
В конце прошлого года, я написал статью, о том как был заинтригован возможностью распознавания объектов на изображениях с помощью нейронных сетей. В той статье мы с помощью PyTorch классифицировали на видео либо ягоду малину, либо ардуино-подобный контроллер. И не смотря на то, что PyTorch мне понравился, обратился я к нему потому, что не смог с наскока разобраться с TensorFlow. Но я пообещал, что ещё вернусь к вопросу распознавания объектов на видео. Кажется пришло время сдержать обещание.
В данной статье мы попробуем на своей локальной машине дообучить уже готовую модель в Tensorflow 1.13 и Object Detection API на нашем собственном наборе изображений, а потом используем её для распознавания ягод и контроллеров, в видеопотоке веб-камеры с помощью OpenCV.
Хотите к лету улучшить навык распознавания ягод? Тогда милости прошу под кат.

Содержание:
Часть I: введение
Часть II: обучаем модель в TenosrFlow
Часть III: применяем модель в OpenCV
Часть IV: заключение
Те кто ознакомился с прошлой статьей про PyTorch, уже знают, что я дилетант в вопросах нейронных сетей. Поэтому не стоит воспринимать, эту статью, как истину в последней инстанции. Но так или иначе я надеюсь, что смогу кому-то помочь разобраться с азами распознавания видео с помощью Tensorflow Object Detection API.
В этот раз я не стремился сделать туториал, поэтому статья выйдет короче чем обычно.
Начну с того, что официальный туториал по применению Object Detection API на локальной машине, мягко говоря сложно назвать исчерпывающим. Мне, как новичку информации было совершенно недостаточно и пришлось ориентироваться на статьи в блогах.
Если честно мне бы хотелось попробовать TensorFlow 2.0, но в большинстве публикаций, на момент написания этой статьи, были не полностью решены вопросы миграции. Поэтому в итоге я остановился на TF 1.13.2.
Инструкции по обучению модели я черпал из этой статьи , а точнее из её первой половины, до момента применения JavaScript (Если вы не владеете английским, можно посмотреть статью на эту же тему на Хабре).
Правда в моем случае есть несколько отличий:
Так же на всякий случай, скажу, что я не использовал графический ускоритель. Обучение производилось только на мощностях процессора.
Набор изображений, конфигурационный файл, сохраненный граф, а также скрипт для распознавания изображения с помощью OpenCV, как всегда можно скачать с GitHub.
Прошли долгие 23 часа обучения модели, весь чай в доме уже выпит, “Что? Где? Когда?” досмотрено и вот мое терпение окончательно подошло к концу.
Останавливаем обучение и сохраняем модель.
Устанавливаем в тоже самое окружение “Анаконды” OpenCV, следующей командой:
У меня в итоге установлена версия 4.2
Дальше инструкции из этой статьи нам уже будут не нужны.
После сохранения модели я сделал одну неочевидную для меня ошибку, а именно сразу попытался подставить использованный ранее в папке training/ файл graph.pbtxt в функцию:
К сожалению, это так не работает и нам придется проделать еще одну манипуляцию, чтобы получить graph.pbtxt для OpenCV.
Скорее всего, то что я сейчас посоветую не очень хороший способ, но для меня он работает.
Скачаем tf_text_graph_ssd.py, а также tf_text_graph_common.py положим их в папку, где лежит наш сохраненный граф (у меня это папка inference_graph).
Затем перейдем в консоли в эту папку и выполним из неё команду примерно следующего содержания:
Вот и всё осталось только загрузить нашу модель в OpenCV.
Как и в статье про PyTorch в части работы с OpenCV я брал за основу программный код из этой публикации.
Я внес небольшие изменения, чтобы его еще немного упростить, но поскольку я не полностью понимаю код, то и комментировать его не буду. Работает и славно.Понятно, что код мог бы быть и лучше, но у меня пока нет времени, чтобы засесть за учебники по OpenCV .
Итак, всё готово. Запускаем модель, наводим объектив на мою старенькую CraftDuino и радуемся результату:

На первый взгляд совсем не дурно, но это только на первый взгляд.
Похоже за 23 часа, модель переобучилась, поэтому выдает серьезные ошибки при определении объектов.
Вот наглядная демонстрация:
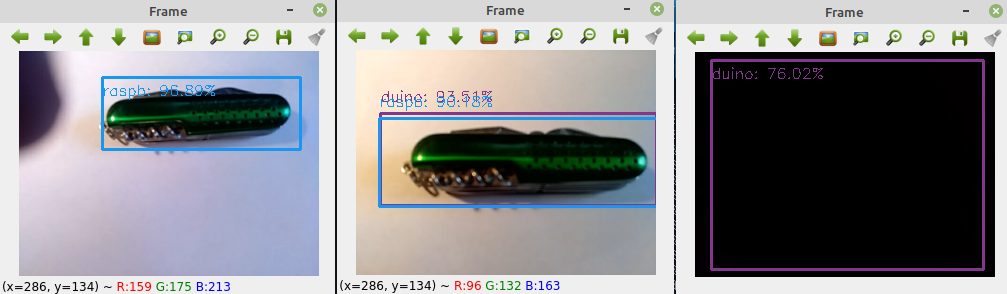
Как видно, не только ножик, но даже просто черный фон, эта модель определяет как ардуино-подобный контроллер. Возможно, всё потому, что в тренировочных данных были темные картинки с Arduino и его аналогами, на которые модель за 23 часа успела натаскаться.
В итоге пришлось загружать свой компьютер еще на 8 часов и обучать новую модель.
С ней дела обстоят намного лучше.
Вот пример с CraftDuino:

Живой малины у меня под рукой нет. Пришлось печатать картинки. С экрана телефона или монитора тоже можно распознать, но с бумаги было удобней.

Проверим, как модель распознает Arduino nano, которую в свое время DrZugrik для меня впаял в свое мега устройство с датчиками:
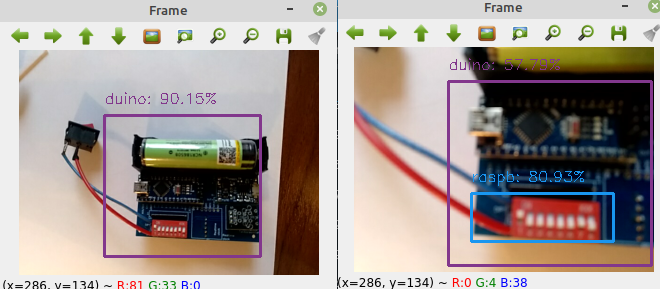
Как видите распознает вполне хорошо, однако при очень неудачном ракурсе и при теплом освещении, может некоторые фрагменты распознать, как малину. Но на самом деле кадр с ошибкой было тяжело поймать в объектив.
Теперь проверим, как она классифицирует те объекты на которых не обучалась.
Снова пример с ножом и черным фоном:

В этот раз все работает, как надо.
Предложим нашей модели распознать контроллер Canny 3 tiny, о котором я писал в прошлой статье.
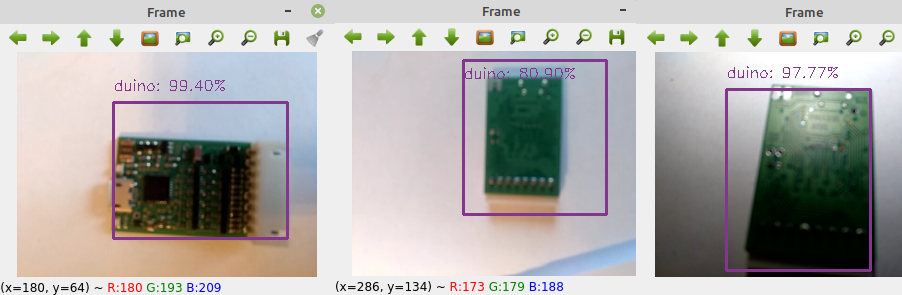
Поскольку наша модель не знает ни о чем, кроме ягоды малины и ардуино-подобных контроллеров, то можно сказать, что модель распознала контроллер Canny вполне успешно.
Правда, как и в случае с Arduino nano, многое зависит от ракурса и освещения.
При теплом свете лампы накаливания и при неудачном ракурсе, контроллер может не только не распознаваться, но даже определиться как малина. Правда, как и в прошлом случае, эти ракурсы еще надо было постараться поймать в объектив.

Ну и последний случай — своеобразный реверанс статье про классификацию изображений в PyTorch. Как и в прошлый раз совместим в одном кадре одноплатный компьютер Raspberry Pi 2 и его логотип. В отличие от прошлой статьи, в которой мы решали задачу классификации и выбирали один наиболее вероятный объект для изображения, в данном случае распознается и логотип и сама «Малина».

В заключение хочется сказать, что не смотря на то, что по неопытности этот небольшой пример работы с Tensorflow Object Detection API отнял у меня оба выходных и часть понедельника, я ни о чем не жалею. Когда хоть немного разберешся, как этим всем пользоваться становится безумно любопытно. В процессе обучения начинаешь относится к модели, как к живой, следишь за её успехами и неудачами.
Поэтому, рекомендую всем кто с этим не знаком однажды попробовать, распознать что-нибудь свое.
Тем более, как выснилось в процессе, вам даже не нужно покупать настоящую веб-камеру. Дело в том, что во время подготовки статьи я умудрился доломать свою веб-камеру (сломал механизм фокусировки) и уже думал, что придется всё забросить. Но оказалось, что с помощью Droidcam можно использовать смартфон вместо веб-камеры (не сочтите за рекламу). Причем качество съемки получилось сильно лучше, чем у сломавшейся камеры, а это весьма влияло на качество распознавания объектов на изображении.
Кстати поскольку в Anaconda нормальную сборку pycocotools я нашел только для Linux, а переключаться в процессе работы между операционными системами мне было лень, то всю эту статью я подготовил только с использованием oпрограмного обеспечения с открытым исходным кодом. Нашлись аналоги и Word и Photoshop и даже драйвер для принтера. Первый раз в моей жизни случилось такое. Оказалось, что современные версии ОС Linux и прикладных программ могут быть очень удобными, даже для человека более 25 лет использующего ОС от Microsoft.
P.S. Если кто-то знает, как нормально запустить Object Detection API
для Tensorflow версии 2 и выше, отпишитесь пожалуйста в личку или в комментарии.
Всем хорошего дня и крепкого здоровья!
В данной статье мы попробуем на своей локальной машине дообучить уже готовую модель в Tensorflow 1.13 и Object Detection API на нашем собственном наборе изображений, а потом используем её для распознавания ягод и контроллеров, в видеопотоке веб-камеры с помощью OpenCV.
Хотите к лету улучшить навык распознавания ягод? Тогда милости прошу под кат.
Содержание:
Часть I: введение
Часть II: обучаем модель в TenosrFlow
Часть III: применяем модель в OpenCV
Часть IV: заключение
Часть I: введение
Те кто ознакомился с прошлой статьей про PyTorch, уже знают, что я дилетант в вопросах нейронных сетей. Поэтому не стоит воспринимать, эту статью, как истину в последней инстанции. Но так или иначе я надеюсь, что смогу кому-то помочь разобраться с азами распознавания видео с помощью Tensorflow Object Detection API.
В этот раз я не стремился сделать туториал, поэтому статья выйдет короче чем обычно.
Начну с того, что официальный туториал по применению Object Detection API на локальной машине, мягко говоря сложно назвать исчерпывающим. Мне, как новичку информации было совершенно недостаточно и пришлось ориентироваться на статьи в блогах.
Если честно мне бы хотелось попробовать TensorFlow 2.0, но в большинстве публикаций, на момент написания этой статьи, были не полностью решены вопросы миграции. Поэтому в итоге я остановился на TF 1.13.2.
Часть II: обучаем модель в TensorFlow
Инструкции по обучению модели я черпал из этой статьи , а точнее из её первой половины, до момента применения JavaScript (Если вы не владеете английским, можно посмотреть статью на эту же тему на Хабре).
Правда в моем случае есть несколько отличий:
- Я использовал Linux, потому что в Anaconda для Linux уже есть собранные protobuf и pycocoapi, поэтому мне не пришлось их собирать самому.
- Я использовал версию TensorFlow 1.13.2, а также ветку Object Detection API 1.13 потому, что актуальная ветка выдавала ошибку с TensorFlow 1.13.2. Текущую ветку master мне вроде бы удавалось запустить с версией TF 1.15, но для этой статьи я остановился на версии 1.13.
- Необходимо будет установить более старую версию numpy — 1.17.5, версия 1.18 вызывала у меня ошибку.
- Вместо модели faster_rcnn_inception_v2_coco мы будем использовать ssd_mobilenet_v2_coco, поэтому будут небольшие изменения, но всё делается по аналогии.
Так же на всякий случай, скажу, что я не использовал графический ускоритель. Обучение производилось только на мощностях процессора.
Набор изображений, конфигурационный файл, сохраненный граф, а также скрипт для распознавания изображения с помощью OpenCV, как всегда можно скачать с GitHub.
Прошли долгие 23 часа обучения модели, весь чай в доме уже выпит, “Что? Где? Когда?” досмотрено и вот мое терпение окончательно подошло к концу.
Останавливаем обучение и сохраняем модель.
Устанавливаем в тоже самое окружение “Анаконды” OpenCV, следующей командой:
conda install -c conda-forge opencvУ меня в итоге установлена версия 4.2
Дальше инструкции из этой статьи нам уже будут не нужны.
После сохранения модели я сделал одну неочевидную для меня ошибку, а именно сразу попытался подставить использованный ранее в папке training/ файл graph.pbtxt в функцию:
cv2.dnn.readNetFromTensorflow()К сожалению, это так не работает и нам придется проделать еще одну манипуляцию, чтобы получить graph.pbtxt для OpenCV.
Скорее всего, то что я сейчас посоветую не очень хороший способ, но для меня он работает.
Скачаем tf_text_graph_ssd.py, а также tf_text_graph_common.py положим их в папку, где лежит наш сохраненный граф (у меня это папка inference_graph).
Затем перейдем в консоли в эту папку и выполним из неё команду примерно следующего содержания:
python tf_text_graph_ssd.py --input frozen_inference_graph.pb --config pipeline.config --output frozen/graph.pbtxtВот и всё осталось только загрузить нашу модель в OpenCV.
Часть III: применяем модель в OpenCV
Как и в статье про PyTorch в части работы с OpenCV я брал за основу программный код из этой публикации.
Я внес небольшие изменения, чтобы его еще немного упростить, но поскольку я не полностью понимаю код, то и комментировать его не буду. Работает и славно.Понятно, что код мог бы быть и лучше, но у меня пока нет времени, чтобы засесть за учебники по OpenCV .
Код для работы с OpenCV
# USAGE
# based on this code https://proglib.io/p/real-time-object-detection/
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import imutils
import time
import cv2
prototxt="graph.pbtxt"
model="frozen_inference_graph.pb"
min_confidence = 0.5
# initialize the list of class labels MobileNet SSD was trained to
# detect, then generate a set of bounding box colors for each class
CLASSES = ["background", "duino","raspb"]
COLORS = [(40,50,60),((140,55,130)),(240,150,25)]
# load our serialized model from disk
print("[INFO] loading model...")
net =cv2.dnn.readNetFromTensorflow(model,prototxt)
# initialize the video stream, allow the cammera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(0.5)
fps = FPS().start()
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 400 pixels
frame = vs.read()
frame = imutils.resize(frame, width=300)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, size=(300, 300), swapRB=True)
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
print (detections)
confidence = detections[0, 0, i, 2]
if confidence > min_confidence:
# extract the index of the class label from the
# `detections`, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# draw the prediction on the frame
label = "{}: {:.2f}%".format(CLASSES[idx],
confidence * 100)
cv2.rectangle(frame, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y+3),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 1)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
Итак, всё готово. Запускаем модель, наводим объектив на мою старенькую CraftDuino и радуемся результату:
На первый взгляд совсем не дурно, но это только на первый взгляд.
Похоже за 23 часа, модель переобучилась, поэтому выдает серьезные ошибки при определении объектов.
Вот наглядная демонстрация:
Как видно, не только ножик, но даже просто черный фон, эта модель определяет как ардуино-подобный контроллер. Возможно, всё потому, что в тренировочных данных были темные картинки с Arduino и его аналогами, на которые модель за 23 часа успела натаскаться.
В итоге пришлось загружать свой компьютер еще на 8 часов и обучать новую модель.
С ней дела обстоят намного лучше.
Вот пример с CraftDuino:
Живой малины у меня под рукой нет. Пришлось печатать картинки. С экрана телефона или монитора тоже можно распознать, но с бумаги было удобней.
Проверим, как модель распознает Arduino nano, которую в свое время DrZugrik для меня впаял в свое мега устройство с датчиками:
Как видите распознает вполне хорошо, однако при очень неудачном ракурсе и при теплом освещении, может некоторые фрагменты распознать, как малину. Но на самом деле кадр с ошибкой было тяжело поймать в объектив.
Теперь проверим, как она классифицирует те объекты на которых не обучалась.
Снова пример с ножом и черным фоном:
В этот раз все работает, как надо.
Предложим нашей модели распознать контроллер Canny 3 tiny, о котором я писал в прошлой статье.
Поскольку наша модель не знает ни о чем, кроме ягоды малины и ардуино-подобных контроллеров, то можно сказать, что модель распознала контроллер Canny вполне успешно.
Правда, как и в случае с Arduino nano, многое зависит от ракурса и освещения.
При теплом свете лампы накаливания и при неудачном ракурсе, контроллер может не только не распознаваться, но даже определиться как малина. Правда, как и в прошлом случае, эти ракурсы еще надо было постараться поймать в объектив.
Ну и последний случай — своеобразный реверанс статье про классификацию изображений в PyTorch. Как и в прошлый раз совместим в одном кадре одноплатный компьютер Raspberry Pi 2 и его логотип. В отличие от прошлой статьи, в которой мы решали задачу классификации и выбирали один наиболее вероятный объект для изображения, в данном случае распознается и логотип и сама «Малина».
Часть IV: заключение
В заключение хочется сказать, что не смотря на то, что по неопытности этот небольшой пример работы с Tensorflow Object Detection API отнял у меня оба выходных и часть понедельника, я ни о чем не жалею. Когда хоть немного разберешся, как этим всем пользоваться становится безумно любопытно. В процессе обучения начинаешь относится к модели, как к живой, следишь за её успехами и неудачами.
Поэтому, рекомендую всем кто с этим не знаком однажды попробовать, распознать что-нибудь свое.
Тем более, как выснилось в процессе, вам даже не нужно покупать настоящую веб-камеру. Дело в том, что во время подготовки статьи я умудрился доломать свою веб-камеру (сломал механизм фокусировки) и уже думал, что придется всё забросить. Но оказалось, что с помощью Droidcam можно использовать смартфон вместо веб-камеры (не сочтите за рекламу). Причем качество съемки получилось сильно лучше, чем у сломавшейся камеры, а это весьма влияло на качество распознавания объектов на изображении.
Кстати поскольку в Anaconda нормальную сборку pycocotools я нашел только для Linux, а переключаться в процессе работы между операционными системами мне было лень, то всю эту статью я подготовил только с использованием oпрограмного обеспечения с открытым исходным кодом. Нашлись аналоги и Word и Photoshop и даже драйвер для принтера. Первый раз в моей жизни случилось такое. Оказалось, что современные версии ОС Linux и прикладных программ могут быть очень удобными, даже для человека более 25 лет использующего ОС от Microsoft.
P.S. Если кто-то знает, как нормально запустить Object Detection API
для Tensorflow версии 2 и выше, отпишитесь пожалуйста в личку или в комментарии.
Всем хорошего дня и крепкого здоровья!
Ajex
Вставлю свои пару копеек.
pycocotools (да и все остальное для tensorflow ) нормально ставиться и работает под Windows 7, проверено лично.
Вот по первой же ссылке из гугла www.kaggle.com/c/tgs-salt-identification-challenge/discussion/62381
Попробовал только что собрать у себя под Win7 под Анакондой:
C Tensorflow 2 сам намучался намедни. Почти ни один из примеров без диких плясок (а то и с ними) не работает. Потому сам откатился до 1.15.
На GPU обучение работает конечно повеселее, чем на процессоре.
Себе вот заказал Google Coral USB Accelerator + PiCar модель, хочу заставить модель ездить по линиям и распознавать дорожные знаки. По вот этому примеру.
towardsdatascience.com/deeppicar-part-1-102e03c83f2c
Собственно собрал уже все, запустил, пока жду акселератор, пробую заставить ездить по полоскам для начала.
Кстати, отличная цель обучится Deep Learning на карантине. :)
BosonBeard Автор
Да, конечно оно собирается, есть много примеров как раз под windows. Тут скорее мне было любопытно пару дней пользоваться только Linux, получилось вполне комфортно.
P.S. поддерживаю Вас. Учить TensorFlow во время карантина — вполне достойная идея!