
Сегодня вместо решения абстрактных алгоритмических задач мы выступим в роли детектива, по крупицам доставшейся информации исследующего неэффективные запросы, и рассмотрим три реальных дела, встречавшихся в разное время на просторах нашего приложения СБИС, когда простота и наивность при написании SQL превращалась в дополнительную нагрузку для PostgreSQL-сервера.

Дедукция и индукция помогут нам вычислить, что же все-таки хотел получить от СУБД разработчик, и почему это получилось не слишком оптимально. Итак, сегодня нас ждут:
#1: Дело о

Давайте посмотрим на достаточно тривиальный запрос из недр функционала работы с каталогом товаров внутри складского учета, в котором вроде бы и ошибиться-то сложно.
Мы пока ничего не знаем ни о структуре базы, ни о том, что этот запрос должен сделать — восстановим все это, воспользовавшись утиным тестом:
Любую оптимизацию производительности я рекомендую начинать с выяснения, что же вообще происходит в запросе, для чего именно он нужен.
В целом, это достаточно простой запрос, который идет рекурсивно по номенклатуре, вычитывая на первом шаге карточки товаров по списку идентификаторов, который был передан параметром.
На этом же шаге, помимо самого ID номенклатурной карточки, мы получаем идентификатор ее предка по иерархии и начинаем формировать массив-путь.
Обратим внимание, что для каждой найденной записи номенклатуры будет произведен поиск связанной записи в соседней таблице
На каждом следующем шаге рекурсии будет происходить то же самое, но уже для записей карточек-предков по иерархии. А раз в запросе применено ключевое слово
Ну, и в финале мы оставляем только те записи, которые являются финальными в «цепочке» — то есть мы простроили путь «вверх» отдельно для каждого исходного идентификатора.
Какие очевидные проблемы при выполнении данного запроса нам грозят?
Обратим внимание на конкретный вариант плана такого запроса:
Во-первых, стоит избавиться от дубль-чтений одних и тех же карточек при движении вверх по иерархии.
Поскольку мы получили только набор самих записей, теперь нам надо выстроить из них «цепочки» потомок-предок рекурсивным спуском сверху-вниз:
Теперь из полученных «путей-из-ID» восстановим значение поля
Остался последний шаг — преобразовать цепочку ID в цепочку
В результате, целиком наш запрос будет выглядеть примерно так:

Второй запрос оказался намного «кучерявее», но интереснее с практической точки зрения, поскольку вызывается очень часто для получения информации о персонах как внутри нашей корпоративной социальной сети, так и другими сервисами, использующими ее.
Поскольку запрос достаточно объемный, я сразу скрою его под спойлером и буду приводить только варианты после каждого шага оптимизации, в результате которых он худел все сильнее и сильнее. Но сначала небольшое лирическое отступление.

Даже беглого взгляда на диаграмму выполнения достаточно, чтобы сразу увидеть, что в плане встречаются подозрительно одинаковые куски (
Эти субпланы соответствуют подзапросам по развороту массива пользователей из
Заметим, что все эти подзапросы работают с одним и тем же исходным набором данных, просто кто-то берет из него данные по одному условию, а кто-то по другому; кто-то сортирует, а кто-то — нет; кто-то берет все поля из всех записей, а кто-то только пару из первой…

План уже много приятнее и много короче. Кто самое слабое звено теперь?
Так, стоп… Мы в
Я это к тому, что мы сначала нашли, сгруппировали, сериализовали, потом достали, десериализовали, «развернули»… Что бы серверу не поработать-то?..
Кто теперь выглядит лишним?

Смотрим теперь на запрос очень-очень пристально, и задумываемся:

Итого, запрос мы ускорили больше чем в 2 раза, а упростили — на порядок. Будьте ленивее, не пишите много, не копипастите!

В этот раз я не буду подробно приводить запрос после каждой модификации, просто напишу мысли, которые возникли при анализе и приведу результат:
Надеюсь, вы почерпнули полезное для себя из сегодняшнего поста. А более подробно о каждом использованном способе оптимизации можно познакомиться в отдельных статьях моих циклов.
PostgreSQL Antipatterns:
SQL HowTo:
Дедукция и индукция помогут нам вычислить, что же все-таки хотел получить от СУБД разработчик, и почему это получилось не слишком оптимально. Итак, сегодня нас ждут:
- Дело о непростом пути вверх
Разберем в live-видео на реальном примере некоторые из способов улучшения производительности иерархического запроса. - Дело о худеющем запросе
Увидим, как можно запрос упростить и ускорить в несколько раз, пошагово применяя стандартные методики. - Дело о развесистой клюкве
Восстановим структуру БД на основании единственного запроса с 11JOINи предложим альтернативный вариант решения на ней той же задачи.
#1: Дело о непростом пути вверх
Давайте посмотрим на достаточно тривиальный запрос из недр функционала работы с каталогом товаров внутри складского учета, в котором вроде бы и ошибиться-то сложно.
WITH RECURSIVE h AS (
SELECT
n."@Номенклатура" id
, ARRAY[
coalesce(
(
SELECT
ne."Info"
FROM
"NomenclatureExt" ne
WHERE
ne."@Номенклатура" = n."@Номенклатура"
LIMIT 1
)
, '{}'
)
] res
, n."Раздел" -- предок по иерархии
FROM
"Номенклатура" n
WHERE
n."@Номенклатура" = ANY($1::integer[])
UNION -- уникализация
SELECT
h.id
, array_append(
h.res
, coalesce(
(
SELECT
ne."Info"
FROM
"NomenclatureExt" ne
WHERE
ne."@Номенклатура" = n."@Номенклатура"
LIMIT 1
)
, '{}'
)
) -- расширение массива
, n."Раздел"
FROM
"Номенклатура" n
, h
WHERE
n."@Номенклатура" = h."Раздел" -- двигаемся вверх по иерархии в сторону предков
)
SELECT
h.id
, h.res
FROM
h
WHERE
h."Раздел" IS NULL;Мы пока ничего не знаем ни о структуре базы, ни о том, что этот запрос должен сделать — восстановим все это, воспользовавшись утиным тестом:
Если нечто выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, и есть утка.
Что/зачем делает запрос?
Любую оптимизацию производительности я рекомендую начинать с выяснения, что же вообще происходит в запросе, для чего именно он нужен.
В целом, это достаточно простой запрос, который идет рекурсивно по номенклатуре, вычитывая на первом шаге карточки товаров по списку идентификаторов, который был передан параметром.
WITH RECURSIVE / PathНа этом же шаге, помимо самого ID номенклатурной карточки, мы получаем идентификатор ее предка по иерархии и начинаем формировать массив-путь.
SubqueryОбратим внимание, что для каждой найденной записи номенклатуры будет произведен поиск связанной записи в соседней таблице
NomenclatureExt. Явно это какая-то расширенная информация по номенклатурной карточке, связанная 1-в-1.UNIONНа каждом следующем шаге рекурсии будет происходить то же самое, но уже для записей карточек-предков по иерархии. А раз в запросе применено ключевое слово
UNION, а не UNION ALL, то записи будут уникализироваться на каждой рекурсивной итерации.Path FilterНу, и в финале мы оставляем только те записи, которые являются финальными в «цепочке» — то есть мы простроили путь «вверх» отдельно для каждого исходного идентификатора.
Проблемы в запросе
Какие очевидные проблемы при выполнении данного запроса нам грозят?
- Повторная вычитка одного «предка»
Переданные карточки с очень большой вероятностью будут находиться в одном или соседних разделах, но эта информация у нас нигде не учитывается. Поэтому, при движении по иерархии вверх, мы будем вычитывать одни и те же промежуточные узлы раз за разом.
Представим, что на первом шаге мы передали 60 идентификаторов в запрос и нашли эти 60 карточек из одного раздела. Несмотря на это, мы будем искать одного и того же предка те же 60 раз. - Повторная вычитка связанной записи
Поскольку мы вычитываем связанную запись независимо ни от чего, то и этот поиск мы делаем ровно столько же раз, сколько вычитываем запись основную. - Вложенный запрос под уникализацией
Одно и то же значение из связанной записи вычитывается каждый раз, и только после этого «схлапывается» до единственного экземпляра.
То есть в нашем примере 59 из 60 вложенных запросов будут выполнены заведомо абсолютно зря.
Обратим внимание на конкретный вариант плана такого запроса:
- 107 карточек вычитано
Bitmap Scanна стартовой итерации рекурсии и плюсом к ним — 107 индексных поисков связанных - Поскольку PostgreSQL заранее не понимает, сколько и каких записей мы найдем вверх по иерархии, он вычитывает сразу все 18K из номенклатуры с помощью
Seq Scan. В результате, из 22мс выполнения запроса 12мс мы потратили на чтение всей таблицы и еще 5мс — на ее хэширование, итого — больше 77%. - Из вычитанных 18K нужными нам по результату
Hash Joinокажутся только 475 штук — и теперь добавим к ним еще 475Index Scanпо связанным записям. - Итого: 22мс и 2843 buffers суммарно.
Что/как можно исправить?
Во-первых, стоит избавиться от дубль-чтений одних и тех же карточек при движении вверх по иерархии.
- Поскольку нам нужны сразу и идентификатор самой карточки, и идентификатор ее предка, будем вычитывать записи сразу целиком как
(tableAlias). - Вычитку будем производить с помощью конструкции
= ANY(ARRAY(...)), исключая возможность возникновения неудобныхJOIN. - Для возможности уникализации и хэширования скастуем записи таблицы в
(row)::text. - Поскольку внутри рекурсии обращение к рекурсивной части может быть только однократным и строго не внутри вложенных запросов, вместо этого «материализуем» ее внутри отдельной CTE.
- Таблицу состоящую из единственного столбца можно «свернуть» с помощью
ARRAY(TABLE X)до скалярного значения-массива. А если в ней и так одна запись, то использовать ее с нужной раскастовкой(TABLE X)::integer[].
-- рекурсивный подъем вверх до корня с поиском только уникальных записей
, it AS (
SELECT
it::text -- иначе не работает уникализация через UNION
FROM
"Номенклатура" it
WHERE
"@Номенклатура" = ANY((TABLE src)::integer[])
UNION
(
WITH X AS (
SELECT DISTINCT
(it::"Номенклатура")."Раздел"
FROM
it
WHERE
(it::"Номенклатура")."Раздел" IS NOT NULL
)
SELECT
it2::text
FROM
"Номенклатура" it2
WHERE
"@Номенклатура" = ANY(ARRAY(TABLE X))
)
)Поскольку мы получили только набор самих записей, теперь нам надо выстроить из них «цепочки» потомок-предок рекурсивным спуском сверху-вниз:
-- рекурсивный спуск вниз для формирования "пути" к каждой карточке
, itr AS (
SELECT
ARRAY[(it::"Номенклатура")."@Номенклатура"] path
, it::"Номенклатура" -- запись исходной таблицы
FROM
it
WHERE
(it::"Номенклатура")."Раздел" IS NULL -- стартуем от "корневых" записей
UNION ALL
SELECT
ARRAY[((_it.it)::"Номенклатура")."@Номенклатура"] || itr.path -- наращиваем "путь" спереди
, (_it.it)::"Номенклатура"
FROM
itr
JOIN
it _it
ON ((_it.it)::"Номенклатура")."Раздел@" IS NOT FALSE AND
((_it.it)::"Номенклатура")."Раздел" = (itr.it)."@Номенклатура"
)Теперь из полученных «путей-из-ID» восстановим значение поля
Info из связанной таблицы. Но бегать так по каждому ID несколько раз для преобразования каждого отдельного пути будет очень долго, поэтому:- Соберем весь набор ID, встречающихся в «путях». Но это ровно тот же набор, который дают ID самих наших извлеченных записей.
- Извлечем опять сразу все нужные нам записи связанной таблицы за один проход через
= ANY(ARRAY(...)). - Сложим все полученные значения нужного поля в
hstore-«словарик».
-- формируем словарь info для каждого ключа, чтобы не бегать по записям CTE
, hs AS (
SELECT
hstore(
array_agg("@Номенклатура"::text)
, array_agg(coalesce("Info", '{}'))
)
FROM
"NomenclatureExt"
WHERE
"@Номенклатура" = ANY(ARRAY(
SELECT
(it)."@Номенклатура"
FROM
itr
))
)Остался последний шаг — преобразовать цепочку ID в цепочку
Info с помощью ARRAY(SELECT ... unnest(...)):, ARRAY(
SELECT
(TABLE hs) -> id::text -- извлекаем данные из "словаря"
FROM
unnest(path) id
) res
В результате, целиком наш запрос будет выглядеть примерно так:
-- список всех исходных ID
WITH RECURSIVE src AS (
SELECT $1::integer[] -- набор ID в виде сериализованного массива
)
-- рекурсивный подъем вверх до корня с поиском только уникальных записей
, it AS (
SELECT
it::text -- иначе не работает уникализация через UNION
FROM
"Номенклатура" it
WHERE
"@Номенклатура" = ANY((TABLE src)::integer[])
UNION
(
WITH X AS (
SELECT DISTINCT
(it::"Номенклатура")."Раздел"
FROM
it
WHERE
(it::"Номенклатура")."Раздел" IS NOT NULL
)
SELECT
it2::text
FROM
"Номенклатура" it2
WHERE
"@Номенклатура" = ANY(ARRAY(TABLE X))
)
)
-- рекурсивный спуск вниз для формирования "пути" к каждой карточке
, itr AS (
SELECT
ARRAY[(it::"Номенклатура")."@Номенклатура"] path
, it::"Номенклатура"
FROM
it
WHERE
WHERE
(it::"Номенклатура")."Раздел" IS NULL -- стартуем от "корневых" записей
UNION ALL
SELECT
ARRAY[((_it.it)::"Номенклатура")."@Номенклатура"] || itr.path -- наращиваем "путь" спереди
, (_it.it)::"Номенклатура"
FROM
itr
JOIN
it _it
ON ((_it.it)::"Номенклатура")."Раздел@" IS NOT FALSE AND
((_it.it)::"Номенклатура")."Раздел" = (itr.it)."@Номенклатура"
)
-- формируем словарь info для каждого ключа, чтобы не бегать по записям CTE
, hs AS (
SELECT
hstore(
array_agg("@Номенклатура"::text)
, array_agg(coalesce("Info", '{}'))
)
FROM
"NomenclatureExt"
WHERE
"@Номенклатура" = ANY(ARRAY(
SELECT
(it)."@Номенклатура"
FROM
itr
))
)
-- строим цепочку info для каждого id из оригинального набора
SELECT
path[1] id
, ARRAY(
SELECT
(TABLE hs) -> id::text -- извлекаем данные из "словаря"
FROM
unnest(path) id
) res
FROM
itr
WHERE
path[1] = ANY((TABLE src)::integer[]); -- ограничиваемся только стартовым набором
- Теперь на каждом шаге рекурсии (а их получается 4, в соответствии с глубиной дерева) мы добавляем, в среднем, всего по 12 записей.
- Восстановление путей «вниз» заняло большую часть времени — 10мс. Можно сделать и меньше, но это гораздо сложнее.
- Итого, новый запрос выполняется 15мс вместо 22мс и читает только лишь 860 страниц данных вместо 2843, что имеет принципиальное влияние на время работы, когда нет возможности обеспечить постоянное присутствие этих данных в кэше.
#2: Дело о худеющем запросе
Второй запрос оказался намного «кучерявее», но интереснее с практической точки зрения, поскольку вызывается очень часто для получения информации о персонах как внутри нашей корпоративной социальной сети, так и другими сервисами, использующими ее.
Поскольку запрос достаточно объемный, я сразу скрою его под спойлером и буду приводить только варианты после каждого шага оптимизации, в результате которых он худел все сильнее и сильнее. Но сначала небольшое лирическое отступление.
Регулярно возникают реплики типа "Вот ты ускорил запрос в 10 раз, но всего на 10мс — оно же того не стоит! Мы лучше поставим еще пару реплик! Вместо 100MB памяти получилось 1MB? Да нам проще памяти на сервер добавить!"
Тут какой момент — разработчик, вооруженный набором стандартных приемов, на оптимизацию запроса тратит константное время (= деньги), а с увеличением функционала и количества пользователей нагрузка на БД растет примерно как N(logN), а даже не линейно. То есть если сейчас ваш проект «ест» CPU базы на 50%, готовьтесь к тому, что уже через год вам придется ставить еще один такой же сервер (= деньги), потом еще и еще…
Оптимизация запросов не избавляет от добавления мощностей, но сильно отодвигает их в будущее. Добившись вместо нагрузки в 50% всего 10%, вы сможете не расширять «железо» еще года 2-3, а «вложить» те же деньги, например, в увеличение штата или чьей-то зарплаты.
00: исходное состояние
00: исходный запрос, 7.2мс
WITH personIds("Персона") AS (
SELECT
$1::uuid[]
)
, persons AS (
SELECT
P."Персона"
, coalesce(P."Фамилия", '') "Фамилия"
, coalesce(P."Имя", '') "Имя"
, coalesce(P."Отчество", '') "Отчество"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ФамилияЛица"
ELSE
P."Фамилия"
END
, ''
) "ФамилияЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ИмяЛица"
ELSE
P."Имя"
END
, ''
) "ИмяЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ОтчествоЛица"
ELSE
P."Отчество"
END
, ''
) "ОтчествоЛица"
, P."Примечание"
, P."Обновлено"
, P."Уволен"
, P."Группа"
, P."Пол"
, P."Логин"
, P."Город"
, P."ДатаРождения"
, P."$Создано"::date "ДатаРегистрации"
, coalesce(P."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(P."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
FROM
"Персона" P
WHERE
"Персона" = ANY((TABLE personids)::uuid[])
)
, counts AS (
SELECT
NULL c
)
, users AS (
SELECT
hstore(
array_agg("Персона"::text)
, array_agg(udata::text)
)
FROM
(
SELECT
"Персона"::text
, array_agg(u::text) udata
FROM
"Пользователь" u
WHERE
"Персона" IN (
SELECT
"Персона"
FROM
persons
) AND
(
"Главный" OR
(
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)
)
GROUP BY 1
) u2
)
, T1 AS (
SELECT
persons."Персона"
, persons."Фамилия"
, persons."Имя"
, persons."Отчество"
, persons."ФамилияЛица"
, persons."ИмяЛица"
, persons."ОтчествоЛица"
, persons."Примечание"
, persons."Обновлено"
, persons."Город"
, coalesce(persons."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(persons."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, counts.c "Всего"
, persons."Группа"
, (
SELECT
ARRAY(
SELECT
row_to_json(t2)
FROM
(
SELECT
"Пользователь" >> 32 as "Account"
, "Пользователь" & x'FFFFFFFF'::bigint "Face"
, coalesce("ЕстьПользователь", TRUE) "HasUser"
, coalesce("ЕстьПользователь", TRUE) AND coalesce("Входил", TRUE) "HasLoggedIn"
, coalesce("Уволен", persons."Уволен") "Fired"
FROM
(
SELECT
*
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata15
WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
) udata2
) t2
)
)::text[] "Users"
, coalesce(
(
SELECT
row_to_json(t3)
FROM
(
SELECT
"Пользователь" >> 32 as "Account"
, "Пользователь" & x'FFFFFFFF'::bigint "Face"
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata2
WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Пользователь" >> 32 = 5313189::int
ORDER BY
"ЕстьПользователь" DESC, "Входил" DESC
LIMIT 1
) t3
)
, (
SELECT
row_to_json(t4)
FROM
(
SELECT
"Пользователь" >> 32 as "Account"
, "Пользователь" & x'FFFFFFFF'::bigint "Face"
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata2
WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Главный"
ORDER BY
"ЕстьПользователь" DESC, "Входил" DESC
LIMIT 1
) t4
)
, (
SELECT
row_to_json(t5)
FROM
(
SELECT
"Пользователь" >> 32 as "Account"
, "Пользователь" & x'FFFFFFFF'::bigint "Face"
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata2
WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
LIMIT 1
) t5
)
) "PrimaryFaceAccount"
, (
SELECT
"Пользователь" >> 32
FROM
(
SELECT
"Пользователь"
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata2
WHERE
"Главный"
) t3
LIMIT 1
) "MainAccount"
, ARRAY(
SELECT
"Значение"::int
FROM
"КонтактныеДанные"
WHERE
persons."Группа" AND
"Персона" = persons."Персона" AND
"Тип" = 'account'
) "АккаунтыГруппы"
, persons."Пол"
, persons."Логин"
, persons."ДатаРождения"
, persons."ДатаРегистрации"
FROM
persons
, counts
)
SELECT
CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END "LastName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END "FirstName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END "PatronymicName"
, *
FROM
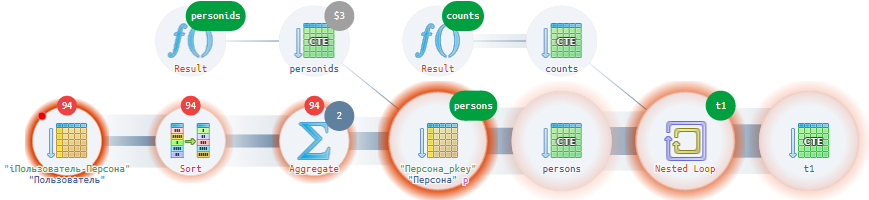
T1;Даже беглого взгляда на диаграмму выполнения достаточно, чтобы сразу увидеть, что в плане встречаются подозрительно одинаковые куски (
SubPlan 8, SubPlan 10, SubPlan 12, SubPlan 14, SubPlan 16), внутри которых время тратится на unnest записей из массива внутри CTE.Эти субпланы соответствуют подзапросам по развороту массива пользователей из
hstore по ключу каждой отдельной персоны: , coalesce(
(
SELECT
row_to_json(T)
FROM
(
SELECT
...
FROM
(
SELECT
(udata::"Пользователь").*
FROM
unnest(((TABLE users) -> "Персона"::text)::text[]) udata
) udata2
WHERE
...
ORDER BY
...
LIMIT 1
) T
)
Заметим, что все эти подзапросы работают с одним и тем же исходным набором данных, просто кто-то берет из него данные по одному условию, а кто-то по другому; кто-то сортирует, а кто-то — нет; кто-то берет все поля из всех записей, а кто-то только пару из первой…
- Можно ли сделать все то же самое за один проход? Конечно! В этом нам помогут
FILTER(9.4+) иLATERAL(9.3+). - Вместо построения JSON независимо в 5 разных местах (по одним и тем же записям, в основном). Построим эти JSON сразу для каждой исходной записи — в «полном» (5 ключей) и «коротком» (2 ключа) вариантах.
- Сортировка исходного набора совпадает во всех местах, где используется. Где не используется — значит, непринципиально для данных, и ее можно использовать все равно.
LIMIT 1можно успешно заменить на извлечение первого элемента массива:arr[1]. Так что собираем по каждому условию именно массивы.- Для одновременного возврата нескольких агрегатов используем сериализацию в
ARRAY[aggx::text, aggy::text].
01. FILTER + LATERAL + single JSON (4мс, -45%)
WITH personIds("Персона") AS (
SELECT
$1::uuid[]
)
, persons AS (
SELECT
P."Персона"
, coalesce(P."Фамилия", '') "Фамилия"
, coalesce(P."Имя", '') "Имя"
, coalesce(P."Отчество", '') "Отчество"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ФамилияЛица"
ELSE
P."Фамилия"
END
, ''
) "ФамилияЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ИмяЛица"
ELSE
P."Имя"
END
, ''
) "ИмяЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ОтчествоЛица"
ELSE
P."Отчество"
END
, ''
) "ОтчествоЛица"
, P."Примечание"
, P."Обновлено"
, P."Уволен"
, P."Группа"
, P."Пол"
, P."Логин"
, P."Город"
, P."ДатаРождения"
, P."$Создано"::date "ДатаРегистрации"
, coalesce(P."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(P."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
FROM
"Персона" P
WHERE
"Персона" = ANY((TABLE personids)::uuid[])
)
, counts AS (
SELECT
NULL c
)
, users AS (
SELECT
hstore(
array_agg("Персона"::text)
, array_agg(udata::text)
)
FROM
(
SELECT
"Персона"::text
, array_agg(u::text) udata
FROM
"Пользователь" u
WHERE
"Персона" IN (
SELECT
"Персона"
FROM
persons
) AND
(
"Главный" OR
(
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)
)
GROUP BY 1
) u2
)
, T1 AS (
SELECT
persons."Персона"
, persons."Фамилия"
, persons."Имя"
, persons."Отчество"
, persons."ФамилияЛица"
, persons."ИмяЛица"
, persons."ОтчествоЛица"
, persons."Примечание"
, persons."Обновлено"
, persons."Город"
, coalesce(persons."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(persons."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, counts.c "Всего"
, persons."Группа"
-- 8< --
, coalesce(usjs[1]::text[], '{}') "Users"
, coalesce(
(usjs[2]::json[])[1]
, (usjs[3]::json[])[1]
, (usjs[4]::json[])[1]
) "PrimaryFaceAccount"
, ((usjs[5]::json[])[1] ->> 'Account')::bigint "MainAccount"
-- 8< --
, ARRAY(
SELECT
"Значение"::int
FROM
"КонтактныеДанные"
WHERE
persons."Группа" AND
"Персона" = persons."Персона" AND
"Тип" = 'account'
) "АккаунтыГруппы"
, persons."Пол"
, persons."Логин"
, persons."ДатаРождения"
, persons."ДатаРегистрации"
FROM
persons
, counts
-- 8< --
, LATERAL (
SELECT
ARRAY[ -- массив сериализованных json[]
array_agg(json_f) FILTER (WHERE -- фильтрация по необходимому условию
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Пользователь" >> 32 = 5313189::int
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Главный"
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Главный"
)::text
] usjs
FROM
(
SELECT -- готовим JSON для каждой записи сразу, потом только используем готовый
json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
, 'HasUser'
, coalesce("ЕстьПользователь", TRUE)
, 'HasLoggedIn'
, coalesce("ЕстьПользователь", TRUE) AND coalesce("Входил", TRUE)
, 'Fired'
, coalesce("Уволен", persons."Уволен")
) json_f
, json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
) json_s
, *
FROM
(
SELECT
(unnest).*
FROM
unnest(((TABLE users) -> "Персона"::text)::"Пользователь"[])
) T
ORDER BY -- сортировка одна на всех
"ЕстьПользователь" DESC, "Входил" DESC
) T
) usjs
-- 8< --
)
SELECT
CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END "LastName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END "FirstName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END "PatronymicName"
, *
FROM
T1;План уже много приятнее и много короче. Кто самое слабое звено теперь?
unnest!Так, стоп… Мы в
unnest по каждой персоне «разворачиваем» массив, который ранее засунули в hstore с ключом этой же персоны? А «физически-то» мы все равно отбираем в hstore независимо по каждой персоне.Я это к тому, что мы сначала нашли, сгруппировали, сериализовали, потом достали, десериализовали, «развернули»… Что бы серверу не поработать-то?..
- В общем, выносим формирование JSON в подзапрос именно по каждой из персон. В результате у нас исчезает CTE users и hstore.
02. Подзапрос (4мс, -45%)
WITH personIds("Персона") AS (
SELECT
$1::uuid[]
)
, persons AS (
SELECT
P."Персона"
, coalesce(P."Фамилия", '') "Фамилия"
, coalesce(P."Имя", '') "Имя"
, coalesce(P."Отчество", '') "Отчество"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ФамилияЛица"
ELSE
P."Фамилия"
END
, ''
) "ФамилияЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ИмяЛица"
ELSE
P."Имя"
END
, ''
) "ИмяЛица"
, coalesce(
CASE
WHEN nullif(P."ФамилияЛица", '') IS NOT NULL THEN
P."ОтчествоЛица"
ELSE
P."Отчество"
END
, ''
) "ОтчествоЛица"
, P."Примечание"
, P."Обновлено"
, P."Уволен"
, P."Группа"
, P."Пол"
, P."Логин"
, P."Город"
, P."ДатаРождения"
, P."$Создано"::date "ДатаРегистрации"
, coalesce(P."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(P."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
-- 8< --
, (
SELECT
ARRAY[ -- массив сериализованных json[]
array_agg(json_f) FILTER (WHERE -- фильтрация по необходимому условию
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Пользователь" >> 32 = 5313189::int
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Главный"
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Главный"
)::text
] usjs
FROM
(
SELECT -- готовим JSON для каждой записи сразу, потом только используем готовый
json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
, 'HasUser'
, coalesce("ЕстьПользователь", TRUE)
, 'HasLoggedIn'
, coalesce("ЕстьПользователь", TRUE) AND coalesce("Входил", TRUE)
, 'Fired'
, coalesce("Уволен", P."Уволен")
) json_f
, json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
) json_s
, *
FROM
"Пользователь"
WHERE
"Персона" = P."Персона" AND
(
"Главный" OR
(
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)
)
ORDER BY -- сортировка одна на всех
"ЕстьПользователь" DESC, "Входил" DESC
) T
) usjs
-- 8< --
FROM
"Персона" P
WHERE
"Персона" = ANY((TABLE personids)::uuid[])
)
, counts AS (
SELECT
NULL c
)
, T1 AS (
SELECT
persons."Персона"
, persons."Фамилия"
, persons."Имя"
, persons."Отчество"
, persons."ФамилияЛица"
, persons."ИмяЛица"
, persons."ОтчествоЛица"
, persons."Примечание"
, persons."Обновлено"
, persons."Город"
, coalesce(persons."ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce(persons."ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, counts.c "Всего"
, persons."Группа"
, coalesce(usjs[1]::text[], '{}') "Users"
, coalesce(
(usjs[2]::json[])[1]
, (usjs[3]::json[])[1]
, (usjs[4]::json[])[1]
) "PrimaryFaceAccount"
, ((usjs[5]::json[])[1] ->> 'Account')::bigint "MainAccount"
, ARRAY(
SELECT
"Значение"::int
FROM
"КонтактныеДанные"
WHERE
persons."Группа" AND
"Персона" = persons."Персона" AND
"Тип" = 'account'
) "АккаунтыГруппы"
, persons."Пол"
, persons."Логин"
, persons."ДатаРождения"
, persons."ДатаРегистрации"
FROM
persons
, counts
)
SELECT
CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END "LastName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END "FirstName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END "PatronymicName"
, *
FROM
T1;Кто теперь выглядит лишним?
- Очевидно,
CTE personids(заменяем на inline-параметр с раскастовкой) иCTE counts(вообще какой-то странный атавизм, возвращающий один NULL). - После этого замечаем, что все выборки у нас стали из единственной таблички, поэтому лучше убрать избыточные алиасы.
03. Inline-параметры (3.9мс, -46%)
WITH persons AS (
SELECT
"Персона"
, coalesce("Фамилия", '') "Фамилия"
, coalesce("Имя", '') "Имя"
, coalesce("Отчество", '') "Отчество"
, coalesce(
CASE
WHEN nullif("ФамилияЛица", '') IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END
, ''
) "ФамилияЛица"
, coalesce(
CASE
WHEN nullif("ФамилияЛица", '') IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END
, ''
) "ИмяЛица"
, coalesce(
CASE
WHEN nullif("ФамилияЛица", '') IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END
, ''
) "ОтчествоЛица"
, "Примечание"
, "Обновлено"
, "Уволен"
, "Группа"
, "Пол"
, "Логин"
, "Город"
, "ДатаРождения"
, "$Создано"::date "ДатаРегистрации"
, coalesce("ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce("ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, (
SELECT
ARRAY[ -- массив сериализованных json[]
array_agg(json_f) FILTER (WHERE -- фильтрация по необходимому условию
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Пользователь" >> 32 = 5313189::int
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Главный"
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Главный"
)::text
] usjs
FROM
(
SELECT -- готовим JSON для каждой записи сразу, потом только используем готовый
json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
, 'HasUser'
, coalesce("ЕстьПользователь", TRUE)
, 'HasLoggedIn'
, coalesce("ЕстьПользователь", TRUE) AND coalesce("Входил", TRUE)
, 'Fired'
, coalesce("Уволен", p."Уволен")
) json_f
, json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
) json_s
, *
FROM
"Пользователь"
WHERE
"Персона" = p."Персона" AND
(
"Главный" OR
(
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)
)
ORDER BY -- сортировка одна на всех
"ЕстьПользователь" DESC, "Входил" DESC
) T
) usjs
FROM
"Персона" p
WHERE
-- 8< --
"Персона" = ANY($1::uuid[])
-- 8< --
)
, T1 AS (
SELECT
"Персона"
, "Фамилия"
, "Имя"
, "Отчество"
, "ФамилияЛица"
, "ИмяЛица"
, "ОтчествоЛица"
, "Примечание"
, "Обновлено"
, "Город"
, coalesce("ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce("ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, NULL::bigint "Всего"
, "Группа"
, coalesce(usjs[1]::text[], '{}') "Users"
, coalesce(
(usjs[2]::json[])[1]
, (usjs[3]::json[])[1]
, (usjs[4]::json[])[1]
) "PrimaryFaceAccount"
, ((usjs[5]::json[])[1] ->> 'Account')::bigint "MainAccount"
, ARRAY(
SELECT
"Значение"::int
FROM
"КонтактныеДанные"
WHERE
persons."Группа" AND
"Персона" = persons."Персона" AND
"Тип" = 'account'
) "АккаунтыГруппы"
, "Пол"
, "Логин"
, "ДатаРождения"
, "ДатаРегистрации"
FROM
persons
)
SELECT
CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END "LastName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END "FirstName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END "PatronymicName"
, *
FROM
T1;Смотрим теперь на запрос очень-очень пристально, и задумываемся:
- Зачем нам лишняя CTE T1 (ведь
CTE Scanстоит ресурсов)? - Зачем мы один и тот же список полей переписываем дважды?
- Зачем дважды применяется
coalesceна одни и те же поля?
04. Убрали все лишнее (3.2мс, -56%)
WITH p AS (
SELECT
*
-- 8< --
, CASE
WHEN nullif("ФамилияЛица", '') IS NOT NULL THEN
ARRAY[
coalesce("ФамилияЛица", '')
, coalesce("ИмяЛица", '')
, coalesce("ОтчествоЛица", '')
]
ELSE
ARRAY[
coalesce("Фамилия", '')
, coalesce("Имя", '')
, coalesce("Отчество", '')
]
END fio
-- 8< --
, (
SELECT
ARRAY[ -- массив сериализованных json[]
array_agg(json_f) FILTER (WHERE -- фильтрация по необходимому условию
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Пользователь" >> 32 = 5313189::int
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE AND
"Главный"
)::text
, array_agg(json_s) FILTER (WHERE
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)::text
, array_agg(json_s) FILTER (WHERE
"Главный"
)::text
] usjs
FROM
(
SELECT -- готовим JSON для каждой записи сразу, потом только используем готовый
json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
, 'HasUser'
, coalesce("ЕстьПользователь", TRUE)
, 'HasLoggedIn'
, coalesce("ЕстьПользователь", TRUE) AND coalesce("Входил", TRUE)
, 'Fired'
, coalesce("Уволен", p."Уволен")
) json_f
, json_build_object(
'Account'
, "Пользователь" >> 32
, 'Face'
, "Пользователь" & x'FFFFFFFF'::bigint
) json_s
, *
FROM
"Пользователь"
WHERE
"Персона" = p."Персона" AND
(
"Главный" OR
(
"Уволен" IS DISTINCT FROM TRUE AND
"Удален" IS DISTINCT FROM TRUE
)
)
ORDER BY -- сортировка одна на всех
"ЕстьПользователь" DESC, "Входил" DESC
) T
) usjs
FROM
"Персона" p
WHERE
"Персона" = ANY($1::uuid[])
)
-- 8< --
SELECT
CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ФамилияЛица"
ELSE
"Фамилия"
END "LastName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ИмяЛица"
ELSE
"Имя"
END "FirstName"
, CASE
WHEN "ЕстьКорпАккаунт" OR "MainAccount" IS NOT NULL THEN
"ОтчествоЛица"
ELSE
"Отчество"
END "PatronymicName"
, *
FROM
(
SELECT
"Персона"
, coalesce("Фамилия", '') "Фамилия"
, coalesce("Имя", '') "Имя"
, coalesce("Отчество", '') "Отчество"
-- 8< --
, fio[1] "ФамилияЛица"
, fio[2] "ИмяЛица"
, fio[3] "ОтчествоЛица"
-- 8< --
, "Примечание"
, "Обновлено"
, "Город"
, coalesce("ОтдельныйПрофиль", FALSE) "ОтдельныйПрофиль"
, coalesce("ЕстьКорпАккаунт", FALSE) "ЕстьКорпАккаунт"
, NULL::bigint "Всего"
, "Группа"
, coalesce(usjs[1]::text[], '{}') "Users"
, coalesce(
(usjs[2]::json[])[1]
, (usjs[3]::json[])[1]
, (usjs[4]::json[])[1]
) "PrimaryFaceAccount"
, ((usjs[5]::json[])[1] ->> 'Account')::bigint "MainAccount"
, ARRAY(
SELECT
"Значение"::int
FROM
"КонтактныеДанные"
WHERE
p."Группа" AND
-- 8< --
("Персона", "Тип") = (p."Персона", 'account')
-- 8< --
) "АккаунтыГруппы"
, "Пол"
, "Логин"
, "ДатаРождения"
, "$Создано"::date "ДатаРегистрации"
FROM
p
) T;
-- 8< --Итого, запрос мы ускорили больше чем в 2 раза, а упростили — на порядок. Будьте ленивее, не пишите много, не копипастите!
#3: Дело о развесистой клюкве
В своем докладе на конференции я говорил, что самая большая проблема, с которой приходится сталкиваться при оптимизации запросов — алгоритмическая. То есть когда разработчик «не заморачивается» пониманием того, как конкретно БД должна/будет выполнять запрос.Именно таким оказался запрос из последнего сегодняшнего дела:
Классический пример — цепочкаJOIN'ов, приводящая к развесистой «клюкве» изNested Loop/Hash Join/Merge Joinв плане. В особо клинических случаях к ней добавляется «схлапывание» полученной «матрицы» с помощьюDISTINCT/GROUP BY.
Оригинальный запрос, 10.1мс, 11600 buffers

SELECT DISTINCT ON (db."@ПулСерверов")
group_id."@ПулСерверов" "ИдГруппы"
, group_id."Название" "ИмяГруппы"
, CASE
WHEN group_id."Название" = 'Управление облаком' THEN
TRUE
ELSE
FALSE
END "ЭтоУправлениеОблаком"
, group_id."Тип" "Тип"
, group_id."Заблокирован" "Заблокирован"
, CASE
WHEN group_id."Тип" = 15 THEN
app."Код"
ELSE
group_id."Код"
END "Код"
, is_demo."@ПулСерверов" is not null "Демо"
, group_ext_id."ДопустимоеЧислоПользователей" "ДопустимоеЧислоПользователей"
, group_ext_id."Состояние" "Состояние"
, db."@ПулСерверов" "ИдБД"
, db_name."ИмяБД" "ИмяБД"
, hosts."Название" "ХостБД"
, db_name."Порт" "ПортБД"
, group_id. "Отстойник" "Отстойник"
, (
WITH params AS(
SELECT
cpv."Значение"
, cpv."Сайт"
FROM
"ОбщиеПараметры" cp
INNER JOIN
"ЗначенияОбщихПараметров" cpv
ON cp."@ОбщиеПараметры" = cpv."ОбщиеПараметры"
WHERE
cp."Название" = 'session_cache_time' AND
(cpv."Сайт" = 9 or cpv."Сайт" is null)
)
SELECT
coalesce(
(SELECT "Значение" FROM params WHERE "Сайт" = 9)
, (SELECT "Значение" FROM params WHERE "Сайт" IS NULL)
, (SELECT "ЗначениеПоУмолчанию" FROM "ОбщиеПараметры" WHERE "Название" = 'session_cache_time')
, 60::text
)::integer
) "ТаймаутКэша"
, CASE
WHEN nullif(111, 0) IS NULL THEN
NULL
WHEN 111 = group_id."@ПулСерверов" THEN
TRUE
ELSE
FALSE
END "Эталонная"
, site."@Сайт" "ИдСайта"
, site."Адрес" "ИмяСайта"
FROM
"ПулСерверов" group_id
JOIN
"ПулРасширение" group_ext_id
ON group_id."@ПулСерверов" = group_ext_id."@ПулСерверов" AND NOT (group_id."@ПулСерверов" = ANY('{}'::integer[]))
JOIN
"ПулСерверов" folder_db
ON group_id."@ПулСерверов" = folder_db."Раздел"
JOIN
"ПулСерверов" db
ON folder_db."@ПулСерверов" = db."Раздел"
LEFT JOIN
"Сервер" hosts
ON db."Сервер" = hosts."@Сервер"
JOIN
"БазаДанных" db_name
ON db."@ПулСерверов" = db_name."@ПулСерверов"
LEFT JOIN
(
WITH list_demo_app AS (
SELECT
ps0."ПулСерверов"
FROM
"ОбщиеПараметры" p0
INNER JOIN
"ОбщиеПараметры" p1
ON p1."Раздел" = p0."@ОбщиеПараметры" AND p0."Название" = 'Управление облаком'
INNER JOIN
"ОбщиеПараметры" p2
ON p2."Раздел" = p1."@ОбщиеПараметры" AND p1."Название" = 'Шайтан' AND p2."Название" = 'ЭтоДемонстрационнаяГруппа'
INNER JOIN
"ОбщиеПараметрыСервис" ps0
ON ps0."ОбщиеПараметры" = p2."@ОбщиеПараметры"
)
, list_demo_srv AS (
SELECT
pool1."@ПулСерверов"
FROM
list_demo_app ls
INNER JOIN
"ПулСерверов" pool0
ON ls."ПулСерверов" = pool0."@ПулСерверов"
INNER JOIN
"ПулСерверов" pool1
ON pool1."Раздел" = pool0."@ПулСерверов" AND pool1."Тип" = 15
)
SELECT
"@ПулСерверов"
FROM
list_demo_srv
) is_demo
ON is_demo."@ПулСерверов" = group_id."@ПулСерверов"
JOIN
"ПулСерверов" app
ON group_id."Раздел" = app."@ПулСерверов"
LEFT JOIN
"Приложение" service
ON service."ПулСерверов" = group_id."@ПулСерверов"
LEFT JOIN
"СайтПриложение" site_app
ON site_app."Приложение" = service."Раздел"
LEFT JOIN
"Сайт" site
ON site."@Сайт" = site_app."Сайт"
WHERE
group_id."Тип" = 15 AND
folder_db."Тип" = 8 AND
db."Тип" = 4 AND
db_name."ИмяБД" IS NOT NULL AND
(
(1 = 1 AND is_demo."@ПулСерверов" IS NOT NULL) OR
(1 = 2 AND is_demo."@ПулСерверов" IS NULL) OR
1 NOT IN (1, 2)
);В этот раз я не буду подробно приводить запрос после каждой модификации, просто напишу мысли, которые возникли при анализе и приведу результат:
- В запросе используется 11 таблиц, провязанных JOIN'ами… Это очень смело. Чтобы так делать безболезненно, вы должны точно знать, что после каждого шага связывания количество записей будет ограничено, буквально, единицами. Иначе рискуете получить join 1000 x 1000.
- Внимательно смотрим на запрос и строим понятийную модель БД. Разработчику, который это писал проще — он ее и так «знает», а нам придется восстановить на основе условий соединений, названий полей и бытовой логики. Вообще, если вы «графически» представляете, как у вас устроена БД, это может сильно помочь с написанием хорошего запроса. У меня получилось вот так:

- За счет
DISTINCT ON(db."@ПулСерверов")мы ожидаем результат, уникализованный по записиdb, в нашей схеме она вон аж в каком низу… Но посмотрим на условия запроса в самом низу — они из каждой сущности(group_id, folder_db, db)отсекают «сверху вниз» по значению типа существенные куски. - Теперь самое интересное — вложенный запрос, создающий выборку
is_demo. Заметим, что его тело не зависит ни от чего — то есть его можно смело поднять в самое начало основного WITH-блока. То есть лишнее выделение в подзапрос тут только усложняет все без какого-либо профита. - Заметим, что условия
is_demo."@ПулСерверов" = group_id."@ПулСерверов"иis_demo."@ПулСерверов" IS NOT NULLприLEFT JOINэтих таблиц, фактически, означает необходимость присутствия PK group_id среди идентификаторов в is_demo.
Самое очевидное, что тут можно сделать — так и переписать запрос, отбирая записиgroup_idпо набору идентификаторовis_demo. - Переписываем извлечение этих сущностей в независимые CTE, и с удивлением замечаем, что у нас на БД отсутствуют подходящие индексы по
ПулСерверов(Тип, Раздел). Причем эти типы — константны с точки зрения приложения, поэтому лучше — триплет индексовПулСерверов(Раздел) WHERE Тип = .... - Вспомним, что пересечение нескольких CTE может быть весьма затратным, и заменим его на «JOIN через словарь», предварительно сформировав его из записей group_id, folder_db и db — ведь это одна исходная таблица
ПулСерверов. - Вложенный запрос получения параметра
ТаймаутКэшапросто переписываем, избавляя от ненужных CTE.
Результат: 0.4мс (в 25 раз лучше), 134 buffers (в 86 раз лучше)

WITH demo_app AS (
SELECT
ps0."ПулСерверов"
FROM
"ОбщиеПараметры" p0
JOIN
"ОбщиеПараметры" p1
ON (p1."Раздел", p1."Название") = (p0."@ОбщиеПараметры", 'Шайтан')
JOIN
"ОбщиеПараметры" p2
ON (p2."Раздел", p2."Название") = (p1."@ОбщиеПараметры", 'ЭтоДемонстрационнаяГруппа')
JOIN
"ОбщиеПараметрыСервис" ps0
ON ps0."ОбщиеПараметры" = p2."@ОбщиеПараметры"
WHERE
p0."Название" = 'Управление облаком'
)
, demo_srv as(
SELECT
pool1."@ПулСерверов"
FROM
demo_app ls
JOIN
"ПулСерверов" pool0
ON ls."ПулСерверов" = pool0."@ПулСерверов"
JOIN
"ПулСерверов" pool1
ON (pool1."Тип", pool1."Раздел") = (15, pool0."@ПулСерверов") -- CREATE INDEX CONCURRENTLY "iПС-tmp0-t15" ON "ПулСерверов"("Раздел") WHERE "Тип" = 15;
)
, grp AS (
SELECT
grp
FROM
"ПулСерверов" grp
WHERE
"Тип" = 15 AND
"@ПулСерверов" = ANY(ARRAY(
SELECT
"@ПулСерверов"
FROM
demo_srv
))
)
, fld AS (
SELECT
fld
FROM
"ПулСерверов" fld
WHERE
"Раздел" = ANY(ARRAY(
SELECT
(grp)."@ПулСерверов"
FROM
grp
)) AND
"Тип" = 8 -- CREATE INDEX CONCURRENTLY "iПС-tmp0-t8" ON "ПулСерверов"("Раздел") WHERE "Тип" = 8;
)
, dbs AS (
SELECT
dbs
FROM
"ПулСерверов" dbs
WHERE
"Раздел" = ANY(ARRAY(
SELECT
(fld)."@ПулСерверов"
FROM
fld
)) AND
"Тип" = 4 -- CREATE INDEX CONCURRENTLY "iПС-tmp0-t4" ON "ПулСерверов"("Раздел") WHERE "Тип" = 4;
)
, srvhs AS (
SELECT
hstore(
array_agg((dbs)."@ПулСерверов"::text)
, array_agg((dbs)::text)
)
FROM
(
TABLE dbs
UNION ALL
TABLE fld
UNION ALL
TABLE grp
) T
)
SELECT
(grp)."@ПулСерверов" "ИдГруппы"
, (grp)."Название" "ИмяГруппы"
, (grp)."Название" IS NOT DISTINCT FROM 'Управление облаком' "ЭтоУправлениеОблаком"
, (grp)."Тип"
, (grp)."Заблокирован"
, CASE
WHEN (grp)."Тип" = 15 THEN
app."Код"
ELSE
(grp)."Код"
END "Код"
, TRUE "Демо"
, grpe."ДопустимоеЧислоПользователей"
, grpe."Состояние"
, (dbn)."@ПулСерверов" "ИдБД"
, dbn."ИмяБД"
, dbh."Название" "ХостБД"
, dbn."Порт" "ПортБД"
, (grp)."Отстойник"
, (
SELECT
coalesce(
(
SELECT
"Значение"
FROM
"ЗначенияОбщихПараметров"
WHERE
"ОбщиеПараметры" = cp."@ОбщиеПараметры" AND
coalesce("Сайт", 9) = 9
ORDER BY
"Сайт" NULLS LAST
LIMIT 1
)
, "ЗначениеПоУмолчанию"
, '60'
)::integer
FROM
"ОбщиеПараметры" cp
WHERE
"Название" = 'session_cache_time'
) "ТаймаутКэша"
, CASE
WHEN nullif(111, 0) IS NULL THEN
NULL
WHEN (grp)."@ПулСерверов" = 111 THEN
TRUE
ELSE
FALSE
END "Эталонная"
, site."@Сайт" "ИдСайта"
, site."Адрес" "ИмяСайта"
--
, *
FROM
dbs
JOIN
"БазаДанных" dbn
ON dbn."@ПулСерверов" = (dbs.dbs)."@ПулСерверов"
JOIN LATERAL
(
SELECT
((TABLE srvhs)->((dbs)."Раздел"::text))::"ПулСерверов" fld
) fld ON TRUE
JOIN LATERAL
(
SELECT
((TABLE srvhs)->((fld)."Раздел"::text))::"ПулСерверов" grp
) grp ON TRUE
JOIN
"ПулРасширение" grpe
ON grpe."@ПулСерверов" = (grp)."@ПулСерверов"
JOIN
"ПулСерверов" app
ON app."@ПулСерверов" = (grp)."Раздел"
JOIN
"Сервер" dbh
ON dbh."@Сервер" = (dbs)."Сервер"
LEFT JOIN
"Приложение" srv
ON srv."ПулСерверов" = (grp)."@ПулСерверов"
LEFT JOIN
"СайтПриложение" site_app
ON site_app."Приложение" = srv."Раздел"
LEFT JOIN
"Сайт" site
ON site."@Сайт" = site_app."Сайт"
WHERE
dbn."ИмяБД" IS NOT NULL;Надеюсь, вы почерпнули полезное для себя из сегодняшнего поста. А более подробно о каждом использованном способе оптимизации можно познакомиться в отдельных статьях моих циклов.
PostgreSQL Antipatterns:
- CTE x CTE
- редкая запись долетит до середины JOIN
- ударим словарем по тяжелому JOIN
- насколько глубока кроличья нора? пробежимся по иерархии
- DISTINCT и LIMIT: «Должен остаться только один!»
SQL HowTo: