
При сложной обработке больших наборов данных (разные ETL-процессы: импорты, конвертации и синхронизации с внешним источником) часто возникает необходимость временно «запомнить», и сразу быстро обработать что-то объемное.
Типовая задача подобного рода звучит обычно примерно так: «Вот тут бухгалтерия выгрузила из клиент-банка последние поступившие оплаты, надо их быстренько вкачать на сайт и привязать к счетам»
Но когда объем этого «чего-то» начинает измеряться сотнями мегабайт, а сервис при этом должен продолжать работать с базой в режиме 24x7, возникает множество side-эффектов, которые будут портить вам жизнь.
Чтобы справиться с ними в PostgreSQL (да и не только в нем), можно использовать некоторые возможности для оптимизаций, которые позволят обработать все быстрее и с меньшим расходом ресурсов.
Сначала давайте определимся, куда мы можем залить данные, которые мы хотим «отпроцессить».
В принципе, для PostgreSQL временные — это такие же таблицы, как и любые другие. Поэтому неверны суеверия типа «там все хранится только в памяти, а она может кончиться». Но есть и несколько существенных отличий.
Если два подключения попытаются одновременно выполнить
А вот если оба попытаются выполнить
При закрытии подключения все временные таблицы автоматически удаляются, поэтому «вручную» выполнять
Если вы работаете через pgbouncer в transaction mode, то база-то продолжает считать, что это соединение все еще активно, и в нем-то эта временная таблица по-прежнему существует.
Поэтому попытка создать ее повторно, уже из другого подключения к pgbouncer, приведет к ошибке. Но это можно обойти, воспользовавшись
Правда, лучше так все-таки не делать, потому что затем можно «внезапно» обнаружить там, оставшиеся от «предыдущего владельца» данные. Вместо этого гораздо лучше прочитать-таки мануал, и увидеть, что при создании таблицы есть возможность дописать
В силу принадлежности только определенному соединению, временные таблицы не реплицируются. Зато это избавляет от необходимости двойной записи данных в heap + WAL, поэтому INSERT/UPDATE/DELETE в нее существенно быстрее.
Но поскольку временная — это все-таки «почти обычная» таблица, то и на реплике ее создать нельзя тоже. По крайней мере, пока, хотя соответствующий патч уже давно ходит.
Но что делать, например, если у вас есть какой-то громоздкий ETL-процесс, который не удается реализовать в рамках одной транзакции, а у вас таки pgbouncer в transaction mode?..
Или поток данных настолько велик, что недостаточно пропускной способности одного соединения с БД (читай, одного процесса на CPU)?..
Или часть операций идут асинхронно в разных коннектах?..
Тут вариант только один — временно создавать не-временную таблицу. Каламбур, ага. То есть:
А теперь — ложка дегтя. По сути, вся запись в PostgreSQL происходит дважды — сначала в WAL, потом уже в тела таблицы/индексов. Все это сделано для поддержки ACID и корректной видимости данных между
Но нам-то этого не нужно! У нас весь процесс или целиком успешно прошел, или нет. Неважно, сколько в нем будет промежуточных транзакций — нам не интересно «продолжать процесс с середины», особенно когда непонятно, где она была.
Для этого разработчики PostgreSQL еще в версии 9.1 внедрили такую штуку как нежурналируемые (UNLOGGED) таблицы:
Если таки нет, и кейс выше похож на ваш — используйте
Эта конструкция позволяет при создании таблицы задать автоматическое поведение при завершении транзакции.
Про
Поскольку вся инфраструктура хранения метаописания временной таблицы ровно такая же, как и у обычной, то постоянное создание-удаление временных таблиц приводит к сильному «разбуханию» системных таблиц pg_class, pg_attribute, pg_attrdef, pg_depend,…
Теперь представьте, что у вас есть воркер на прямом соединении с БД, который каждую секунду открывает новую транзакцию, создает, наполняет, обрабатывает и удаляет временную таблицу… Мусора в системных таблицах накопится в избытке, а это лишние тормоза при каждой операции.
В общем, не надо так! В этом случае гораздо эффективнее
Я упомянул в начале, что один из типичных use case для временных таблиц — это разного рода импорты — и разработчик устало копипастит список полей целевой таблицы в объявление своей временной…
Но лень — двигатель прогресса! Поэтому создать новую таблицу «по образцу» можно гораздо проще:
Поскольку нагенерить потом в эту таблицу можно весьма много данных, то поиски по ней станут ни разу не быстрыми. Но против этого есть традиционное решение — индексы! И, да, у временной таблицы тоже могут быть индексы.
Поскольку, зачастую, нужные индексы совпадают с индексами целевой таблицы, то можно просто написать
Если вам нужны еще и
Но тут уже надо понимать, что если вы создавали импорт-таблицу сразу с индексами, то заливаться данные будут дольше, чем если сначала все залить, а уже потом накатить индексы — посмотрите в качестве примера, как это делает pg_dump.
В общем, RTFM!
Скажу просто — используйте
Итак, пусть наша вводная выглядит примерно так:
Классическим примером подобной ситуации является база КЛАДР — всего адресов много, но в каждой недельной выгрузке изменений (переименований населенных пунктов, объединений улиц, появлений новых домов) совсем немного даже в масштабе всей страны.
Для простоты допустим, что вам даже реструктурировать данные не нужно — просто привести таблицу в нужный вид, то есть:
Почему именно в таком порядке стоит делать операции? Потому что именно так размер таблицы вырастет минимально (помни про MVCC!).
Нет, конечно можно обойтись всего двумя операциями:
Но при этом, благодаря MVCC, размер таблицы увеличится ровно в два раза! Получить +1M образов записей в таблице из-за обновления 10K — так себе избыточность…
Более опытный разработчик знает, что всю табличку целиком можно достаточно дешево зачистить:
Метод действенный, иногда вполне применим, но есть незадача… Вливать 1M записей мы будем до-о-олго, поэтому оставить таблицу пустой на все это время (как произойдет без оборачивания в единую транзакцию) не можем себе позволить.
А значит:
Че-то нехорошо получается…
Как вариант — залить все в отдельную новую таблицу, а потом просто переименовать на место старой. Пара противных мелочей:
Был WIP-патч от Simon Riggs, который предлагал сделать
Итак, останавливаемся на неблокирующем варианте из трех операций. Почти трех… Как это сделать наиболее эффективно?
В том же самом КЛАДРе все изменившиеся записи необходимо дополнительно прогнать через постобработку — нормализовать, выделить ключевые слова, привести к нужным структурам. Но как узнать — что именно изменялось, не усложняя при этом код синхронизации, в идеале, вообще не трогая его?
Если доступ на запись в момент синхронизации есть только у вашего процесса, то можно воспользоваться триггером, который соберет для нас все изменения:
Теперь мы можем перед началом синхронизации триггеры наложить (или включить через
А потом спокойно из log-таблиц извлекаем все нужные нам изменения и прогоняем по дополнительным обработчикам.
Выше мы рассматривали случаи, когда структуры данных источника и приемника совпадают. Но что делать, если выгрузка из внешней системы имеет формат отличный от структуры хранения у нас в базе?
Возьмем в качестве примера хранение клиентов и счетов по ним, классический вариант «многие-к-одному»:
А вот выгрузка из внешнего источника приходит нам в виде «все в одном»:
Очевидно, что данные по клиентам могут дублироваться в таком варианте, а основной записью является «счет»:
Для модели просто вставим наши тестовые данные, но помним —
Сначала выделим те «разрезы», на которые наши «факты» ссылаются. В нашем случае счета ссылаются на клиентов:
Чтобы счета правильно связать с ID клиентов, нам эти идентификаторы надо сначала узнать или сгенерировать. Добавим под них поля:
Воспользуемся описанным выше способом синхронизации таблиц с небольшой поправкой — не будем ничего обновлять и удалять в целевой таблице, ведь импорт клиентов у нас «append-only»:
Собственно, все — в
Типовая задача подобного рода звучит обычно примерно так: «Вот тут бухгалтерия выгрузила из клиент-банка последние поступившие оплаты, надо их быстренько вкачать на сайт и привязать к счетам»
Но когда объем этого «чего-то» начинает измеряться сотнями мегабайт, а сервис при этом должен продолжать работать с базой в режиме 24x7, возникает множество side-эффектов, которые будут портить вам жизнь.
Чтобы справиться с ними в PostgreSQL (да и не только в нем), можно использовать некоторые возможности для оптимизаций, которые позволят обработать все быстрее и с меньшим расходом ресурсов.
1. Куда грузить?
Сначала давайте определимся, куда мы можем залить данные, которые мы хотим «отпроцессить».
1.1. Временные таблицы (TEMPORARY TABLE)
В принципе, для PostgreSQL временные — это такие же таблицы, как и любые другие. Поэтому неверны суеверия типа «там все хранится только в памяти, а она может кончиться». Но есть и несколько существенных отличий.
Свой «неймспейс» для каждого подключения к БД
Если два подключения попытаются одновременно выполнить
CREATE TABLE x, то кто-то обязательно получит ошибку неуникальности объектов БД.А вот если оба попытаются выполнить
CREATE TEMPORARY TABLE x, то оба нормально это сделают, и каждый получит свой экземпляр таблицы. И ничего общего между ними не будет.«Самоуничтожение» при disconnect
При закрытии подключения все временные таблицы автоматически удаляются, поэтому «вручную» выполнять
DROP TABLE x смысла нет никакого, кроме…Если вы работаете через pgbouncer в transaction mode, то база-то продолжает считать, что это соединение все еще активно, и в нем-то эта временная таблица по-прежнему существует.
Поэтому попытка создать ее повторно, уже из другого подключения к pgbouncer, приведет к ошибке. Но это можно обойти, воспользовавшись
CREATE TEMPORARY TABLE IF NOT EXISTS x.Правда, лучше так все-таки не делать, потому что затем можно «внезапно» обнаружить там, оставшиеся от «предыдущего владельца» данные. Вместо этого гораздо лучше прочитать-таки мануал, и увидеть, что при создании таблицы есть возможность дописать
ON COMMIT DROP — то есть при завершении транзакции таблица будет автоматически удалена.Не-репликация
В силу принадлежности только определенному соединению, временные таблицы не реплицируются. Зато это избавляет от необходимости двойной записи данных в heap + WAL, поэтому INSERT/UPDATE/DELETE в нее существенно быстрее.
Но поскольку временная — это все-таки «почти обычная» таблица, то и на реплике ее создать нельзя тоже. По крайней мере, пока, хотя соответствующий патч уже давно ходит.
1.2. Нежурналируемые таблицы (UNLOGGED TABLE)
Но что делать, например, если у вас есть какой-то громоздкий ETL-процесс, который не удается реализовать в рамках одной транзакции, а у вас таки pgbouncer в transaction mode?..
Или поток данных настолько велик, что недостаточно пропускной способности одного соединения с БД (читай, одного процесса на CPU)?..
Или часть операций идут асинхронно в разных коннектах?..
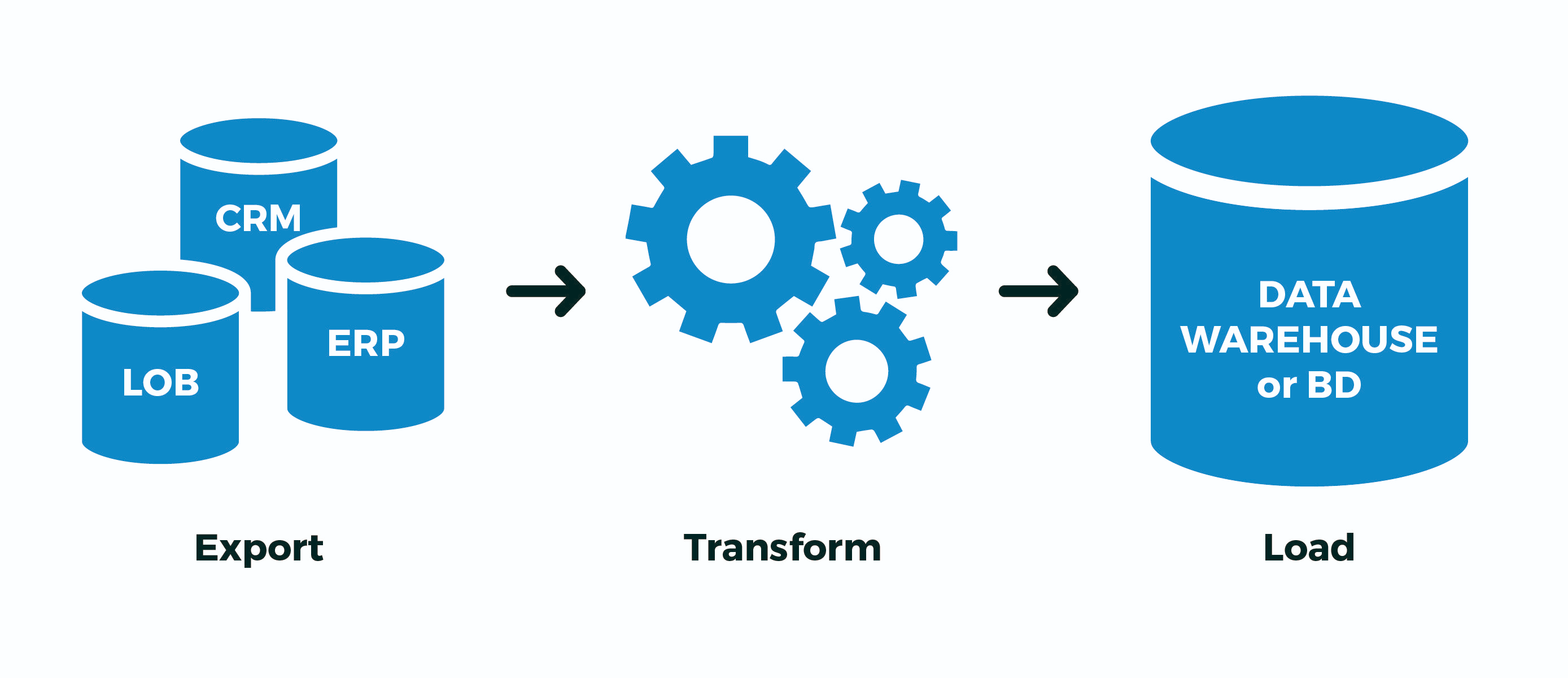
Тут вариант только один — временно создавать не-временную таблицу. Каламбур, ага. То есть:
- создал «свои» таблицы с максимально-случайными именами, чтобы ни с кем не пересечься
- Extract: залил в них данные из внешнего источника
- Transform: преобразовал, заполнил ключевые связывающие поля
- Load: перелил готовые данные в целевые таблицы
- удалил «свои» таблицы
А теперь — ложка дегтя. По сути, вся запись в PostgreSQL происходит дважды — сначала в WAL, потом уже в тела таблицы/индексов. Все это сделано для поддержки ACID и корректной видимости данных между
COMMIT'нутыми и ROLLBACK'нутыми транзакциями.Но нам-то этого не нужно! У нас весь процесс или целиком успешно прошел, или нет. Неважно, сколько в нем будет промежуточных транзакций — нам не интересно «продолжать процесс с середины», особенно когда непонятно, где она была.
Для этого разработчики PostgreSQL еще в версии 9.1 внедрили такую штуку как нежурналируемые (UNLOGGED) таблицы:
С этим указанием таблица создаётся как нежурналируемая. Данные, записываемые в нежурналируемые таблицы, не проходят через журнал предзаписи (см. Главу 29), в результате чего такие таблицы работают гораздо быстрее обычных. Однако, они не защищены от сбоя; при сбое или аварийном отключении сервера нежурналируемая таблица автоматически усекается. Кроме того, содержимое нежурналируемой таблицы не реплицируется на ведомые серверы. Любые индексы, создаваемые для нежурналируемой таблицы, автоматически становятся нежурналируемыми.Короче, будет сильно быстрее, но если сервер БД «упадет» — будет неприятно. Но часто ли это происходит, и умеет ли ваш ETL-процесс это корректно дорабатывать «с середины» после «оживления» БД?..
Если таки нет, и кейс выше похож на ваш — используйте
UNLOGGED, но никогда не включайте этот атрибут на реальных таблицах, данные из которых вам дороги.1.3. ON COMMIT { DELETE ROWS | DROP }
Эта конструкция позволяет при создании таблицы задать автоматическое поведение при завершении транзакции.
Про
ON COMMIT DROP я уже написал выше, он генерирует DROP TABLE, а вот с ON COMMIT DELETE ROWS ситуация интереснее — тут генерируется TRUNCATE TABLE.Поскольку вся инфраструктура хранения метаописания временной таблицы ровно такая же, как и у обычной, то постоянное создание-удаление временных таблиц приводит к сильному «разбуханию» системных таблиц pg_class, pg_attribute, pg_attrdef, pg_depend,…
Теперь представьте, что у вас есть воркер на прямом соединении с БД, который каждую секунду открывает новую транзакцию, создает, наполняет, обрабатывает и удаляет временную таблицу… Мусора в системных таблицах накопится в избытке, а это лишние тормоза при каждой операции.
В общем, не надо так! В этом случае гораздо эффективнее
CREATE TEMPORARY TABLE x ... ON COMMIT DELETE ROWS вынести за цикл транзакций — тогда к началу каждой новой транзакции таблицы уже будет существовать (экономим вызов CREATE), но будет пустой, благодаря TRUNCATE (его вызов мы тоже сэкономили) при завершении предыдущей транзакции.1.4. LIKE… INCLUDING ...
Я упомянул в начале, что один из типичных use case для временных таблиц — это разного рода импорты — и разработчик устало копипастит список полей целевой таблицы в объявление своей временной…
Но лень — двигатель прогресса! Поэтому создать новую таблицу «по образцу» можно гораздо проще:
CREATE TEMPORARY TABLE import_table(
LIKE target_table
);Поскольку нагенерить потом в эту таблицу можно весьма много данных, то поиски по ней станут ни разу не быстрыми. Но против этого есть традиционное решение — индексы! И, да, у временной таблицы тоже могут быть индексы.
Поскольку, зачастую, нужные индексы совпадают с индексами целевой таблицы, то можно просто написать
LIKE target_table INCLUDING INDEXES.Если вам нужны еще и
DEFAULT-значения (например, для заполнения значений первичного ключа), можно воспользоваться LIKE target_table INCLUDING DEFAULTS. Ну или просто — LIKE target_table INCLUDING ALL — скопирует дефолты, индексы, констрейнты,…Но тут уже надо понимать, что если вы создавали импорт-таблицу сразу с индексами, то заливаться данные будут дольше, чем если сначала все залить, а уже потом накатить индексы — посмотрите в качестве примера, как это делает pg_dump.
В общем, RTFM!
2. Как писать?
Скажу просто — используйте
COPY-поток вместо «пачки» INSERT, ускорение в разы. Можно даже прямо из предварительно сформированного файла.3. Как обрабатывать?
Итак, пусть наша вводная выглядит примерно так:
- у вас в базе хранится табличка с клиентскими данными на 1M записей
- каждый день клиент присылает вам новый полный «образ»
- по опыту вы знаете, что от раза к разу изменяется не более 10K записей
Классическим примером подобной ситуации является база КЛАДР — всего адресов много, но в каждой недельной выгрузке изменений (переименований населенных пунктов, объединений улиц, появлений новых домов) совсем немного даже в масштабе всей страны.
3.1. Алгоритм полной синхронизации
Для простоты допустим, что вам даже реструктурировать данные не нужно — просто привести таблицу в нужный вид, то есть:
- удалить все, чего уже нет
- обновить все, что уже было, и надо обновлять
- вставить все, чего еще не было
Почему именно в таком порядке стоит делать операции? Потому что именно так размер таблицы вырастет минимально (помни про MVCC!).
DELETE FROM dst
Нет, конечно можно обойтись всего двумя операциями:
- удалить (
DELETE) вообще все - вставить все из нового образа
Но при этом, благодаря MVCC, размер таблицы увеличится ровно в два раза! Получить +1M образов записей в таблице из-за обновления 10K — так себе избыточность…
TRUNCATE dst
Более опытный разработчик знает, что всю табличку целиком можно достаточно дешево зачистить:
- очистить (
TRUNCATE) таблицу целиком - вставить все из нового образа
Метод действенный, иногда вполне применим, но есть незадача… Вливать 1M записей мы будем до-о-олго, поэтому оставить таблицу пустой на все это время (как произойдет без оборачивания в единую транзакцию) не можем себе позволить.
А значит:
- у нас начинается длительная транзакция
TRUNCATEнакладывает AccessExclusive-блокировку- мы долго делаем вставку, а все остальные в это время не могут даже
SELECT
Че-то нехорошо получается…
ALTER TABLE… RENAME… / DROP TABLE ...
Как вариант — залить все в отдельную новую таблицу, а потом просто переименовать на место старой. Пара противных мелочей:
- таки тоже AccessExclusive, хоть и существенно меньше по времени
- сбрасываются все планы запросов/статистика этой таблицы, надо гонять ANALYZE
- ломаются все внешние ключи (FK) на таблицу
Был WIP-патч от Simon Riggs, который предлагал сделать
ALTER-операцию для подмены тела таблицы на файловом уровне, не трогая статистику и FK, но не собрал кворума.DELETE, UPDATE, INSERT
Итак, останавливаемся на неблокирующем варианте из трех операций. Почти трех… Как это сделать наиболее эффективно?
-- все делаем в рамках транзакции, чтобы никто не видел "промежуточных" состояний
BEGIN;
-- создаем временную таблицу с импортируемыми данными
CREATE TEMPORARY TABLE tmp(
LIKE dst INCLUDING INDEXES -- по образу и подобию, вместе с индексами
) ON COMMIT DROP; -- за рамками транзакции она нам не нужна
-- быстро-быстро вливаем новый образ через COPY
COPY tmp FROM STDIN;
-- ...
-- \.
-- удаляем отсутствующие
DELETE FROM
dst D
USING
dst X
LEFT JOIN
tmp Y
USING(pk1, pk2) -- поля первичного ключа
WHERE
(D.pk1, D.pk2) = (X.pk1, X.pk2) AND
Y IS NOT DISTINCT FROM NULL; -- "антиджойн"
-- обновляем оставшиеся
UPDATE
dst D
SET
(f1, f2, f3) = (T.f1, T.f2, T.f3)
FROM
tmp T
WHERE
(D.pk1, D.pk2) = (T.pk1, T.pk2) AND
(D.f1, D.f2, D.f3) IS DISTINCT FROM (T.f1, T.f2, T.f3); -- незачем обновлять совпадающие
-- вставляем отсутствующие
INSERT INTO
dst
SELECT
T.*
FROM
tmp T
LEFT JOIN
dst D
USING(pk1, pk2)
WHERE
D IS NOT DISTINCT FROM NULL;
COMMIT;
3.2. Постобработка импорта
В том же самом КЛАДРе все изменившиеся записи необходимо дополнительно прогнать через постобработку — нормализовать, выделить ключевые слова, привести к нужным структурам. Но как узнать — что именно изменялось, не усложняя при этом код синхронизации, в идеале, вообще не трогая его?
Если доступ на запись в момент синхронизации есть только у вашего процесса, то можно воспользоваться триггером, который соберет для нас все изменения:
-- целевые таблицы
CREATE TABLE kladr(...);
CREATE TABLE kladr_house(...);
-- таблицы с историей изменений
CREATE TABLE kladr$log(
ro kladr, -- тут лежат целые образы записей старой/новой
rn kladr
);
CREATE TABLE kladr_house$log(
ro kladr_house,
rn kladr_house
);
-- общая функция логирования изменений
CREATE OR REPLACE FUNCTION diff$log() RETURNS trigger AS $$
DECLARE
dst varchar = TG_TABLE_NAME || '$log';
stmt text = '';
BEGIN
-- проверяем необходимость логгирования при обновлении записи
IF TG_OP = 'UPDATE' THEN
IF NEW IS NOT DISTINCT FROM OLD THEN
RETURN NEW;
END IF;
END IF;
-- создаем запись лога
stmt = 'INSERT INTO ' || dst::text || '(ro,rn)VALUES(';
CASE TG_OP
WHEN 'INSERT' THEN
EXECUTE stmt || 'NULL,$1)' USING NEW;
WHEN 'UPDATE' THEN
EXECUTE stmt || '$1,$2)' USING OLD, NEW;
WHEN 'DELETE' THEN
EXECUTE stmt || '$1,NULL)' USING OLD;
END CASE;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Теперь мы можем перед началом синхронизации триггеры наложить (или включить через
ALTER TABLE ... ENABLE TRIGGER ...):CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr_house
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
А потом спокойно из log-таблиц извлекаем все нужные нам изменения и прогоняем по дополнительным обработчикам.
3.3. Импорт связанных наборов
Выше мы рассматривали случаи, когда структуры данных источника и приемника совпадают. Но что делать, если выгрузка из внешней системы имеет формат отличный от структуры хранения у нас в базе?
Возьмем в качестве примера хранение клиентов и счетов по ним, классический вариант «многие-к-одному»:
CREATE TABLE client(
client_id
serial
PRIMARY KEY
, inn
varchar
UNIQUE
, name
varchar
);
CREATE TABLE invoice(
invoice_id
serial
PRIMARY KEY
, client_id
integer
REFERENCES client(client_id)
, number
varchar
, dt
date
, sum
numeric(32,2)
);А вот выгрузка из внешнего источника приходит нам в виде «все в одном»:
CREATE TEMPORARY TABLE invoice_import(
client_inn
varchar
, client_name
varchar
, invoice_number
varchar
, invoice_dt
date
, invoice_sum
numeric(32,2)
);Очевидно, что данные по клиентам могут дублироваться в таком варианте, а основной записью является «счет»:
0123456789;Вася;A-01;2020-03-16;1000.00
9876543210;Петя;A-02;2020-03-16;666.00
0123456789;Вася;B-03;2020-03-16;9999.00
Для модели просто вставим наши тестовые данные, но помним —
COPY эффективнее!INSERT INTO invoice_import
VALUES
('0123456789', 'Вася', 'A-01', '2020-03-16', 1000.00)
, ('9876543210', 'Петя', 'A-02', '2020-03-16', 666.00)
, ('0123456789', 'Вася', 'B-03', '2020-03-16', 9999.00);Сначала выделим те «разрезы», на которые наши «факты» ссылаются. В нашем случае счета ссылаются на клиентов:
CREATE TEMPORARY TABLE client_import AS
SELECT DISTINCT ON(client_inn)
-- можно просто SELECT DISTINCT, если данные заведомо непротиворечивы
client_inn inn
, client_name "name"
FROM
invoice_import;Чтобы счета правильно связать с ID клиентов, нам эти идентификаторы надо сначала узнать или сгенерировать. Добавим под них поля:
ALTER TABLE invoice_import ADD COLUMN client_id integer;
ALTER TABLE client_import ADD COLUMN client_id integer;Воспользуемся описанным выше способом синхронизации таблиц с небольшой поправкой — не будем ничего обновлять и удалять в целевой таблице, ведь импорт клиентов у нас «append-only»:
-- проставляем в таблице импорта ID уже существующих записей
UPDATE
client_import T
SET
client_id = D.client_id
FROM
client D
WHERE
T.inn = D.inn; -- unique key
-- вставляем отсутствовавшие записи и проставляем их ID
WITH ins AS (
INSERT INTO client(
inn
, name
)
SELECT
inn
, name
FROM
client_import
WHERE
client_id IS NULL -- если ID не проставился
RETURNING *
)
UPDATE
client_import T
SET
client_id = D.client_id
FROM
ins D
WHERE
T.inn = D.inn; -- unique key
-- проставляем ID клиентов у записей счетов
UPDATE
invoice_import T
SET
client_id = D.client_id
FROM
client_import D
WHERE
T.client_inn = D.inn; -- прикладной ключ
Собственно, все — в
invoice_import теперь у нас заполнено поле связи client_id, с которым мы и вставим счет.


aborouhin
А в чём преимущества описанного подхода по сравнению с использованием отдельных ETL-инструментов? Ну, например, Apache NiFi.
Kilor Автор
Например, одно из преимуществ в том, что вы полностью контролируете все операции на каждом этапе (и понимаете как и когда они происходят). То есть когда такой импорт — лишь одна, и не доминирующая, функция вашего продукта.
Например, тот же импорт выписки из клиент-банка и связывание платежек со счетами для интернет-магазина. Разворачивать ради одной такой функции дополнительный не особо простой софт не всегда эффективно по сравнению с «сделал сам в 5 строк».
aborouhin
С другой стороны, тот же NiFi:
1) в аббревиатуре ETL выполнит букву E (Вы привели пример с КЛАДР (ныне ФИАС), я сейчас работаю ЕГРЮЛ — в любом случае, это загрузка с внешнего HTTP/FTP с учётом ранее загруженного);
2) проверит соответствие загруженных данных схеме, сообщит в случае ошибки (мало ли что поменяют или выложат битый файл, бывало);
3) выполнит букву T, не грузя этим сервер БД, которому и так есть чем заняться (в случае с ЕГРЮЛ — разделит скачанный XML на отдельные события по каждому юр. лицу, в КЛАДР/ФИАС тоже надо осуществить что-то подобное, наверняка);
4) размажет по времени букву L, чтобы и тут не создавать пиковых нагрузок на БД;
5) уведомит другие сервисы, которым надо бы узнать о произошедшем, не запрашивая постоянно БД (в моём случае — опубликует сообщение в Kafka).
Ваше решение обеспечивает только четвёртый пункт. Ну и по степени контроля над процессом / подробности логирования тоже к NiFi и аналогам придраться сложно. Я как раз думал, что именно эту часть процесса подобный софт и облегчает.
Kilor Автор
Я не говорю, что другие инструменты не нужны, но дополнительно к СУБД и БЛ, которая и делает парсинг XML в адекватной схеме (а явно не БД), вы уже ввели в систему NiFi и Kafka. Не каждый разработчик готов сразу шагать в «суровый энтерпрайз», кому-то предложенного подхода может оказаться вполне достаточно.
aborouhin
Просто я уже влез вот в эти все фишки из «сурового энтерпрайза» в своём стартапном по сути проекте — и пытаюсь найти этому оправдание :)
sshikov
Не стоит тут искать оправдание. Инструменты, работающие вне СУБД, для таких задач намного удобнее (я правда назвал бы Camel, но не думаю что это принципиально).
И как-то знаете,
>когда объем этого «чего-то» начинает измеряться сотнями мегабайт
у меня вызывает вопросы: а почему не гигабайт? Как-то маловато будет. Сотни мегабайт — это на сегодня намного меньше типового объема оперативки. Т.е. работаем по сценарию «залили все в память, там переварили, вернули в БД». И никаких проблем при этом. Более того, я по такому сценарию еще в 2010 примерно работал — и мы получили ускорение (не на ETL правда, а на отчете) на пару порядков.
Kilor Автор
sshikov
Терабайт уже хорошие размерчики, у нас есть некоторое число таких табличек, и могу честно сказать, что почти каждая из них требует какого-либо индивидуального подхода, чтобы не работать сутками, а уложиться например часа в четыре.
Кстати, а PG как-то ограничивает использование всей доступной памяти? Ну т.е. можно ли реально написать хранимку, которая употребит имеющиеся на машинке условные полтерабайта оперативки?
Пишите, почитаем)
Kilor Автор
Написать можно, но обычно это плохо заканчивается приходом OOM Killer, потому что является результатом какой-то плохо ограниченной рекурсии. В реальных применениях гораздо чаще произойдет использование temp buffers.
sshikov
>Нет, это не время обработки, а входящий объем.
Обычно есть ограничения и на время обработки (скажем, входящие за вчера нужно обработать сегодня, а лучше до утра, а иначе отчеты за вчера будут только послезавтра). А уж параллелить и так есть что — если у нас в наличии таблица скажем пять терабайт, это не значит, что она в схеме одна — там может быть их еще пятьсот.
Так что у нас вся обработка и так параллелится, это вообще Хадуп в моем случае. Штук 400 процессов вполне типично для нескольких терабайт одной таблицы. А для тех где до 10 терабайт в сутки только изменений — там вообще история совсем отдельная.
Kilor Автор
Было бы интересно почитать.
sshikov
Ну, терабайт в отлайне не получается никак. Тупо в диски упирается, например. А в целом стратегия работы с терабайтами в хадупе — это довольно интересная тема, только очень техническая, я не уверен, что готов по ней что-то интересное написать. С одной стороны, все в общем просто — берем терабайт, берем скажем 100 узлов кластера, уже получилось 10 гигабайт на узел — не так и много. То есть, если мы обработку можем тупо распараллелить на 100 потоков (так, чтобы потом не забить всю сеть обменом промежуточными результатами) — мы все сделаем с такой скоростью, как будто это были 10 гигабайт. Ну, почти.
А дальше уже идут попытки найти алгоритм, который хорошо параллелится. Скажем, сортировка параллелится не очень, а фильтр Блума — сильно лучше.
Kilor Автор
С учетом колебаний нагрузки день-ночь реальные пики получаются больше, но не выше 100MB/s обычно, SSD спокойно справляются. Но это как раз история про «индивидуальный подход» к данным, да.
sshikov
>вы уже ввели в систему NiFi и Kafka
Собственно, а попробуйте каким-то образом сообщить другим процессам, если у вас таковые есть, что в БД что-то произошло? У вас так или иначе появится какой-то messaging, не кафка, так JMS, не ActiveMQ, так QPID. Наличие messaging — это не недостаток, скажем прямо. Это особенность развитой архитектуры (во завернул :)
А вот у решения «целиком внутри БД» есть один существенный недостаток — оно делается как правило на одном языке, который не очень хорошо подходит для каких-либо задач помимо манипулирования собственно данными из базы.
Это и для PL/SQL в общем так, и для постгреса, да и для MS SQL не сильно отличается. Даже там, где можно применить скажем Java (в Oracle), или C# (MS SQL), это выливается в совершенно ненужные приседания, и обычно проще все сделать снаружи БД, нежели внутри.
>Не каждый разработчик готов сразу шагать
Ну да, если такое ограничение для вас имеет место — тогда решение как решение, почему нет?
Kilor Автор
sshikov
Ну это вы про сообщения внутри, да. Такое и у MS SQL есть. И такое иногда очень полезно — потому что послав сообщение, вы автоматически его обработку сделаете в другой транзакции. Вот только с другими системами такое не очень удобно стыкуется. Послать-то можно — вызов хранимой процедуры, и ок, а вот получить без опроса как-то не очень выходит, надо чтобы хранимая процедура хотя бы REST научилась вызывать, например.
Kilor Автор
www.psycopg.org/docs/advanced.html#asynchronous-notifications
asmm
del