
IBM Watson — одна из первых когнитивных систем в мире. Эта система умеет очень многое, благодаря чему возможности Watson используются во многих сферах — от кулинарии до предсказания аварий в населенных пунктах. В общем-то, большинство возможностей Watson не являются чем-то уникальным, но в комплексе все эти возможности представляют собой весьма мощный инструмент для решения разнообразных вопросов.
Например — распознавание естественного языка, динамическое обучение системы, построение и оценка гипотез. Все это позволило IBM Watson научиться давать прямые корректные ответы (с высокой степенью достоверности) на вопросы оператора. При этом когнитивная система умеет использовать для работы большие массивы глобальных неструктурированных данных, Big Data. Каковы основные принципы работы IBM Watson с языком? Об этом — в продолжении.
Основные сложности распознавания естественного языка
Для человека язык — это средство выражения мысли. Мы используем язык для передачи своего мнения, каких-либо данных и сведений. Можем делать прогнозы и формировать теории. Именно язык — краеугольный камень нашего сознания. При этом, вот парадокс, язык человека очень неточный.
Многие термины — нелогичны, и компьютерным системам понять нас бывает очень сложно. Например, как может быть тонким голос? Как можно сгореть со стыда? Для машины это — проблема, для человека же — вполне обыденная вещь. Дело в том, что для правильного ответа на вопрос во многих случаях необходимо учитывать имеющийся контекст. При отсутствии достаточной фактической информации трудно правильно ответить на вопрос, даже если вы можете найти точный ответ на элементы вопроса в буквальном смысле.
Обработка естественного языка — начало
Многие компьютерные системы способны анализировать язык, но при этом проводится поверхностный анализ. Это может иметь смысл, например, для того, чтобы поставить статистически обоснованную оценку тенденций в изменении эмоций на больших массивах информации. Здесь точность передачи информации не слишком важна, поскольку если даже если предположить, что число ошибочно-позитивных результатов примерно равно числу ошибочно-негативных результатов, то они компенсируют друг друга.
Но если значение имеют все случаи, то системы, которые работают с поверхностным анализом языка, уже не могут нормально делать свою работу. Ярким примером сказанному может быть задача для голосового помощника любого из мобильных устройств. Если сказать «найди мне пиццу», то помощник выведет список пиццерий. Если же сказать «не ищи мне пиццу в Мадриде», например, система все равно будет искать. Такие системы работают, идентифицируя некоторые ключевые слова и используя определенный набор правил. Результат может быть точным в заданной системе правил, но неправильным.
Глубокая обработка естественного языка
Для того, чтобы научить систему анализировать сложные смысловые конструкции, с учетом эмоций и прочих факторов, специалисты использовали глубокую обработку естественного языка. А именно — вопросно-ответную систему контентной аналитики (Deep Question*Answering, DeepQA). Если требуется большая точность, то приходится использовать дополнительные методы обработки естественного языка.
IBM Watson — система глубокой обработки естественного языка. При анализе определенного вопроса, для того, чтобы дать правильный ответ, система старается оценить как можно более обширный контекст. При этом используется не только информация вопроса, но и данные базы знаний.
Создание системы, способной провести глубокую обработку естественного языка, позволило решить и другую проблему — анализ огромного количества информации, которая генерируется ежедневно. Это неструктурированная информация, вроде твитов, сообщений социальных сетей, отчеты, статьи и прочее. IBM Watson научился использовать все это для решения задач, поставленных человеком.
Когнитивная система IBM Watson
Watson — это уже иной уровень вычислительных возможностей. Система умеет разделять определенные высказывания на естественном языке и находить связи между этими высказываниями. При этом Watson справляется с задачей, во многих случаях, даже лучше человека, при этом обработка данных идет гораздо быстрее, работа ведется с гораздо большими объемами — человек на такое просто неспособен.

Основные характеристики когнитивной системы
Система работает в таком порядке:
1. Получив вопрос, Watson выполняет его синтаксический анализ, чтобы выделить основные особенности вопроса.
2. Система генерирует ряд гипотез, просматривая корпус в поисках фраз, которые с некоторой долей вероятности могут содержать необходимый ответ. Для того чтобы вести эффективный поиск в потоках неструктурированной информации, нужны совершенно другие вычислительные возможности * их называют когнитивными системами. (не очень понимаю последнее предложение и роль звёздочки)
3. Система выполняет глубокое сравнение языка вопроса и языка каждого из возможных вариантов ответа, применяя различные алгоритмы логического вывода.
Это трудный этап. Существуют сотни алгоритмов логического вывода, и все они выполняют разные сравнения. Например, одни выполняют поиск совпадающих терминов и синонимов, вторые рассматривают временные и пространственные особенности, тогда как третьи анализируют подходящие источники контекстуальной информации.
4. Каждый алгоритм логического вывода выставляет одну или несколько оценок, показывающих, в какой степени возможный ответ следует из вопроса, в той области, которая рассматривается данным алгоритмом.
5. Каждой полученной оценке затем присваивается весовой коэффициент по статистической модели, которая фиксирует, насколько успешно справился алгоритм с выявлением логических связей между двумя аналогичными фразами из этой области в “период обучения” Watson. Эта статистическая модель может быть использована впоследствии для определения общего уровня уверенности системы Watson в том, что возможный вариант ответа следует из вопроса.
6. Watson повторяет процесс для каждого возможного варианта ответа до тех пор, пока не найдет ответы, которые будут иметь больше шансов оказаться правильными, чем остальные.
Как уже говорилось выше, для правильного ответа на вопрос системе необходимо обращаться к дополнительным источникам данных. Это могут быть учебники, мануалы, FAQ, новости и все прочее. Watson за считанные секунды обрабатывает огромные массивы информации для получения правильного ответа. При этом найденное содержимое тоже проверяется, отсеиваются устаревшие и бесполезные данные.
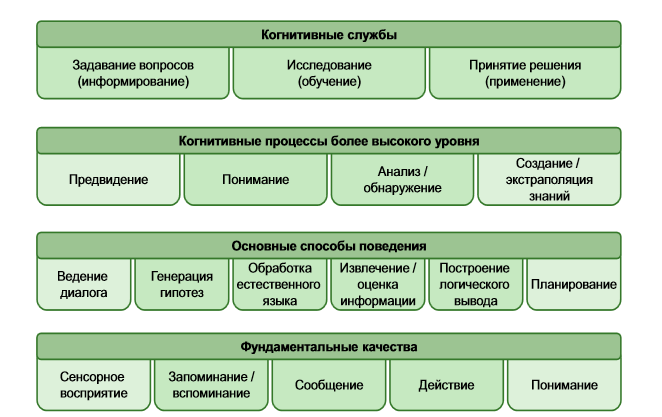
Элементы когнитивной системы
Общий смысл текста Watson выводит из полученной информации, из дополнительной базы. При этом используется заголовок документа, часть текста документа или весь текст.
Когнитивные системы, их способы сбора, запоминания и извлечения информации схожи с тем, как анализирует информацию человек. При этом когнитивные системы могут передавать информацию и действовать. Вот примеры поведенческих конструктов, которые используются в этом случае:
— способность создавать и проверять гипотезы;
— способность разбивать на составляющие и строить логические выводы о языке;
— способность извлекать и оценивать полезную информацию (такую как даты, местоположения и характеристики).
Без этих способностей ни компьютер, ни человек не смогут определить правильную взаимосвязь между вопросами и ответами.
Когнитивные процессы более высокого порядка могут достичь высокого уровня понимания, ориентируясь на основные способы поведения. Для того чтобы понять что-то, мы должны уметь разделить информацию на более мелкие элементы, которые достаточно хорошо упорядочены на рассматриваемом уровне. Физические процессы у человека протекают совсем не так, как процессы в космическом масштабе или на уровне элементарных частиц. Так же и когнитивные системы предназначены для работы на уровне человека, хотя они представляют огромное множество людей.
В связи с этим понимание языка начинается с понимания более простых правил языка – не только формальной грамматики, но и неформальных соглашений, которые наблюдаются в повседневном использовании.
Зачем все это?
Сейчас когнитивная система IBM Watson, благодаря многолетнему обучению и совершенствованию, может выполнять работу в самых разных сферах. Здесь и медицина, и кулинария, и лингвистика, и решение бизнес-задач с задачами научными.
Изначально у специалистов был выбор — сделать систему универсальной или специализированной. У каждого из вариантов есть свои достоинства и недостатки, но выбор был сделан в сторону универсальности.
Компания уже много раз убедилась в правильности совершенного выбора — перед IBM Watson открылось огромное количество возможностей. Например, когнитивная система помогает найти индивидуальный метод лечения раковых заболеваний, или составить оригинальнейший рецепт, или наладить бизнес-процесс в компании. Множество проблем решено, но еще больше только предстоит решить.

iCubeDm
По вашему мнению, возможно ли использование такого рода систем для онлайн-перевода с языка на язык?
Я говорю о случае, когда общается, например, японец, не знающий русского с русским, не знающим японского.
Сейчас это общение достигается благодаря использованию третьего не нативного языка (например английского).
Так вот, повторю вопрос. Возможно ли использование такого рода систем для решения такой ситуации, когда японец говорит на японском и моментально получает ответ на японском, а русский, в свою очередь, на русском?
Спасибо.
Whiteha
Конечно возможно с некоторыми доработками
marks
Конечно возможно. Более того, такие системы уже разрабатываются. Конечно, все это — не дело пары дней, но в конце-концов подобные вещи появятся, и станут привычными элементами нашего окружения.
iCubeDm
Можете привести примеры таких проектов, если не сложно?
akimovpro
ABBYY Compreno с переводом на другие языки может работать.
samodum
Это как-то странно идти по пути «испорченного телефона», используя для перевода третий язык. Никто из серьёзных переводчиков так не делает, это неверный путь.
Суть перевода с одного языка на другой (рус -> яп, яп -> рус) в том, чтобы представить структуру предложения в виде некоего дерева зависимостей и отношений между словами, а затем эту структуру перевести на другой язык.
iCubeDm
Я имел ввиду не переводчиков, а просто двух людей, владеющих каждый своим языком. Переводчик, по факту, тот же третий элемент системы — связующее звено.
Дабы прояснить ситуацию — приведу пример:
Международная компания по разработке некоего ПО.
В компании работают люди разных национальностей. Из них возьмем пару того же японца и русского, которым нужно работать над проектом. У обоих свои нативные языки и приобретенный английский. В такой ситуации они вынуждены общаться на английском языке, но от этого сильно падает эффективность (банально скорость передачи и усвоения информации на нативном языке на порядок выше).
Мой вопрос был в том, возможно ли при использовании подобных систем типа Watson исключить использование английского языка, а работать на нативном, который автоматом адаптировался бы под другой язык.
Фух, длинно вышло. Извиняюсь за многабукаф)
samodum
Вообще-то, это и есть основная цель машинного перевода. И над этой задачей бьются уже 70 лет.
iCubeDm
Но подобных инструментов до сих пор ещё не было. Поэтому вопрос вполне логичен, не так ли?)
Duduka
Напишите мето-систему, и отображение в нее этих двух языков. Задача не имееющая, сама по себе, решения.
samodum
Как это нет? А как работает любой переводчик? Google Translate, PROMT?
iCubeDm
Не думаю, что Google Translate, а особенно PROMT — когнитивные системы (=
Machine Learning, Big Data — да. Watson вроде бы как чуть другое.
samodum
Такие модные сегодня слова как «Machine Learning» и «Big Data» появились много позднее вышеперечисленных переводчиков. Вопрос: как они работали раньше?
iCubeDm
Ну наверняка те же алгоритмы назывались чуть менее модно. Сами теории не сказать, чтобы свежие, как французский багет.
samodum
На каких источниках (книг, публикаций, ...) основано это предположение?
iCubeDm
Конкретно данный комментарий основан исключительно на персональных предположениях. Именно поэтому было использовано слово «наверняка».
А с какой целью был развит такой дотошный интерес? Я что-то не то написал? Попрошу тогда разъяснить в чем я не прав.
samodum
За 70 лет написаны тонны книг. Есть что почитать, чтобы не основываться «исключительно на персональных предположениях»
iCubeDm
Спасибо за ценный совет. Учту на будущее.