

Выбросы или аномалии – это точки данных, которые отклоняются от нормы набора данных. Порой кажется, что они были получены с помощью какого-то другого механизма.
Обнаружение аномалий – это обычно задача обучения без учителя, цель которой состоит в выявлении подозрительных наблюдений в данных. Ограничение состоит в стоимости неправильного обозначения нормальных точек как аномалий и невозможности найти фактические аномалии.
Областью применения поиска аномалий может быть обнаружение вторжений в сеть, мониторинг качества данных и арбитраж цен на финансовых рынках.
Обнаружение выбросов на основе копул (COPOD) – это новый алгоритм обнаружения аномалий. В Python он реализован в пакете PyOD.
У этого алгоритма есть несколько ключевых функций, которые выделяют его среди конкурирующих алгоритмов:
Он детерминированный;
Не используются гиперпараметры (это важно, поскольку трудно настроить гиперпараметры в задачах обнаружения выбросов, ведь настоящие метрики оказываются редкими, неизвестными или их может быть трудно получить).
Высочайшая производительность при обнаружении аномалий на эталонных наборах данных;
Интерпретируемость и легкость при визуализации аномалий;
Быстрота и точность вычислений;
Масштабируемость до многомерных наборов данных.
Самой большой проблемой COPOD является сложная математика, лежащая в основе алгоритма. В этой статье два раздела:
Краткое изложение ключевых понятий копул и описание алгоритма COPOD;
Руководство по использованию COPOD на Python, рассказывающее, как с помощью этого алгоритма легко обнаружить аномалии в данных.
Модель копул для обнаружения аномалий
Определение копул
Что такое копула?
Если говорить простым языком, то копула описывает структуру зависимости между случайными величинами.
Если же говорить формальным языком то, «копула – это многомерная функция распределения, определённая на n-мерном единичном кубе [1, 0]n, такая, что каждое её маргинальное распределение равномерно на интервале [1, 0]» (Википедия).
Другими словами, вы можете описать распределение вероятностей в многомерном наборе данных, отделив маргинальное распределение для каждой переменной от копулы, которая представляет из себя многомерное распределение вероятностей, описывающее зависимость между переменными.
«Копулы – это функции, которые позволяют нам отделять маргинальные распределения от структуры зависимостей данного многомерного распределения.»
Алгоритм COPOD
Алгоритм COPOD дает несколько математических оценок и делает несколько преобразований для вычисления оценки выбросов для каждой строки.

Шаг 1: Для каждого измерения (столбца) в наборе данных –
Вычислите кумулятивную функцию распределения для левого хвоста
Вычислите кумулятивную функцию распределения для правого хвоста
Вычислите коэффициент асимметрии
Шаг 2: С помощью функций из первого шага, вычислите
Эмпирическую копулу для левого хвоста
Эмпирическую копулу для правого хвоста
Значения эмпирических копул с поправкой на асимметрию для каждой строки
В итоге у вас появляются три новых значения на скалярную величину (строка + столбец) в фрейме данных.
Значения копул могут быть интерпретированы как вероятности для левого и правого хвостов и вероятности с поправкой на асимметрию соответственно.
Шаг 3: Вычислите оценки аномалий для каждой строки вашего набора данных на основе значений, полученных во втором шаге. В этом шаге мы опираемся на то, что наименьшие вероятности хвостов (копулы) приводят к наибольшим значениям отрицательного логарифма.
Для каждой строки
Найдите сумму отрицательных логарифмов эмпирической копулы для левого хвоста
Найдите сумму отрицательных логарифмов эмпирической копулы для правого хвоста
Найдите сумму отрицательных логарифмов эмпирической копулы с поправкой на асимметрию
Оценкой (score) аномалий для строки будет максимальное значение из этих сумм.
Оценка аномалий
Интерпретация: более высокая оценка указывает на низкую вероятность экземпляра данных, поскольку он на находится в хвосте распределения данных.
Показатели выбросов находятся в диапазоне (0, ∞) и напрямую сопоставимы. Они не указывают напрямую на вероятность выбросов. Вместо этого они измеряют «правдоподобность» строки относительно других точек в наборе данных.
Есть два варианта получения более точных прогнозов от COPOD:
Установите пороговое значение для оценки выбросов, тогда любая строка с оценкой, превышающей порог, будет аномалией.
Выберите значения топ-k-ого или топ-k-ого процентиля оценки аномалий.
В PyOD пороговые значения автоматически устанавливаются, основываясь на заданной контаминации (загрязненности данных) или ожидаемой доли аномалий в обучающих данных. Подробнее об этом мы поговорим позже.
Руководство для Python
COPOD реализован в пакете PyOD (https://github.com/yzhao062/pyod) и его очень легко использовать.
Для начала загрузите или сгенерируйте данные для поиска аномалий.

Я использую функцию generate_data из PyOD для создания синтетического набора данных с 200 обучающими сэмплами и 100 тестовыми. Нормальные сэмплы генерируются многомерным распределением Гаусса. Сэмпл выбросов генерируется с помощью равномерного распределения.
В обучающих и тестовых наборах по 5 признаков и по 10% строк аномалий. Я добавлю данным немного шума, чтобы усложнить четкое разделение нормальных точек и выбросов.
Ниже я построил обучающий и тестовый датасеты, проецируемые на два измерения с помощью метода главных компонент.

Обучение и обнаружение
Дальше я обучаю COPOD на обучающих данных и анализирую тестовый набор.

Для запуска методов fit и decision_function потребовалось менее 1 секунды. В PyOD у (обученного) детектора выбросов есть две ключевые функции: decision_function и predict.
decision_functionвозвращает оценку аномалий для каждой строки.predictвозвращает массив из 0 и 1, показывающей является ли каждая из строк нормальной (0) или выбросом (1). Функция прогнозирования просто применяет пороговое значение к оценке аномалий, возвращаемой функциейdecision_function. Пороговое значение автоматически калибруется на основе заданного значения контаминации, установленного при инициализации детектора (например,clf=COPOD(contamination=0.1)).contaminationуказывает на ожидаемый процент выбросов в обучающих данных.
COPOD не нуждается в обучающих данных
В реальной жизни вы, наверное, не размечаете данные на обучающие и тестовые — это нормально! Однако вы все еще можете использовать COPOD для поиска выбросов.
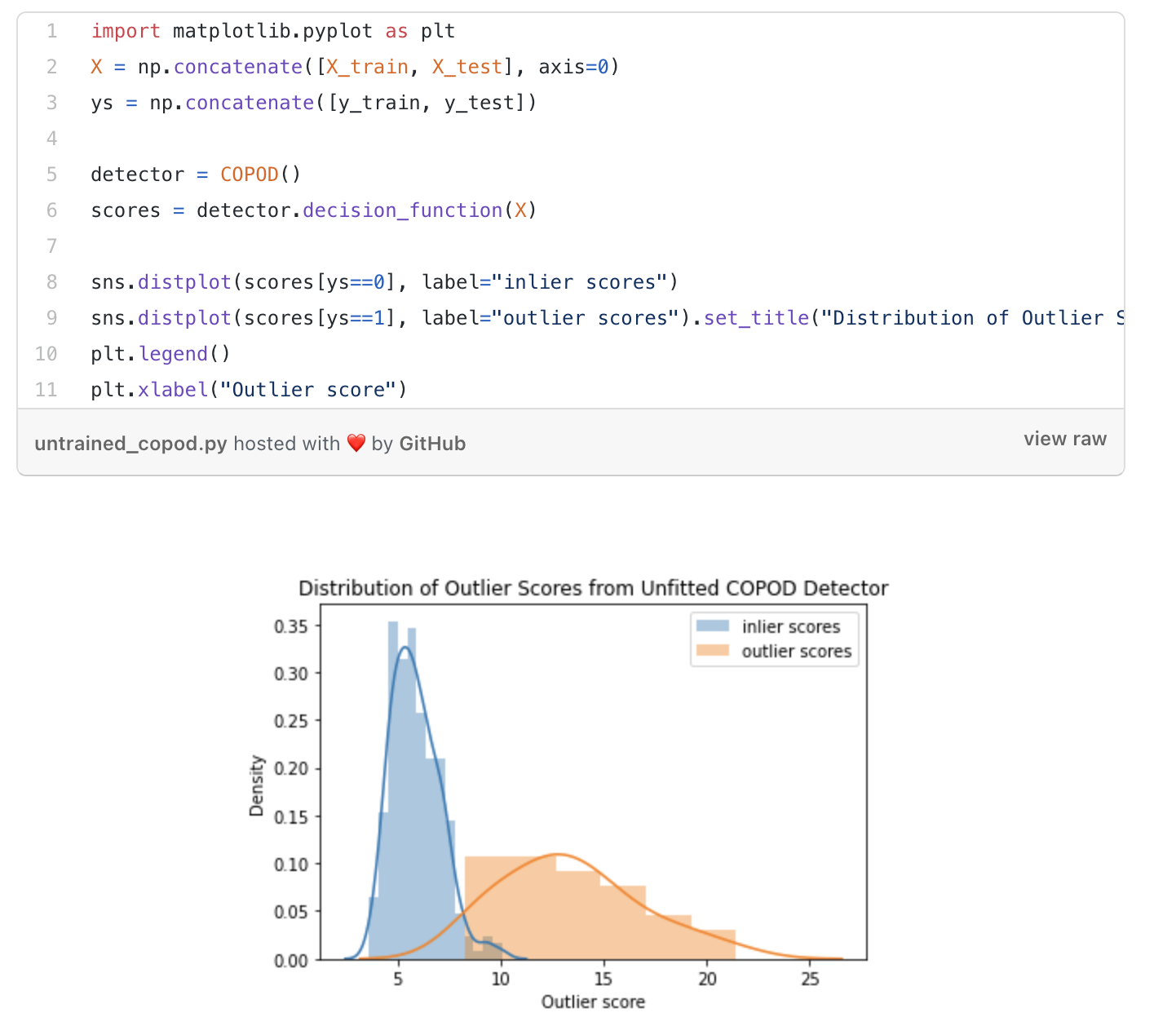
Как видно из примера выше, я инициализировал алгоритм COPOD и просто передал данные через функцию decision_function без обучения. Оценки аномалий для точек выбросов были намного выше, чем для нормальных точек данных.
При работе очень полезно выбрать пороговые значения для оценок аномалий COPOD, чтобы определить, какие данные следует расценивать как аномалии.
Классная функция: Объяснение аномалий
COPOD может объяснить, какие признаки внесли наибольший вклад в оценку выбросов. Это особенно полезно, когда в вашем наборе много признаков или вы хотите рассказать человеку-рецензенту, почему алгоритм выбрал конкретную строку в качестве выброса.
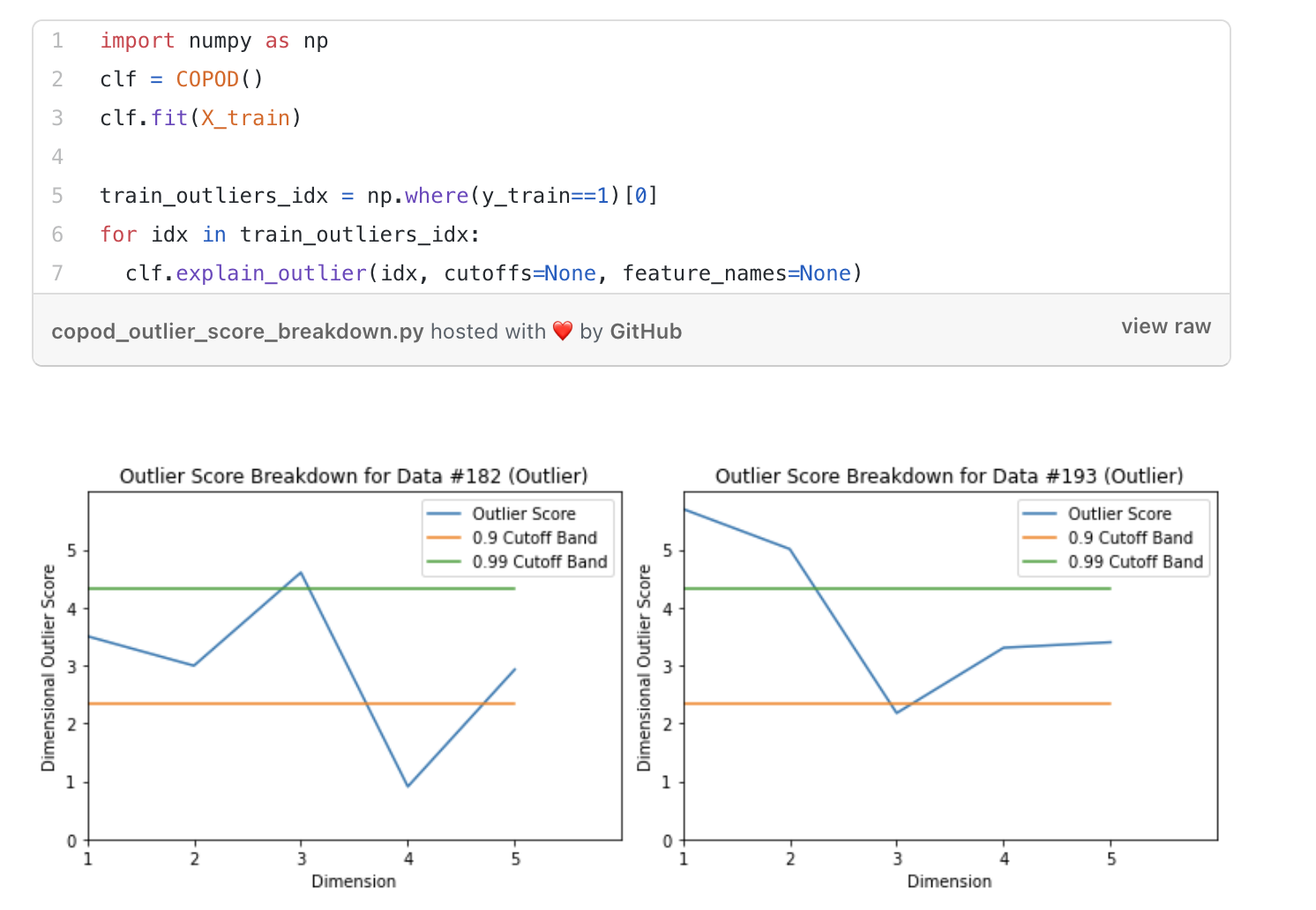
На двух графиках выбросов выше синим цветом показаны оценки выбросов признаков-уровней для двух настоящих аномалий (строк), обнаруженных с помощью COPOD. Ось Х – признаки, а Y – оценка аномалий для этого признака. Также отображаются оценки аномалий в 90-м и 99-м процентилях.
На левом графике (строка № 182) оценка аномалий для измерения 3 превышает 99-й процентиль и являются причиной того, что которой строка является выбросом.
На правом графике (строка № 193) значения выбросов для измерений 1 и 2 превышают 99-й процентиль и являются причиной того, что строка является выбросом.
Спасибо за прочтение!
COPOD – это быстрый, мощный и простой алгоритм обнаружения аномалий. Я надеюсь, что он найдет свое место в вашем инструментарии для обнаружения выбросов.
Чтобы узнать больше о PyOD и выявлении аномалий, ознакомьтесь с этими другими статьями:
https://pub.towardsai.net/why-outlier-detection-is-hard-94386578be6c
https://towardsdatascience.com/pyod-a-unified-python-library-for-anomaly-detection-3608ec1fe321
Источники:
[2009.09463] COPOD: Copula-Based Outlier Detection (arxiv.org) (https://arxiv.org/abs/2009.09463)
pyod/copod_example.py в ветке master · yzhao062/pyod · GitHub (https://github.com/yzhao062/pyod/blob/master/examples/copod_example.py)
Материал подготовлен в рамках курса «Machine Learning. Advanced». Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация здесь.