

Привет, Хабр! В нашей практике разработчиков электронных устройств и встраиваемых систем мы часто сталкиваемся с необходимостью хранить параметры устройства. Это могут быть, например, такие параметры как яркость дисплея, язык, рабочая частота радиоканала или IP адрес – да что угодно. Единого общепринятого подхода для решения этой задачи нет, и я предлагаю обсудить ниже наиболее очевидные варианты, их достоинства и недостатки, а также предложить реализацию, к которой я пришел в результате работы над несколькими проектами. Поехали!
Немного общей информации о ПЗУ.
Для того, чтобы хранить данные при выключенном питании люди придумали ПЗУ (постоянное запоминающее устройство). В мире Embedded зачастую используется встроенное в микроконтроллер ПЗУ либо внешнее (по отношению к процессору или микроконтроллеру) ПЗУ в виде микросхемы, подключаемой к по интерфейсам SPI или I2C. Физические особенности реализации ПЗУ в кремнии таковы, что из ПЗУ можно читать информацию быстро и по произвольным адресам, а вот для записи данных нужно ПЗУ сначала стереть. Стирать можно всю микросхему или же фрагмент. Фрагмент зависит от организации памяти внутри, это может быть сектор, страница или даже байт. Впрочем, время стирания одного байта, как правило, равняется времени стирания страницы, что наталкивает на мысль о том, что внутри все-таки стирается полностью страница, просто неявно. Вот операция стирания как раз самая долгая. Для того, чтобы программа не ждала готовности ПЗУ, придумывают разные ухищрения – кеш в ОЗУ и отложенную запись.
Предположим, у нас есть некое ПЗУ, из которого мы можем считывать информацию, записывать, и программный интерфейс которого представлен двумя функциями:
eeprom_read(uint32_t address, uint8_t *data, uint32_t count);
eeprom_write(uint32_t address, const uint8_t *data, uint32_t count);На данном этапе будем считать, что нас не волнуют особенности записи в ПЗУ и функция записи делает все, что нужно, включая стирание. Имея эти две функции, мы можем прочитать или записать произвольное количество байт по произвольному адресу. С другой стороны, есть задача хранить некие параметры в этом ПЗУ и иметь возможность работать с ними (читать / записывать). Давайте подумаем, как это можно сделать.
Вариант 1.
uint8_t param1;
uint32_t param2;
// Читаем один байт по адресу 0x00
eeprom_read(0x00, ¶m1, 1);
do_the_job1(param1);
// Читаем 32-битовое слово по адресу 0x01
eeprom_read(0x01, ¶m2, 4);
do_the_job2(param2);
// Пишем один байт по адресу 0x02
eeprom_write(0x02, (const uint8_t *)¶m1, 1);
// Пишем 32-битовое слово по адресу 0x03
eeprom_write(0x03, (const uint8_t *)¶m2, 4);Вариант, пожалуй, самый очевидный. Давайте подумаем, что здесь плохо:
Адреса захардкожены. Нужно внимательно контролировать где какой параметр лежит и сколько он занимает байт. При большом количестве параметров очень трудно не допустить ошибку.
Для исправления адресов нужно искать обращения к ПЗУ по коду всего проекта
Информация, хранящаяся в ПЗУ, неструктурирована
Отсутствует контроль перекрытия адресов. Можно невозбранно записать байт в середину 4-байтового числа
Нет контроля ошибок. Валидность записываемых данных никак не проверяется
Сериализация / десериализация многобайтовых данных возлагается на компилятор и зависит от endianness вычислительной платформы
В общем случае код непереносим на другую платформу
Ну а что же хорошего?
Самый простой и быстрый способ.
Самая эффективная реализация сериализации / десериализации данных – благодаря компилятору.
Такой подход годится, если у вас 1-2 переменные в коде. Ладно, я пошутил, так, скорее всего, никто писать не будет. Даже самый начинающий программист быстро поймет, что лучше бы адреса определить где-нибудь в виде набора макроопределений. Вот так:
Вариант 2.
#define PARAM1_ADDR 0x00
#define PARAM2_ADDR 0x01
#define PARAM3_ADDR 0x05Ну и коде вместо магического числа будет красоваться чуть более осмысленное выражение:
eeprom_read(PARAM2_ADDR, ¶m2, 4);Можно еще размер параметров в байтах аналогично объявить. Что это нам дает по сравнению с первым вариантом:
Адреса переменных и их размер сосредоточены в одном месте, их теперь проще редактировать
Меньше магических чисел
Но в целом все те же недостатки. А что если все данные объединить в структуру? Например, такую:
Вариант 3.
#define STRUCT_PARAM_ADDR 0x00
struct myParamStruct {
uint8_t param1;
uint32_t param2;
char param3[10];
} paramSet;
// Читаем
eeprom_read(STRUCT_PARAM_ADDR, (uint8_t *)¶mSet, sizeof(paramSet));
do_the_job1(¶mSet);
// Пишем
eeprom_write(STRUCT_PARAM_ADDR, (const uint8_t *)¶mSet, sizeof(paramSet));
// Используем считанный параметр
setVolume(paramSet.param1);
paramSet.param2 = getLevel();
Уже лучше. Что хорошего нам дает объединение данных в структуру:
Лаконичность. Одной строчкой мы записываем или считываем множество данных
Сохраняется эффективность сериализации / десериализации, унаследованная от первого варианта
Весьма простая реализация
Появляется возможность очень лихо мультиплицировать однотипные параметры (достаточно объявить в структуре массив элементов, при этом сами элементы уже могут быть достаточно сложными)
Контроль за адресами параметров теперь возложен на компилятор. Нам только остается определить адрес в ПЗУ, по которому располагается структура и ее размер, если мы планируем что-то еще хранить там же
Недостатки:
При модификации одного поля требуется перезаписать полностью все данные
Увеличенное время работы с ПЗУ. Недостаток усугубляется, если параметров много
По-прежнему нет никакого контроля ошибок. Требуется вручную проверять все поля на допустимость значений
Давайте подумаем, что здесь можно улучшить. Во-первых, логично держать параметры в ОЗУ, считывая их при запуске и записывая при выключении устройства или по какому-нибудь событию. Во-вторых, можно добавить контроль целостности для всех параметров, вычисляя CRC16 или CRC32 побайтно и записывая в ту же ПЗУ.
Вариант 4.
#define STRUCT_PARAM_ADDR 0x00
#define CRC32_ADDR 0x100
struct myParamStruct {
uint8_t param1;
uint32_t param2;
char param3[10];
} paramSet;
uint32_t crc32;
// Проверка на перекрытие адресов
#if (STRUCT_PARAM_ADDR + sizeof(paramSet)) > CRC32_ADDR
#error Size of struct myParamStruct is too big!
#endif
// Читаем
eeprom_read(STRUCT_PARAM_ADDR, (uint8_t *)¶mSet, sizeof(paramSet));
eeprom_read(CRC32_ADDR , (uint8_t *)&crc32, sizeof(crc32));
if (get_сrc32(¶mSet, sizeof(paramSet)) != crc32)
{
// TODO Обработать ошибку целостности параметров
}
do_the_job1(¶mSet);
// Пишем
eeprom_write(STRUCT_PARAM_ADDR, (const uint8_t *)¶mSet, sizeof(paramSet));
crc32 = get_сrc32(¶mSet, sizeof(paramSet));
eeprom_write(CRC32_ADDR, (uint8_t *)&crc32, sizeof(crc32));
Что общего у всех перечисленных вариантов:
Работа с ПЗУ ведется непосредственно из кода приложения. При необходимости заменить названия функций или целиком модуль работы с ПЗУ, требуется довольно бесполезная правка application кода
Много информационного шума. Названия функций доступа к ПЗУ, адреса и размеры переменных, приведения типов – все это лишняя информация, который мешает сосредоточиться на функциональном коде
Требуется отдельная явная проверка записываемых и считанных данных на валидность
Затруднен доступ к параметрам через внешний интерфейс. Если нужно считывать или записывать отдельный параметр, в протоколе обмена с внешним миром придется так или иначе дублировать описание структуру вашего набора параметров. Ну или гонять по интерфейсу полный набор байт – сериализованное представление нашей структуры с параметрами
В целом все вышеперечисленные варианты вполне приемлемы, если количество параметров относительно невелико. Это правда, если у вас простая программа, которую не предполагается переносить на другой МК или менять компилятор, лучше не усложнять. Но что делать, если код ответственный, параметров много, и их организация сложнее чем просто массив? Давайте подумаем, что хотелось бы от идеального решения (в чем-то перекликается с принципами ООП, да):
Изолированность от железа. Программный модуль не должен включать в себя функции работы с ПЗУ
Переносимость. Модуль должен одинаково работать на микроконтроллере и ПК в каком-нибудь Qt Creator
Изолированность внутренней реализации. Для работы с модулем должен быть определен интерфейс из набора функций
Возможность сложной организации данных. Возможность объединения параметров в группы, создание массивов групп в произвольном виде
Автоматическое распределение памяти ПЗУ для хранения переменных
Отсутствие избыточности при хранении данных. Упаковка в памяти должна быть плотной – если параметр состоит из 3 байт, он и в ПЗУ должен занимать 3 байта
Удобный API для передачи параметров через коммуникационные интерфейсы
Возможность хранения разных типов данных. Целые числа, числа с плавающей запятой, строки + возможность расширения новыми типами данных
контроль целостности данных
контроль валидности данных
наличие callback при изменении параметра
детерминированное время доступа к параметру
язык С для применения в чисто C проектах
Итак, переходим к самому интересному. Определим основные постулаты реализации:
В основе модуля лежит древовидная структура дескрипторов и линейный массив байт, на который дескрипторы ссылаются
В дереве существуют терминальные и нетерминальные узлы
Терминальные узлы дерева описывают некий параметр. Описание состоит из адреса сериализованного представления в ОЗУ, указателей на функцию – обработчик запросов, значений по-умолчанию, минимального и максимального значения и других данных. Определим полный набор описания позже
Нетерминальные узлы описывают терминальные и нетерминальные узлы, находящиеся ниже по иерархии (входящие в данный узел)
Доступ к параметрам осуществляется путем перехода по ветвям дерева, при этом ветвь определяется индексом на текущем уровне иерархии
Данные хранятся в ОЗУ в сериализованном виде. При чтении данные десериализуются в значение нужного типа. При записи – сериализуются
В принципе все. На этом списке статью можно было бы на этом закончить. Но давайте посмотрим в деталях, как это можно реализовать.
Перечислим типы узлов:
// Node type
typedef enum {
sNode, // Simple (terminating) node
hNode, // Hierarchy node
lNode, // List node
} nodeType;
sNode – (сокр. Simple node) это терминальный узел. hNode (hierarchy node) – узел, включающий в себя узлы разных типов (структура). lNode – узел, включающий в себя узлы одного типа (массив). Имея эти три типа, мы можем описать сколь угодно сложное дерево. Проиллюстрируем на примере (буквенно-цифровые обозначения нужны только для пояснения, но они же будут использованы в примере для пущей ясности):
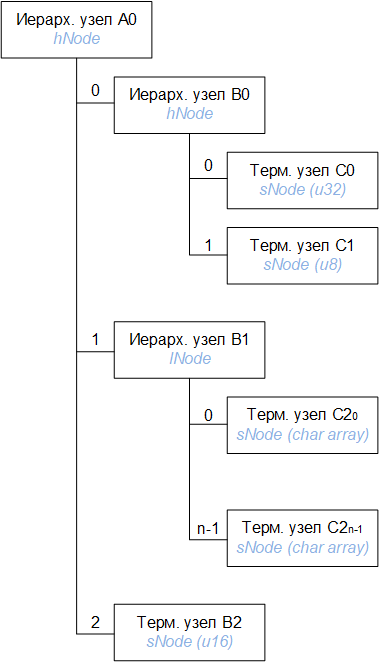
Это простое дерево, описывающее несколько терминальных узлов и переходы к ним. Дерево начинается с корневого узла А0, на следующем уровне иерархии содержит три узла – B0, B1 и B2. Из них B2 – терминальный узел, остальные содержат вложенные узлы внутри себя. B0 – промежуточный узел иерархии, B1 – тоже промежуточный, но содержащий массив однотипных элементов внутри. Узлы C – терминальные. Например, если мы хотим обратиться к узлу C25, нужно выбрать последовательность переходов (1, 5), начиная от корня. Вроде не rocket science, едем дальше.
Итак, узлами дерева у нас являются дескрипторы. Определим общий для всех дескрипторов набор полей:
#define GENERIC_NODE_PATTERN nodeType type; \
uint32_t ramOffset; /* Used by hNode for fast indexed access */ \
uint32_t romOffset;
// Generic node descriptor
struct node_t {
GENERIC_NODE_PATTERN
};
У любого узла есть тип, а также смещение в ОЗУ и в ПЗУ. Это смещение мы руками задавать не будем, иначе теряется весь смысл. Оно будет вычисляться один раз при инициализации.
Описание узла иерархии (hNode):
// Hierarchy node descriptor
struct hNode_t {
// Common
GENERIC_NODE_PATTERN
// Custom
uint16_t hListSize; // Child list size
struct node_t **hList; // List of child node descriptors
};
В hNode входят общие для всех узлов поля (совершенно верно, такое вот «наследование» в С), размер списка вложенных узлов и указатель на список. Заранее количества вложенных узлов мы не знаем, поэтому оставим просто указатель.
Ну и массив lNode:
// List node descriptor
struct lNode_t {
// Common
GENERIC_NODE_PATTERN
// Custom
uint16_t hListSize; // Count of child elements (all elements are equal)
struct node_t *element; // Child node descriptor (since all are equal, single descriptor is used)
uint32_t elementRamSize;
uint32_t elementRomSize;
};
Здесь мы указываем размер массива, дескриптор вложенных элементов (они все одного типа, поэтому нужен только один дескриптор), размер элементов в ОЗУ и в ПЗУ. Тут нужно пояснить, зачем нужны отдельные смещения для ОЗУ и ПЗУ. Дело в том, что встречаются параметры, которые должны существовать, но их не нужно хранить в ПЗУ. Простейший (хотя, возможно, и не самый удачный) пример – версия ПО. На такие элементы расходовать драгоценное ПЗУ мы не будем. Прежде чем перейти к дескриптору sNode, давайте еще определим, как у нас будут описываться свойства параметров, в зависимости от их типа. Сделаем это для целых чисел и строк. При желании этот список можно будет расширить.
struct u32Prm_t {
uint32_t defaultValue;
uint32_t minValue;
uint32_t maxValue;
};
struct charArrayPrm_t {
const char *defaultValue;
};
Для целых у нас есть значение по-умолчанию, минимальное и максимальное значения. Для строк и того меньше – только значение по-умолчанию.
Итак, дескриптор параметра:
// Simple (terminating) node descriptor
struct sNode_t {
// Common
GENERIC_NODE_PATTERN
// Custom
uint32_t size;
uint8_t accessLevel;
storageType storage;
onChangeCallback changeCallback;
requestHandler rqHandler;
union {
struct u32Prm_t u32Prm;
struct charArrayPrm_t charArrayPrm; // not 0-terminated
} varData;
};
У любого параметра есть его размер в байтах (size), признак хранения (хранится он в ПЗУ или нет), callback на изменение, обработчик запросов, а также специфичные для типа данные. Кроме того, есть еще указатель уровня доступа – пользователь / разработчик / whatever. Пригодится для защиты от несанкционированного изменения. Ну и само собой тип и смещение в ОЗУ / ПЗУ.
Хорошо, с этим тоже вроде все понятно. Из этих дескрипторов мы выстроим дерево и напишем функцию обработки запроса, которая будет принимать в качестве аргументов список индексов для переходов, а также тип запроса – чтение / запись / верификация, права доступа и, собственно данные. Эта функция будет передвигаться по дереву, начиная с корня, пока не дойдет до терминального узла, а затем вызовет его обработчик запроса, который тоже будем задавать при конструировании дерева. Обработчик выполнит нужные действия и вернет результат выполнения операции. Сейчас нужно понять, как хранить данные в ОЗУ (помним, что они лежат в сериализованном виде) и как связать их с дескрипторами (задать те самые смещения). С sNode все просто – есть уже готовый адрес, по которому и лежат данные - бери и используй. Вернее, не совсем так. Когда функция обработки запроса доходит до терминального узла, у нее должен появиться корректный адрес. Вот для его получения и должен быть определен алгоритм. А как быть с hNode и lNode? Нужно еще обеспечить целостность параметров… После некоторого размышления я пришел к такой форме:
Целостность обеспечивается контрольной суммой CRC16, которая вычисляется для hNode или lNode по всем терминальным узлам, входящим в него (и только по ним – вложенные узлы не используются в расчете CRC для данного узла). CRC16 кажется разумным выбором, но ничто не мешает использовать CRC32 или сумму Флетчера или другой тип контрольной суммы.
Для hNode или lNode в ОЗУ хранятся два байта CRC16, а затем все данные всех терминальных узлов на данном уровне иерархии, пусть даже они описаны в дереве с промежутками.
Все иерархические узлы, входящие в данный hNode, хранятся аналогично, но уже на своем уровне.
Смещение для всех узлов вычисляется при инициализации дерева. Потребуется функция, которая обойдет все дерево и всем узлам задаст смещение. Потом, при обработке запроса, мы будем переходить по узлам и просто суммировать все смещения, получая в итоге нужный адрес.
Изобразим карту памяти для дерева выше:

В первый уровень иерархии дерева входят узлы B0, B1 и B2. Из них B0 и B1 пропускаем, потому что они нетерминальные. Значит, для первого уровня записываем только данные узла B2. А дальше по порядку анализируем узлы B0 и B1 и действуем аналогично. Проходя таким образом все дерево, получаем карту памяти (смещения) для всех узлов дерева. Эти смещения мы записываем в соответствующие поля дескрипторов чтобы иметь их под рукой при обращении к параметрам. Алгоритм достаточно прост, поэтому блок-схему приводить не буду. Сразу код.
Функция инициализации
resultType initNode(node_t *node, uint32_t *ramSize, uint32_t *romSize, nodeInitContext_t *ctx)
{
hNode_t *hnode;
lNode_t *lnode;
sNode_t *snode;
uint16_t i;
uint32_t ramOffset = 0;
uint32_t romOffset = 0;
uint32_t nodeRamSize, nodeRomSize;
ctx->depth++;
if (ctx->depth > ctx->maxDepth)
{
ctx->maxDepth = ctx->depth;
if (ctx->maxDepth > ctx->maxAllowedDepth)
{
SETTINGS_ASSERT_NEVER_EXECUTE();
*ramSize = 0;
*romSize = 0;
return Result_DepthExceeded;
}
}
switch (node->type)
{
case hNode:
hnode = (hNode_t *)node;
// First few bytes are used by CRC
ramOffset += NODE_CRC_SIZE;
romOffset += NODE_CRC_SIZE;
// Init terminating nodes
for (i=0; i<hnode->hListSize; i++)
{
#if ERROR_ON_UNITIALIZED_NODE == 1
SETTINGS_ASSERT_TRUE(hnode->hList[i]);
#else
if (hnode->hList[i] == 0)
continue;
#endif
if (hnode->hList[i]->type == sNode)
{
initNode(hnode->hList[i], &nodeRamSize, &nodeRomSize, ctx);
hnode->hList[i]->ramOffset = ramOffset;
hnode->hList[i]->romOffset = romOffset;
ramOffset += nodeRamSize;
romOffset += nodeRomSize;
}
}
// Here ROM offset may be page-aligned for hierarchy nodes if necessary
// Init hierarchy nodes
for (i=0; i<hnode->hListSize; i++)
{
if (hnode->hList[i] == 0)
continue;
if ((hnode->hList[i]->type == hNode) || (hnode->hList[i]->type == lNode))
{
initNode(hnode->hList[i], &nodeRamSize, &nodeRomSize, ctx);
hnode->hList[i]->ramOffset = ramOffset;
hnode->hList[i]->romOffset = romOffset;
// Here ROM offset may be page-aligned for hierarchy nodes if necessary
ramOffset += nodeRamSize;
romOffset += nodeRomSize;
}
}
// Return used amount of RAM and ROM
*ramSize = ramOffset;
*romSize = romOffset;
break;
case lNode:
lnode = (lNode_t *)node;
// First few bytes are used by CRC
ramOffset += NODE_CRC_SIZE;
romOffset += NODE_CRC_SIZE;
initNode(lnode->element, &nodeRamSize, &nodeRomSize, ctx);
lnode->element->ramOffset = ramOffset;
lnode->element->romOffset = romOffset;
lnode->elementRamSize = nodeRamSize;
lnode->elementRomSize = nodeRomSize;
// Here ROM offset may be page-aligned for hierarchy nodes if necessary
ramOffset += nodeRamSize * lnode->hListSize;
romOffset += nodeRomSize * lnode->hListSize;
// Return used amount of RAM and ROM
*ramSize = ramOffset;
*romSize = romOffset;
break;
case sNode:
snode = (sNode_t *)node;
// Return used amount of RAM and ROM
*ramSize = snode->size;
*romSize = (snode->storage == RomStored) ? snode->size : 0;
break;
default:
SETTINGS_ASSERT_NEVER_EXECUTE();
break;
}
ctx->depth--;
return Result_OK;
}
Функция рекурсивная, для ограничения глубины (читай, количества вложенных вызовов) в случае, если что пошло не так, а также подсчета максимальной глубины дерева в качестве параметра передается структура:
// Node init context data
struct nodeInitContext_t {
uint32_t depth; // Current depth for a node
uint32_t maxDepth; // Maximum depth for whole tree
uint32_t maxAllowedDepth; // Maximum alowed depth (if maxDepth esceeds this value, error is generated)
};
При вызове из основной программы в качестве узла передается дескриптор корневого узла дерева (в нашем примере это дескриптор узла А0), указатели на переменные смещения ОЗУ и ПЗУ (да, можно было бы их упаковать в nodeInitContext_t, но так уж сложилось) и собственно контекст инициализации. Например:
nodeInitContext_t ctx;
// Create RAM and ROM map for the whole tree
ctx.depth = 0;
ctx.maxDepth = 0;
ctx.maxAllowedDepth = 10;
// InitNode is first initialization stage, it does not actualy use RAM or ROM, only tree structure is created
initNode((node_t *)hRoot, &ramSize, &romSize, &ctx);
SETTINGS_ASSERT_TRUE(ramSize <= SETTINGS_RAM_SIZE);
hRoot->ramOffset = 0; // Start address for RAM
hRoot->romOffset = 0; // Start address for ROM
SETTINGS_DEBUG("Settings total RAM: %d, ROM %d bytes, depth %d\n", ramSize, romSize, ctx.maxDepth);
После вызова этой функции карта памяти размечена, мы можем легко узнать адрес сериализованного представления каждого параметра и можем приступать к валидации данных. Для валидации мы снова пробегаем по дереву, для каждого терминального узла вызываем его обработчик с командой восстановить и проверить данные (здесь идет массовое чтение данных из ПЗУ). Если все данные узлов в hNode валидны, в заключение проверяется контрольная сумма. Если она совпадает, то все хорошо, считаем, что параметры для конкретной hNode валидны. Если нет, записываем рассчитанную контрольную сумму в ПЗУ вместо старой. Кроме того, может понадобиться сбросить все параметры на значения по-умолчанию. Тогда принудительно всем параметрам задаем значение по-умолчанию и обновляем контрольную сумму. Функция валидации также вызывается рекурсивно.
Функция валидации
resultType validateNode(node_t *node, uint32_t nodeRamBase, uint32_t nodeRomBase, uint8_t useDefaults)
{
hNode_t *hnode;
lNode_t *lnode;
sNode_t *snode;
uint16_t i;
uint32_t ramAddr, romAddr;
resultType result, nodeResult, snodeResult;
resultType crcCheckResult;
switch (node->type)
{
case hNode:
hnode = (hNode_t *)node;
result = Result_OK;
snodeResult = Result_OK;
// Run through all nodes, check if values are valid
for (i=0; i<hnode->hListSize; i++)
{
#if ERROR_ON_UNITIALIZED_NODE == 1
SETTINGS_ASSERT_TRUE(hnode->hList[i]);
#else
if (hnode->hList[i] == 0)
continue;
#endif
pushArg(argHistory, SETTINGS_MAX_DEPTH, i);
ramAddr = nodeRamBase + hnode->hList[i]->ramOffset;
romAddr = nodeRomBase + hnode->hList[i]->romOffset;
nodeResult = validateNode(hnode->hList[i], ramAddr, romAddr, useDefaults);
popArg(argHistory, SETTINGS_MAX_DEPTH);
if (hnode->hList[i]->type == sNode)
snodeResult = (resultType)(snodeResult | nodeResult);
else
result = (resultType)(result | nodeResult);
}
if (useDefaults)
{
// All nodes have been restored already. Update hnode CRC
updateNodeCRC((node_t *)hnode, nodeRamBase, nodeRomBase);
result = (resultType)(result | Result_UpdatedRom);
}
else
{
if (snodeResult == Result_OK)
{
// All snodes are valid. Restore and check hnode CRC
readRom(nodeRamBase, nodeRomBase, NODE_CRC_SIZE);
crcCheckResult = checkNodeCRC((node_t *)hnode, nodeRamBase);
}
if ((snodeResult != Result_OK) || (crcCheckResult != Result_OK))
{
// Run through snodes again, force defaults
for (i=0; i<hnode->hListSize; i++)
{
if (hnode->hList[i]->type != sNode)
continue;
pushArg(argHistory, SETTINGS_MAX_DEPTH, i);
ramAddr = nodeRamBase + hnode->hList[i]->ramOffset;
romAddr = nodeRomBase + hnode->hList[i]->romOffset;
nodeResult = validateNode(hnode->hList[i], ramAddr, romAddr, 1);
popArg(argHistory, SETTINGS_MAX_DEPTH);
}
// Update hnode CRC
updateNodeCRC((node_t *)hnode, nodeRamBase, nodeRomBase);
result = (resultType)(result | Result_UpdatedRom);
}
}
break;
case lNode:
lnode = (lNode_t *)node;
result = Result_OK;
snodeResult = Result_OK;
// Run through all nodes, check if values are valid
for (i=0; i<lnode->hListSize; i++)
{
// Here ROM offset may be page-aligned for hierarchy nodes if necessary
pushArg(argHistory, SETTINGS_MAX_DEPTH, i);
ramAddr = nodeRamBase + lnode->element->ramOffset + (lnode->elementRamSize * i);
romAddr = nodeRomBase + lnode->element->romOffset + (lnode->elementRomSize * i);
nodeResult = validateNode(lnode->element, ramAddr, romAddr, useDefaults);
popArg(argHistory, SETTINGS_MAX_DEPTH);
if (lnode->element->type == sNode)
snodeResult = (resultType)(snodeResult | nodeResult);
else
result = (resultType)(result | nodeResult);
}
if (useDefaults)
{
// All nodes have been restored already. Update lnode CRC
updateNodeCRC((node_t *)lnode, nodeRamBase, nodeRomBase);
result = (resultType)(result | Result_UpdatedRom);
}
else
{
if (snodeResult == Result_OK)
{
// All snodes are valid. Restore and check lnode CRC
readRom(nodeRamBase, nodeRomBase, NODE_CRC_SIZE);
crcCheckResult = checkNodeCRC((node_t *)lnode, nodeRamBase);
}
if ((snodeResult != Result_OK) || (crcCheckResult != Result_OK))
{
for (i=0; i<lnode->hListSize; i++)
{
if (lnode->element->type != sNode)
break;
// Here ROM offset may be page-aligned for hierarchy nodes if necessary
pushArg(argHistory, SETTINGS_MAX_DEPTH, i);
ramAddr = nodeRamBase + lnode->element->ramOffset + (lnode->elementRamSize * i);
romAddr = nodeRomBase + lnode->element->romOffset + (lnode->elementRomSize * i);
nodeResult = validateNode(lnode->element, ramAddr, romAddr, 1);
popArg(argHistory, SETTINGS_MAX_DEPTH);
}
// Update hnode CRC
updateNodeCRC((node_t *)lnode, nodeRamBase, nodeRomBase);
result = (resultType)(result | Result_UpdatedRom);
}
}
break;
case sNode:
snode = (sNode_t *)node;
SETTINGS_ASSERT_TRUE(snode->rqHandler != 0);
result = snode->rqHandler((useDefaults) ? rqRestoreDefault : rqRestoreValidate, snode, nodeRamBase, nodeRomBase, 0);
break;
default:
SETTINGS_ASSERT_NEVER_EXECUTE();
result = Result_UnknownNodeType;
break;
}
return result;
}
Вызывать мы ее будем вот так:
// Validate values and check CRC
result = validateNode((node_t *)hRoot, hRoot->ramOffset, hRoot->romOffset, useDefaults);
SETTINGS_DEBUG("Validate result 0x%02X %s\n", result, (result & Result_UpdatedRom) ? "(defaults restored)" : "");
Здесь еще нужно обратить внимание вот на что. Мы говорим, что у нас есть callback-функции, которые вызываются при выполнении запроса, например, записи нового значения. Может случиться так, что удобно будет использовать одну callback функцию для нескольких терминальных узлов, например, массива. Но этой функции может потребоваться знать, с каким именно параметром она имеет дело и какое значение было записано. Я решил не мелочиться и записывать все индексы при переходе по дереву в отдельный массив argHistory, а значение в union callbackCache. Callback знает для какого параметра его вызвали и может правильно привести тип callbackCache.
Итак, с деревом и внутренней структурой более-менее все. Приведу два обработчика для определенных нами в начале типов – целого 32-битового числа и строк.
Обработчик для 32-битных целых чисел
validateResult validateU32(uint32_t value, struct u32Prm_t *prm)
{
return ((prm->minValue <= value) && (value <= prm->maxValue)) ? ValidateOk : ValidateErr;
}
resultType handleRequestU32(rqType rq, struct sNode_t *pNode, uint32_t nodeRamBase, uint32_t nodeRomBase, request_t *rqst)
{
resultType result = Result_OK;
uint32_t val32;
uint32_t *pVal32;
//SETTINGS_DEBUG("U32 node rq %d, node size %d, ram %d, rom %d", rq, pNode->size, nodeRamBase, nodeRomBase);
switch (rq)
{
case rqRead:
if (rqst->raw)
{
memcpy(rqst->raw, &ram[nodeRamBase], pNode->size);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
bytesToU32MsbFirst(&ram[nodeRamBase], &val32, pNode->size);
*pVal32 = val32;
}
break;
case rqApplyNoCb:
case rqApply:
case rqStore:
case rqWriteNoCb:
case rqWrite:
if (rqst->raw)
{
// Serialize to validate
bytesToU32MsbFirst(rqst->raw, &val32, pNode->size);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
val32 = *pVal32;
}
if (rq & rqApply)
{
if (validateU32(val32, &pNode->varData.u32Prm) == ValidateOk)
{
u32toBytesMsbFirst(&val32, &ram[nodeRamBase], pNode->size);
// Request arguments may be provided by GetRequestArg() if required by callback
// New value may be directly obtained using GetCallbackCache() if required by callback
callbackCache.i32 = val32;
if (pNode->changeCallback)
pNode->changeCallback(rq, argHistory[0]);
}
else
{
#if ERROR_ON_VALIDATE_FAILED == 1
SETTINGS_ASSERT_NEVER_EXECUTE();
#endif
result = Result_ValidateError;
break;
}
}
if (rq & rqStore)
{
if (pNode->storage == RomStored)
{
writeRom(nodeRomBase, nodeRamBase, pNode->size);
result = (resultType)(result | Result_UpdatedRom);
}
}
break;
case rqValidate:
if (rqst->raw)
{
// Serialize to validate
bytesToU32MsbFirst(rqst->raw, &val32, pNode->size);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
val32 = *pVal32;
}
result = (validateU32(*pVal32, &pNode->varData.u32Prm) == ValidateOk) ? Result_OK : Result_ValidateError;
break;
case rqGetMin:
if (rqst->raw)
{
u32toBytesMsbFirst(&pNode->varData.u32Prm.minValue, rqst->raw, pNode->size);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
*pVal32 = pNode->varData.u32Prm.minValue;
}
break;
case rqGetMax:
if (rqst->raw)
{
u32toBytesMsbFirst(&pNode->varData.u32Prm.maxValue, rqst->raw, pNode->size);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
*pVal32 = pNode->varData.u32Prm.maxValue;
}
break;
case rqGetSize:
if (rqst->raw)
{
u32toBytesMsbFirst(&pNode->size, rqst->raw, 4);
}
else
{
pVal32 = (uint32_t *)rqst->val.i32;
*pVal32 = pNode->size;
}
break;
case rqRestoreValidate:
if (pNode->storage == RomStored)
{
readRom(nodeRamBase, nodeRomBase, pNode->size);
bytesToU32MsbFirst(&ram[nodeRamBase], &val32, pNode->size);
result = (validateU32(val32, &pNode->varData.u32Prm) == ValidateOk) ? Result_OK : Result_ValidateError;
}
else
{
val32 = pNode->varData.u32Prm.defaultValue;
u32toBytesMsbFirst(&val32, &ram[nodeRamBase], pNode->size);
}
break;
case rqRestoreDefault:
val32 = pNode->varData.u32Prm.defaultValue;
u32toBytesMsbFirst(&val32, &ram[nodeRamBase], pNode->size);
if (pNode->storage == RomStored)
{
writeRom(nodeRomBase, nodeRamBase, pNode->size);
result = (resultType)(result | Result_UpdatedRom);
}
break;
default:
result = Result_WrongRequestType;
break;
}
return result;
}
И для строк:
Обработчик для строк
resultType handleRequestCharArray(rqType rq, struct sNode_t *pNode, uint32_t nodeRamBase, uint32_t nodeRomBase, request_t *rqst)
{
resultType result = Result_OK;
//SETTINGS_DEBUG("Char node rq %d, node size %d, ram %d, rom %d", rq, pNode->size, nodeRamBase, nodeRomBase);
switch (rq)
{
case rqRead:
memcpy(rqst->raw, &ram[nodeRamBase], pNode->size);
break;
case rqApplyNoCb:
case rqApply:
case rqStore:
case rqWriteNoCb:
case rqWrite:
if (rq & rqApply)
{
if (rqst->raw != 0)
{
memcpy(&ram[nodeRamBase], rqst->raw, pNode->size);
// Request arguments may be provided by GetRequestArg() if required by callback
// New value may be directly obtained using GetCallbackCache() if required by callback
callbackCache.str = (char *)rqst->raw;
// Request arguments may be provided by GetRequestArg() if required by callback
if (pNode->changeCallback)
pNode->changeCallback(rq, argHistory[0]);
}
else
{
#if ERROR_ON_VALIDATE_FAILED == 1
SETTINGS_ASSERT_NEVER_EXECUTE();
#endif
result = Result_ValidateError;
break;
}
}
if (rq & rqStore)
{
if (pNode->storage == RomStored)
{
writeRom(nodeRomBase, nodeRamBase, pNode->size);
result = (resultType)(result | Result_UpdatedRom);
}
}
break;
case rqValidate:
// Char arrays are assumed to be correct
// If validate is required for specific case, custom request handler should be used
result = (rqst->raw != 0) ? Result_OK : Result_ValidateError;
break;
case rqGetMin:
case rqGetMax:
SETTINGS_ASSERT_NEVER_EXECUTE();
result = Result_WrongRequestType;
break;
case rqGetSize:
if (rqst->raw)
{
u32toBytesMsbFirst(&pNode->size, rqst->raw, 4);
}
else
{
uint32_t *pVal32 = (uint32_t *)rqst->val.i32;
*pVal32 = pNode->size;
}
break;
case rqRestoreValidate:
if (pNode->storage == RomStored)
{
readRom(nodeRamBase, nodeRomBase, pNode->size);
}
else
{
if (pNode->varData.charArrayPrm.defaultValue)
memcpy(&ram[nodeRamBase], pNode->varData.charArrayPrm.defaultValue, pNode->size);
else
memset(&ram[nodeRamBase], 0, pNode->size);
}
break;
case rqRestoreDefault:
if (pNode->varData.charArrayPrm.defaultValue)
memcpy(&ram[nodeRamBase], pNode->varData.charArrayPrm.defaultValue, pNode->size);
else
memset(&ram[nodeRamBase], 0, pNode->size);
if (pNode->storage == RomStored)
{
writeRom(nodeRomBase, nodeRamBase, pNode->size);
result = (resultType)(result | Result_UpdatedRom);
}
break;
default:
result = Result_WrongRequestType;
break;
}
return result;
}
Определены следующие типы запросов (не фантазия, продиктованы требованиями одного из проектов):
// Request type
typedef enum {
rqRead = 0x00,
rqApplyNoCb = 0x01,
rqApply = 0x03, // Update cache only
rqStore = 0x04, // Write to ROM only
rqWriteNoCb = (rqStore | rqApplyNoCb),
rqWrite = (rqStore | rqApply),
rqValidate = 0x08,
rqGetMin = 0x10,
rqGetMax = 0x20,
rqGetSize = 0x40,
rqRestoreValidate = 0xFE,
rqRestoreDefault = 0xFF
} rqType;
В общем случае параметр можно прочитать, получить его максимальное и минимальное значения, получить размер в байтах, проверить на валидность. Также можно записать (в ОЗУ и ПЗУ), применить (только в ОЗУ), записать или применить без вызова callback или записать только в ПЗУ. Как мы ранее говорили, доступ к модулю осуществляется через функцию, обрабатывающую запрос. Сам запрос определен как структура:
// Request data structure
typedef struct {
rqType rq;
accessLevel accLevel;
uint32_t arg[SETTINGS_MAX_DEPTH];
union {
int32_t *i32;
} val;
uint8_t *raw; // Raw serialized data. If set to non-zero, data must be read or written in raw serialized form
// Char arrays always use raw form.
resultType result; // Returned request result
} request_t;
При обращении к модулю мы указываем тип запроса, перечисляем индексы для доступа к параметру и говорим, нужно ли нам сериализованное представление или десериализованное. Последнее позволяет легко передавать параметры через интерфейсы связи. Сама функция обработки запроса довольно тривиальна:
Функция обработки запроса
resultType settingsRequest(request_t *rqst)
{
node_t *pNode = (node_t *)hRoot;
hNode_t *nnode = 0;
lNode_t *lnode = 0;
node_t *pHostNode = (node_t *)hRoot; // Should be updated before use
uint32_t hostNodeRamOffset = hRoot->ramOffset; // Should be updated before use
uint32_t hostNodeRomOffset = hRoot->romOffset; // Should be updated before use
uint32_t currArg, argIndex = 0;
uint32_t ramOffset = hRoot->ramOffset;
uint32_t romOffset = hRoot->romOffset;
resultType result = Result_OK;
// Move through the node tree according to the argument list
while(pNode->type != sNode)
{
if (argIndex >= SETTINGS_MAX_DEPTH - 1)
{
result = Result_DepthExceeded;
break;
}
currArg = rqst->arg[argIndex++];
pushArg(argHistory, SETTINGS_MAX_DEPTH, currArg);
switch(pNode->type)
{
case hNode:
pHostNode = pNode; // Save hNode for CRC update if required by sNode request handler
hostNodeRamOffset = ramOffset; // Save RAM address
hostNodeRomOffset = romOffset; // Save ROM address
nnode = (hNode_t *)pNode;
SETTINGS_ASSERT_TRUE(currArg < nnode->hListSize);
SETTINGS_ASSERT_TRUE(nnode->hList);
pNode = nnode->hList[currArg];
SETTINGS_ASSERT_TRUE(pNode);
ramOffset += pNode->ramOffset;
romOffset += pNode->romOffset;
break;
case lNode:
pHostNode = pNode; // Save lNode for CRC update if required by sNode request handler
hostNodeRamOffset = ramOffset; // Save RAM address
hostNodeRomOffset = romOffset; // Save ROM address
lnode = (lNode_t *)pNode;
SETTINGS_ASSERT_TRUE(currArg < lnode->hListSize);
pNode = lnode->element;
SETTINGS_ASSERT_TRUE(pNode);
ramOffset += lnode->element->ramOffset + lnode->elementRamSize * currArg;
romOffset += lnode->element->romOffset + lnode->elementRomSize * currArg;
break;
default:
SETTINGS_ASSERT_NEVER_EXECUTE();
result = Result_UnknownNodeType;
break;
}
}
if (result == Result_OK)
{
// Terminating node is found
SETTINGS_ASSERT_TRUE(((sNode_t *)pNode)->rqHandler);
result = ((sNode_t *)pNode)->rqHandler(rqst->rq, (sNode_t *)pNode, ramOffset, romOffset, rqst);
if (result & Result_UpdatedRom)
{
// Hide ROM flag
result = (resultType)(result & ~Result_UpdatedRom);
updateNodeCRC(pHostNode, hostNodeRamOffset, hostNodeRomOffset);
}
}
rqst->result = result;
return result;
}
По сути, в ней мы переходим по элементам массива, вычисляем элементарным сложением смещение параметра, выполняем различные параноидальные и не очень проверки и в конце концов доходим до терминального узла и вызываем его обработчик запроса. Все просто :)
Ладно, давай уже как этим пользоваться…
Перед использованием нужно сконструировать это самое дерево дескрипторов. В начале я написал несколько функций, с помощью которых удобно создавать дескрипторы. Типа такой:
sNode_t *u32Node(uint8_t accessLevel, storageType storage,
uint32_t minValue, uint32_t maxValue, uint32_t defaultValue,
onChangeCallback changeCallback)
{
sNode_t *node = createSNode(4);
node->rqHandler = handleRequestU32;
node->accessLevel = accessLevel;
node->storage = storage;
node->changeCallback = changeCallback;
node->varData.u32Prm.defaultValue = defaultValue;
node->varData.u32Prm.minValue = minValue;
node->varData.u32Prm.maxValue = maxValue;
return node;
}
А sNode создавалась при помощи вот этого:
sNode_t *createSNode(uint16_t size)
{
sNode_t *snode = (sNode_t *)SETTINGS_ALLOCATE(sizeof(sNode_t));
SETTINGS_ASSERT_TRUE(snode != 0);
snode->type = sNode;
snode->size = size;
return snode;
}
SETTINGS_ALLOCATE можно определить в заголовочном файле как обычный malloc или же чуть сэкономить на дескрипторах и воспользоваться незатейливым менеджером памяти, который умеет только выделять – кто же не хочет изобрести свой велосипед менеджер памяти:
void *settingsAlloc(uint32_t size)
{
void *pRam = &allocRam[allocRamAddr];
uint32_t nextAddr = allocRamAddr + size;
if (nextAddr <= allocRamSize)
{
// OK
allocRamAddr = nextAddr;
memset(pRam, 0, size);
}
else
{
// Out of memory
pRam = 0;
}
return pRam;
}
Все эти функции нужны чтобы легко и непринужденно создавать описание дерева параметров в таком духе:
hNode_B0 = createHNode(2);
addToHList(hNode_B0, 0, u32Node ( AccessByAll, RomStored, 0, 100000, 12345, onB0ParamsChanged)); // C0
addToHList(hNode_B0, 1, u32Node ( AccessByAll, RomStored, 0, 144, 5, onB0ParamsChanged)); // C1
lNode_B1 = createLNode(35, charNode ( AccessByAll, RomStored, C2_SIZE, dfltC2, onC2ParamsChanged)); // C2
hRoot = createHNode(3); // A0
addToHList(hRoot, 0, hNode_B0);
addToHList(hRoot, 1, lNode_B1);
addToHList(hRoot, 2, u16Node ( AccessByAll, NotRomStored, 1, 1024, 16, 0)); // B2
И все бы ничего, но эти рюшечки могут съесть довольно значимый кусок памяти (и таки съели в одном проекте, где с памятью совсем плохо), так что я их вынес под условную компиляцию ENABLE_NODE_CONSTRUCTORS и запасся вместо них такого рода макроопределениями:
#define u32Node(accs, stor, min, max, dflt, callback) \
{.type = sNode, .ramOffset = 0, .romOffset = 0, .size = 4, .accessLevel = accs, .storage = stor, .changeCallback = callback, .rqHandler = handleRequestU32, \
.varData.u32Prm = {.defaultValue = dflt, .minValue = min, .maxValue = max}}
и
#define charNode(accs, stor, sz, dflt, callback) \
{.type = sNode, .ramOffset = 0, .romOffset = 0, .size = sz, .accessLevel = accs, .storage = stor, .changeCallback = callback, .rqHandler = handleRequestCharArray, \
.varData.charArrayPrm = {.defaultValue = dflt}}
Давайте посмотрим, как будет выглядеть описание дерева параметров для нашего примера выше (пусть у нас будет C2_NODES_COUNT штук узлов C2), определенное с помощью этих макросов:
// Integer node: Access type Storage type Minimum Maximum Default Callback
// b0param_C0
static sNode_t node_C0 = u32Node ( AccessByAll, RomStored, 0, 100000, 12345, onB0ParamsChanged );
// b0param_C1
static sNode_t node_C1 = u8Node ( AccessByAll, RomStored, 0, 144, 5, onB0ParamsChanged );
// root
static node_t *hNodes_B0[b0param_Count] = {(node_t *)&node_C0, (node_t *)&node_C1};
static hNode_t hNode_B0 = hNode(hNodes_B0);
// b1param_C2i
// Char node: Access type Storage type Size Default Callback
static sNode_t node_C2 = charNode ( AccessByAll, RomStored, C2_SIZE, dfltC2, onC2ParamsChanged );
static lNode_t lNode_B1 = lNode(C2_NODES_COUNT, (node_t *)&node_C2);
// Integer node: Access type Storage type Minimum Maximum Default Callback
static sNode_t node_B2 = u16Node ( AccessByAll, NotRomStored, 1, 1024, 16, 0 );
// Root (A0)
static node_t *hNodes_A0[pGroup_Count] = {(node_t *)&hNode_B0, (node_t *)&lNode_B1, (node_t *)&node_B2};
static hNode_t hNode_A0 = hNode(hNodes_A0);
hNode_t *hRoot = &hNode_A0;
Не очень лакончино, но что поделать - такой вариант самый экономный.
Как обращаться из кода.
Допустим, нам нужно получить значение параметра С0. Мы должны сделать следующее:
request_t rq;
int32_t val32 = 0;
rq.rq = rqRead;
rq.arg[0] = 0; // 0 = B0
rq.arg[1] = 0; // 0 = C0
rq.val.i32 = &val32;
rq.raw = 0;
settingsRequest(&rq);
if (rq.result == Result_OK)
{
do_the_job(val32);
}
Запись 12-го элемента из массива элементов C2:
request_t rq;
int32_t value = 87; // new value
rq.rq = rqWrite;
rq.arg[0] = 1; // B1
rq.arg[1] = 12; // C2[12]
rq.val.i32 = &value;
rq.raw = 0;
settingsRequest(&rq);
if (rq.result == Result_OK)
{
do_the_job();
}
Проверка допустимости значения элемента B2:
request_t rq;
int32_t val32 = 235; // Value being checked
rq.rq = rqValidate;
rq.arg[0] = 2; // 2 = B2
rq.pval.i32 = &val32;
SettingsRequest(&rq);
if (rq.result == Result_OK)
{
do_the_job();
}
else if (rq.result == Result_ValidateError)
{
handle_error();
}
Длинно? Длинно. Тут есть простор для фантазии. Можно написать функцию – обработчик запросов с неопределенным количеством аргументов, или с++ обертку с предопределенным количеством аргументов со значениями по-умолчанию. В одном из проектов максимальная глубина дерева параметров была равна 4 и я использовал такую функцию:
settings_WriteI32_4(pGroup_Sensor, pSensorTempRef, i, 1, 4, (int32_t)temp);Возвращаемся к началу. Стратегии работы с ПЗУ.
Cреди прочих требований указано отсутствие привязки к ПЗУ. Действительно так и есть. Я намеренно сделал возможность работы без внешнего драйвера - если определен NOROM, то вызовы внешних функций и вовсе имитируются функциями-заглушками. Это позволяет, в том числе, отлаживать и тестировать модуля на ПК. В реальном проекте, конечно, нужно реализовать чтение / запись ПЗУ. Как именно это сделать, зависит от проекта. В одном случае это может быть простое блокирующееся обращение непосредственно к драйверу ПЗУ, в другом – сложный механизм в отдельном потоке ОСРВ с возможностью отложенной записи. Естественно, в исходном виде модуль не является потокобезопасным, так что, если нужно обращаться к нему из разных задач, нужно реализовать защиту разделяемого ресурса.
Плюсы и минусы.
Ну что же, вроде все поставленные цели достигнуты. Давайте, однако, будем справедливы и отметим, чем может быть плох или неудобен получившийся программный модуль:
Накладные расходы. Все-таки, хотя вычислительная сложность при обращении к параметру стремится к О(n) (где n – это глубина дерева), все-таки они есть. Ну что же, неизбежная расплата.
Несколько перегруженный интерфейс для обращения (нужно заполнить поля структуры). Решается введением удобных функций – оберток.
Определенные ограничения на алгоритм работы с ПЗУ. Модуль никак не учитывает особенности работы ПЗУ, перечисленные в начале статьи. Например, ПЗУ может уметь стирать только сектор, понадобится теневое копирование всего сектора. Но это есть следствие разделения обязанностей модулей. Вопрос на будущую проработку.
В данном опусе я рассказал об одной из проблем разработки встраиваемого программного обеспечения и поделился интересным на мой взгляд способом решения. Естественно, я не могу предоставить боевой проект, в котором используется этот алгоритм, а также опустил кое-какие детали реализации. Но вот ссылка, где вы найдете файлы с исходным кодом, пригодные для сборки, запуска и экспериментов. Пишите в комментариях, как вы храните параметры устройств.
Спасибо за внимание!
Комментарии (12)

AKudinov
03.12.2021 11:20+2Мне кажется, вот это вот момент:
держать параметры в ОЗУ, считывая их при запуске и записывая при выключении устройства или по какому-нибудь событию
таит в себе огромную опасность. А что, если питание внезапно выключили? А что, если питание выключили посреди записи структуры?
Кажется, что в структуре нужно добавить полеcount, и когда возникает необходимость записать структуру, наращиватьcountи записывать структуру рядом. При чтении считывать все доступные целые структуры, и выбирать экземпляр с максимальным (по соответствующему модулю, конечно(count. Естественно, не забывать стирать их по кругу, оставляя, например, 3 экземпляра в памяти.
Но вот как решать проблему с тем, что при изменении одного параметра надо всю структуру переписать (изнашивая память), остаётся вопросом.
TheNavi
03.12.2021 12:30Для этого есть целый гайдлайны от производителей микроконтроллеров. И там обычно описывается варианты rotating записи в EEPROM. И сделано это вполне из осознанных вещей. У большинства EEPROM на рынке, плюс-минус количество гарантированных циклов перезаписи ячеек порядка 100000. Есть правда и high endurance варианты - но ценник выше. И этого может быть как много - так и мало, в зависимости от приложения (может оно раз в месяц будет обновлять ячейку,) а вот если обновлять раз в секунду - то пичалька наступит быстро - через примерно 28 часов работы устройства . А если EEPROM вшит в кристалл контроллера - ну как то будет жалко. Поэтому существуют множество вариантов как работать с EEPROM - как минимум используя кольцевую запись структур данных, создавая rotating EEPROM библиотеки, типа таких https://tinkerman.cat/post/eeprom-rotation-for-esp8266-and-esp32. Ну и плюсом будет, целосность данных - при частичной записи последний записаный вариант будет поврежден и будет взят предыдущий.

Polaris99
03.12.2021 17:54+1Достаточно иметь две копии, обе одновременно повредить при записи невозможно.


Tsvetik
03.12.2021 12:14Вариант 10
Использовать easyflash, или flashDB https://github.com/armink/EasyFlash
Вариант 11
Использовать FatFs от Чана


IronHead
03.12.2021 13:03+1Обычно в проектах на МК использую вариант:
#define SETTING_ADDR 0xROMADDRESS #define SETTING_KEY 0xRANDOMKEY struct myParamStruct { uint32_t key; size_t size; struct param_pam_pam; uint32_t crc; } paramSet; settings_read(¶m_pam_pam); serrings_write(param_pam_pam);В функции settings_read происходит чтение памяти по указанному адресу хранения настроек, после чего вычитывается размер записанных данных, этот размер сравнивается с sizeof(param_pam_pam) если равен — то сверяем CRC и если все проверки пройдены — выгружаем себе в работу param_pam_pam.
Если что то пошло не так, например размер или CRC не сходится — грузим дефолтные настройки в param_pam_pam и вызываем serrings_write(param_pam_pam);
В param_pam_pam можем так же делать структуры из структур.
Даже школьник разберется
IbhSvenssen
03.12.2021 18:49Аналогично делаю, только пишу в память два одинаковых блока, и при чтении проверяю оба, если один из них повреждён, то восстанавливаю из целого. Если оба повреждены, тогда уже дефолтные гружу.

Indemsys
03.12.2021 16:05В противовес иерархической структуре можно использовать плоскую таблицу с парой полей parent - child.
Да, проход по таблице займёт больше тактов чем по ветвям дерева. Но разница в этих расхода несущественны при количестве параметров в районе сотен. Но при этом сильно упростится автогенерация сорсов с таблицей параметров.
Вообще кардинальное решение - не писать вручную организацию и объявление параметров в исходниках. Тогда совершенно не будет важно представлены они деревом или простой структурой.
Параметры удобно создавать в специализированной утилите с GUI на PC. После чего утилита автоматически генерирует исходники для объявления, управления и представления параметров.При чем ведь надо ещё помнить что параметры часто должны быть доступны для просмотра и редактирования из различных интерфейсов: через терминал, через WEB, через IoT протоколы типа MQTT... И тогда приходит идея хранить все в JSON, как самом гибком для структур данных. А потом этот формат транслировать в структуру на С для доступа из программы, и в чистом виде пересылать, если надо сделать WEB интерфейс.
Сам JSON в сжатом виде хранить во Flash микроконтроллера. Для этого даже специальная файловая система придуманаДля количества данных в тысячи и более уникальных записей применяют уже настоящие базы данных типа SQLite и полнофункциональную файловую систему FAT32 на uSD карте или eMMC чипе. Где-то видел портированную версию SQLite под STM32. Но не могу вспомнить где.

amarkevich
04.12.2021 00:04Целостность обеспечивается контрольной суммой
можно разделить реализацию настроек от подсистемы хранения, как например сделано в Zephyr Settings: есть некая абстракция для работы непосредственно с деревом настроек, а за целостность отвечает слой хранения.
lamerok
Спасибо за статью, идея хорошая, не могли бы пояснить, зачем вообще иметь древовидную структуру хранения параметров? Почему например нельзя просто сделать параметры индивидуальные и обращаться к ним по имени?
Если надо по индексу к ним обращаться то можно запихать их в список, ну типа такого.
Можно сделать несколько таких списков и делать ссылку друг на друга
Но это правда на С++, зато там нет никаких указателей.
Если что описание параметра будет выглядеть как то так:
Начальное значение тут нужно для того, чтобы задать что-то в случае, если при считывании параметра будет ошибка контрольной суммы.
Ссылка на драйвер - можно подсовывать любой, который будет работать хоть с со страничной, хоть с обычной, хоть с ОЗУ и памятью программ. Он и будет обеспечивать особенности работы разных ПЗУ.