
Когда много работаешь с данными, нужно часто строить графики и делать разными преобразования над таблицами. Важно научиться делать это быстро и минимально напрягая мозг. Дело в том, что анализ данных во многом заключается в придумывании и проверке гипотез. Придумывать, конечно, интереснее, чем проверять. Но делать нужно и то и другое. Хорошие инструменты в тренированных руках помогают тратить на техническую работу минимальное количество времени и интеллектуальной энергии.
Я попробовал много инструментов: Excel, Python+Matplotlib, R+ggplot, Python+ggplot, и остановился на связке Python+Pandas+Seaborn. Решил с их использованием уже много задач и хотел бы поделиться наблюдениями.
Я покажу процесс исследования одного странного датасета. Речь пойдёт о расписании всех спортивных мероприятий с участием российских спортсменов за последние 8 лет. Кстати, если у кого-то после прочтения появятся идеи, что с этими данными делать, пожалуйста, напишите, потому что я ничего толкового так и не придумал.
Захватывающий этап парсинга rst и doc-файликов с сайта Минспорта я пропускаю. Предположим, что все данные уже есть в виде DataFrame'a:
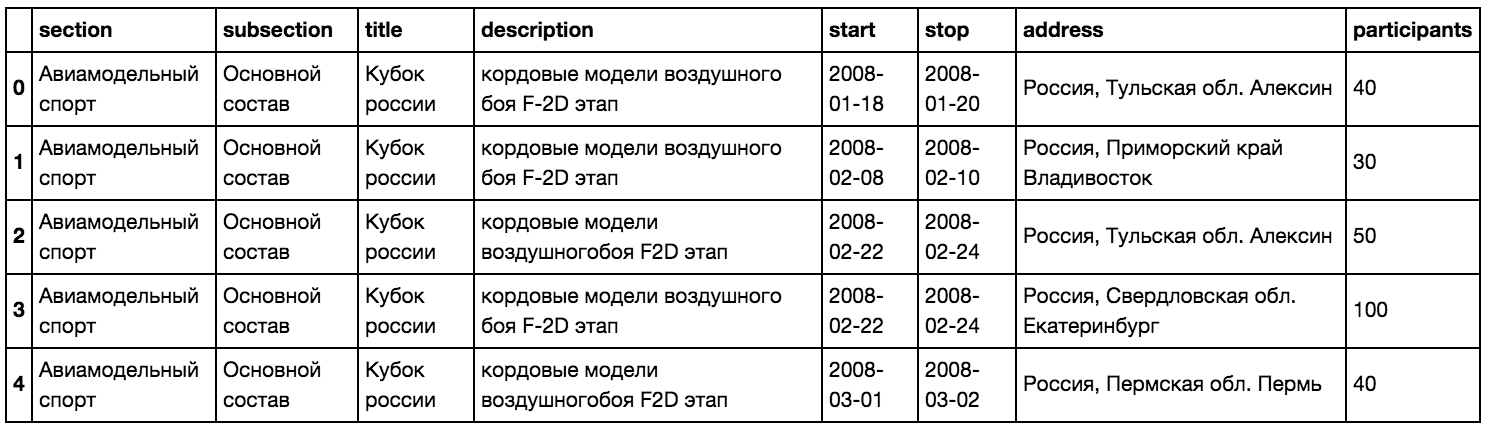
Таблица не большая, но и не маленькая:
Первым делом хотелось бы посмотреть, какие виды спорта представлены:
Отсортируем:
Достаточно странный топ. Отсортируем не по числу мероприятий, а по числу участников:
Так лучше. Теперь нарисуем график для топ-30:
Я не фанат супер-сурового инженерного дизайна, поэтому всегда импортирую Seaborn:
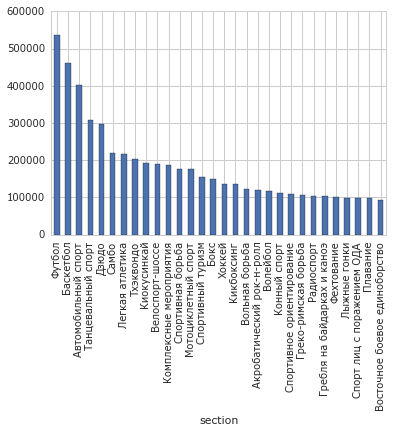
Идеально! Никакой другой функциональности Seaborn здесь использовано не будет. У меня чаще всего так и получается — Seaborn появляется только, чтобы графики стали красивыми. Это уже немало, но, вообще, библиотека умеет много чего другого.
Теперь интересно посмотреть на изменение числа мероприятий во времени. Всё то же самое только группировать нужно по дате:
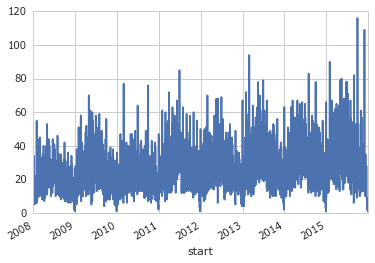
Почти готово. Нужно сделать детализацию, например, по неделям, а не по дням:
Было бы интереснее посмотреть на этот граф в разбивке по видам спорта. Для этого нужно сгруппировать данные по дате и виду спорта:
И нарисовать:
Блестяще, ничего не понятно. Для начала уберём всё кроме топ-40 видов спорта, кстати, код для расчёта топа уже есть, заново не надо писать:
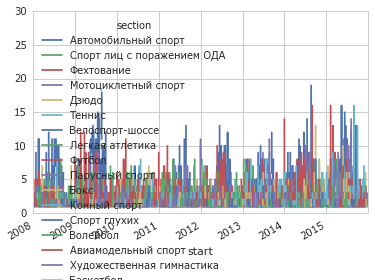
Ладно, сделаем детализацию по неделям:
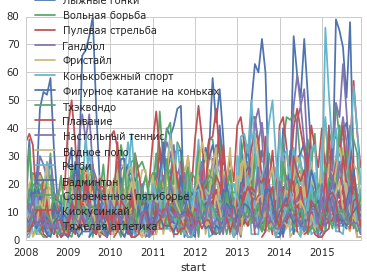
Почти то, что надо, теперь расположим каждую линию на отдельном графике:
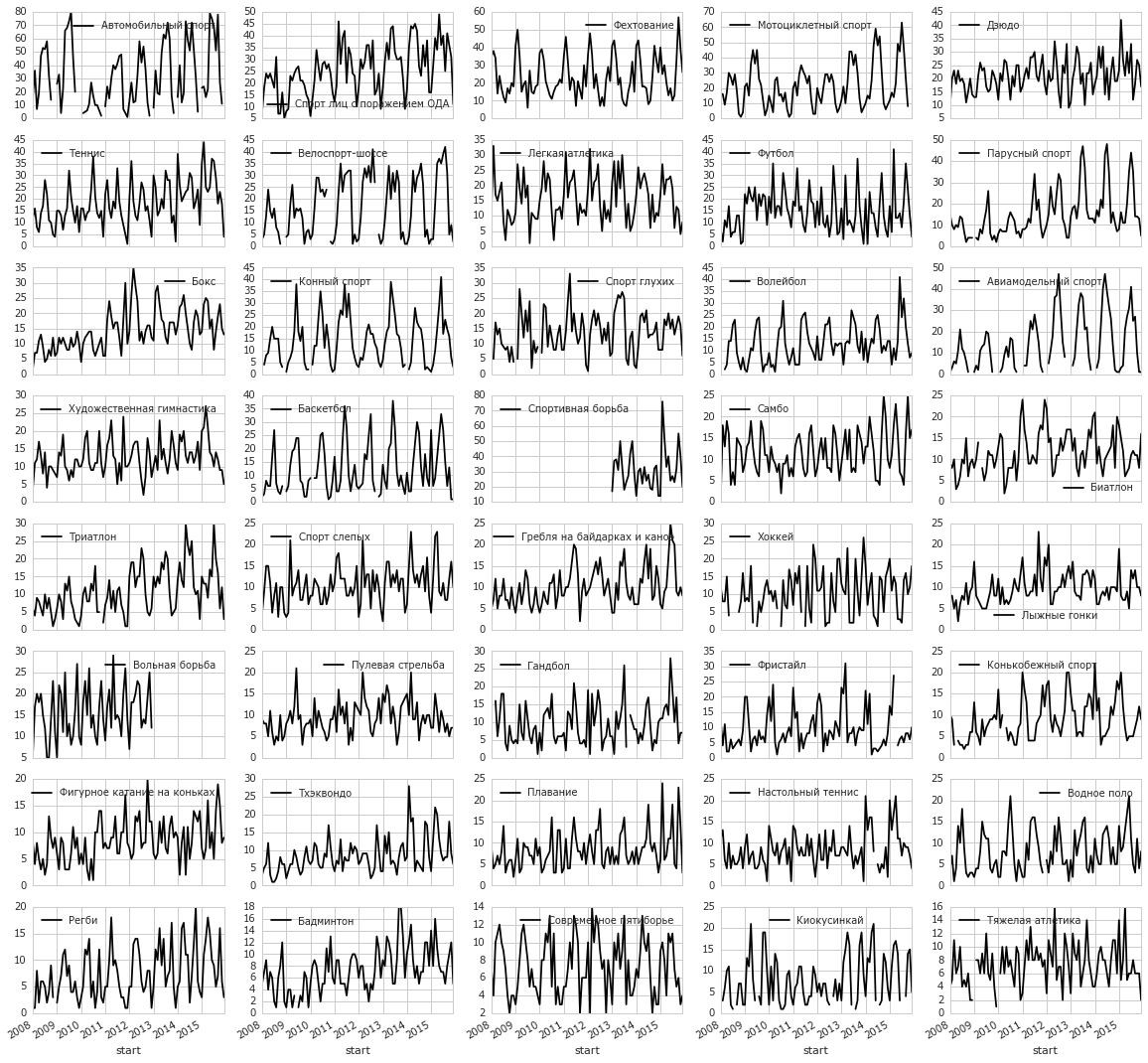
Что мне нравится в этом подходе? Функция plot очень простая, у неё всего несколько важных аргументов: kind, subplots, figsize. Результат зависит в основном от структуры данных, для которых вызывается plot. То есть не нужно осваивать отдельно инструмент для рисования графиков. Нужно научиться преобразовывать данные. С Pandas это сделать не очень сложно. Достаточно выучить несколько «кирпичиков»: groupby, sort, head, pivot_table, reindex, resample, и применять их в разных комбинациях.
Я попробовал много инструментов: Excel, Python+Matplotlib, R+ggplot, Python+ggplot, и остановился на связке Python+Pandas+Seaborn. Решил с их использованием уже много задач и хотел бы поделиться наблюдениями.
Я покажу процесс исследования одного странного датасета. Речь пойдёт о расписании всех спортивных мероприятий с участием российских спортсменов за последние 8 лет. Кстати, если у кого-то после прочтения появятся идеи, что с этими данными делать, пожалуйста, напишите, потому что я ничего толкового так и не придумал.
Захватывающий этап парсинга rst и doc-файликов с сайта Минспорта я пропускаю. Предположим, что все данные уже есть в виде DataFrame'a:
data.head()
Таблица не большая, но и не маленькая:
len(data)
76601
Первым делом хотелось бы посмотреть, какие виды спорта представлены:
table = data.groupby('section').size()
table
section
R4 11
Авиамодельный спорт 1206
Автомобильный спорт 2787
Автомодельный спорт 160
Айкидо 26
Айсшток 49
Академическая гребля 358
Акробатический рок-н-ролл 293
Альпинизм 355
Американский футбол 86
Армейский рукопашный бой 15
Армспорт 159
Бадминтон 698
Баскетбол 1160
Бейсбол 176
Биатлон 1101
Бильярдный спорт 442
Бобслей 53
Бобслей (скелетон) 368
Бодибилдинг 94
Бокс 1374
Борьба на поясах 144
Боулинг 134
...
Отсортируем:
table = data.groupby('section').size()
table = table.sort(inplace=False, ascending=False)
table
section
Автомобильный спорт 2787
Спорт лиц с поражением ОДА 2469
Фехтование 2253
Мотоциклетный спорт 2025
Дзюдо 2022
Теннис 1770
Велоспорт-шоссе 1561
Легкая атлетика 1511
Футбол 1432
Парусный спорт 1418
Бокс 1374
Конный спорт 1297
Спорт глухих 1277
Волейбол 1208
Авиамодельный спорт 1206
Художественная гимнастика 1196
...
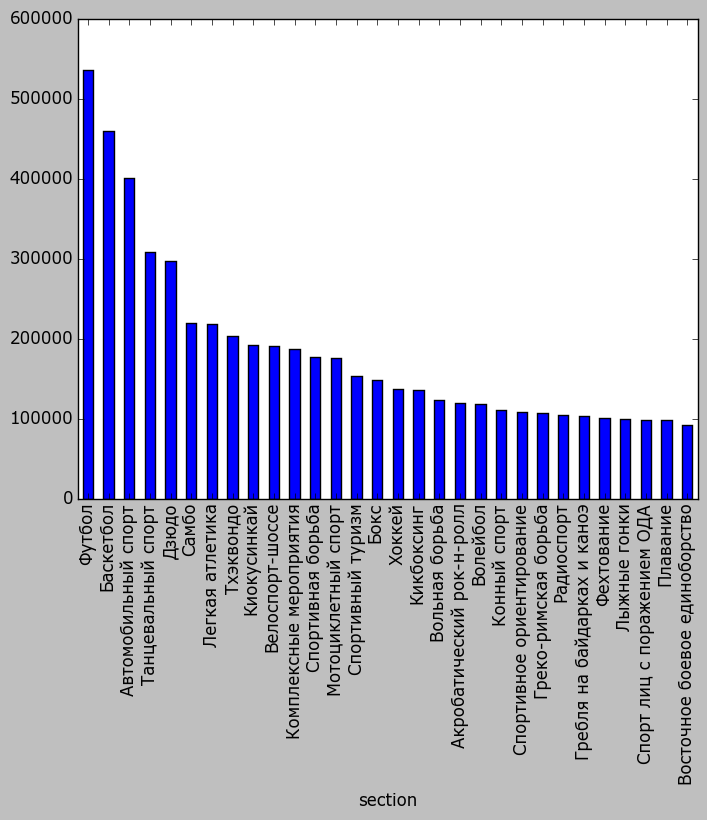
Достаточно странный топ. Отсортируем не по числу мероприятий, а по числу участников:
table = data.groupby('section').participants.sum()
table = table.sort(inplace=False, ascending=False)
table
Футбол 535305
Баскетбол 460100
Автомобильный спорт 401397
Танцевальный спорт 307731
Дзюдо 297023
Самбо 219013
Легкая атлетика 217761
Тхэквондо 202859
Киокусинкай 191995
Велоспорт-шоссе 190293
Комплексные мероприятия 187294
Спортивная борьба 177312
Мотоциклетный спорт 176387
Спортивный туризм 153417
Бокс 148654
Хоккей 136849
Кикбоксинг 136099
...
Так лучше. Теперь нарисуем график для топ-30:
table = data.groupby('section').participants.sum()
table = table.sort(inplace=False, ascending=False)
table.head(30).plot(kind='bar')
Я не фанат супер-сурового инженерного дизайна, поэтому всегда импортирую Seaborn:
import seaborn
table = data.groupby('section').participants.sum()
table = table.sort(inplace=False, ascending=False)
table.head(30).plot(kind='bar')
Идеально! Никакой другой функциональности Seaborn здесь использовано не будет. У меня чаще всего так и получается — Seaborn появляется только, чтобы графики стали красивыми. Это уже немало, но, вообще, библиотека умеет много чего другого.
Теперь интересно посмотреть на изменение числа мероприятий во времени. Всё то же самое только группировать нужно по дате:
table = data.groupby('start').size()
table.plot()
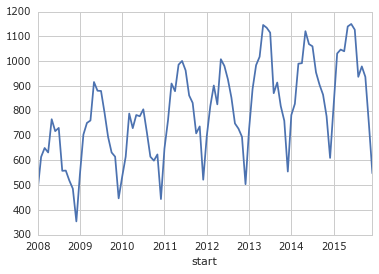
Почти готово. Нужно сделать детализацию, например, по неделям, а не по дням:
table = data.groupby('start').size()
table = table.resample('M', how='sum')
table.plot()
- Спортивная жизнь зимой наименее активна.
- Тренд до последнего времени восходящий.
- В 2010 был какой-то провал.
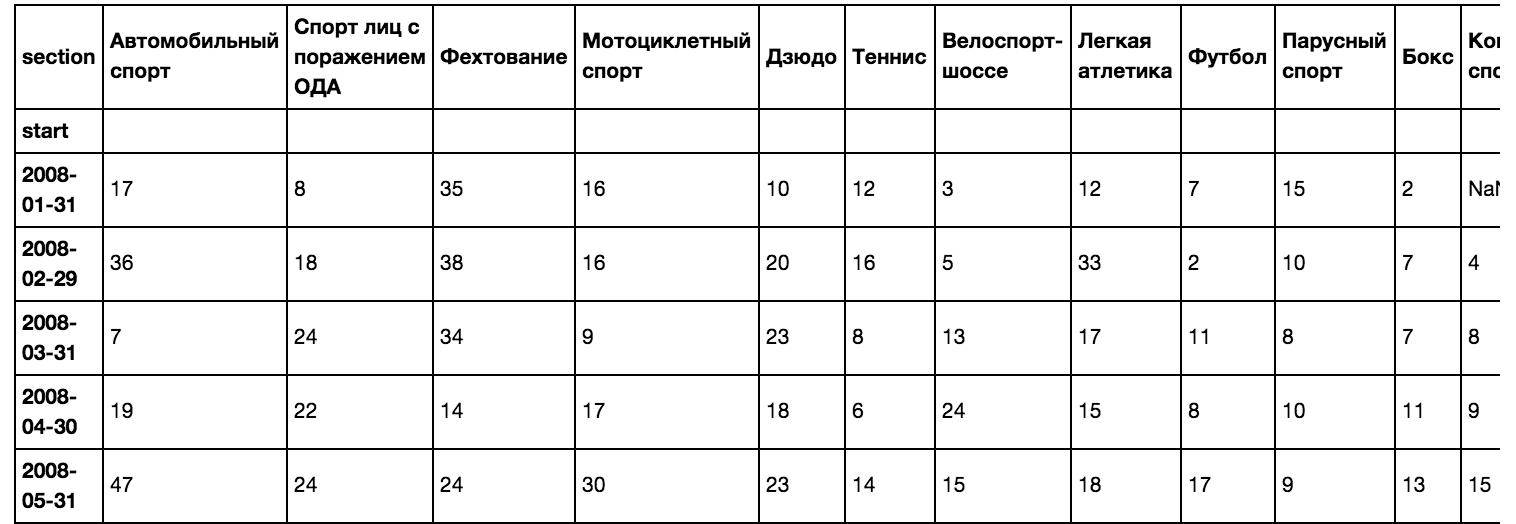
Было бы интереснее посмотреть на этот граф в разбивке по видам спорта. Для этого нужно сгруппировать данные по дате и виду спорта:
table = data.pivot_table(index='start', columns='section', values='participants', aggfunc=len)
table.head()
И нарисовать:
table.plot()
Блестяще, ничего не понятно. Для начала уберём всё кроме топ-40 видов спорта, кстати, код для расчёта топа уже есть, заново не надо писать:
table = data.groupby('section').size()
table = table.sort(inplace=False, ascending=False)
order = table.head(40).index
table = data.pivot_table(index='start', columns='section', values='participants', aggfunc=len)
table = table.reindex(columns=order)
table.plot()
Ладно, сделаем детализацию по неделям:
table = data.groupby('section').size()
table = table.sort(inplace=False, ascending=False)
order = table.head(40).index
table = data.pivot_table(index='start', columns='section', values='participants', aggfunc=len)
table = table.reindex(columns=order)
table = table.resample('M', how='sum')
table.plot()
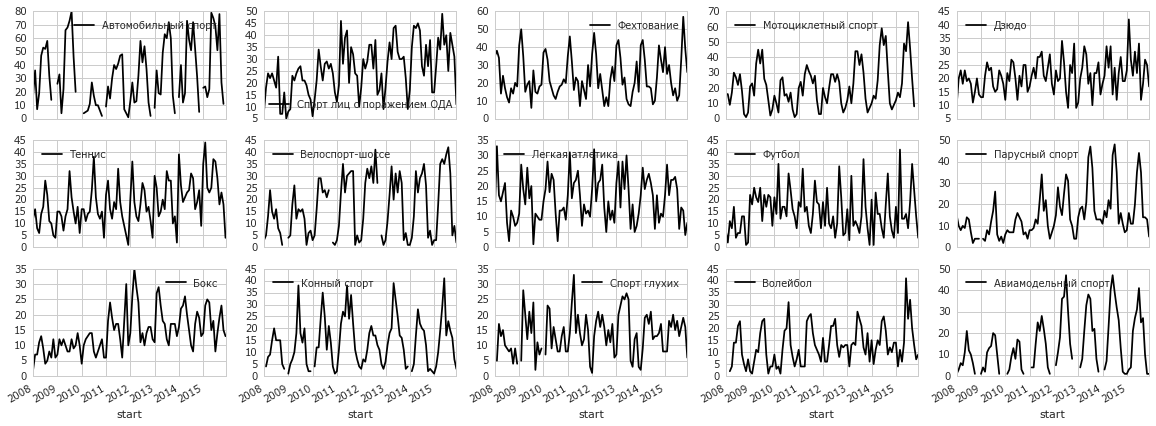
Почти то, что надо, теперь расположим каждую линию на отдельном графике:
table = data.groupby('section').size()
table = table.sort(inplace=False, ascending=False)
order = table.head(40).index
table = data.pivot_table(index='start', columns='section', values='participants', aggfunc=len)
table = table.reindex(columns=order)
table = table.resample('M', how='sum')
table.plot(subplots=True, layout=(8, 5), figsize=(20, 20))
- Для некоторых видов наблюдаются тренды в числе мероприятий:
- Сильно растёт спорт для инвалидов (лиц с поражением ОДА) и автомобильный спорт.
- Слегка растёт мотоциклетный спорт, дзюдо, самбо, парусный спорт, волейбол, тхэквондо, бадминтон.
- У футбола какой-интересный тренд.
- Бокс перестал расти в 2012 году.
- Надо отметить что падения числа мероприятий нигде не наблюдается.
- Иногда есть периодичность в числе мероприятий, что не удивительно:
- Парусный спорт, конные спорт, авиамодельный спорт, велоспорт замирают зимой.
- Вообще зимой у многих видов затишье. Но бывает и наоборот, например, во фристайле.
- Интересный рисунок у тенниса и лёгкой атлетики, который повторяется каждый год
Что мне нравится в этом подходе? Функция plot очень простая, у неё всего несколько важных аргументов: kind, subplots, figsize. Результат зависит в основном от структуры данных, для которых вызывается plot. То есть не нужно осваивать отдельно инструмент для рисования графиков. Нужно научиться преобразовывать данные. С Pandas это сделать не очень сложно. Достаточно выучить несколько «кирпичиков»: groupby, sort, head, pivot_table, reindex, resample, и применять их в разных комбинациях.

PavelMSTU
Чем лучше/хуже Python+Matplotlib?
alexkuku
Простые графики, которые нужно строить часто, реализуются проще. Попробуй с matplotlib построить гистограмму с подписями-словами (первая картинка в тексте). А здесь table.plot(kind='bar'). При этом что-то сложное нужно делать через matplotlib. Scatter plot с точками разного размера и цвета через table.plot(...) не построишь