
Это репост статьи, опубликованной на сайте dou.ua. В статье Анна Пономарева, Game Analyst в Plarium Kharkiv, делится личными наработками по проведению A/B-тестирования: описывает каждый шаг, освещает сложности и ловушки, с которыми можно столкнуться, и рассказывает об опыте их решения.

В каждое изменение в игре команда вкладывает много труда, сил и ресурсов: иногда разработка новой функциональности или уровня занимает несколько месяцев. Задача аналитика — минимизировать риски от внедрения подобных изменений и помочь команде принять верное решение о дальнейшем развитии проекта.
При анализе решений важно руководствоваться статистически значимыми данными, которые соответствуют предпочтениям аудитории, а не интуитивным предположениям. Получить такие данные и оценить их помогает А/В-тестирование.
По поисковому запросу «А/В-тестирование» или «сплит-тестирование» большинство источников предлагает несколько «простых» шагов для успешного проведения теста. В моей стратегии таких шагов шесть.
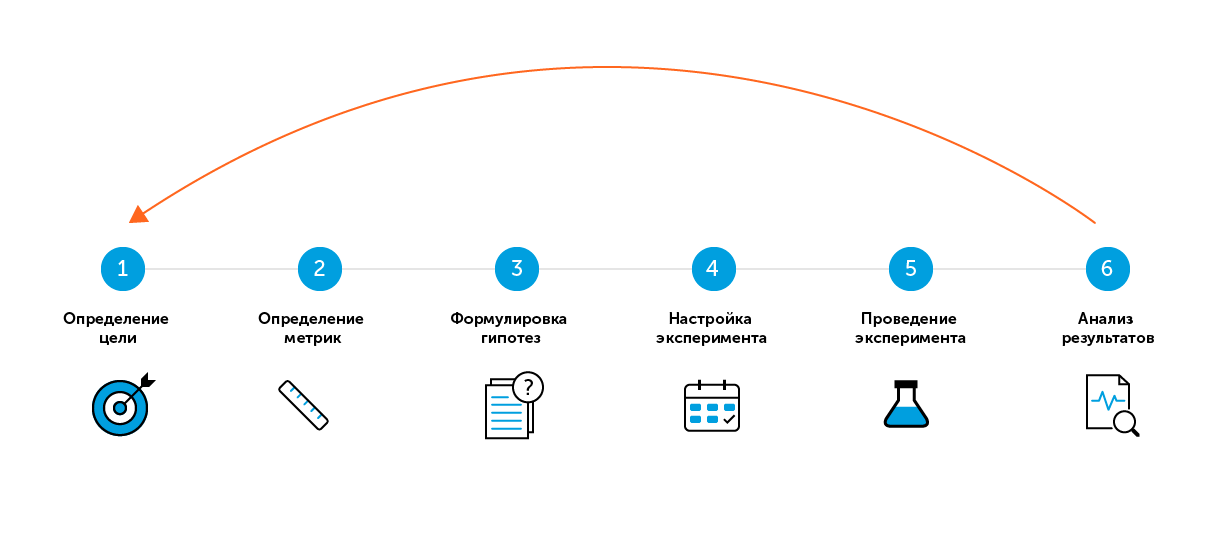
На первый взгляд всё просто:
На практике сложнее. Чтобы команда внедрила лучшее решение, мне как аналитику нужно ответить, насколько я уверена в результатах теста. Разберемся со сложностями пошагово.
C одной стороны, мы можем протестировать всё, что приходит в голову каждому члену команды, — от цвета кнопки до уровней сложности игры. Техническая возможность проводить сплит-тесты закладывается в наши продукты еще на этапе проектирования.
С другой — все предложения по улучшению игры важно приоритизировать по уровню эффекта, оказываемого на целевую метрику. Поэтому сначала составляем план запуска сплит-тестирования от наиболее приоритетной гипотезы до наименее.
Мы стараемся не проводить несколько А/В-тестов параллельно, чтобы точно понимать, какая из новых функциональностей повлияла на целевую метрику. Кажется, что при такой стратегии потребуется больше времени на проверку всех гипотез. Но приоритизация помогает отсечь неперспективные гипотезы еще на этапе планирования.
Мы получаем данные, максимально отражающие эффект от конкретных изменений, и не тратим время на постановку тестов с сомнительным эффектом.
План запуска обязательно обсуждаем с командой, поскольку на разных этапах жизненного цикла продукта акцент интереса смещается. В начале проекта это обычно Retention D1 — доля игроков, которые вернулись в игру на следующий день после ее установки. На более поздних этапах это могут быть метрики удержания или монетизации: Conversion, ARPU и другие.
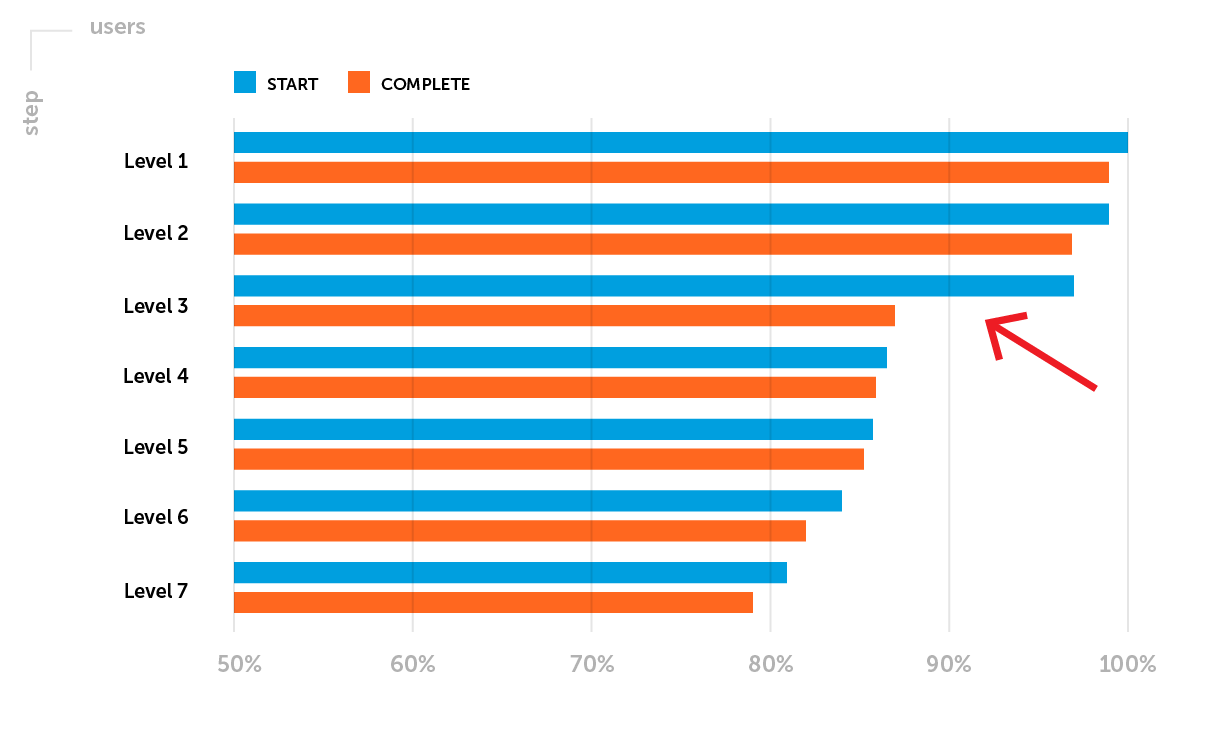
Пример. После выхода проекта в софтлонч особого внимания требуют метрики удержания. На этом этапе выделим одну из возможных проблем: Retention D1 не выходит на уровень бенчмарок компании для конкретного жанра игры. Необходимо проанализировать воронку прохождения первых уровней. Допустим, вы заметили большой дроп игроков между стартом и комплитом 3-го уровня — низкий Completion Rate 3-го уровня.
Цель планируемого А/В-теста: повысить Retention D1 за счет увеличения доли игроков, которые успешно завершили 3-й уровень.
До запуска А/В-теста определяем отслеживаемый параметр — выбираем метрику, изменения которой покажут, является ли новая функциональность игры более успешной, чем изначальная.
Метрики бывают двух типов:
Тип метрики влияет на выбор метода и инструментов оценки значимости результатов.
Вероятно, тестируемая функциональность повлияет не на одну целевую, а на ряд метрик. Поэтому мы смотрим на изменения в целом, но не пытаемся найти «хоть что-то», когда статистической значимости при оценке целевой метрики нет.
Согласно цели из первого шага, для предстоящего А/В-теста будем оценивать Completion Rate 3-го уровня — качественную метрику.
Каждый А/В-тест проверяет одну общую гипотезу, которая формулируется перед запуском. Отвечаем на вопрос: какие изменения ожидаем в тестовой группе? Формулировка обычно выглядит так:
«Ожидаем, что (воздействие) вызовет (изменение)»
Статистические методы работают от обратного — мы не можем с их помощью доказать, что гипотеза верна. Поэтому после формулирования общей гипотезы определяют две статистические. Они помогают понять: наблюдаемая разница между контрольной группой A и тестовой группой B — это случайность или результат изменений.
В нашем примере:
На этом этапе, кроме формулирования гипотезы, необходимо оценить ожидаемый эффект.
Гипотеза: «Ожидаем, что уменьшение сложности 3-го уровня вызовет рост Completion Rate 3-го уровня с 85% до 95%, то есть более чем на 11%».
(95%-85%)/85% = 0,117 => 11,7%
В этом примере при определении ожидаемого Completion Rate 3-го уровня мы стремимся приблизить его к среднему значению Completion Rate начальных уровней.
1. Определяем параметры для А/В-групп перед запуском эксперимента: на какую аудиторию запускаем тест, на какую долю игроков, какие настройки устанавливаем в каждой группе.
2. Проверяем репрезентативность выборки в целом и однородность выборок в группах. Можно предварительно запустить А/А-тест для оценки этих параметров — тест, в котором тестовая и контрольная группы имеют одинаковую функциональность. А/А-тест помогает убедиться, что в обеих группах целевые метрики не имеют статистически значимого различия. Если же различия есть, А/В-тест с такими настройками — объемом выборки и уровнем доверия — запускать нельзя.
Выборка не будет идеально репрезентативной, но мы всегда обращаем внимание на структуру пользователей в разрезе их характеристик — новый/старый пользователь, уровень в игре, страна. Всё привязано к цели А/В-теста и оговаривается заранее. Важно, чтобы структура пользователей в каждой группе была условно одинаковая.
Тут потенциально опасны две ловушки:
3. Рассчитываем объем выборки и длительность проведения эксперимента.
Казалось бы, момент прозрачный, принимая во внимание огромный набор онлайн-калькуляторов.
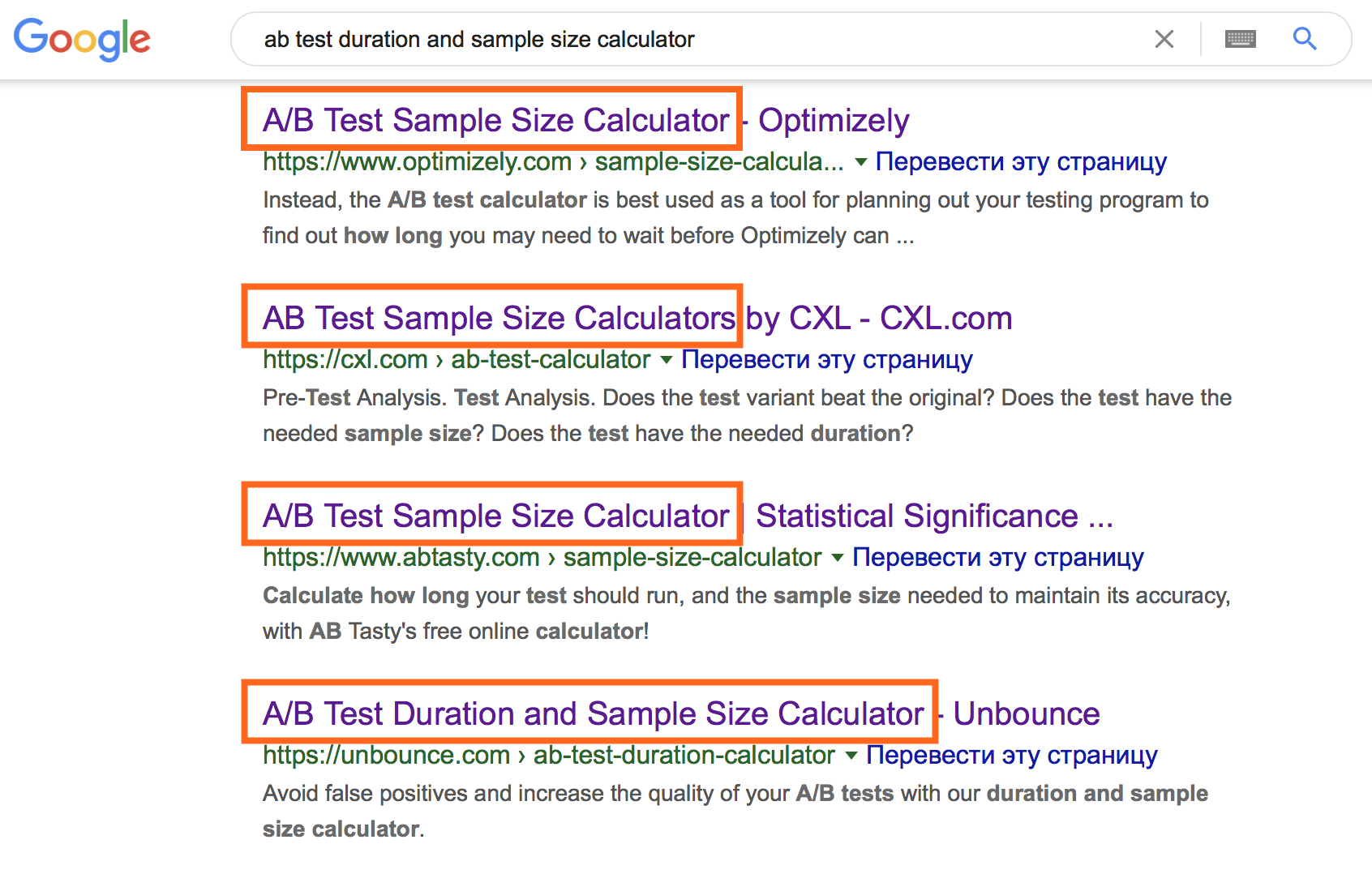
Однако их использование предполагает ввод специфичной начальной информации. Чтобы выбрать соответствующий вариант онлайн-калькулятора, вспомните про типы данных и разберитесь со следующими терминами.
Совокупность этих параметров позволяет рассчитать необходимый объем выборки в каждой группе и длительность теста.
В онлайн-калькуляторе можно «побаловаться» с входными данными, чтобы понять природу их взаимосвязей.
Пример. С помощью калькулятора Optimizely рассчитаем объем выборки для коэффициента конверсии 1%. Учтем, что предполагаемый размер эффекта составит 5% при 95% уровне доверия (показатель рассчитывается как 1-?). Обратите внимание: в интерфейсе этого калькулятора термин Statistical significance используется в значении «Уровень доверия» при уровне значимости 5%.
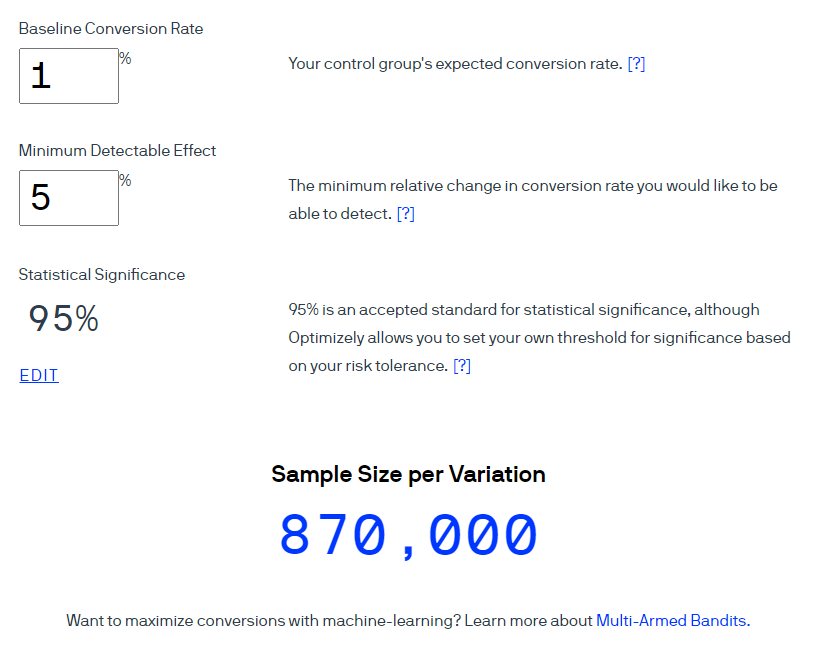
Optimizely утверждает, что в каждую группу должны попасть 870 000 пользователей.
Переводим размер выборки в приблизительную длительность теста — два простых вычисления.
Расчет № 1. Размер выборки ? количество групп в эксперименте = общее количество необходимых пользователей
Расчет № 2. Общее количество необходимых пользователей ? среднее количество пользователей в день = примерное количество дней эксперимента
Если в первую группу требуется 870 000 пользователей, то для теста двух вариантов общее количество пользователей составит 1 740 000. С учетом трафика 1000 игроков в день, тест должен длиться 1740 дней. Такая длительность не оправдана. На этом этапе мы обычно пересматриваем гипотезу, исходные данные и целесообразность проведения теста.
В нашем примере с улучшением 3-го уровня конверсия — это доля тех, кто успешно завершил 3-й уровень. То есть коэффициент конверсии составляет 85%, мы хотим увеличить этот показатель минимум на 11%. При уровне доверия 95% получаем 130 пользователей на группу.

При том же объеме трафика в 1000 пользователей тест, грубо говоря, можно закончить менее чем за день. Этот вывод в корне неправильный, так как не учитывает недельную сезонность. Поведение пользователей отличается в разные дни недели, например, может изменяться по праздникам. И в одних проектах это влияние очень сильное, в других едва заметное. Не во всех проектах и не для всех тестов это необходимое условие, но на проектах, с которыми мне доводилось работать, недельная сезонность в КPI наблюдалась всегда.
Поэтому длительность теста мы округляем до недель, чтобы учесть сезонность. Чаще наш цикл тестирования составляет одну-две недели в зависимости от типа А/В-теста.
После запуска А/В-теста сразу возникает желание посмотреть на результаты, но большинство источников строго-настрого запрещает это делать, чтобы исключить проблему «подглядывания» (peeking problem). Объяснить суть проблемы простыми словами, на мой взгляд, пока ни у кого не получилось. Авторы подобных статей основывают доказательства на оценке вероятностей, различных результатах математического моделирования, которые уводят читателей в зону «сложных математических формул». Основной их вывод — практически неоспоримый факт: не смотрите на данные до того, как наберется требуемая выборка и пройдет требуемое количество дней после запуска теста. В результате проблему «подглядывания» многие интерпретируют неправильно и следуют рекомендациям буквально.
Мы настроили процессы так, чтобы ежедневно видеть актуальные данные для мониторинга KPI проектов. В заранее подготовленных дашбордах следим за ходом эксперимента с самого запуска: проверяем, равномерно ли набираются группы, нет ли критичных проблем после запуска теста, которые могут повлиять на результаты, и так далее.
Главное правило — не делать преждевременных выводов. Все выводы формулируются в соответствии с заложенным дизайном А/В-теста и сводятся в детализированном отчете. Мы мониторим изменения показателя с момента запуска А/В-теста.
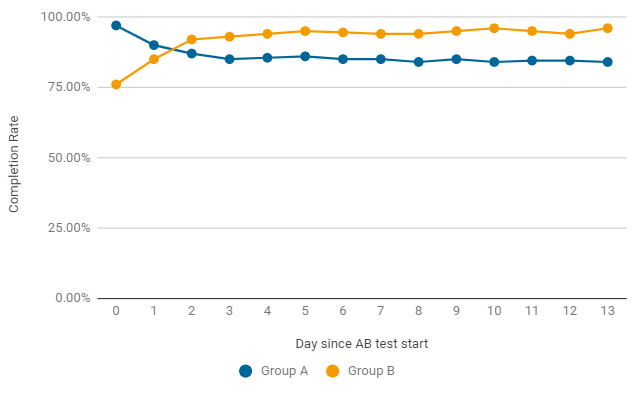
Пример, как в А/В-тесте по дням может меняться Completion Rate. В первые два дня после запуска побеждал вариант игры без изменений (группа А), но это оказалось просто случайностью. Уже после второго дня показатель в группе В приобретает стабильно лучшие результаты. Для завершения тесту нужна не просто статистическая значимость, но и стабильность, поэтому ждем окончания теста.
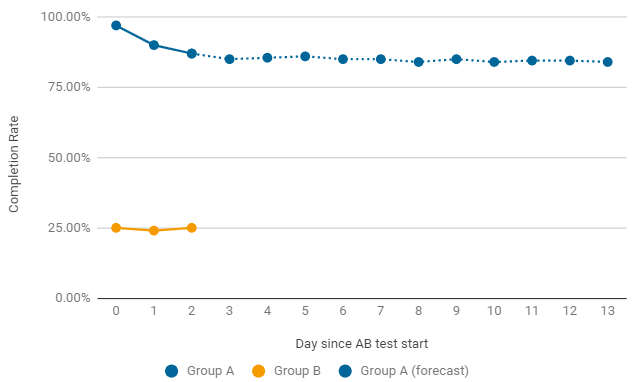
Пример, когда стоит преждевременно завершить А/В-тест. Если после запуска одна из групп дает критично низкие показатели, мы сразу ищем причины такого падения. Самые частые — ошибки в конфигурации и настройках игрового уровня. В таком случае текущий тест отключается преждевременно и запускается новый, с исправлениями.
Расчет ключевых метрик не представляет особой сложности, а вот оценка значимости полученных результатов — отдельная проблема.
Для проверки статистической значимости результатов при оценивании качественных метрик, таких как Retention и Сonvertion, можно использовать онлайн-калькуляторы.
Мой топ-3 онлайн-калькуляторов для таких задач:
Пример. Для анализа подобных А/В-тестов у нас есть дашборд, который отображает всю информацию, необходимую для построения выводов, и автоматически подсвечивает результат со значимым изменением целевого показателя.

Давайте посмотрим, как с помощью калькуляторов построить выводы по данному А/В-тесту.
Исходные данные:
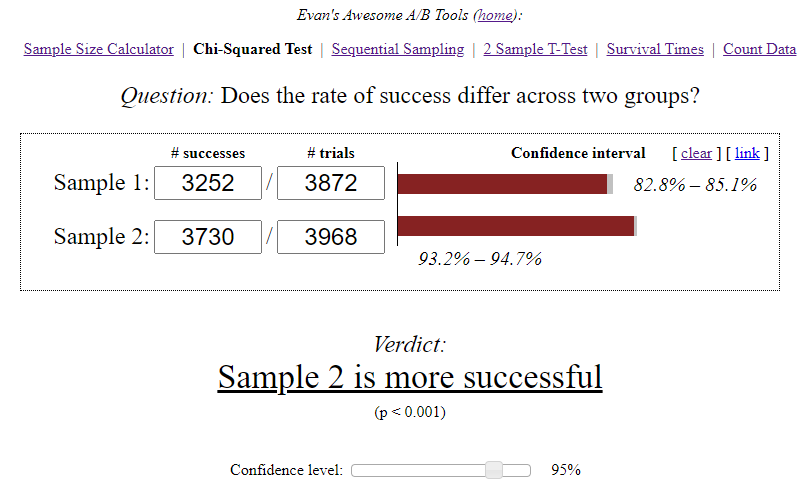
Калькулятор Evan’s Awesome A/B Tools рассчитал для каждого варианта доверительный интервал с учетом объема выборки и выбранного уровня значимости.
Самостоятельные выводы:
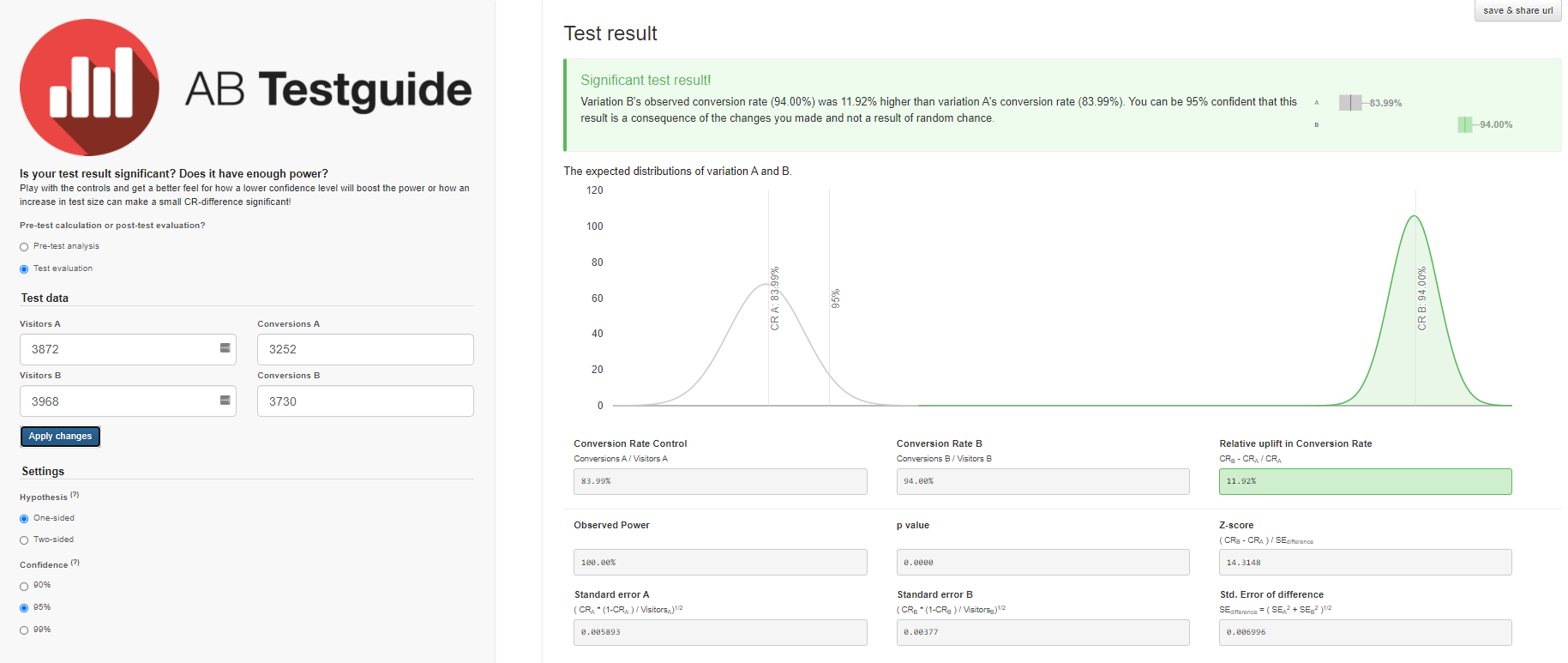
Схожие результаты получим и с калькулятором A/B Testguide. Но здесь уже можно поиграться с настройками, получить графический результат и сформулированные выводы.
Если пугает такое количество настроек, нет желания или потребности разбираться с разнообразием рассчитанных калькулятором данных, можно использовать A/B Testing Calculator от Neilpatel.
В каждом онлайн-калькуляторе заложены свои критерии и алгоритмы, которые могут не учитывать всех особенностей эксперимента. В результате возникают вопросы и сомнения в интерпретации результатов. Кроме того, если целевая метрика количественная — средний чек или средняя длина первой сессии — перечисленные онлайн-калькуляторы уже не применимы и требуются более продвинутые методы оценки.
Я оформляю детальный отчет по каждому А/В-тесту, поэтому подобрала и реализовала подходящие под мои задачи методы и критерии для оценки статистической значимости результатов.
А/В-тест — инструмент, который не дает однозначного ответа на вопрос «Какой вариант лучше?», а лишь позволяет снизить неопределенность на пути к поиску оптимальных решений. При его проведении детали важны на всех этапах подготовки, каждая неточность стоит ресурсов и может негативно повлиять на достоверность результатов. Надеюсь, эта статья была полезной для вас и поможет избежать ошибок при А/В-тестировании.
В каждое изменение в игре команда вкладывает много труда, сил и ресурсов: иногда разработка новой функциональности или уровня занимает несколько месяцев. Задача аналитика — минимизировать риски от внедрения подобных изменений и помочь команде принять верное решение о дальнейшем развитии проекта.
При анализе решений важно руководствоваться статистически значимыми данными, которые соответствуют предпочтениям аудитории, а не интуитивным предположениям. Получить такие данные и оценить их помогает А/В-тестирование.
6 «простых» шагов A/B-тестирования
По поисковому запросу «А/В-тестирование» или «сплит-тестирование» большинство источников предлагает несколько «простых» шагов для успешного проведения теста. В моей стратегии таких шагов шесть.
На первый взгляд всё просто:
- есть группа А, контрольная, без изменений в игре;
- есть группа В, тестовая, с изменениями. Например, добавлена новая функциональность, повышена сложность уровней, изменен туториал;
- запускаем тест и смотрим, у какого варианта показатели лучше.
На практике сложнее. Чтобы команда внедрила лучшее решение, мне как аналитику нужно ответить, насколько я уверена в результатах теста. Разберемся со сложностями пошагово.
Шаг 1. Определяем цель
C одной стороны, мы можем протестировать всё, что приходит в голову каждому члену команды, — от цвета кнопки до уровней сложности игры. Техническая возможность проводить сплит-тесты закладывается в наши продукты еще на этапе проектирования.
С другой — все предложения по улучшению игры важно приоритизировать по уровню эффекта, оказываемого на целевую метрику. Поэтому сначала составляем план запуска сплит-тестирования от наиболее приоритетной гипотезы до наименее.
Мы стараемся не проводить несколько А/В-тестов параллельно, чтобы точно понимать, какая из новых функциональностей повлияла на целевую метрику. Кажется, что при такой стратегии потребуется больше времени на проверку всех гипотез. Но приоритизация помогает отсечь неперспективные гипотезы еще на этапе планирования.
Мы получаем данные, максимально отражающие эффект от конкретных изменений, и не тратим время на постановку тестов с сомнительным эффектом.
План запуска обязательно обсуждаем с командой, поскольку на разных этапах жизненного цикла продукта акцент интереса смещается. В начале проекта это обычно Retention D1 — доля игроков, которые вернулись в игру на следующий день после ее установки. На более поздних этапах это могут быть метрики удержания или монетизации: Conversion, ARPU и другие.
Пример. После выхода проекта в софтлонч особого внимания требуют метрики удержания. На этом этапе выделим одну из возможных проблем: Retention D1 не выходит на уровень бенчмарок компании для конкретного жанра игры. Необходимо проанализировать воронку прохождения первых уровней. Допустим, вы заметили большой дроп игроков между стартом и комплитом 3-го уровня — низкий Completion Rate 3-го уровня.
Цель планируемого А/В-теста: повысить Retention D1 за счет увеличения доли игроков, которые успешно завершили 3-й уровень.
Шаг 2. Определяем метрики
До запуска А/В-теста определяем отслеживаемый параметр — выбираем метрику, изменения которой покажут, является ли новая функциональность игры более успешной, чем изначальная.
Метрики бывают двух типов:
- количественные — средняя продолжительность сессии, величина среднего чека, время прохождения уровня, количество опыта и так далее;
- качественные — Retention, Conversion Rate и прочие.
Тип метрики влияет на выбор метода и инструментов оценки значимости результатов.
Вероятно, тестируемая функциональность повлияет не на одну целевую, а на ряд метрик. Поэтому мы смотрим на изменения в целом, но не пытаемся найти «хоть что-то», когда статистической значимости при оценке целевой метрики нет.
Согласно цели из первого шага, для предстоящего А/В-теста будем оценивать Completion Rate 3-го уровня — качественную метрику.
Шаг 3. Формулируем гипотезу
Каждый А/В-тест проверяет одну общую гипотезу, которая формулируется перед запуском. Отвечаем на вопрос: какие изменения ожидаем в тестовой группе? Формулировка обычно выглядит так:
«Ожидаем, что (воздействие) вызовет (изменение)»
Статистические методы работают от обратного — мы не можем с их помощью доказать, что гипотеза верна. Поэтому после формулирования общей гипотезы определяют две статистические. Они помогают понять: наблюдаемая разница между контрольной группой A и тестовой группой B — это случайность или результат изменений.
В нашем примере:
- Нулевая гипотеза (H0): снижение сложности 3-го уровня не повлияет на долю пользователей, успешно завершивших 3-й уровень. Completion Rate 3-го уровня для групп А и В на самом деле не отличаются, и наблюдаемые различия случайны.
- Альтернативная гипотеза (H1): снижение сложности 3-го уровня увеличит долю пользователей, успешно завершивших 3-й уровень. Completion Rate 3-го уровня в группе B выше, чем в группе A, и эти различия — результат изменений.
На этом этапе, кроме формулирования гипотезы, необходимо оценить ожидаемый эффект.
Гипотеза: «Ожидаем, что уменьшение сложности 3-го уровня вызовет рост Completion Rate 3-го уровня с 85% до 95%, то есть более чем на 11%».
(95%-85%)/85% = 0,117 => 11,7%
В этом примере при определении ожидаемого Completion Rate 3-го уровня мы стремимся приблизить его к среднему значению Completion Rate начальных уровней.
Шаг 4. Настраиваем эксперимент
1. Определяем параметры для А/В-групп перед запуском эксперимента: на какую аудиторию запускаем тест, на какую долю игроков, какие настройки устанавливаем в каждой группе.
2. Проверяем репрезентативность выборки в целом и однородность выборок в группах. Можно предварительно запустить А/А-тест для оценки этих параметров — тест, в котором тестовая и контрольная группы имеют одинаковую функциональность. А/А-тест помогает убедиться, что в обеих группах целевые метрики не имеют статистически значимого различия. Если же различия есть, А/В-тест с такими настройками — объемом выборки и уровнем доверия — запускать нельзя.
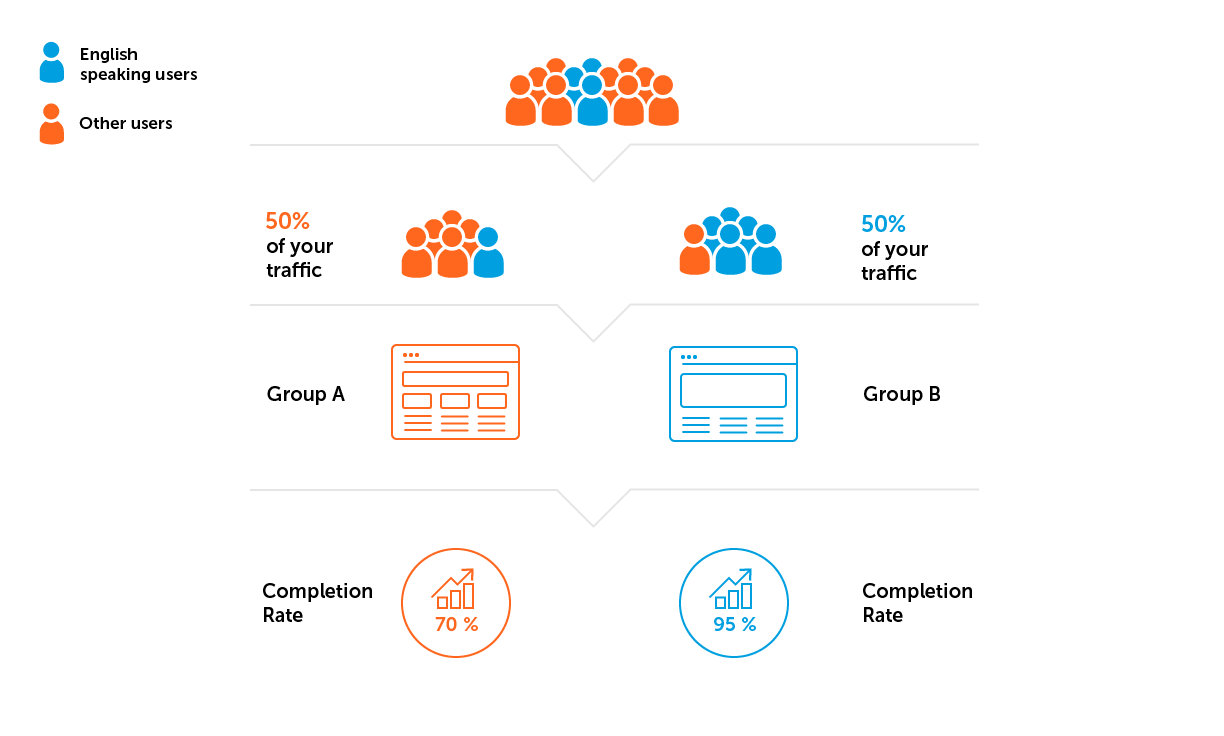
Выборка не будет идеально репрезентативной, но мы всегда обращаем внимание на структуру пользователей в разрезе их характеристик — новый/старый пользователь, уровень в игре, страна. Всё привязано к цели А/В-теста и оговаривается заранее. Важно, чтобы структура пользователей в каждой группе была условно одинаковая.
Тут потенциально опасны две ловушки:
- Высокие показатели метрик в группах во время эксперимента могут быть следствием привлечения хорошего трафика. Трафик хороший, если показатели вовлеченности высокие. Плохой трафик — самая частая причина падения метрик.
- Неоднородность выборки. Допустим, проект из нашего примера разрабатывается для англоговорящей аудитории. Значит, нам нужно избежать ситуации, когда в одну из групп попадет больше пользователей из стран, где английский язык — не преобладающий.
3. Рассчитываем объем выборки и длительность проведения эксперимента.
Казалось бы, момент прозрачный, принимая во внимание огромный набор онлайн-калькуляторов.
Однако их использование предполагает ввод специфичной начальной информации. Чтобы выбрать соответствующий вариант онлайн-калькулятора, вспомните про типы данных и разберитесь со следующими терминами.
- Генеральная совокупность — все пользователи, на которых в дальнейшем будут распространены выводы А/В-теста.
- Выборка — пользователи, которые фактически попадают в тестирование. По результатам анализа выборки делаются выводы о поведении всей генеральной совокупности.
- Базовый уровень конверсии, который ожидаем увидеть в контрольной группе. Для оценки этого показателя берем исторические данные — усредненный показатель за последний месяц, но учитываем не только среднее значение, а и динамику показателя, тренд и так далее.
- Размер эффекта, который ожидаем увидеть в тестовой группе. Этот показатель определяем самостоятельно и обязательно оговариваем перед запуском эксперимента.
- Уровень статистической значимости (?) — вероятность совершить ошибку первого рода, то есть отвергнуть нулевую гипотезу (Н0), когда она на самом деле верна.
- Уровень доверия (1-?) — процент уверенности в том, что результаты теста верны, если он показал разницу.
- Мощность критерия (1-?) — процент уверенности в том, что результаты теста верны, если он не показал разницу.
Совокупность этих параметров позволяет рассчитать необходимый объем выборки в каждой группе и длительность теста.
В онлайн-калькуляторе можно «побаловаться» с входными данными, чтобы понять природу их взаимосвязей.
Пример. С помощью калькулятора Optimizely рассчитаем объем выборки для коэффициента конверсии 1%. Учтем, что предполагаемый размер эффекта составит 5% при 95% уровне доверия (показатель рассчитывается как 1-?). Обратите внимание: в интерфейсе этого калькулятора термин Statistical significance используется в значении «Уровень доверия» при уровне значимости 5%.
Optimizely утверждает, что в каждую группу должны попасть 870 000 пользователей.
Переводим размер выборки в приблизительную длительность теста — два простых вычисления.
Расчет № 1. Размер выборки ? количество групп в эксперименте = общее количество необходимых пользователей
Расчет № 2. Общее количество необходимых пользователей ? среднее количество пользователей в день = примерное количество дней эксперимента
Если в первую группу требуется 870 000 пользователей, то для теста двух вариантов общее количество пользователей составит 1 740 000. С учетом трафика 1000 игроков в день, тест должен длиться 1740 дней. Такая длительность не оправдана. На этом этапе мы обычно пересматриваем гипотезу, исходные данные и целесообразность проведения теста.
В нашем примере с улучшением 3-го уровня конверсия — это доля тех, кто успешно завершил 3-й уровень. То есть коэффициент конверсии составляет 85%, мы хотим увеличить этот показатель минимум на 11%. При уровне доверия 95% получаем 130 пользователей на группу.
При том же объеме трафика в 1000 пользователей тест, грубо говоря, можно закончить менее чем за день. Этот вывод в корне неправильный, так как не учитывает недельную сезонность. Поведение пользователей отличается в разные дни недели, например, может изменяться по праздникам. И в одних проектах это влияние очень сильное, в других едва заметное. Не во всех проектах и не для всех тестов это необходимое условие, но на проектах, с которыми мне доводилось работать, недельная сезонность в КPI наблюдалась всегда.
Поэтому длительность теста мы округляем до недель, чтобы учесть сезонность. Чаще наш цикл тестирования составляет одну-две недели в зависимости от типа А/В-теста.
Шаг 5. Проводим эксперимент
После запуска А/В-теста сразу возникает желание посмотреть на результаты, но большинство источников строго-настрого запрещает это делать, чтобы исключить проблему «подглядывания» (peeking problem). Объяснить суть проблемы простыми словами, на мой взгляд, пока ни у кого не получилось. Авторы подобных статей основывают доказательства на оценке вероятностей, различных результатах математического моделирования, которые уводят читателей в зону «сложных математических формул». Основной их вывод — практически неоспоримый факт: не смотрите на данные до того, как наберется требуемая выборка и пройдет требуемое количество дней после запуска теста. В результате проблему «подглядывания» многие интерпретируют неправильно и следуют рекомендациям буквально.
Мы настроили процессы так, чтобы ежедневно видеть актуальные данные для мониторинга KPI проектов. В заранее подготовленных дашбордах следим за ходом эксперимента с самого запуска: проверяем, равномерно ли набираются группы, нет ли критичных проблем после запуска теста, которые могут повлиять на результаты, и так далее.
Главное правило — не делать преждевременных выводов. Все выводы формулируются в соответствии с заложенным дизайном А/В-теста и сводятся в детализированном отчете. Мы мониторим изменения показателя с момента запуска А/В-теста.
Пример, как в А/В-тесте по дням может меняться Completion Rate. В первые два дня после запуска побеждал вариант игры без изменений (группа А), но это оказалось просто случайностью. Уже после второго дня показатель в группе В приобретает стабильно лучшие результаты. Для завершения тесту нужна не просто статистическая значимость, но и стабильность, поэтому ждем окончания теста.
Пример, когда стоит преждевременно завершить А/В-тест. Если после запуска одна из групп дает критично низкие показатели, мы сразу ищем причины такого падения. Самые частые — ошибки в конфигурации и настройках игрового уровня. В таком случае текущий тест отключается преждевременно и запускается новый, с исправлениями.
Шаг 6. Анализируем результаты
Расчет ключевых метрик не представляет особой сложности, а вот оценка значимости полученных результатов — отдельная проблема.
Для проверки статистической значимости результатов при оценивании качественных метрик, таких как Retention и Сonvertion, можно использовать онлайн-калькуляторы.
Мой топ-3 онлайн-калькуляторов для таких задач:
- Evan’s Awesome A/B Tools — один из самых популярных. В нем реализовано несколько методов оценки значимости теста. При использовании нужно четко понимать сущность каждого введенного параметра, самостоятельно интерпретировать результаты и формулировать выводы.
- Если к ответу нужны математические обоснования, используйте A/B Testguide. Калькулятор будет полезен тем, кто хочет разобраться в сути самого метода оценки значимости. Большой плюс — графическая визуализация результатов в виде двух распределений, построенных на основе исходных данных.
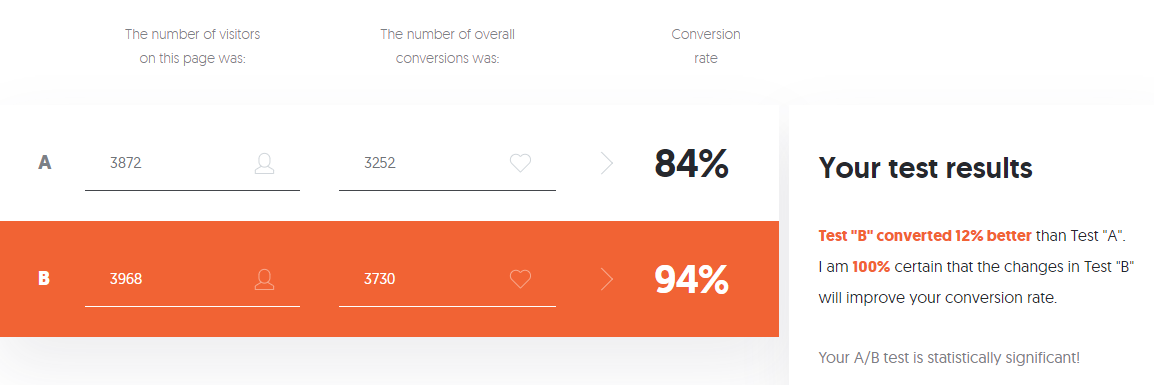
- Для быстрой оценки тестов с количеством групп две и более используйте A/B Testing Calculator от Neilpatel. Он прост в использовании и не только указывает на вариант-победитель, но и самостоятельно формулирует вывод.
Пример. Для анализа подобных А/В-тестов у нас есть дашборд, который отображает всю информацию, необходимую для построения выводов, и автоматически подсвечивает результат со значимым изменением целевого показателя.
Давайте посмотрим, как с помощью калькуляторов построить выводы по данному А/В-тесту.
Исходные данные:
- В группе А из 3870 пользователей, начавших 3-й уровень, всего 3252 пользователя успешно его прошли — это 84%.
- В группе В из 3968 пользователей 3730 успешно прошли уровень — это 94%.
Калькулятор Evan’s Awesome A/B Tools рассчитал для каждого варианта доверительный интервал с учетом объема выборки и выбранного уровня значимости.
Самостоятельные выводы:
- Коэффициент конверсии в группе A — 84,00%, доверительный интервал 82,8%—85,1%. Коэффициент конверсии в группе B — 94,00%, доверительный интервал 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- Коэффициент конверсии в группе В на 12% выше, чем коэффициент конверсии в группе A. Этот результат — следствие внесенных изменений, а не случайность. Уровень доверия 95%.
- Рекомендуем применить настройки группы В для всех пользователей.
Схожие результаты получим и с калькулятором A/B Testguide. Но здесь уже можно поиграться с настройками, получить графический результат и сформулированные выводы.
Если пугает такое количество настроек, нет желания или потребности разбираться с разнообразием рассчитанных калькулятором данных, можно использовать A/B Testing Calculator от Neilpatel.
В каждом онлайн-калькуляторе заложены свои критерии и алгоритмы, которые могут не учитывать всех особенностей эксперимента. В результате возникают вопросы и сомнения в интерпретации результатов. Кроме того, если целевая метрика количественная — средний чек или средняя длина первой сессии — перечисленные онлайн-калькуляторы уже не применимы и требуются более продвинутые методы оценки.
Я оформляю детальный отчет по каждому А/В-тесту, поэтому подобрала и реализовала подходящие под мои задачи методы и критерии для оценки статистической значимости результатов.
Заключение
А/В-тест — инструмент, который не дает однозначного ответа на вопрос «Какой вариант лучше?», а лишь позволяет снизить неопределенность на пути к поиску оптимальных решений. При его проведении детали важны на всех этапах подготовки, каждая неточность стоит ресурсов и может негативно повлиять на достоверность результатов. Надеюсь, эта статья была полезной для вас и поможет избежать ошибок при А/В-тестировании.