
Предисловие
AWS — крупнейший поставщик облачных услуг. Общие облачные сервисы включают хранилище, вычислительную мощность, базы данных, аналитику, безопасность, мониторинг, инструменты разработчика, сети.
Cloud — это место, где вы храните свои данные/приложения/процессы и получаете к ним доступ в любое время через Интернет.
The Five Pillar

Инженеры AWS написали документацию с основными практиками для правильного и безболезненного размещения в облаке, найти его можно здесь. В эти практики входят:
- Operational Excellence
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
Разберем эти практики и Shared responsibility model в этом подкате.
Operation Excellence
Человеческая ошибка является основной причиной неисправностей и эксплуатационных происшествий. Чем больше операций можно автоматизировать, тем меньше вероятность человеческой ошибки.
Данная практика направлена на автоматизацию процессов, для того чтобы уменьшить фактор человеческой ошибки.
Две концепции:
- Infrastructure as a Code (ex. CloudFormation. CDK)
- Observability (Analytics, Metrics, Actions)
Infrastructure as a Code позволяет писать код для разворачивания сервисов AWS через yaml/json(CloudFormation) файлы или на любимом вами языке(Cloud Development Kit). Один раз пишете – много раз используете, ну разве не рай для DevOps?
Observability позволяет просматривать вашу инфраструктуру, собирать различные метрики и если происходит какая-нибудь плохая или ожидаемо хорошая ситуация, то в AWS вы можете на это настроить действие.
Пример плохой ситуации: Вы развернули большой сервис по доставке еды. Протестировали, всё работает идеально, приложение набирает популярность, ваш cloud engineer горизонтально масштабирует ваш сервис до 100 экземпляров, и в какой-то момент половина экземпляров приходит в не действие (предположим, что кто-то неправильно прикурил сигарету на ночном перекуре в датацентре AWS). И половина пользователей начинает жаловаться на не доступность доставки еды. А что делать ночью без еды?
Что же мы делали до того как узнали про operation excellence: звоним cloud engineer, он летит в офис к своему ПК, в треморе начинает разворачивать экземпляры в другом датацентре AWS. И ура, к утру все сервисы восcтановлены. Но клиенты уже потеряны, они нашли себе другую доставку. You lose!
Что же мы делаем после того как узнали про operation excellence: настраиваем метрику на минимальное количества экземпляров 100, и когда в следующий раз кто-то попробует прикурить – мы уже будем готовы и AWS за нас вернёт все не достающие экземпляры сразу же как произойдет проблема. You win!
Security
Фокусируется на том, как защитить вашу инфраструктуру в облаке. Три важные концепции, связанные с безопасностью в облаке:
- Identity and Access Management (IAM)
- Network Security
- Data Encryption
IAM – ключевой сервис AWS, который позволяет создавать пользователей, роли, группы, политики.
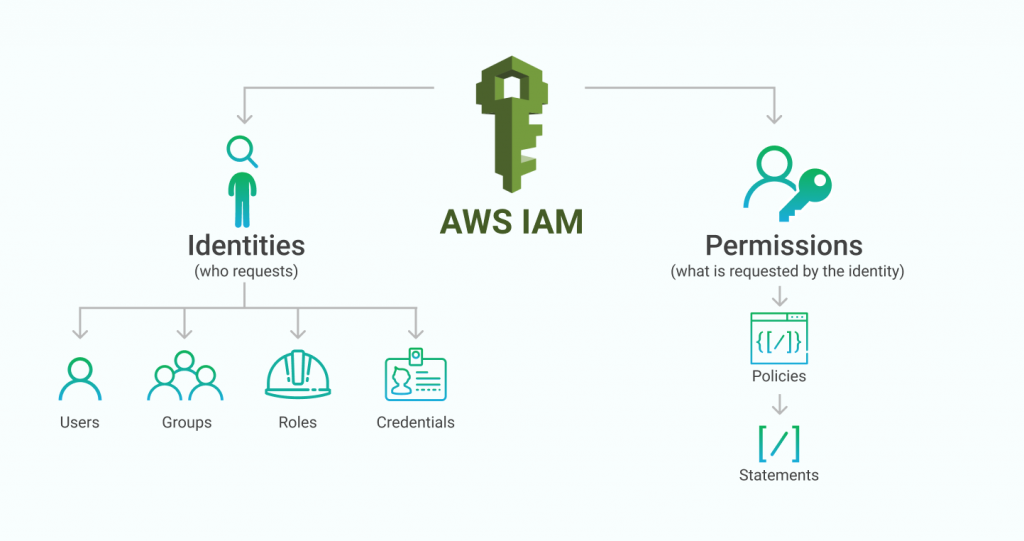
Network security – вы можете настраивать какой трафик может перемещаться по вашей сети в облаке, а какой нет. Все возможные виды фильтрации: от проверки headers в https запросах до портов tcp соединений.
Reliability
Фокусируется на том, как вы можете создавать сервисы, устойчивые к сбоям. Облако дает вам средства для создания отказоустойчивых сервисов, которые могут противостоять сбоям, чтобы вы проектировали свои сервисы с учетом надежности.
Две концепции для создания отказоустойчивых систем:
- Fault Isolation(Resource, Availability Zone, Region)
- Limits(soft and hard)
Fault Isolation говорит о том что стоит изолировать ваши сервисы от сбоев, чем меньше частей вашей системы выйдет из строя – тем лучше, казалось бы всё просто.
Что надо делать чтобы этого достичь? Делать ваши сервисы высокодоступными(high availability) вам поможет размещения ресурсов в разных датацентрах AWS, в разных регионах и зонах доступности.

Вторая концепция – настройка ограничений. Самый доступный пример защита от DDoS-атак, Тестируете рабочую пропускную способность своего приложения, ставите ограничение на приём максисум 150% от текущей пропускную способности, и “задудосить” вас не получится.
Performance Efficiency
Фокусируется на том, как вы можете эффективно и масштабируемо запускать службы в облаке. Хотя облако дает вам возможность обрабатывать любой объем трафика, оно требует, чтобы вы выбирали и настраивали свои службы с учетом масштабирования.
Две основные концепции:
- Selection
- Scaling
Первая концепция – выбор сервисов под ваши нужды. Выбирайте те сервисы которые подходят под вашу конкретную задачу. Если это пакетная обработка больших данных – есть AWS EMR, если потоковая – Kinesis, если миграция данных в облако – AWS DataSync. Все они оптимизированы под свою конкретную задачу.
Scaling позволяет увеличивать перфоманс вашего приложения с помощью нарастания мощностей экземпляра (vertical scaling) или увеличением их количества (horizontal scaling).

Cost optimization
Фокусируется на оптимизации затрат помогает достичь бизнес-результатов при минимизации затрат. Pay-as-you-go модель вносит следующие изменения в ваш процесс оптимизации затрат:
- Pay For Use
- Cost Optimization Lifecycle
Shared responsibility model
Эта модель показывает кто за что несёт ответственность в AWS.
С документации AWS: “AWS несет ответственность за защиту инфраструктуры облака AWS, на которой работают все предлагаемые сервисы. Эта инфраструктура состоит из аппаратного и программного обеспечения, сетей и объектов, на базе которых работают облачные сервисы AWS.
Ответственность клиента будет определяться выбранными для использования облачными сервисами AWS. Выбор сервисов определяет объем работ по настройке, которые должен выполнить клиент в рамках своих обязанностей по обеспечению безопасности. Клиенты, которые развертывают инстанс Amazon EC2, отвечают за управление гостевой операционной системой (включая обновления и исправления безопасности), любым прикладным программным обеспечением или сервисными компонентами, установленными на инстансах, и за настройку брандмауэра (группы безопасности), предоставляемого AWS, для каждого инстанса. В случае абстрактных сервисов, таких как Amazon S3 и Amazon DynamoDB, AWS управляет уровнем инфраструктуры, операционной системой и платформой, а клиенты получают доступ к конечным точкам для хранения и извлечения данных. Клиенты отвечают за управление своими данными (включая параметры шифрования), классификацию своих ресурсов и использование инструментов IAM для применения соответствующих разрешений.”
О чём это говорит? Если ядерная бомба упадёт на датацентр AWS – они берут ответственность за это происшествие на себя. И они будут оправдываться/возмещать ущерб. Если вы не шифруете данные при передачи с вашего компьютера и данные перехватили и украли – это ваша проблема.
Послесловие
Вы прочитали «AWS Cloud Core Concepts». В этом статье вы узнали следующее:
- Пять столпов архитектуры AWS
- Важные модели, которые представляют собой облачный образ мышления
- Ключевые концепции в рамках каждого из пяти столпов
- Shared responsibility model
Источники
aws.amazon.com/ru/getting-started/fundamentals-core-concepts
aws.amazon.com/ru/compliance/shared-responsibility-model