
Фишинговые электронные письма - это сообщения, которые кажутся очень похожими на настоящие, например, рассылку от вашего любимого интернет-магазина, но при этом они заманивают людей нажимать на прикрепленные вредоносные ссылки или документы.

Все более креативные фишинговые кампании в последние годы требуют более умных систем обнаружения. В связи с этим на помощь приходит глубокое обучение, а именно обработка естественного языка (NLP) с использованием глубоких нейронных сетей. Для обучения и тестирования этих сетей требуются знания из большого количества электронных писем.
Однако ежедневные сообщения пользователей, содержащие личную информацию, трудно собирать в реальной жизни на сервере для обучения нейронной сети из-за проблем с конфиденциальностью (Вы же не хотите, чтобы Ваши письма читал какой-то искусственный интеллект). Поэтому в статье предлагается способ обнаружения фишинговых сообщений, называемый Federated Phish Bowl (далее FPB), использующий федеративное обучение и рекуррентную нейронную сеть с долгой краткосрочной памятью (LSTM).
Давайте же подробнее разберемся, как работает предложенный метод!
Нейронные сети, а именно LSTM

Сейчас практически все люди хотя бы слышали про нейронные сети, но не многие знают, как они работают. Для начала представим, что это “черный ящик”, который может решить какую-нибудь поставленную задачку. Вот самые популярные из них:
Классификация (например, отличить котиков от собачек)
Регрессия (по описанию человека определить его возраст)
Конкретных подслучаев можно перечислить бесконечно много. Главное понимать, что приходит на вход сети и что мы хотим из неё получить.
Если говорить конкретнее, то нейронная сеть - это сложная функция, которая применяется ко входным данным (любую картинку или текст мы можем представить в виде матриц или векторов), а на выходе данной функции получается матрица, вектор или же число, в зависимости от поставленной задачи.
Для работы с текстовыми последовательностями были придуманы рекуррентные нейронные сети (RNN, их улучшение - LSTM, которая бывает двунаправленной, когда последовательность обрабатывается в двух направлениях). Сети называются рекуррентными, потому что он в них одинаковые блоки обрабатывают элементы последовательностей и свои выходы. Данные сети хороши тем, что в отличие, например, от свёрточных, в них учитывается порядок элементов последовательности (слова в предложениях могут обрабатываться согласно временной шкале).
Для начала нужно получить информативное векторное представление слов, которое должно учитывать близость между словами, их контексты,а также быть осознанного размера (например, Word Embeddings).
Остановимся подробнее на блоках LSTM:
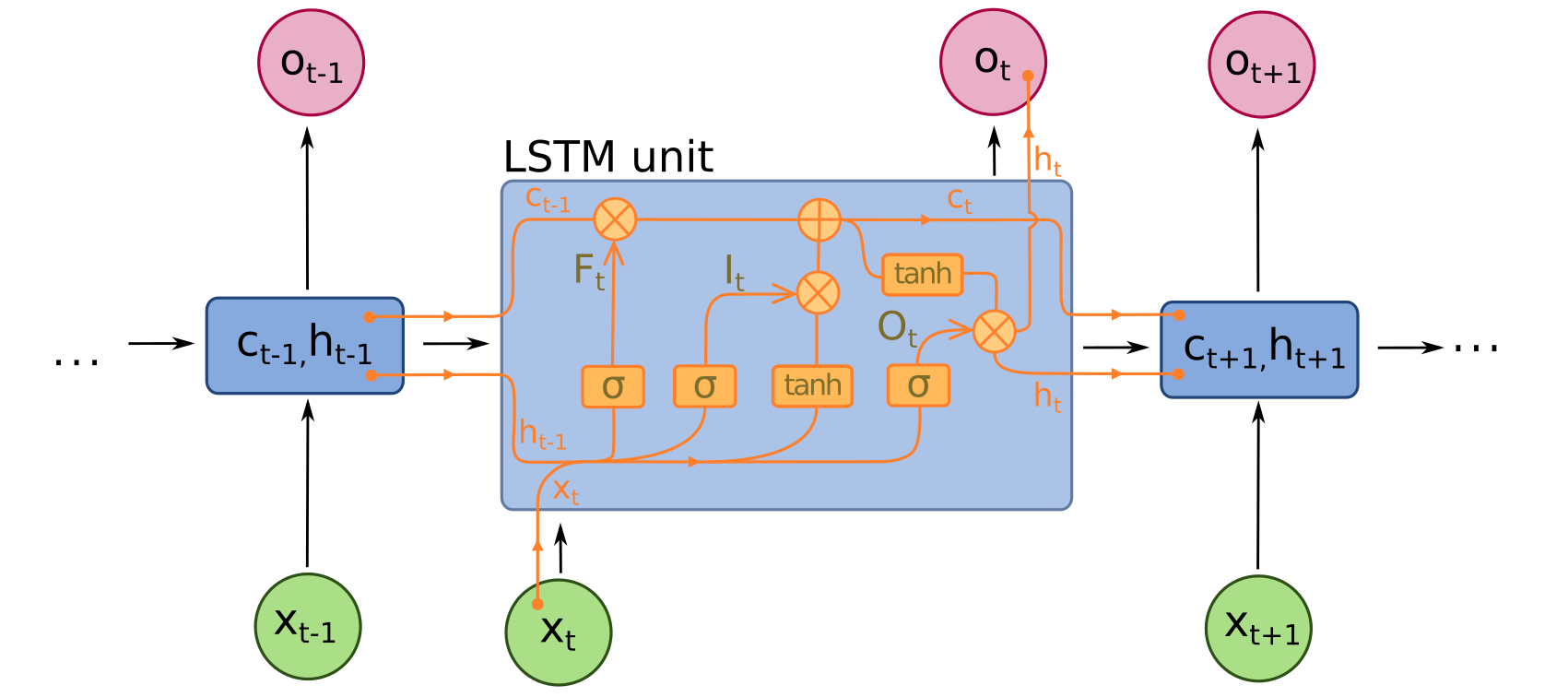
Так выглядит одна ячейка LSTM. Из рисунка видно, что на вход ячейки приходит вектор слова (Xt, обозначен зеленым цветом), вектора короткой и долгосрочной памяти из прошлой ячейки (Ht и Ct соответственно), также Ht может рассматриваться, как отдельный выход из ячейки. А именно: мы с помощью сети прочитали всё сообщение, которое пришло на почту, то есть выход из последней ячейки собрал всю информацию о тексте. Поэтому по данному выходу можно понять, фишинговое это сообщение или нет. По сути показывая сети много разных сообщений (фишинговых и нет), мы учим её классифицировать наши письма.
Для улучшения качества классификации применяются различные усложнения архитектуры. Например, сеть можно сделать двунаправленной (Bidirectional LSTM).
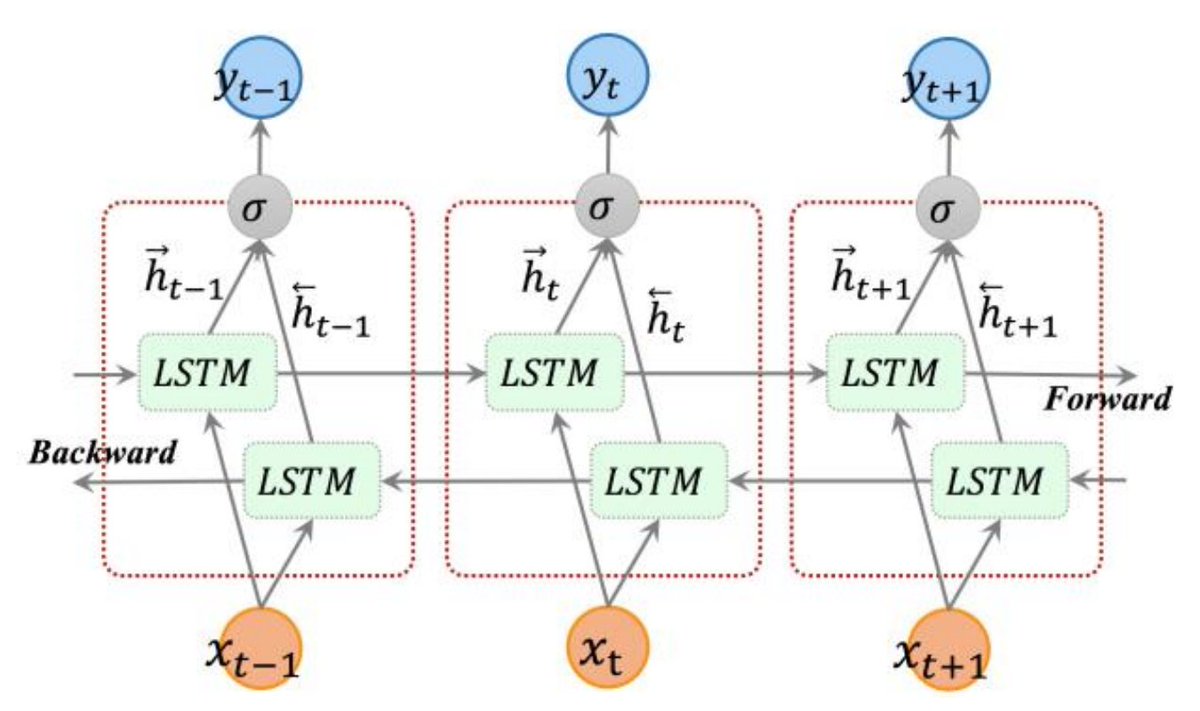
Сначала сеть обрабатывает слова от начала сообщения до конца, а затем от конца к началу. После чего объединяет результаты обоих проходов для более информативного представления последовательности. Такой подход помогает сети “не забывать” информацию из начала последовательности (такое случается, когда сообщение очень длинное).
FPB предлагает использовать подход, показанный на следующем изображении:
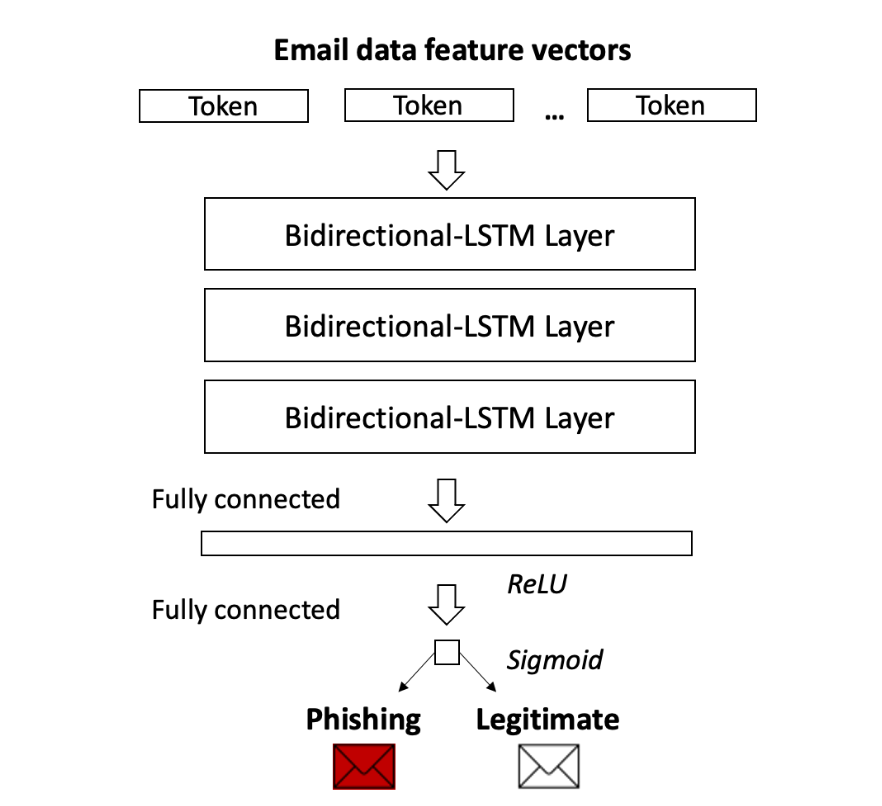
Здесь используется 3 двунаправленные LSTM, где каждая последующая сеть обрабатывает выход предыдущей, после чего результат подаётся на вход полносвязному слою (можно считать, что умножаем выход на матрицу, а затем применяем нелинейность. Куда же нейронные сети без них). После чего получаем некоторое число для каждого сообщения, которое с помощью функции sigmoid переводим в диапазон [0, 1], что позволяет нам предсказать вероятность того, что наше сообщение фишинговое.
Федеративное обучение
Мы разобрались с тем, как определить, является ли сообщение фишинговым. Осталось понять, как сохранить конфиденциальность данных пользователя. Для начала введем понятие федеративного обучения.
Федеративное обучение - это метод машинного обучения, который обучает алгоритм на нескольких децентрализованных устройствах или серверах, содержащих локальные образцы данных, без обмена ими. Этот подход отличается от традиционных централизованных методов машинного обучения (когда все локальные наборы данных загружаются на один сервер), а также от более классических децентрализованных подходов, которые часто предполагают, что локальные выборки данных распределены одинаково. Общий принцип заключается в обучении локальных моделей на локальных выборках данных и обмене параметрами (например, весами глубокой нейронной сети) между соответствующими локальными узлами с определенной частотой для создания глобальной модели, общей для всех узлов.
Основное различие между федеративным и распределенным обучением заключается в предположениях относительно свойств локальных наборов данных, поскольку распределенное обучение направлено на распараллеливание вычислительных мощностей, в то время как федеративное обучение нацелено на обучение на неоднородных наборах данных. Хотя распределенное обучение также направлено на обучение одной модели на нескольких серверах, общее базовое предположение заключается в том, что локальные наборы данных распределены одинаково (i.i.d.) и примерно имеют одинаковый размер. Ни одна из этих гипотез не предназначена для федеративного обучения; вместо этого наборы данных, как правило, неоднородны, и их размеры могут варьироваться на несколько порядков.
Более того, клиенты (узлы), участвующие в федеративном обучении, могут быть ненадежными, так как они подвержены большему количеству сбоев, из-за того, что они обычно пользуются не самыми мощными средствами связи и системами с батарейным питанием (например, смартфонами) . В распределенном обучении узлы, как правило, являются центрами обработки данных, которые обладают мощными вычислительными возможностями и соединены друг с другом быстрыми сетями.
На рисунке показан способ приватного обучения, предложенный в рассматриваемой статье.
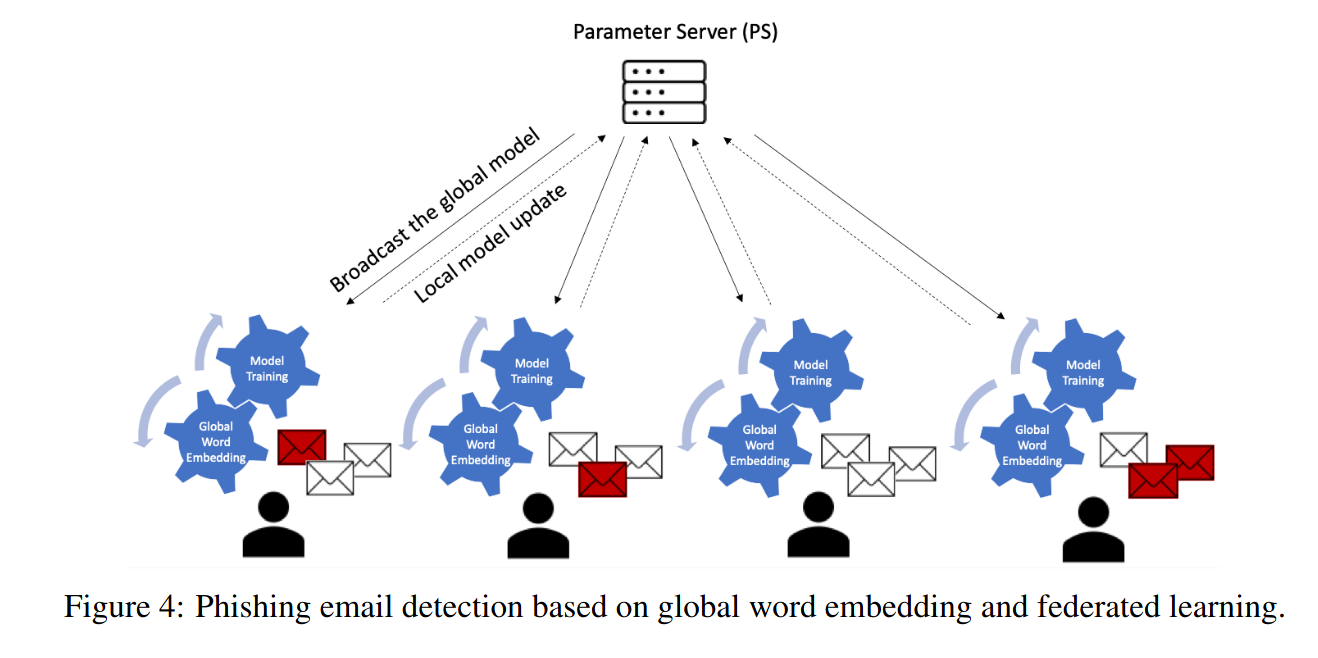
Две модели работают одновременно на сервере FPB, где одна используется для обучения, а другая - для работы в реальном времени. Для каждых нескольких итераций обучения, дообученная модель заменяет текущую модель, работающую в реальном времени. Двумя достоинствами этой архитектуры являются сохранение конфиденциальности данных, при которой оригинальные тексты в электронных письмах считаются невозможными для восстановления на основе общих весовых коэффициентов модели, и более высокая производительность модели с использованием агрегирования.
В статье предлагается сценарий с N клиентами, в котором у каждого клиента одинаковое количество хорошо сбалансированных обучающих данных. Другими словами, данные, принадлежащие каждому клиенту, независимы и одинаково распределены (IID).
Для обучения модели FPB с использованием федеративного обучения (FL) сервер параметров (PS) инициализирует глобальную модель (DL) на основе вышеупомянутых двунаправленных нейронных сетей LSTM и отправляет глобальную модель с глобальной матрицей преобразования слов в векторы всем клиентам на первом этапе обучения (см. рис.). Впоследствии, каждый раунд, PS случайным образом выбирает подмножество клиентов для обучения локальной модели, где клиент обновляет локальную модель DL на основе своих обучающих данных.
Заключение
Мы рассмотрели эффективный способ обнаружения фишинговых сообщений, приходящих на почту, который позволяет сохранить данные пользователей конфиденциальными.
Источники
vya
Сегодня фишинг, а завтра запреты Роскомнадзора? Так и до мыслепреступлений с развитием технологий дойдём.;)
janekorelskaya Автор
С развитием технологий всё развивается, в том числе и различные мошеннические операции. Хорошо бы знать, как с этим бороться современными методами. На мой взгляд, в этом плане статья довольно познавательная)