
Популярный аргумент к ставшей вирусной публикации про коронавирус — да как же можно по трём случаям какую-то статистику выводить? Нельзя делать выводы по таким маленьким выборкам! Эту историю про размеры выборок все, кто учился социальным наукам, впитали с молоком альма матери. И это правильно в тех ситуациях, с которыми мы обычно имеем дело — с выборочными статистиками.
К случаю с тремя умершими эти статистики имеют весьма опосредованное отношение. В те годы, когда я ещё преподавал матметоды для психологов в универе, я всегда пытался остановиться на этом месте — то, о чём весь этот курс, не имеет отношения к фактическим данным. Только к задаче, когда нам надо по случайной выборке сделать какой-то вывод о генеральной совокупности.
И вот перед нами число 3. Три умерших, не вектор какой-нибудь, не таблица и не выборка. Это факт. Три умерших попали к нам совершенно не случайно. Они умерли.
Итак, рассмотрим один из самых простых методов определения количества заболевших — по коэффициенту летальности и количеству смертей. Допустим, что нам известна летальность и она равна 1%. В этой ситуации логичным и правильным будет считать, что количество выздоровевших будет равно 297. Но какова же надёжность этого суждения? Можем ли мы просто отмахнуться от того, что у нас есть трое умерших, заявив, что три — не статистика?

На этот вопрос нам ответит отрицательное биномиальное распределение и пророк его — Википедия. Там много греческих буковок, если вы их, как и я, боитесь, то я вам расскажу, что получается. Это распределение как раз отвечает на вопрос о том, сколько раз надо кинуть кубик, чтобы пять раз выпала шестёрка. Я пользуюсь для расчётов языком программирования R, в котором есть готовая функция, позволяющая оценить доверительный интервал.
Здесь p — это 2.5% снизу и 2.5% сверху, между которыми и находится искомый диапазон.
Результат — доверительный интервал от 60 до 717. Не так уж и плохо! Вполне вероятно, что трое умерших означают совсем даже не 297 выздоровевших, а всего шестьдесят! Но может быть и за семьсот. :-(
Для совсем подозрительных, которые не верят в отрицательное биномиальное распределение, могу предложить численное моделирование. Вообще, если не знаешь, как посчитать по формулам и распределениям — моделируй! В любой непонятной ситуации моделируй, Монте Карло ждёт тебя.
Напишем функцию random_infected, которое моделирует ситуацию болезней и смертей.
Эта функция делает следующее — бросает «n-гранный» кубик (используя равномерное распределение). Если выпала единичка, то увеличивает число dead и число all на единицу. А если не выпала — то только число all. Каждый бросок этого кубика — это заболевший человек, который может либо умереть, либо выздороветь. Как только у нас набирается заданное параметром deaths количество умерших, мы останавливаемся и сообщаем, сколько раз бросали кубик (число all). Вероятность выпадения единички на нашем воображаемом кубике — это и есть летальность, в нашем случае параметр fatality_rate.
А теперь посчитаем это число 100 тысяч раз. У меня ноутбук старенький, так что неохота ждать, пока посчитается миллион.
После этого можно посчитать среднее арифметическое полученных чисел. У меня получилось 301.2 — очень похоже на ожидаемое число 300. Вот так выглядит распределение количеств бросаний нашего кубика смерти:

Вот оно — отрицательное биномиальное распределение, прошу любить и жаловать. Можно относительно легко по таким данным дать примерные ответы на вопросы — какова вероятность, что общее количество заболевших меньше пятидесяти (1.2%) или больше 1000 (0.3%).
Разумеется, это просто оценки. Они основаны на данных, которые могут быть неверны. Мы не знаем об истинной летальности коронавируса. Но чем меньше эта самая летальность, тем больше случаев заболеваний приходится на одного умершего и тем больше оценки масштабов пандемии.
Напомню, что это кубик мы бросаем мгновенно. К модели расчёта по смертности, которая использовалась в нашумевшей статье Томаса Пуэйо у меня есть небольшая претензия. Там мы предполагаем, исходя из 3 умерших в день X, летальности в 1% и знания о том, что среднее время между заражением и смертью составляет 17 дней, что в день X-17 заразилось 300 человек. Однако такой расчёт справедлив только в случае, если количество заболевающих каждый день одинаковое. Так как 17 дней — это не строгое число, у него тоже есть доверительные интервалы и ошибки. Если у нас бурный рост количества заболевших, то среди умерших в день X мы имеем некоторое количество заразившихся не 17 дней назад, а 16 или 15 дней, а может и 10 дней назад. Возможно, их даже больше, чем тех, кто заразился 17 дней назад. Таким образом, в ситуации быстрого роста количества заболевших такой обратный расчёт может приводить к завышенным оценкам распространённости заболевания. В общем, всё сложно.
P.S. Спасибо Григорию Демину за подсказку про тип распределения.
К случаю с тремя умершими эти статистики имеют весьма опосредованное отношение. В те годы, когда я ещё преподавал матметоды для психологов в универе, я всегда пытался остановиться на этом месте — то, о чём весь этот курс, не имеет отношения к фактическим данным. Только к задаче, когда нам надо по случайной выборке сделать какой-то вывод о генеральной совокупности.
И вот перед нами число 3. Три умерших, не вектор какой-нибудь, не таблица и не выборка. Это факт. Три умерших попали к нам совершенно не случайно. Они умерли.
Итак, рассмотрим один из самых простых методов определения количества заболевших — по коэффициенту летальности и количеству смертей. Допустим, что нам известна летальность и она равна 1%. В этой ситуации логичным и правильным будет считать, что количество выздоровевших будет равно 297. Но какова же надёжность этого суждения? Можем ли мы просто отмахнуться от того, что у нас есть трое умерших, заявив, что три — не статистика?
На этот вопрос нам ответит отрицательное биномиальное распределение и пророк его — Википедия. Там много греческих буковок, если вы их, как и я, боитесь, то я вам расскажу, что получается. Это распределение как раз отвечает на вопрос о том, сколько раз надо кинуть кубик, чтобы пять раз выпала шестёрка. Я пользуюсь для расчётов языком программирования R, в котором есть готовая функция, позволяющая оценить доверительный интервал.
qnbinom(p=c(.025,.975),size=3, prob=0.01)Здесь p — это 2.5% снизу и 2.5% сверху, между которыми и находится искомый диапазон.
Результат — доверительный интервал от 60 до 717. Не так уж и плохо! Вполне вероятно, что трое умерших означают совсем даже не 297 выздоровевших, а всего шестьдесят! Но может быть и за семьсот. :-(
Для совсем подозрительных, которые не верят в отрицательное биномиальное распределение, могу предложить численное моделирование. Вообще, если не знаешь, как посчитать по формулам и распределениям — моделируй! В любой непонятной ситуации моделируй, Монте Карло ждёт тебя.
Напишем функцию random_infected, которое моделирует ситуацию болезней и смертей.
random_infected <- function(deaths, fatality_rate)
{
dead = 0
all = 1
while (dead < deaths) {
if (runif(1) < fatality_rate) {
all = all + 1
dead = dead + 1
} else
all = all + 1
}
return(all)
}Эта функция делает следующее — бросает «n-гранный» кубик (используя равномерное распределение). Если выпала единичка, то увеличивает число dead и число all на единицу. А если не выпала — то только число all. Каждый бросок этого кубика — это заболевший человек, который может либо умереть, либо выздороветь. Как только у нас набирается заданное параметром deaths количество умерших, мы останавливаемся и сообщаем, сколько раз бросали кубик (число all). Вероятность выпадения единички на нашем воображаемом кубике — это и есть летальность, в нашем случае параметр fatality_rate.
infected_sizes<-replicate(100000,random_infected(deaths=3,fatality_rate=0.01))А теперь посчитаем это число 100 тысяч раз. У меня ноутбук старенький, так что неохота ждать, пока посчитается миллион.
После этого можно посчитать среднее арифметическое полученных чисел. У меня получилось 301.2 — очень похоже на ожидаемое число 300. Вот так выглядит распределение количеств бросаний нашего кубика смерти:
library(ggplot2)
theme_set(theme_classic())
g <- ggplot(data.frame(infected_sizes=infected_sizes), aes(infected_sizes))
g + geom_density(alpha=0.8,fill="plum")
Вот оно — отрицательное биномиальное распределение, прошу любить и жаловать. Можно относительно легко по таким данным дать примерные ответы на вопросы — какова вероятность, что общее количество заболевших меньше пятидесяти (1.2%) или больше 1000 (0.3%).
Разумеется, это просто оценки. Они основаны на данных, которые могут быть неверны. Мы не знаем об истинной летальности коронавируса. Но чем меньше эта самая летальность, тем больше случаев заболеваний приходится на одного умершего и тем больше оценки масштабов пандемии.
Напомню, что это кубик мы бросаем мгновенно. К модели расчёта по смертности, которая использовалась в нашумевшей статье Томаса Пуэйо у меня есть небольшая претензия. Там мы предполагаем, исходя из 3 умерших в день X, летальности в 1% и знания о том, что среднее время между заражением и смертью составляет 17 дней, что в день X-17 заразилось 300 человек. Однако такой расчёт справедлив только в случае, если количество заболевающих каждый день одинаковое. Так как 17 дней — это не строгое число, у него тоже есть доверительные интервалы и ошибки. Если у нас бурный рост количества заболевших, то среди умерших в день X мы имеем некоторое количество заразившихся не 17 дней назад, а 16 или 15 дней, а может и 10 дней назад. Возможно, их даже больше, чем тех, кто заразился 17 дней назад. Таким образом, в ситуации быстрого роста количества заболевших такой обратный расчёт может приводить к завышенным оценкам распространённости заболевания. В общем, всё сложно.
P.S. Спасибо Григорию Демину за подсказку про тип распределения.











volokhonsky Автор
Ну вот, первый в жизни пост на хабре и кто-то ставит минусы. Говорят, не соответствует тематике хабра…
Gorthauer87
Кажется у людей нервы сдают
Nicks_TechSupport
Не могу поставить плюс, мне кто-то карму заминусил((
volokhonsky Автор
И вот тебе её снова заминусили, бедолага. :-)
Nicks_TechSupport
И не говори, Хабр в последнее время стал похож на набег школьников...
vvzvlad
Некоторых людей жизнь ничему не учит.
Nicks_TechSupport
Ок, раз вы все такие просвещённые, может расскажете за что люди просто жмакают минус, зачастую никак не аргументируя?
khim
Минус жмакают не «за что», а «для чего». Чтобы не видеть больше «дурацких постов».
Конечно чтобы постов реально стало меньше нужно, чтобы это сделало 11 человек… да и понятие «дурацкости» у всех разное. Так что работает это не всегда правильно, но… основная идея в этом.
Собственно об этом написано прямо в документации: Карма — это ключевой инструмент внутрисайтового механизма коллективной модерации.
Это не оценка вашей личности. И не почётная грамота. А всего лишь оценка ваших статей и комментариев.
Вот я просмотрел ваши комментарии (статей пока нет) и вижу, что есть несколько интересных замечаний и куча «информационного мусора»… а его на Хабре не любят, так как и без того им весь интернет засран.
Nicks_TechSupport
Спасибо за аргументированный ответ.
Первый адекватный за сегодня.
А статей нет, потому как особе некогда их писать, либо к к моменту написания она уже становится неактуальной к публикации.
Nicks_TechSupport
Спасибо за аргументированный ответ.
Первый адекватный за сегодня.
А статей нет, потому как особе некогда их писать, либо к к моменту написания она уже становится неактуальной к публикации.
volokhonsky Автор
Вот скажи мне, зачем ты разместил второй раз комментарий, который заминусили? Ты может не понял, за что? За утверждение «первый адекватный за сегодня». И за неспособность статьи писать.
netricks
Соответствует.
Практическое применение отрицательного биномиального распределения и расчет доверительных интервалов в контексте стоящей на повестке дня темы.
Очень даже соответствует.
sa1ntik
Минусы не ставил :)
Но хочу сказать, что ваш анализ(как и попытки анализа у многих других людей) был бы замечательным, если бы он был медицинским.
В вашем случае вы совершаете ровно то же самое упрощение модели, что и авторы других исследований — вы отбрасываете возраст. А потом на основании этих упрощений делаете некие выводы.
В соседних темах я уже писал, что использовать данные о смертности на всем известном круизном лайнере нельзя, если мы только не говорим о возрастной категории 60++ (вернее даже 70+), ведь именно таков средний возраст пассажиров любого круизного лайнера (а все погибшие на нём возраста 70+).
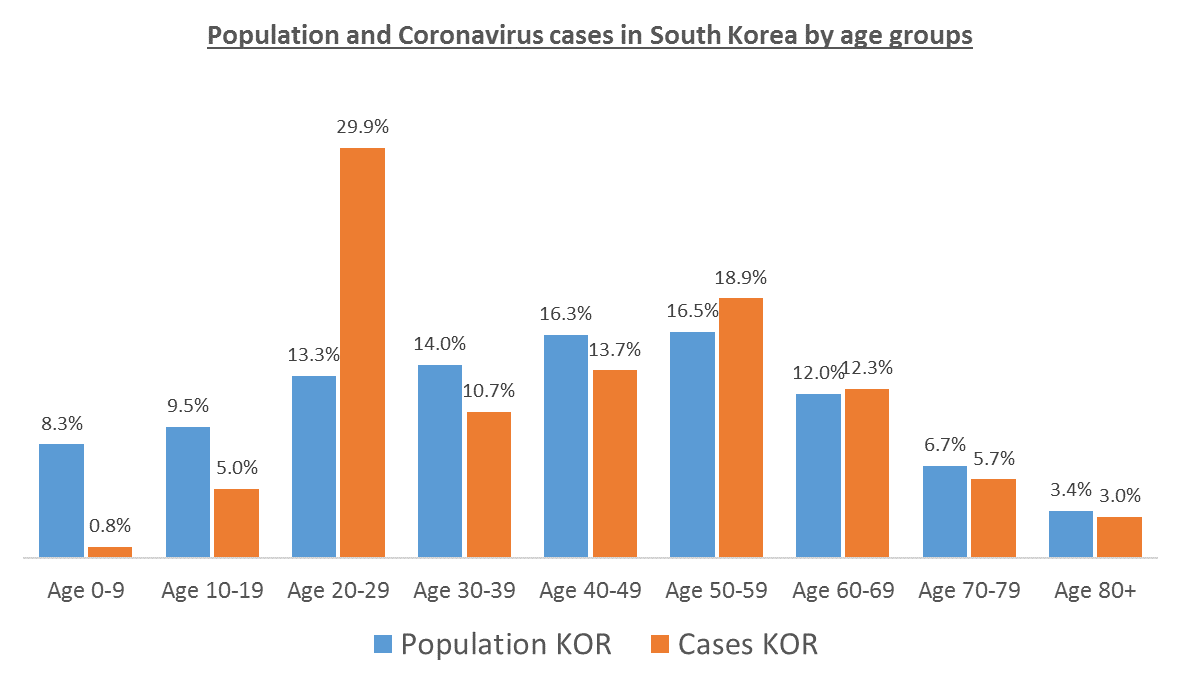
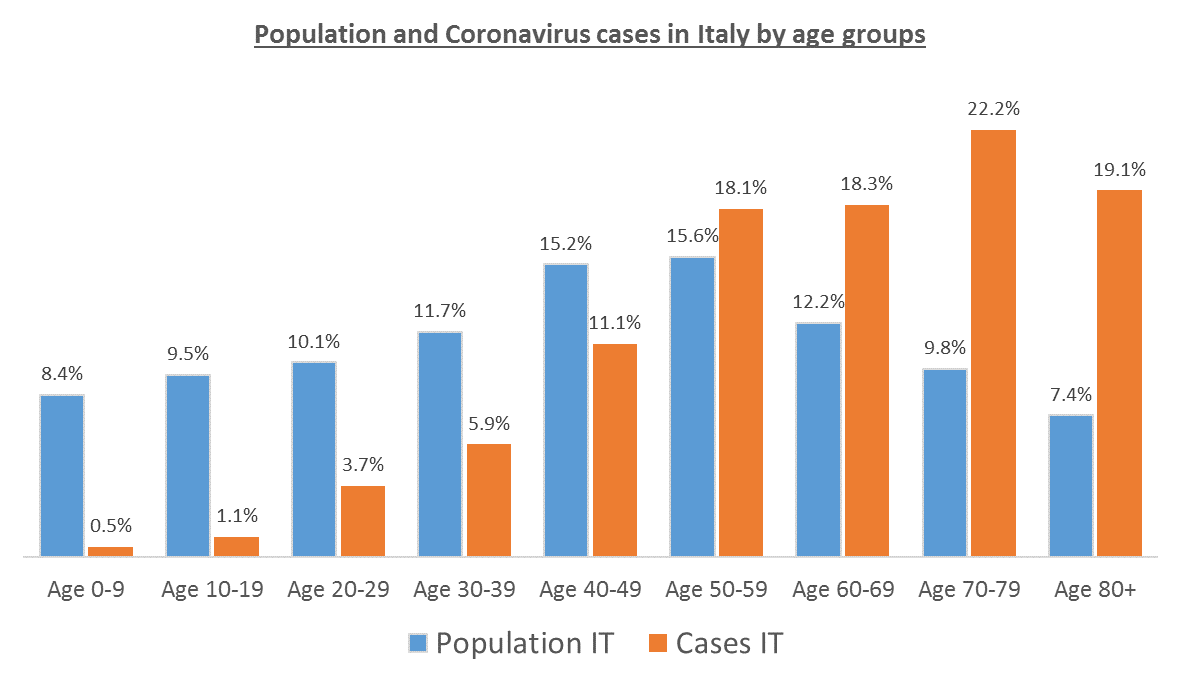
Говоря о статистике смертности в Южной Корее, в большинстве случаев, никак не принимается во внимание тот факт, что большая часть заразившихся в ЮК — люди до 40 лет (преимущественно женщины). А в той же самой Италии — относительно пожилые люди. К слову именно поэтому по уровню смертности Италия обгоняет Китай.
Поэтому возраст заболевших и умерших это именно та часть модели, которую нельзя упрощать. Потому что в данном случае именно она и оказывает наибольшее влияние на протекание болезни в реальном мире.
volokhonsky Автор
А никто вроде бы и не упрощает настолько. Мы не используем для расчётов ни летальность итальянскую, ни даже корейскую, не говоря уже о летальности с круизного лайнера. Потому что представляем себе, что доля недиагностированных заболеваний всегда относительно высока. Так что оценка летальности берётся, как правило, по нижней границе.
Почему же нельзя упрощать-то? Простите, но без упрощения нельзя построить никакую модель. При отсутствии необходимых данных, ориентируемся на максимально ожидаемые. Я бы не стал для России делать скидку на то, что у нас доля пожилых меньше, чем в Италии. Тут, знаете ли, год за два считается. В том смысле, что наши шестидесятилетние по уровню здоровья и прочим параметрам едва ли имеют больше шансов, чем итальянские семидесятилетние. Но может быть и нет… К сожалению, мы это скоро узнаем с некоторой степенью достоверности.
sa1ntik
Нижняя граница по Китайским расчётам — 0.2%; по Корейским — 0% для возрастных групп 0-9, 10-19, 20-29 (если ничего не поменялось, справедливо для данных на конец прошлой недели). Максимальная летальность вируса, по Китайским данным, наблюдается у возрастной группы 80+ и для всех случаев составляет 14,8% (для подтверждённых случаев 21,9%). То есть разница почти на два порядка (или на два с лишним).
Я знаю, что без упрощений нельзя построить никакую модель, вернее её построение потребует увеличения необходимых ресурсов и поэтому не предлагаю учитывать потребление сигарет в Италии и Корее.
А вот упрощать то, что оказывает наибольшее влияние на результат — нельзя. Например, если не ошибаюсь, в Корее на 2213 заболевших возраста 20-29 лет приходится 0 смертей. В то время как в Италии, как я и говорил, пик заболевших пришёлся на возраст 70-79 лет.
Данные о смертности, впрочем, тоже известны.
Поэтому упрощая модель по возрасту вы делаете её абсолютно недостоверной. Со всеми вытекающими из этого проблемами.
P.s. Да, в том числе поэтому в Корее столь низкий процент смертности — там заразились, в основном, молодые. В каком-то плане это именно обычное везение, а не просто во время принятые меры и состояние системы здравоохранения.
volokhonsky Автор
OK, давайте возьмём за разумное допущение, что пока неизвестны дополнительные данные, передача болезни происходит равномерно по всем возрастам? Можно попробовать пересчитать, взвешивая корейские данные на российские демографические пропорции. Попробую ночью посчитать, но там уж я едва ли осилю прикинуть доверительные интервалы — так и не освоил учёт взвешивания при их калькуляции…
sa1ntik
Давайте допустим.
Так а корейские данные на какие возрастные группы? Ведь именно это важно. Упраздняя в статистике о проценте погибших возраст, вы делаете статистику «не статистикой». После этого она будет годна лишь для пресс-релизов. Я с этого и начал: мешать смертности разных возрастных категорий не стоит.
andrew911
Проблема в том, что в Корее проверяли всех подряд, поэтому % зараженных в возрастных группах практически одинаков, в Италии тестируют тяжелых с симптомами, которые преобладают в старшей возрастной группе
sa1ntik
Нет, не всех подряд а тех, кто контактировал с зараженными в первую очередь. Так же как и в Китае
Нет, там так же тестируют тех, кто контактировал с зараженными. Просто более медленно.
И да, симптомы появляются у всех возрастных категорий. А вот осложнения — нет. В одном из прошлых постов меня поправили насчет бессимптомного течения болезни (я допускал, что оно есть). Так вот: на текущий момент болезнь практически не встречается в бессимптомной форме.
andrew911
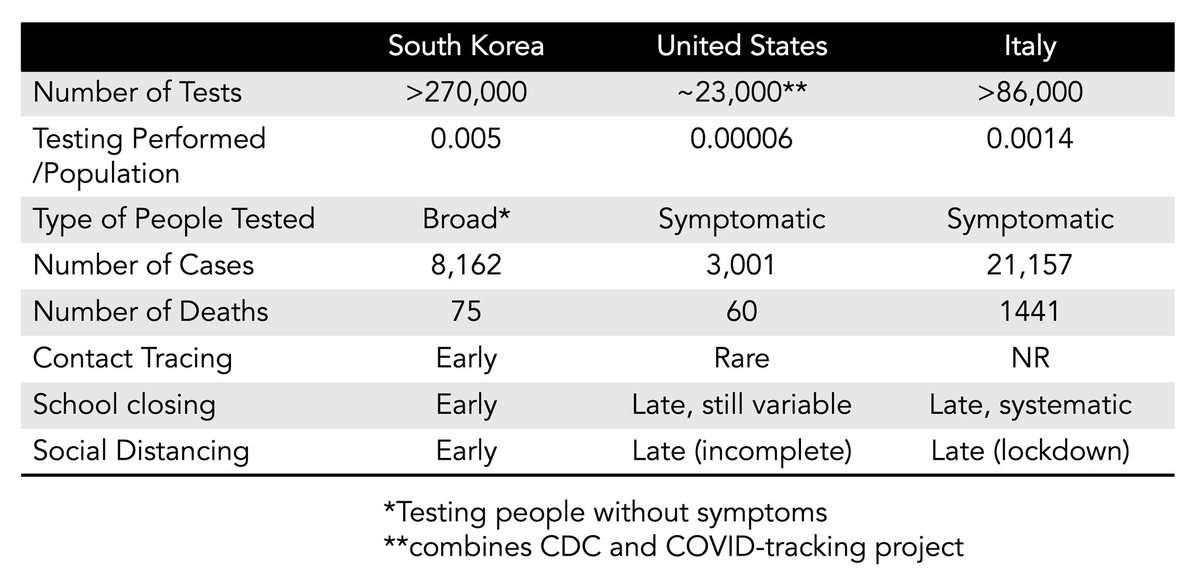
Не совсем так, в Италии на 86т тестов 21т зараженных, можно сделать выводы кого они тестируют.
Ну и про не встречается в бессимптомной хотелось бы видеть источники и что считается за симптомы.
sa1ntik
Можно: больных и тех, кто с ними контактировал, по-моему это очевидно из цифр :)
Так же и в Корее, просто там круг контактов устанавливается лучше в том числе благодаря треккингу сотовых телефонов по вышкам, например.
По данным WHO в Китае полученных на основании данных массового скрининга на вирус (примерно 320 тысяч человек) менее 1% доказанных случаев заражения протекают бессимптомно. Причем из этих 1% у более 75% симптомы развились уже после тестирования.
За симптомы считается проявление любых симптомов ОРВИ, специфичных для COVID 19. То есть это не «пневмония + ИВЛ», если вы об этом.
andrew911
Для Кореи написано, что не только тех кто с симптомами.
По поводу бессимптомности не все так просто.
sa1ntik
И тех, кто с ними контактировал)
Ни одна страна мира сейчас не в состоянии проверять просто так всех подряд. Вернее в состоянии, но это займет больше года. Поэтому проверяют тех, кто в группе риска. А это те, у кого симптомы ОРВИ и те, кто контактировал с подтверждёнными больными.
Да всё очень даже просто:
И
На мой взгляд статья абсолютно очевидна: человек становится заразным до того, как у него могут появится симптомы, но при этом это не означает что симптомы у него не появятся в будущем. Поэтому более 99% переносчиков окажется в группе с симптомами и в это время будет отправлено на диагностику.
Chamie
andrew911
«практически», можно посмотреть другие группы и сравнить с Италией
Chamie
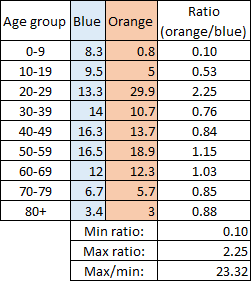
Ну вот я смотрю на другие группы, и в половине из них показатели в 5(!) раз ниже. Это «практически одинаков»?
andrew911
Практически одинаково соотношение между оранжевым и синим столбиком
Chamie
Оно тоже до 25 раз различается.
andrew911
Сравни с Италией группы после 30
Chamie
Может, скажешь, наконец, нормально, что имел в виду? Я, знаешь, не подряжался сидеть и расчёты забивать после каждого твоего комментария.
andrew911
Что заболевшие в Корее более равномерно распределены по возрастным группам, чем в Италии и это, скорее всего, результат более широкого тестирования
Chamie
Это если совершенно игнорировать группу 20-29?
andrew911
Нет правил без исключений, возможно у них больше активность и количество связей, что приводит к большей вероятности.
sa1ntik
В смысле «правил без исключений»?
Одна из девяти возрастных групп (причем не самая многочисленная, Корея — пожилая страна, да и это видно из распределения на графике) даёт треть случаев заболевания. И вы это называете «исключением»? :)
PsyHaSTe
А где вы смотрите за что минусы ставят? Нигде не мог найти ни разу...
Chamie
Давно пробовали? Фичу в конце ноября выпустили.
PsyHaSTe
Я видел новость. Только я за эти месяцы раз 5 облазил весь личный кабинет, и нигде не нашел этой информации. Всё, что есть: вот такая статистика
Не, мож я слепой, но — не нашел. Поэтому был бы рад получить информацию, где это можно найти.
0xd34df00d
Нажмите на сам счётчик под (вашей) публикацией.
PsyHaSTe
Ничего себе! Спасибо, я бы долго искал.
Кто-то поставил минус монадам за «много рекламы». Очень интересно)
0xd34df00d
Смешнее, когда одновременно есть «низкий уровень технического материала», «в статье нет ничего нового» и «ничего не понял после прочтения».