
Сегодня свыше 90 процентов компаний из Fortune 500 используют 360 performance review (обзор качества работы) для оценки компетенций сотрудников. Этот метод анализа завоевал популярность, так как позволяет получить сбалансированное понимание о человеке, избегая субъективных мнений (насколько это вообще возможно в такой непростой сфере, как работа с людьми). Результаты исследования базируются на мнениях руководителя, коллег, подчиненных, а также на самооценке самого сотрудника. Важно понимать, что анализ 360 проводится на основе ценностей и компетенций компании, то есть затрагивает не бизнес-результаты (что и сколько было достигнуто), а то, как это было сделано.
Метод 360 performance review используется и в Х5 Retail Group. Сегодня мы расскажем о практических наработках BigData X5 для углубленной HR-аналитики.

Очевидно, точность такого метода, хоть и повышается за счет усреднения различных мнений, все равно зависит от открытости и энтузиазма, с которым люди заполняют опросники, от понимания ими шкалы, от силы команды, атмосферы в коллективе, и многого другого.
Важным аспектом работы такой системы является взаимодействие с заполняющими опросники. Если человек бездумно ставит всем пятерки, с ним нужно работать, разъяснять важность процесса. В России существует определенное отношение к оценкам на основе пятибалльной шкалы, в соответствие с которой троечник — это так себе персонаж, хорошист — нормально, ну а отличник — это вот, кто хорошо работает, это похвала. Двоечники же остаются на второй год, да и вообще «их немного, да и в нашей компании не видел ни разу», — так обычно отвечают менеджеры про свой коллектив. «Где-то», но не у нас. Итого, если вы считаете, что работник хорош, вы ставите ему четверку, потому что троечка… ну троечка и есть, а если вы приятельствуете, то можно и пятерку поставить — ничтоже сумняшеся. Приводит это к перекосу оценок, к высокому проценту пятерок в опросе, который вырождается почти в двухбалльный: с четверками и пятерками.
Обучение оценивающих представляет собой медленный и печальный (ну ок, не всегда печальный) процесс, включающий в себя пояснения: как работает инструмент; как верно оценивать человека, не ударяясь ни в восхищение по итогам одного единственного взаимодействия, ни в негатив по итогам одного грубоватого письма; как выглядит шкала оценки, отличная от привычной в школе; обзор типичных ошибок ревьюеров, и так далее. Очень важно расслабить людей, уйти от восприятия ими процесса как yet another boring tool, избавить от страха, что оценка повлияет на финансовые результаты коллеги. Здесь принципиально важно не принимать поспешных кадровых решений и не корректировать командный состав по свежим следам.
Постановка аналитического процесса с точки зрения сотрудника HR хорошо изложена в тексте от Авито, который я всячески рекомендую к прочтению. Ребята наблюдали сильный перекос в сторону добра, количество четверок («выше ожиданий») было схоже с числом троек («соответствует ожиданиям»). С рассуждениями про «добрых и злых» столкнулись и мы, хотя и использовали шкалу нашей собственной разработки.
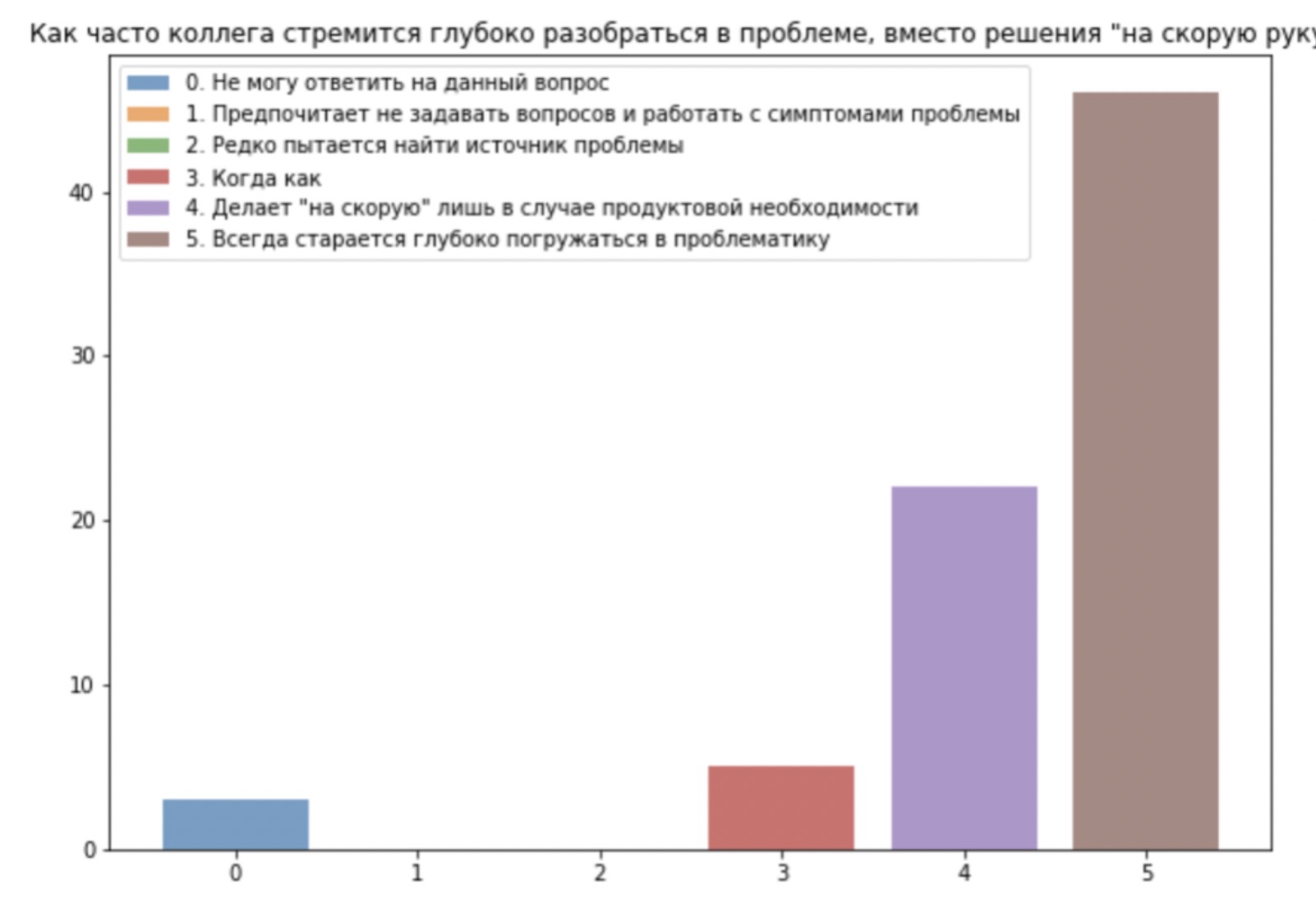
Дальше голоса разделились. Или это сильная дружная команда, или одно из двух. Поэтому мы быстренько запустили второе ревью на другой команде,
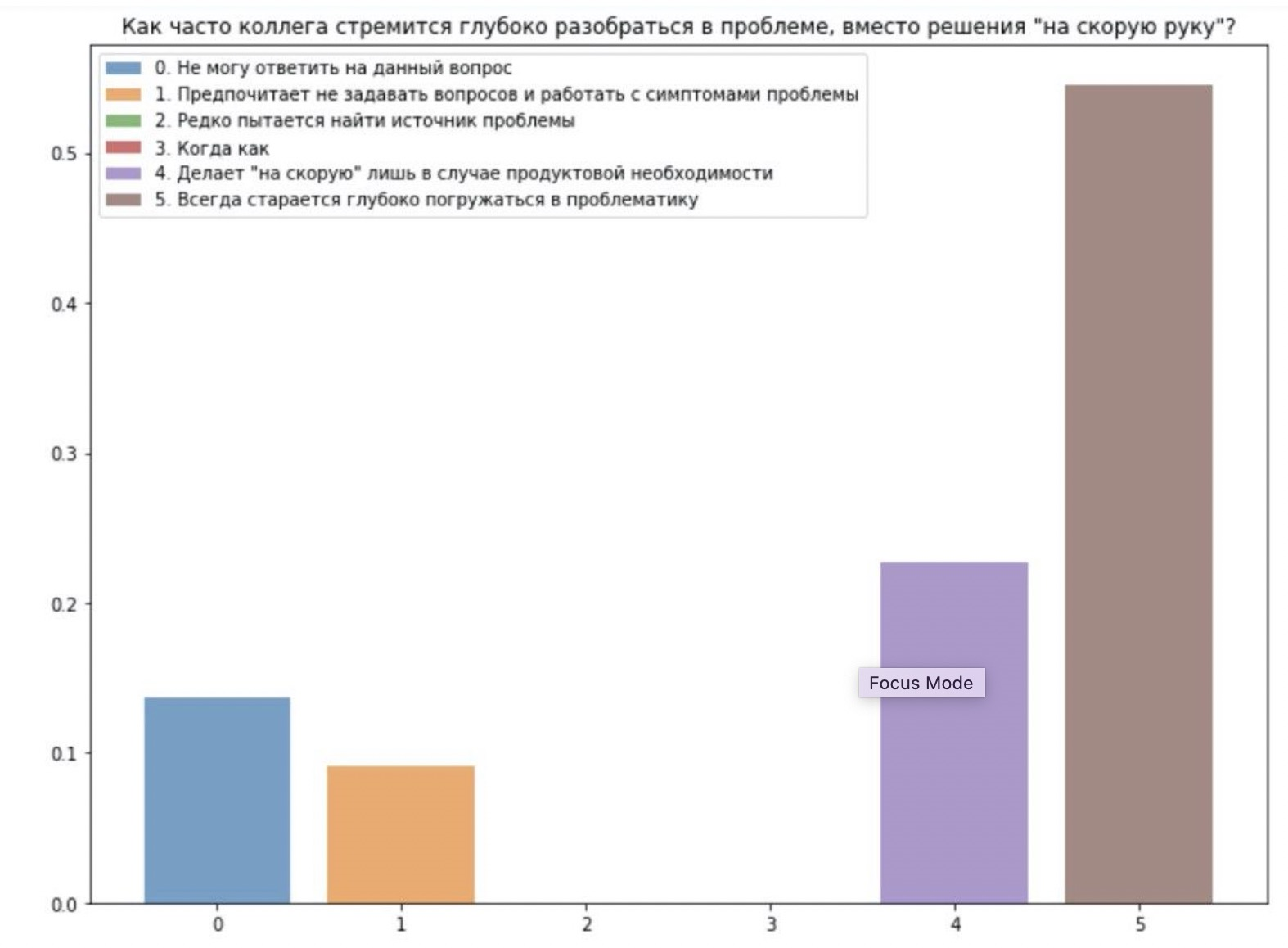
и убедились, что иногда и без дополнительной работы по разъяснению шкалы и калибровке оценок можно получать данные с высокой дисперсией. То есть, нужно и работать с людьми, и учитывать органическую склонность к «объективным» оценкам. А может, это и разногласия внутри команды, что, вообще говоря, тоже полезно знать.
Оценка 360, вообще говоря, используется в двух целях: развитие сотрудников и анализ качества работы. Важно понимать, что выходные результаты могут отличаться в зависимости от степени подготовленности и открытости тех, кто предоставляет обратную связь. Когда мы создаем инструмент для расширения возможностей развития сотрудников, нам важно обеспечить анонимную обратную связь от различных источников, чтобы помочь ему понять свои сильные и слабые стороны, прокачать навыки, развить недостающие качества. Опрос фокусируется на компетенциях или же поведенческих особенностях, тесно связанных с выполнением должностных обязанностей, и ценностях организации. Когда мы запускаем такой инструмент, мы обязаны четко дать понять участникам, что мы не будем использовать результаты для кадровых решений. Наш рассказ будет об использовании метода 360 ревью в целях развития сотрудников.
Данные по развитию сотрудников нужны для оценки сильных сторон и областей для развития, а не для вынесения решений о премировании/кадровых изменениях. Для компании также важно понимать, насколько ценности человека соотносятся с ценностями компании. Результаты 360 всегда предоставляются сотруднику и его руководителю.
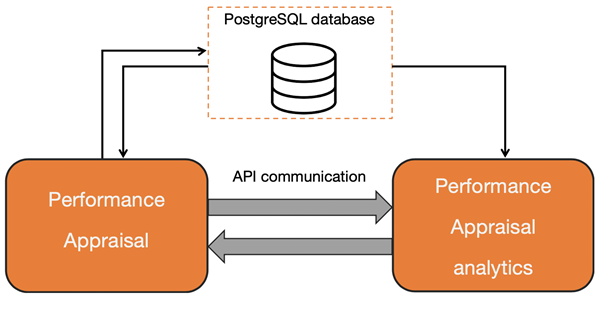
Оценки и результаты прохождения опросов 360 – это ценный кладезь данных, который можно использовать для получения инсайтов и построения аналитических отчетов. Эти данные нужны для вычисления «поправочных» коэффициентов, которые помогут получить более достоверный результат, а также для кластеризации сотрудников по компетенциям, навыкам, составления «профиля» отдельных команд и многого другого. Для всех этих вычислений требуются дополнительные мощности и фреймворки, которые мы решили вынести в отдельный микросервис. Таким образом, мы логически отделили ту часть, которую видит пользователь (из HR департамента), от «аналитической» части, на которой производятся все дополнительные аналитические вычисления. Такой подход позволяет развивать эти сервисы независимо, и дает возможность к дополнительному разделению вычислений. Аналитический сервис не имеет собственной базы данных, все вычисления делаются на основе тех данных, которые лежат в базе данных основного сервиса, и осуществляет взаимодействие с помощью REST-API.
Аналитический сервис представляет из себя отдельный сервер, написанный на Flask, а основной сервис реализован на NodeJS с базой данных PostgreSQL. Эта, вне всякого сомнения, непростая схема взаимодействия представлена ниже:
Рассмотрим пример оценки опросов в других командах, назовем их команда А и команда Б. Представим ситуацию, что в команде А сотрудники дружат, хорошо относятся друг к другу, и, соответственно, средний балл может быть довольно высоким. В противовес команде А предположим, что команда Б состоит из более критически настроенных людей, которые честно ставят высокий балл только тем сотрудникам, которые действительно показывают выдающиеся результаты.
Как же нам сравнить двух сотрудников из команды А и команды Б? Для сравнения сотрудников из разных команд мы используем специальную «командную» калибровку, чтобы получить score сотрудника относительно среднего score в его команде. Без формулы здесь не обойтись.
Допустим, у нас есть сотрудник x со score 0.9 из команды А, средний score которой равен 0.85, и есть сотрудник y со score 0.65 из команды Б, средний score которой равен 0.5. После вычета средних score команд мы получаем «откалиброванные» скоры по сотрудникам:
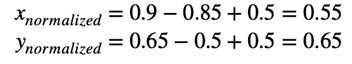
Таким образом, видим, что сотрудник y имеет откалиброванный score выше, чем откалиброванный score сотрудника x.
Такой же пример применим и к нормализации внутри команды. Все сотрудники разные и склонны оценивать коллег тоже по-разному. Допустим, есть сотрудник x, который очень хорошо относится ко всем коллегам, и ставит всем средний score 0.8, и есть сотрудник y, который более критично смотрит на окружающих и в среднем оценивает других сотрудников на 0.5. Когда сотрудники x и y оценивают сотрудника z, то они могут оценить его одинаково хорошо (или одинаково плохо), но в своей системе ценностей, поэтому при усреднении среднего score внутри команды мы вычитаем среднее каждого сотрудника, которое высчитывается по историческим данным. Допустим, сотрудник x оценил сотрудника z на 0.9, а сотрудника y – на 0.7, усредненный score будет равен
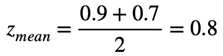
Однако, если мы вычтем средние исторически оценки авторов, то мы получим
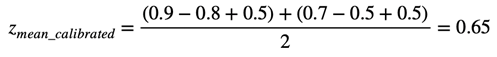
После такой калибровки мы получаем показатель, который учитывает «систему ценностей» каждого сотрудника и, следовательно, является более «честным».
Важно то, что мы можем при определении профиля человека взвешивать оценки от ревьюеров с разными коэффициентами. Есть множество свидетельств, что руководители склонны более точно и беспристрастно оценивать людей (собственно, в том числе поэтому они и оказались там, где оказались), скорее всего, в силу большего опыта.
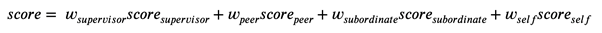
Значения весов по умолчанию равны 0.25, то есть мы в текущей версии не отдаем предпочтения ни одной из категорий респондентов, но как говорилось в одном старом анекдоте, “инструмент то имеется”.
Иными словами, собрав оценки, откалиброванные по авторам, мы пытаемся загнать их в глобальную “систему координат”, чтобы иметь возможность извлекать из данных корректные инсайты. В противном случае, из-за смещенных оценок мы можем открыть какую-нибудь удивительную закономерность, которой реально не существует, и чего доброго, начнем развивать сотрудника в направлении, противоположном его профилю.
Пусть мы добились успеха, и у нас есть сведенные в единый формат векторы, представляющие профиль компетенций сотрудника. Причем есть векторы, полученные от коллег, руководителя, подчиненных и из самооценки. Все это мы собираем в куб (если быть точным, параллелепипед, но дальше я буду использовать термин куб по аналогии с OLAP-кубами).
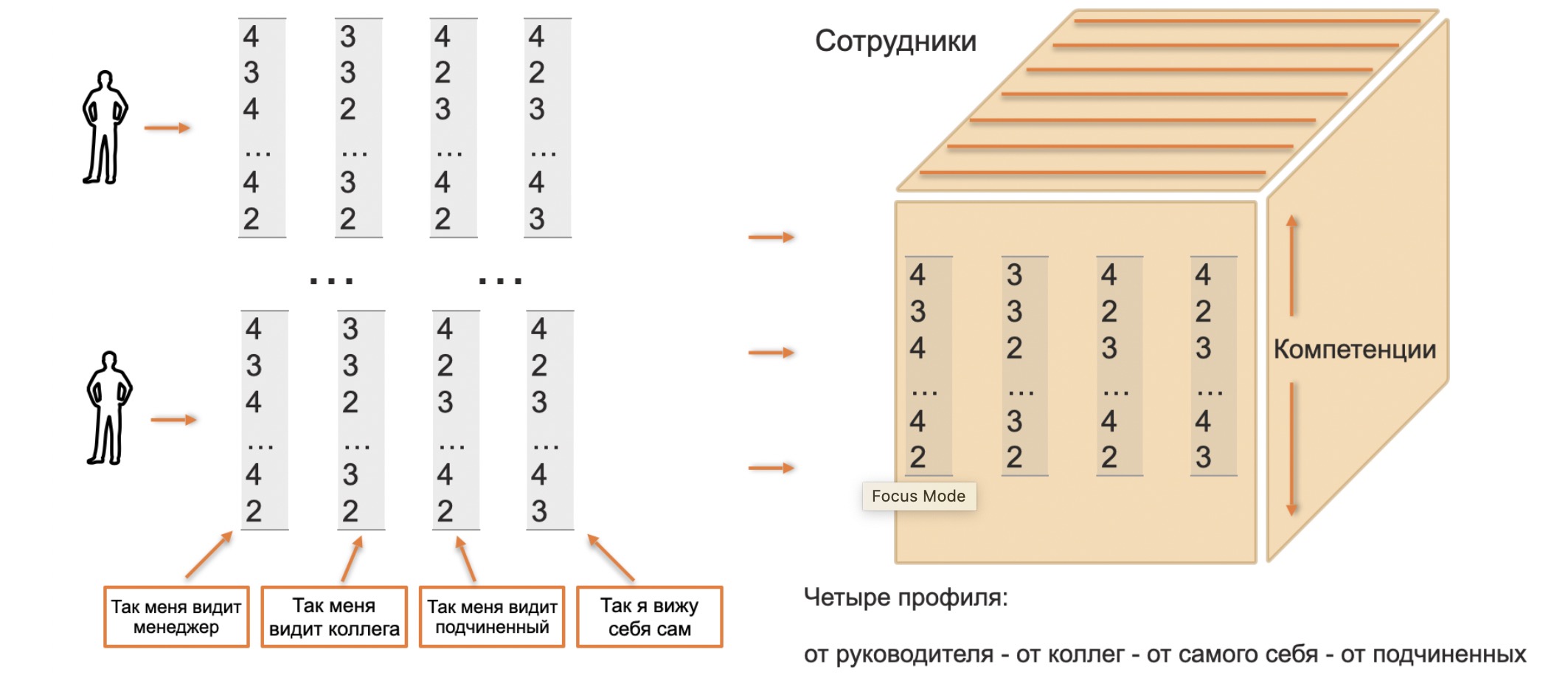
А вот теперь, рассекая куб по различным осям, мы можем получать различные аналитические зависимости. К примеру, зафиксируем компетенцию, и посмотрим ее распределение по организации целиком или же кросскомандно внутри организации. Или возьмем крайний правый столбец с оценками от менеджеров, и посмотрим внутри организации на дисперсию оценок, чтобы понять, нет ли здесь каких-то удивительных открытий.
Развивая эту логику, можно получать диаграммы сравнения сотрудников, как внутри команды, так и принадлежащих разным подразделениям, так называемые паутинчатые; а можно на той же диаграмме привести средние значения компетенций в команде и понять для конкретного человека, где он выбивается относительно команды и в какую сторону; можно взять и другую команду вместо той, в которой находится сотрудник и сравнить ее средние компетенции с компетенциями человека. Да что там, если размахнуться, можно и команду сравнить относительно другой команды, вот какая веселая игра может выйти.
Можно провести и анализ кластеров определенных типажей внутри организации, чтобы отыскать людей, которые, быть может, являются эффективными коммуникаторами, или же экспертами, известными своим глубоким подходом к решению проблем.
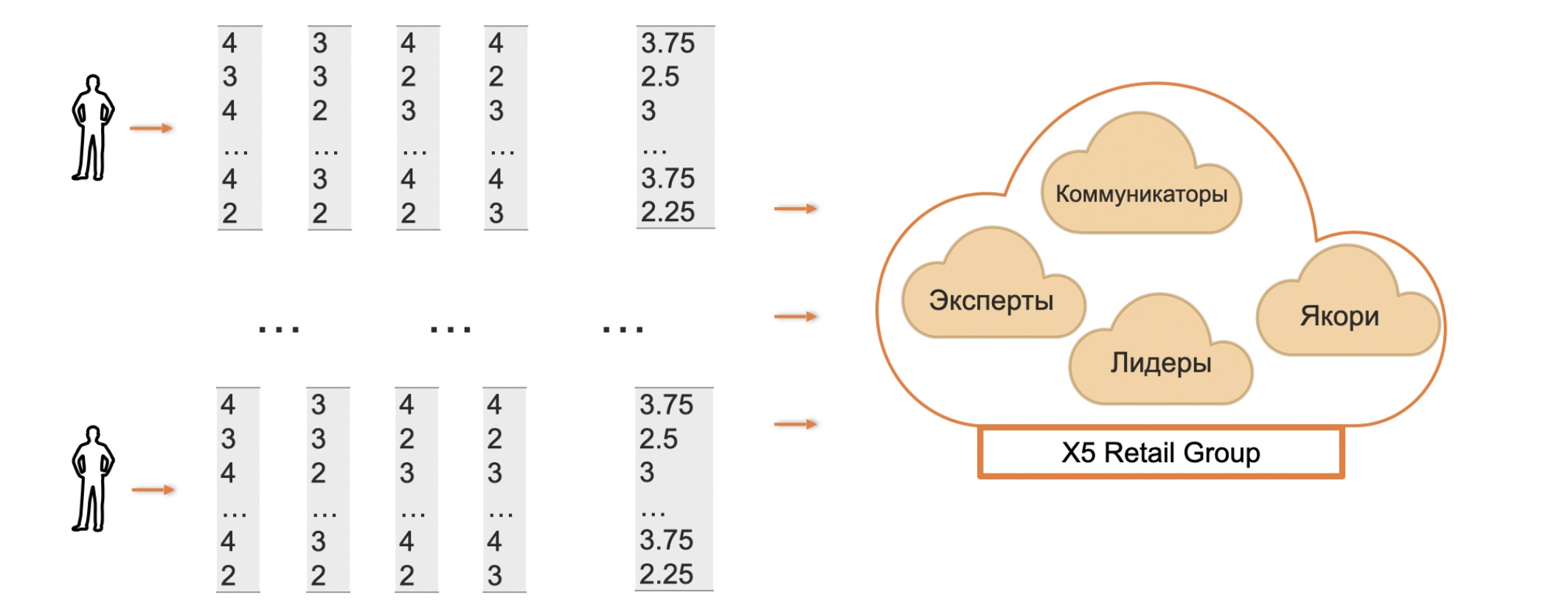
Возможны и более простые аналитически находки, хотя и не менее интересные. В частности, высокая дисперсия оценок у одного из сотрудников при опросе среди коллег может свидетельствовать о полярном восприятии его коллегами.
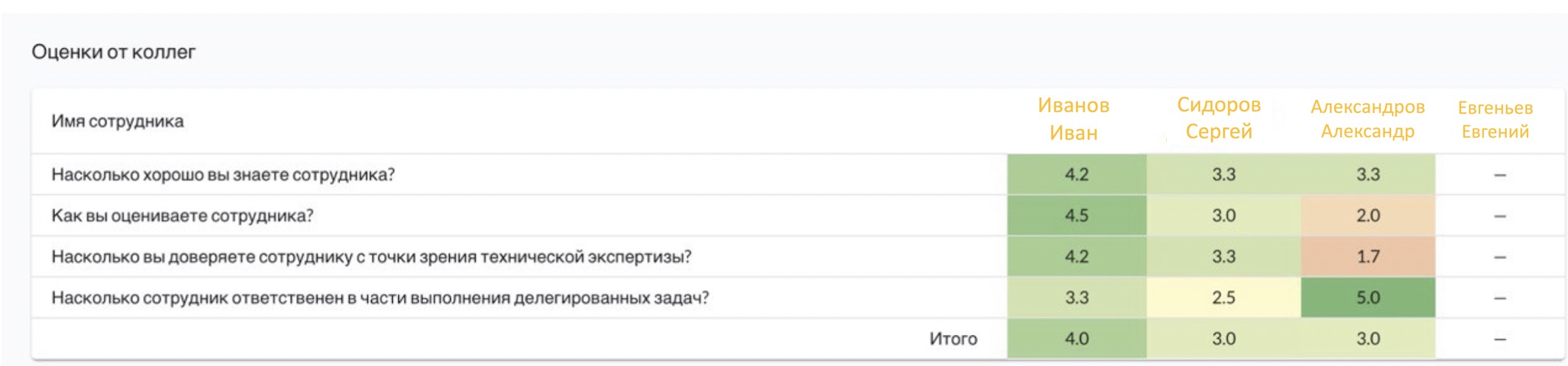
А если дисперсия высока и при сравнении оценок от коллег, и от руководителя? Очень уж по-разному коллеги и руководитель оценивают сотрудника? Пожалуй, тут можно и заинтересоваться, что за руководитель такой, и не слишком ли он строг к членам своей команды (ну или наоборот, некритичен). Или же сделать вывод о принципиальной сверхобъективности руководителей в организации, если подобный паттерн будет повторяться и для остальных команд.
Высокое количество пропусков оценок для кого-либо из сотрудников скорее всего укажет на то, что человек мало вовлечен во взаимодействие с коллегами. В то же время для некоторых команд в Х5 это вполне себе modus operandi, и ничего удивительного тут нет, но очевидно, что для каких-то команд это будет служить индикатором к необходимости изменений в процессе работы.
В дальнейшем мы хотим формировать более тонкие вопросы в исследовательской форме, с тем, чтобы устранять смещения оценок на этом этапе, уходя от ручной работы с пользователями сервиса и бесконечных разъяснений — как правильно выбирать оценки и что они означают. У нас есть несколько идей, они в процессе верификации, и мы с вами обязательно поделимся результатами. Хотим и применять к кубу с данными более хитрые методики, помимо разрезов по осям и кластеризации. Тут мы пробуем различные автоэнкодеры, линейные и нелинейные, выискиваем кроссвязи между представлениями вдоль разных координатных осей. В общем, работы много, данные непослушные, а настройка системы нелегка :)
Авторы:
Евгений Макаров
Валерий Бабушкин
Святослав Орешин
Даниил Павлюченко
Евгений Молодкин
Метод 360 performance review используется и в Х5 Retail Group. Сегодня мы расскажем о практических наработках BigData X5 для углубленной HR-аналитики.
Очевидно, точность такого метода, хоть и повышается за счет усреднения различных мнений, все равно зависит от открытости и энтузиазма, с которым люди заполняют опросники, от понимания ими шкалы, от силы команды, атмосферы в коллективе, и многого другого.
Важным аспектом работы такой системы является взаимодействие с заполняющими опросники. Если человек бездумно ставит всем пятерки, с ним нужно работать, разъяснять важность процесса. В России существует определенное отношение к оценкам на основе пятибалльной шкалы, в соответствие с которой троечник — это так себе персонаж, хорошист — нормально, ну а отличник — это вот, кто хорошо работает, это похвала. Двоечники же остаются на второй год, да и вообще «их немного, да и в нашей компании не видел ни разу», — так обычно отвечают менеджеры про свой коллектив. «Где-то», но не у нас. Итого, если вы считаете, что работник хорош, вы ставите ему четверку, потому что троечка… ну троечка и есть, а если вы приятельствуете, то можно и пятерку поставить — ничтоже сумняшеся. Приводит это к перекосу оценок, к высокому проценту пятерок в опросе, который вырождается почти в двухбалльный: с четверками и пятерками.
Обучение оценивающих представляет собой медленный и печальный (ну ок, не всегда печальный) процесс, включающий в себя пояснения: как работает инструмент; как верно оценивать человека, не ударяясь ни в восхищение по итогам одного единственного взаимодействия, ни в негатив по итогам одного грубоватого письма; как выглядит шкала оценки, отличная от привычной в школе; обзор типичных ошибок ревьюеров, и так далее. Очень важно расслабить людей, уйти от восприятия ими процесса как yet another boring tool, избавить от страха, что оценка повлияет на финансовые результаты коллеги. Здесь принципиально важно не принимать поспешных кадровых решений и не корректировать командный состав по свежим следам.
Постановка аналитического процесса с точки зрения сотрудника HR хорошо изложена в тексте от Авито, который я всячески рекомендую к прочтению. Ребята наблюдали сильный перекос в сторону добра, количество четверок («выше ожиданий») было схоже с числом троек («соответствует ожиданиям»). С рассуждениями про «добрых и злых» столкнулись и мы, хотя и использовали шкалу нашей собственной разработки.
Дальше голоса разделились. Или это сильная дружная команда, или одно из двух. Поэтому мы быстренько запустили второе ревью на другой команде,
и убедились, что иногда и без дополнительной работы по разъяснению шкалы и калибровке оценок можно получать данные с высокой дисперсией. То есть, нужно и работать с людьми, и учитывать органическую склонность к «объективным» оценкам. А может, это и разногласия внутри команды, что, вообще говоря, тоже полезно знать.
Оценка 360, вообще говоря, используется в двух целях: развитие сотрудников и анализ качества работы. Важно понимать, что выходные результаты могут отличаться в зависимости от степени подготовленности и открытости тех, кто предоставляет обратную связь. Когда мы создаем инструмент для расширения возможностей развития сотрудников, нам важно обеспечить анонимную обратную связь от различных источников, чтобы помочь ему понять свои сильные и слабые стороны, прокачать навыки, развить недостающие качества. Опрос фокусируется на компетенциях или же поведенческих особенностях, тесно связанных с выполнением должностных обязанностей, и ценностях организации. Когда мы запускаем такой инструмент, мы обязаны четко дать понять участникам, что мы не будем использовать результаты для кадровых решений. Наш рассказ будет об использовании метода 360 ревью в целях развития сотрудников.
Данные по развитию сотрудников нужны для оценки сильных сторон и областей для развития, а не для вынесения решений о премировании/кадровых изменениях. Для компании также важно понимать, насколько ценности человека соотносятся с ценностями компании. Результаты 360 всегда предоставляются сотруднику и его руководителю.
Оценки и результаты прохождения опросов 360 – это ценный кладезь данных, который можно использовать для получения инсайтов и построения аналитических отчетов. Эти данные нужны для вычисления «поправочных» коэффициентов, которые помогут получить более достоверный результат, а также для кластеризации сотрудников по компетенциям, навыкам, составления «профиля» отдельных команд и многого другого. Для всех этих вычислений требуются дополнительные мощности и фреймворки, которые мы решили вынести в отдельный микросервис. Таким образом, мы логически отделили ту часть, которую видит пользователь (из HR департамента), от «аналитической» части, на которой производятся все дополнительные аналитические вычисления. Такой подход позволяет развивать эти сервисы независимо, и дает возможность к дополнительному разделению вычислений. Аналитический сервис не имеет собственной базы данных, все вычисления делаются на основе тех данных, которые лежат в базе данных основного сервиса, и осуществляет взаимодействие с помощью REST-API.
Аналитический сервис представляет из себя отдельный сервер, написанный на Flask, а основной сервис реализован на NodeJS с базой данных PostgreSQL. Эта, вне всякого сомнения, непростая схема взаимодействия представлена ниже:
Рассмотрим пример оценки опросов в других командах, назовем их команда А и команда Б. Представим ситуацию, что в команде А сотрудники дружат, хорошо относятся друг к другу, и, соответственно, средний балл может быть довольно высоким. В противовес команде А предположим, что команда Б состоит из более критически настроенных людей, которые честно ставят высокий балл только тем сотрудникам, которые действительно показывают выдающиеся результаты.
Как же нам сравнить двух сотрудников из команды А и команды Б? Для сравнения сотрудников из разных команд мы используем специальную «командную» калибровку, чтобы получить score сотрудника относительно среднего score в его команде. Без формулы здесь не обойтись.
Допустим, у нас есть сотрудник x со score 0.9 из команды А, средний score которой равен 0.85, и есть сотрудник y со score 0.65 из команды Б, средний score которой равен 0.5. После вычета средних score команд мы получаем «откалиброванные» скоры по сотрудникам:
Таким образом, видим, что сотрудник y имеет откалиброванный score выше, чем откалиброванный score сотрудника x.
Такой же пример применим и к нормализации внутри команды. Все сотрудники разные и склонны оценивать коллег тоже по-разному. Допустим, есть сотрудник x, который очень хорошо относится ко всем коллегам, и ставит всем средний score 0.8, и есть сотрудник y, который более критично смотрит на окружающих и в среднем оценивает других сотрудников на 0.5. Когда сотрудники x и y оценивают сотрудника z, то они могут оценить его одинаково хорошо (или одинаково плохо), но в своей системе ценностей, поэтому при усреднении среднего score внутри команды мы вычитаем среднее каждого сотрудника, которое высчитывается по историческим данным. Допустим, сотрудник x оценил сотрудника z на 0.9, а сотрудника y – на 0.7, усредненный score будет равен
Однако, если мы вычтем средние исторически оценки авторов, то мы получим
После такой калибровки мы получаем показатель, который учитывает «систему ценностей» каждого сотрудника и, следовательно, является более «честным».
Важно то, что мы можем при определении профиля человека взвешивать оценки от ревьюеров с разными коэффициентами. Есть множество свидетельств, что руководители склонны более точно и беспристрастно оценивать людей (собственно, в том числе поэтому они и оказались там, где оказались), скорее всего, в силу большего опыта.
Значения весов по умолчанию равны 0.25, то есть мы в текущей версии не отдаем предпочтения ни одной из категорий респондентов, но как говорилось в одном старом анекдоте, “инструмент то имеется”.
Иными словами, собрав оценки, откалиброванные по авторам, мы пытаемся загнать их в глобальную “систему координат”, чтобы иметь возможность извлекать из данных корректные инсайты. В противном случае, из-за смещенных оценок мы можем открыть какую-нибудь удивительную закономерность, которой реально не существует, и чего доброго, начнем развивать сотрудника в направлении, противоположном его профилю.
Пусть мы добились успеха, и у нас есть сведенные в единый формат векторы, представляющие профиль компетенций сотрудника. Причем есть векторы, полученные от коллег, руководителя, подчиненных и из самооценки. Все это мы собираем в куб (если быть точным, параллелепипед, но дальше я буду использовать термин куб по аналогии с OLAP-кубами).
А вот теперь, рассекая куб по различным осям, мы можем получать различные аналитические зависимости. К примеру, зафиксируем компетенцию, и посмотрим ее распределение по организации целиком или же кросскомандно внутри организации. Или возьмем крайний правый столбец с оценками от менеджеров, и посмотрим внутри организации на дисперсию оценок, чтобы понять, нет ли здесь каких-то удивительных открытий.
Развивая эту логику, можно получать диаграммы сравнения сотрудников, как внутри команды, так и принадлежащих разным подразделениям, так называемые паутинчатые; а можно на той же диаграмме привести средние значения компетенций в команде и понять для конкретного человека, где он выбивается относительно команды и в какую сторону; можно взять и другую команду вместо той, в которой находится сотрудник и сравнить ее средние компетенции с компетенциями человека. Да что там, если размахнуться, можно и команду сравнить относительно другой команды, вот какая веселая игра может выйти.
Можно провести и анализ кластеров определенных типажей внутри организации, чтобы отыскать людей, которые, быть может, являются эффективными коммуникаторами, или же экспертами, известными своим глубоким подходом к решению проблем.
Возможны и более простые аналитически находки, хотя и не менее интересные. В частности, высокая дисперсия оценок у одного из сотрудников при опросе среди коллег может свидетельствовать о полярном восприятии его коллегами.
А если дисперсия высока и при сравнении оценок от коллег, и от руководителя? Очень уж по-разному коллеги и руководитель оценивают сотрудника? Пожалуй, тут можно и заинтересоваться, что за руководитель такой, и не слишком ли он строг к членам своей команды (ну или наоборот, некритичен). Или же сделать вывод о принципиальной сверхобъективности руководителей в организации, если подобный паттерн будет повторяться и для остальных команд.
Высокое количество пропусков оценок для кого-либо из сотрудников скорее всего укажет на то, что человек мало вовлечен во взаимодействие с коллегами. В то же время для некоторых команд в Х5 это вполне себе modus operandi, и ничего удивительного тут нет, но очевидно, что для каких-то команд это будет служить индикатором к необходимости изменений в процессе работы.
В дальнейшем мы хотим формировать более тонкие вопросы в исследовательской форме, с тем, чтобы устранять смещения оценок на этом этапе, уходя от ручной работы с пользователями сервиса и бесконечных разъяснений — как правильно выбирать оценки и что они означают. У нас есть несколько идей, они в процессе верификации, и мы с вами обязательно поделимся результатами. Хотим и применять к кубу с данными более хитрые методики, помимо разрезов по осям и кластеризации. Тут мы пробуем различные автоэнкодеры, линейные и нелинейные, выискиваем кроссвязи между представлениями вдоль разных координатных осей. В общем, работы много, данные непослушные, а настройка системы нелегка :)
Авторы:
Евгений Макаров
Валерий Бабушкин
Святослав Орешин
Даниил Павлюченко
Евгений Молодкин
RuslanGabbasov
Я думаю нормализация оценок по сотрудникам это самообман. Обычно задачки на оценку 360 людям приходят с периодичность раз в пару месяцев и, выбранная в прошлый раз шкала, в голове не сохраняется. Сегодня устал и все задолбали: шкала нормальных оценок от 2 до 4, настало лето и хорошее настроение всем от 4 до 5. Да и вообще мерять с помощью балльной системы по 360 это явно от большой менеджерской лени, единственный способ вскрыть проблемы и реально оценить эффективность оцениваемого можно если не лениться и каждый раз создавать новый набор открытых вопросов, а затем читать и думать. Объективности 360 реально добавляет мало, но зато дает возможность для адекватной субъективной оценки.
X5RetailGroup Автор
Все верно, исторические колебания есть. Но есть и гипотеза, что как раз усреднение оценок коллег позволяет немного убрать этот шум. Один пришел не в духе, зато другой — как раз в хорошем настроении. И так далее. Сюда же оценка от руководителя — предполагается, что он подходит ответственно, и убирает свой bias. То есть аргументы За имеются тоже. Опять же, с авторами оценок нужно работать, но это уже хорошо описано в процитированном тексте от коллег.
Тут ведь дело даже не в менеджерской лени, а в наличии инструмента, который может как-то помочь даже трудолюбивому менеджеру, который чего-то просто забыл или не учел.
В целом мы согласны, что любая работа с людьми — дело тонкое, инструменты ненадежны, и несколько раз в тексте на это указали, тут спорить действительно не о чем.