

Мы запускаем серию статей про CV в ритейле. За несколько лет работы с технологиями искусственного интеллекта у нас появилось много опыта и накопилось несколько успешных кейсов внедрения компьютерного зрения в реальный бизнес. И нам есть чем поделиться: распознавание ценников, прайсов сигарет, разметка полок и многое другое. В этой статье расскажем про то, как мы научились распознавать товары на фото, как отличить водку от яйца и не дать нейронке принять тебя за древесный уголь.
Первые варианты решения
Когда мы решали задачу по определению товара на фото, у нас было 1000+ товаров, несколько миллионов фото с меткой о них, один MobileNet, пару серверов с видеокартами и куча проблем, связанных с актуальностью такой модели. Почему MobileNet, а не более сложные архитектуры и пайплайны? Потому что пользы от них мало. Разрабатывать и обучать их дорого и долго, распознавать нужно сейчас. На многих наших фото большую часть занимает изображение одного товара, поэтому здесь хватает только одного классификатора.
Из миллиона фотографий мы легко собрали нужный датасет. Для начала брали по 5000 изображений на товар. Со сбором данных практически не было проблем, не считая товаров-аналогов, но вернемся к ним позже.
Чтобы обучить модель распознаванию товаров по фотографиям в разных сетях мы выполняли несколько шагов.
Проводили аналитику для того, чтобы понять в каких кейсах ошибаемся. Например, в нашей модели может не быть какого-то товара или фотографии из определенной сети в магазине могут отличаться от тех, которые есть в нашем датасете. Бывали моменты, когда нейронка ошибалась и выдавала не то, что надо. Иногда даже наши фото сотрудников принимала за древесный уголь или яйцо. В общем, проверяли и обманывали модель как могли, чтобы добиться наилучшего результата.
В начале проекта нашли группу товаров, которые путались между собой. Оказалось, что там были фотографии с прайсами сигарет, а распознавание таких фото вообще не входит в задачу распознавания товаров. Обычно цены на сигареты выглядят таким образом.

О задаче распознавания прайс-листов на сигареты мы расскажем в другой статье.
После проведенной аналитики, обновляли датасет, скачивая новые фотографии. Затем брали предобученную модель, меняли слой ответственный за классификацию и дообучали под новые классы.
И таким образом, мы правильно распознавали 75,5% фото товаров.
Учитывая наш бизнес-процесс этого хватило для запуска модели в продакшн, но не гарантировало 100% распознавание. О проблемах, связанных с моделью мы напишем дальше, но были и проблемы с качеством фотографий. Например, были фотографии с бликами и засветами или на изображении была только половина товара или нужный объект находился где-то с краю. Такие кейсы мы решали административным способом и записывали обучающие видео как правильно делать фотографии.
Так о каких проблемах упоминали в начале?
По внешнему виду сложно определить объем товара, поэтому наша модель часто путала SKU одного товара, но с разными объемами.

Добавление новых товаров было привязано к релизу модели, и мы не могли оперативно добавлять их, т.к. тренировка занимала по несколько дней. В итоге новые товары могли неделю ошибочно распознаваться. Ассортимент обновлялся довольно часто и в какой-то момент возникла ситуация, когда ML-оборудование постоянно было занято обучением модели, и нам не хватало ресурсов для проведения других экспериментов, т.к. их было ограниченное количество.
Фото товаров содержали товары-аналоги, которые по характеристикам и стоимости соответствуют самому товару, но не являются им, и в нашем случае содержат такую же метку, как и основной товар. Для нас это означало:
Что мы заставляем нашу модель выучивать внешний вид сразу нескольких разных товаров.
Разные товары могут иметь общие аналоги и, соответственно, мы показываем нейронке один и тот же товар в разных классах и путаем её.
Менеджеры торговой сети сами решают какие у товара аналоги и часто их меняют, или вообще могут начать этот товар продавать у себя, поэтому он перестанет быть аналогом.

Таким образом, мы поняли, что нам нужна более сложная логика для распознавания товаров, чем просто использование классификатора.
Как отвязать добавление новых товаров от релиза модели
Для классических методов классификации требуется большой датасет, а обучать модель при таком количестве изображений можно достаточно долго. Поэтому у нас было время придумать альтернативы. А они есть!
Основная идея заключается в том, чтобы не решать каждый раз задачу классификации, а один раз обучить модель, которая будет возвращать векторное представление объекта, которое можно использовать для поиска в базе данных с уже рассчитанными векторами для каждого класса. Делать это можно с помощью различных вариаций ArcFace и triplet loss. Такой подход называется Metric Learning.

Во избежании технических неудобств с выбором негативных и позитивных примеров для triplet loss, мы взяли arcface, поскольку он хорошо показывает себя в аналогичной задаче в области распознавания лиц.
Использование Metric Learning позволило нам уменьшить количество необходимых данных для обучения до 500 изображений на класс. Релиз новых товаров в системе происходит с помощью добавления их векторного представления в базу. Но их качество распознавания ниже, чем у тех, на которых модель обучалась. Такой подход позволяет нам делать прогноз даже тогда, когда модель не видела товар, а обучать ее можно гораздо быстрее.
Однако, есть проблема, которую даже Metric Learning методами тяжело решить — определение объемов. В повседневной жизни мы можем это сделать путем сравнения объектов между собой. Научить этому модель довольно тяжело. Порой одни и те же товары разного объема выглядят почти одинаково, а обучать нейронную сеть разделению таких изображений на два класса неправильно. Поэтому фотографии с разным объемом объединяются в один кластер, а в дальнейшем добавляется постобработка по уточнению объема товара. Например, уточнять объем можно по цене, либо по отношению размеров с другими объектами на фотографии.
А что делать с товарами-аналогами?
Для быстрой разметки нам было необходимо объединять товары в группы по внешнему виду. В open source инструментах такого функционала нет, поэтому мы разработали свою платформу разметки. Ключевой функцией стала “Найти похожие”.

Мы определяем некачественную фото по следующим признакам:
Фотография размыта
Фотография сделана с плохого ракурса
Товар находится за дверью в холодильнике
Товар находится не по центру кадра, дизайн упаковки сильно обрезан, невозможно идентифицировать товар
Для группировки товаров, был разработан функционал “Найти похожие”. В одной группе могут быть разные вкусы, фото одно товара-аналога и тд. Эта фича позволяет сортировать фотографии в папке по “схожести” с выбранным изображением. Более наглядно можно объяснить двумя фотографиями.
До использования функции “Найти похожие”:
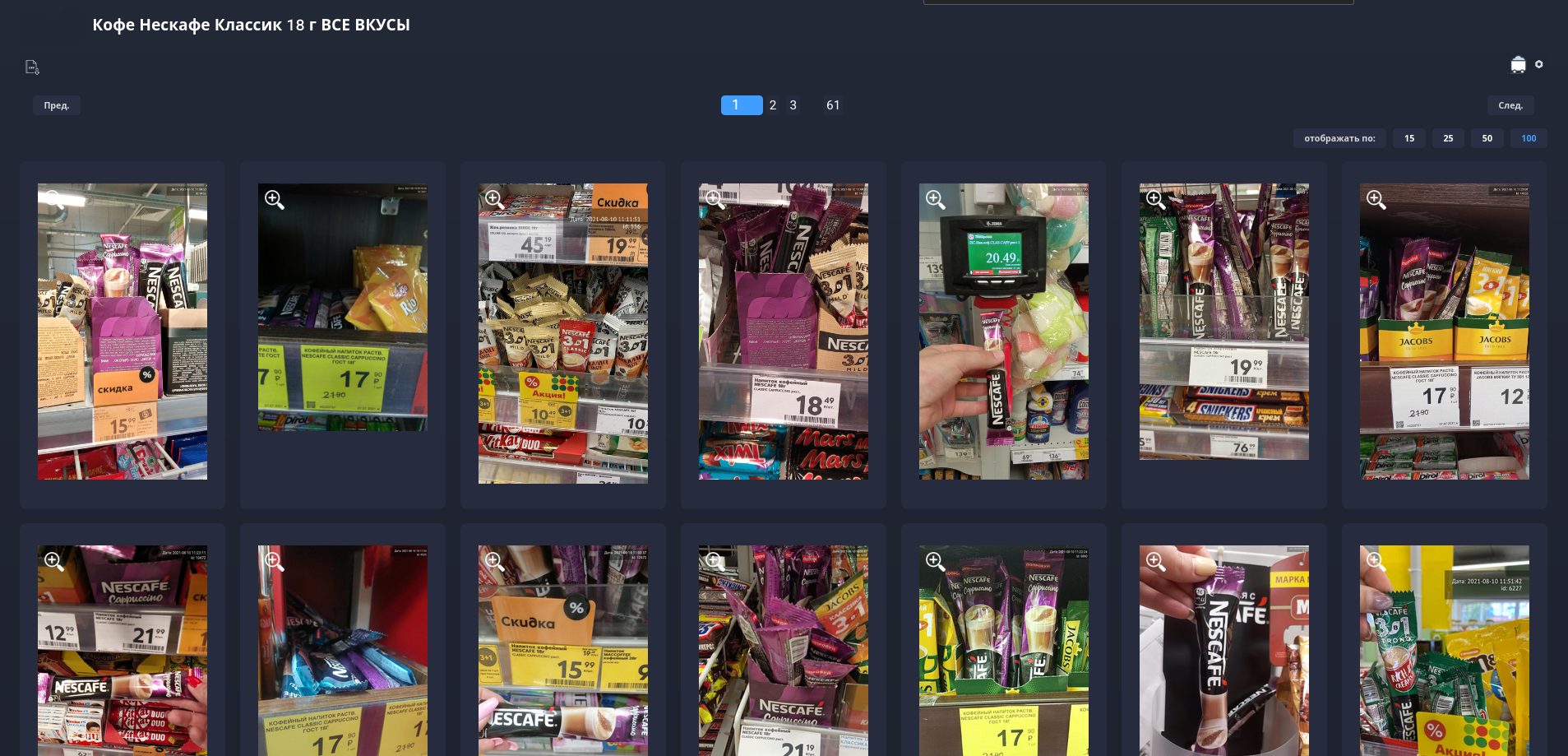
После:
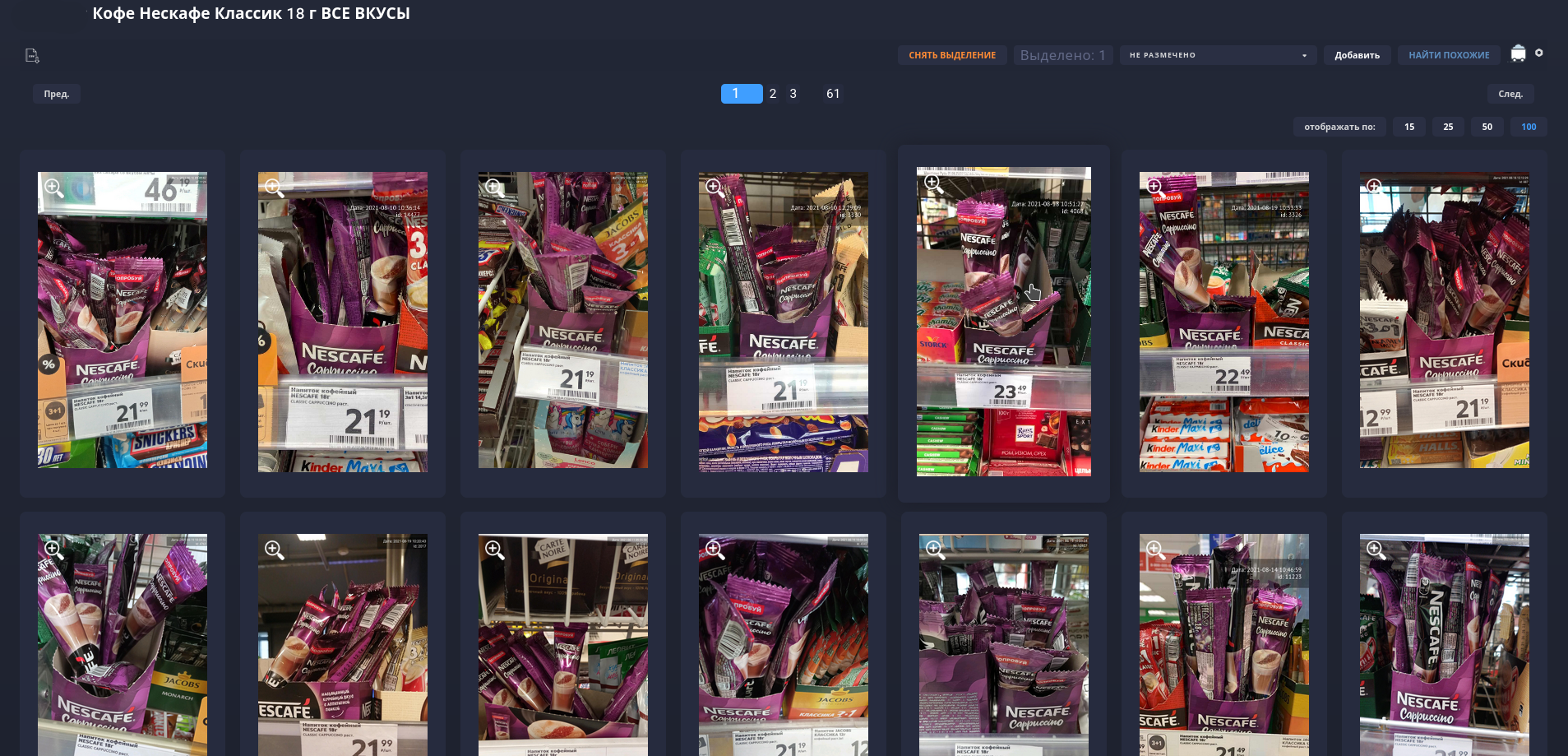
И с помощью такого функционала мы смогли отделить товары-аналоги от основного товара.
После внедрения Metric Learning и своей платформы разметки мы пришли к следующему пайплайну.
Проводим аналитику и собираем новые товары или те, которые плохо распознаются.
Выделяем из новых фото группы товаров.
Если нужно, дообучаем модель.
Векторизуем все группы товаров и добавляем в базу. Аналоги векторизуются отдельно, но им проставляется метка основного товара.
Когда приходит фото на распознавание, мы извлекаем из него вектор признаков и сравниваем с теми, которые есть в базе, и выбираем товар с наиболее похожим вектором.
И проверяем насколько большое расстояние у этого товара и отправленного изображения. Если оно больше определенного порога, мы понимаем, что такого товара у нас нет в базе. И так мы перестали путать людей с углем.
И по итогу мы теперь можем на лету обновлять базу распознаваемых товаров и аналогов, а также увеличили качество распознавания товаров до 87,5%. А для устранения проблемы с объемами мы стали анализировать ценники, но об этом расскажем в другой раз.
DrBulkin
Одно слово - крутота
Soorin
Зелёный клубничный сок на КДПВ только смущает.