

Доброго времени суток.
Представляю вашему вниманию перевод статьи «Algorithms on Graphs: Let’s talk Depth-First Search (DFS) and Breadth-First Search (BFS)» автора Try Khov.
Что такое обход графа?
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.
Поиск в глубину
DFS следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
Давайте рассмотрим пример. Предположим, что у нас есть ориентированный граф, который выглядит так:

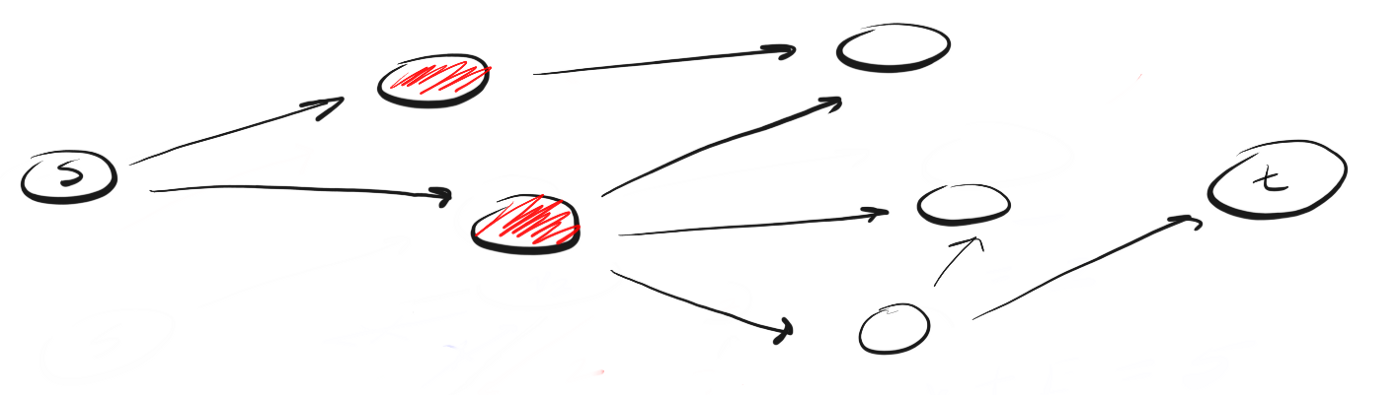
Мы находимся в точке «s» и нам нужно найти вершину «t». Применяя DFS, мы исследуем один из возможных путей, двигаемся по нему до конца и, если не обнаружили t, возвращаемся и исследуем другой путь. Вот как выглядит процесс:

Здесь мы двигаемся по пути (p1) к ближайшей вершине и видим, что это не конец пути. Поэтому мы переходим к следующей вершине.

Мы достигли конца p1, но не нашли t, поэтому возвращаемся в s и двигаемся по второму пути.

Достигнув ближайшей к точке «s» вершины пути «p2» мы видим три возможных направления для дальнейшего движения. Поскольку вершину, венчающую первое направление, мы уже посещали, то двигаемся по второму.

Мы вновь достигли конца пути, но не нашли t, поэтому возвращаемся назад. Следуем по третьему пути и, наконец, достигаем искомой вершины «t».

Так работает DFS. Двигаемся по определенному пути до конца. Если конец пути — это искомая вершина, мы закончили. Если нет, возвращаемся назад и двигаемся по другому пути до тех пор, пока не исследуем все варианты.
Мы следуем этому алгоритму применительно к каждой посещенной вершине.
Необходимость многократного повторения процедуры указывает на необходимость использования рекурсии для реализации алгоритма.
Вот JavaScript-код:
// при условии, что мы имеем дело со смежным списком
// например, таким: adj = {A: [B,C], B:[D,F], ... }
function dfs(adj, v, t) {
// adj - смежный список
// v - посещенный узел (вершина)
// t - пункт назначения
// это общие случаи
// либо достигли пункта назначения, либо уже посещали узел
if(v === t) return true
if(v.visited) return false
// помечаем узел как посещенный
v.visited = true
// исследуем всех соседей (ближайшие соседние вершины) v
for(let neighbor of adj[v]) {
// если сосед не посещался
if(!neighbor.visited) {
// двигаемся по пути и проверяем, не достигли ли мы пункта назначения
let reached = dfs(adj, neighbor, t)
// возвращаем true, если достигли
if(reached) return true
}
}
// если от v до t добраться невозможно
return false
}
Заметка: этот специальный DFS-алгоритм позволяет проверить, возможно ли добраться из одного места в другое. DFS может использоваться в разных целях. От этих целей зависит то, как будет выглядеть сам алгоритм. Тем не менее, общая концепция выглядит именно так.
Анализ DFS
Давайте проанализируем этот алгоритм. Поскольку мы обходим каждого «соседа» каждого узла, игнорируя тех, которых посещали ранее, мы имеем время выполнения, равное O(V + E).
Краткое объяснение того, что означает V+E:
V — общее количество вершин. E — общее количество граней (ребер).
Может показаться, что правильнее использовать V*E, однако давайте подумаем, что означает V*E.
V*E означает, что применительно к каждой вершине, мы должны исследовать все грани графа безотносительно принадлежности этих граней конкретной вершине.
С другой стороны, V+E означает, что для каждой вершины мы оцениваем лишь примыкающие к ней грани. Возвращаясь к примеру, каждая вершина имеет определенное количество граней и, в худшем случае, мы обойдем все вершины (O(V)) и исследуем все грани (O(E)). Мы имеем V вершин и E граней, поэтому получаем V+E.
Далее, поскольку мы используем рекурсию для обхода каждой вершины, это означает, что используется стек (бесконечная рекурсия приводит к ошибке переполнения стека). Поэтому пространственная сложность составляет O(V).
Теперь рассмотрим BFS.
Поиск в ширину
BFS следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того, чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз. Это означает следующее:
Вместо следования по пути, BFS подразумевает посещение ближайших к s соседей за одно действие (шаг), затем посещение соседей соседей и так до тех пор, пока не будет обнаружено t.

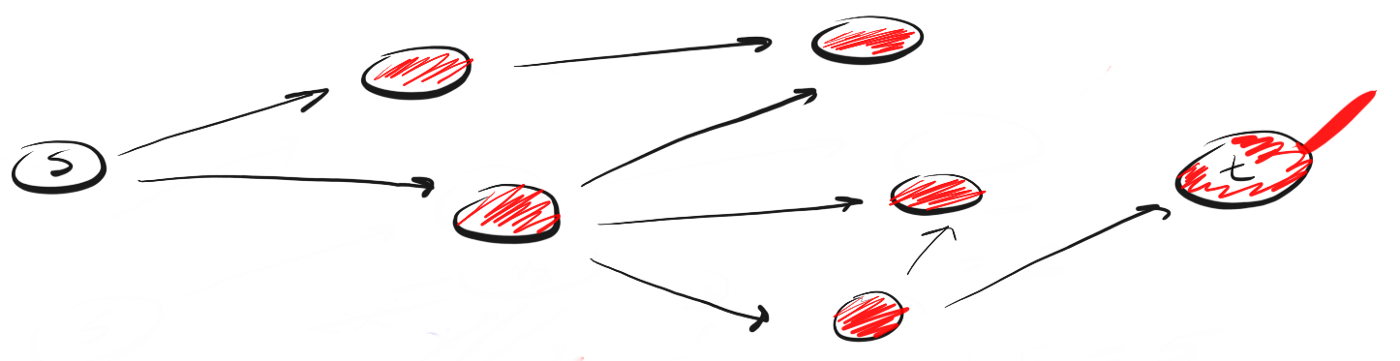
Чем DFS отличается от BFS? Мне нравится думать, что DFS идет напролом, а BFS не торопится, а изучает все в пределах одного шага.
Далее возникает вопрос: как узнать, каких соседей следует посетить первыми?
Для этого мы можем воспользоваться концепцией «первым вошел, первым вышел» (first-in-first-out, FIFO) из очереди (queue). Мы помещаем в очередь сначала ближайшую к нам вершину, затем ее непосещенных соседей, и продолжаем этот процесс, пока очередь не опустеет или пока мы не найдем искомую вершину.
Вот код:
// при условии, что мы имеем дело со смежным списком
// например, таким: adj = {A:[B,C,D], B:[E,F], ... }
function bfs(adj, s, t) {
// adj - смежный список
// s - начальная вершина
// t - пункт назначения
// инициализируем очередь
let queue = []
// добавляем s в очередь
queue.push(s)
// помечаем s как посещенную вершину во избежание повторного добавления в очередь
s.visited = true
while(queue.length > 0) {
// удаляем первый (верхний) элемент из очереди
let v = queue.shift()
// abj[v] - соседи v
for(let neighbor of adj[v]) {
// если сосед не посещался
if(!neighbor.visited) {
// добавляем его в очередь
queue.push(neighbor)
// помечаем вершину как посещенную
neighbor.visited = true
// если сосед является пунктом назначения, мы победили
if(neighbor === t) return true
}
}
}
// если t не обнаружено, значит пункта назначения достичь невозможно
return false
}
Анализ BFS
Может показаться, что BFS работает медленнее. Однако если внимательно присмотреться к визуализациям, можно увидеть, что они имеют одинаковое время выполнения.
Очередь предполагает обработку каждой вершины перед достижением пункта назначения. Это означает, что, в худшем случае, BFS исследует все вершины и грани.
Несмотря на то, что BFS может казаться медленнее, на самом деле он быстрее, поскольку при работе с большими графами обнаруживается, что DFS тратит много времени на следование по путям, которые в конечном счете оказываются ложными. BFS часто используется для нахождения кратчайшего пути между двумя вершинами.
Таким образом, время выполнения BFS также составляет O(V + E), а поскольку мы используем очередь, вмещающую все вершины, его пространственная сложность составляет O(V).
Аналогии из реальной жизни
Если приводить аналогии из реальной жизни, то вот как я представляю себе работу DFS и BFS.
Когда я думаю о DFS, то представляю себе мышь в лабиринте в поисках еды. Для того, чтобы попасть к цели мышь вынуждена много раз упираться в тупик, возвращаться и двигаться по другому пути, и так до тех пор, пока она не найдет выход из лабиринта или еду.

Упрощенная версия выглядит так:

В свою очередь, когда я думаю о BFS, то представляю себе круги на воде. Падение камня в воду приводит к распространению возмущения (кругов) во всех направлениях от центра.

Упрощенная версия выглядит так:

Выводы
- Поиск в глубину и поиск в ширину используются для обхода графа.
- DFS двигается по граням туда и обратно, а BFS распространяется по соседям в поисках цели.
- DFS использует стек, а BFS — очередь.
- Время выполнения обоих составляет O(V + E), а пространственная сложность — O(V).
- Данные алгоритмы имеют разную философию, но одинаково важны для работы с графами.
Прим. пер.: я не специалист по алгоритмам и структурам данных, поэтому при обнаружении ошибок, неточностей или некорректности формулировок, прошу написать в личку для исправления и уточнения. Буду признателен.
Благодарю за внимание.
Klotos
Полагаю, в оригинале под переменной adj подразумевается "Adjacency list", а значит, правильнее будет не «смежный список» (что это вообще такое — смежный список? Смежный с чем?), а список смежностей. Мне также встречался термин «список соответствий».
И каким боком эта статья относится к хабу ".NET"?