
Хоть мы тогда и сами об этом не знали, но создавать сервис для аренды выделенных серверов мы начали два года назад. При запуске новых регионов публичного облака нам требовалось оперативно развернуть множество серверов разных конфигураций по всему миру, но целыми днями заниматься этим вручную никто не хотел. Вместо людей со стальными нервами мы нашли более изящное решение в лице Ironic — сервиса OpenStack для провижининга «голого железа». Совместно с другими инструментами он позволял и раскатывать образ, и настраивать систему, и на тот момент этого уже было достаточно. Позже в Ironic появились такие возможности, что это решение начало закрывать вообще все наши задачи по управлению инфраструктурой в облаке. А раз уж мы справились с этим, то почему бы не сделать на основе служебного инструмента публичный сервис с автоматической подготовкой выделенных серверов? О том, что из этого вышло — под катом.

Шёл 2014 год…
Серверы мы деплоили на коленке через PXE boot и kickstart. Это решение хоть и работало, но имело недостатки:
Сети переключались вручную;
Выбор сервера и его перевод в загрузку по PXE выполнялся вручную;
Сборка рейда и обновление прошивок — тоже manual mode.
Сначала для решения проблемы мы хотели просто написать свой bash-скрипт, который и будет всё делать. К счастью, руки до этого так и не дошли, и мы рассмотрели все существующие на тот момент варианты:
MaaS — предлагался как коробочное решение от одной очень солидной компании за не менее солидную сумму;
Cobbler — тут нам сказать особо нечего, так как в команде не нашлось инженеров с необходимым знанием технологии;
Foreman — казался неплохим решением, тем более что мы использовали Puppet;
OpenStack Ironic — хоть инженеров с опытом по этому продукту в команде тогда и не нашлось, но у нас уже был опыт работы с Openstack по виртуализации. Так что ставка была сделана на то, что в будущем мы сможем красиво всё собрать в один OpenStack. Понятное дело, в этом мы глубоко заблуждались, но об этом позже.
В итоге автоматизировать деплой серверов мы решили с помощью Ironic, а эти работы в дальнейшем положили начало куда более масштабному проекту. Рассказываем, как так вышло.
Шаг 1: автоматизируем управление внутренней инфраструктурой облака
Наши решения работают на основе разных технологий Intel: облачные сервисы — на процессорах Intel Xeon Gold 6152, 6252 и 5220, кеш-серверы CDN — на Intel Xeon Platinum, а в апреле 2021 мы также одними из первых в мире начали интеграцию Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих облачных сервисов. Чтобы вручную управлять всем этим пулом железа для сервисных целей облака, ежедневно разворачивать по всему миру серверы с разными конфигурациями и всё это ещё и как-то поддерживать, нам требовался либо целый штат специалистов, либо инструменты автоматизации, которые бы обеспечили высокий темп экспансии в регионы и облегчили жизнь нашим админам. Как уже говорилось, для этих целей мы решили использовать Ironic. На момент внедрения — два года назад — это был уже достаточно зрелый сервис со следующими возможностями:
Удалённое управление серверами;
Сбор информации о конфигурациях и коммутации ещё не запущенных серверов;
Установка ОС на произвольном сервере;
Настройка сети с использованием протоколов 802.1q и 802.3ad.
Нас такое решение вполне устраивало, поэтому на нём мы и остановились, а для настройки операционной системы на сервере решили использовать cloud-init. Рабочий процесс был простым и прозрачным:
Сначала формировался загрузочный ISO-диск с информацией о настройках сервера, пакетах и сетевых интерфейсах.
На физическом сервере запускался процесс исследования с помощью компонента Ironic Inspect.
Затем этот сервер Ironic загружал с конфигурационным образом.
Начинался процесс автоматической установки CentOS, настраивались сетевые интерфейсы, ставились пакеты.
Подробней весь жизненный цикл можно увидеть на следующей схеме:
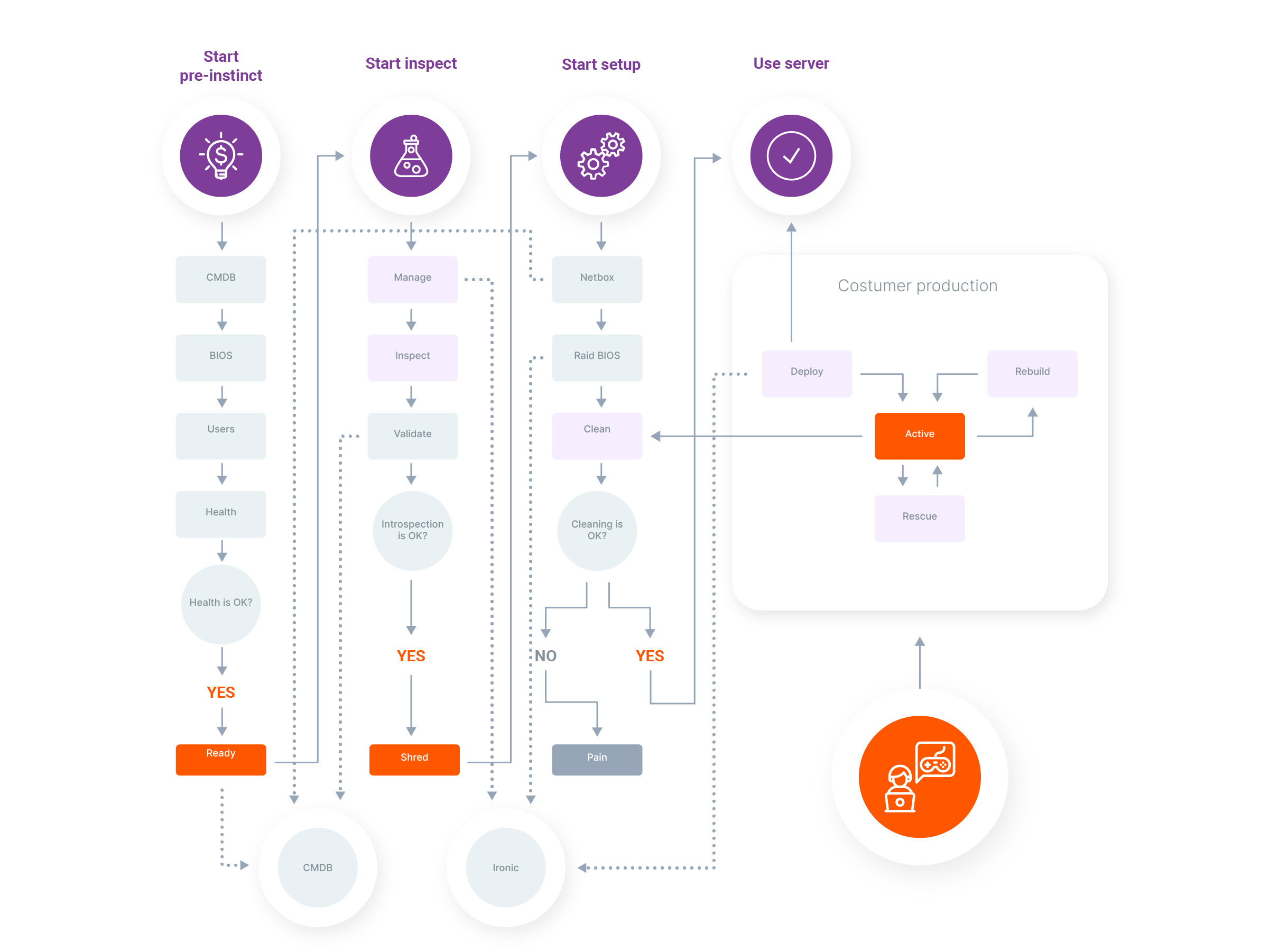
Так всё и продолжалось, пока Ironic становился более зрелым продуктом. Со скрипом, но всё же в нём появились новые возможности, в том числе и всё необходимое для автоматизированного управления RAID-контроллерами, обновления прошивок и развёртывания образов системы с произвольных HTTP-ресурсов через интернет. Так что со временем у нас появилось полноценное решение для автоматизации вообще всех задач по управлению инфраструктурой в облаке — им стала связка Ironic с cloud-init и используемой нами CI/CD. Чем не задел на что-то большее?
Шаг 2: планируем создание новой услуги из андерклауда
Сначала мы использовали инструмент только для служебных целей. Он хорошо справлялся с автоматизацией задач по управлению инфраструктурой облака, но этим наши планы не ограничивались: нам также требовалось подготовить решение для провижининга арендуемых заказчиками выделенных серверов. Оно бы пришлось как нельзя кстати, так как упрощало аренду серверов bare metal для потенциальных клиентов, а сомнений в их наличии у нас не было. На тот момент пользователи и без того часто заказывали у нас выделенные серверы — обычно они разворачивали на них продакшн-среды для высоконагруженных приложений, так как «голое железо» оказывалось производительней и безопасней виртуальных машин, к тому же на нём не было «шумных соседей». Вот только времени на подготовку каждого физического сервера у нас уходило в разы больше, ведь для этого всё требовалось делать вручную:
Сначала выбирать из пула доступных наиболее подходящий сервер;
Затем применять определённую конфигурацию для оборудования (настроить сетевые интерфейсы, RAID-контроллеры);
Постоянно поддерживать в актуальной версии системное ПО (firmware или версию BIOS);
Загружать и устанавливать операционную систему, выполнять пост-инстал скрипты.
Автоматический провижининг избавил бы нас от лишних сложностей. К тому же его потенциал не ограничивался упрощением подготовки серверов: он вполне мог лечь в основу полноценного облачного сервиса, с помощью которого пользователи будут за несколько минут разворачивать узлы bare metal, а арендовать выделенный сервер будет не сложней виртуального. Так из внутреннего компонента мы решили развивать новую услугу для пользователей облака — Bare-Metal-as-a-Service.
Шаг 3: автоматизируем провижининг выделенных серверов в публичном облаке
С помощью автоматизации мы планировали решить несколько задач: ускорить подготовку выделенных серверов, сделать возможной одновременную работу сразу с несколькими из них, сократить простой между операциями и исключить человеческий фактор. Добиться этого нам удалось с помощью общедоступных инструментов и пары собственных доработок. Объяснить, как всё работает, проще всего на конкретном примере — теперь для того, чтобы сервер стал доступен для заказа клиентом, мы выполняем следующие действия:
Заносим сервер в CMDB (сейчас для этого у нас уже есть NetBox).
Через Redfish выполняем преднастройку BIOS — активируем загрузку по PXE и настраиваем её режимы, — а также создаём пользователей для удалённого управления.
Проверяем работоспособность сервера и передаём управление Ironic.
Инженер добавляет сервер в нужную плайсмент-группу.
Убеждаемся, что данные в CMDB и Ironic совпадают — в противном случае на этом этапе требуется ручное вмешательство оператора.
После успешной проверки данных Ironic выполняет настройку RAID и BIOS, а также первоначальную очистку сервера с помощью ATA Secure Erase или shred в зависимости от того, что поддерживает RAID-контроллер.
Вот и всё, сервер попадает в пул доступных для заказа. Решение обеспечивает все наши текущие потребности и реализовано на общедоступных инструментах, так что нам не нужно ежемесячно платить за сторонний продукт и мы ни с кем не связаны лицензионными обязательствами. С поставленными задачами оно справляется на все сто — пользователи с помощью этого решения создают узлы bare metal почти так же быстро, как и виртуальные машины.
Шаг 4: добавляем новую услугу в облачную экосистему
Сейчас пользователи часто используют услугу Bare-Metal-as-a-Service в сочетании с другими нашими сервисами. Это позволяет им быстро получить готовую и гибкую инфраструктуру с простым управлением выделенными серверами и виртуальными машинами, приватными и публичными сетями, а также другими облачными решениями. Заказчикам такой подход помогает эффективно и экономично использовать ресурсы, а мы в результате успешно развиваем собственную экосистему сервисов, так как клиенты пользуются сразу комплексом наших решений. Помимо прочего, это открывает для заказчиков новые сценарии использования публичного облака — например, можно держать продакшн-среды на выделенных серверах, а при всплесках нагрузки за минуту разворачивать дополнительные мощности на виртуальных машинах, которые затем можно легко удалить. Чтобы новая услуга стала такой важной частью нашей экосистемы сервисов, после работ над автоматическим провижинингом нам предстояло решить ещё много задач.
Для начала, чтобы пользоваться новым сервисом было просто, заказ выделенных серверов мы сделали схожим с деплоем виртуальных машин — теперь для этого достаточно выбрать нужные характеристики, подключить публичную, приватную или сразу несколько сетей и через несколько минут получить готовый к работе сервер. Это решение уже прошло испытание боем: когда одному нашему клиенту не хватало виртуальных машин, он в тот же день оформил заказ и без проблем переехал на bare metal. С некоторыми другими задачами всё оказалось не так просто — остановимся на паре из них.
Избавляемся от «шумных соседей»
Главное отличие публичного сервиса от внутреннего компонента — наличие уникальных пользователей. Несмотря на то что все серверы живут в одном пуле, заказчикам как-то нужно обеспечить их изолированность друг от друга. Мы добились этого с помощью механизма мультитенантности. Готовые SDN-решения для этого не подходили, так как из-за них нам потребовалось бы ответвляться от существующей инфраструктуры. Нам также нужно было предусмотреть мультиплатформенность, поскольку наши облака распределены по всему миру и сетевое оборудование может варьироваться от региона к региону. В поисках подходящих решений нам пришлось досконально изучить вопрос, оптимальным вариантом оказался Networking-Ansible ML2 Driver. Правда, без ложки дёгтя в нём не обошлось — драйвер не умел объединять порты в MLAG, чего нам очень хотелось. Тогда мы сами научили его нужным образом агрегировать каналы на наших коммутаторах, но тут же столкнулись с другой проблемой при настройке интерфейсов внутри самого физического сервера.
Мы ожидали от cloud-init, что при выборе пользователем нескольких сетей они будут настроены с помощью сабинтерфейсов, но этого почему-то не происходило. Как оказалось, проблема была в том, что cloud-init недополучает из config-drive информацию о VLAN-ах, если порт настраивается транком. К счастью, на просторах opendev мы нашли патч, который мог бы исправить эту проблему. Сложность была в том, что он ещё находился в разработке, так что тут нам опять пришлось поработать напильником, чтобы самим довести патч до ума.
Теперь всё работает следующим образом:
Сетевые интерфейсы по умолчанию автоматически агрегируются и в транк перебрасываются как публичные, так и приватные сети. Пользователи же могут сконфигурировать свой ландшафт любым удобным образом, объединяя публичные и приватные сети в своём проекте — это позволяет им максимально эффективно использовать ресурсы;
По умолчанию все порты сервера находятся в несуществующей сети, но мы уже знаем в какой коммутатор воткнут каждый из них. Когда пользователь заказывает сервер, портам открывается доступ к PXE-серверам, запускается загрузчик, заливается образ, а дальше порты конфигурируются в целевую схему и сервер отдаётся клиенту.
Получается следующая схема потоков трафика:
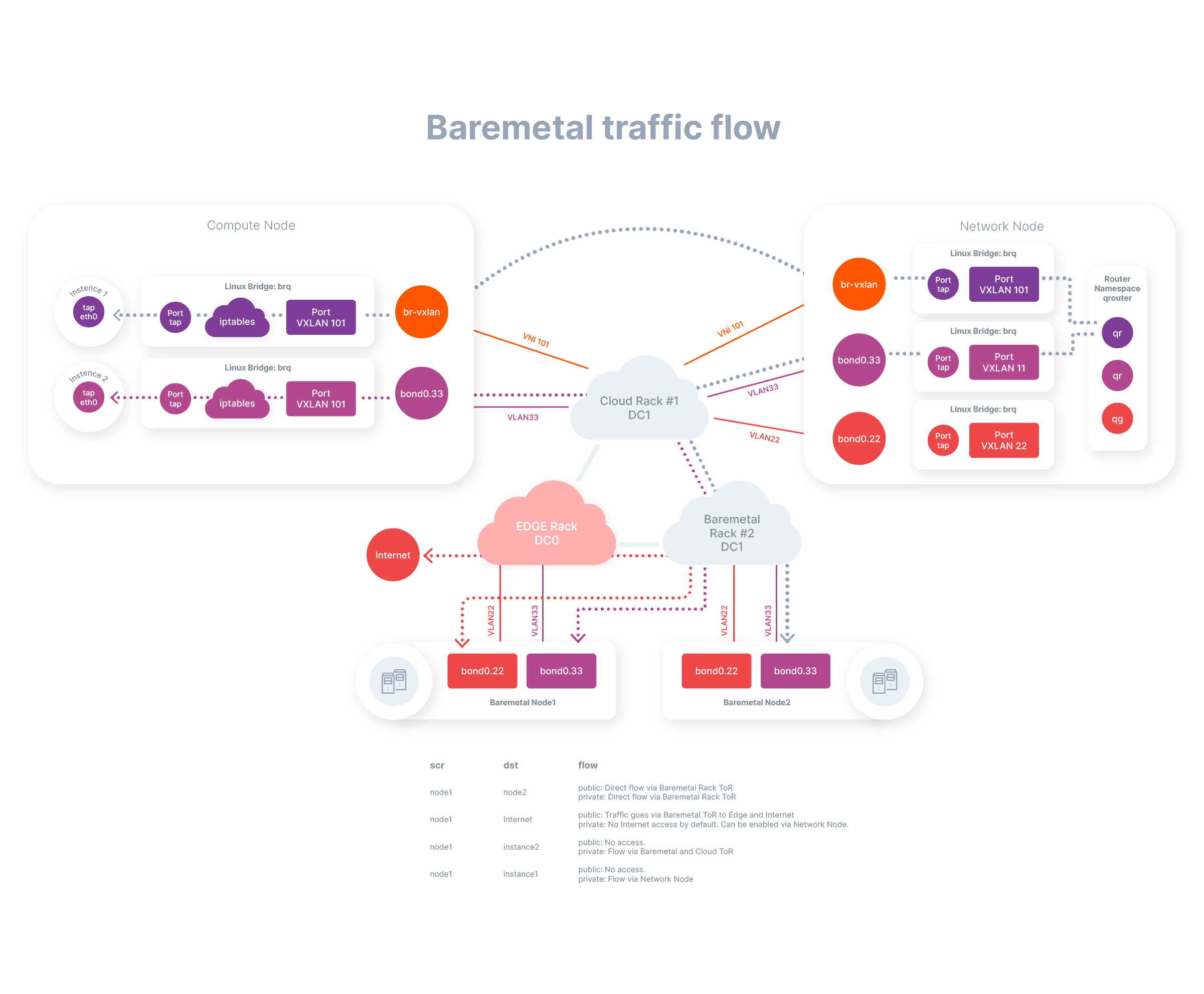
Ну и заодно мы не забываем про VXLAN для bare metal и сейчас ведём разработку решения, позволяющего работать с сетью, используя эту технологию.
Пишем драйвер консоли для iDRAC
Без serial console траблшутинг bare metal был бы неполным, так как для пользователя она остаётся единственным способом подключения к серверу, если привычные варианты — SSH и RDP — вдруг оказываются недоступны. Проблема возникла при имплементации сервиса, когда стало понятно, что в Ironic отсутствует поддержка виртуальной консоли iDRAC. Чтобы всё же получить к ней доступ, нам пришлось самим написать драйвер. Для этого мы изучили имеющиеся драйверы в Ironic для работы с консолями iLo и IPMI, а затем написали собственное решение по схожему принципу. Получившийся драйвер отлично справляется со своими задачами, но только в тех случаях, когда образ пользователя умеет отдавать диагностику в COM-порт — к счастью, в современных версиях Linux и Windows проблем с этим не возникает даже из коробки. Вот только с виртуальной консолью проблемы на этом не кончились.
Следующая сложность возникла с проксированием портов самой консоли. За их работу отвечает компонент Nova — nova-serialproxy — принцип работы которого слегка отличается, но в целом схож с компонентом nova-novncproxy. Проблема обнаружилась на одном из этапов работы serial console, который организован следующим образом:
Пользователь запрашивает serial console в личном кабинете — создаётся запрос посредством REST API.
Компонент nova-api обращается к nova-compute для получения URL с валидным токеном и открытием веб-сокета на подключение.
API нашего личного кабинета получает этот URL и делает по нему обращение уже непосредственно в nova-serialproxy.
Затем происходит проксирование запроса nova-serialproxy к ironic-conductor на порт физического сервера для подключения к его виртуальной консоли.
Вот наглядное описание этой цепочки действий:

Проблема возникала на четвёртом этапе — иногда в этот момент пользователи в течение непродолжительного времени получали ошибку "Address already in use". Мы не сразу поняли, с чем связано такое поведение, так как обнаружить порт консоли занятым каким-то другим процессом в списке прослушиваемых портов нам никак не удавалось. Первым делом мы решили изучить socat, с помощью которого осуществлялось взаимодействие с виртуальной консолью от контроллера. Однако, найти корень проблемы так и не получалось, в том числе из-за того, что на момент обращения пользователей в службу поддержки ошибки уже не возникало. Но однажды нам повезло: в тот раз проблема никак не решилась сама собой и ещё была актуальна, когда клиент о ней сообщил.
Тогда нам удалось обнаружить, что HAproxy на контроллерах проксирует соединение к БД, где ему для инициализации подключения назначался порт консоли. Решение оказалось довольно простым: мы стали резервировать порты с помощью параметра ядра net.ipv4.ip_local_reserved_ports и выбрали диапазон в плоскости 48 тысяч, где конечный порт для консоли в момент подготовки сервера для аренды автоматически указывался в соответствии с последним октетом iDRAC-адреса.
Шаг 5: запускаем bare metal во всех регионах публичного облака
В результате этих работ из служебного компонента нам удалось сделать полноценный сервис в составе публичного облака. Останавливаться на этом мы не планируем и первым делом расширяем географию присутствия облака: теперь, помимо виртуальных машин, во всех новых регионах мы сразу будем предоставлять и выделенные серверы. Развиваться будет и сам сервис: в ближайшие полтора года мы планируем создать решения на базе серверов bare metal для работы с большими данными и CaaS-сервисами, в том числе с Managed Kubernetes, а также внедрить возможность разворачивать приложения из нашего маркетплейса на выделенных серверах. Подробней обо всём этом мы ещё расскажем отдельно — stay tuned.
VG_GC
Наконец-то нормальный материал по деплою bare metal