
Теория
База данных Cache представляет собой каталог с названием базы, в котором содержится файл CACHE.DAT. На *nix-системах, в качестве базы данных может выступать раздел на диске.
Данные в Cache хранятся в блоках, а те, в свою очередь, организованы в виде сбалансированного B*-дерева. Если вспомнить, что мы храним глобалы в виде дерева в упрощённом понимании, ветками в таком дереве будут сами индексы глобала, а листьями – значения индекса глобала. Отличие сбалансированного B*-дерева от обычного B-дерева в том, что ветви имеют правые связи, помогающие (в нашем случае с глобалами) обходить индексы достаточно быстро с помощью функций $Order и $Query, без необходимости подниматься к стволу дерева.
Размер блока в файле БД фиксированный, по умолчанию он составляет 8192Б, но есть возможность разрешить создавать БД с размерами блоков 16кБ, 32кБ и 64кБ. Разработчик системы может выбрать необходимый размер блока в зависимости от характера данных, которые он планирует хранить. Но всегда нужно учитывать, что чтение данных производится поблочно – даже если запрошено одно значение размером 1 байт, будет прочитано несколько блоков, и только последним в этой цепочке будет блок с данными. Cache также имеет разные буферы глобалов – нельзя смонтировать или создать новую БД, если в системе не настроен буфер глобалов с соответствующим размером блока – это приведёт к ошибке.


На картинке как раз выделена память для буфера глобалов для баз с 8кБ блоками – только такие базы с 8кБ блоками и будут работать в этой системе. Блоки в БД сгруппированы в карты, одна карта в случае с 8кБ блоком описывает 62464 блока, и хранится в блоке карты, который идёт первым в карте.
Типы блоков
Существует несколько типов блоков. На каждом уровне блоков правая связь должна указывать на блок того же типа, либо на нулевой блок, что может означать, что дальше данных нет.
- тип 9: блок каталога глобалов. Используется для описания всех имеющихся глобалов и их параметров. Для каждого глобала в этом блоке определена сортировка (collation) индексов глобала — очень важный параметр, отвечающий за сортировку данных. Этот параметр не может быть изменен после создания глобала;
- тип 66: блок указателей верхнего уровня. На этот блок сверху может указывать только блок каталога глобала;
- тип 6: блок указателей нижнего уровня, выше него должны быть блоки указателей верхнего уровня, а ниже только блоки данных;
- тип 70: блок указателей верхнего и нижнего уровня сразу. Используется, когда значений в глобале пока не так много, и нет нужды заводить несколько уровней блоков. Указывает на блоки данных — на такие блоки ссылаются блоки каталога глобалов;
- тип 2: блок указателей, для хранения достаточно большого глобала. Может потребоваться больше уровней блоков указателей для того, чтобы обеспечить равномерное распределение значений по уровню блоков данных. Данный блок находится между блоками указателями;
- тип 8: блок данных. В таком блоке хранятся значения не для одного узла глобалов а сразу для нескольких;
- тип 24: блок хранения больших строк. Если значение одного глобала не может быть умещено в один блок, то оно помещается в такой блок, а узел в блоке данных хранит ссылки на список блоков больших строк, а также общую длину значения;
- тип 16: блоки карты. Необходимы для хранения информации о том, какие блоки на данный момент свободны.
Итак, в первом блоке базы данных Cache находится служебная информация о файле БД. Во втором – карта блоков. А первый блок каталога идёт третьим (блок номер 3) и таких блоков каталога может быть несколько для БД. Далее идут блоки-указателей (ветви), блоки данных (листья деревьев) и блоки больших строк. Как я уже писал выше, блок(и) каталога глобалов хранит информацию о всех имеющихся глобалах в БД. Он также может хранить настройки глобала даже в том случае, если данных в таком глобале вообще нет. В таком случае узел, описывающий такой глобал, будет иметь нулевую нижнюю ссылку. Просмотреть список глобалов из каталога глобалов можно через портал управления. Там же можно включить возможность сохранения глобала в каталоге после удаления – например, для сохранения сортировки.

Там же можно создать новый глобал – в таком случае можно задать сразу любую доступную сортировку и выбрать её отличной от той, что установлена по умолчанию в базе данных.

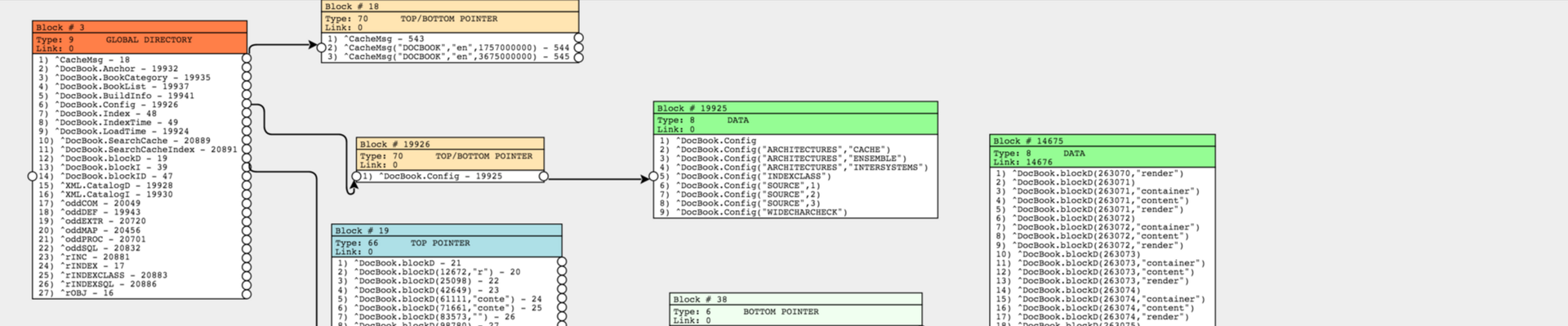
В общем виде дерево блоков можно представить как на картинке ниже. Красным цветом отмечены ссылки на блоки.

Целостность базы данных
На текущий момент развития СУБД Cache возможные случаи и ошибки, которые могли бы привести к деградации БД, сведены к минимуму, и необходимость ремонта базы данных возникает всё реже. Но проверку целостности в любом случае рекомендуется проводить регулярно на автоматической основе. Для этого есть утилита ^Integrity, которую можно запустить через терминал из области %SYS, через портал управления, на странице Базы данных, а также через менеджер задач. Кстати, задача по автоматической проверке целостности уже настроена по умолчанию, но отключена – её достаточно только активировать:


В процессе проверки целостности, проверяется правильность указания нижних ссылок, правильность типов блоков, выполняется проверка правых связей. Сравниваются также и узлы глобалов, чтобы они соответствовали порядку сортировки. Если в результате проверки целостности всё-таки были обнаружены ошибки, то можно воспользоваться утилитой ^REPAIR, которую можно запустить в области %SYS. Эта утилита позволяет как просмотреть любой блок, так и подредактировать при необходимости, т.е. отремонтировать БД.
Практика
Но всё это теория. Как выглядит глобал и его блоки на самом деле – судить пока довольно сложно. Единственный сейчас доступный способ просмотра блоков – это упомянутая выше утилита ^REPAIR. Вывод этой программы выглядит примерно так:

Я не так давно начал работать над проектом, который позволяет пройтись по дереву блоков, без риска повредить БД, и удобно просматривать в браузере, с возможностью сохранить эту визуализацию в SVG или PNG-формате. Проект называется CacheBlocksExplorer, исходники проекта выложены на Github.

Из реализованных возможностей:
- Возможность просмотреть любую настроенную или просто смонтированную БД в системе;
- Возможность просматривать информацию по блоку, тип блока, правый указатель, список узлов с их ссылками;
- При клике на любой узел, имеющий ссылку на нижний блок, информацию по данному блоку загрузится и отобразится, так же как и ссылка на загруженный блок;
- Есть возможность удалить из отображения некоторые блоки, просто удалив ссылку, к изменениям в данных это не приведет.
Что еще необходимо сделать:
- Отображение правой ссылки: на данный момент отображается как информация по блоку, хотелось бы показать в виде стрелочки;
- Поддержка отображения блоков больших строк: сейчас они просто не отображаются;
- Отображение всех блоков каталога глобалов, а не только третьего.
Также хотел сделать отображение сразу всего дерева, но пока не нашёл такой подходящей библиотеки, которая могла бы достаточно быстро отобразить несколько сотен тысяч блоков вместе со связями, в текущей библиотеке это получается очень медленно и отрисовка в браузере получалась медленнее, чем чтение этой структуры в Cache.
В следующей статье я расскажу подробнее на примерах, как всё работает и что можно узнать о наших глобалах и блоках, если у вас есть такой инструмент, как разработанный мной Cache Block Explorer.
Комментарии (9)

AlexeyMaslov
06.10.2015 13:43+3Автору респект: подобные статьи особенно нужны, т.к. документация скупа на эту тему. Большинству из нас пришлось изучать структуру блоков с помощью REPAIR, пусть новичкам будет чуть полегче.

smagen
14.10.2015 13:08+1Данная статья – очень большой прогресс во всём блоге. Но для тех, кто пользовался реляционными СУБД с MVCC, серьёзный подводный камень глобалов – это их модель конкурентности. Без понимания этих особенностей, от использования глобалов можно сильно проиграть в производительсности, вместо того, чтобы что-то выиграть. Надеюсь, в будущих постах, эта тема будет раскрыта.

tsafin
14.10.2015 13:27+1Хотелось бы подчеркнуть, что Дима DAiMor не является сотрудником InterSystems и, реализовав отличный инструмент просмотра структуры глобалов и карты распределения блоков, он пишет о том как можно изучать внутренности текущей реализации с использованием его внешнего инструмента. Ни больше и не меньше.
В следующих двух его постах он покажет (в картинках! :) ) как использовать его просмотрщик, и, боюсь там ни слова не будет про MVCC.
tsafin
14.10.2015 13:32+1С другой стороны, отходя от ткущего топика, да «блокировщики против версионщиков» важная тема, и её при случае надо рассмотреть. И, конечно же, над уметь правильно использовать глобалы и CacheSQL реализацию на оных.
А давайте Вы, Александр smagen попытаетесь написать такую статью, с Вашим пересечением экспертизы и в Cache и PostgreSQL?smagen
14.10.2015 15:49Экспертизы в Cache у меня нет. В 2008-2009 годах был печальный опыт использования объектного доступа и SQL в Cache. Никаких преимуществ от использования этих двух инструментов я на тот момент не заметил (возможно, сейчас, ситуация несколько изменилась). Дальше мой интерес к Cache двигался в основном ощущением несоответствия между тем, что я увидел на собственном опыте, и тем, что у продукта, есть клиенты, успешно выполненные проекты, коммерческий успех. До какой-то степени этот пробел я восполнил, но на экспертизу мои познания явно не тянут.
excoder
Статьи по Cache на хабре всегда интересны, но складывается такое впечатление – требуется весьма низкоуровневое понимание этой технологии, чтобы эффективно с ней работать. Может быть я не так понимаю нишу этой технологии?
misha_shar53
Не так. Низкоуровневое понимание ненужно. Обращение к данным элементарно, как к индексированному массиву. Администрирование эпизодическое. Установка и настройка необходимого уровня архивирования. За много лет работы с CACHE мне ни разу не пришлось ремонтировать блоки. Есть архивы, журнал.
DAiMor
Для начинающего в Cache такие знания не особо нужны, чтобы не забивать голову такими подробностями, на самом деле большинство разработчиков думаю о блоках знают, то что они есть, не особо вникая в сами процессы там возникающие. Все видели что есть буфер глобалов 8кБ, есть БД с 8кБ блоком, и большинству этого будет достаточно.
Что касается этой статьи, то это уже уверенный уровень владения Cache. И такие знания могут быть полезны, когда проекты становятся большими, и требуется выжать максимум из всего. Когда размеры БД становятся довольно большими, а диски перестают справляться с нагрузкой, тогда может стать полезным узнать а как можно ускорить чтение БД, как его можно оптимизировать.
И я почти уверен что такое возможно не только для Cache, наверняка в других СУБД есть порой необходимость выйти на низкий уровень, чтобы достичь поставленных целей.
Например, одна из задач которая у меня возникала, это узнать подробно сколько места занимает глобал, вес глобала нужно было знать на разных его уровнях. чтобы определить именно ту ветку которая занимает места больше всего, по той или иной причине. Это было распухание временного глобала. Таких инструментов не было в ранних версиях, и делал такой расчет обходя блоки, и вытаскивая из них нужную информацию.
intersystems
Вход в технологию на самом деле ниже, чем кажется.
Нашим партнерам, которые начинают первый проект на технологиях InterSystems, часто достаточно одного двух спецкурсов чтобы уже через пару недель полноценно включиться в разработку проекта на Cache или Ensemble. Учитывая, что в большинстве проектов наших новых заказчиков мы помогаем сделать Proof-of-Concept, эффективность выбора технологии становится видимой очень быстро.
Если говорить о нишах: мы очень успешно делали и делаем интеграционные проекты с помощью платформы Ensemble.
Все случаи, где сейчас успешен NoSQL — там также будет успешна Cache, потому как по природе управления хранимыми данными Cache есть то, что сейчас называют NoSQL.
Традиционно Cache сильна в медицинских решениях со сложными и разреженными структурами данных, сложной логикой работы с данными, а также в высоконагруженных транзакционных системах — биржи, брокеры, банки.
Если есть сложная бизнес-логика, которую трудно распахивать с помощью SQL процедур — это тоже наше поле, т.к. Cache Object Script (COS) может в некоторых случаях намного эффективнее, быстрее и очевиднее управляться с данными, чем это делают хранимые процедуры в SQL серверах (это не критика SQL хранимых процедур — они эффективны, и у нас они тоже есть. Но существует много случаев, когда эффективнее COS). И, что немаловажно, такое решение легко поддерживаемо.
Наши партнеры и клиенты также могут сказать о низкой стоимости владения, о работе службе поддержки — но это уже наверно не релевантно хабру.