
Остановка нефтегазовых заводов — это миллионы долларов убытков. К сожалению, остановка обычно неизбежна, поскольку существует большое количество технологического оборудования и инструментов, которые могут выйти из строя без предупреждения. Инженеры по эксплуатации и техническому обслуживанию должны оставаться до поздней ночи, чтобы найти основную причину отказа оборудования и как можно скорее вернуть его в строй. В этом посте приводим 2 решения для поиска основных причин незапланированных остановок на нефтегазоперерабатывающем заводе.

Иногда процесс тайм-аута занимает от нескольких дней до недель, прежде чем удастся выявить и устранить истинные первопричины. Ускорение этого процесса всего на несколько часов — уже значительно снизит убытки. Чтобы проиллюстрировать презентацию о том, как инженеры решают проблему, давайте посмотрим на синтетические данные всего с 20 датчиков ниже. На этом графике есть два датчика, которые сильно связаны статистически, и, допустим, один из них — настоящая, основная причина событий отключения.
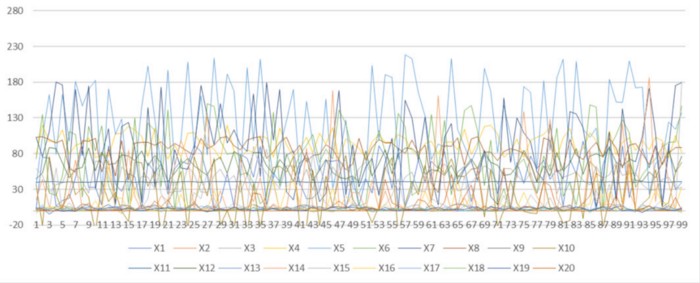
Синтетические данные для моделирования показаний датчиков завода
К сожалению, глядя на график, трудно определить, какие два из датчиков связаны, не так ли? Поскольку на небольшом нефтегазовом заводе имеется от 1000 до 3000 датчиков, это одна из по-настоящему проблемных точек для инженеров по эксплуатации и техническому обслуживанию (включая меня) при выявлении таких датчиков и основных причин. Помните, что можно сэкономить миллионы долларов, если мы сможем быстрее найти такие отношения.
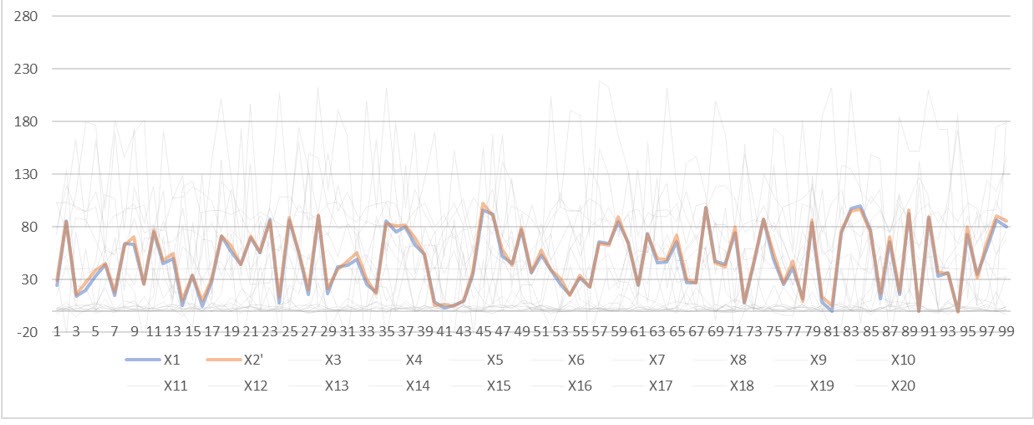
Два статистически связанных датчика из 20 других обычных датчиков
Я поделюсь с вами двумя методиками, которые мы попробовали и нашли приемлемый уровень успеха, чтобы выявить взаимосвязь между этими двумя соответствующими датчиками среди других. Но прежде позвольте мне объяснить, почему это важно для инженеров и операторов.
Во-первых, для любого события отключения на современном нефтегазовом заводе верно, что в диспетчерской установлена сложная система управления, которая может показать «метку первой блокировки». Эта «первая метка» датчика, запускающего событие отключения (например, высокий-высокий сигнал тревоги давления на выходе компрессора, низкий-низкий уровень тревоги в критическом сепараторе).
Этот первый датчик блокировки очень важен для инженеров по эксплуатации и техническому обслуживанию для начала изучения потенциальных первопричин, вызывающих остановку завода. В большинстве случаев инженеры и операторы могут решить проблему остановки завода, просто взглянув на эту первую метку блокировки. Однако во многих случаях это мало что нам даст, поскольку переработка нефти и газа настолько сложна, что появление этой первой метки блокировки — последнее, что произойдёт, тогда как мы хотим знать, что произошло до её срабатывания.
Как только мы изучим первый датчик блокировки и количество времени до события отключения, мы можем использовать полученные сведения для выполнения метода кластеризации, чтобы определить, какие датчики ведут себя так же, как первые датчики блокировки. Мы считаем, что метод иерархической кластеризации и создание дендрограмм — это полезный подход к визуализации, который может дать информацию пользователю, не имеющему отношения к науке о данных. Пример показан на рисунке ниже.
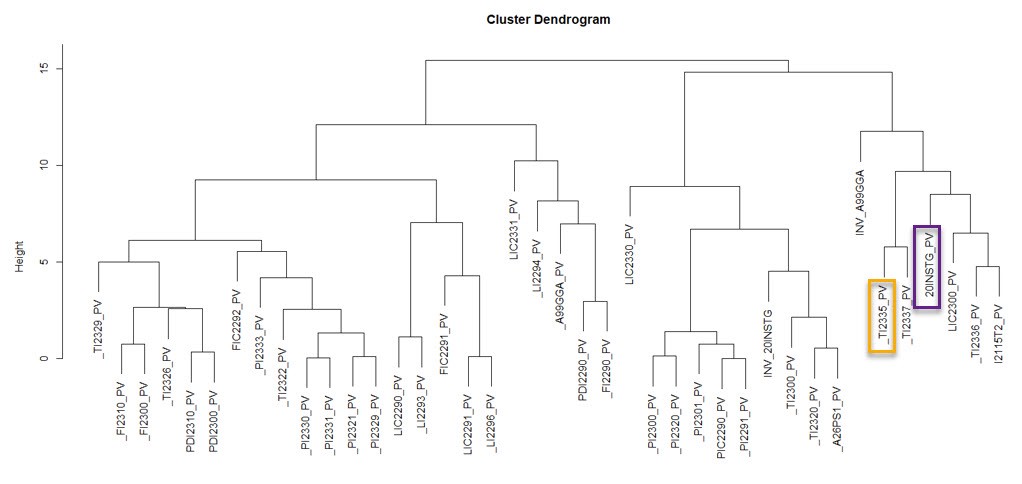
Кластеризация дендрограммы методом иерархической кластеризации
Этот метод не только полезен при поиске основной причины незапланированного отключения, но и может применяться при поиске любых связанных с ним датчиков, которые ведут себя иначе, чем в нормальном состоянии. Например, допустим, что датчик TI2335 показывает неизвестное повышение температуры всасывающего газоочистителя, и мы хотим выяснить, какова основная причина аномального повышения. Мы можем использовать этот метод, чтобы найти соответствующие датчики, которые нужно посмотреть. Вместо того чтобы искать среди 1000-3000 датчиков, инженеры могут сосредоточиться только на датчиках, которые расположены близко к аномальным датчикам или первым датчикам блокировки. Тогда время устранения неполадок может значительно сократиться. К сожалению, этот метод применим далеко не во всех случаях. Поэтому мы попробовали некоторые другие методы.

Сэр Клайв Грейнджер
Тест на причинность Грейнджера — это статистический тест гипотезы для определения того, полезен ли один набор данных временных рядов для прогнозирования другого ряда. Он был опубликован сэром Клайвом Грейнджером в 1969 году, а в 2003 году он получил за свою работу Нобелевскую премию.
Когда экономист собирает статистические данные и превращает их в переменные, возникает одна общая проблема. Он не может определить, какая переменная независима, а какая является зависимой. Другими словами, мы не знаем, какой фактор вызывает другой фактор.
Пример нагляднее: когда экономисты пытаются найти связь между валовым внутренним производством (ВВП) и фондовым индексом. Во время процветания экономики ВВП и фондовый индекс также растут. Когда экономика страны в упадке, ВВП и фондовый индекс также снизятся. Однако одно вызывает другое. Некоторые утверждают, что ВВП должен быть независимой переменной, поскольку он отражает реальное внутреннее производство и потребление. Напротив, другие считают, что, чем выше фондовый индекс, тем больше инвесторы будут вкладывать в экономику страны, так как это надёжность, на которую инвесторы всегда обращают внимание. Эта проблема приводит к совершенно иной финансовой стратегии страны — вкладывать деньги в развитие экономики на местах или в развитие фондового рынка.

Тест на причинно-следственные связи Грейнжера
Сэр Грейнджер смог придумать статистический способ проверить, влияет ли одна переменная на другую, какое-то влияние — это одно направление или два направления, поэтому он получил за это Нобелевскую премию. Когда возникает такая проблема, кто-то может использовать этот тест для проверки других странных проблем; например для выяснения, что было раньше: курица или яйцо, в работе Турмана и Фишера (1988).
Хотя наша проблема не такая причудливая, как описанные выше, когда я пытался воспользоваться тестом на причинную связь Грейнжера в нашей проблеме. То есть с помощью этого теста можно отсеять некоторые не связанные друг с другом датчики и ранжировать связанные датчики, используя полученное р-значение. Для группы параметров процесса результат вполне удовлетворителен.
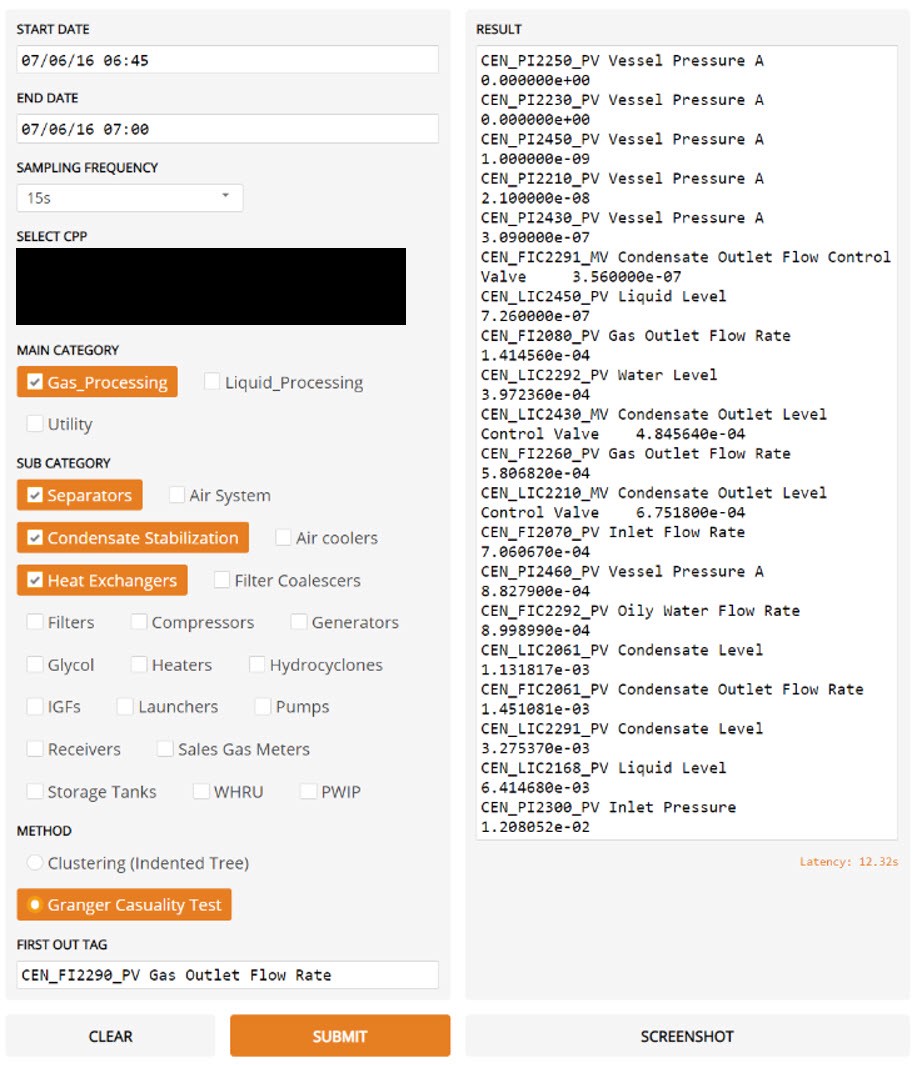
Далее для создания полезного GUI взаимодействия с пользователями, не обладающими навыками программирования, мы воспользовались библиотекой Gradio и создали красивую графику на этапе прототипирования.
Таким образом, из того, что я пробовал до сих пор, иерархическая кластеризация хорошо работает с газоперерабатывающей частью, тогда как тест на причинно-следственные связи Грейнджера хорошо работает с жидкостной обрабатывающей частью. Одна из причин этого заключается в том, что в жидкостном процессе, по природе несжимаемой жидкости, обычно требуется время, прежде чем датчики успеют отреагировать на изменение процесса. В газовой фазе это не так.
Вот так методы Data Science применяются для решения реальных нефтегазовых проблем. Если у вас есть желание научиться этому и применить DS к проекту, над которым сейчас работаете — то мы ждем вас.

Иногда процесс тайм-аута занимает от нескольких дней до недель, прежде чем удастся выявить и устранить истинные первопричины. Ускорение этого процесса всего на несколько часов — уже значительно снизит убытки. Чтобы проиллюстрировать презентацию о том, как инженеры решают проблему, давайте посмотрим на синтетические данные всего с 20 датчиков ниже. На этом графике есть два датчика, которые сильно связаны статистически, и, допустим, один из них — настоящая, основная причина событий отключения.
Синтетические данные для моделирования показаний датчиков завода
К сожалению, глядя на график, трудно определить, какие два из датчиков связаны, не так ли? Поскольку на небольшом нефтегазовом заводе имеется от 1000 до 3000 датчиков, это одна из по-настоящему проблемных точек для инженеров по эксплуатации и техническому обслуживанию (включая меня) при выявлении таких датчиков и основных причин. Помните, что можно сэкономить миллионы долларов, если мы сможем быстрее найти такие отношения.
Два статистически связанных датчика из 20 других обычных датчиков
Я поделюсь с вами двумя методиками, которые мы попробовали и нашли приемлемый уровень успеха, чтобы выявить взаимосвязь между этими двумя соответствующими датчиками среди других. Но прежде позвольте мне объяснить, почему это важно для инженеров и операторов.
Во-первых, для любого события отключения на современном нефтегазовом заводе верно, что в диспетчерской установлена сложная система управления, которая может показать «метку первой блокировки». Эта «первая метка» датчика, запускающего событие отключения (например, высокий-высокий сигнал тревоги давления на выходе компрессора, низкий-низкий уровень тревоги в критическом сепараторе).
Важность
Этот первый датчик блокировки очень важен для инженеров по эксплуатации и техническому обслуживанию для начала изучения потенциальных первопричин, вызывающих остановку завода. В большинстве случаев инженеры и операторы могут решить проблему остановки завода, просто взглянув на эту первую метку блокировки. Однако во многих случаях это мало что нам даст, поскольку переработка нефти и газа настолько сложна, что появление этой первой метки блокировки — последнее, что произойдёт, тогда как мы хотим знать, что произошло до её срабатывания.
Первое решение: иерархическая кластеризация
Как только мы изучим первый датчик блокировки и количество времени до события отключения, мы можем использовать полученные сведения для выполнения метода кластеризации, чтобы определить, какие датчики ведут себя так же, как первые датчики блокировки. Мы считаем, что метод иерархической кластеризации и создание дендрограмм — это полезный подход к визуализации, который может дать информацию пользователю, не имеющему отношения к науке о данных. Пример показан на рисунке ниже.
Кластеризация дендрограммы методом иерархической кластеризации
Этот метод не только полезен при поиске основной причины незапланированного отключения, но и может применяться при поиске любых связанных с ним датчиков, которые ведут себя иначе, чем в нормальном состоянии. Например, допустим, что датчик TI2335 показывает неизвестное повышение температуры всасывающего газоочистителя, и мы хотим выяснить, какова основная причина аномального повышения. Мы можем использовать этот метод, чтобы найти соответствующие датчики, которые нужно посмотреть. Вместо того чтобы искать среди 1000-3000 датчиков, инженеры могут сосредоточиться только на датчиках, которые расположены близко к аномальным датчикам или первым датчикам блокировки. Тогда время устранения неполадок может значительно сократиться. К сожалению, этот метод применим далеко не во всех случаях. Поэтому мы попробовали некоторые другие методы.
Второе решение: тест на причинность Грейнджера
Сэр Клайв Грейнджер
Тест на причинность Грейнджера — это статистический тест гипотезы для определения того, полезен ли один набор данных временных рядов для прогнозирования другого ряда. Он был опубликован сэром Клайвом Грейнджером в 1969 году, а в 2003 году он получил за свою работу Нобелевскую премию.
Когда экономист собирает статистические данные и превращает их в переменные, возникает одна общая проблема. Он не может определить, какая переменная независима, а какая является зависимой. Другими словами, мы не знаем, какой фактор вызывает другой фактор.
Пример нагляднее: когда экономисты пытаются найти связь между валовым внутренним производством (ВВП) и фондовым индексом. Во время процветания экономики ВВП и фондовый индекс также растут. Когда экономика страны в упадке, ВВП и фондовый индекс также снизятся. Однако одно вызывает другое. Некоторые утверждают, что ВВП должен быть независимой переменной, поскольку он отражает реальное внутреннее производство и потребление. Напротив, другие считают, что, чем выше фондовый индекс, тем больше инвесторы будут вкладывать в экономику страны, так как это надёжность, на которую инвесторы всегда обращают внимание. Эта проблема приводит к совершенно иной финансовой стратегии страны — вкладывать деньги в развитие экономики на местах или в развитие фондового рынка.
Тест на причинно-следственные связи Грейнжера
Сэр Грейнджер смог придумать статистический способ проверить, влияет ли одна переменная на другую, какое-то влияние — это одно направление или два направления, поэтому он получил за это Нобелевскую премию. Когда возникает такая проблема, кто-то может использовать этот тест для проверки других странных проблем; например для выяснения, что было раньше: курица или яйцо, в работе Турмана и Фишера (1988).
Хотя наша проблема не такая причудливая, как описанные выше, когда я пытался воспользоваться тестом на причинную связь Грейнжера в нашей проблеме. То есть с помощью этого теста можно отсеять некоторые не связанные друг с другом датчики и ранжировать связанные датчики, используя полученное р-значение. Для группы параметров процесса результат вполне удовлетворителен.
Далее для создания полезного GUI взаимодействия с пользователями, не обладающими навыками программирования, мы воспользовались библиотекой Gradio и создали красивую графику на этапе прототипирования.
Заключение
Таким образом, из того, что я пробовал до сих пор, иерархическая кластеризация хорошо работает с газоперерабатывающей частью, тогда как тест на причинно-следственные связи Грейнджера хорошо работает с жидкостной обрабатывающей частью. Одна из причин этого заключается в том, что в жидкостном процессе, по природе несжимаемой жидкости, обычно требуется время, прежде чем датчики успеют отреагировать на изменение процесса. В газовой фазе это не так.
Вот так методы Data Science применяются для решения реальных нефтегазовых проблем. Если у вас есть желание научиться этому и применить DS к проекту, над которым сейчас работаете — то мы ждем вас.
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Веб-разработчик
КУРСЫ
- Курс по Machine Learning
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Python для веб-разработки»
- Курс по JavaScript
- Курс «Математика и Machine Learning для Data Science»
- Курс по аналитике данных
- Курс по DevOps
Goron_Dekar
А зачем использовать техники статистической обработки blackbox'a там, где заранее известны (и, скорее всего, детально описаны и промоделированы) все технические процессы?
innovaIT
Это вы плохо знаете производство.) в сельском хозяйстве, например, конечный результат не предсказуем. И все варианты предусмотреть в принципе нельзя. Там могут бегать 12 теоретиков вокруг одной сушки и не понимать, почему же теория не сходится с практикой.
aaabramenko
Когда в руках молоток, всё вокруг кажется гвоздями.