
В этой переведенной статье ее автор, Rebecca Vickery, делится интересными функциями scikit-learn. Оригинал опубликован в блоге towardsdatascience.com.

Фото с сайта Unsplash. Автор: Sasha • Stories
Scikit-learn является одной из наиболее широко используемых библиотек Python для машинного обучения. Ее простой стандартный интерфейс позволяет производить препроцессинг данных, а также заниматься обучением, оптимизацией и оценкой модели.
Этот проект, разработанный Дэвидом Курнапо (David Cournapeau), появился на свет в рамках программы Google Summer of Code и был выпущен в 2010 году. С момента своего создания библиотека превратилась в инфраструктуру с широкими возможностями для создания моделей машинного обучения. Новые функции позволяют решать еще больше задач и повышают удобство использования. В этой статье я расскажу о десяти самых интересных функциях, о которых вы могли не знать.
В API библиотеки scikit-learn можно найти встроенные датасеты, содержащие как сгенерированные, так и реально существующие данные. Ими можно воспользоваться, набрав всего одну строку кода. Такие данные крайне полезны, если вы только учитесь или просто хотите что-то быстро протестировать.
Также с помощью специального инструмента вы сможете сами сгенерировать синтетические данные для задач регрессии
Каждый метод позволяет получить данные, уже разбитые на Х (признаки) и Y (целевая переменная), чтобы их можно было использовать непосредственно для обучения модели.
Если вы хотите получить доступ к разнообразным общедоступным датасетам прямо через scikit-learn, обратите внимание на удобную функцию, которая позволяет импортировать данные напрямую с сайта openml.org. На этом сайте хранится более 21 000 различных датасетов, которые можно использовать в проектах машинного обучения.
При создании модели машинного обучения для какого-либо проекта разумно сначала создать baseline модель. Она представляет собой простейшую (dummy) модель, которая всегда предсказывает наиболее часто встречающийся класс. Так вы получите контрольные данные для сравнительной оценки построенной вами более сложной модели. К тому же вы сможете быть уверены в качестве ее работы, например, в том, что она выдает не просто набор случайно подобранных данных.
В библиотеке scikit-learn есть
В библиотеке scikit-learn есть встроенный API для визуализации, который позволяет визуализировать работу модели, не импортируя какие-либо другие библиотеки. В нем представлены следующие опции: графики зависимостей, матрица ошибок, кривые ROC и Precision-Recall.
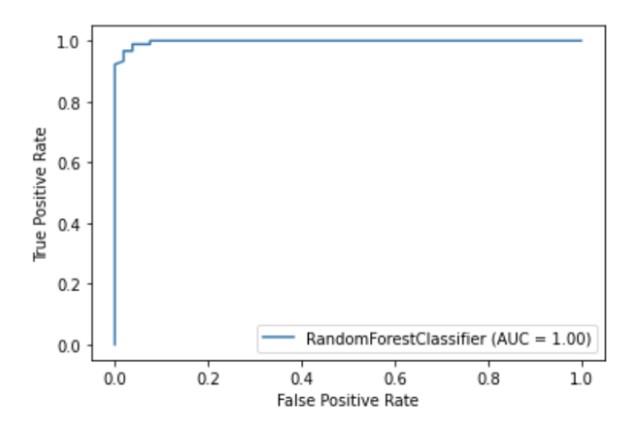
Иллюстрация автора
Один из способов улучшить качество модели — это использовать в обучении только самые полезные признаки или удалять малоинформативные. Этот процесс называется отбором признаков.
В scikit-learn есть ряд методов для проведения отбора признаков, один из них —
Помимо возможности использовать огромный список алгоритмов для машинного обучения, scikit-learn также предоставляет ряд функций для препроцессинга и преобразования данных. Чтобы обеспечить воспроизводимость и доступность в процессе машинного обучения, в scikit-learn были созданы пайплайны, которые позволяют объединять различные шаги препроцессинга и этап обучения модели.
В пайплайне хранятся все этапы рабочего процесса в виде единого объекта, который можно вызвать методами fit и predict. Когда вы запускаете метод fit на объекте пайплайна, автоматически выполняются шаги препроцессинга и обучения модели.
Многие датасеты содержат разные типы признаков, для препроцессинга которых потребуется несколько различных этапов. Например, вы можете столкнуться с сочетанием категориальных и числовых данных, и, возможно, захотите масштабировать колонки с числовыми данными и преобразовать категориальные признаки в числовые с помощью one-hot encoding.
Пайплайн scikit-learn снабжен функцией ColumnTransformer, которая позволяет без труда обозначить наиболее подходящий способ препроцессинга для конкретных колонок через индексацию или путем указания наименования колонок.
Часто пайплайны становятся довольно сложными, особенно при работе с реальными данными. Поэтому весьма удобно, что с помощью scikit-learn можно вывести HTML-схему шагов вашего пайплайна.

Иллюстрация автора
Функция
Существует множество сторонних библиотек, которые совместимы с scikit-learn и расширяют ее функционал.
Например, библиотека Category Encoders, которая предоставляет более широкий выбор методов препроцессинга категориальных признаков, или библиотека ELI5 — для более подробной интерпретации модели.
Обоими ресурсами также можно воспользоваться напрямую через пайплайн scikit-learn.
Спасибо за внимание!
Фото с сайта Unsplash. Автор: Sasha • Stories
Scikit-learn является одной из наиболее широко используемых библиотек Python для машинного обучения. Ее простой стандартный интерфейс позволяет производить препроцессинг данных, а также заниматься обучением, оптимизацией и оценкой модели.
Этот проект, разработанный Дэвидом Курнапо (David Cournapeau), появился на свет в рамках программы Google Summer of Code и был выпущен в 2010 году. С момента своего создания библиотека превратилась в инфраструктуру с широкими возможностями для создания моделей машинного обучения. Новые функции позволяют решать еще больше задач и повышают удобство использования. В этой статье я расскажу о десяти самых интересных функциях, о которых вы могли не знать.
1. Встроенные датасеты
В API библиотеки scikit-learn можно найти встроенные датасеты, содержащие как сгенерированные, так и реально существующие данные. Ими можно воспользоваться, набрав всего одну строку кода. Такие данные крайне полезны, если вы только учитесь или просто хотите что-то быстро протестировать.
Также с помощью специального инструмента вы сможете сами сгенерировать синтетические данные для задач регрессии
make_regression(), кластеризации make_blobs() и классификации make_classification().Каждый метод позволяет получить данные, уже разбитые на Х (признаки) и Y (целевая переменная), чтобы их можно было использовать непосредственно для обучения модели.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Доступ к сторонним публичным датасетам
Если вы хотите получить доступ к разнообразным общедоступным датасетам прямо через scikit-learn, обратите внимание на удобную функцию, которая позволяет импортировать данные напрямую с сайта openml.org. На этом сайте хранится более 21 000 различных датасетов, которые можно использовать в проектах машинного обучения.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Готовые классификаторы для обучения baseline моделей
При создании модели машинного обучения для какого-либо проекта разумно сначала создать baseline модель. Она представляет собой простейшую (dummy) модель, которая всегда предсказывает наиболее часто встречающийся класс. Так вы получите контрольные данные для сравнительной оценки построенной вами более сложной модели. К тому же вы сможете быть уверены в качестве ее работы, например, в том, что она выдает не просто набор случайно подобранных данных.
В библиотеке scikit-learn есть
DummyClassifier() для задач классификации и DummyRegressor() для работы с регрессией.from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Собственный API для визуализации
В библиотеке scikit-learn есть встроенный API для визуализации, который позволяет визуализировать работу модели, не импортируя какие-либо другие библиотеки. В нем представлены следующие опции: графики зависимостей, матрица ошибок, кривые ROC и Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()Иллюстрация автора
5. Встроенные методы отбора признаков
Один из способов улучшить качество модели — это использовать в обучении только самые полезные признаки или удалять малоинформативные. Этот процесс называется отбором признаков.
В scikit-learn есть ряд методов для проведения отбора признаков, один из них —
SelectPercentile(). Этот метод отбирает Х-процентиль наиболее информативных признаков на основании указанного статистического метода оценки.from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Пайплайны для объединения этапов в процессе машинного обучения
Помимо возможности использовать огромный список алгоритмов для машинного обучения, scikit-learn также предоставляет ряд функций для препроцессинга и преобразования данных. Чтобы обеспечить воспроизводимость и доступность в процессе машинного обучения, в scikit-learn были созданы пайплайны, которые позволяют объединять различные шаги препроцессинга и этап обучения модели.
В пайплайне хранятся все этапы рабочего процесса в виде единого объекта, который можно вызвать методами fit и predict. Когда вы запускаете метод fit на объекте пайплайна, автоматически выполняются шаги препроцессинга и обучения модели.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer, чтобы варьировать методы препроцессинга для различных признаков
Многие датасеты содержат разные типы признаков, для препроцессинга которых потребуется несколько различных этапов. Например, вы можете столкнуться с сочетанием категориальных и числовых данных, и, возможно, захотите масштабировать колонки с числовыми данными и преобразовать категориальные признаки в числовые с помощью one-hot encoding.
Пайплайн scikit-learn снабжен функцией ColumnTransformer, которая позволяет без труда обозначить наиболее подходящий способ препроцессинга для конкретных колонок через индексацию или путем указания наименования колонок.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Легкое получение HTML-изображения вашего пайплайна
Часто пайплайны становятся довольно сложными, особенно при работе с реальными данными. Поэтому весьма удобно, что с помощью scikit-learn можно вывести HTML-схему шагов вашего пайплайна.
from sklearn import set_config
set_config(display='diagram')
lrИллюстрация автора
9. Функция построения графика для визуализации деревьев решений
Функция
plot_tree() позволяет создать схему шагов, присутствующих в модели дерева принятия решений.import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Множество сторонних библиотек, расширяющих функции scikit-learn
Существует множество сторонних библиотек, которые совместимы с scikit-learn и расширяют ее функционал.
Например, библиотека Category Encoders, которая предоставляет более широкий выбор методов препроцессинга категориальных признаков, или библиотека ELI5 — для более подробной интерпретации модели.
Обоими ресурсами также можно воспользоваться напрямую через пайплайн scikit-learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Спасибо за внимание!