

Привет, Хабр! Меня зовут Александр Черёмухин, я тимлид администраторов Hadoop в Big Data МТС. Мы прошли довольно длинный эволюционный путь в автоматизации администрирования и хотелось бы им поделиться с сообществом. Возможно наш опыт пригодится и другим специалистам, работающим с Hadoop.
Примечание: об этом решении Саша рассказал на прошедшем митапе администраторов Hadoop, если вам больше нравится формат видео — смотрите его тут. Ну а если вам ближе текст — читайте дальше.
Общая картина
Все это время мы использовали (и используем пока что) дистрибутив HDP (Hortonworks Data Platform). Исторически у нас есть версия 2.6.5, то есть вторая ветка, и все новые установки у нас уже установлены на версии 3.
Есть тут и свои особенности. Например у нас есть кластеры как на baremetal, большие прод-кластера мы все запускаем на «железе» и кластеры в облаке (OpenStack), которые мы используем либо для каких-то тестовых установок.
Как было изначально
Когда Big Data МТС только начиналась, кластеры в большей степени устанавливались вручную. Даже несмотря на то, что дистрибутив HDP предоставляет довольно мощные средства администрирования кластеров в виде Ambari.

Если детальнее, то установка кластеров ранее выглядела так: Сначала настраивалось все окружение на нодах в виде Java, PostgreSQL, настраивались хостнеймы и так далее, подкручивались системные настройки. Затем (опять же вручную) настраивался репозиторий (мы используем Artifactory в качестве кэширующих репозиториев), после чего ставились Ambari Server и Ambari Agents.
Ambari состоит из Ambari Server и Ambari Agents, которые ставятся на каждую ноду кластера. Собственно, Ambari Agent и управляет непосредственно нодой и сервисом HDP, который на ней находится.
После всего этого администратор должен был зайти в Ambari Server, выбрать все необходимые компоненты, после чего установить компоненты кластера на ноды.
Либо не установить, потому что не всегда все идет хорошо. Ambari – инструмент, конечно, довольно эффективный, но не все пречеки, которые он осуществляет, покрывают полный спектр всех проверок, которые необходимы на кластере.
Думаю понятно, что такая система была довольно сложной. Из-за человеческого фактора ряд кластеров могли получить некоторую индивидуальность в нехорошем смысле этого слова, что довольно опасно в плане накопления некоторого legacy, отличий между кластерами и всего такого.
Автоматизируй это
Нас эти сложности утомили, и мы решили разработать инструмент для автоматизированной раскатки кластеров. Название нашлось само собой — HDP Install, простое, но зато сразу понятно о чем речь. HDP Install — это программа написанная на Go c использованием Ansible, которая является своеобразным оркестратором и валидатором конфигов, которые мы подаем на вход. Под капотом используются на всех этапах (о которых чуть ниже) ansible-playbook и ansible-roles.
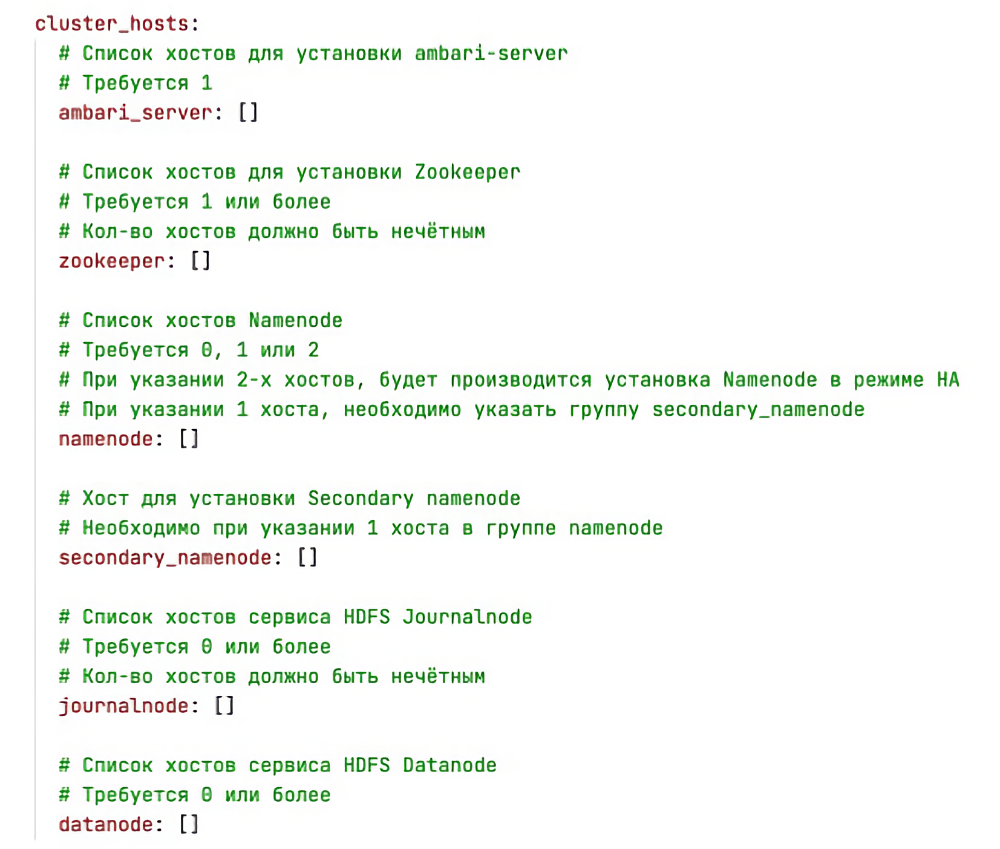
Вся топология кластера и его базовые настройки, которые мы должны и ожидаем получить после этого процесса, описываются в едином конфиге в формате YAML.
В результате полного цикла работы HDP Install мы получаем уже готовый работающий кластер с установленным окружением – JDK, PostgreSQL, настроенные дата-сорсы для Ranger, например, для Hive Metastore, для того же самого Ambari и так далее. Кроме того, готовый кластер уже настроен для нашей инфраструктуры, то есть это произведена интеграция с LDAP, Active Directory и так далее.
Как работает HDP Install
Дальше расскажу сколько этапов работы удалось «упаковать» в наше решение.
Prechecks. На этом этапе происходит проверка конфигурации оси, «железа», доступности репозиториев (например будет обнаружена сетевая связанность). Проверяются маунт-пойнты (например на дата-нодах), правильность прописывания всех хостнеймов, чтобы все было по FQDN и т.д. Если по какой-либо причине пречеки валятся, мы можем потом их перезапустить. А вообще каждый этап работы HDP Install может быть запущен с произвольного шага.
Common. На данном этапе идет установка пререквизитов в виде JDK, подтягивания сертификатов, настройка /etc/hosts и прочие необходимые пререквизиты, которые рекомендуются как Hortonworks (теперь это Cloudera), так и в целом необходимы для функционирования Hadoop как такового.
Data Sources. На этапе настройки дата-сорсов идет установка PostgreSQL, а также прописывание баз данных и схем для Ambari DB, Hive Metastore DB, Ranger DB. ]
Ambari. Здесь мы уже подходим непосредственно к установке кластера, раскатываются Ambari Server на управляющую, менеджмент-ноду и Ambari Agents на все остальные ноды кластера. После чего посредством использования Ambari API происходит установка наших компонентов, которые были ранее описаны в нашем конфиг-файле YAML.
HDP. Это, наверное, самый длинный этап, в котором происходит раскатка всех компонентов, а также керберизация, если это необходимо (в наших реалиях это всегда необходимо, все наши кластер керберизированы).
Postconf. Заключительный этап, в котором на основании ранее заполненного конфиг-файла прописываются необходимые параметры, базовые хипы для Hive, Name Node, Data Node так далее, интеграция с LDAP и прочие базовые конфиги, которые необходимы для функционирования.
Profit!
В результате мы получаем работающий кластер, у которого (благодаря использованию HDP Install) есть следующие плюсы:
Переиспользуемость. Уже успешную, зарекомендовавшую себя конфигурацию мы можем использовать повторно, раскатав, либо на новом «железе» (по требованию), либо в OpenStack. Тут же мы получаем и возможность автоматизации подъема кластеров в облаке.
Повторяемость конфигурации. Мы можем хранить ее, например, в Git и отдавать продуктам Big Data для какого-то использования. Опять-таки, любой продукт Big Data может взять HDP Install, и воспользоваться им для раскатки своего какого-нибудь тестового или dev-кластера.
Минимизация ручного труда и человеческого фактора. Для нас это пожалуй самый большой плюс, ведь с HDP Install сложнее ошибиться.
После того, как мы получили работающий кластер, казалось бы, все хорошо, можно остановиться. Когда мы раскатываем dev или тестовый кластер, то как правило, этого достаточно. Но в случае с продом нам этого мало.
Катим кластер на прод
Для того чтобы этот кластер мы могли поддерживать в проде и как-то гарантировать его консистентность, мониторинг, вокруг него есть довольно обширная инфраструктура, которая видна на схеме ниже.

В эту инфраструктуру входят:
Мониторинг — нас есть целый ряд разработанных нами экспортеров для Prometheus, который мы используем для мониторинга. Также мы используем такие экспортеры, как jmx-exporter, практически на все важные компоненты кластера.
filebeat — для отправки логов ELK.
Разработанные нами системы бэкапов, например, бэкап fsimage.
Ряд пререквизитов в виде, например, Python virtualenvs — для того чтобы наши дата-инженеры, дата-сайентисты могли комфортно работать и выполнять свои задачи.
Кейтабы для Kerberos разложенные по дата-нодам и по эдж-нодам — для того чтобы регламентные задачи могли отрабатывать.
Ряд задач требует другие версии Spark, не только 2.3.2 (которая входит в стек HDP), а еще и Spark 2.4.4, это тоже должно присутствовать рядом с кластером.
Кроме того, нужна вменяемая система конфигурирования настроек именно самого кластера, потому что лезть каждый раз в Ambari для того чтобы руками подтюнить какой-то параметр — это не дело.
Чтобы иметь возможность апгрейдить всю эту систему, мы разработали специальные пайплайны для кластеров.
Что за пайплайны для кластеров?
Пайплайн представляет из себя, Git-репозиторий для каждого кластера (мы используем GitLab), который содержит в себе blueprint.json, в котором находятся параметры этого кластера. Кроме того, есть отдельный репозиторий Common, который содержит в себе единый blueprint универсальных настроек для кластера. Мы стараемся стандартизировать все наши ноды, поэтому такие вещи, как, например, пути на дата-нодах до файлов HDFS, или пути до YARN или до юзер-кэшей - прописаны в Common. Какие-то базовые, не меняющиеся настройки хипов, тоже прописаны там.
Топология кластера описывается в специальном файлике inventory.ini, в котором все ноды типизированы по функционалу — по нейм-нодам, дата-нодам, Kafka-нодам и так далее.
Для того чтобы прокидывать настройки, прописанные в blueprint, до кластера, мы разработали небольшую утилиту и назвали ее ambacfg, (Ambari-конфигурирование), которая валидирует, парсит blueprint, вычленяет из него обновленные настройки и применяет их на кластере через API.
Пайплайны, имеют функционал раскатки необходимого окружения на серверы. Например если где-то забыли установить JDK, то он будет раскатан. Если нам необходима установка какого-нибудь дополнительного virtualenv по требованию дата-инженеров, то мы прописываем это в настройках пайплайна, и этот virtualenv будет раскатан на всех нодах, где его до сих пор не было.
Для всего этого мы используем Jenkins, и Ansible «под капотом». Все хранится в Git, что дает нам очень много бонусов, и flow его выглядит как на картинке ниже. Например, нам захотелось увеличить heapsize Hive-сервера. В любой непонятной ситуации увеличивай heapsize, ага.

Мы делаем новую ветку в Git, вносим в нее изменения, допустим, мы увеличили heap Hive-сервера, после чего создается merge request, кто-нибудь из нашей команды или несколько человек ревьюит этот merge request, и апрувит, если все хорошо, после чего происходит commit master, и пайплайн побежал автоматически.
Этот пример, конечно, очень простой, и показывает собственно работу ambacfg, когда он берет новую настройку из blueprint, вычленяет ее и применяет на кластере. Здесь можно применять не только настройки кластера, но и всего окружения. Предположим, какой-то другой команде Big Datа потребовалось новое Python-окружение — они могут сделать нам merge request с описанием того что им нужно (версия Python, пакеты), мы его ревьюим, если все хорошо то подтверждаем и пайплайн “побежал”.
Или другой пример, предположим у нас появилась новая техучетка, под которой должны бежать какие-то новые регламентные процессы. Команда продукта может в наш корпоративный Vault, который мы используем для всех реденшенов, залить свой keytab-файл, залить нам merge request на раскатку этого keytab-файла, keytab-файл после коммита в мастер — побежит.
Как работает пайплайн
В чем-то этапы работы пайплайна напоминают работу HDP Install, что довольно естественно, потому что некоторые шаги логически его повторяют, но есть и отличия.
Первый этап – тесты. Здесь происходит валидация корректности всех настроек. Если blueprint или конфиг по каким-то причинам сломался — тесты не пройдут.
Configure — применение настроек Common и настроек конкретного кластера. На данном этапе вначале применяются настройки кластера из blueprint репозитория Common, после чего применяются настройки конкретного кластера, который бежит в данный момент.
Prechecs — это проверка окружения именно со стороны операционной системы, доступность репозиториев, корректность хостнеймов, есть ли все маунт-пойнты, и все такое прочее.
Prepare — установка зависимостей, Java, Kerberos, при необходимости накатка каких-то RPM-пакетов и так далее. Это всегда будет раскатано автоматически на всех новых нодах, которые мы добавляем.
Deploy — установка сопутствующего ПО, которое необходимо уже нам. Это Prometheus для мониторинга, filebeat для ELK и HA Proxy для обеспечения high availability некоторых сервисов (например Ranger).
Postconf — конфигурирование этих компонентов. Здесь происходит раскатка конфигов для filebeat, для jmx-экспортеров и так далее.
После чего происходит последний, пользовательский шаг — раскатка необходимых virtualenvs для Python.
После прокатки этого пайплайна, мы можем быть уверены, что необходимые компоненты HDP раскатаны и указаны все необходимые нам конфиги самого Hadoop и HDP, а все дата-ноды, эдж-ноды и остальные ноды кластера приведены в нужное состояние. Версия JDK соответствует, все нужные экспортеры разложены, filebeats разложены с нужной конфигурацией и так далее.
Польза пайплайнов
В первую очередь это хранение в Git истории изменения конфигурации (страховка от ошибок никогда не помешает). У нас появляется такой плюс, как легкий процесс масштабирования, в случае чего мы можем и переиспользовать эти пайплайны на новых кластерах. Получаем мы и гибкость при добавлении новых компонентов в окружение. Расширение кластера происходит достаточно легко, мы просто добавляем, допустим, ряд новых дата-нод в кластер, запускаем пайплайн, на выходе пайплайна нода уже готова для функционирования полностью.
Еще один жирный плюс — возможность быстрого восстановления. Когда кластер большой — бывает что диски с железом летят и нода может выбыть на определенное время, пока в дата-центре будут эту ноду залечивать и обратно втыкать в кластер. После инцидента мы просто запускаем пайплайн и на выходе нода будет в нормальном состоянии.
Тем самым мы поддерживаем консистентность всех настроек кластера и всех его нод. Когда нод уже за сотню или за две сотни, это для нас критически важно, иначе бы мы просто сошли с ума, поддерживая все это руками.
Итоги
Вернемся к тому, с чего мы начинали. Это был небольшой ад в виде ручной настройки кластера, Ambari и отслеживания глазами или какими-то подручными Ansible-плейбуками, версионности всех JDK на всех нодах и все такое прочее.
Но теперь у нас появилось, по сути, как бы два инструмента, логически друг-друга дополняющих. Первый – это HDP Install для автоматизации раскатки кластеров. Он гибкий и позволяет использовать любые комбинации компонентов кластера. И наши пайплайны для того чтобы мы могли автоматизированно конфигурировать как кластер, так и все окружение вокруг него.
Надеюсь, рассказ о нашем опыте будет полезен другим администраторам Hadoop и наведет их на мысли по разработке своих инструментов.
Комментарии (9)

sshikov
30.07.2021 20:17Не нашел описания того, каковы масштабы деятельности. Т.е., сколько примерно самих кластеров, сколько в них обычно узлов, и все такое. Это не помешало бы, чтобы понимать объемы работ.

solarwind Автор
02.08.2021 18:53Самые большие два прод-кластера на железе - ~160-220 нод. Еще несколько поменьше - 10-60 нод. Периодически для разных целей поднимаются и впоследствии умирают (или нет) мелкие кластера по 4-10 нод. В нашем опенстеке таких вообще много, десятки.
sshikov
02.08.2021 21:00Понятно. Ожидаемо вполне солидные размеры. У нас коллеги на похожих масштабах регулярно забывают что-то сконфигурировать, так как помнить, что у вас там на 200 нодах — невозможно, надо либо автоматизировать, либо записывать, но все равно потом автоматизировать :) И даже на 20 нодах — но если у тебя хотя бы 10 таких кластеров, то эффект в общем получается тот же самый, если не хуже.
solarwind Автор
03.08.2021 10:06Точно, все так. Кроме того, без автоматизации спустя годы кластер обрастает таким количеством ручных настроек и обвязок, что и вспомнить все проблематично. Легаси. Поэтому лучше автоматизировать, и чем раньше, тем лучше. :-)
sshikov
03.08.2021 10:28Да, это само собой. Мне как-то приходилось настраивать чуть более простой кластер, три QPID и три Karaf, ну и всякие там HAProxy — так это без автоматизации такая… примерно месяц занимала настройка нового стенда из трех машин. Не чистого времени конечно, а календарно.

chemtech
03.08.2021 07:57Спасибо за пост. Будете ли opensource-ить свои наработки?
solarwind Автор
03.08.2021 09:57+1Желание такое имеется, но пока не очень понятно, имеет ли смысл опенсорсить наработки для умершего дистрибутива хадупа (HDP). Там все-таки есть много именно особенностей, связанных именно с HDP. Да и много интеграции с нашей собственной инфраструктурой. Посмотрим, если сделаем более универсально, то выложим.
loltrol
Ambari уже давно мертво после слияния hortonworks и cloudera. + "приготовить" ambari иногда было в разы сложнее чем вручную разобраться с каждым сервисом и навалять парочку ansible скриптов, особенно с последними релизами ambari. На сколько я знаю, был выбран курс в сторону saas на основе Cloudera Manager, но этот CM еще более тупиковый чем ambari. А потом я там перестал крутиться и не знаю чем закончилось, если кто то расскажет - будет интересно :)
solarwind Автор
Умер не столько Ambari, сколько платформа HDP как таковая. А в CDP всю жизнь был как раз Cloudera Manager, и он для своих целей весьма неплох.