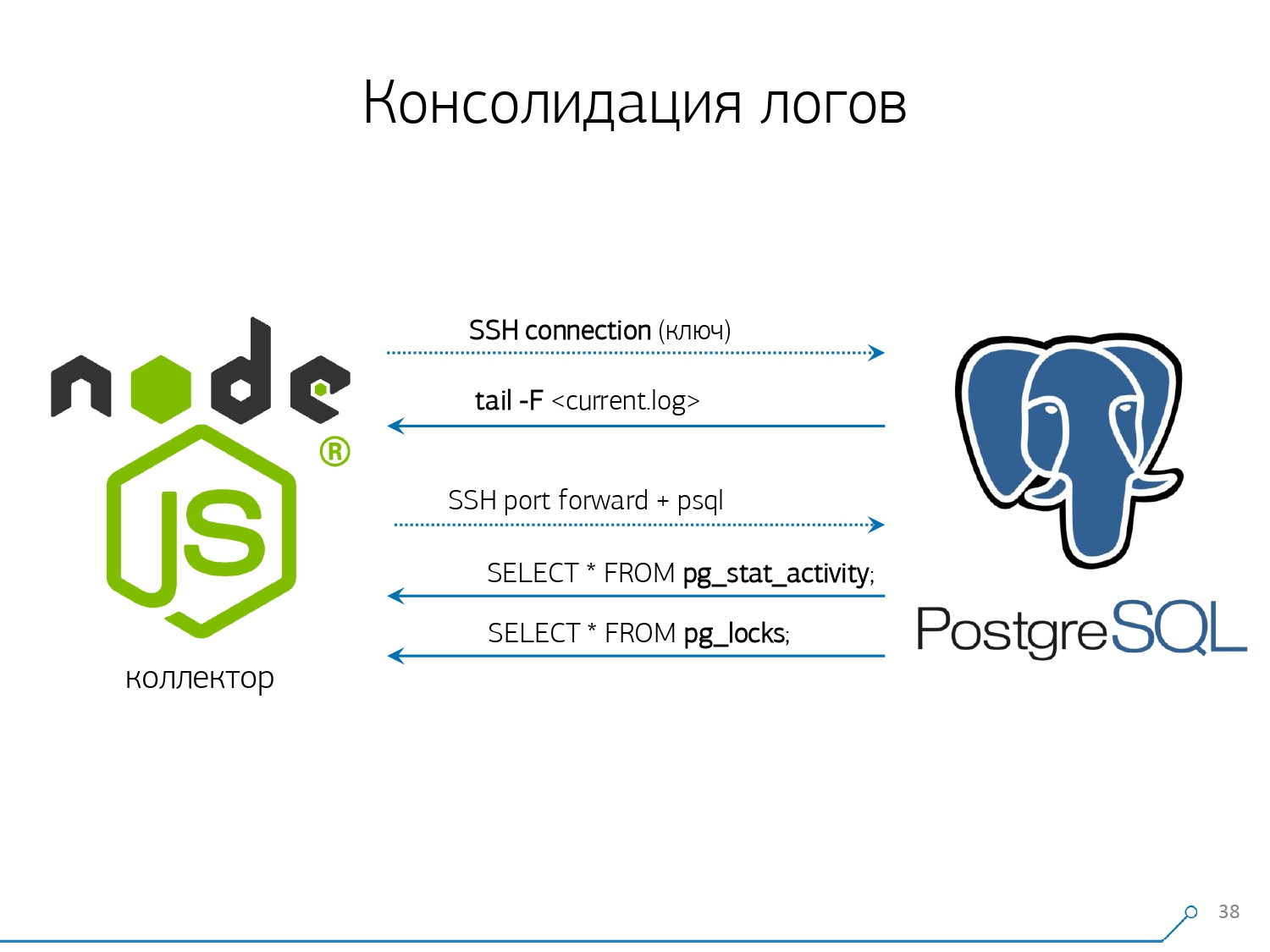
Поэтому мы решили с «копипастой» бороться и начали писать коллектор.
Коллектор подключается по SSH, «натягивает» с помощью сертификата защищенное соединение до сервера с базой и
Поскольку мы уже начали писать интерфейс на Node.js, то на нем же и коллектор продолжили писать. И эта технология себя оправдала, потому что для работы со слабоформатированными текстовыми данными, которыми и является лог, использовать JavaScript очень удобно. А сама инфраструктура Node.js в качестве backend-платформы позволяет легко и удобно работать с сетевыми соединениями, да и вообще с какими-то потоками данных.
Соответственно, мы «натягиваем» два соединения: первое, чтобы «слушать» сам лог и его к себе забирать, а второе — чтобы периодически у базы спрашивать. «А вот в логе прилетело, что заблокирована табличка с oid 123», но разработчику это не говорит ни о чем, и неплохо бы спросить у базы «А что же все-таки такое OID = 123?» И так мы периодически спрашиваем у базы то, что у себя еще не знаем.

«Лишь одного ты не учел, есть вид слоноподобных пчел!..» Мы начинали разрабатывать эту систему, когда хотели отмониторить 10 серверов. Наиболее критичных в нашем понимании, на которых возникали какие-то проблемы, с которыми было сложно разбираться. Но в течение первого же квартала мы получили на мониторинг сотню — потому что система «зашла», все захотели, всем удобно.
Все это надо складывать, данных поток большой, активный. Собственно, что мониторим, с чем умеем разбираться — то и используем. Используем в качестве хранилища данных тоже PostgreSQL. А ничего быстрее, чтобы «лить» в него данные, чем оператор
Но просто «лить» данные — не совсем наша технология. Потому что если у вас на сотне серверов происходит примерно 50k запросов в секунду, то это вам генерирует 100-150GB логов в день. Поэтому нам пришлось базу аккуратно «пилить».
Во-первых, мы сделали секционирование по дням, потому что, по большому счету, никого не интересует корреляция между сутками. Какая разница, что у тебя было вчера, если сегодня ночью ты выкатил новую версию приложения — и уже какая-то новая статистика.
Во-вторых, мы научились (вынуждены были) очень-очень быстро писать с помощью

Третий момент — пришлось отказаться от триггеров, соответственно, и от Foreign Keys. То есть у нас нет совсем ссылочной целостности. Потому что если у вас есть таблица, на которой есть пара FK, и вы говорите в структуре БД, что «вот запись из лога ссылается по FK, например, на группу записей», то когда вы ее вставляете, PostgreSQL ничего не остается, кроме как взять и честно выполнить
Мы получаем вместо одной записи в целевую таблицу и ее индексы, еще плюсом чтения из всех таблиц, на которые она ссылается. А нам это совсем не надо — наша задача записать как можно больше и как можно быстрее с наименьшей нагрузкой. Так что FK — долой!
Следующий момент — агрегация и хэширование. Изначально они были у нас реализованы в БД — ведь удобно же сразу, когда прилетает запись, сделать в какой-то табличке «плюс один» прямо в триггере. Хорошо, удобно, но плохо тем же — вставляете одну запись, а вынуждены прочитать и записать еще что-то из другой таблицы. Причем, мало того, что прочитать и записать — еще и сделать это каждый раз.
А теперь представьте, что у вас есть табличка, в которой вы просто считаете количество запросов, прошедших по конкретному хосту:
Да, у вас в случае каких-то неполадок может «развалиться» логическая целостность, но это практически нереальный кейс — потому что у вас нормальный сервер, на нем батарейка в контроллере, у вас журнал транзакций, журнал на файловой системе… В общем, не стоит оно того. Не стоит та потеря производительности, которую вы получаете за счет работы триггеров/FK, тех расходов, которые вы несете при этом.
То же самое и с хэшированием. Летит к вам некий запрос, вы от него вычисляете в БД некий идентификатор, пишете в базу и всем потом говорите его. Все хорошо, пока в момент записи к вам не придет второй желающий записать его же — и у вас возникнет блокировка, а это уже плохо. Поэтому если вы можете генерацию каких-то ID вынести на клиента (относительно базы), лучше это сделать.
Нам просто идеально подошло использовать MD5 от текста — запроса, плана, шаблона,… Мы вычисляем его на стороне коллектора, и «льем» в базу уже готовый ID. Длина MD5 и посуточное секционирование позволяют нам не беспокоиться о возможных коллизиях.
Но чтобы это все записать быстро, нам понадобилось модифицировать саму процедуру записи.
Как обычно пишут данные? У нас есть какой-то датасет, мы его раскладываем на несколько таблиц, а потом COPY — сначала в первую, потом во вторую, в третью… Неудобно, потому что мы вроде один поток данных пишем за три шага последовательно. Неприятно. Можно ли сделать быстрее? Можно!
Для этого достаточно всего лишь разложить эти потоки параллельно друг с другом. Получается, что у нас летят в отдельных потоках ошибки, запросы, шаблоны, блокировки,… — и мы пишем это все параллельно. Для этого достаточно держать постоянно открытым COPY-канал на каждую отдельную целевую таблицу.

То есть у коллектора всегда есть стрим, в который я могу записать нужные мне данные. Но чтобы база эти данные увидела, а кто-нибудь не висел в блокировки, ожидая, пока эти данные запишутся, COPY надо прерывать с определенной периодичностью. Для нас наиболее эффективным получился период порядка 100мс — закрываем и сразу снова открываем на ту же таблицу. А если у нас одного потока не хватает при каких-то пиках, то мы делаем пулинг до определенного предела.
Дополнительно мы выяснили, что для такого профиля нагрузки любая агрегация, когда записи собираются в пакеты — это зло. Классическое зло — это
Чтобы избавиться от таких аномалий, просто не агрегируйте ничего, не буферизируйте вообще. И если буферизация на диск все-таки возникает (к счастью, Stream API в Node.js позволяет это узнать) — отложите это соединение. Вот когда вам придет событие, что оно снова свободно — пишите в него из накопившейся очереди. А пока оно занято — берите из пула следующее, свободное, и пишите в него.
До внедрения такого подхода к записи данных у нас было примерно 4K write ops, а таким способом сократили нагрузку в 4 раза. Сейчас выросли еще в 6 раз за счет новых наблюдаемых баз — до 100MB/s. И теперь мы храним логи за последние 3 месяца в объеме около 10-15TB, надеясь, что уж за три-то месяца любую проблему любой разработчик способен решить.
Но просто собрать все эти данные — хорошо, полезно, уместно, но мало — их надо понять. Потому что это миллионы различных планов за сутки.

Но миллионы — это неуправляемо, надо сначала сделать «поменьше». И, в первую очередь, надо решить, как это «поменьше» вы будете организовывать.
Мы выделили для себя три ключевые момента:
Чтобы понять «кто» прислал нам запрос, мы пользуемся штатным средством — установкой переменной сессии:
После того, как мы передали «хозяина» запроса, его надо вывести в лог — для этого конфигурируем переменную
Дальше мы поняли, что не очень интересно смотреть корреляцию по одному запросу между разными серверами. Нечасто получается ситуация, когда у вас одно приложение одинаково «лажает» и тут, и там. Но даже если одинаково — посмотрите на любой из этих серверов.
Так вот, разреза «один сервер — один день» нам оказалось достаточно для любого анализа.
Первый аналитический разрез — это тот самый «шаблон» — сокращенная форма представления плана, очищенная от всех численных показателей. Второй разрез — приложение или метод, а третий — это конкретный узел плана, который вызвал у нас проблемы.
Когда мы перешли от конкретных экземпляров к шаблонам, получили сразу два преимущества:

Остальные способы базируются на тех показателях, которые мы извлекаем из плана: сколько раз происходил такой шаблон, суммарное и среднее время, сколько данных вычитано с диска, а сколько из памяти…
Потому что вы, например, приходите на страницу аналитики по хосту, смотрите — что-то слишком много по диску читать начало. Диск на сервере не справляется — а кто с него читает?
И вы можете отсортировать по любому столбцу и решить, с чем вы будете прямо сейчас разбираться — с нагрузкой на процессор или на диск, или с общим количеством запросов… Отсортировали, посмотрели «топовые», починили — выкатили новую версию приложения.
[видеолекция]
И сразу вы можете увидеть разные приложения, которые ходят с одним и тем же шаблоном от запроса типа
Обратный способ — от приложения сразу увидеть, что оно делает. Например, фронтенд — это, это, вот это, а еще вот это раз в час (как раз таймлайн помогает). И сразу возникает вопрос — вроде бы не дело фронтенда делать что-то раз в час…

Через какое-то время мы поняли, что нам не хватает агрегированной статистики в разрезе узлов плана. Мы вычленили из планов только те узлы, которые что-то делают с данными самих таблиц (читают/пишут их по индексу или нет). По сути, относительно предыдущей картинки добавляется всего один аспект — сколько записей этот узел нам принес, а сколько отбросил (Rows Removed by Filter).
У вас нет подходящего индекса на табличке, вы делаете к ней запрос, он пролетает мимо индекса, падает в Seq Scan… все записи, кроме одной вы отфильтровали. А зачем вам за сутки 100M отфильтрованных записей, не лучше ли индекс накатить?

Разобрав все планы по узлам, мы поняли, что есть некоторые типовые структуры в планах, которые с очень большой вероятностью выглядят подозрительно. И неплохо бы разработчику подсказать: «Друг, вот тут ты сначала читаешь по индексу, потом сортируешь, а потом отрезаешь» — как правило, там одна запись.
Все кто писал запросы, с таким паттерном, наверняка, сталкивались: «Дай мне последний заказ по Васе, его дату» И если у вас индекса по дате нету, или в использовавшемся индексе нет даты, то вот ровно на такие «грабли» и наступите.
Но мы же знаем, что это «грабли» — так почему бы сразу не подсказать разработчику, что ему стоит сделать. Соответственно, открывая сейчас план, наш разработчик сразу видит красивую картинку с подсказками, где ему сразу говорят: «У тебя проблемы тут и тут, а решаются они так и так.»
В результате, объем того опыта, который был необходим для решения проблем в начале и сейчас, упал в разы. Вот такой инструмент у нас получился.

Какие технические решения позволяют нам эффективно обрабатывать такой объем информации, и как это облегчает жизнь обычного разработчика.
Кому интересен разбор конкретных проблем и разные техники оптимизаций SQL-запросов и решения типовых DBA-задач в PostgreSQL — можно также ознакомиться с серией статей на эту тему.
Меня зовут Кирилл Боровиков, я представляю компанию «Тензор». Конкретно я специализируюсь на работе с базами данных в нашей компании.
Сегодня я вам расскажу, как мы занимаемся оптимизацией запросов, когда вам надо не «расковырять» производительность какого-то одного запроса, а решить проблему массово. Когда запросов миллионы, и вам надо найти какие-то подходы к решению этой большой проблемы.
Вообще, «Тензор» для миллиона наших клиентов — это СБИС — наше приложение: корпоративная социальная сеть, решения для видеосвязи, для документооборота внутреннего и внешнего, учетные системы для бухгалтерии и склада,… То есть такой «мегакомбайн» для комплексного управления бизнесом, в котором больше 100 различных внутренних проектов.
Чтобы все они нормально работали и развивались — у нас 10 центров разработки по всей стране, в них — больше 1000 разработчиков.
С PostgreSQL мы работаем с 2008 года и накопили большой объем того, что мы обрабатываем — это клиентские данные, статистические, аналитические, данные из внешних информационных систем — больше 400TB. Только «в продакшене» около 250 серверов, а суммарно БД-серверов, которые мы мониторим — около 1000.
SQL — декларативный язык. Вы описываете не «как» что-то должно работать, а «что» вы хотите получить. СУБД лучше знает как сделать JOIN — как соединить ваши таблички, какие условия наложить, что пойдет по индексу, что нет…
Некоторые СУБД принимают подсказки: «Нет, вот эти две таблички соединяй в такой-то очереди», но PostgreSQL так не умеет. Это осознанная позиция ведущих разработчиков: «Лучше мы допилим оптимизатор запроса, чем разрешим разработчикам пользоваться какими-то хинтами».
Но, несмотря на то, что PostgreSQL не дает «снаружи» управлять собой, он отлично позволяет увидеть, что происходит у него «внутри», когда вы выполняете свой запрос, и где возникают у него проблемы.
Вообще, с какими классическими проблемами приходит разработчик [к DBA] обычно? «Вот мы тут выполнили запрос, и у нас все медленно, все повисло, что-то происходит… Беда какая-то!»
Причины почти всегда одни и те же:
- неэффективный алгоритм запроса
Разработчик: «Сейчас я в SQL ему 10 табличек через JOIN...» — и ожидает, что его условия чудесным образом эффективно «развяжутся», и он получит все быстро. Но чудес не бывает, и любая система при такой вариативности (10 таблиц в одном FROM) всегда дает какую-то погрешность. [статья] - неактуальная статистика
Момент очень актуален именно для PostgreSQL, когда вы большой датасет «влили» на сервер, делаете запрос — а он у вас «сексканит» по табличке. Потому что вчера в ней лежало 10 записей, а сегодня 10 миллионов, но PostgreSQL об этом еще не в курсе, и надо ему об этом подсказать. [статья] - «затык» по ресурсам
Вы поставили большую и тяжелую нагруженную базу поставили на слабый сервер, у которого не хватает диска, памяти, производительности самого процессора. И все… Где-то есть потолок производительности, выше которого вы прыгнуть уже не можете. - блокировки
Сложный момент, но они наиболее актуальны для различных модифицирующих запросов (INSERT, UPDATE, DELETE) — это отдельная большая тема.
Получение плана
… А для всего остального нам нужен план! Нам нужно видеть, что происходит внутри сервера.
План выполнения запроса для PostgreSQL — это дерево алгоритма выполнения запроса в текстовом представлении. Именно того алгоритма, который в результате анализа планировщиком был признан наиболее эффективным.
Каждый узел дерева — операция: извлечение данных из таблицы или индекса, построение битовой карты, соединение двух таблиц, объединение, пересечение или исключение выборок. Выполнение запроса — проход по узлам этого дерева.
Чтобы получить план запроса, самый простой способ — выполнить оператор
EXPLAIN. Чтобы получить со всеми реальными атрибутами, то есть на самом деле выполнить запрос на базе — EXPLAIN (ANALYZE, BUFFERS) SELECT ....Плохой момент: когда вы его выполняете, это происходит «здесь и сейчас», поэтому подходит только для локальной отладки. Если же вы берете какой-то высоконагруженный сервер, который стоит под сильным потоком изменений данных, и видите: «Ай! Вот тут у нас медленно выполнялся запрос.» Полчаса, час назад — пока вы бегали и доставали этот запрос из логов, несли его снова на сервер, у вас весь датасет и статистика изменились. Вы его выполняете, чтобы отладить — а он выполняется быстро! И вы не можете понять «почему», почему было медленно.
Для того, чтобы понять, что было ровно в тот момент, когда запрос выполняется на сервере, умные люди написали модуль auto_explain. Он присутствует практически во всех наиболее распространенных дистрибутивах PostgreSQL, и его можно просто активировать в конфиг-файле.
Если он понимает, что какой-то запрос выполняется дольше той границы, которую вы ему сказали, он делает «снимок» плана этого запроса и пишет их вместе в лог.
Вроде все теперь хорошо, идем в лог и видим там… [портянка текста]. Но сказать ничего про него не можем, кроме того факта, что это отличный план, потому что выполнялся 11мс.
Вроде все хорошо — но ничего не понятно, что на самом деле происходило. Кроме общего времени особо ничего и не видим. Потому что смотреть на такую «латуху» plain text вообще ненаглядно.
Но даже пусть ненаглядно, пусть неудобно, но есть более капитальные проблемы:
- В узле указывается сумма по ресурсам всего поддерева под ним. То есть просто так узнать, сколько вот тут конкретно на этом Index Scan было потрачено времени — нельзя, если под ним есть какое-нибудь вложенное условие. Мы должны динамически смотреть, нет ли внутри «детей» и условных переменных, CTE — и вычитать это все «в уме».
- Второй момент: время, которое указывается на узле, — это время однократного выполнения узла. Если этот узел выполнялся в результате, например, цикла по записям таблицы, несколько раз, то в плане увеличивается количество loops — циклов этого узла. Но само время атомарного выполнения остается в плане прежним. То есть для того, чтобы понять, а сколько же этот узел выполнялся всего суммарно, надо одно умножать на другое — опять-таки «в уме».
При таких раскладах понять «Кто самое слабое звено?» практически нереально. Поэтому даже сами разработчики в «мануале» пишут, что «Понимание плана — это искусство, которому надо учиться, опыт...».
Но у нас 1000 разработчиков, и каждому из них этот опыт не передашь в голову. Я, ты, он — знают, а кто-то вон там — уже нет. Может, он научится, а может и нет, но работать ему надо уже сейчас — а откуда бы ему взять этот опыт.
Визуализация плана
Поэтому мы поняли — чтобы разбираться с этими проблемами, нам нужна хорошая визуализация плана. [статья]
Мы пошли сначала «по рынку» — давайте-ка в интернете поищем, что вообще существует.
Но, оказалось, что относительно «живых» решений, которые более-менее развиваются, совсем мало — буквально, одно: explain.depesz.com от Hubert Lubaczewski. На вход в поле «скармливаешь» текстовое представление плана, он тебе показывает табличку с разобранными данными:
- собственное время отработки узла
- время суммарное по всему поддереву
- количество записей, которое было извлечено, и которое статистически ожидалось
- само тело узла
Также у этого сервиса есть возможность делиться архивом ссылок. Ты кинул туда свой план и говоришь: «Эй, Вася, вот тебе ссылка, там что-то не так».
Но есть и небольшие проблемы.
Во-первых, громадное количество «копипасты». Ты берешь кусок лога, засовываешь туда, и снова, и снова.
Во-вторых, нет анализа количества прочитанных данных — тех самых buffers, которые выводит
EXPLAIN (ANALYZE, BUFFERS), тут мы не видим. Он просто не умеет их разбирать, понимать и с ними работать. Когда вы читаете много данных и понимаете, что можете неправильно «разложиться» по диску и кэшу в памяти, эта информация очень важна.Третий отрицательный момент — очень слабое развитие этого проекта. Коммиты очень мелкие, хорошо если раз в полгода, и код на Perl'е.
Но это все «лирика», с этим можно было бы как-то жить, но есть одна вещь, которая нас сильно отвернула от этого сервиса. Это ошибки анализа Common Table Expression (CTE) и разных динамических узлов вроде InitPlan/SubPlan.
Если верить этой картинке, то у нас суммарное время выполнения каждого отдельного узла больше, чем общее время выполнения всего запроса. Все просто — из узла CTE Scan не вычли время генерации этой CTE. Поэтому мы уже не знаем правильного ответа, сколько же заняло само сканирование CTE.
Тут мы поняли, что пора писать свое — ура-ура! Каждый разработчик говорит: «Сейчас мы свое напишем, супер просто будет!»
Взяли типичный для web-сервисов стек: ядро на Node.js + Express, натянули Bootstrap и для диаграммок красивых — D3.js. И наши ожидания вполне оправдались — первый прототип мы получили за 2 недели:
- собственный парсер плана
То есть теперь мы можем вообще любой план разбирать из тех, которые генерирует PostgreSQL. - корректный анализ динамических узлов — CTE Scan, InitPlan, SubPlan
- анализ распределения buffers — где страницы данных из памяти читаются, где из локального кэша, где с диска
- получили наглядность
Чтобы не в логе все вот это вот «копать», а видеть «самое слабое звено» сразу на картинке.
Мы получили примерно такую картинку — сразу с подсветкой синтаксиса. Но обычно наши разработчики работают уже не с полным представлением плана, а с тем, что покороче. Ведь все циферки мы уже распарсили и в сторону их налево-направо закинули, а посередине оставили только первую строчку, что это за узел: CTE Scan, генерация CTE или Seq Scan по какой-то табличке.
Вот это представление сокращенное мы называем шаблоном плана.
Что еще было бы удобно? Было бы удобно видеть, какая доля на какой узел от общего времени у нас распределяется — и просто «приклеили» сбоку pie chart.
Наводим на узел и видим — у нас, оказывается Seq Scan от всего времени занял меньше четверти, а остальные 3/4 у нас занял CTE Scan. Ужас! Это маленькое замечание по поводу «скорострельности» CTE Scan, если вы их активно используете в своих запросах. Они не очень быстрые — они проигрывают даже обычному табличному сканированию. [статья] [статья]
Но обычно такие диаграммы бывают поинтереснее, посложнее, когда мы сразу наводим на сегмент, и видим, например, что больше половины всего времени какой-то Seq Scan «съел». Да еще внутри там какой-то Filter был, куча записей отброшено по нему… Можно вот эту картинку прямо кидать разработчику и говорить: «Вася, у тебя тут вообще все плохо! Разберись, посмотри — что-то не так!»
Естественно, без «граблей» не обошлось.
Первое на что «наступили» — это проблема округления. Время узла каждого отдельного в плане указывается с точностью до 1мкс. И когда количество циклов узла превышает, например, 1000 — после выполнения PostgreSQL поделил «с точностью до», то при обратном расчете мы получаем общее время «где-то между 0.95мс и 1.05мс». Когда счет идет на микросекунды — еще ничего, а вот когда уже на [милли]секунды — приходится при «развязывании» ресурсов по узлам плана «кто у кого сколько потребил» эту информацию учитывать.
Второй момент, более сложный, это распределение ресурсов (тех самых buffers) по динамическим узлам. Это стоило нам к первым 2 неделям на прототип еще плюсом недели 4.
Проблему такую получить достаточно просто — делаем CTE и в ней что-то якобы читаем. На самом деле, PostgreSQL «умный» и ничего прямо там читать не будет. Потом мы из нее берем первую запись, а к ней — сто первую из той же самой CTE.
Смотрим план и понимаем — странно, у нас 3 buffers (страницы данных) были «потреблены» в Seq Scan, еще 1 в CTE Scan, и еще 2 во втором CTE Scan. То есть если все просто просуммировать, у нас получится 6, но из таблички-то мы прочитали всего 3! CTE Scan ведь ничего ниоткуда не читает, а работает прямо с памятью процесса. То есть здесь явно что-то не так!
На самом-то деле получается, что здесь все те 3 страницы данных, которые были запрошены у Seq Scan, сначала 1 попросил 1-й CTE Scan, а потом 2-й, и ему дочитали еще 2. То есть всего было прочитано 3 страницы данных, а не 6.
И эта картинка привела нас к пониманию, что выполнение плана — это уже не дерево, а просто какой-то ациклический граф. И у нас получилась вот такая примерно диаграмма, чтобы мы понимали «что-откуда вообще пришло». То есть вот здесь мы создали CTE из pg_class, и два раза ее попросили, и практически все время у нас ушло по ветке, когда мы просили ее 2й раз. Понятно, что прочитать 101-ю запись — это намного дороже, чем просто 1-ю из таблички.
Мы на какое-то время выдохнули. Сказали: «Теперь, Нео, ты знаешь кунг-фу! Теперь наш опыт у тебя прямо на экране. Теперь ты можешь им пользоваться.» [статья]
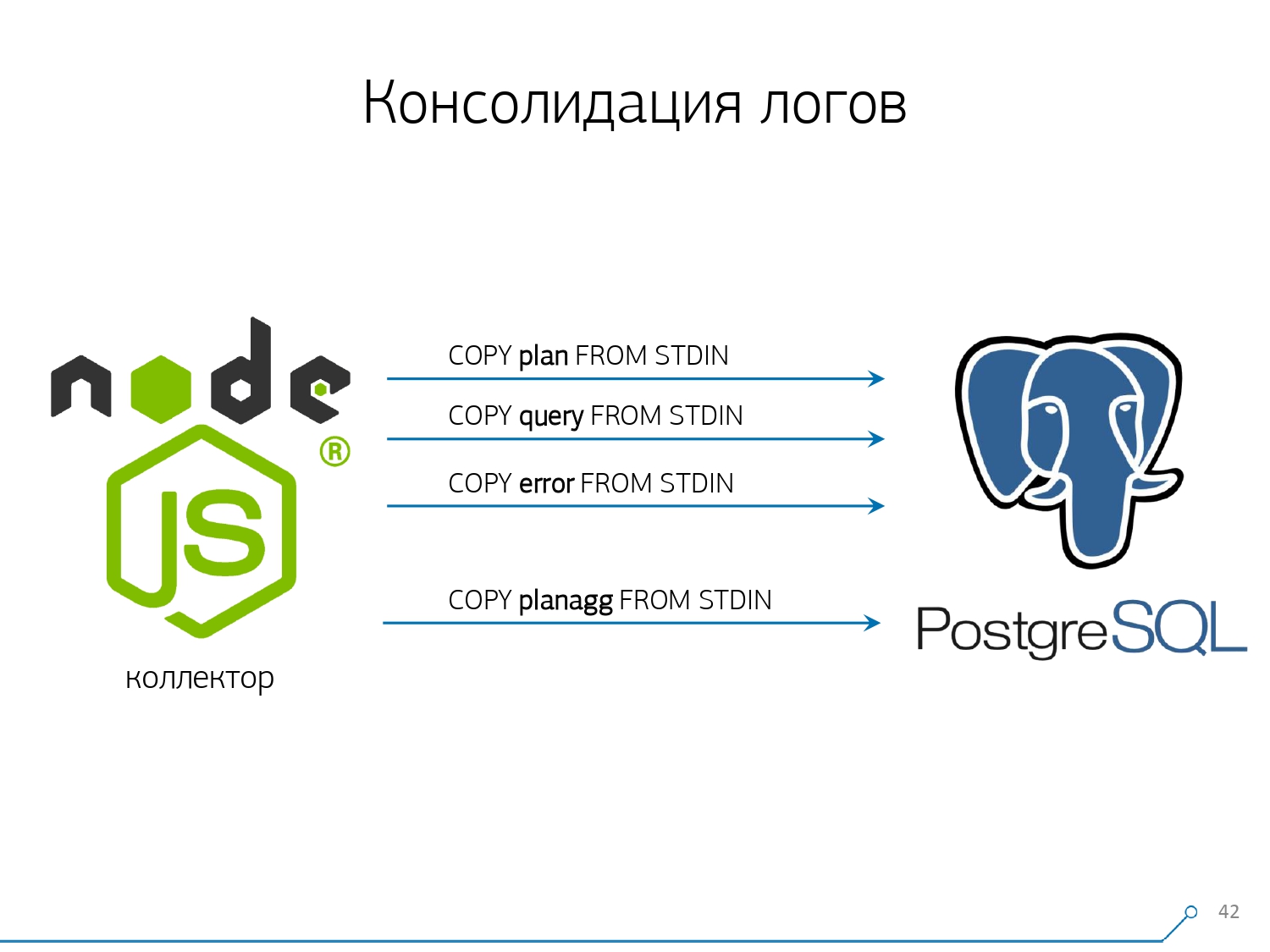
Консолидация логов
Наши 1000 разработчиков облегченно вздохнули. Но мы-то понимали, что у нас только «боевых» серверов сотни, и весь этот «копипаст» со стороны разработчиков совсем не удобен. Мы поняли, что надо это самим собирать.
Вообще, есть штатный модуль, который умеет собирать статистику, правда, его так же нужно в конфиге активировать — это модуль pg_stat_statements. Но он нас не устроил.
Во-первых, одним и тем же запросам по разным схемам в рамках одной базы он присваивает разные QueryId. То есть если сначала сделать
SET search_path = '01'; SELECT * FROM user LIMIT 1;, а потом SET search_path = '02'; и такой же запрос, то в статистике этого модуля будут разные записи, и я не смогу собрать общую статистику именно в разрезе этого профиля запроса, без учета схем.Второй момент, который нам помешал его использовать — отсутствие планов. То есть плана — нет, есть только сам запрос. Мы видим что тормозило, но не понимаем, почему. И тут мы возвращаемся к проблеме быстроизменяемого датасета.
И последний момент — отсутствие «фактов». То есть нельзя адресоваться к конкретному экземпляру выполнения запроса — его нет, есть только агрегированная статистика. С этим хоть и можно работать, просто очень сложно.
Поэтому мы решили с «копипастой» бороться и начали писать коллектор.
Коллектор подключается по SSH, «натягивает» с помощью сертификата защищенное соединение до сервера с базой и
tail -F «цепляется» к нему на лог-файл. Таким образом, в этой сессии мы получаем полное «зеркало» всего лог-файла, который генерирует сервер. Нагрузка на сам сервер при этом минимальна, ведь мы там ничего не парсим, просто зеркалируем трафик.Поскольку мы уже начали писать интерфейс на Node.js, то на нем же и коллектор продолжили писать. И эта технология себя оправдала, потому что для работы со слабоформатированными текстовыми данными, которыми и является лог, использовать JavaScript очень удобно. А сама инфраструктура Node.js в качестве backend-платформы позволяет легко и удобно работать с сетевыми соединениями, да и вообще с какими-то потоками данных.
Соответственно, мы «натягиваем» два соединения: первое, чтобы «слушать» сам лог и его к себе забирать, а второе — чтобы периодически у базы спрашивать. «А вот в логе прилетело, что заблокирована табличка с oid 123», но разработчику это не говорит ни о чем, и неплохо бы спросить у базы «А что же все-таки такое OID = 123?» И так мы периодически спрашиваем у базы то, что у себя еще не знаем.
«Лишь одного ты не учел, есть вид слоноподобных пчел!..» Мы начинали разрабатывать эту систему, когда хотели отмониторить 10 серверов. Наиболее критичных в нашем понимании, на которых возникали какие-то проблемы, с которыми было сложно разбираться. Но в течение первого же квартала мы получили на мониторинг сотню — потому что система «зашла», все захотели, всем удобно.
Все это надо складывать, данных поток большой, активный. Собственно, что мониторим, с чем умеем разбираться — то и используем. Используем в качестве хранилища данных тоже PostgreSQL. А ничего быстрее, чтобы «лить» в него данные, чем оператор
COPY пока нету.Но просто «лить» данные — не совсем наша технология. Потому что если у вас на сотне серверов происходит примерно 50k запросов в секунду, то это вам генерирует 100-150GB логов в день. Поэтому нам пришлось базу аккуратно «пилить».
Во-первых, мы сделали секционирование по дням, потому что, по большому счету, никого не интересует корреляция между сутками. Какая разница, что у тебя было вчера, если сегодня ночью ты выкатил новую версию приложения — и уже какая-то новая статистика.
Во-вторых, мы научились (вынуждены были) очень-очень быстро писать с помощью
COPY. То есть не просто COPY, потому что он быстрее, чем INSERT, а еще быстрее.Третий момент — пришлось отказаться от триггеров, соответственно, и от Foreign Keys. То есть у нас нет совсем ссылочной целостности. Потому что если у вас есть таблица, на которой есть пара FK, и вы говорите в структуре БД, что «вот запись из лога ссылается по FK, например, на группу записей», то когда вы ее вставляете, PostgreSQL ничего не остается, кроме как взять и честно выполнить
SELECT 1 FROM master_fk1_table WHERE ... с тем идентификатором, который вы пытаетесь вставить — просто для того, чтобы проверить, что эта запись там присутствует, что вы не «обламываете» своей вставкой этот Foreign Key.Мы получаем вместо одной записи в целевую таблицу и ее индексы, еще плюсом чтения из всех таблиц, на которые она ссылается. А нам это совсем не надо — наша задача записать как можно больше и как можно быстрее с наименьшей нагрузкой. Так что FK — долой!
Следующий момент — агрегация и хэширование. Изначально они были у нас реализованы в БД — ведь удобно же сразу, когда прилетает запись, сделать в какой-то табличке «плюс один» прямо в триггере. Хорошо, удобно, но плохо тем же — вставляете одну запись, а вынуждены прочитать и записать еще что-то из другой таблицы. Причем, мало того, что прочитать и записать — еще и сделать это каждый раз.
А теперь представьте, что у вас есть табличка, в которой вы просто считаете количество запросов, прошедших по конкретному хосту:
+1, +1, +1, ..., +1. А вам это, в принципе, не нужно — это все можно просуммировать в памяти на коллекторе и отправить в базу за один раз +10.Да, у вас в случае каких-то неполадок может «развалиться» логическая целостность, но это практически нереальный кейс — потому что у вас нормальный сервер, на нем батарейка в контроллере, у вас журнал транзакций, журнал на файловой системе… В общем, не стоит оно того. Не стоит та потеря производительности, которую вы получаете за счет работы триггеров/FK, тех расходов, которые вы несете при этом.
То же самое и с хэшированием. Летит к вам некий запрос, вы от него вычисляете в БД некий идентификатор, пишете в базу и всем потом говорите его. Все хорошо, пока в момент записи к вам не придет второй желающий записать его же — и у вас возникнет блокировка, а это уже плохо. Поэтому если вы можете генерацию каких-то ID вынести на клиента (относительно базы), лучше это сделать.
Нам просто идеально подошло использовать MD5 от текста — запроса, плана, шаблона,… Мы вычисляем его на стороне коллектора, и «льем» в базу уже готовый ID. Длина MD5 и посуточное секционирование позволяют нам не беспокоиться о возможных коллизиях.
Но чтобы это все записать быстро, нам понадобилось модифицировать саму процедуру записи.
Как обычно пишут данные? У нас есть какой-то датасет, мы его раскладываем на несколько таблиц, а потом COPY — сначала в первую, потом во вторую, в третью… Неудобно, потому что мы вроде один поток данных пишем за три шага последовательно. Неприятно. Можно ли сделать быстрее? Можно!
Для этого достаточно всего лишь разложить эти потоки параллельно друг с другом. Получается, что у нас летят в отдельных потоках ошибки, запросы, шаблоны, блокировки,… — и мы пишем это все параллельно. Для этого достаточно держать постоянно открытым COPY-канал на каждую отдельную целевую таблицу.
То есть у коллектора всегда есть стрим, в который я могу записать нужные мне данные. Но чтобы база эти данные увидела, а кто-нибудь не висел в блокировки, ожидая, пока эти данные запишутся, COPY надо прерывать с определенной периодичностью. Для нас наиболее эффективным получился период порядка 100мс — закрываем и сразу снова открываем на ту же таблицу. А если у нас одного потока не хватает при каких-то пиках, то мы делаем пулинг до определенного предела.
Дополнительно мы выяснили, что для такого профиля нагрузки любая агрегация, когда записи собираются в пакеты — это зло. Классическое зло — это
INSERT ... VALUES и дальше 1000 записей. Потому что в этот момент у вас возникает пик записи по носителю, и все остальные, пытающиеся что-то записать на диск, будут ждать.Чтобы избавиться от таких аномалий, просто не агрегируйте ничего, не буферизируйте вообще. И если буферизация на диск все-таки возникает (к счастью, Stream API в Node.js позволяет это узнать) — отложите это соединение. Вот когда вам придет событие, что оно снова свободно — пишите в него из накопившейся очереди. А пока оно занято — берите из пула следующее, свободное, и пишите в него.
До внедрения такого подхода к записи данных у нас было примерно 4K write ops, а таким способом сократили нагрузку в 4 раза. Сейчас выросли еще в 6 раз за счет новых наблюдаемых баз — до 100MB/s. И теперь мы храним логи за последние 3 месяца в объеме около 10-15TB, надеясь, что уж за три-то месяца любую проблему любой разработчик способен решить.
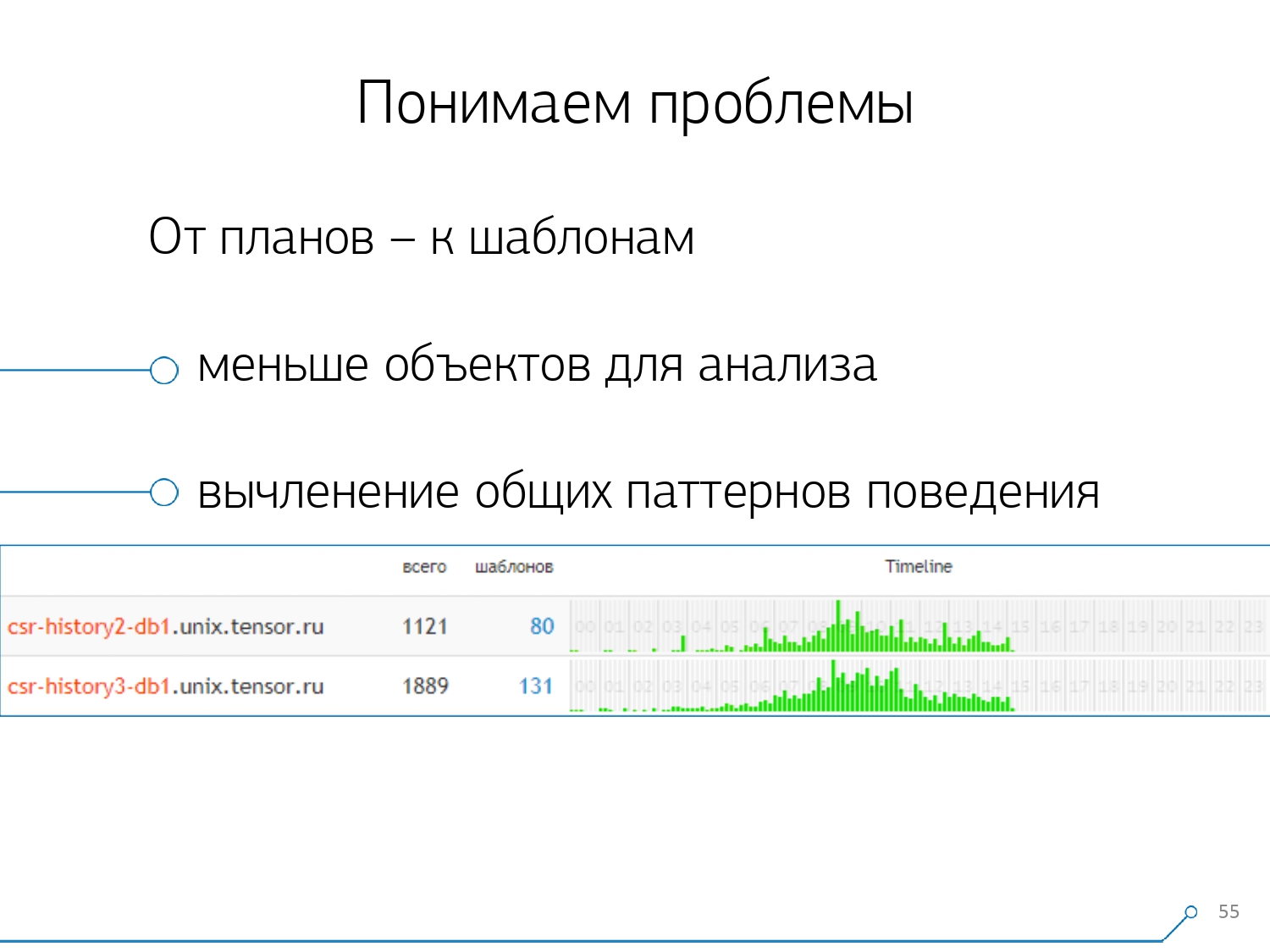
Понимаем проблемы
Но просто собрать все эти данные — хорошо, полезно, уместно, но мало — их надо понять. Потому что это миллионы различных планов за сутки.
Но миллионы — это неуправляемо, надо сначала сделать «поменьше». И, в первую очередь, надо решить, как это «поменьше» вы будете организовывать.
Мы выделили для себя три ключевые момента:
- кто этот запрос прислал
То есть из какого приложения он «прилетел»: web-интерфейс, backend, платежная система или что-то еще. - где это произошло
На каком конкретном сервере. Потому что если у вас под одним приложением стоит несколько серверов, и внезапно один «затупил» (потому что «диск сгнил», «память протекла», еще какая-то беда), то надо конкретно адресоваться до сервера. - как именно проявлялась проблема в том или ином плане
Чтобы понять «кто» прислал нам запрос, мы пользуемся штатным средством — установкой переменной сессии:
SET application_name = '{bl-host}:{bl-method}'; — посыдаем имя хоста бизнес-логики, с которого идет запрос, и имя метода или приложения, которое его инициировало.После того, как мы передали «хозяина» запроса, его надо вывести в лог — для этого конфигурируем переменную
log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Кому интересно, может посмотреть в мануале, что это все значит. Получается, что мы в логе видим:- время
- идентификаторы процесса и транзакции
- имя базы
- IP того, кто прислал этот запрос
- и имя метода
Дальше мы поняли, что не очень интересно смотреть корреляцию по одному запросу между разными серверами. Нечасто получается ситуация, когда у вас одно приложение одинаково «лажает» и тут, и там. Но даже если одинаково — посмотрите на любой из этих серверов.
Так вот, разреза «один сервер — один день» нам оказалось достаточно для любого анализа.
Первый аналитический разрез — это тот самый «шаблон» — сокращенная форма представления плана, очищенная от всех численных показателей. Второй разрез — приложение или метод, а третий — это конкретный узел плана, который вызвал у нас проблемы.
Когда мы перешли от конкретных экземпляров к шаблонам, получили сразу два преимущества:
- кратное уменьшение количества объектов для анализа
Приходится разбирать проблему уже не по тысячам запросов или планов, а по десяткам шаблонов. - таймлайн
То есть, обобщив «факты» в рамках какого-то разреза, можно отобразить их появление в течение дня. И тут вы можете понять, что если у вас какой-то шаблон происходит, например, раз в час, а должен бы — раз в сутки, стоит задуматься, что пошло не так — кем и зачем он вызван, может, его и быть тут не должно. Это еще один нечисловой, чисто визуальный, способ анализа.
Остальные способы базируются на тех показателях, которые мы извлекаем из плана: сколько раз происходил такой шаблон, суммарное и среднее время, сколько данных вычитано с диска, а сколько из памяти…
Потому что вы, например, приходите на страницу аналитики по хосту, смотрите — что-то слишком много по диску читать начало. Диск на сервере не справляется — а кто с него читает?
И вы можете отсортировать по любому столбцу и решить, с чем вы будете прямо сейчас разбираться — с нагрузкой на процессор или на диск, или с общим количеством запросов… Отсортировали, посмотрели «топовые», починили — выкатили новую версию приложения.
[видеолекция]
И сразу вы можете увидеть разные приложения, которые ходят с одним и тем же шаблоном от запроса типа
SELECT * FROM users WHERE login = 'Vasya'. Фронтенд, бэкенд, процессинг… И вы задумываетесь, зачем бы процессингу читать пользователя, если он с ним не взаимодействует.Обратный способ — от приложения сразу увидеть, что оно делает. Например, фронтенд — это, это, вот это, а еще вот это раз в час (как раз таймлайн помогает). И сразу возникает вопрос — вроде бы не дело фронтенда делать что-то раз в час…
Через какое-то время мы поняли, что нам не хватает агрегированной статистики в разрезе узлов плана. Мы вычленили из планов только те узлы, которые что-то делают с данными самих таблиц (читают/пишут их по индексу или нет). По сути, относительно предыдущей картинки добавляется всего один аспект — сколько записей этот узел нам принес, а сколько отбросил (Rows Removed by Filter).
У вас нет подходящего индекса на табличке, вы делаете к ней запрос, он пролетает мимо индекса, падает в Seq Scan… все записи, кроме одной вы отфильтровали. А зачем вам за сутки 100M отфильтрованных записей, не лучше ли индекс накатить?
Разобрав все планы по узлам, мы поняли, что есть некоторые типовые структуры в планах, которые с очень большой вероятностью выглядят подозрительно. И неплохо бы разработчику подсказать: «Друг, вот тут ты сначала читаешь по индексу, потом сортируешь, а потом отрезаешь» — как правило, там одна запись.
Все кто писал запросы, с таким паттерном, наверняка, сталкивались: «Дай мне последний заказ по Васе, его дату» И если у вас индекса по дате нету, или в использовавшемся индексе нет даты, то вот ровно на такие «грабли» и наступите.
Но мы же знаем, что это «грабли» — так почему бы сразу не подсказать разработчику, что ему стоит сделать. Соответственно, открывая сейчас план, наш разработчик сразу видит красивую картинку с подсказками, где ему сразу говорят: «У тебя проблемы тут и тут, а решаются они так и так.»
В результате, объем того опыта, который был необходим для решения проблем в начале и сейчас, упал в разы. Вот такой инструмент у нас получился.




chemtech
Спасибо. Планируете ли публиковать в opensource ваш explain, чтобы можно было его локально развернуть?
Kilor Автор
Думаем об этом.
А пока выставляем «по кусочкам» в качестве публичных сервисов:
habr.com/ru/company/tensor/blog/477624
explain.tensor.ru