
В течение нескольких лет я работала над личным проектом создания (а на самом деле исследования) «фальшивого эмулятора», то есть написанного на JavaScript эмулятора никогда не существовавшего компьютера. Эта машина должна была стать данью памяти восьми- и шестнадцатибитным компьютерам 1980-х и 90-х.
Однако мне нравятся сложности: в этой машине ещё и использовался новый набор инструкций. Он похож на наборы, применявшиеся в ту эпоху, но немного проще в работе. Так родился Retroputer. В течение нескольких лет эмулятор расширял свои возможности и совершенствовался, но, скорее всего, он никогда не будет «закончен» (в конце концов, это ведь личный проект-исследование).
Когда появился @bbcmicrobot, я захотела создать нечто подобное для Retroputer. Мои навыки разработки на JS в основном ограничивались фронтендом, поэтому это будет отличным поводом получить опыт бэкенда. Только есть одна проблема: Retroputer может понимать только собственный язык ассемблера. Пока у него нет поддержки BASIC.
Так я и пришла к созданию интерпретатора BASIC в стиле 80-х, то есть полностью на языке ассемблера, как его тогда и писали. Я решила, что стоит поделиться своей работой, потому что нам не часто приходится погружаться в области, столь далёкие от привычных абстракций. Мой повседневный инструмент (JavaScript) делает многие аспекты тривиальными, и иногда это даже кажется магией. Понимание самого нижнего уровня процессов часто помогает в понимании этих абстракций.
Итак, давайте приступим.
Характеристики Retroputer
- 16КБ ROM (KERNEL) c 1КБ для временного хранения (scratch space)
- 512КБ ОЗУ, из которых 64КБ можно использовать для исполняемых инструкций
- 16-битный процессор 6516, способный выполнять адресацию 512КБ ОЗУ в 4 банках по 64КБ каждый
- Генератор видеосигналов 4025, способный генерировать дисплей, спрайты и произвольные шрифты
- Генератор звука 1125
- Интерфейс жёсткого диска 9800 для устройства постоянного хранения
Парсинг на низкоуровневом языке ассемблера
Когда я писала ассемблер для Retroputer, то могла использовать очень удобный инструмент Pegjs. Он обеспечивал быструю работу собственного синтаксиса ассемблера, но, к сожалению, ничего подобного для Retroputer ASM не существует. То есть нам придётся идти трудным путём.
Сам парсинг выполняется в несколько этапов. Язык, использующий компилятор, парсит код в абстрактное синтаксическое дерево (AST) (или в иное представление), а затем может использовать это дерево для генерации готового нативного кода. Следовательно, для успешной компиляции программа должна быть синтаксически корректной.
У некоторых современных интерпретаторов тоже имеется эта концепция, потому что часто полезно бывает генерировать промежуточное AST и исполнять его, а не исходный код.
Но для интерпретатора BASIC на машине с ограниченными ресурсами наиболее эффективно будет выполнять парсинг в несколько этапов, часть из которых происходит во время выполнения. Однако это означает, что синтаксические ошибки невозможно будет обнаружить до запуска программы и перехода к области кода с ошибкой.
Парсинг Retroputer BASIC состоит из трёх этапов:
- Преобразование строк
- Токенизация
- Проверка синтаксиса во время выполнения
Первые два этапа происходят в процессе ввода пользователем программы (или её загрузки). Последний происходит при выполнении программы. По сути, первые два создают фюзеляж самолёта, но не гарантируют, что он взлетит. Последний этап является лётчиком-испытателем — мы надеемся, что он взлетит, но не уверены в этом, пока он не попробует.
Примечание: исходный код Retroputer BASIC (в процессе разработки) доступен на GitHub.
Преобразование строк
Это простейшая часть всего процесса. Вводимая пользователем строка преобразуется в верхний регистр, чтобы упростить (и ускорить) последующие процессы. BASIC не учитывает регистр символов, поэтому мы можем этим воспользоваться.
<pre>print 2+2
' becomes:
PRINT 2+2</pre>Выполнить подобное на JavaScript очень легко, правда?
theLine = theLine.toUpperCase();Но на языке ассемблера этот процесс более детализирован. Нам нужно считать символ, преобразовать его в верхний регистр, а затем куда-то сохранить.
ld y, 0 # y is our index
_loop: ld al, [d, x, y] # [d,x] is pointer to string
cmp al, 97 # is al (char) in range?
brs n _continue # Not a lowercase char; continue
cmp al, 123 # high portion
brs !n _continue # not a lowercase char; continue
and al, 0b1101_1111 # uppercase!
st [d, x, y], al # store back (we modify the original)
_continue: inc y # move our index along
cmp al, 0 # check for NULL
brs !z _loop # No? Go back for more.Приведённый выше код не совсем соответствует семантике версии кода на JavaScript. Важное отличие заключается в том, что сегодня для работы с текстом мы используем Unicode, поэтому преобразование ввода из нижнего в верхний регистр часто может оказываться более сложным, а иногда и невозможным (это зависит от языка). Retroputer живёт в мире ASCII (точнее, в мире собственной вариации ASCII под названием RetSCII), то есть все поддерживаемые символы кодируются восемью битами. Для многих языков этого совершенно недостаточно, зато отвечает реалиям того времени.
Это также означает, что для преобразования из нижнего в верхний регистр мы можем использовать милую особенность ASCII. «A» в верхнем регистре представлена в ASCII кодом
65, а буква «a» в нижнем регистре представлена кодом 97. Если вам знакомы степени двойки, то вы должны были заметить эту разницу.Итак, оказывается, буквы в нижнем регистре задаются числом, которое ровно на 32 больше, чем число буквы в нижнем регистре. Если мы знаем, что значение находится в нужном интервале, нам достаточно всего лишь вычесть 32!
Такой подход сработает, но мы можем и просто немного модифицировать биты. В случае Retroputer это не будет быстрее, чем вычитание, однако при отсутствии вычитания нам не придётся во время выполнения вычислений обращать внимание на флаг переноса/заимствования. Оказывается, мы можем использовать побитовое
and, чтобы отключить бит в месте значения 32.and al, 0b1101_1111 # turn off bit in 32-place
# versus
clr c # clear carry
sub al, 32 # subtract 32Но тут есть одна тонкость: не всё можно преобразовать в верхний регистр. Например, если пользователь добавил строковый литерал, то нам нужно быть более внимательными, ведь мы не хотим, чтобы Retroputer BASIC постоянно кричал на пользователя капсом. (Хотя у многих компьютеров той эпохи не было нижнего регистра, у Retroputer такого ограничения нет.)
Например:
print "Hello, World!"
' should become:
PRINT "Hello, World!"
' and not
PRINT "HELLO, WORLD!"Это означает, что нам нужно отслеживать, не находимся ли мы посередине строкового литерала. В BASIC есть только одно обозначение этого: двойные кавычки. Если символ является двойной кавычкой, мы можем установить флаг и в зависимости от значения флага выполнять преобразование в верхний регистр или оставить всё как есть.
Оказывается, в JavaScript для этого нет встроенной функциональности, но мы можем создать её сами:
const len = theLine.length;
let insideString = false;
for (let i = 0; i < len; i++) {
const ch = theLine[i];
if (ch === `"`) insideString = !insideString;
if (!insideString) {
const newCh = ch.toUpperCase();
if (ch !== newCh) theLine[i] = newCh;
}
}Теперь логика на JS более точно соответствует ассемблерной версии, хотя мы снова немного используем возможности поддержки Unicode в JS.
Версия на ассемблере выглядит так:
ld y, 0 # y is our index
ld bl, 0 # === insideString (false)
_loop: ld al, [d, x, y] # [d,x] is pointer to string
cmp al, 34 # is al a double quote?
brs !z check_char # no? should we uppercase it?
xor bl, 0xFF # yes? toggle insideString
_check_char:
cmp bl, 0xFF # inside a string?
brs z _continue # yes? don't modify it
cmp al, 97 # is al (char) in range? "a"
brs n _continue # Not a lowercase char; continue
cmp al, 123 # high portion "z"
brs !n _continue # not a lowercase char; continue
and al, 0b1101_1111 # uppercase!
st [d, x, y], al # store back (we modify the original)
_continue: inc y # move our index along
cmp al, 0 # check for NULL
brs !z _loop # No? Go back for more.Пока мы выполнили только преобразование вводимого текста в верхний регистр, но можно использовать определение строкового литерала ещё для другой возможности. Мы можем выполнить ещё одну проверку синтаксиса!
Если в конце процесса мы выясним, что
inString по-прежнему истинно (bl = 0xFF), то можем вернуть ошибку, потому что это означает что где-то в строке есть незавершённый строковый литерал.Примечание: оказалось, что многие версии BASIC довольно снисходительно относятся к отсутствию закрывающих кавычек у строк. Это я выяснила при создании собственного интерпретатора. Хоть это и так, мне не кажется такое правильным, поэтому Retroputer BASIC не позволяет этого.
Токенизация
Следующий этап парсинга заключается в преобразовании введённой строки в нечто более эффективное для выполнения интерпретатором Retroputer BASIC. Мы стремимся максимально близко подойти к концепции абстрактного дерева синтаксиса, но результат всё равно не будет деревом. Но это будет нечто, что мы сможем быстро обрабатывать во время выполнения.
Общей чертой первых микрокомпьютеров была очень ограниченная память. Retroputer имеет больше памяти, чем большинство стандартных машин того времени, но её всё равно намного меньше, чем у современных компьютеров. Поэтому длинные программы на BASIC запросто могут занять слишком много памяти, если они сохраняются в процессе ввода пользователем.
Для экономии места ключевые слова в процессе ввода программы в память токенизируются. Этот процесс преобразует ключевые слова в однобайтовые токены. Ключевые слова всегда имеют длину не менее двух байтов, так что при вводе экономия становится больше. Также это означает, что мы можем использовать во время выполнения таблицу поиска для вызова соответствующих процедур языка ассемблера.
Однако Retroputer BASIC заходит немного дальше, чем большинство версий BASIC того времени. Сверх того он преобразует числа в двоичный вид, помечает строки, вычисляет ссылки на переменные, и многое другое. Если честно, из-за этого тратится больше места, но преимущества скорости (и простоты выполнения) перевешивают этот недостаток.
Итак, здесь используются следующие этапы:
- Токенизация чисел
Числа преобразуются в двоичный вид, чтобы не преобразовывать их каждый раз, когда они встречаются в программе. Если числа встречаются только один раз, то рост производительности оказывается не таким большим, но в цикле с большим количеством вычислений это выгодно, потому что число уже представлено в виде, который может понять компьютер. - Пометка строк
Так как память ограничена, если в коде есть строка, которую можно использовать без изменений, то логично будет так и поступить. Например,PRINT "Hello, World"может выводить «Hello, World» непосредственно из строки программы вместо выделения нового пространства, копирования строки и её вывода.
Чтобы упростить пропуск строк во время выполнения программы, мы также храним длину самой строки. - Поиск в таблице ключевых слов
Всё, что не является числом или строкой, может быть ключевым словом, поэтому нам нужно выполнять поиск по списку ключевых слов. Это тривиально на JavaScript, но совсем непросто на ассемблере!
После нахождения ключевого слова связанный с ним токен сохраняется в памяти программы (вместо всего ключевого слова целиком). В результате этого мы можем сэкономить много пространства, особенно когда команду типаPRINTможно сократить до одного байта! - Вычисление указателей на переменные
Имена переменных Retroputer BASIC значимы только до первых двух символов (на данный момент). Благодаря этому можно тривиальным образом искать переменную в массиве при помощи довольно простого математического выражения. Но даже в таком случае вычисления занимают время, поэтому было бы здорово, если бы нам не приходилось этого делать при встрече с переменной.
Retroputer BASIC будет вычислять индекс и хранить его вместе с именем переменной. Кроме имени переменной он также хранит длину переменной, чтобы ускорить выполнение программы. Это занимает большое количество пространства и не было бы хорошим решением для компьютеров с ограниченной памятью, но подходит для Retroputer BASIC.
В посте я не буду подробно рассказывать о реализации этого этапа на языке ассемблера, оставлю его на будущее. Но не волнуйтесь, кода там много.
Проверка синтаксиса во время выполнения программы
Последним, но не менее важным этапом является проверка синтаксиса во время выполнения. После преобразования кода в токенизированный вид реализовать его довольно легко.
Во-первых, на этапе выполнения BASIC проверяет, обрабатывает ли он в данный момент токен. У всех токенов включен старший бит (то есть они имеют значение от 128 и выше). Если обнаружен токен, то мы можем определить, какую подпроцедуру нужно вызвать, найдя её в таблице векторов. Кроме того, это делает тривиальным отображение ошибок синтаксиса — некоторые ключевые слова не имеют смысла в качестве операторов, поэтому таблица векторов просто указывает на процедуру, генерирующую синтаксическую ошибку.
После вызова обработчика токена оператора обработчик берёт на себя всю дополнительную работу по парсингу. Для получения токенов и перехода между ними он может использовать
gettok, gettok-raw, peektok и т.д. Если токен представляет собой нечто, не ожидаемое процедурой, то процедура просто возвращает код ошибки. Именно на этом этапе отлавливаются и синтаксические ошибки, и ошибки согласования типов.В случае, если оператор должен вычислить выражение, то выполняется другой этап парсинга. Во время парсинга выражения используется ещё одна таблица поиска векторов, то есть мы можем перехватывать ключевые слова, не относящиеся к математическому выражению, и возвращать соответствующие ошибки. Например, если попробовать ввести
PRINT 2+CLS, то мы получим синтаксическую ошибку на CLS (CLS — это ключевое слово-сокращение от «clear screen»).Примечание: из этой таблицы мы также можем определять приоритет математических операторов и количество необходимых параметров. Это важно для самого вычисления выражения, но это можно также использовать для перехватывания случаев, когда пользователь не указал достаточное количество аргументов.
Так как токен напрямую сопоставляется с элементом таблицы поиска векторов, выполнение программы может выполняться довольно быстро и с минимальными усилиями. Задача парсинга каждого типа операторов поручается самому обработчику, и в общем случае это не вызывает особых проблем. Наверно, самыми сложными для парсинга являются
PRINT и INPUT, но на каждом шаге за раз берётся по одному токену.Поскольку многие проверки не выполняются до времени выполнения программы, это означает, что до возникновения ошибки у нас могут быть частичные результаты. Например:
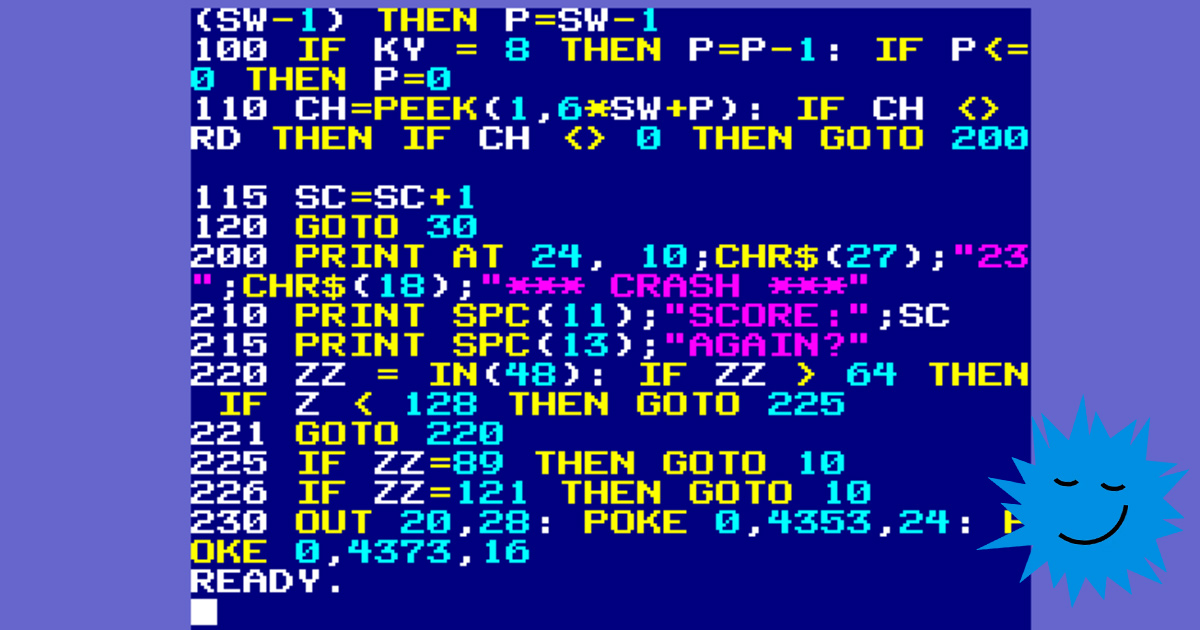
PRINT "Hello";CLS
Hello
?Syntax ErrorКроме того, это означает, что если программа оставляет экран в состоянии, в котором мы не можем видеть текст, то у нас могут возникнуть проблемы с устранением ошибок. Если выводится синтаксическая ошибка, но мы её не видим, то что нам делать?
У такого способа проверки синтаксиса определённо есть свои недостатки, однако он позволяет реализовать довольно простой интерпретатор.
Токенизация пользовательского ввода
Как упоминалось ранее, обычно версии BASIC той эпохи использовали тактику токенизации. Для экономии пространства и повышения скорости выполнения ключевые слова «ужимались» в однобайтные токены (или двухбайтные, если нужно больше ключевых слов).
Давайте представим, что у нас есть простая строка кода, очищающая экран и печатающая стандартное приветствие:
CLS: PRINT "Hello, World"Хотя само по себе это не занимает особо много памяти, если писать длинную программу, то множество слов в этой программе будет ключевыми словами. Если сжать их (токенизировать), то можно сэкономить солидную долю пространства. Например, после токенизации показанной выше строки в памяти будет находиться примерно такое:
8A E3 B5 FC Hello, World 00 00Не составит особого труда преобразовать это обратно в исходную конструкцию:
| Байт | Ключевое слово | Примечания |
|---|---|---|
| 8A |
CLS |
|
| E3 | ":" | Конец конструкции |
| 32 | " " | Мы храним не более одного пробела |
| B5 |
|
|
| FB | Строка в коде | Далее идёт строковый литерал |
| Hello, World, 00 | Строки завершаются нулевым байтом | |
| 00 | Конец строки кода | Строки кода тоже завершаются нулевым байтом |
Возможно, вам покажется, что это большой объём работы, зато и экономия пространства может быть значительной. В примере это не особо заметно, но даже по нему можно представить, как быстро может накапливаться сэкономленное пространство. В данном случае сжатый результат имеет размер 19 байт. Исходный текст состоит из 26 байт (с учётом завершающего нулевого байта).
Экономия пространства становится важной, если речь идёт об интерпретаторе BASIC, работающем на машине с очень малым количеством ОЗУ под пользовательские программы. Поэтому такое сжатие очень важно и привлекательно, даже если бы оно не имело дополнительных преимуществ.
Итак, как же нам токенизировать нечто подобное? Поначалу кажется, что на JavaScript это делается достаточно тривиально. Имея массив строк, можно быстро заменить каждое ключевое слово соответствующим токеном. Правда?
Кажется, это работа для
String#replace? При наивном подходе можно попробовать нечто подобное:const tokens = ["CLS", "PRINT", ":" ];
function tokenize (inStr) {
const newStr = inStr;
tokens.forEach((token, idx) => newStr = newStr.replace(
new RegExp(token, "g"), String.fromCharCode(128+idx)
);
return newStr;
}К сожалению, вскоре мы осознаем, что не можем заменять токенами строковые литералы. Это значит, что нужно выполнять обработку посимвольно, с учётом контекста, чтобы не сжимать элементы, не являющиеся ключевыми словами.
Этот новый алгоритм более близок к коду на языке ассемблера в Retroputer, но JS всё равно сильно упрощает работу. Вот начало кода на JS (в этом посте мы постепенно будем его дополнять):
const tokens = ["CLS", "PRINT", ":" ];
function tokenize(inStr) {
let out = []; // return value is "crunched" array
let idx = 0; // index into inStr
let ch = ""; // current character
while (idx < inStr.length) {
ch = inStr.charCodeAt(idx); // get the current character code
// our logic is going to go here
out.push(ch); // for now push the character
idx++; // and keep going (next char)
}
out.push(0); // we end with NUL
return out;
}Мы начинаем с очень упрощённого списка токенов, потому что никому не захочется видеть всю таблицу в таком формате (она длинная, а таблицы токенов Retroputer на самом деле создаёт из файла JS!), но для наших целей этого будет достаточно. Принцип здесь заключается в том, что когда мы видим токен, то записываем его индекс в выходной массив.
На этом этапе у нас есть функция, которая пока просто преобразует строку в эквивалентные ей коды символов. Пока она не особо полезна, но может служить удобным каркасом.
Версия на языке ассемблера довольно похожа на показанную выше.
do {
call _get-source-index # get next character index (in y)
dl := <BP+source>,y # read next char from our source string (ch)
call _adv-source-index # advance our source index
call _get-target-index # get position in target ("out" in JS)
<BP+target>,y := dl # store to target (out[y] = ch)
call _adv-target-index # move it along
cmp dl, 0 # was char 0? if so, break
} while !zЯ не включил в пример выше
_get-source-index или другие функции, потому что их задачи понятны из названия: они просто получают, задают исходный и целевой индексы, а также перемещаются по ним. Стоит заметить что в отличие от JS, в языке ассемблера нет динамически выделяемых массивов, поэтому этот алгоритм выделяет буфер достаточного размера. При перемещении по входной строке мы должны знать, куда записывать следующий токен в целевом буфере, и что целевой индекс делает выше. Каждая из вызываемых выше функций возвращает индекс в Y. Например, функция _adv-target-index увеличивает целевой индекс на единицу (эквивалент y++).Аккуратнее с литералами
Нам нужно быть внимательными: строковые литералы могут сбить с толку токенизатор — мы не можем просто заменить каждую соответствующую ключевому слову строку символов значением токена. Если мы видим строковый литерал, в котором есть «CLS», то не должны стремиться токенизировать его. Он не должен быть исполняемым, и если мы выведем его… то вместо него выведем соответствующий токену байт. Скорее всего, разработчик подразумевал не это.
С другой стороны, численные литералы не должны иметь подобной проблемы, потому что в BASIC нет ключевых слов в виде чисел. Но даже в таком случае, нет никакого смысла, столкнувшись с числом, выполнять поиск ключевого слова — зачем зря тратить время?
Токенизация строковых литералов
Итак, давайте для начала проверим, начинается ли строка — в JS это сделать не особо сложно:
if (ch === 34) {
out.push (0xFB); // string-in-code token
idx++;
ch = inStr.charCodeAt(idx); // get next character after the quote
while (ch !== 34 && idx < inStr.length) {
out.push(ch);
idx++;
ch = inStr.charCodeAt(idx);
};
idx++; // go past the quote
out.push(0); // end of string
continue;
}Двойная кавычка представлена кодом символа 34. Другие языки программирования могут распознавать намного больше стилей кавычек (например, JS или C), но с BASIC всё просто: или двойные кавычки, или ничего.
Когда мы видим, что начинается строка, то можем просто брать оставшиеся символы и добавлять в выходной массив, пока не встретим ещё одну кавычку.
После считывания всей строки нужно добавить нулевой байт, потому что Retroputer BASIC использует строки в стиле C. Если бы мы хотели использовать строки в стиле Pascal, то могли бы хранить счётчик и вставлять длину строкового литерала. В любом случае, это не вызывает особых проблем. Единственная причина, по которой я использовала строки, завершающиеся нулевым байтом, заключается в том, что с ними очень просто работать на языке ассемблера — нам достаточно просто сравнивать с нулевым байтом, а не хранить счётчик.
Итак, JavaScript был не особо сложным. Думаю, большинство из вас решило бы использовать нечто более абстрактное, например, регулярное выражение. Мне кажется, этот код сделает наши намерения более очевидными.
if (ch === 34) {
out.push (0xFB); // string-in-code token
const stringLiteral = inStr.substr(idx+1).match(/^[^"]*/)[0];
idx += stringLiteral.length+1;
out.push(...Array.from(stringLiteral, ch => ch.charCodeAt(0)));
idx++; // go past the quote
out.push(0); // end of string
continue;
}Приведённый выше код примерно такой же, но вместо посимвольной проверки мы позволяем JS просто выполнить
match. Мы знаем, что получим совпадение (мы ведь находимся в строке), поэтому нам даже не нужно проверять, было ли совпадение удачным. Затем мы выполняем инкремент индекса на длину строки и копируем символы в выходной массив. По моему мнению, такой код гораздо легче понять (однако он подразумевает понимание регулярных выражений, а также особенностей синтаксиса ES6, например, … и стрелочных функций).Разумеется, на языке ассемблера нам придётся вручную проделывать всю работу, которую выполняет JS. Результат оказывается очень похожим на нашу первую попытку создания кода на JS:
cmp dl, constants.QUOTE # is dl a quote?
brs !Z not-a-string # nope; not a string
call _get-target-index # get next position in crunch target
dl := brodata.TOK_CODE_STRING # "String" token
<bp+target>,y := dl # Store it into the crunch target
call _adv-target-index
still-a-string:
call _get-source-index
dl := <bp+source>,y # get string character
call _adv-source-index
cmp dl, constants.QUOTE # if it's a quote, we can zero it
if Z {
dl := 0
}
call _get-target-index
<bp+target>,y := dl # write to target
call _adv-target-index
cmp dl, 0 # are we done?
brs !Z still-a-string # no, keep going
continue # next!
not-a-string:Стоит добавить замечание о парсере языка ассемблера Retroputer — он имеет базовую поддержку высокоуровневых конструкций, например, блоков и циклов. Поэтому
if Z {…} будет выполнять содержимое внутри блока при установленном нулевом флаге, а continue можно использовать для ветвления обратно к началу блока (break также используется для выхода из блока). Ассемблер преобразует это в различные инструкции сравнения и ветвления, поэтому CPU не видит высокоуровневых частей кода, но это немного упрощает написание кода.Токенизация чисел
Кроме того, не имеет смысла пытаться искать в списке ключевых слов числа, поэтому мы можем просто их пропускать. Большинство версий BASIC делают нечто похожее на показанную выше процедуру обработки строк — если считанный символ является цифрой, он будет конкатенирован с выходными данными, после чего за дело примется сжиматель.
Retroputer BASIC (и некоторые другие версии BASIC, например, Atari BASIC) делает ещё один шаг вперёд: он преобразует число в соответствующий двоичный формат. Это сделать очень легко — если мы встречаем цифру, то умножаем накопитель на 10 и прибавляем цифру, продолжая так, пока продолжают встречаться цифры. (Однако стоит заметить, что пока Retroputer BASIC работает только с целочисленными значениями, добавление чисел с плавающей запятой уже в моём списке todo.)
(Надо сказать, что в настоящее время Retroputer BASIC ничего не делает, когда происходит целочисленное переполнение, знаковое или беззнаковое. Когда я добавлю числа с плавающей запятой, Retroputer будет преобразовывать и в вид с плавающей запятой.)
Retroputer BASIC делает и ещё один шаг вперёд: он также распознаёт шестнадцатеричные числа и преобразует их в двоичный эквивалент. В качестве обозначения таких чисел используется
0x (как и в JS), а сам язык имеет дополнительную логику, обеспечивающую возврат ошибки, если указано несколько символов x.На языке ассемблера проверка того, является ли символ цифрой, не так уж сложна, но для этого требуется пара сравнений: нужно убедиться, что код символа находится между
0x30 и 0x39. (Это коды символов «0» и «9».)Получив символ-цифру, мы можем воспользоваться ещё одним удобным свойством набора символов.
0x30 — это код символа «0», 0x31 — код «1», и так далее. При желании мы могли бы вычесть 0x30, но есть способ попроще: достаточно отбросить четыре старших бита:and dl, 0b0000_1111К сожалению, это не сработает, если нам нужно обрабатывать шестнадцатеричные числа. В этом случае можно выполнить вычитание, а затем сравнить с 10, а потом снова уменьшить на 7, если код больше 10 (учитывая, что шестнадцатеричные числа — это «A»-«Z» в верхнем регистре).
В JS можно снова использовать регулярные выражения, а затем, когда получим совпадение числа, можно вызвать
Number(), что даёт нам ещё одно преимущество: шестнадцатеричные числа тоже преобразуются тривиально, потому что Number() делает это автоматически, если число начинается с 0x.Как же это будет выглядеть на JavaScript?
if (ch >= 48 && ch <= 57) {
out.push (0xFD); // number token
const numberLiteralStr = inStr.substr(idx).match(/^[\d|A-F|a-f|x|X]+/)[0];
idx += numberLiteralStr.length;
const numberLiteral = Number(numberLiteralStr);
const bytes = new Uint8Array(new Uint16Array([numberLiteral]).buffer);
out.push(...bytes)
continue;
}Регулярное выражение позволяет использовать любые сочетания цифр или шестнадцатеричных цифр (плюс
x для перехода в шестнадцатеричный режим). Выражение неидеально, например, оно позволяет использовать несколько x, но пока этого вполне достаточно.В приведённом выше коде может вызывать вопросы преобразование числа в байты.
Number() выполнила всю сложную работу по превращению строки цифр в число, с которым может работать JavaScript, но теперь нам нужно представить его в виде последовательности байтов. Для такого преобразования можно использовать математику:const hiByte = (numberLiteral & 0xFF00) >> 8;
const loByte = (numberLiteral & 0x00FF);… и для целого числа это сделать легко. Но благодаря использованию типизированных массивов JS можно не заниматься всеми этими вычислениями, а заодно подготовиться к обработке чисел с плавающей запятой в будущем (мы просто заменим
Uint16Array на Float64Array).Код для выполнения этой задачи на языке ассемблера немного длиннее, зато он и делает немного больше. Retroputer использует ещё одну оптимизацию: если число мало, то оно сохраняется в меньшем формате. Это означает, что 0-255 можно хранить в одном байте, а более длинные числа занимают два.
Поиск ключевых слов
Итак мы проделали довольно много работы, но пока так и не сжали ни одного ключевого слова. Разобравшись с числами и строковыми литералами, мы можем быть уверенными, что всё остальное является или ключевым словом, или именем переменной. (Или же пробелом, но это легко проверить.)
В BASIC ключевые слова не всегда начинаются с алфавитного символа, токенами также считаются операторы и разделители. Но переменные тоже начинаются с алфавитного символа. Так что мы не можем сразу определить, что будем сжимать — ключевое слово или переменную. Это нас устраивает — если мы не найдём совпадения в списке токенов, то будем считать, что это переменная.
Как же нам проверить, что потенциальное ключевое слово действительно им является? Если бы мы писали на JavaScript, то могли бы использовать метод
Array#findIndex.const tokenMatch = tokens.findIndex(token =>
inStr.substr(idx).startsWith(token));
if (tokenMatch > -1) {
out.push(tokenMatch + 128);
idx += tokens[tokenMatch].length;
continue;
}Метод
Array#findIndex итеративно обходит массив tokens и мы можем проверить, начинается ли inStr (по текущему idx) с проверяемого нами токена. Работая с нашим упрощённым списком токенов, мы сделаем нечто подобное (предположим, что inStr.substr(idx)===”PRINT”):| token | .startsWith(token)? | Индекс |
|---|---|---|
| CLS | false | 0 |
| true | 1 |
Примечание: как и в случае
indexOf в JS, если ничего не найдено, мы получаем -1.Если совпадение найдено, можно сохранить его индекс в возвращаемом массиве. Но как нам позже отличить токен от символа? Легко: включим старший бит, а это можно сделать, прибавив к значению токена 128.
(Примечание: если нам нужно больше токенов, чем 128, то для некоторых токенов пришлось бы использовать два байта. Это немного всё усложняет, но не так сильно. В некоторых версиях BASIC это реализовано, например, в различных Microsoft BASIC.)
Мы закончили работу на JavaScript, но как нам это сделать на языке ассемблера?
Оказывается, почти так же, но код будет намного длиннее.
search-keywords:
bl := [d, x] # get first character of current token
cmp bl, constants.NUL # if it's NUL, we've exhausted the list
brs Z exit-keyword-search # so we're clearly not a keyword
clr Z # compare strings, but with partial equality
call [vectors.STRCMP] # so that our source doesn't need NUL between
# tokens; c will now be how many chars got
# compared
if !Z {
do { # no match; advance past our token in the list
inc x # character by character
bl := [d, x] # tokens are terminated with NULs
cmp bl, constants.NUL # so if we see it, we can stop
} while !z
inc x # go past the token #
inc x # in the lookup table
brs search-keywords # and keep looking for a match
}
clr c # found the match!
add x, c # c is the length of the match
inc x # past the NUL
bl := [d, x] # bl is now the token #
call _get-target-index
<bp+target>,y := bl # write the token #
call _adv-target-index
call _get-source-index # advance past the token in the source
clr c
add y, c # by adding the character count
dec y # back off by one (we'll advance again later)
call _set-source-index
continueНу всё выглядит не так уж плохо. Алгоритм почти такой же, только таблица токенов на языке ассемблера структурирована немного иначе. Она выглядит примерно так:
CLS 00 80
PRINT 00 81
: 00 82Каждое ключевое слово завершается нулевым байтом, за которым следует номер токена.
Однако мы упускаем здесь нечто важное — как же вообще выполняется это сравнение строк? В ядре Retroputer есть процедура
STRCMP, которой мы можем воспользоваться, но как она выглядит?strcmp: {
enter 0x00
push a
push b
push d
push y
pushf
if Z {
bl := 0x00 # Checking for full equality
} else {
bl := 0x01 # only checking for partial equality
}
_main:
y := 0 # start of string
top:
cl := [d, x, y] # character in string A
al := <bp+4>,y # character in string B
cmp bl, 0x01 # check if we're doing full equality
if Z {
cmp cl, 0 # we're not, so check for an early nul
# in string b
brs Z strings-are-equal # if it's NUL, we calling them equal
}
cmp cl, al # check character
if Z {
cmp cl, 0 # equal, but check for NUL
brs Z strings-are-equal # NUL reached, strings are equal
inc y # next character
brs top # not NUL, so keep going...
}
# if here, the strings aren't equal
if N {
popf # string is less than
set N
clr Z
brs _out
} else {
popf # string is greater than
clr N
clr Z
brs _out
}
strings-are-equal:
popf
clr N # Not less than
set Z # but Equal
_out:
c := y # make sure we know how many chars
# were compared
pop y
pop d
pop b
pop a
exit 0x00
ret
}
Не знаю как вы, а я всё больше и больше начинаю любить метод
String#startsWith из JS. Да, он делает то же самое, но нам не приходится писать всю внутреннюю логику!Обработка переменных
Работа над сжатием ключевых завершена, так что мы можем закончить. Но Retroputer BASIC делает ещё один шаг вперёд — токенизирует переменные. Мне кажется, так поступали только немногие версии BASIC из 80-х и 90-х, потому что в условиях ограниченной памяти это может вредить. Но если памяти много, то токенизация переменных помогает повысить производительность.
Вот что делает Retroputer BASIC:
- Он считывает до двух первых символов имени переменной. (Это было стандартным неудобством версий BASIC той эпохи из-за ограничений памяти.)
- По этим двум символам он определяет индекс переменной. «A» — это переменная 0, «A0» — переменная 53, и т.д. Уравнение довольно простое, но сейчас оно нас не интересует.
- BASIC продолжает сканирование в поисках символа типа переменной. Например,
$в BASIC обозначает строковую переменную. Тип переменной хранится парой битов выше в индексе переменной. - Затем BASIC записывает тип и индекс в выходные данные, а потом вместе с самим именем переменной записывает длину этого имени. Именно на этом мы теряем экономию пространства!
(Примечание: когда Retroputer BASIC научится динамически выделять память под переменные, мы заменим индекс указателем на переменную. Ещё один пункт в списке todo!)
Благодаря этому поиск переменных во время выполнения становится невероятно быстрым: нам не нужно парсить имя переменной и вычислять индекс каждый раз, когда мы встречаем переменную. В сплошных циклах экономия может быть солидной. Но за это приходится платить большую цену: нам нужно хранить указатель и имя переменной вместе, поэтому для каждой встреченной переменной нам нужно добавлять в выходные данные по четыре лишних байта.
Вам решать, стоит ли оно того.
Как бы то ни было, на JavaScript тоже легко определять, является ли оставшееся в потоке символов переменной:
const variableMatch = inStr.substr(idx).match(/^[A-Z]+[A-Z0-9]*[\$]*/);
if (variableMatch) {
const variableName = variableMatch[0];
idx += variableName.length;
// tokenize it (omitted; nothing new here)
continue;
}Я не буду подробно описывать код, который сейчас Retroputer использует для токенизации переменных, он слишком многословен. Мы вернёмся к нему, когда я добавлю динамическое выделение памяти под переменные.
Токенизация завершена
Если теперь протестировать наш код на JS, то мы получим массив байтов, похожий на тот, который Retroputer BASIC использует внутри:
console.log(toHex(tokenize(`CLS: PRINT "Hello, World"`)));
// 80 82 20 81 20 FB 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 00 00 Ого, какой объём работы для экономии нескольких байтов. Но когда свободной памяти всего пара килобайтов, оно того стоит! Но это не единственное преимущество сжимания вводимого пользователем текста, мы ещё и ускоряем выполнение программы.
Чтобы объяснить, почему так получается, нам нужно понять, как Retroputer исполняет код. Пока я не буду вдаваться в подробности, но вкратце для исполнения кода требуется следующее:
- Получаем байт из памяти
- Если у байта включен старший бит, то это токен, а в противном случае это синтаксическая ошибка (или NUL; в любом случае, на этом мы заканчиваем работу со строкой программы)
- Ищем обработчик токена в массиве — этот массив содержит указатели на сами функции, которые обрабатывают токен
- Вызываем обработчик (он отвечает за получение аргументов и тому подобное)
- Повторяем всё заново
Это ещё одна причина токенизации ключевых слов — выполнение логики ключевого слова становится тривиальным, достаточно найти адрес в массиве и вызвать его.
Хотелось бы подчеркнуть, что несмотря на важность токенизации для экономии пространства, она также повышает скорость выполнения.
Например, цикл выполнения на JS может выглядеть примерно так:
const handlers = [ cls, print, endOfStmt ];
bytes.forEach(byte => handlers[byte] && handlers[byte]());Разумеется, на самом деле всё не так просто, он гораздо больше, но это уже тема для другого поста!
Ресурсы
- Полный код этого поста на JavaScript
- Исходный код Retroputer (на текущем этапе развития)
- Список ресурсов, использованных для этого проекта
На правах рекламы
Мощные VPS с защитой от DDoS-атак и новейшим железом. Всё это про наши эпичные серверы. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
