

Несколько лет назад, занимался изучением теории музыки, продавал и писал аудио-инструментал для аренды или заказов. Изначально, процесс явно творческий, но вскоре, мой интерес к коммерческой части превысил и возник вопрос: «В каком же темпе создавать ритм музыки?».
Мною была замечена тенденция вариаций темпа популярных песен одного жанра, поэтому идея анализа крупной выборки лучших композиций, для определения популярного [часто: самого продаваемого] диапазона темпа исполнения, не покидала с тех пор…
BPM [в музыке] — показатель, для определения скорости исполнения композиции, путём измерения количества тактовых долей в минуту.
1: Пролог
Устанавливаем «Matplotlib» и «Pandas» с необходимыми зависимостями через pip-менеджер в консоли/терминале.

Создаём директорию, а потом виртуальное окружение для проекта. После, подключаем библиотеки в IDE [в моём случае: PyCharm].
![File — Settings — Project: [...] — Python Interpreter](https://habrastorage.org/getpro/habr/upload_files/590/20a/990/59020a990cba62c14e17a86425e14cc4.gif "File — Settings — Project: [...] — Python Interpreter")
2: BPM
BPM будем вычислять через функцию «Detect tempo» в FL Studio и через сайт tunebat.com

3: DataSet
Начинаем создание DataSet’а [выборки-коллекции данных] в Excel, для каждого жанра. Экспортируем в CSV-формат с настройками разделителя — запятой. Следующие CSV-файлы создавал в IDE, так удобнее. Выборки перемещаем в директорию, где находится файл самой программы.
В первой строке CSV-файлов указываются параметры, которые разделяются запятыми. Следующие строки содержат уже значения этих параметров. При окончательной проверке, DataSet должен последовательно содержать данные: названия трека, BPM и год выхода композиции. Будем использовать информацию выборки в сто песен, для каждого жанра из выбранных пяти.

4: Rap — построение точечной диаграммы и гистограммы
Выборка взята здесь: rollingstone.com/100-greatest-hip-hop-songs-of-all-time
Сам CSV-DataSet: github.com/Rap.csv
На основе информации DataSet'а, создаём точечную диаграмму [Scatter Plots] для изучения взаимосвязи между BPM и годом выпуска, а также для отображения концентраций при ранжировании данных.

«Код точечной диаграммы с комментариями»
from matplotlib import pyplot as plt # Первый каноничный импорт
import pandas as pd # Второй каноничный импорт для обработки DataSet'а
plt.style.use('fivethirtyeight') # Назначаем стилистику визуализации
data_set = pd.read_csv('Rap.csv') # Считываем данные SCV-файла с DataSet'ом
bpm = data_set['bpm'] # Переменная, для параметра BPM в каждой строке
year = data_set['year'] # Переменная, для параметра "год релиза" в каждой строке
plt.scatter( # Построение точечного графика и его настройка
bpm, year, # Данные для осей «x» и «y»
c=bpm, # Привязка цвета к нужной оси
s=bpm*1.5, # Зависимость размера точки
cmap='gist_heat', # Цветовая карта графика
edgecolor='black', # Цвет контура точки
linewidth=.7 # Толщина контура точки
)
bar = plt.colorbar( # Построение шкалы BPM
orientation='horizontal', # Ориентация шкалы
shrink=0.8, # Масштаб шкалы
extend='both', # Скос краёв шкалы
extendfrac=.1 # Угол скоса краёв
)
bar.set_label('Шкала ударов в минуту', fontsize=18) # Подпись шкалы
plt.title('Популярность скорости ' # Заголовок графика
'исполнения в Rap\'е ', fontsize=25)
plt.xlabel('BPM', fontsize=18) # Ось абсцисс
plt.ylabel('Год релиза', fontsize=18) # Ось ординат
plt.tight_layout() # Настройка параметров подзаголовков в области отображения
plt.show() # Вывод на экранЕсли диаграмма отражает точечное положение трека в зависимости двух переменных, — BPM и года релиза, — то гистограмма покажет частоту-количество попаданий значения BPM для каждого диапазона на шкале. Таким образом, определится популярность определенного темпа.

«Код гистограммы без комментариев»
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
plt.style.use("fivethirtyeight")
data_set = pd.read_csv('Rap end.csv')
index = data_set['number']
ranges = data_set['bpm_range']
counter = Counter()
for index in ranges:
counter.update(index.split(';'))
range_bpm = []
value = []
for item in counter.most_common(100):
range_bpm.append(item[0])
value.append(item[1])
range_bpm.reverse()
value.reverse()
plt.barh(
range_bpm, value,
linewidth=.5,
edgecolor='black',
color='#e85b45',
label='Количество точек на предыдущем графике'
)
plt.legend()
plt.title('Популярность интервала значений BPM в rap\'е', fontsize=25)
plt.xlabel('Количество песен в диапазоне BPM', fontsize=18)
plt.ylabel('Диапазоны BPM', fontsize=18)
plt.tight_layout()
plt.show()5: Рок
Выборка взята здесь: rockfm.ru/top100
Сам CSV-DataSet: github.com/Rock.csv
Однозначности пока что нет, — особенность жанра. — поэтому, второй график построен при округлении параметра «year/год выхода композиции».

«Код точечной диаграммы с комментариями»
from matplotlib import pyplot as plt # Первый каноничный импорт
import pandas as pd # Второй каноничный импорт для обработки DataSet'а
plt.style.use('fivethirtyeight') # Назначаем стилистику визуализации
data_set = pd.read_csv('Rock.csv') # Считываем данные SCV-файла с DataSet'ом
bpm = data_set['bpm'] # Переменная, для параметра BPM в каждой строке
year = data_set['year'] # Переменная, для параметра "год релиза" в каждой строке
plt.scatter( # Построение точечного графика и его настройка
bpm, year, # Данные для осей «x» и «y»
c=bpm, # Привязка цвета к нужной оси
s=bpm*1.5, # Зависимость размера точки
cmap='gist_heat', # Цветовая карта графика
edgecolor='black', # Цвет контура точки
linewidth=.7 # Толщина контура точки
alpha=.7 # Прозрачность точки
)
bar = plt.colorbar( # Построение шкалы BPM
orientation='horizontal', # Ориентация шкалы
shrink=0.8, # Масштаб шкалы
extend='both', # Скос краёв шкалы
extendfrac=.1 # Угол скоса краёв
)
bar.set_label('Шкала ударов в минуту', fontsize=18) # Подпись шкалы
plt.title('Популярность скорости ' # Заголовок графика
'исполнения в роке', fontsize=25)
plt.xlabel('BPM', fontsize=18) # Ось абсцисс
plt.ylabel('Год релиза', fontsize=18) # Ось ординат
plt.tight_layout() # Настройка параметров подзаголовков в области отображения
plt.show() # Вывод на экран
«Код гистограммы без комментариев»
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
plt.style.use("fivethirtyeight")
data_set = pd.read_csv('Rock end.csv')
index = data_set['number']
ranges = data_set['bpm_range']
counter = Counter()
for index in ranges:
counter.update(index.split(';'))
range_bpm = []
value = []
for item in counter.most_common(100):
range_bpm.append(item[0])
value.append(item[1])
range_bpm.reverse()
value.reverse()
plt.barh(
range_bpm, value,
linewidth=.5,
edgecolor='black',
color='#e85b45',
label='Количество точек на предыдущем графике'
)
plt.legend()
plt.title('Популярность интервала значений BPM в роке', fontsize=25)
plt.xlabel('Количество песен в диапазоне BPM', fontsize=18)
plt.ylabel('Диапазоны BPM', fontsize=18)
plt.tight_layout()
plt.show()6: Блюз
Выборка взята здесь: digitaldreamdoor.com/best_bluesong
Сам CSV-DataSet: github.com/Blues.csv

«Код точечной диаграммы с комментариями»
from matplotlib import pyplot as plt # Первый каноничный импорт
import pandas as pd # Второй каноничный импорт для обработки DataSet'а
plt.style.use('fivethirtyeight') # Назначаем стилистику визуализации
data_set = pd.read_csv('Blues.csv') # Считываем данные SCV-файла с DataSet'ом
bpm = data_set['bpm'] # Переменная, для параметра BPM в каждой строке
year = data_set['year'] # Переменная, для параметра "год релиза" в каждой строке
plt.scatter( # Построение точечного графика и его настройка
bpm, year, # Данные для осей «x» и «y»
c=bpm, # Привязка цвета к нужной оси
s=bpm*1.5, # Зависимость размера точки
cmap='gist_heat', # Цветовая карта графика
edgecolor='black', # Цвет контура точки
linewidth=.7 # Толщина контура точки
)
bar = plt.colorbar( # Построение шкалы BPM
orientation='horizontal', # Ориентация шкалы
shrink=0.8, # Масштаб шкалы
extend='both', # Скос краёв шкалы
extendfrac=.1 # Угол скоса краёв
)
bar.set_label('Шкала ударов в минуту', fontsize=18) # Подпись шкалы
plt.title('Популярность скорости ' # Заголовок графика
'исполнения в блюзе', fontsize=25)
plt.xlabel('BPM', fontsize=18) # Ось абсцисс
plt.ylabel('Год релиза', fontsize=18) # Ось ординат
plt.tight_layout() # Настройка параметров подзаголовков в области отображения
plt.show() # Вывод на экран
«Код гистограммы без комментариев»
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
plt.style.use("fivethirtyeight")
data_set = pd.read_csv('Blues end.csv')
index = data_set['number']
ranges = data_set['bpm_range']
counter = Counter()
for index in ranges:
counter.update(index.split(';'))
range_bpm = []
value = []
for item in counter.most_common(100):
range_bpm.append(item[0])
value.append(item[1])
range_bpm.reverse()
value.reverse()
plt.barh(
range_bpm, value,
linewidth=.5,
edgecolor='black',
color='#e85b45',
label='Количество точек на предыдущем графике'
)
plt.legend()
plt.title('Популярность интервала значений BPM в блюзе', fontsize=25)
plt.xlabel('Количество песен в диапазоне BPM', fontsize=18)
plt.ylabel('Диапазоны BPM', fontsize=18)
plt.tight_layout()
plt.show()7: Chillout
Выборка взята здесь: open.spotify.com
Сам CSV-DataSet: github.com/Chillout.csv
Много наложений точек друг на друга. К сожалению, не знаю, как это исправить. Пришлось сделать точки более прозрачными, с помощью аргумента «alpha» функции «.scatter».
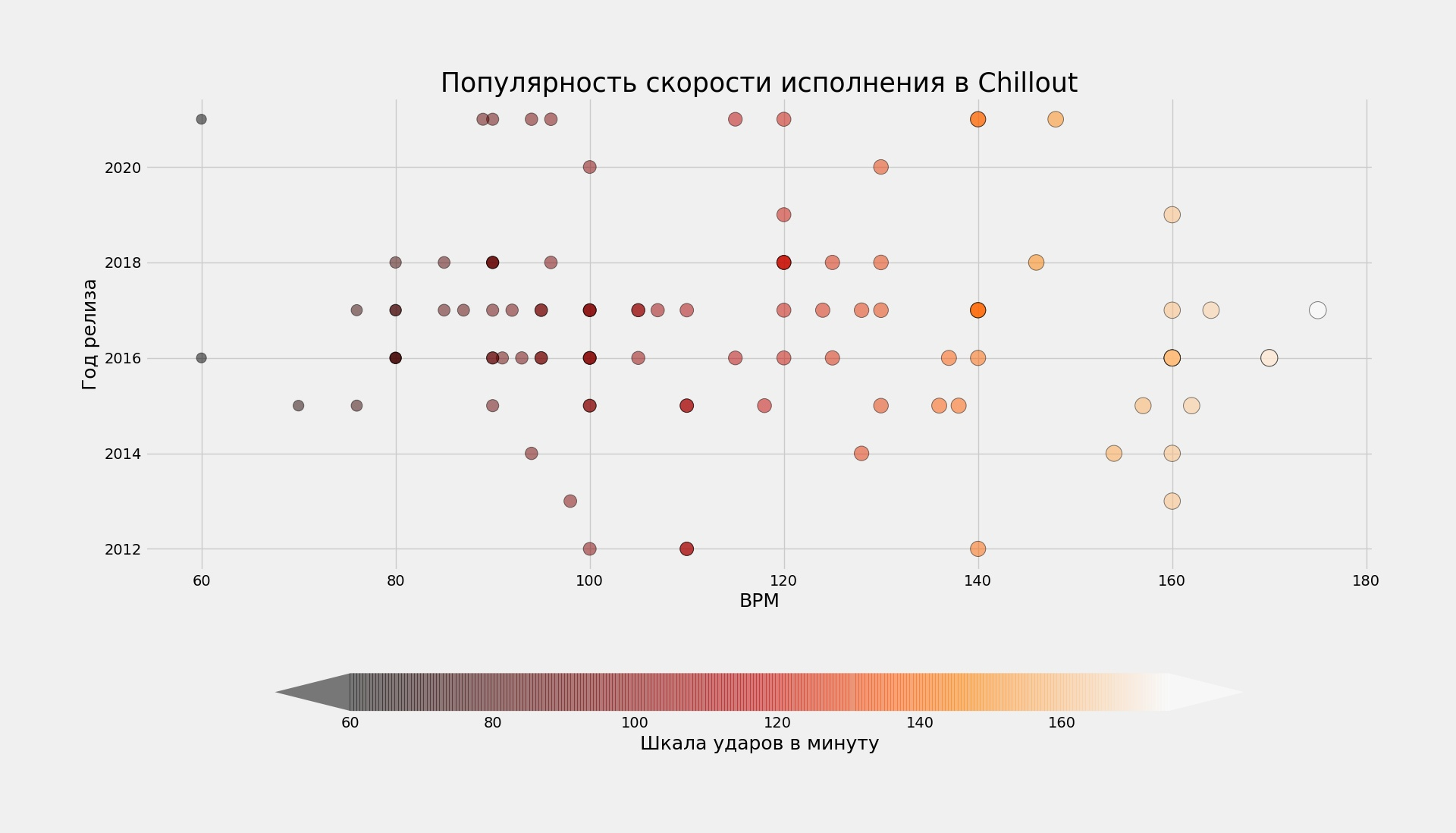
«Код точечной диаграммы с комментариями»
from matplotlib import pyplot as plt # Первый каноничный импорт
import pandas as pd # Второй каноничный импорт для обработки DataSet'а
plt.style.use('fivethirtyeight') # Назначаем стилистику визуализации
data_set = pd.read_csv('Chillout.csv') # Считываем данные SCV-файла с DataSet'ом
bpm = data_set['bpm'] # Переменная, для параметра BPM в каждой строке
year = data_set['year'] # Переменная, для параметра "год релиза" в каждой строке
plt.scatter( # Построение точечного графика и его настройка
bpm, year, # Данные для осей «x» и «y»
c=bpm, # Привязка цвета к нужной оси
s=bpm*1.5, # Зависимость размера точки
cmap='gist_heat', # Цветовая карта графика
edgecolor='black', # Цвет контура точки
linewidth=.7 # Толщина контура точки
alpha=.5 # Прозрачность точки
)
bar = plt.colorbar( # Построение шкалы BPM
orientation='horizontal', # Ориентация шкалы
shrink=0.8, # Масштаб шкалы
extend='both', # Скос краёв шкалы
extendfrac=.1 # Угол скоса краёв
)
bar.set_label('Шкала ударов в минуту', fontsize=18) # Подпись шкалы
plt.title('Популярность скорости ' # Заголовок графика
'исполнения в Chillout', fontsize=25)
plt.xlabel('BPM', fontsize=18) # Ось абсцисс
plt.ylabel('Год релиза', fontsize=18) # Ось ординат
plt.tight_layout() # Настройка параметров подзаголовков в области отображения
plt.show() # Вывод на экран
«Код гистограммы без комментариев»
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
plt.style.use("fivethirtyeight")
data_set = pd.read_csv('Chillout end.csv')
index = data_set['number']
ranges = data_set['bpm_range']
counter = Counter()
for index in ranges:
counter.update(index.split(';'))
range_bpm = []
value = []
for item in counter.most_common(100):
range_bpm.append(item[0])
value.append(item[1])
range_bpm.reverse()
value.reverse()
plt.barh(
range_bpm, value,
linewidth=.5,
edgecolor='black',
color='#e85b45',
label='Количество точек на предыдущем графике'
)
plt.legend()
plt.title('Популярность интервала значений BPM в Chillout', fontsize=25)
plt.xlabel('Количество песен в диапазоне BPM', fontsize=18)
plt.ylabel('Диапазоны BPM', fontsize=18)
plt.tight_layout()
plt.show()8: EDM
Выборка взята здесь: edmcharts.net
Сам CSV-DataSet: github.com/EDM.csv
Здесь также для наглядности пришлось сделать точки ещё более прозрачными. Если кто-то знает, как исправить дефект наложения, прошу написать в комментариях.

«Код точечной диаграммы с комментариями»
from matplotlib import pyplot as plt # Первый каноничный импорт
import pandas as pd # Второй каноничный импорт для обработки DataSet'а
plt.style.use('fivethirtyeight') # Назначаем стилистику визуализации
data_set = pd.read_csv('EDM.csv') # Считываем данные SCV-файла с DataSet'ом
bpm = data_set['bpm'] # Переменная, для параметра BPM в каждой строке
year = data_set['year'] # Переменная, для параметра "год релиза" в каждой строке
plt.scatter( # Построение точечного графика и его настройка
bpm, year, # Данные для осей «x» и «y»
c=bpm, # Привязка цвета к нужной оси
s=bpm*1.5, # Зависимость размера точки
cmap='gist_heat', # Цветовая карта графика
edgecolor='black', # Цвет контура точки
linewidth=.7 # Толщина контура точки
alpha=.2 # Прозрачность точки
)
bar = plt.colorbar( # Построение шкалы BPM
orientation='horizontal', # Ориентация шкалы
shrink=0.8, # Масштаб шкалы
extend='both', # Скос краёв шкалы
extendfrac=.1 # Угол скоса краёв
)
bar.set_label('Шкала ударов в минуту', fontsize=18) # Подпись шкалы
plt.title('Популярность скорости ' # Заголовок графика
'исполнения в EDM', fontsize=25)
plt.xlabel('BPM', fontsize=18) # Ось абсцисс
plt.ylabel('Год релиза', fontsize=18) # Ось ординат
plt.tight_layout() # Настройка параметров подзаголовков в области отображения
plt.show() # Вывод на экран
«Код гистограммы без комментариев»
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
plt.style.use("fivethirtyeight")
data_set = pd.read_csv('EDM end.csv')
index = data_set['number']
ranges = data_set['bpm_range']
counter = Counter()
for index in ranges:
counter.update(index.split(';'))
range_bpm = []
value = []
for item in counter.most_common(100):
range_bpm.append(item[0])
value.append(item[1])
range_bpm.reverse()
value.reverse()
plt.barh(
range_bpm, value,
linewidth=.5,
edgecolor='black',
color='#e85b45',
label='Количество точек на предыдущем графике'
)
plt.legend()
plt.title('Популярность интервала значений BPM в EDM', fontsize=25)
plt.xlabel('Количество песен в диапазоне BPM', fontsize=18)
plt.ylabel('Диапазоны BPM', fontsize=18)
plt.tight_layout()
plt.show()9: Заключение
Самым простым графиком сравним количество попаданий в каждый диапазон, композиций, из всех проанализированных ранее жанров*.
* такие жанры как ethnic, ambient, folk, dubstep, reggae и др, не удалось к сожалению разобрать из-за отсутствия качественной выборки...
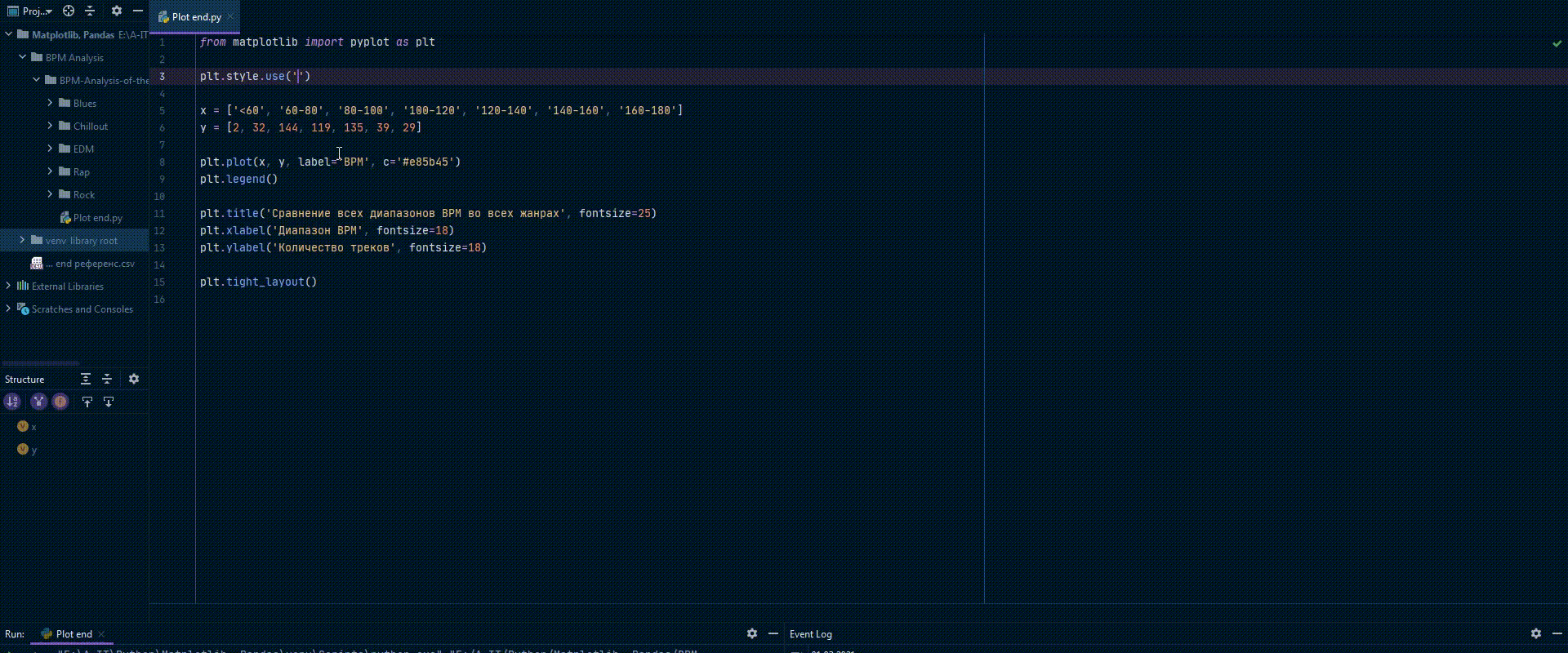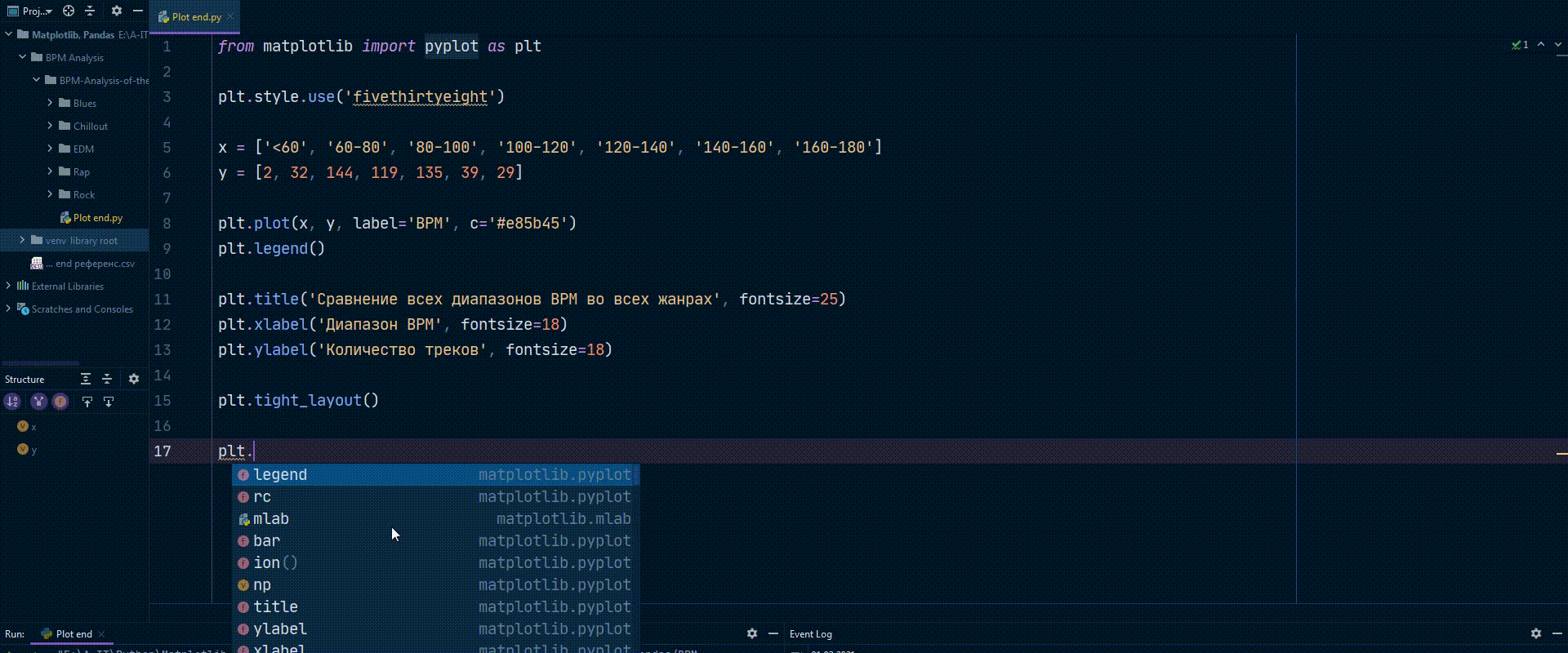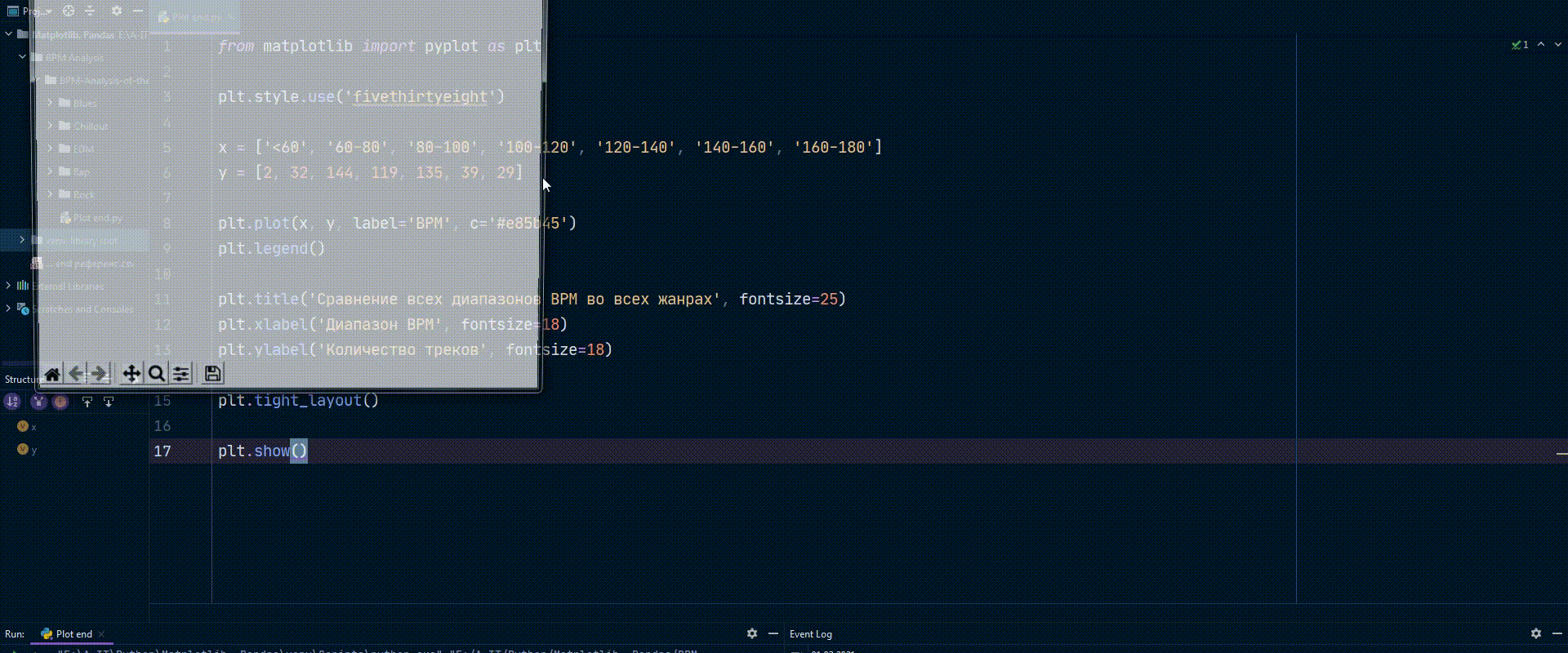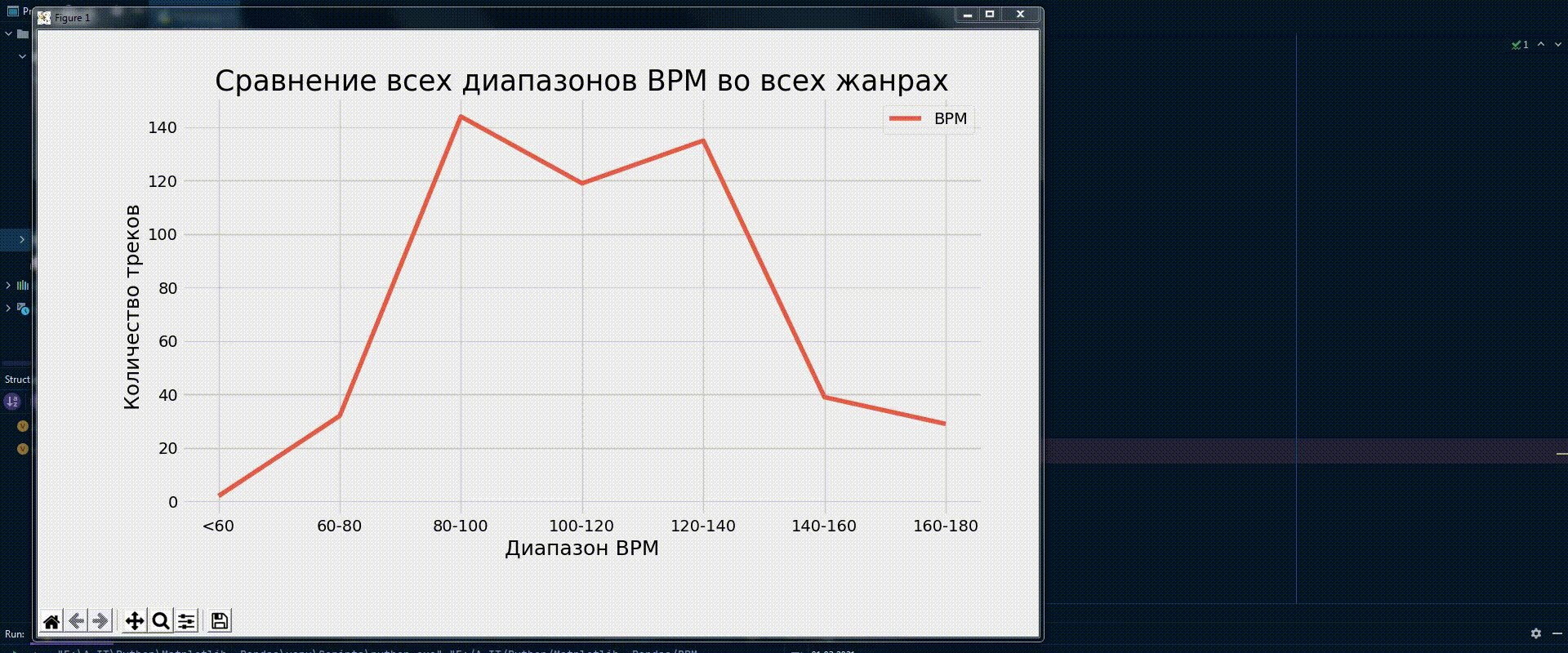
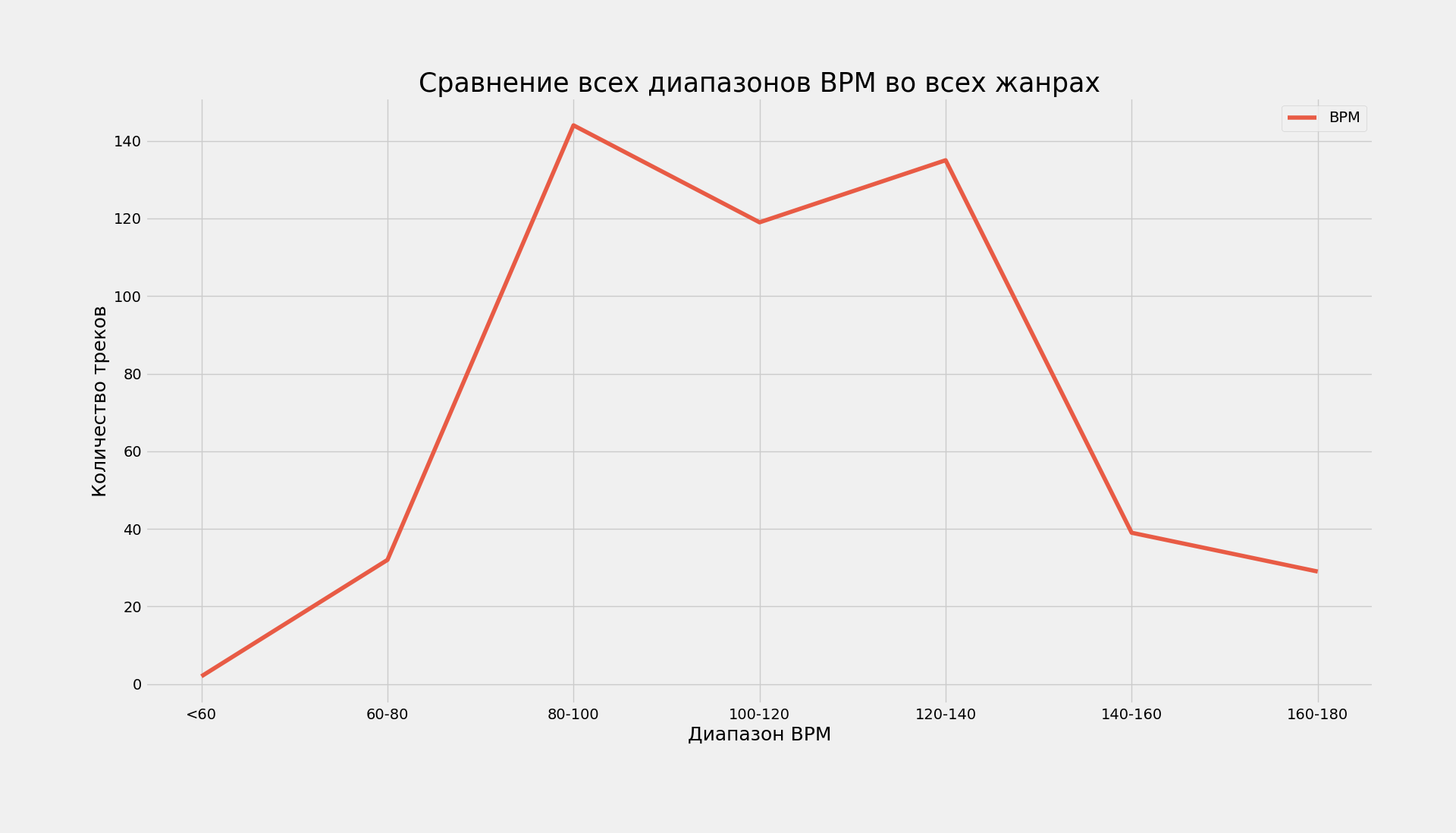
BPM/Кол-во треков | <60 | 60-80 | 80-100 | 100-120 | 120-140 | 140-160 | 160-180 |
Blues | 2 | 9 | 25 | 35 | 15 | 6 | 8 |
Chillout | 11 | 35 | 18 | 19 | 12 | 5 | |
EDM | 1 | 3 | 21 | 67 | 6 | 2 | |
Rap | 5 | 61 | 20 | 7 | 4 | 3 | |
Rock | 6 | 20 | 25 | 27 | 11 | 11 | |
Итог: | 2 | 32 | 144 | 119 | 135 | 39 | 29 |
«Простой код, простого графика»
from matplotlib import pyplot as plt
plt.style.use('fivethirtyeight')
x = ['<60', '60-80', '80-100', '100-120', '120-140', '140-160', '160-180']
y = [2, 32, 144, 119, 135, 39, 29]
plt.plot(x, y, label='BPM', c='#e85b45')
plt.legend()
plt.title('Сравнение всех диапазонов BPM во всех жанрах', fontsize=25)
plt.xlabel('Диапазон BPM', fontsize=18)
plt.ylabel('Количество треков', fontsize=18)
plt.tight_layout()
plt.show()




Sultansoy
Автор, а я правильно вас понял, что вы для 500 треков проклацали кнопки, чтобы получить бпм в фруктах?
SCUIIIPTOR Автор
Нет, это было бы невероятно долго и не разумно))
Функционал Fruity Loops использовался для тех композиций, данных о BPM которых, не было на сайте указанном в главе «BPM».