
Это первая часть статьи, в которой будет рассмотрена GO-часть нового сервиса подписания для всем известного (а если не всем, то многим) портала Госуслуг. Сюда входит конфигурирование, тестирование, ресты, файловый менеджер и планировщик. В общем все то, что происходит до того, как данные будут переданы в C-часть для подписания и верификации. Я также кратко опишу основные предпосылки к созданию нового сервиса.
Дисклеймер!
Автор этой статьи не писатель, а разработчик, который пытается в первый раз интересно описать достаточно сложный проект.
Во второй части будут рассмотрены CGO-прослойка и C-часть, в которой происходит подписание и верификация данных. Там же будут описаны самые важные оптимизации, ради которых этот сервис и создавался.
Upd: вышла вторая часть статьи
Для сохранения времени читателей примеры кода в этой статье по возможности упрощены. Там, где это не мешает читаемости, полностью удалена инициализация переменных, переиспользование буферов, обработка ошибок и освобождение памяти.
А чтобы еще сильнее упростить дальнейшее чтение, я сделал схему, в которой есть все элементы обеих частей статьи. Те элементы, которые будут рассмотрены в этой статье, выделены красным.
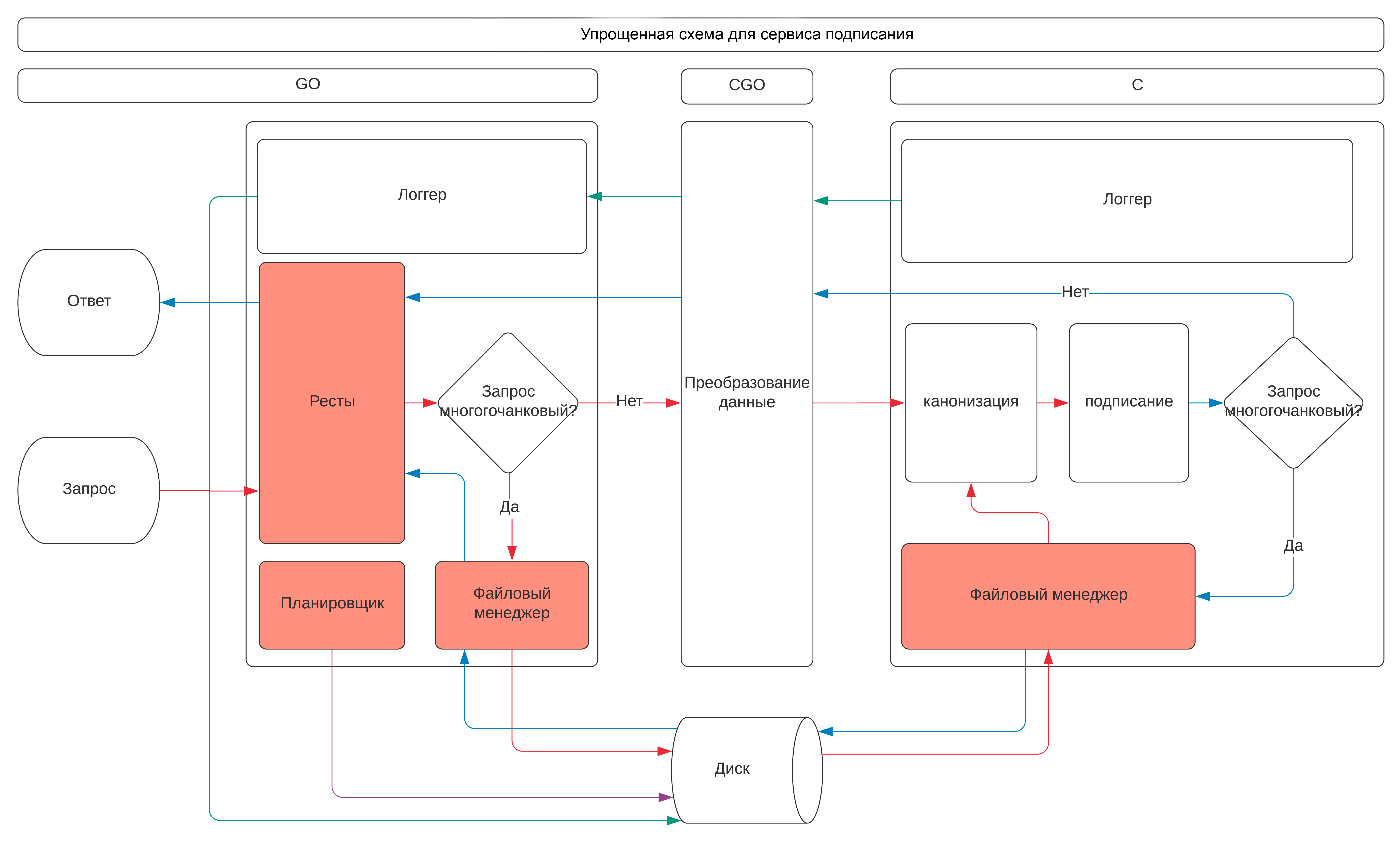
Немного о терминах
Перед тем как начать, думаю, надо дать краткое описание некоторых терминов:
Единый портал государственных и муниципальных услуг (функций) (ЕПГУ, далее по тексту просто Госуслуги). Это портал, где у каждого гражданина есть возможность:
узнать информацию о государственных и муниципальных услугах;
заказать госуслуги в электронной форме;
записаться на приём в ведомство;
оплатить любым электронным способом штрафы Госавтоинспекции, судебные и налоговые задолженности, госпошлины, услуги ЖКХ;
оценить качество предоставления госуслуг.
Единая система межведомственного электронного взаимодействия (СМЭВ) — информационная система, которая позволяет федеральным, региональным и местным органам власти, кредитным организациям (банкам), внебюджетным фондам и прочим участникам СМЭВ обмениваться данными, необходимыми для оказания государственных услуг гражданам и организациям в электронном виде, а также для реализации других своих функций
Существует 2 версии СМЭВ — это СМЭВ2 и СМЭВ3, они отличаются методическими рекомендациями и разным набором возможностей, но для этой статьи понимание этих отличий не обязательно.
Мотивы и предпосылки
Новый сервис подписания изначально задумывался как более производительная версия аналогичного сервиса для СМЭВ. Но в ходе работ он перерос в универсальный сервис, работающий практически со всеми стандартами, которые используются в инфраструктуре Госуслуг. Например, сейчас новый сервис можно использовать для:
Создания и верификации простых подписей
Подписания и верификации запросов для СМЭВ2 по стандарту WS-Security + XMLDSig
Подписания и верификации запросов для СМЭВ3 по стандарту XMLDSig
Подписания и верификации файлов по стандартам CMS и CAdES-BES
Подписания и верификации OAuth токенов для единой системы идентификации и аутентификации по стандартам CMS и CAdES-BES
Подписания и верификации JWT
При этом поддерживаются ГОСТ-2012 как для 256, так и 512-битных ключей.
Это дало возможно использовать КриптоПро только в экземплярах нового сервиса подписания, которыми могут одновременно пользоваться несколько систем. Что, в свою очередь, позволило экономить много ресурсов на закупках лицензий. Но, самое главное, это позволило сделать процесс работы с подписанием одинаковым во всех системах.
Помимо всего вышесказанного, этот проект одновременно и эксперимент по использованию GO в связке с C для проектов, которые должны работать очень быстро, но при этом иметь некритичные по производительности места, в которых можно использовать более высокоуровневый язык. Поскольку до работы над сервисом мы с GO не сталкивались, некоторые решения могут быть не оптимальными. Тем не менее, итоговый результат более чем удовлетворительный.
Финальный объем проекта сравнительно небольшой, приблизительно 28000 строк кода. Это особенно удивительно с учетом того, что у нас всего 4 внешних зависимости (libxml2 и КриптоПро, github.com/google/uuid, ithub.com/spf13/viper), что обязало нас взять на себя очень много работы с криптографическими стандартами.
GO-часть
Теперь предлагаю перейти к самому сервису подписания на C и GO. Чтобы повествование шло более логично, я начну описывать все с самого верха, начиная с конфигурационного файла. А затем буду спускаться все ниже и ниже, чтобы ближе к концу описание самых низкоуровневых операций и оптимизаций, которые как раз и позволяют сервису работать очень быстро, не осталось без контекста.
Конфигурационный файл
Конфигурационный файл у сервиса один, вследствие чего он получился достаточно большим, более 200 строчек.
И большую его часть занимает настройка тестов, потому что практически сразу стало очевидно, что без хорошо продуманных тестов разработка может сильно затянуться. Настроить в тестах можно практически все, начиная от количества потоков и списка ключей, с которыми будет проводится тестирование. И заканчивая очень подробным описанием параметров и файлов, с которыми будут запускаться сами тесты.
Такое внимание к тестам было важно потому, что GO для меня был новым языком, и предугадать все неправильные решения заранее было практически невозможно. А хорошие тесты позволили не бояться на ходу переписывать конкретные модули или даже всю архитектуру проекта целиком, что я и делал неоднократно.
Именно благодаря этому итоговый объем проекта 28000 строк, а не 60000 - 100000, что вполне естественно для проектов без четкой постановки и изменением планов в ходе разработки. Это также позволило создать легко расширяемую, универсальную архитектуру, благодаря которой добавление новых возможностей сейчас может занимать 1– 2 дня, а не несколько недель.
Помимо тестов в конфигурационном файле можно настроить и другие базовые вещи, например, контейнеры, с которыми будет происходить подписание, логер, планировщик и значения по умолчанию для некоторых параметров в запросах.
На последнем я предлагаю задержаться и постараюсь объяснить, почему параметры в запросах это не просто необоснованное раздувание конфигурационного файла, а то, что может сильно упростить взаимодействие с сервисом.
Самое очевидное, это то, что для базовых случаев, которых будет подавляющее большинство, эти параметры позволяют не перегружать запросы лишней информацией, или даже вообще отказаться от всех параметров, что при работе с небольшими файлами может экономить 5–10% трафика.
И, самое главное, каждый экземпляр сервиса в зависимости от среды и задач можно настроить оптимальным образом, что может в итоге дать существенный выигрыш в производительности.
Отдельно еще можно выделить настройку, которая ограничивает максимальный размер запроса, обрабатываемого без использования временных файлов, но лучше не забегать вперед, дальше я про нее обязательно вспомню.
Как следствие того, что конфигурационный файл получился очень большим и того, что его можно менять прямо во время работы сервиса, возникла необходимость контролировать целостность и базовые правила его заполнения. Для этого при каждом запуске сервиса или при каждом получении сигнала SIGHUP вызывается метод, который валидирует данные и пишет ошибки в случае необходимости.
Тестирование
В первую очередь для сервиса были написаны стандартные GO-тесты. В них нет ничего особенного, поэтому останавливаться на этом мы не будем.
Но одними стандартными тестами все не обошлось. По ходу развития сервиса появилась необходимость еще и в тестах, которые позволили бы проверять стабильности сервиса при больших нагрузках. А поскольку стандартные средства GO не позволяли сделать все необходимое, для этих целей был выбран JMeter. Впоследствии JMeter так же оказался очень удобным для профилирования C-части в связке с pprof.
Но, как вы уже, наверное, поняли, поддержка двух больших, независимых наборов тестов в условиях постоянно дорабатывающейся архитектуры занятие очень трудозатратное. Для решения этой проблемы были сделаны универсальные наборы данных для обычных и нагрузочных тестов. А нагрузочные тесы были по возможности сделаны максимально похожими на интеграционные тесты, что затем позволило тратить заметно меньше времени на доработки.
Также в проекте используются линтеры из golangci-lint, которые позволяют лучше следить за качеством кода. Впрочем, на них можно подробно не останавливаться, на Хабре про линтеры много отдельных статей.
Ресты
Теперь наконец то можно перейти к тому, что эти самые тесты и тестируют, к рестам, которых на текущий момент в сервисе 17.
Один из них health-check, который возвращает основную информацию о текущем экземпляре сервиса. И еще 8 групп по 2 реста, которые отвечают за подпись и верификацию по конкретному стандарту. Сам список поддерживаемых стандартов есть в начале статьи.
Изначально была идея осветить каждый их них, но в процессе написания статьи стало понятно, что в этом нет смысла. В основном потому, что одной из главных целей при проектировании этого сервиса была однообразность везде, где это не вредит качеству и очевидности кода. Даже переменные, настройки в конфиге, параметры в методах и самих рестах, отвечающие за одно и тоже, называются одинаково. Благодаря однообразности можно приблизительно понять, как работают все ресты, просто рассмотрев самые большие и сложные из них – ресты для подписания запросов в СМЭВ2 и СМЭВ3. Далее по тексту все примеры будут приводиться в контексте именно этих рестов.
Файловый менеджер
Ключевое отличие всех сервисов подписания в разных системах было в том, что они не были приспособлены для подписи очень больших файлов. Один такой файл мог запросто положить весь сервис.
В новом сервисе мы постарались к ним подготовиться. Для этого все файлы были разделены на 2 категории:
Очень большие файлы, которые должны приходить по чанкам и до момента, пока не придут все чанки, храниться на диске. После подписания таких файлов возвращаемый результат тоже может быть разбит на чанки по желанию клиента.
Небольшие файлы, максимальный размер которых определяется в конфигурационном файле. Они должны быть проброшены в C-часть без копирования и подписаны сразу. Это позволяет таким запросам подписываться практически мгновенно, и при этом существенно не нагружать память.
После разделения файлов на 2 категории тут же возникла другая проблема. Как передавать большие объемы данных между двумя языками?
Вот тут и возникла необходимость в файловом менеджере, который будет работать как в C, так и в GO-частях. Вообще, при проектировании файлового менеджера главная идея была в том, чтобы код в C и в GO-частях не заботился о том, где и как хранятся файлы. А мог просто по uuid из запроса получить требуемые ему данные. Например, подписанный файл или конкретный чанк неподписанного файла. При этом все это должно было работать одинаково на обеих сторонах сервиса.
Для этого файловый менеджер пришлось разделять на 2 части. Первая часть находится на стороне GO. Она умеет делать все необходимые операции, например, записывать или удалять файлы и чанки, собирать из чанков итоговый файл для отправки и т.д. Синхронизация между С и GO-частями также происходит на стороне GO, за счет возможности блокировать директорию по uuid перед вызовом C-кода.
Вторая часть находится на стороне C. Она намного скромнее по возможностям – умеет всего лишь читать определенные чанки и разбивать на чанки итоговый подписанный xml, но именно благодаря этой части удается экономить очень много памяти при работе с большими файлами.
Например, при чтении больших файлов по чанкам самым очевидным было бы сначала вычитать все в память, а потом уже по этим данным построить DOM. Но вместо этого libxml2 позволяет почанково передавать парсеру все необходимые данные, тем самым существенно экономя максимально потребляемый одним запросом объем памяти
Вот так, например, выглядит метод для парсинга многочанкового документа:
В примере вызовом xmlCreatePushParserCtxt создается контекст парсера, а для добавления в него чанков вызывается xmlParseChunk.
//Парсинг всех доступных чанков
for(int i = 1; i <= numberOfChunks; i++)
{
//Чтение данных из файла в буфер
result = fread(data, sizeof(char), fileSize, pFile);
if (result != fileSize)
{
res = GENERAL_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "fread failed");
goto err;
}
if(1 == i)
{
//Инициализация парсера
ctxt = xmlCreatePushParserCtxt(NULL, NULL, chars, sizeof(chars), filePath);
if (NULL == ctxt) {
res = XML_PARSE_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlCreatePushParserCtxt failed");
goto err;
}
//Добавление поддержки больших файлов
res = xmlCtxtUseOptions(ctxt, XML_PARSE_HUGE);
if(OK != res)
{
res = XML_PARSE_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlCtxtUseOptions failed");
goto err;
}
//Парсинг первого чанка
res = xmlParseChunk(ctxt, data + sizeof(chars), fileSize - sizeof(chars), 0);
if(OK != res)
{
res = XML_PARSE_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed");
goto err;
}
if (1 != ctxt->wellFormed || 0 != ctxt->errNo)
{
res = XML_PARSE_ERROR;
formatErrorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed, wellFormed: %d, err: %d", ctxt->wellFormed, ctxt->errNo);
goto err;
}
}
else if(numberOfChunks == i)
{
//Парсинг последнего чанка
res = xmlParseChunk(ctxt, data, fileSize, 1);
if(OK != res)
{
res = XML_PARSE_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed");
goto err;
}
if (1 != ctxt->wellFormed || 0 != ctxt->errNo)
{
res = XML_PARSE_ERROR;
formatErrorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed, wellFormed: %d, err: %d", ctxt->wellFormed, ctxt->errNo);
goto err;
}
//Возвращение ссылки на распаршеный документ
*doc = ctxt->myDoc;
}
else
{
//Парсинг промежуточных чанков
res = xmlParseChunk(ctxt, data, fileSize, 0);
if(OK != res)
{
res = XML_PARSE_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed");
goto err;
}
if (1 != ctxt->wellFormed || 0 != ctxt->errNo)
{
res = XML_PARSE_ERROR;
formatErrorLog(uuid, LOGGER_FILE_INFO, "xmlParseChunk failed, wellFormed: %d, err: %d", ctxt->wellFormed, ctxt->errNo);
goto err;
}
}
}
При этом во время дампа подписанного xml-файла также удается существенно экономить размер одновременно занимаемой памяти благодаря тому, что в libxml2 есть возможность в метод дампа xml передать собственный буфер, для которого будут определены callback-и в которые будут передаваться данные небольшими порциями. Как только этих данных станет достаточно для записи в чанк, размер которого определил клиент, то они будут записаны на диск, а буфер переиспользован.
Ниже пример метода для дампа xml в несколько чанков.
В примере из метода dumpXmlDocAndSplitIntoChunks вызывается метод xmlOutputBufferCreateIO, позволяющий создать буфер, при заполнении которого будут вызываться переданные нами callback-и dumpToFileWriteCallback и dumpToFileCloseCallback. В которые первым параметром будет приходить переданный нами контекст callbackData. Для простоты пример с dumpToFileCloseCallback и writeToFile я приводить не стал.
Впоследствии этот буфер передается в метод xmlNodeDumpOutput, который и будет заниматься дампом.
static error_code dumpXmlDocAndSplitIntoChunks(const char *uuid, xmlDocPtr *doc, const char *tempDirPath, int *signedXmlLen, const char *chunkType, const int chunkSizeInByte, int *numberOfChunks)
{
xmlNodePtr rootNode = NULL;
xmlOutputBufferPtr buf = NULL;
dumpToFileWriteCallbackTempData callbackTempData = {0};
dumpToFileWriteCallbackData callbackData = {uuid, tempDirPath, chunkType, chunkSizeInByte, numberOfChunks, signedXmlLen, &callbackTempData};
int bufRes = 0;
error_code res = OK;
debugLog(uuid, LOGGER_FILE_INFO, "started");
if(NULL == doc || NULL == tempDirPath || NULL == signedXmlLen || NULL == chunkType || 0 == chunkSizeInByte || 0 == numberOfChunks)
{
res = BAD_INPUT;
errorLog(uuid, LOGGER_FILE_INFO, "bad input");
goto err;
}
rootNode = xmlDocGetRootElement(*doc);
if(NULL == rootNode)
{
res = GENERAL_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlDocGetRootElement failed");
goto err;
}
buf = xmlOutputBufferCreateIO(dumpToFileWriteCallback, dumpToFileCloseCallback, &callbackData, NULL);
if(NULL == buf)
{
res = GENERAL_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlOutputBufferCreateIO failed");
goto err;
}
xmlNodeDumpOutput(buf, *doc, rootNode, 0, 0, NULL);
bufRes = xmlOutputBufferFlush(buf);
if(0 > bufRes)
{
res = GENERAL_ERROR;
errorLog(uuid, LOGGER_FILE_INFO, "xmlOutputBufferFlush failed");
goto err;
};
err:
if(NULL != buf)
xmlOutputBufferClose(buf);
return res;
}Пример определения структур dumpToFileWriteCallbackTempData и dumpToFileWriteCallbackData:
typedef struct
{
char *tempBuf;
int tempBufLen;
int tempBufSize;
bool tempBufAllocated;
} dumpToFileWriteCallbackTempData;
typedef struct
{
const char *uuid;
const char *tempDirPath;
const char *chunkType;
const int chunkSizeInByte;
int *numberOfChunks;
int *signedXmlLen;
dumpToFileWriteCallbackTempData *tempData;
} dumpToFileWriteCallbackData;Пример dumpToFileWriteCallback:
static int dumpToFileWriteCallback(void *context, const char *buffer, int len)
{
dumpToFileWriteCallbackData *callbackData = (dumpToFileWriteCallbackData*) context;
dumpToFileWriteCallbackTempData *tempData = (dumpToFileWriteCallbackTempData*) callbackData->tempData;
int internalLen = 0;
error_code res = OK;
//Вызывается при флуше
if(len <= 0 && tempData->tempBufSize != 0)
{
//Запись данных в файл
res = writeToFile(callbackData->uuid, callbackData->tempDirPath, callbackData->chunkType, *callbackData->numberOfChunks + 1, tempData->tempBuf, tempData->tempBufSize);
if(OK != res)
{
errorLog(callbackData->uuid, LOGGER_FILE_INFO, "writeToFile failed");
return -1;
}
*callbackData->numberOfChunks += 1;
*callbackData->signedXmlLen += tempData->tempBufSize;
tempData->tempBufSize = 0;
return len;
}
if(len <= 0)
return len;
if(!tempData->tempBufAllocated)
{
tempData->tempBuf = (char*) malloc(callbackData->chunkSizeInByte);
if(NULL == tempData->tempBuf)
{
errorLog(callbackData->uuid, LOGGER_FILE_INFO, "malloc failed");
return -1;
}
tempData->tempBufLen = callbackData->chunkSizeInByte;
tempData->tempBufSize = 0;
tempData->tempBufAllocated = true;
*callbackData->numberOfChunks = 0;
*callbackData->signedXmlLen = 0;
}
internalLen = len;
while(0 != internalLen)
{
if(internalLen == tempData->tempBufLen)
{
//Запись данных в файл
res = writeToFile(callbackData->uuid, callbackData->tempDirPath, callbackData->chunkType, *callbackData->numberOfChunks + 1, buffer, len);
if(OK != res)
{
errorLog(callbackData->uuid, LOGGER_FILE_INFO, "writeToFile failed");
return -1;
}
internalLen -= len;
*callbackData->numberOfChunks += 1;
*callbackData->signedXmlLen += len;
break;
}
if(tempData->tempBufSize == tempData->tempBufLen)
{
//Запись данных в файл
res = writeToFile(callbackData->uuid, callbackData->tempDirPath, callbackData->chunkType, *callbackData->numberOfChunks + 1, tempData->tempBuf, tempData->tempBufSize);
if(OK != res)
{
errorLog(callbackData->uuid, LOGGER_FILE_INFO, "writeToFile failed");
return -1;
}
*callbackData->numberOfChunks += 1;
*callbackData->signedXmlLen += tempData->tempBufSize;
tempData->tempBufSize = 0;
}
int freeSpaceInBuf = tempData->tempBufLen - tempData->tempBufSize;
if( internalLen < freeSpaceInBuf )
{
memcpy(tempData->tempBuf + tempData->tempBufSize, buffer, internalLen);
tempData->tempBufSize +=internalLen;
internalLen = 0;
break;
}
else if( internalLen > freeSpaceInBuf )
{
memcpy(tempData->tempBuf + tempData->tempBufSize, buffer, freeSpaceInBuf);
tempData->tempBufSize +=freeSpaceInBuf;
buffer += freeSpaceInBuf;
internalLen -= freeSpaceInBuf;
continue;
}
}
return len;
}Самое главное, что позволяет этим двум частям обходится без передачи какой-либо информации, кроме uuid и количества чанков — это универсальные имена для файлов.
Например, когда первый чанк файла приходит на подписание, то он будет называться unsignedXmlChunk_1 (если файл передавался без разбиения на чанки, то он будет файлом, состоящим из одного чанка) и будет лежать в директории, имя которой — это uuid из запроса. Соответственно, когда из GO части вызывается метод для подписания запроса, в который предается количество чанков и uuid, то C-часть точно может сказать файловому менеджеру какие файлы ей нужны для подписания. Когда итоговый подписанный файл нужно записать на диск, он будет сохраняться в ту же директорию, но уже с именем signedXmlChunk_1. И GO-часть при отсутствии ошибок будет пытаться вернуть именно этот файл в качестве ответа.
Вот так, например, выглядит метод для добавления чанков для файлов разных типов:
func AddSignedXmlChunk(uuid string, tempDirPath string, chunkName string, content io.Reader, lockDir bool) (err error) {
return addChunk(uuid, tempDirPath, "signedXmlChunk_"+chunkName, content, lockDir)
}
func AddUnsignedXmlChunk(uuid string, tempDirPath string, chunkName string, content io.Reader, lockDir bool) (err error) {
return addChunk(uuid, tempDirPath, "unsignedXmlChunk_"+chunkName, content, lockDir)
}
func addChunk(uuid string, tempDirPath string, chunkName string, content io.Reader, lockDir bool) (err error) {
file, err := os.OpenFile(filepath.Join(tempDirPath, chunkName), os.O_WRONLY|os.O_CREATE|os.O_EXCL, 0644)
if err != nil {
logger.Error.Println(uuid, err)
return err
}
defer func() {
defErr := file.Close()
if defErr != nil {
logger.Error.Println(uuid, defErr)
err = defErr
}
}()
n, err := io.Copy(file, content)
if err != nil {
logger.Error.Println(uuid, "Copy error", err, ", bytes written", n)
return err
}
return err
}При удалении уже не использующихся файлов из временных директорий каждый тип файлов удаляется отдельными вызовами, как только это становится возможно. А сама временная директория удаляется только если в ней не осталось больше файлов. Если в результате какой-то ошибки из директории не были удалены все файлы, то вернется ошибка, которая позволит на очень ранних стадиях понять, что есть какие-то проблемы. Самое главное, что директория со всеми файлами после ошибки останется нетронутой, что существенно упростит анализ этой проблемы в будущем.
А чтобы файлы слишком долго не занимали место на диске, например, в случае проблем у клиента, из-за которых он не смог прислать все чанки, возникла необходимость в планировщике, который мог бы находить такие файлы и вовремя их удалять.
Благодаря стандартному подходу к работе с директориями, блокировкам и неймингу файлов, такой планировщик оказалось сделать не так уж сложно. Ему достаточно зайти в стандартную директорию по аналогии с файловым менеджером и удалить все устаревшие файлы.
Заключение
Несмотря на то, что эта часть статьи получилась достаточно объемной, это только предисловие ко второй части статьи, которая уже вышла.
А пока буду рад обсудить все вышесказанное в комментариях.


uvelichitel
Vadim3785 Автор
Мы использовали yaml, в первую очередь потому что он уже до этого много в каких проектах использовался