
Понимаем и создаём
Хорошие новости перед статьей: высоких математических скиллов для прочтения и (надеюсь!) понимания не требуется.
Дисклеймер: кодовая часть данной статьи, как и предыдущей, является адаптированным, дополненным и протестированным переводом. Я благодарна автору, потому что это один из первых моих опытов в коде, после которого меня поперло ещё больше. Надеюсь, что на вас моя адаптация подействует так же!
Итак, поехали!
Структура такая:
- Что такое цепь Маркова?
- Пример работы цепочки
- Матрица переходов
- Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных
Что такое цепь Маркова?
Цепь Маркова — инструмент из теории случайных процессов, состоящий из последовательности n количества состояний. Связи между узлами (значениями) цепочки при этом создаются, только если состояния стоят строго рядом друг с другом.
Держа в голове жирношрифтовое слово только, выведем свойство цепи Маркова:
Вероятность наступления некоторого нового состояния в цепочке зависит только от настоящего состояния и математически не учитывает опыт прошлых состояний => Марковская цепь — это цепь без памяти.
Иначе говоря, новое значение всегда пляшет от того, которое его непосредственно держит за ручку.
Пример работы цепочки
Как и автор статьи, из которой позаимствована кодовая реализация, возьмем рандомную последовательность слов.
Старт — искусственная — шуба — искусственная — еда — искусственная — паста — искусственная — шуба — искусственная — конец
Представим, что на самом деле это великолепный стих и нашей задачей является скопировать стиль автора. (Но делать так, конечно, неэтично)
Как решать?
Первое явное, что хочется сделать — посчитать частотность слов (если бы мы делали это с живым текстом, для начала стоило бы провести нормализацию — привести каждое слово к лемме (словарной форме)).
Старт == 1
Искусственная == 5
Шуба == 2
Паста == 1
Еда == 1
Конец == 1
Держа в голове, что у нас цепочка Маркова, мы можем построить распределение новых слов в зависимости от предыдущих графически:

Словесно:
- состояние шубы, еды и пасты 100% за собой влекут состояние искусственная p = 1
- состояние “искусственная” равновероятно может привести к 4 состояниям, и вероятность прийти к состоянию искусственной шубы выше, чем к трём остальным
- состояние конца никуда не ведет
- состояние «старт» 100% влечет состояние «искусственная»
Выглядит прикольно и логично, но на этом визуальная красота не заканчивается! Мы также можем построить матрицу переходов, и на её основе аппелировать следующей математической справедливостью:

Что на русском означает «сумма ряда вероятностей для некоторого события k, зависимого от i == сумме всех значений вероятностей события k в зависимости от наступления состояния i, где событие k == m+1, а событие i == m (то есть событие k всегда на единицу отличается от i)».
Но для начала поймем, что такое матрица.
Матрица переходов
При работе с цепями Маркова мы имеем дело со стохастический матрицей переходов — совокупностью векторов, внутри которых значения отражают значения вероятностей между градациями.
Да, да, звучит так, как звучит.
Но выглядит не так страшно:

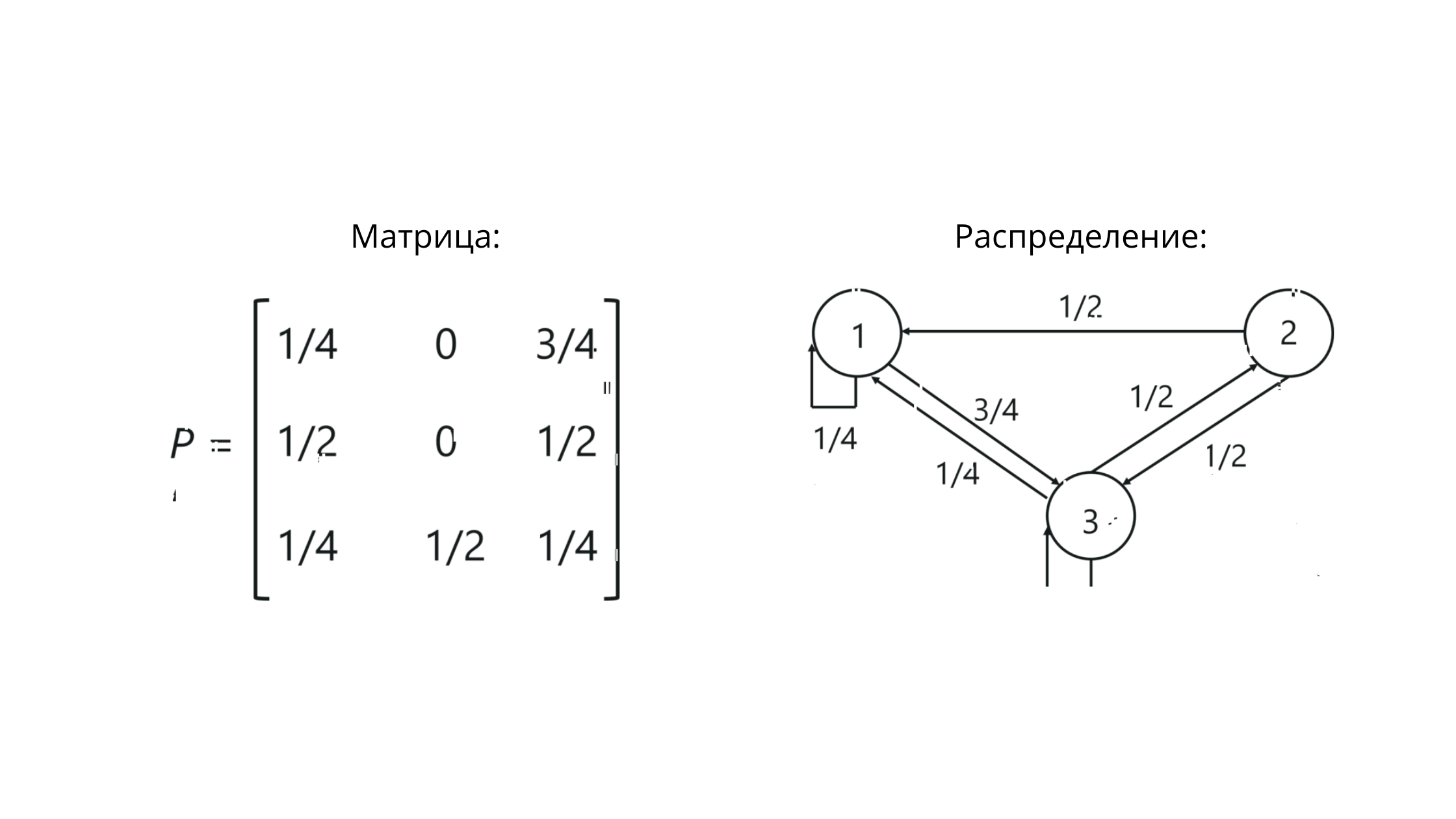
P — это обозначение матрицы. Значения на пересечении столбцов и строк здесь отражают вероятности переходов между состояниями.
Для нашего примера это будет выглядеть как-то так:

Заметьте, что сумма значений в строке == 1. Это говорит о том, что мы правильно всё построили, ведь сумма значений в строке стохастический матрицы должна равняться единице.
Голый пример без искусственных шуб и паст:
Ещё более голый пример — единичная матрица для:
- случая когда нельзя из А перейти обратно В, а из В — обратно в А[1]
- случая, когда переход из А в В обратно возможен[2]

Респекто. С теорией закончили.
Используем Пайтон.
Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных
Шаг 1
Импортируем релевантный пакет для работы и достаём данные.
import numpy as np
data = open('/Users/sad__sabrina/Desktop/док1.txt', encoding='utf8').read()
print(data)
В теории вероятностей и смежных областях, марковский процесс , названный в честь русского математика Андрея Маркова , является случайным процессом , который удовлетворяет свойство Маркова (иногда характеризуются как « memorylessness »). Грубо говоря, процесс удовлетворяет свойству Маркова , если можно делать прогнозы на будущее процесса , основанного исключительно на его нынешнем состоянии точно так же , как можно было бы знать всю историю процесса, а значит , независимо от такой истории; т.е., условно на нынешнее состояние системы, ее прошлое и будущее государства независимы .
Не заостряйте внимание на структуре текста, но обратите внимание на кодировку utf8. Это важно для прочтения данных.
Шаг 2
Разделим данные на слова.
ind_words = data.split()
print(ind_words)
['\ufeffВ', 'теории', 'вероятностей', 'и', 'смежных', 'областях,', 'марковский', 'процесс', ',', 'названный', 'в', 'честь', 'русского', 'математика', 'Андрея', 'Маркова', ',', 'является', 'случайным', 'процессом', ',', 'который', 'удовлетворяет', 'свойство', 'Маркова', '(иногда', 'характеризуются', 'как', '«', 'memorylessness', '»).', 'Грубо', 'говоря,', 'процесс', 'удовлетворяет', 'свойству', 'Маркова', ',', 'если', 'можно', 'делать', 'прогнозы', 'на', 'будущее', 'процесса', ',', 'основанного', 'исключительно', 'на', 'его', 'нынешнем', 'состоянии', 'точно', 'так', 'же', ',', 'как', 'можно', 'было', 'бы', 'знать', 'всю', 'историю', 'процесса,', 'а', 'значит', ',', 'независимо', 'от', 'такой', 'истории;', 'т.е.,', 'условно', 'на', 'нынешнее', 'состояние', 'системы,', 'ее', 'прошлое', 'и', 'будущее', 'государства', 'независимы', '.']Шаг 3
Создадим функцию для связки пар слов.
def make_pairs(ind_words):
for i in range(len(ind_words) - 1):
yield (ind_words[i], ind_words[i + 1])
pair = make_pairs(ind_words)Главный нюанс функции в применении оператора yield(). Он помогает нам удовлетворить критерию цепочки Маркова — критерию хранения без памяти. Благодаря yield, наша функция будет создавать новые пары в процессе итераций(повторений), а не хранить все.
Тут может возникнуть непонимание, ведь одно слово может переходить в разные. Это мы решим, создав словарь для нашей функции.
Шаг 4
word_dict = {}
for word_1, word_2 in pair:
if word_1 in word_dict.keys():
word_dict[word_1].append(word_2)
else:
word_dict[word_1] = [word_2]Здесь:
- если у нас в словаре уже есть запись о первом слове в паре, функция добавляет следующее потенциальное значение в список.
- иначе: создаётся новая запись.
Шаг 5
Рандомно выберем первое слово и, чтобы слово было действительно случайным, зададим условие while при помощи строкового метода islower(), который удовлетворяет True в случае, когда в строке значения из букв нижнего регистра, допуская наличие цифр или символов.
При этом зададим количество слов 20.
first_word = np.random.choice(ind_words)
while first_word.islower():
chain = [first_word]
n_words = 20
first_word = np.random.choice(ind_words)
for i in range(n_words):
chain.append(np.random.choice(word_dict[chain[-1]]))Шаг 6
Запустим нашу рандомную штуку!
print(' '.join(chain))
независимо от такой истории; т.е., условно на нынешнее состояние системы, ее прошлое и смежных областях, марковский процесс удовлетворяет свойству Маркова (иногдаФункция join() — функция для работы со строками. В скобках мы указали разделитель для значений в строке(пробел).
А текст… ну, звучит по-машинному и почти логично.
P.S. Как вы могли заметить, цепи Маркова удобны в лингвистике, но их применение выходит за рамки обработки естественного языка. Здесь и здесь вы можете ознакомиться с применением цепей в других задачах.
P.P.S. Если моя практика кода вышла непонятной для вас, прилагаю исходную статью. Обязательно примените код на практике — чувство, когда оно «побежало и сгенерировало» заряжает!
Жду ваших мнений и буду рада конструктивным замечаниям по статье!


DanInSpace
Ухх, после прочтения статьи меня тоже "поперло". Спасибо вам за новые идеи и мотивацию. Ни за что бы не понял что это перевод
anonymous Автор
Благодарю за обратную связь!