
В популярных фреймворках машинного обучения TensorFlow и PyTorch при инициализации весов нейросети используются случайные числа. В этой статье мы попытаемся разобраться, почему для этих целей не используют ноль или какую-нибудь константу.
Кто хочет быстрый и короткий ответ на этот вопрос, вот он: если инициализировать веса нулями, то нейросеть может не обучаться совсем или обучаться плохо.
Кто хочет более развёрнуто узнать, что значит «плохо», может просто перемотать к заключению в конце статьи.
А тем, кто хочет в деталях разобраться с основами обучения нейронных сетей, добро пожаловать в мир математических формул. Мы детально разберём, из-за чего в механизме обучения может произойти «сбой».
Начнём с теории
Рассмотрим однослойный перцептрон с одним выходом и активационной функцией .

Здесь –
-й вход,
– количество входов,
–
-й вес,
– смещение,
– выход. Значение выхода
равно
, где
. В целях упрощения будем считать, что смещение
реализуется как (
)-й вход со значением входа
и весом
. Тогда
.
Посмотрим, как будет работать обучение при помощи метода градиентного спуска. Пусть – правильное значение выхода для некоторого входа
. В качестве функции ошибки будем использовать среднеквадратичную ошибку (MSE):
, где
– число элементов в обучающем наборе данных. Для простоты рассмотрим случай с одним элементом в обучающей выборке, т. е.
,
.
В соответствии с методом градиентного спуска, на каждой итерации вектор весов обновляется следующим образом:
. Здесь
– вектор весов на
-м шаге обучения,
– коэффициент скорости обучения (learning rate),
– градиент функции ошибки, рассчитываемый по формуле:
Здесь – частная производная
по
. Рассчитаем её значение:
Поскольку
то , где
– величина ошибки предсказания.
Обучение перцептрона осуществляется на значениях из обучающей выборки (в нашем случае на единственном значении вектора ), поэтому значение производной
необходимо брать в точке
.
Таким образом, на каждом шаге обучения каждый вес увеличивается на величину
Посмотрим внимательно, какие величины входят в качестве множителей при расчёте величины:
– коэффициент скорости обучения,
– ошибка предсказания,
– значение производной активационной функции
в точке
,
– значение соответствующего входа на векторе из обучающей выборки.
Заметим, что в общем случае сам вес не входит в эту формулу в качестве множителя в явном виде.
Вывод. Если на некотором шаге обучения вес равен
, то это не значит, что на следующем шаге данный вес обязательно останется равным
. Он может как увеличиться, так и уменьшиться.
Теперь посмотрим, как это работает на практике
Пусть у нас имеется однослойный перцептрон с одним выходом и линейной активационной функцией
. Её производная
равна 1 для всех
. Пусть количество входов
, веса инициализированы нулями и есть обучающая выборка из одного элемента:
.
Промоделируем, как будет осуществляться обучение с коэффициентом скорости обучения .
Вспомним формулы
Шаг |
Начальное значение |
|||
1 |
(0; 0; 0) |
0 |
-42 |
(4,2; 16,8; 8,4) |
2 |
(4,2; 16,8; 8,4) |
44,1 |
2,1 |
(-0,21; -0,84; -0,42) |
3 |
(3,99; 15,96; 7,98) |
41,895 |
-0,105 |
(0,0105; 0,042; 0,021) |
4 |
(4,005; 16,002; 8,001) |
42,00525 |
0,00525 |
(-0,00053; -0,0021; -0,00105) |
5 |
(3,99998; 15,9999; 7,99995) |
41,99974 |
-0,00026 |
(0,00003; 0,00010; 0,00005) |
6 |
(4,00000; 16,00001; 8,00000) |
42,00001 |
0,00001 |
Здесь все числа приведены с точностью до 5 знаков после запятой.
Как видно, перцептрон довольно быстро пришёл к значениям весов, близких к . При
значение выхода
равно
, а величина ошибки
равна нулю.
То есть перцептрон вполне успешно обучился, стартуя с весов, инициализированных нулями. Причём, что важно, все веса получились различными.
Более сложные варианты
Рассмотрим перцептрон с несколькими выходами. В этом случае получается та же ситуация — перцептрон успешно обучается и в этом случае. Это следует из того, что перцептрон с выходами можно рассматривать как
независимых перцептронов с одним выходом. А перцептроны с одним выходом, как мы выяснили, умеют обучаться при инициализации весов нулевыми значениями.
Это справедливо как для линейной, так и для нелинейных активационных функций с ненулевыми значениями производных (,
,
,
и др.). С этими активационными функциями перцептрон успешно обучается, стартуя с нулевых весов.
Однако проблема всё-же возникает при использовании в качестве активационной функции или
с нулевым коэффициентом наклона для отрицательных чисел (negative slope). В этом случае левая производная в нуле равна нулю, а правая – не равна нулю, поэтому производная математически не определена. Однако для метода градиентного спуска некоторое значение производной активационной функции
всё же должно быть определено. И в реализациях TensorFlow и PyTorch производная
в нуле считается равной нулю. Из-за этого при инициализации весов нулями величина
для каждого веса равна нулю. Поэтому веса не изменяются, и обучения не происходит.
Но описанная выше проблема с активационной функцией может проявляться и при весах, инициализированных случайным образом, причём даже с разными знаками. Например, если веса были инициализированы как
, то на описанном выше обучающем датасете из одного элемента обучение не произойдёт, поскольку значение
отрицательно:
, производная активационной функции
при отрицательных значениях аргумента равна нулю, а нулевое значение производной активационной функции приводит к обнулению изменений весов
.
То есть при использовании обучение может не происходить как при инициализации весов нулями, так и при инициализации их случайными значениями. Следовательно, описанный выше кейс с
нельзя считать веским аргументом против инициализации весов нулями и константами. Скорее, это довод против использования
.
Так почему бы не инициализировать веса нулями, если это не мешает обучению (если не применять relu)?
Для этого рассмотрим более сложную нейронную сеть
Пусть имеется нейронная сеть состоящая из входного слоя с элементами, одного скрытого слоя с
элементами и выходного слоя с
элементами.

Введём обозначения: –
-й вход,
–
-й элемент скрытого слоя,
–
-й выход,
– активационная функция скрытого слоя,
– активационная функция выходного слоя,
– вес между
-м входом и
-м элементом скрытого слоя,
– вес между
-м элементом скрытого слоя и
-м выходом. Как и ранее, считаем, что смещения реализуются через дополнительные элементы:
,
.
Обозначим – значение
-го нейрона скрытого слоя до применения активационной функции, тогда
– значение
-го нейрона скрытого слоя после применения активационной функции. Обозначим
– значение
-го нейрона выходного слоя до применения активационной функции, тогда
– значение
-го нейрона выходного слоя после применения активационной функции.
Пусть у нас имеется обучающая выборка из одной пары векторов . В качестве функции ошибки
по-прежнему будем рассматривать среднеквадратичную ошибку (MSE). Тогда
.
Как происходит обучение многослойной нейронной сети
Для обучения нейронной сети, как и раньше, будем применять формулу , где
– вектор весов на
-м шаге обучения,
– коэффициент скорости обучения (learning rate),
– градиент функции ошибки. Отличие от однослойного перцептрона заключается в том, что частные производные
считаются по-разному для разных слоёв.
Сначала рассмотрим веса , соединяющие скрытый слой и выходной слой. Вычислим следующую вспомогательную частную производную:
Смысл этого равенства следующий. Вес , связывающий
-й элемент скрытого слоя и
-й выход, влияет только на
-й выход нейросети. На остальные выходы он не влияет. Этот факт достаточно очевиден и без применения формул.
Теперь мы можем рассчитать частную производную :
Здесь .
Таким образом, мы получили формулу, аналогичную формуле для однослойного перцептрона с одним выходом. Отличие лишь в том, что в данном случае рассматриваются сразу несколько выходов.
Следовательно, обучение весов на последнем слое многослойного перцептрона происходит по тем же правилам, как в однослойном перцептроне. Только в этом случае в качестве входного слоя для весов выступает скрытый слой нейронной сети.
Однако, несмотря на одинаковые правила, обучение нейронной сети со скрытым слоем всё же кардинально отличается от обучения однослойного перцептрона. Чтобы понять причины этого, сначала разберёмся, как рассчитываются частные производные функции ошибки по весам
соединяющим входной и скрытый слой.
Для начала вычислим вспомогательные величины:
Теперь найдём искомую производную:
Заметим, то данная формула очень похожа на формулудля величины
с той лишь разницей, что вместо производной активационной функции
выходного слоя используется производная активационной функции
скрытого слоя. Вместо значения
(значение
-го элемента скрытого слоя) используется
(значение
-го элемента входного слоя). Вместо ошибки
на
-м выходе используется следующая величина, которую можно рассматривать как сумму «обратно распространённых» ошибок:
В этом и заключается алгоритм обратного распространения ошибки. Расчёт осуществляется по слоям от выходного слоя к входному. Для каждого нейрона текущего слоя рассчитывается «ошибка». Для выходного слоя ошибка равна разности предсказанного значения и правильного значения из обучающей выборки. Для скрытых слоёв ошибка рассчитывается как взвешенная сумма ошибок на нейронах более поздних слоёв, умноженных на значения производных активационных функций и значения соответствующих весов (см. формулу ).

Теперь давайте ещё раз выпишем ключевые формулы для вычисления изменения весов при помощи алгоритма обратного распространения ошибки.
Выводы по формулам
В этом разделе формулы приведены между любыми двумя соседними слоями. Далее используются обозначения – номер нейрона на текущем слое,
– номер нейрона (на следующем слое.
При расчёте ошибки каждое слагаемое пропорционально:
– ошибке на следующем слое,
– значению производной активационной функции на следующем слое,
-
– весу соответствующей связи.

Расчёт ошибки для i-го элемента
Изменение веса пропорционально:
– ошибке на следующем слое.
– значению производной активационной функции на следующем слое,
– коэффициенту скорости обучения,
– значению
-го элемента текущего слоя.
")
Теперь мы приходим к ответу
Все веса инициализированы нулями
Допустим в начальный момент времени все веса нейронной сети инициализированы нулями. Воспользуемся формулами из предыдущего раздела. Получаем, что все значения на скрытом слое в начальный момент времени нулевые, и все выходы
нулевые, а также изменения весов
между скрытым и выходным слоем нулевые. При этом ошибка на выходе
может быть не нулевой. Но из-за того, что веса
нулевые, то ошибка
на скрытом слое по всем элементам равна нулю. Следовательно, изменения весов
равны нулю. Следовательно, никакие веса не изменяются, и обучения не происходит.
Теперь рассмотрим более общий случай
Рассмотрим ситуацию, когда веса инициализированы константой
, а веса
инициализированы константой
(возможно, совпадающей с
).
Первая итерация алгоритма:
, по условию кейса
, по условию кейса
– все значения на скрытом слое одинаковы (кроме нейрона смещения
). Это следует из п. 1.
– все выходы одинаковы (следует из пунктов 2 и 3)
– ошибки на выходном слое могут быть различными (из-за разных значений
в обучающем наборе)
– ошибки на скрытом слое одинаковы (в т. ч. и для нейрона смещения
). Это следует из пунктов 2 и 5. В формуле для расчёта величины
суммируются вообще говоря разные слагаемые. Но их сумма одинакова по всем элементам скрытого слоя.
-
– все изменения весов, ведущих к одному выходу, одинаковы, т. е.
(кроме весов, исходящих из нейрона смещения). Изменение веса
, исходящего из нейрона смещения, может отличаться от изменений остальных весов
, ведущих к тому же выходу
Изменения весов, исходящих из одного элемента скрытого слоя, могут отличаться, т.е.
и
могут отличаться. Это следует из пунктов 3 и 5.
– изменения весов, ведущих к одному элементу скрытого слоя, могут отличаться, т. е.
и
могут отличаться. Но изменения весов, исходящих из одного входа, одинаковы, т.е.
. Последнее равенство справедливо также и для входа
, использующегося для смещения. Это следует из пунктов 1 и 6.

На картинке выше одним и тем же цветом выделены одинаковые веса. Зелёным выделены веса , исходящие из входа
. Все такие веса одинаковы. Красным выделены веса
, ведущие к выходу
(за исключением веса
, исходящего из нейрона смещения
). Все такие веса одинаковы. Вес
может отличаться от остальных весов
.
Таким образом, исходное условие ,
перестаёт соблюдаться. Поэтому рассмотрим вторую итерацию алгоритма.
Вторая итерация алгоритма
– веса, исходящие из одного входа, одинаковы (в т. ч для входа смещения
) . Это результат первой итерации алгоритма.
– веса, ведущие к одному выходу (за исключением весов, исходящих из нейрона смещения
) одинаковы. Это результат первой итерации алгоритма.
– все значения на скрытом слое одинаковы (кроме нейрона смещения
). Это следует из того, что
.
– выходы могут быть различны. Это следует из того, что веса, ведущие к разным выходам, могут быть различны.
– ошибки на выходном слое могут быть различны (из-за различных значений
на выходном слое).
-
– ошибки на скрытом слое одинаковы (за исключением ошибки на нейроне смещения
). Это следует из равенства:
.
– идентично первой итерации алгоритма.
– идентично первой итерации алгоритма.
Таким образом, условие, указанное в пунктах 1 и 2, продолжает соблюдаться. И далее процесс обучения повторяется по сценарию второй итерации алгоритма.
Почему это плохо
На каждом шаге алгоритма обучения все значения нейронов скрытого слоя одинаковы (кроме нейрона смещения). Для фиксированного выхода
все веса
(кроме веса, исходящего из нейрона смещения) одинаковы.
Поэтому данная нейронная сеть будет функционировать и обучаться так же, как некоторая вырожденная нейронная сеть, в которой на скрытом слое всего один нейрон (не считая нейрона смещения). При этом веса вырожденной нейронной сети равны весам
исходной нейронной сети (включая нейрон смещения). Веса
вырожденной нейронной сети равны значениям
исходной нейронной сети (за исключением весов нейрона смещения). Веса
нейрона смещения вырожденной нейронной сети равны значениям
нейрона смещения исходной нейронной сети.
")
Интуитивно понятно, что такая вырожденная нейронная сеть обладает более узким пространством ответов, чем нейронная сеть с бóльшим числом нейронов на скрытом слое. То есть она может выдавать меньше различных комбинаций значений выходов. Это следует из того, что вектор выходных значений начинает зависеть не от
входов, а лишь от одного значения
(вектор выходных значений зависит от весов в обоих случаях, поэтому с этой точки зрения ситуации одинаковы).
Формально это можно доказать на примере задачи XOR.
Суть задачи XOR и доказательство утверждения
Необходимо с помощью нейронной сети реализовать выход функции XOR. То есть:
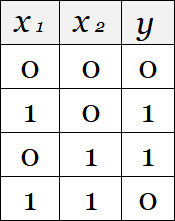
Соответственно, в данной задаче количество выходов равно 1.
Допустим также, что активационные функции должны быть неубывающими.
Если у нас нет ограничений на количество нейронов на скрытом слое, то для решения задачи XOR достаточно взять нейронную сеть, изображённую на рисунке, с нейронами на скрытом слое и с активационной функцией
на скрытом и выходном слоях. Такая нейронная сеть выдаёт на выход значения, равные значениям из описанной выше таблицы для функции XOR.

Если же количество нейронов на скрытом слое равно единице, то мы получим следующую схему:

В этом случае ,
.
Далее докажем, что такая архитектура нейронной сети не может воспроизводить значения из таблицы для функции XOR.
Предположим, что решение задачи найдено. То есть найдены веса, при которых значения выхода зависят от входов
и
, как указано в таблице.
Это означает, что при одних значениях входа значение выхода , а при других значения выхода значение выхода
. Поскольку мы предположили, что решение задачи уже найдено, т. е. веса найдены и зафиксированы, то значение выхода
зависит только от
.
Обозначим как множество значений
, при которых
. И обозначим как
множество значений
, при которых
. Отметим, что множества
и
не пересекаются, поскольку для
значение
должно было бы одновременно равняться нулю и единице.
Также отметим, что существует число , для которого:
Это следует из того, что активационная функция не убывает.
Поскольку , то обозначим как
множество значений
, при которых
. Обозначим как
множество значений
, при которых
. Отметим, что множества
и
не пересекаются, поскольку для
значение
должно одновременно принадлежать
и
, что невозможно, поскольку множества
и
не пересекаются.
Из условий задачи и свойств множеств и
получаем следующую систему:
Также отметим, что существует число , для которого:
Это следует из неравенств и того, что активационная функция
не убывает.
Рассмотрим первый случай: . Второй случай:
рассматривается аналогично.
Составим систему неравенств:
Решаем:
Сложим (1) и (4) строчки и (2) и (3). Получаем:
Однако в этом случае выход нейронной сети всегда равен одному и тому же числу
, что противоречит условиям задачи.
Таким образом, мы предположили, что нейросеть с одним нейроном на скрытом слое и неубывающими активационными функциями на скрытом и выходном слоях может воспроизвести выходные значения в соответствии с таблицей значений функции XOR. Однако мы пришли к противоречию. Следовательно, нейросеть с такой архитектурой не может моделировать значения функции XOR.
Вывод
Если веса связей между каждыми двумя последовательными слоями инициализированы некоторой константой (вообще говоря, различной для каждой пары последовательных слоёв), то пространство возможных выходных значений нейронной сети сужается по сравнению со случаем, когда все веса инициализированы различными случайными значениями.
Иными словами, нейронная сеть не сможет предсказывать то, что она могла бы предсказать при инициализации весов различными случайными значениями.
Заключение
В этой статье мы разобрали, как обучается однослойный перцептрон и нейронная сеть, состоящая из двух полносвязных слоёв (скрытого и выходного). Основной акцент был сделан на то, как влияют промежуточные значения на значения функции ошибки и в конечном итоге на изменения весов.
Мы убедились на примере, что инициализация весов нулями не мешает однослойному перцептрону обучаться. Также мы выяснили, что при инициализации весов нулями нейронная сеть со скрытым слоем теряет часть пространства возможных выходных значений, поскольку становится эквивалентна нейросети с одним нейроном на скрытом слое.
phenik
Подобная оптимизация весов синапсов происходит в биологических сетях развивающего мозга плода и в постнатальный период. Это позволяет произвести предварительную настройку важного с точки зрения выживания функционала, использовать его сразу после рождения, и более эффективно производить дальнейшее обучение в младенчестве, включая по малому числу примеров. Своеобразный период предобучения, настройки ожиданий. Его механизмы, включая генетические, исследуются см. этот комент со ссылками на некоторые источники.
AnonimYYYs
Не совсем понимаю, чем это отличается от банально двух эпох обучения одной нейронки на одной картинке?
rPman
первые слои можно инициализировать весами, скопировав их из нейронной-сети классификатор (она по уму может быть заметно меньше целевой) на основе данных входного вектора.
Fell-x27
Можно подобрать сид рандома, при котором сходимость лучше, если вы об этом. Веса не обязаны быть каждый раз новыми при каждом прогоне - тогда потеряется контроль над ситуацией. Но можно инициализировать одним и тем же случайным набором из раза в раз во время настройки.
demidovd98
Если я правильно понял вашу идею, то Вы только что изобрели fine-tuning :)
phenik
Благодарю за ответы. Идея комента состояла несколько в другом, она во втором абзаце, но чтобы понять о чем речь нужно посмотреть источники по ссылке. Эволюция решала подобную задачу для несравненно более сложного случая, чем сейчас решают специалисты по глубокому обучению для ИНС. Искала способ своеобразного «предобучения» функционала нейронных сетей растущего мозга плода, полезного, с точки зрения выживания, сразу после рождения. Например, распознавание лиц или дискриминация численности объектов, хотя бы приближенная. Однако нет возможности в геноме задать значения весов всех синапсов, как из-за их количества, так неопределенности их локализации в развивающихся сетях мозга. Эволюционное решение состояло в генерации определенной спонтанной активности направленной от формирующихся органов чувств, например, нейронов сетчатки глаз, по восходящим путям мозга к корковым отделам. Своеобразный встроенный «эмулятор реальности» в растущем мозге) Схематически это выглядит так:
Источник.
Как реализовать аналог такой схемы для предобучения ИНС, например, классификатора изображений? Действительно разными методами повторного обучения, как и предлагается в ответах. Но как проделать это без повторного обучения? Эволюция выработала схему генерации оптимальной активности самими структурами мозга, а не повторяет всю эволюционной историю для каждого нового плода. Это равносильно некоторой процедуре обработки обучающей выборки, на выходе кот. получаются оценки весов ИНС. Они присваиваются сетке, и тогда ее обучение может производиться только на подмножестве обучающей выборке. При этом результат обучения должен быть не хуже, чем для обучения на всей выборке. Но время обучения должно уменьшается. Вопрос в затратах на такую процедуру, если он невелики, то должен быть выигрыш в весьма затратных процессах обучения ИНС. Простоя идея такой процедуры состоит в сложение всех изображений из обучающей выборки и усреднения цветов пикселей, или использования другой подходящей статистики. Получившимся результирующим изображением (аналогом спонтанной активности в мозге плода) обучаем сеть, и тем самым присваиваем ей оптимальные начальные значения весов определяемые обучающей выборкой, а не случайными. Затем как обычно производится обучение на обучающей выборке меньшей по числу, чем исходной, использованной в процедуре оценки.
emidovd98Не… передрали у природы) впрочем, как и сама идея ИНС была передрана.