

Проблема
Штрихкод — классная штука для маркировки всего на свете, от товаров до людей. Сейчас в ходу около двух десятков стандартов двумерных штрихкодов, и ещё десятки неудачных, трагически непонятых, самопальных и внутренних корпоративных вариантов, большинство из которых с треском проигрывает обычному QR-коду. Распространённость и простота реализации сделали его самым популярным среди двумерных штрихкодов, но и у него есть недостаток, характерный для всех линейных собратьев: он вмещает очень мало информации. В 2-3 килобайта можно уместить ссылку или небольшой отрывок текста, но даже небольшая картинка или обычный документ уже не влезут даже в самый большой код.
Понятно, что вместимость обычного QR-подобного квадратика можно увеличить, увеличивая размер матрицы, добавляя цвета и играясь с формой ячеек. Единого стандарта для таких расширенных кодов нет, кроме проприетарного Microsoft Tag (HCCB) с неясными перспективами развития и использования. Расширение палитры и изменение пикселей также усложняет чтение кода в сложных условиях (плохая печать, цветное или недостаточное освещение), но всё равно даёт очень ограниченное увеличение ёмкости и не позволяет без боли передать даже мегабайт данных.
Хороший пример такого самодельного стандарта — Jabcode
Решить проблему уже давно предложили радикально: в отличие от линейных штрихкодов, QR встречаются не только в напечатанном виде, но и на экранах устройств в приложениях и на сайтах. Значит, если чем-то в стандарте придётся поступиться, пусть это будет возможность физической печати кода — сделаем его анимированным! Таким образом моментально превращаем статичный квадратик в источник неограниченного объёма данных, которые можно будет передавать по воздуху без подключения к любым сетям. Разумеется, скорость передачи будет невысокой, и обычная считывалка QR не сможет обработать такой код, но принцип раскодирования почти тот же и изобретать велосипед не придётся.
TXQR
Первой готовой и продуманной реализацией, из всех, что мне удалось найти, стал TXQR от Ивана Данилюка (блог, GitHub). В проекте есть спецификация и PoC на Go с приложением под iOS.
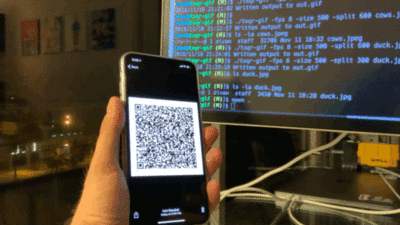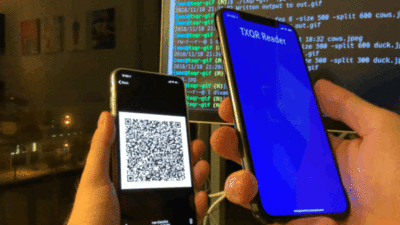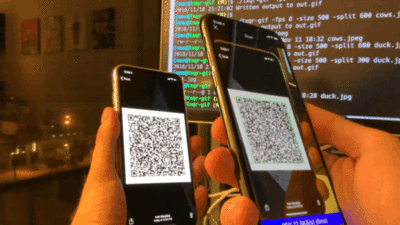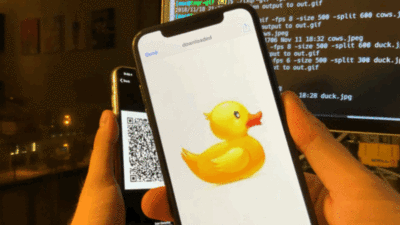
Сначала код TXQR просто прокручивал обычные QR-коды в цикле, а телефон старался их считать как можно точнее, получая коррекцию ошибок только при следующем повторении цикла. В тестах автор гонял файл на 13 килобайт, получив пиковую скорость 9 KB/s. В следующей итерации формат стал использовать фонтанные коды (точнее, Luby transform code), чтобы через избыточность позволить выполнять коррекцию ошибок в любых фреймах, не дожидаясь прокрутки цикла:
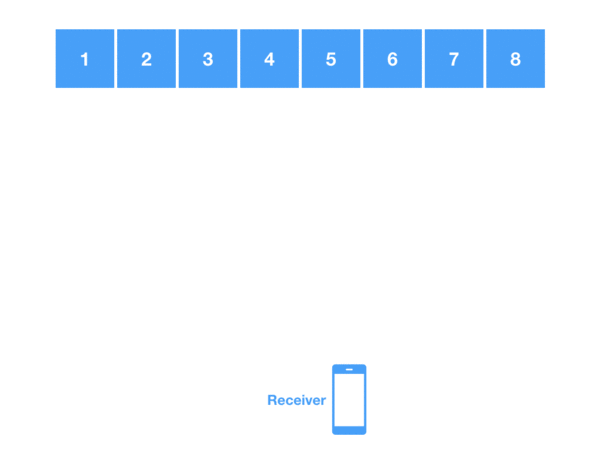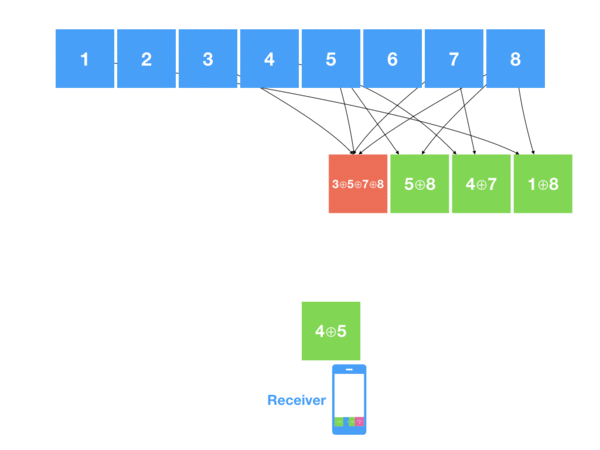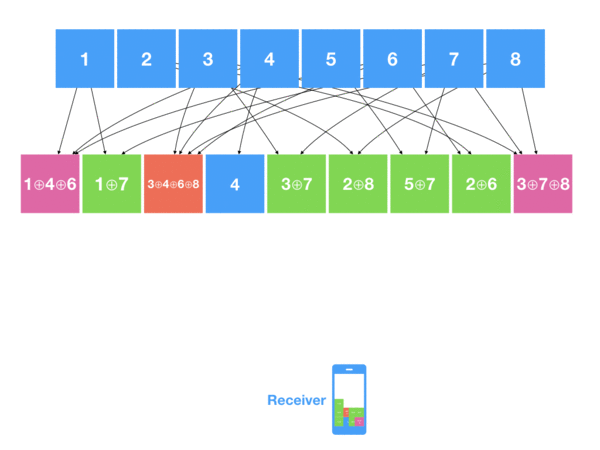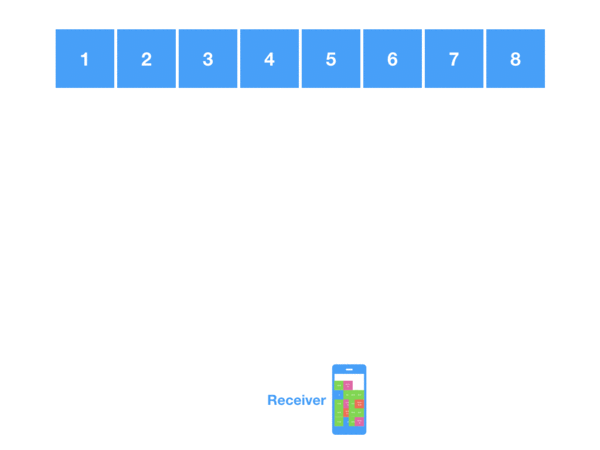
Если вкратце, исходные данные делятся на блоки, которые рандомно XOR-ятся в закодированные блоки, которые уже отправляются в фреймы. Некоторые блоки могут не склеиваться, что уменьшает оверхед. На клиенте получаемые из фреймов блоки XOR-ятся с уже полученными данными, в итоге получается проверенная на ошибки исходная структура данных. Больше почитать можно на вики и в статье Ивана про переход на фонтанные коды. В общем, несмотря на существенный оверхед, скорость декодирования данных существенно возросла:

Теперь в пике TXQR выдаёт около 25 KB/s при низком уровне коррекции ошибок. Запомним это значение и перейдём к его преемнику, созданному двумя годами позже. Встречайте,
Cimbar
Cimbar (Color Icon Matrix bar codes) ещё больше отошёл от стандарта QR-кода, сохранив только визуальное сходство. Этот формат выжимает как можно большую пропускную способность, используя сразу цвета, иконки 8х8 вместо обычных пикселей и, разумеется, анимацию. В одну клетку кодируется 4 бита информации, и еще 2 или 3 бита добавляется за счёт использования цветовой схемы (на 4 или 8 цветов), позволяя хранить до 7 бит в одной клетке:

Кодирование в cimbar происходит по алгоритму, схожему с хэшированием изображений: декодер сравнивает тайл 4х4 со словарем из 16 ожидаемых тайлов и выбирает тот, у которого оказывается самый близкий хэш. Аналогично, для каждого тайла берётся средний цвет и сравнивается со словарём ожидаемых цветов, затем выбирается ближайший. Затем полученные данные проходят проверку ошибок по комбинации кода Рида — Соломона, для фонтанных кодов используется wirehair. В текущем (не окончательном) формате размер сетки 1024х1024 символа, и при использовании на маленьких экранах или с плохой камерой код не всегда читается хорошо, поэтому разработчик обдумывает вариант пожертвовать пропускной способностью в угоду универсальности.
Выглядит итоговая картинка довольно жутко и эпилептично, но позволяет добиться при обычном уровне коррекции стабильных 700-800 KB/s! Это в 32 раза быстрее чем пиковая скорость TXQR при заниженной коррекции ошибок, и в этом можно убедиться самостоятельно:
- Заходим на cimbar.org и загружаем файл потяжелее. Сначала лучше не уходить в крайности, я разок попробовал загрузить 10-мегабайтный .apk и устал держать телефон на весу, пока он качался, поэтому начинать стоит с 500KB-2MB.
- Качаем приложение под Android
- Включаем режим полёта и сканируем код. Не забудьте выбрать нужную цветовую палитру, по умолчанию на сайте и в приложении стоит 4 цвета.
- Наслаждаемся магией!
Заключение
Пока проект существует как PoC, но разработчик явно хочет довести его до ума и развить в полезный стандарт. Доки и реализация на питоне лежат в основном репозитории, оптимизированная библиотека на C/C++ живёт отдельно, мобильное приложение здесь. На сайте cimbar.org кодировщик работает через wasm, репо найти не удалось.
Air-gapped передача данных это круто и всегда весело придумывать сценарии использования для них. Я уже попробовал передавать приложения через cimbar и вижу в этом много интересных возможностей. Если у вас тоже появились оригинальные идеи, обсудим в комментариях.
На правах рекламы
Наша компания предлагает аренду VPS для совершенно любых проектов. Предлагаем широкий выбор тарифных планов, максимальная конфигурация позволит разместить практически любой проект — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe!






























Tyusha
По-моему, QR-код в целом мало востребован. Вот сколько раз за прошедший год вы пользовались QR-кодом. Мне кажется, я раз или два, и то в этом не было большой необходимости.
braineater
Почти все платежки, коммунальные, налоговые имеют QR код для быстрой оплаты. Зеленый и красный банки точно умеют их считывать.
vikarti
Иметь то имеют только вот:
— часто это не QR-код а Aztec-код (вариация на туже тему, визуально отличается например тем что нет квадратиков в углах)
— нет стандарта (точнее есть но есть и документы которые ему не соответствуют и их авторы говорят что у них — все правильно) на то, что и как писать в этот код (и некоторые получатели считают что все нормально когда при оплате им по реквизитам в их же QR-коде — они не видят кто платеж делал, мол руками добавляйте)
— нет стандарта на кодировку. Соответственно как минимум один региональный банк тупо пробует перекодировать строки по разному (для всех существующих кодировок русского языка включая экзотику вроде iso-8859-5 и скидывает все варианты бэку а то пробует найти хоть что-то (для автоопределения кодировки текста слишком мало)).
geher
В подавляющем количестве квитанций это именно QR код. А так, да, иногда встречается и экзотика, например, Datamatrix.
Проблемы при формировании QR кода иногда случаются, но это всегда ошибка компании, напечатавшей квитанцию. Как правило в следующем месяце квитанция приходит уже с правильным QR кодом.
vikarti
У меня другой опыт на этот счет.
И как разработчика и как обычного пользователя который по этому коду платить пробует а потом начинаются выяснения почему в следующий квитанции долги.
inkelyad
Если компания ухитряется платежные атрибуты в этом QR коде (я так понимаю, про ГОСТ Р 56042-2014 речь идет) неправильно записать, то она с тем же успехом их неправильно печатает и прямо в самой платежке.
Т.е. попытка оплатить без кода, а по тому, что напечатано — не к тому же ли результату приведет?
vikarti
По тому что напечатано — проходит нормально.
inkelyad
Тогда это очень странно, потому что чтение этого кода, по существу, должно просто заполнять те же самые поля, что иначе вводятся вручную.
Yamazaki123
А вы уверены, что платежка не подменена мошенниками? Схема не самая редкая. Человек глазом обычно графические коды читать не умеет, никаких степеней защиты у документа нет, его просто суют в ящик, люди точно так же суют код в глаз банкомата…
vikarti
Получатель тот же (ИНН/Название). Альтернативных номеров лицевых счетов и прочего просто нет.
AntonioXXX
Про красный не знаю, а зеленый и желтый сами умеют и так подтягивать всё, что нужно для оплаты стандартных платежек.
Toxygen
>Зеленый и красный банки
К чему эти загадки? Почему не называть вещи своими именами?
mrtippler
QR-код на бумажных счетах — это когда-то безусловно был прорыв. Но и эта технология уже постепенно становится ненужной.
Можно просто настроить автоматическую оплату всех счетов за коммунальные услуги, интернет, мобильную связь и пр. регулярные услуги, что определенно быстрее любых QR-кодов.
Я, например, давно это сделал и с удовольствием забыл о необходимости вообще ждать, когда мне принесут бумажный счет и положат его в ящик, сканировать какие-либо коды и нажимать лишние кнопки.
Одно напрягает — показания счетчиков мне пока приходится передавать вручную через личные кабинеты на сайтах поставщиков услуг. Но и эта проблема со временем, думаю, будет решена, потому что давно уже существуют счетчики воды, электроэнергии и т.д., которые могут работать в составе автоматизированных систем учета.
saboteur_kiev
Большой плюс этой технологии, что ссылку можно печатать где угодно. И это плохо работает в стране, где плохо с цифровизацией.
А так — это удобная интеграция с чем угодно.
sumanai
Я бы в своём доме не стал, ибо они имеют свойство меняться, а пару лет назад так вообще подрались и одно время приходило до 3 квитанций от разных поставщиков на один вид услуги. Так вот улетят деньги, а потом концы не найдёшь.
mrtippler
Согласен, не всегда автоплатеж удобен. В вашем конкретном случае, когда постоянно меняются поставщики услуг, лучше проявить осторожность и сначала выяснить кому следует платить…
Ну или когда переезжаешь с места на место, тоже нет смысла настраивать автоплатеж.
Мне удобно — я не переезжаю, и поставщики услуг у меня не меняются.
mistergrim
Ссылки на телефон очень удобно кидать с ПК.
AntonioXXX
А кто генерирует на ПК этот QR-код?
По мне так проще через телеграм кидать (Saved Messages).
JTG
Телеграм — лишнее звено :) Через kdeconnect.kde.org можно кидаться файлами между девайсами, синхронизировать буфер обмена, выводить уведомления с одного девайса на другом и ещё кучу всего. Работает в т.ч. под виндой.
saboteur_kiev
QR код генерирует нужный код здесь и сейчас без лишних сайтов и сервисов, на которых еще непонятно что можно подловить
PsyHaSTe
Не лишнее, потому что хранит историю и не требует заводить +1 приложение, а ещё нативно работает под винду (где у kdeconnect какой-то "early build" только)
Oxyd
Ну сегодня early, а завтра, глядишь уже и допилят до полноценной поддержки.
FTOH
Хром умеет chrome://flags/#sharing-qr-code-generator

mistergrim
Браузерных расширений для этого полно.
legolegs
Например, tab2qr. Есть ли для хрома — не знаю.
QR-код работает без интернета и без собственно сети вообще. Приватность, опять же.
trixy
не знаю почему, но ваш коммент заставил меня задуматься, неужели 2021 год и… нет все ок, в хроме в контекстном меню есть send to your devices. А так бы и дальше через телеграмм перекидывал, хех
juramehanik
в b2b решениях в логистике и складском учете qr код все больше и больше вытесняет data matrix
а это рынок куда крупнее оплаты жкх по коду
saboteur_kiev
У него просто небольшая ниша, но он востребован.
При этом основное удобство QR-кода — в том, что почти на каждом телефоне он уже считывается практически без необходимости стороннего софта.
С другой стороны, считываются в основном только урл-ы, и в отдельных программах свои данные.
Но я согласен, что напрашивается что-то более универсальное, и подходящее для передачи бОльшего объема данных.
Leopotam
В принципе, можно слать специальный линк с урл-схемой (deeplink), на которую зарегано специальное приложение, которое по урлу сможет считать то, что нужно. Вот только смысл теряется в этом случае, т.к надо ставить специальный софт, который уже может качать все что-угодно более простым способом.
Mox
Даже на входах в клубы в Мск были QR коды для регистрации посетителей для covid оповещения.
DmitryLTL
В Китае нищие милостыню просят через QR. Там у большинства кэша вообще нету с собой.
tvr
High Tech, Low Life или киберпанк, который мы заслужили.
Он уже здесь.
tommyangelo27
Я пользовался около 12 раз (примерно раз в месяц на бесконтактной заправке машину заправляю). Больше нигде QR кодов не видел.
pashe
А как же WnatsApp?
philya
Маркировка сигарет, колес, лекарств и всего прочего — это датаматрикс и qr-коды. Скоро каждый из нас будет ежедневно пользоваться, иначе в магазине товар не отдадут.