

Хаос-инжиниринг для Kubernetes становится всё популярнее, и это закономерно: ведь такая инфраструктура создавалась быть готовой к тому, чтобы в любой момент что-нибудь «отстрелило». А значит — это замечательное свойство надо проверять в реальных проектах.
Благо, уже сегодня можно найти не одно Open Source-решение, помогающее в подобных экспериментах. Представляем вашему вниманию их обзор. Он получился весьма объёмным, поэтому был разбит на две части: в этой мы рассмотрим три популярных проекта.
Предыстория
История chaos engineering начинается в 2011, когда в компании Netflix решили, что только избыточная и распределенная инфраструктура может дать действительно высокую отказоустойчивость. Для того, чтоб непрерывно убеждаться в том, что это действительно так, они и создали Chaos Monkey.
Суть этой «обезьяны» сводилась к тому, чтобы регулярно убивать один из экземпляров какого-то сервиса, будь то виртуальная машина или контейнер. Увеличение размера инфраструктуры и эволюция привели к появлению Chaos Kong — сервиса, который отрубает один из трёх регионов AWS. Вот это по-настоящему масштабная проверка отказоустойчивости!
В целом же, список доступных действий для хаос-инжиниринга значительно шире, чем простое «убийство» сервисов. Главная цель этой новой науки — обнаружение вероятных проблем, которые либо не устраняются должным образом, либо не обнаруживаются / не воспроизводятся постоянно. Поэтому «убийством» не ограничиваются: нужно ещё умело вставлять палки в колёса и дисковую подсистему, рвать сетевые соединения и поджаривать CPU с памятью… особо продвинутые могут даже фрагментировать страницы памяти в ядре запущенного pod'а (как это вообще, cgroups?).
Но не буду подробно останавливаться на хаос-инжиниринге как таковом — для этого достаточно почитать замечательный цикл статей, что мы уже переводили для хабры.
Возвращаясь же к «классическому» Chaos Monkey: эта утилита была создана и используется в Netflix. В настоящий момент она интегрирована с платформой непрерывной доставки Spinnaker, поэтому работает с любым поддерживаемым там бэкендом: AWS, Google Compute Engine, Azure, Kubernetes, Cloud Foundry.
Однако такое, казалось бы, удобство таит в себе обратную сторону. Установка/настройка Chaos Monkey для Kubernetes (в связке со Spinnaker) по своей простоте очень далека от привычного Helm-чарта… Далее будут рассмотрены инструменты для chaos engineering, созданные специально для K8s.
1. kube-monkey
- GitHub: https://github.com/asobti/kube-monkey
- Звёзды / контрибьюторы: ~1800 / 20+
- Язык: Go
Один из самых старых проектов среди изначально ориентированных на Kubernetes: первые публичные коммиты в его репозитории состоялись в декабре 2016 года. Попробуем его сразу «в деле» на развёрнутом deployment'е nginx из пяти реплик, попутно рассказывая о возможностях.
Итак, вот манифест для испытаний:
---
apiVersion: v1
kind: Namespace
metadata:
name: test-monkeys
spec:
finalizers:
- kubernetes
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: test-monkeys
spec:
selector:
matchLabels:
app: nginx
replicas: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
ports:
- containerPort: 80
---
Готовый чарт с kube-monkey — самый простой вариант установки и запуска утилиты:
$ git clone https://github.com/asobti/kube-monkey
$ cd kube-monkey/helmНемного модифицируем команду из
README.md, чтобы «обезьянка» жила в своём namespace и начинала работу в двенадцать ночи по Москве, заканчивая за час до полуночи (такое расписание подходило нам на момент написания статьи):$ helm install -n kubemonkey --namespace kubemonkey --set config.dryRun=false --set config.runHour=0 --set config.startHour=1 --set config.endHour=23 --set config.timeZone=Europe/Moscow --set config.debug.schedule_immediate_kill=true --set config.debug.enabled=true kubemonkey
Теперь можно «натравить» обезьянку на nginx с помощью лейблов. Kube-monkey работает по принципу opt-in, т.е. взаимодействует только с теми ресурсами, которые разрешено убивать:
$ kubectl -n test-monkeys label deployment nginx kube-monkey/enabled=enabled
$ kubectl -n test-monkeys label deployment nginx kube-monkey/kill-mode=random-max-percent
$ kubectl -n test-monkeys label deployment nginx kube-monkey/kill-value=100
$ kubectl -n test-monkeys label deployment nginx kube-monkey/identifier=nginxПояснения по лейблам:
- Второй и третий (
kill-mode,kill-value) говорят kube-monkey убивать случайное количество pod'ов из StatefulSets/Deployments/DaemonSets, вплоть до 100%. - Четвёртый (
identifier) определяет уникальный лейбл, по которому kube-monkey найдёт жертв. - Пятый (
mtbf— mean time between failure) определяет, сколько дней должно пройти между убийствами (по умолчанию равен единице).
Сразу появляется ощущение, что пять лейблов — это многовато, чтобы просто взять и кого-то поубивать… Кроме того, есть pull request о том, чтобы
mtbf указывать не только в днях (но и в часах, например, чтобы чаще совершать злодеяния). Однако он висит с 5 февраля без движения, что печально.Ок, посмотрим на логи обезьянки и увидим в конце:
I0831 18:14:53.772484 1 kubemonkey.go:20] Status Update: Generating next schedule in 30 sec
I0831 18:15:23.773017 1 schedule.go:64] Status Update: Generating schedule for terminations
I0831 18:15:23.811425 1 schedule.go:57] Status Update: 1 terminations scheduled today
I0831 18:15:23.811462 1 schedule.go:59] v1.Deployment nginx scheduled for termination at 08/31/2020 21:16:11 +0300 MSK
I0831 18:15:23.811491 1 kubemonkey.go:62] Status Update: Waiting to run scheduled terminations.
********** Today's schedule **********
k8 Api Kind Kind Name Termination Time
----------- --------- ----------------
v1.Deployment nginx 08/31/2020 21:16:11 +0300 MSK
********** End of schedule **********Ура! Chaos-monkey нашла deployment и запланировала убийство одной или более из его реплик. Но что же это и почему?
E0831 18:16:11.869463 1 kubemonkey.go:68] Failed to execute termination for v1.Deployment nginx. Error: v1.Deployment nginx has no running pods at the momentПосмотрим внимательно в мануал ещё раз и увидим (с устаревшим
apiVersion, к сожалению):For newer versions of kubernetes you may need to add the labels to the k8s app metadata as well.--- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monkey-victim namespace: app-namespace labels: kube-monkey/enabled: enabled kube-monkey/identifier: monkey-victim kube-monkey/mtbf: '2' kube-monkey/kill-mode: "fixed" kube-monkey/kill-value: '1' spec: template: metadata: labels: kube-monkey/enabled: enabled kube-monkey/identifier: monkey-victim [... omitted ...]
Ок, изменяем наш шаблон с удалением deployment'а на:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: test-monkeys
labels:
kube-monkey/enabled: enabled
kube-monkey/identifier: nginx
kube-monkey/kill-mode: random-max-percent
kube-monkey/kill-value: "100"
kube-monkey/mtbf: "1"
spec:
selector:
matchLabels:
app: nginx
replicas: 5
template:
metadata:
labels:
app: nginx
kube-monkey/enabled: enabled
kube-monkey/identifier: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
ports:
- containerPort: 80
---Теперь все получилось:
I0831 18:24:20.434516 1 kubemonkey.go:20] Status Update: Generating next schedule in 30 sec
I0831 18:24:50.434838 1 schedule.go:64] Status Update: Generating schedule for terminations
********** Today's schedule **********
k8 Api Kind Kind Name Termination Time
----------- --------- ----------------
v1.Deployment nginx 08/31/2020 21:25:03 +0300 MSK
********** End of schedule **********
I0831 18:24:50.481865 1 schedule.go:57] Status Update: 1 terminations scheduled today
I0831 18:24:50.481917 1 schedule.go:59] v1.Deployment nginx scheduled for termination at 08/31/2020 21:25:03 +0300 MSK
I0831 18:24:50.481971 1 kubemonkey.go:62] Status Update: Waiting to run scheduled terminations.
I0831 18:25:03.540282 1 kubemonkey.go:70] Termination successfully executed for v1.Deployment nginx
I0831 18:25:03.540324 1 kubemonkey.go:73] Status Update: 0 scheduled terminations left.
I0831 18:25:03.540338 1 kubemonkey.go:76] Status Update: All terminations done.
I0831 18:25:03.540499 1 kubemonkey.go:19] Debug mode detected!
I0831 18:25:03.540522 1 kubemonkey.go:20] Status Update: Generating next schedule in 30 secОк, работает хорошо и весьма конкретно. Хотя настраивается сложнее, чем могло быть, не очень гибко, да и функций совсем мало. Бывают и странности в работе:
I0831 18:30:33.163500 1 kubemonkey.go:19] Debug mode detected!
I0831 18:30:33.163513 1 kubemonkey.go:20] Status Update: Generating next schedule in 30 sec
I0831 18:31:03.163706 1 schedule.go:64] Status Update: Generating schedule for terminations
I0831 18:31:03.204975 1 schedule.go:57] Status Update: 1 terminations scheduled today
********** Today's schedule **********
k8 Api Kind Kind Name Termination Time
----------- --------- ----------------
v1.Deployment nginx 08/31/2020 21:31:45 +0300 MSK
********** End of schedule **********
I0831 18:31:03.205027 1 schedule.go:59] v1.Deployment nginx scheduled for termination at 08/31/2020 21:31:45 +0300 MSK
I0831 18:31:03.205080 1 kubemonkey.go:62] Status Update: Waiting to run scheduled terminations.
E0831 18:31:45.250587 1 kubemonkey.go:68] Failed to execute termination for v1.Deployment nginx. Error: no terminations requested for v1.Deployment nginx
I0831 18:31:45.250634 1 kubemonkey.go:73] Status Update: 0 scheduled terminations left.
I0831 18:31:45.250649 1 kubemonkey.go:76] Status Update: All terminations done.
I0831 18:31:45.250828 1 kubemonkey.go:19] Debug mode detected!2. chaoskube
- GitHub: https://github.com/linki/chaoskube
- Звёзды / контрибьюторы: ~1200 / 20+
- Язык: Go
Эта утилита тоже может похвастать длинной историей: первый её релиз состоялся в ноябре 2016 года. У chaoskube есть готовый чарт и хороший мануал по нему. По умолчанию запускается в режиме dry-run, поэтому никто не пострадает.
Запустим на простом deployment'е с nginx, живущем в пространстве имен
test-monkey, и укажем опцию про создание RBAC (потому что у роли default нет нужных прав):$ helm install --name chaoskube --set dryRun=false --set namespaces="test-monkeys" --set rbac.create=true --set rbac.serviceAccountName=chaoskube stable/chaoskube… дело сразу пошло!
$ kubectl -n default logs chaoskube-85f8bf9979-j75qm
time="2020-09-01T08:33:11Z" level=info msg="starting up" dryRun=false interval=10m0s version=v0.14.0
time="2020-09-01T08:33:11Z" level=info msg="connected to cluster" master="https://10.222.0.1:443" serverVersion=v1.16.10
time="2020-09-01T08:33:11Z" level=info msg="setting pod filter" annotations= excludedPodNames="<nil>" includedPodNames="<nil>" labels= minimumAge=0s namespaces=test-monkeys
time="2020-09-01T08:33:11Z" level=info msg="setting quiet times" daysOfYear="[]" timesOfDay="[]" weekdays="[]"
time="2020-09-01T08:33:11Z" level=info msg="setting timezone" location=UTC name=UTC offset=0
time="2020-09-01T08:33:11Z" level=info msg="terminating pod" name=nginx-594cc45b78-8kf64 namespace=test-monkeys
time="2020-09-01T08:43:11Z" level=info msg="terminating pod" name=nginx-594cc45b78-t7wx7 namespace=test-monkeys
time="2020-09-01T08:53:11Z" level=info msg="terminating pod" name=nginx-594cc45b78-8fg9q namespace=test-monkeys
time="2020-09-01T09:03:11Z" level=info msg="terminating pod" name=nginx-594cc45b78-wf5vg namespace=test-monkeysКонфигурировать можно всё, что может потребоваться: часовой пояс, временные исключения, лейблы, по которым ищутся pod'ы-жертвы, и исключения.
Подводя быстрый итог: хороший, удобный и простой инструмент, но, как и kube-monkey, умеет только убивать pod'ы.
3. Chaos Mesh
- GitHub: https://github.com/chaos-mesh/chaos-mesh
- Звёзды / контрибьюторы: 2400 / 50+
- Язык: Go
Chaos Mesh состоит из двух компонентов:
- Chaos Operator — «оператор хаоса», основной компонент, который в свою очередь состоит из:
- controller-manager (управляет Custom Resources),
- chaos-daemon (привилегированный daemonset с возможностями управления сетью, cgroups и т.д.),
- sidecar-контейнера, динамически вставляемогов целевой pod, чтобы вмешиваться в I/O целевого приложения.
- Chaos Dashboard — веб-интерфейс для управления и мониторинга хаос-оператора
Проект входит в CNCF и разработан китайской компанией PingCAP, которая известна своей распределённой, Open Source, cloud-native SQL-базой данных для аналитики в реальном времени — TiDB (мы писали про её «собрата» — TiKV, — тоже входящего в число проектов CNCF).
Итак, «хаос-оператор» использует CRD для определения объектов хаоса. Всего их шесть типов:
PodChaos, NetworkChaos, IOChaos, TimeChaos, StressChaos и KernelChaos. А вот какие доступны действия (эксперименты):- pod-kill — убийство pod'а;
- pod-failure — недоступность pod'а некоторое (определённое) время;
- container-kill — убийство одного из контейнеров pod'а;
- netem chaos — сетевые проблемы, задержки, повторы пакетов;
- network-partition — эмуляция распада сети на сегменты;
- IO chaos — проблемы с диском и чтением/записью;
- time chaos — искажение показателя текущего времени в pod'е;
- cpu-burn — стресс CPU;
- memory-burn — стресс памяти;
- kernel chaos — жертва получит ошибки ядра, фрагментацию страниц памяти, проблемы с блочным I/O.
Объявляя любой из нужных нам Custom Resource, мы можем указать в нём типы действий, лейблы и селекторы для определения целевых namespace или конкретных pod'ов, а также длительность и расписание проведения экспериментов — в общем, всё необходимое для планирования «веселья».
Звучит очень интересно, да? Давайте попробуем! Документация по установке — снова с Helm.
Не забудем указать
--set dashboard.create=true, чтобы получить панели с красивыми графиками! Через пару минут мы получаем целое пространство имён из повелителей хаоса — пока ещё бездействующих, но уже готовых к работе:$ kubectl -n chaos-testing get po
NAME READY STATUS RESTARTS AGE
chaos-controller-manager-bb67cb68f-qpmvf 1/1 Running 0 68s
chaos-daemon-krqsh 1/1 Running 0 68s
chaos-daemon-sk7qf 1/1 Running 0 68s
chaos-daemon-wn9sd 1/1 Running 0 68s
chaos-dashboard-7bd8896c7d-t94pt 1/1 Running 0 68sДля изучения и демонстрации работы chaos-mesh подготовлен подробный мануал, в котором можно увидеть многочисленные возможности оператора. С технической точки зрения, внутри репозитория (https://github.com/chaos-mesh/web-show) находится Deployment тестового приложения на React с сервисом, которому скриптом передаётся IP-адрес pod'а
kube-controller-manager (первый из списка, если у нас мультимастер, или просто единственный). После запуска этот pod начинает непрерывно пинговать pod controller-manager'а и визуализировать на графике этот ping.В нашем случае удобнее выпустить этот график наружу через Ingress, а не команду из
deploy.sh (nohup kubectl port-forward svc/web-show --address 0.0.0.0 8081:8081). Поэтому мы просто применяем Deployment и Service из репозитория и объявляем любой Ingress — просто для того, чтобы можно было попасть в приложение снаружи.
Приятный график. Судя по сегменту ST, у пациента острый инфаркт! Стоп, это же не кардиограмма… А теперь можно применить заклинание хаоса, слегка подкорректировав его для пущей красоты:
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: web-show-network-delay
spec:
action: delay # the specific chaos action to inject
mode: one # the mode to run chaos action; supported modes are one/all/fixed/fixed-percent/random-max-percent
selector: # pods where to inject chaos actions
namespaces:
- test-monkeys
labelSelectors:
"app": "web-show" # the label of the pod for chaos injection
delay:
latency: "50ms"
duration: "10s" # duration for the injected chaos experiment
scheduler: # scheduler rules for the running time of the chaos experiments about pods.
cron: "@every 60s"Результат — ожидаемая нами красивая «пила», сигнализирующая о том, что netem chaos уже работает. И вот тут уже точно инфаркт.
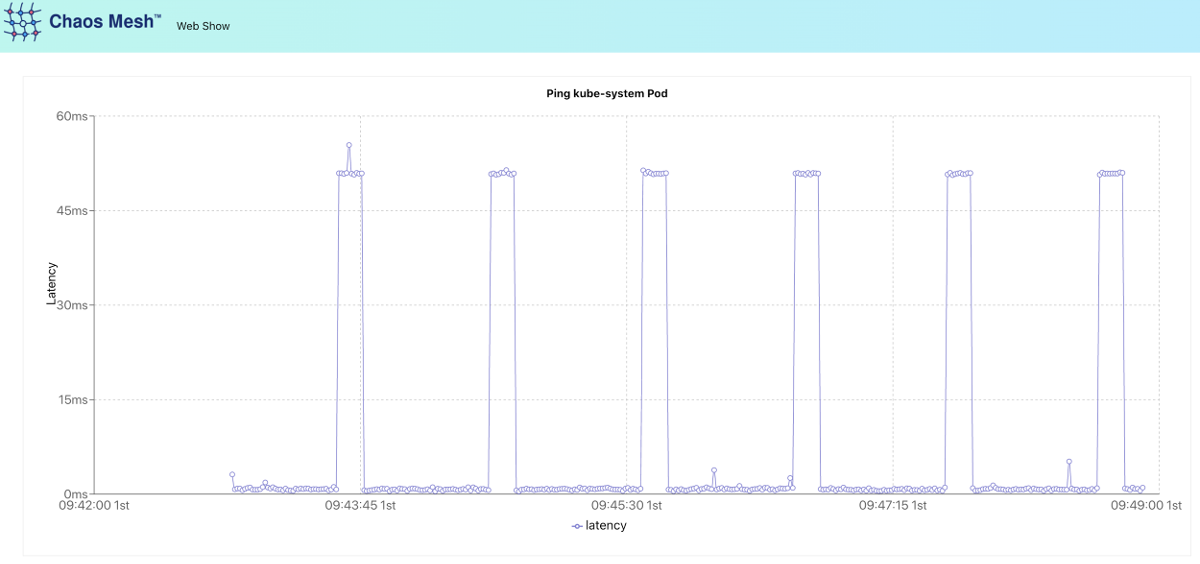
А вот как выглядит chaos-dashboard:

Визуализация событий:

Подробности о конкретном эксперименте:

Есть даже веб-редактор Custom Resources, но встроенной авторизации к нему нет (обязательно надо закрывать авторизацией!):

В завершении обзора этого проекта стоит упомянуть, что недавно (25 сентября 2020 г.) у Chaos Mesh произошло знаменательное событие — релиз версии 1.0.
Продолжение следует
Во второй части статьи будут рассмотрены Litmus Chaos, Chaos Toolkit, игровые варианты хаос-инжиниринга в Kubernetes и некоторые другие проекты, а также подведён общий итог.
ОБНОВЛЕНО (27.11.2020): опубликована вторая часть статьи.
P.S.
Читайте также в нашем блоге:
- «Chaos Engineering: искусство умышленного разрушения. Часть 1» (про концепцию chaos engineering и как он помогает находить/исправлять проблемы до того, как они приведут к сбоям production);
- «Chaos Engineering: искусство умышленного разрушения. Часть 2» (как chaos engineering способствует позитивным культурным изменениям внутри организаций);
- «Chaos Engineering: искусство умышленного разрушения. Часть 3» (практика chaos engineering с внесением неисправностей и существующими для этого инструментами).