
Привет, Хабр! Представляю вашему вниманию перевод статьи "Implementing RoI Pooling in TensorFlow + Keras" автора Jaime Sevilla.
В данный момент я прохожу курс машинного обучения. В учебном блоке "Компьютерное зрение" возникла необходимость в изучении RoI Pooling слоёв. Приведённая ниже статья мне показалась интересной, в связи с чем я решил поделиться переводом с сообществом.
В этом посте мы объясним основную концепцию и общее использование RoI pooling (Region of Interest — область интересов) и предоставим реализацию с использованием слоев Keras среды TensorFlow.
Целевая аудитория этого поста — люди, знакомые с базовой теорией (сверточных) нейронных сетей (CNN) и способные создавать и запускать простые модели с использованием Keras.
Если вы здесь только для кода, обратитесь сюда и не забудьте поставить лайк и поделиться статьей!
Понимание RoI Pooling
RoI Pooling был предложен Россом Гиршиком в статье Fast R-CNN как часть его пайплайна распознавания объектов.
В общем случае использования для RoI Pooling у нас есть подобный изображению объект и несколько областей интереса (RoI — regions of interest), указанных через ограничивающие рамки. Мы хотим создать эмбеддинги (embedding (вложения) — сопоставления произвольной сущности (кусочка картинки) некоторому вектору) из каждого RoI.
Например, в настройке R-CNN у нас есть изображение и механизм выделения регионов-кандидатов, который создает ограничивающие рамки для потенциально интересных частей изображения. Теперь мы хотим создать эмбеддинг для каждого предложенного кусочка изображения.
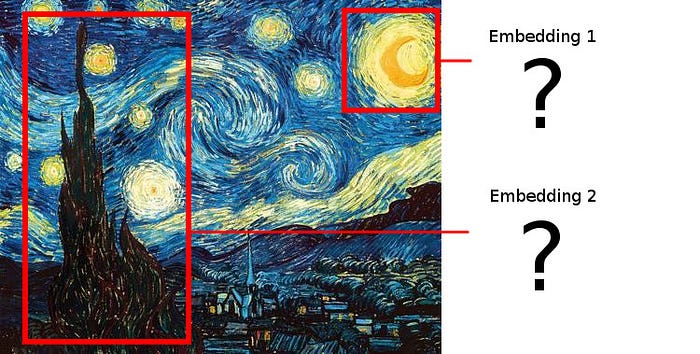
Простое обрезание каждой предложенной области не сработает, потому что мы хотим наложить полученные эмбеддинги друг на друга, и предлагаемые области не обязательно имеют одинаковую форму!
Поэтому нам нужно придумать способ трансформации каждого предложенного кусочка изображения таким образом, чтобы он приводил к созданию эмбеддинга заранее определенной размерности. Как мы можем сделать это?
В задачах компьютерного зрения стандартным способом уменьшения формы изображений является использование какой-либо операции объединения (pooling).
Наиболее распространенным является вариант max pooling, где мы делим входное изображение на (обычно не перекрывающиеся) области одинаковой формы и формируем выход, беря максимальное значение, найденное в каждой области.

Операция maxpool делит каждую область на пулы одинакового размера
Это напрямую не решает проблему, которая у нас есть – кусочки изображения различного размера будут разделяться блоками фиксированной размерности: эмбеддинги будут переменной размерности.
Но этот подход наталкивает на идею. Что если мы разделим каждую интересующую RoI на одно и то же количество областей различной формы и возьмем максимум каждой из них?

Операция ROI Pooling делит сеткой одинакового размера все части изображения, подвергаемые операции pooling.
И это именно то, что делает слой ROI Pooling.
Области применения RoI Pooling.
RoI Pooling — довольно общий инструмент. Как правило, он выходит на свет в сочетании с механизмами выделения кандидатов RoI, устраняя разрыв между выделением кандидатов и их эмбеддингами. Мы увидим два конкретных примера, иллюстрирующих его потенциал.
Во-первых, в контексте распознавания объектов (для которого RoI Pooling был разработан), он позволяет нам разделить пайплайн задач на две части (выделение кандидатов и классификация регионов), сохраняя при этом сквозную (end-to-end) однопроходную (single-pass) дифференцируемую архитектуру.
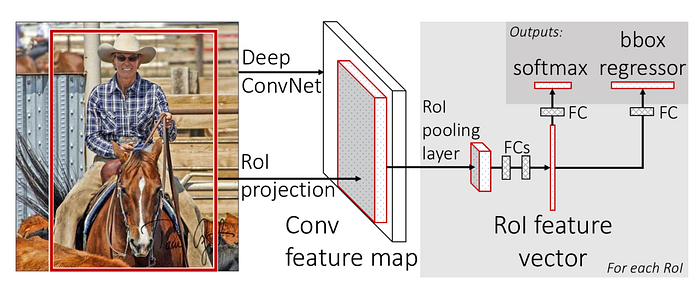
Fast R-CNN, демонстрирующая RoI Pooling, Росс Гиршик
Таким образом, в модели R-CNN у нас сначала есть компонент в модели, который выделяет на изображении фиксированное количество областей интереса (RoI). RoI Pooling позволяет нам запускать классификатор CNN для всех предложенных областей. В качестве ответа алгоритм выбирает регион с максимальной вероятностью целевого класса.
Во-вторых, вместе с выделением регионов-кадидатов, RoI Pooling также может быть использован для реализации визуального внимания (visual attention).
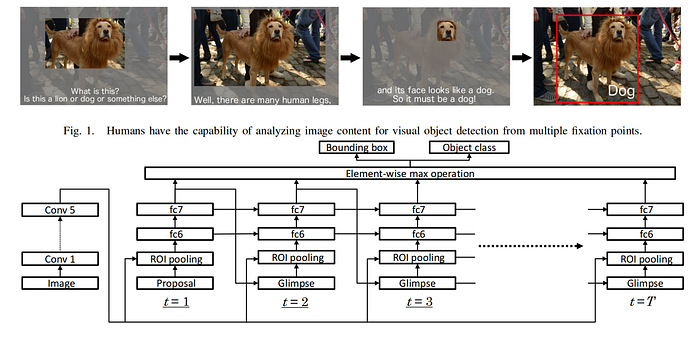
Attentional Network для визуальной детекции обьектов, демонстрирующая ROI Pooling, авторы Hara и др..
В качестве примера в Attentional Network для визуальной детекции обьектов мы видим, как Hara другие соавторы реализовали механизм attention, используя итеративные выделения кандидатов ROI и ROI Pooling. Сначала алгоритм генерирует первого кандидата (t = 1), которого ROI Pooling адаптирует к полносвязным слоям (Fully Connected). Результат используется в качестве входных данных для компонента Glimpse (представление) (t = 2) для генерации нового кандидата, который так же подвергается эмбеддингу с помощью ROI Pooling. Процесс повторяется Т раз.
Реализация.
Прежде чем мы углубимся в реализацию, остановимся на минуту, чтобы подумать о типе сигнатуры слоя ROI.
Он принимает два тензора:
- Пакет (batch) изображений. Чтобы иметь возможность обрабатывать их вместе, все изображения должны иметь одинаковые размеры. Результирующая форма тензора будет (batch_size, img_width, img_height, n_channels), где batch_size- размер пакета изображений, img_width — ширина изображений, img_height — высота изображений, n_channels — количество каналов в изображении.
- Пакет (batch) кандидатов ROI. Если мы хотим объединить их в тензор, количество областей-кандидатов должно быть фиксированным для каждого изображения. Поскольку каждый ограничивающий прямоугольник должен быть указан с 4 координатами, форма этого тензора будет (batch_size, n_rois, 4), где batch_size — размер пакета кандидатов ROI, n_rois — количество кандидатов ROI.
На выходе должен быть:
- Список эмбеддингов для каждого изображения с кодификацией областей, определеннных каждой ROI. Соответствующая форма должна быть (batch_size, n_rois, pooled_width, pooled_height, n_channels). batch_size- размер пакета изображений, n_rois — количество кандидатов ROI, pooled_width — ширина обьединных изображений, pooled_height— высота обьединенных изображений, n_channels — количество каналов в изображении.
Код в Keras
Keras позволяет нам легко реализовывать пользовательские слои посредством наследования базового класса Layer.
В документации tf.keras рекомендуется реализовать методы init, build и call для нашего самодельного слоя. Однако, поскольку целью функции build является добавление весов слоя, а наш слой не имеет весов, нам не нужно переопределять этот метод. Мы также реализуем удобный метод compute_output_shape.
Мы будем писать код для каждой части отдельно, а в конце статьи объединим все куски.
def __init__(self, pooled_height, pooled_width, **kwargs):
self.pooled_height = pooled_height
self.pooled_width = pooled_width
super(ROIPoolingLayer, self).__init__(**kwargs)Конструктор класса довольно прост для понимания. Нам нужно указать целевую высоту и ширину эмбеддингов, которые мы создаём. В последней строке конструктора мы вызываем родительский конструктор для инициализации остальных атрибутов класса.
def compute_output_shape(self, input_shape):
""" Returns the shape of the ROI Layer output
"""
feature_map_shape, rois_shape = input_shape
assert feature_map_shape[0] == rois_shape[0]
batch_size = feature_map_shape[0]
n_rois = rois_shape[1]
n_channels = feature_map_shape[3]
return (batch_size, n_rois, self.pooled_height,
self.pooled_width, n_channels)compute_output_shape — это просто полезная служебная функция, которая скажет нам, каким будет выход слоя для определенного ввода.
Далее мы должны реализовать вызов (call). Функция вызова — это место, где живет логика слоя. Эта функция должна принимать в качестве входных данных два тензора, которые содержат входные данные для слоя ROI Pooling, и выводить тензор с эмбеддингами.
Прежде чем реализовать это, нам нужно реализовать более простую функцию, которая будет брать одно изображение и одну ROI и возвращать соответствующий эмбеддинг.
Давайте сделаем это шаг за шагом.
@staticmethod
def _pool_roi(feature_map, roi, pooled_height, pooled_width):
""" Applies ROI Pooling to a single image and a single ROI
"""# Compute the region of interest
feature_map_height = int(feature_map.shape[0])
feature_map_width = int(feature_map.shape[1])
h_start = tf.cast(feature_map_height * roi[0], 'int32')
w_start = tf.cast(feature_map_width * roi[1], 'int32')
h_end = tf.cast(feature_map_height * roi[2], 'int32')
w_end = tf.cast(feature_map_width * roi[3], 'int32')
region = feature_map[h_start:h_end, w_start:w_end, :]
...Первые шесть строк функции вычисляют, где интересующая область начинается и заканчивается в изображении.
Мы выбрали в качестве соглашения, что координаты каждой ROI должны быть указаны в относительных величинах, как числа между 0 и 1. Конкретно, каждая ROI определяется 4-мерным тензором, содержащим четыре относительные координаты (x_min, y_min, x_max, y_max ).
Мы могли бы решить идентифицировать координаты каждой ROI в абсолютных значениях, но это, как правило, хуже: общей практикой считается варинт с пропусканимем входного изображения через некоторые свертки, которые изменяют размеры изображения, прежде чем подавать его в слой ROI Pooling, что заставит нас отслеживать, как изменяются размеры изображения, чтобы правильно масштабировать ограничивающие рамки ROI.
Седьмая строка просто обрезает изображение до интересующей области с помощью удобного синтаксиса тензорных срезов, который предоставляет нам TensorFlow.
...
# Divide the region into non overlapping areas
region_height = h_end - h_start
region_width = w_end - w_start
h_step = tf.cast(region_height / pooled_height, 'int32')
w_step = tf.cast(region_width / pooled_width , 'int32')
areas = [[(
i*h_step,
j*w_step,
(i+1)*h_step if i+1 < pooled_height else region_height,
(j+1)*w_step if j+1 < pooled_width else region_width
)
for j in range(pooled_width)]
for i in range(pooled_height)]
...В следующих четырех строках мы вычисляем размеры каждой области в ROI, которые будут объединены.
После этого мы создаем 2D массив тензоров, где каждый компонент является кортежем, указывающим координаты начала и конца каждой из областей, в которых мы собираемся взять максимум.
Код, который генерирует сетку координат сектора, кажется слишком сложным, но обратите внимание, что если мы просто разделим ROI на области с размерами (region_height // pooled_height, region_width // pooled_width), то будут некоторые пиксели ROI, которые не попадают ни в один из секторов.
В результате получается 2D список ограничивающих рамок, и мы переходим к следующей части.
...
# Take the maximum of each area and stack the result
def pool_area(x):
return tf.math.reduce_max(region[x[0]:x[2],x[1]:x[3],:], axis=[0,1])
pooled_features = tf.stack([[pool_area(x) for x in row] for row in areas])
return pooled_featuresЭти строки выше делают всю магию. Мы определяем вспомогательную функцию pool_area, которая принимает в качестве входных данных ограничивающую рамку, указанную кортежами, подобными тем, которые мы только что создали, и выводит максимум каждого канала в области.
Мы отображаем pool_area на каждую область, которую мы объявили, используя list comprehension .
К этому моменту мы возвращаем тензор формы (pooled_height, pooled_width, n_channels), содержащий результат пуллинга одной RoI одного изображения.
Следующий шаг — объединение множества RoI на одном изображении. Это легко реализовать с использованием вспомогательной функции и tf.map_fn для получения тензора размерами (n_rois, pooled_height, pooled_width, n_channels).
@staticmethod
def _pool_rois(feature_map, rois, pooled_height, pooled_width):
""" Applies ROI pooling for a single image and varios ROIs
"""
def curried_pool_roi(roi):
return ROIPoolingLayer._pool_roi(feature_map, roi,
pooled_height, pooled_width)
pooled_areas = tf.map_fn(curried_pool_roi, rois, dtype=tf.float32)
return pooled_areasНаконец, нам нужно реализовать итерацию на уровне батча. Если мы передадим в tf.map_fn последовательность тензоров (например, наш ввод x), то под капотом этой функции позаботились о том, чтобы нам зипанули батч.
def call(self, x):
""" Maps the input tensor of the ROI layer to its output
"""
def curried_pool_rois(x):
return ROIPoolingLayer._pool_rois(x[0], x[1],
self.pooled_height,
self.pooled_width)
pooled_areas = tf.map_fn(curried_pool_rois, x, dtype=tf.float32)
return pooled_areasОбратите внимание, что мы должны указывать параметр dtype для tf.map_fn каждый раз, когда ожидаемый вывод не соответствует типу данных его ввода. Как правило, рекомендуется указывать его как можно чаще, чтобы четко указать, как типы изменяются в нашем графе вычислений Tensorflow.
Давайте сложим все вместе:
import tensorflow as tf
from tensorflow.keras.layers import Layer
class ROIPoolingLayer(Layer):
""" Implements Region Of Interest Max Pooling
for channel-first images and relative bounding box coordinates
# Constructor parameters
pooled_height, pooled_width (int) --
specify height and width of layer outputs
Shape of inputs
[(batch_size, pooled_height, pooled_width, n_channels),
(batch_size, num_rois, 4)]
Shape of output
(batch_size, num_rois, pooled_height, pooled_width, n_channels)
"""
def __init__(self, pooled_height, pooled_width, **kwargs):
self.pooled_height = pooled_height
self.pooled_width = pooled_width
super(ROIPoolingLayer, self).__init__(**kwargs)
def compute_output_shape(self, input_shape):
""" Returns the shape of the ROI Layer output
"""
feature_map_shape, rois_shape = input_shape
assert feature_map_shape[0] == rois_shape[0]
batch_size = feature_map_shape[0]
n_rois = rois_shape[1]
n_channels = feature_map_shape[3]
return (batch_size, n_rois, self.pooled_height,
self.pooled_width, n_channels)
def call(self, x):
""" Maps the input tensor of the ROI layer to its output
# Parameters
x[0] -- Convolutional feature map tensor,
shape (batch_size, pooled_height, pooled_width, n_channels)
x[1] -- Tensor of region of interests from candidate bounding boxes,
shape (batch_size, num_rois, 4)
Each region of interest is defined by four relative
coordinates (x_min, y_min, x_max, y_max) between 0 and 1
# Output
pooled_areas -- Tensor with the pooled region of interest, shape
(batch_size, num_rois, pooled_height, pooled_width, n_channels)
"""
def curried_pool_rois(x):
return ROIPoolingLayer._pool_rois(x[0], x[1],
self.pooled_height,
self.pooled_width)
pooled_areas = tf.map_fn(curried_pool_rois, x, dtype=tf.float32)
return pooled_areas
@staticmethod
def _pool_rois(feature_map, rois, pooled_height, pooled_width):
""" Applies ROI pooling for a single image and varios ROIs
"""
def curried_pool_roi(roi):
return ROIPoolingLayer._pool_roi(feature_map, roi,
pooled_height, pooled_width)
pooled_areas = tf.map_fn(curried_pool_roi, rois, dtype=tf.float32)
return pooled_areas
@staticmethod
def _pool_roi(feature_map, roi, pooled_height, pooled_width):
""" Applies ROI pooling to a single image and a single region of interest
"""
# Compute the region of interest
feature_map_height = int(feature_map.shape[0])
feature_map_width = int(feature_map.shape[1])
h_start = tf.cast(feature_map_height * roi[0], 'int32')
w_start = tf.cast(feature_map_width * roi[1], 'int32')
h_end = tf.cast(feature_map_height * roi[2], 'int32')
w_end = tf.cast(feature_map_width * roi[3], 'int32')
region = feature_map[h_start:h_end, w_start:w_end, :]
# Divide the region into non overlapping areas
region_height = h_end - h_start
region_width = w_end - w_start
h_step = tf.cast( region_height / pooled_height, 'int32')
w_step = tf.cast( region_width / pooled_width , 'int32')
areas = [[(
i*h_step,
j*w_step,
(i+1)*h_step if i+1 < pooled_height else region_height,
(j+1)*w_step if j+1 < pooled_width else region_width
)
for j in range(pooled_width)]
for i in range(pooled_height)]
# take the maximum of each area and stack the result
def pool_area(x):
return tf.math.reduce_max(region[x[0]:x[2], x[1]:x[3], :], axis=[0,1])
pooled_features = tf.stack([[pool_area(x) for x in row] for row in areas])
return pooled_featuresДавайте проверим нашу реализацию! Мы собираемся предположить, что 1-канальное изображение размером 100x200, и мы извлечем 2 RoI, используя патчи для пуллинга размером 7x3. Изображения могут иметь регионы, классифицированные максимум в 4 метках. Пример карты призноков — все 1, но одно значение 50 помещено в точку (высота-1, ширина-3).
import numpy as np# Define parameters
batch_size = 1
img_height = 200
img_width = 100
n_channels = 1
n_rois = 2
pooled_height = 3
pooled_width = 7# Create feature map input
feature_maps_shape = (batch_size, img_height, img_width, n_channels)
feature_maps_tf = tf.placeholder(tf.float32, shape=feature_maps_shape)
feature_maps_np = np.ones(feature_maps_tf.shape, dtype='float32')
feature_maps_np[0, img_height-1, img_width-3, 0] = 50
print(f"feature_maps_np.shape = {feature_maps_np.shape}")# Create batch size
roiss_tf = tf.placeholder(tf.float32, shape=(batch_size, n_rois, 4))
roiss_np = np.asarray([[[0.5,0.2,0.7,0.4], [0.0,0.0,1.0,1.0]]], dtype='float32')
print(f"roiss_np.shape = {roiss_np.shape}")# Create layer
roi_layer = ROIPoolingLayer(pooled_height, pooled_width)
pooled_features = roi_layer([feature_maps_tf, roiss_tf])
print(f"output shape of layer call = {pooled_features.shape}")# Run tensorflow session
with tf.Session() as session:
result = session.run(pooled_features,
feed_dict={feature_maps_tf:feature_maps_np,
roiss_tf:roiss_np})
print(f"result.shape = {result.shape}")
print(f"first roi embedding=\n{result[0,0,:,:,0]}")
print(f"second roi embedding=\n{result[0,1,:,:,0]}")Вышеуказанные строки определяют тестовый вход для слоя, строят соответствующие тензоры и запускают сеанс TensorFlow, в ходе которого мы можем проверить работу алгоритма.
Запуск скрипта приведет к следующему выводу:
feature_maps_np.shape = (1, 200, 100, 1)
roiss_np.shape = (1, 2, 4)
output shape of layer call = (1, 2, 3, 7, 1)
result.shape = (1, 2, 3, 7, 1)
first roi embedding=
[[1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1.]]
second roi embedding=
[[ 1. 1. 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1. 1. 50.]]Мы можем проверить, что размер тензорна соответствуют нашим ожидаемым результатам. Полученные эмбеддинги — все 1, кроме той области, где мы ввели значение 50.
Кажется, это работает!
Вывод
И это все на сегодня, ребята!
Сегодня мы узнали, что делает ROI Pooling слой и как мы можем использовать его для реализации внимания (attention). Кроме того, мы узнали, как расширить Keras для реализации пользовательских слоёв без весов, и дали реализацию вышеупомянутого ROI Pooling слоя.
Я надеюсь, что это было полезно для вас, не забудьте поделиться статьей и оставить комментарий, если это было!
Спасибо Ari Brill, Tjark Miener и Bryan Kim за отзывы о статье.
Ссылки
- Ross Girshick. Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Kota Hara, Ming-Yu Liu, Oncel Tuzel, Amir-massoud Farahmand. Attentional Network for Visual Object Detection. 2017.