

Задача
В Uber применяется несколько технологий хранения информации, причем, хранение бизнес-данных зависит от того, какова модель приложения, в которой они применяются. Одна из таких технологий называется Schemaless и обеспечивает моделирование взаимосвязанных записей с представлением в виде одной строки из множества столбцов, а также версионирование для каждого столбца отдельно.
Schemaless в ходу уже пару лет, и там накапливаются данные Uber. Притом, что Uber консолидирует все практические кейсы в Docstore, Schemaless остается источником истины для различных клиентских конвейеров задач, тех, что существуют уже давно. Schemaless как таковая использует быструю (но дорогую) базовую технологию хранения данных, которая позволяет обходиться задержкой порядка нескольких миллисекунд при высоком показателе QPS (запросы в секунду). Кроме того, Schemaless развертывает для каждого региона несколько реплик, чтобы обеспечить сохранность и доступность данных при различных моделях отказов.
Поскольку Schemaless – дорогостоящее хранилище, а данных в нем накапливается все больше, она превратилась в ключевую статью расходов и поэтому требует внимания. Чтобы разобраться в этой ситуации, были проведены замеры, помогающие лучше понять паттерны обращения к данным. Было обнаружено, что в течение некоторого периода времени обращения к данным происходили часто, а после этого – не столь часто. Точная длительность такого периода варьируется от кейса к кейсу, но при любом запросе старые данные все равно должны безусловно предоставляться по запросу.
Требования
Чтобы очертить верное решение такой задачи, мы сформулировали 4 основных требования:
Обратная совместимость
Schemaless в ходу настолько давно, что является неотъемлемой составляющей многих сервисов Uber и даже иерархии сервисов. Следовательно, нам не подходили варианты, которые бы требовали изменить поведение существующих API или ввести новый набор API, поскольку спровоцировали бы целую цепочку изменений во всех сервисах Uber и ухудшили бы эффективность лендинга. Поэтому мы столкнулись с железным требованием сохранить обратную совместимость: у клиентов не должно было возникать необходимости даже минимально менять код, сохраняя при этом максимальную эффективность работы, какую мы в силах достичь.
Задержка
Низкая задержка чрезвычайно важна для своевременного получения данных, поэтому мы поработали вместе с пользовательскими командами, чтобы исследовать различные варианты использования. Исследования показали, что 99-я перцентиль задержки порядка сотен миллисекунд приемлема при работе со старыми данными, тогда как задержка при работе с более новыми данными по-прежнему должна оставаться в пределах пары десятков миллисекунд.
Эффективность
Любое изменение, вносимое в реализацию существующих API, должно оставаться настолько эффективным, насколько это возможно, причем, не только для того, чтобы задержка оставалась низкой, но и для предотвращения чрезмерного расхода ресурсов, в частности, CPU и памяти. Поэтому требовалась оптимизация, которая позволила бы сократить усложнение чтения/записи, как будет показано ниже.
Конфигурируемость
Как упоминалось выше, у Schemaless в Uber есть множество вариантов, использования, которые различаются, в частности, по рисунку доступа и допустимой длительности задержки. Поэтому наше решение необходимо сделать параметризуемым по ключевым показателям, чтобы его можно было конфигурировать и настраивать для различных вариантов использования.
Решение
Ключевая идея в рамках данного решения – трактовать данные в зависимости от паттернов доступа к ним, так у нас получается адекватный показатель ROI. Те данные, к которым обращаются сравнительно часто, могут повлечь относительно серьезные издержки, а данные, востребованные в меньшей степени, должны приносить меньше издержек. Именно эта задача решается при помощи стратификации данных – такой подход концептуально подобен иерархии памяти. Однако, нам нужен способ поддерживать обратную совместимость, чтобы наши клиенты могли работать, не чувствуя изменений. Для этого нужно держать данные в том же слое, что и сложные операции, что будет нетривиально с точки зрения межуровневой координации.
Мы рассмотрели, как можно уменьшить площадь, занимаемую в памяти старыми данными. Экспериментировали с пакетным объединением ячеек с данными (напр., в рамках одной поездки) и применяли разные методы сжатия на уровне приложения, чтобы можно было настраивать сжимаемость данных в зависимости от того, какова ожидаемая производительность приложения. Такой ход также позволил сократить усложнение чтения/записи для заданий обратного заполнения, о чем мы поговорим позже. Мы исследовали различные методы сжатия с разными конфигурациями для разных вариантов использования. Пришли к выводу, что алгоритм сжатия ZSTD позволяет получать общую экономию до 40%, когда мы объединяем в пакеты и сжимаем определенные количества ячеек.
На данном этапе мы осознали, что можем позволить себе внутреннюю стратификацию данных в рамках одного уровня, в то же время все равно уменьшая площадь, отводимую в памяти под старые данные – и все это благодаря сжатию и пакетной обработке. Таким образом, задержка остается в пределах миллисекунд. Поскольку размер пакета и ZSTD – конфигурируемые показатели, нам удалось подстроить наше решение для различных случаев использования, в настоящее время обслуживаемых Schemaless. При наличии правильной реализации нам также удалось удовлетворить и требование по эффективности, то есть, выполнить все четыре требования, обозначенных выше. Мы назвали этот проект Jellyfish (Медуза), так как она плавает эффективнее всех в океане и тратит на преодоление некоторого расстояния меньше энергии в пересчете на массу тела, чем какой-либо другой обитатель моря, обходя по этому показателю даже могучего лосося.
Проверка концепции
Теперь, когда мы схематически обрисовали наше решение, нужно быстро оценить его достоинства. Для этого мы выполнили ряд экспериментов и соорудили экспресс-проверку концепции. Мы хотели оценить, каков тот след в памяти, который мы реально экономим.
Для контроля общей экономии ресурсов Jellyfish использует 2 главных параметра; также они нужны для оценки влияния работы на использование процессора:
Размер пакета: управляет тем, сколько строк можно объединить в пакет
Уровень сжатия: управляет соотношением скорости и ZSTD-сжатия
Опираясь на измерения из проверки концепции, мы установили размер пакета в 100 строк, а уровень ZSTD задали равным 7, что не должно было слишком нагружать процессор.
В совокупности такая комбинация дает общую степень сжатия около 40%, что подчеркнуто на следующем рисунке. Здесь также представлены другие конфигурации, опробованные нами, но они показали либо ухудшение полезного результата, либо сниженную экономию.

Ключевая метрика, за которой нам еще требуется наблюдать – это задержка при «пакетных» запросах. Мы отслеживали ее, начиная с самых ранних этапов реализации, проведя некоторое стресс-тестирование и подтверждаем, что укладываемся в длительность задержек, соответствующую требуемому уровню качества обслуживания – сотни миллисекунд.
Архитектура
Хотя мы и рассмотрели несколько альтернатив, здесь мы обсудим лишь окончательный дизайн. Общая архитектура представлена на следующем рисунке. Есть машинные интерфейсы, реализующие пакетную обработку и работу в режиме реального времени. Машинный интерфейс, работающий в режиме реального времени, идентичен старому, но используется для хранения только старых данных. То есть, новые данные записываются строго в тот интерфейс, что работает в режиме реального времени, во многом как и ранее. Затем данные выводятся наружу за один раз, по прошествии некоторого периода времени, после которого они «остывают».
На следующем рисунке в общем виде представлена новая архитектура компонентов клиентской части (Query Layer) и серверной части (Storage Engine) после внедрения Jellyfish. Для краткости сосредоточимся преимущественно на новых частях, которые показаны зеленым. В сердце этой архитектуры две таблицы: (1) стандартная таблица “реального времени” и (2) новая пакетная таблица. Пользовательские данные сначала записываются в таблицу реального времени, как и ранее. Спустя некоторое время (конфигурируется в зависимости от кейса) данные объединяются в пакеты, сжимаются и после этого передаются в пакетную таблицу. Объединение в пакеты делается ячейка за ячейкой, где ячейка – базовая единица Schemaless.
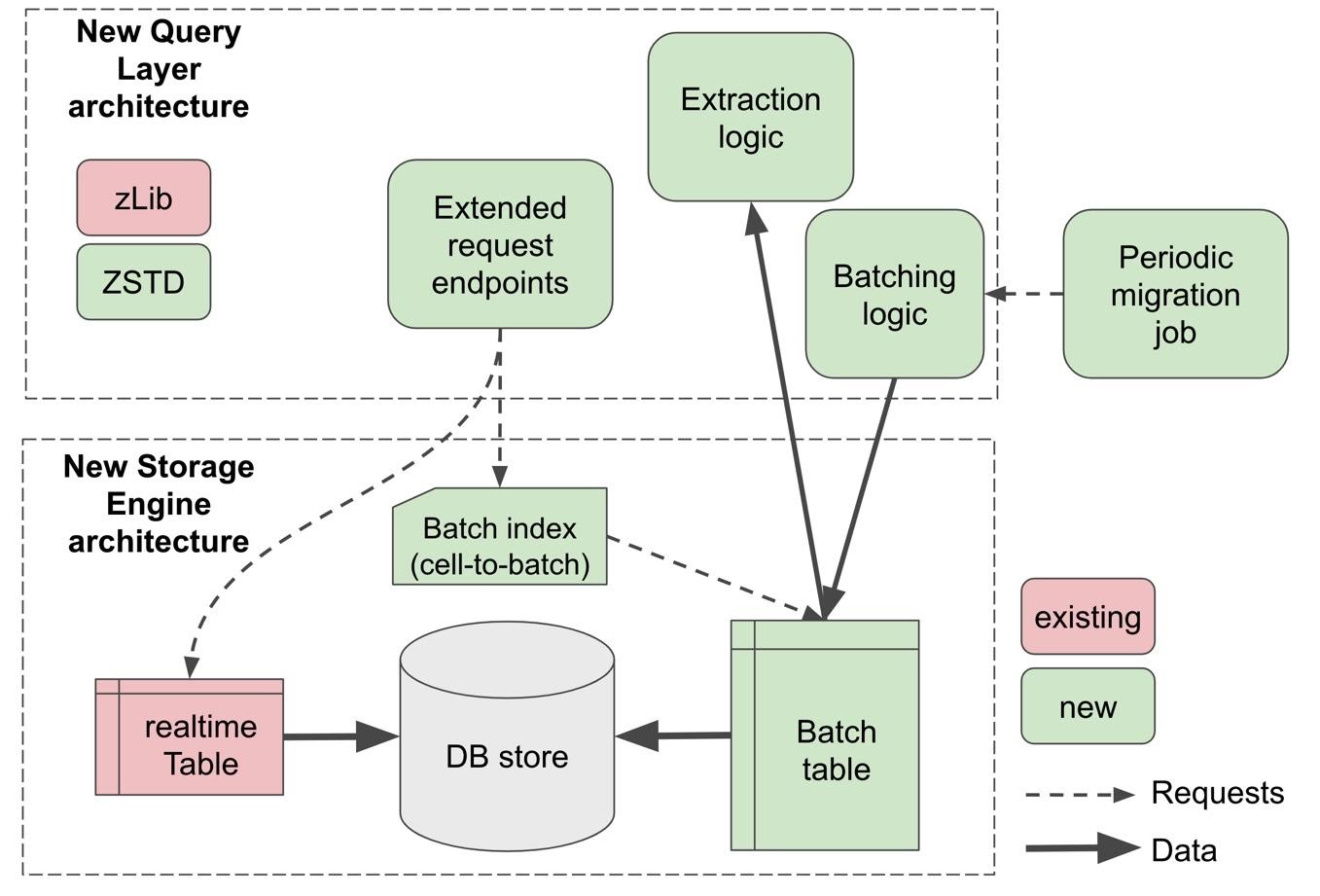
Как понятно из рисунка, Schemaless использует индекс пакетов, который отображается с UUID ячейки на соответствующий UUID пакета (UUID на BID). В ходе считывания старых данных индекс пакета применяется для быстрого извлечения нужного пакета, разжатия его и извлечения нужной ячейки по индексу.
Поток запросов
Такая новая архитектура отражается на потоке пользовательских запросов, и мы проиллюстрируем это на примере операций чтения и записи.
Чтение
Операции считывания отдельных ячеек передают результаты в таблицу реального времени, как обычно, поскольку большинство запросов (> 90%) касается свежих данных. В случае успешности запроса он завершается. В противном случае запрос перекидывается на индекс пакетов, чтобы найти пакетную таблицу и выбрать ее в рамках все того же запроса. Этот поток задач показан на следующем рисунке.

Существует и иной тип операций считывания, при которых запрашивается целая строка (некоторое количество ячеек, образующих логически целостную бизнес-единицу, например, поездку). При таких запросах необходимые данные могут браться как из таблиц реального времени, так и из пакетных таблиц, то есть, пересекать эту границу. При таких запросах вызываются оба машинных интерфейса, после чего результаты объединяются в некотором порядке, определяемом пользователем, как показано ниже.

Запись
Когда данные разбиты по двум таблицам, перестает поддерживаться уникальность первичного ключа. Чтобы этому воспрепятствовать, нужно дополнить запросы на запись такой возможностью: в рамках той же транзакции проверять, наличествуют ли нужные нам данные в пакетном индексе. Мы обнаружили, что поиск в пакетном индексе быстр, так как сами эти операции невелики. На следующем рисунке показан новый поток задач, соответствующий операции записи.

Выкатывание
Поскольку система Schemaless в Uber критически важна, выкатывание Jellyfish должно было пройти абсолютно безупречно. Поэтому самому процессу выкатывания предшествовало несколько стадий валидации, после чего в несколько фаз осуществлялось выкатывание на действующие инстансы. Валидация осуществлялась для всех конечных точек, как новых, так и подхваченных, не только, чтобы обеспечить корректное функционирование, но и для учета пограничных случаев. Далее методом микро-бенчмаркинга были протестированы нефункциональные аспекты конечных точек, чтобы измерить, как новая система укладывается в требуемый хронометраж. Макро-бенчмаркинг применялся к тестовым инстансам, на которых был включен Jellyfish, чтобы охарактеризовать их производительность под разными нагрузками. Также применялось стресс-тестирование, чтобы выявить, как связаны пропускная способность и задержки. Подтверждаем, что уровень качества обслуживания для задержек соблюдается; Jellyfish позволяет ограничить длительность задержек несколькими сотнями миллисекунд.
Подготовив Jellyfish, мы приступили к выкатыванию ее в продакшен. Система Mezzanine, используемая в Uber в качестве хранилища поездок, занимает особенно много места. Мы решили выкатывать Jellyfish поэтапно.
Фазы
Выкатывание в продакшен протекало в несколько фаз, как показано на следующем рисунке. Далее обсуждается, как происходило выкатывание в рамках одного шарда. Вообще выкатывание постепенно охватывало разные шарды и области.

Активация Jellyfish. Конфигурируется Jellyfish и диапазон миграции данных для инстанса, обеспечивается создание пакетного машинного интерфейса.
Миграция. В рамках миграции старые данные считываются с машинного интерфейса реального времени и копируются на пакетный машинный интерфейс. На эту фазу требуется больше всего времени и ресурсов, причем, эти затраты масштабируются в зависимости от объема данных, миграцию которых нужно осуществить.
Проверка согласованности оттеняет трафик, идущий в таблицу реального времени, чтобы можно было валидировать данные на пакетном машинном интерфейсе. Здесь вычисляется дайджест запрошенных старых данных, после чего они сравниваются с данными, поступающими от Jellyfish. Мы ведем отчет по двум видам согласованности: по содержимому и по счету. Для успешной миграции оба этих показателя должны быть равны нулю.
Операция предудаления, фактически обратная операции оттенения, активируется лишь при 100%-й согласованности. Трафик для старых данных фактически подается Jellyfish, тогда как мы все равно вычисляем дайджест данных с машинного интерфейса, работающего в реальном времени, и сравниваем этот дайджест с данными из Jellyfish.
Логическое удаление исключает путь считывания из интерфейса реального времени, причем, только для старых данных, поэтому никакой дайджест для выбранных шардов не вычисляется. На данном этапе в точности эмулируется процесс исчезновения старых данных с интерфейса, работающего в реальном времени. Такой подход помогает протестировать логику стратификации и понять, как будет работать новый поток данных, когда данные будут удалены по-настоящему.
Физическое удаление – это реальное удаление данных после подтверждения того, что логическое удаление прошло успешно. В отличие от всех предыдущих фаз, эта фаза необратима. Кроме того, удаление распределялось по разным репликам для обеспечения доступности данных и бесперебойной работы бизнеса в случае возникновения непредвиденных проблем во время исполнения.
Сложности
При внесении изменений в любую продакшен-систему, работающую в режиме live, неизбежны сложности. Чтобы обеспечить неизменную безопасность и доступность данных, мы осмотрительно организовали работу в несколько фаз. Убедились, что у наших клиентов будет достаточно времени на мониторинг и тестирование, пока мы переходим от одной фазы к следующей.
Одна из сложностей, с которыми пришлось столкнуться – это высокая нагрузка, вызванная тем, что конкретный сервис в основном просеивал старые данные для пересчета их дайджестов. Такая высокая нагрузка приводила к неприемлемым задержкам, поэтому мы работали с клиентом, помогая ему вывести этот старый конвейер из употребления. Другой, более серьезный вызов заключался в том, что пользователи получали неполные данные из старых строк, ячейки которых были недавно обновлены. Необходимо было выкатить исправление, в рамках которого результаты для таких строк объединялись из информации, взятой одновременно с пакетного интерфейса и интерфейса реального времени, и лишь после этого возвращались пользователю. Третья сложность заключалась в том, как скоординировать осуществление такой миграции с другими задачами, опирающимися на активное использование данных, например, с перестройкой пользовательских индексов и с заданиями обратного заполнения.
Вывод: в продакшене обязательно возникнут такие вызовы, которые скажутся не только на сроках проекта, но и на применимости решения. Тщательная диагностика и тесная совместная работа с клиентом абсолютно необходимы, чтобы справиться с такими вызовами.
Оптимизации
На протяжении реализации проекта Jellyfish мы склонялись к оптимизации задержки или пропускной способности на тех участках, где Jellyfish очевидным образом меняла модель доступа к данным. Вот некоторые из таких оптимизаций:
Декодирование запрошенной ячейки: Когда пользователь запрашивает ячейку, одновременно выбирается целый пакет. Мы декодируем только JSON запрошенной ячейки, чтобы таким образом обойтись без декодирования остальных 99 ячеек.
Удаление только метаданных: при удалении ячеек на месте (по причине истечения времени жизни и пр.), мы сначала всего лишь удаляем запись о ячейке из индекса пакетов, так, что пользователь больше не может к ней обратиться. Фактическое удаление ячейки выполняет фоновое задание, производящее операции «прочитать-изменить-записать» для обновления ячейки в пакете. Информация из удаленной ячейки сохраняется в журнальной таблице, чтобы затем ее потребило фоновое задание. Так мы страхуемся от выполнения такой затратной операции в приоритетном режиме, и основной путь чтения/записи при этом не затрагивается, а также сокращается задержка, воспринимаемая пользователем.
Попакетное объединение обновлений: при обновлении ячеек на месте такая операция может по несколько раз затрагивать одну ячейку пакета. Обновления в режиме «чтение-изменение-запись» могут быть затратными как по ресурсам, так и по времени. Попакетно группируя обновления, нам удалось вчетверо сократить общее время обновления, затрачиваемое одним заданием.
Пожинаем эффективность
Когда мы полностью выкатили Jellyfish и убедились, что она соответствует нашим требованиям, результаты не заставили себя ждать. На следующем рисунке показано, как изменялось фактическое место, занимаемое данными в памяти, по мере того, как происходило удаление. В данном конкретном случае Jellyfish позволила сократить фактический объем хранилища на 33%.

Дальнейшая работа
Проект Jellyfish позволил с успехом сократить эксплуатационные расходы Uber, а значит, будет выгоден и в перспективе. Концепция стратификации, представленная здесь, допускает несколько вариантов расширения для дальнейшего повышения эффективности и сокращения расходов. В частности, мы подумываем применить Jellyfish к Docstore, реализовать явную стратификацию и использовать физически раздельные уровни. Отчасти это достигается предоставлением пользователю нового набора API для доступа к старым данным, а также оптимизацией как программных, так и аппаратных стеков для разных уровней.