
 Привет, меня зовут Макс Матюхин, я PHP-программист в компании Badoo. В прошлом месяце в Лондоне прошла очередная Международная конференция разработчиков QCon 2015. Я побывал на ней и теперь хочу поделиться с вами своими впечатлениями о мероприятии и рассказать о самых интересных, на мой взгляд, выступлениях. Из этой статьи вы узнаете чуть больше про архитектуру Uber, Spotify, CloudFlare, а также о том, как Google управляет своей инфраструктурой и многом другом.
Привет, меня зовут Макс Матюхин, я PHP-программист в компании Badoo. В прошлом месяце в Лондоне прошла очередная Международная конференция разработчиков QCon 2015. Я побывал на ней и теперь хочу поделиться с вами своими впечатлениями о мероприятии и рассказать о самых интересных, на мой взгляд, выступлениях. Из этой статьи вы узнаете чуть больше про архитектуру Uber, Spotify, CloudFlare, а также о том, как Google управляет своей инфраструктурой и многом другом.Впервые QCon состоялась в 2007 году в Лондоне и Сан-Франциско. С тех пор она стабильно набирает популярность и расширяет географию, и в этом году она пройдет в 8 городах. Лондонская QCon проходит в самом сердце британской столицы, в двух шагах от Вестминстерского Аббатства. В разное время на QCon выступали такие известные личности, как Martin Fowler, Kent Beck, Erik Meijer, Steve Vinoski, Joe Armstrong, Rich Hickey и многие другие.
В этом году конференция длилась 3 дня, каждый день проводилось 5-7 одновременных секций. Почти все доклады снимались на видео и потом были доступны всем участникам конференции. В течение 6 месяцев эти записи будут выложены в открытый доступ на сайт infoq.com.
Одной из отличительных черт QCon являются так называемые open spaces. В каждой секции в определённое время проходит open space, куда может прийти любой желающий и задать вопросы другим участникам по теме секции или предложить обсуждение какого-либо вопроса в ее рамках.
Что касается докладов, то расскажу я только о тех, которые видел вживую и которые мне действительно понравились. Я опишу их в хронологическом порядке и намеренно не буду раскрывать всех деталей, чтобы вам было интересно смотреть и видео.
Доклады. День #1
To the Moon
Открывал конференцию Russ Olsen, вице-президент компании Cognitect, с докладом «To the Moon».
Это даже был не доклад, а просто интересная история о том, как американцы летали на Луну. Во время холодной войны русские добились впечатляющих достижений в космосе: запустили первый спутник, отправили первого человека в космос, сделали первую фотографию обратной стороны Луны. И все ждали ответа от Америки. Через какое-то время Джон Кеннеди выступил перед конгрессом США с планом высадки человека на Луну и возвращении его домой в целости и сохранности.
Далее автор рассказал о том, как американцы работали над этой программой, о самом процессе высадки на Луну, о возникших проблемах. Далее речь шла о работе над ошибками, о причинах возникновения каждой из проблем, которые могли не только сорвать выполнение задачи, но и угрожали жизни экипажа.
Получился неплохой мотивационный доклад о том, что невозможного не существует.
Видео данного доклада уже доступно: http://www.infoq.com/presentations/moon-software
Treat your Code as a Crime Scene (Adam Tornhill)
В описании доклада говорится, что у автора имеется образование и в области психологии, и в программировании, поэтому он применяет некоторые подходы традиционной и судебной психологии, чтобы найти проблемные места в коде. Автор утверждает, что программирование может взять многое из психологии, потому что оно включает в себя не только написание кода, но и людей, которые принимают решения, исправляют ошибки, общаются друг с другом.
Большую часть времени программисты не пишут код, а изучают уже существующий и вносят в него изменения, поэтому им следует заботиться о том, чтобы их код был прост для понимания.
Далее, после некоторого ликбеза о поведении преступников, автор перешел к описанию утилиты CodeCity http://www.inf.usi.ch/phd/wettel/codecity.html. Эта программа визуализирует ваш код в виде виртуального города, в котором каждый модуль или класс является зданием. Чем сложнее класс, тем больше здание. Но сложность кода сама по себе — не проблема. До тех пор, пока вам не понадобится этот код менять. Поэтому, если на результаты CodeCity наложить частоту изменения каждого модуля, то мы сможем увидеть сложные модули, которые нам приходится часто менять. Рефакторинг именно этих модулей является наиболее целесообразным.
Другая интересная техника анализа кода называется Temporal Coupling Analysis. Представьте, что у вас есть 2 модуля, которые между собой явно не связаны. Но если посмотреть историю их коммитов, то можно увидеть, что очень часто они изменяются вместе. Если модули действительно не связаны между собой, то такое поведение может говорить о наличии copy-paste-кода в обоих модулях.
Не буду полностью пересказывать доклад — лучше его один раз увидеть. В целом автор высказывает интересные, хотя и очевидные идеи. В большинстве случаев он просто анализирует различные статистические показатели кода и истории коммитов и затем правильно визуализирует полученную статистику.
A Taste of Random Decision Forests on Apache Spark (Sean Owen)
Слайды
Доклад представляет из себя короткий семинар по использованию алгоритмов машинного обучения на платформе Apache Spark.
Я шел на этот доклад, чтобы послушать про Spark, и в этом плане доклад меня разочаровал. Про Spark в докладе была буквально пара примеров: чтение набора данных и использование MLLib для построения Decision Tree и Random Decision Tree — базовые вещи. Но для тех, кто только делает первые шаги в Machine Learning и хочет получить хороший пример, как использовать Spark и MLLib для задач классификации, доклад будет довольно полезным.
Автор взял вот этот набор данных https://archive.ics.uci.edu/ml/datasets/Covertype, который содержит данные об участках в лесах Колорадо (30 м? каждый): наклон, высота над уровнем моря, тип почвы, тип лесного покрова и т.д.
Имея эти данные, автор сначала построил дерево принятия решений (Decision Tree), которое училось бы определять тип лесного покрова по основным параметрам — это типичная задача классификации в машинном обучении (Machine Learning). Затем автор постоянно вносил изменения в построенное дерево принятия решений, чтобы улучшить качество классификации (точность, с которой классификатор по переданным параметрам определяет тип лесного покрова).
В какой-то момент автор перешел от алгоритма Decision Tree к алгоритму Random decision forests, который на его данных дал лучшие результаты.
Доклад может быть полезен начинающим как простой пример того, как работают современные специалисты по Data Science. Хотя, на мой взгляд, автор забыл рассказать о проблеме переобучения (Overfitting).
Beating the traffic jam using embedded devices, OPC-UA, Akka and NoSQL (Kristoffer Dyrkorn)
Слайды
Автор работает на государственное учреждение в Норвегии, которое занимается планированием, строительством, эксплуатацией и ремонтом дорог. Задача его проекта — собирать статистику о дорожном трафике и пробках в Норвегии в реальном времени.
Строительство и эксплуатация дорог в Норвегии — это очень дорого. Например, в 2013 году на дороги было потрачено 4,1 миллиарда евро. Виной тому суровый норвежский климат, обработка дорог солью зимой, морские волны и даже птичий помет. И, конечно же, сам дорожный трафик.
Система состоит из множества (более 5000) датчиков, стоящих на дорогах. Они собирают информацию о проезжающих автомобилях, сохраняют ее на локальный диск и отправляют на центральный сервер, используя 3G. Количество датчиков постоянно растет, соответственно, растет и объем хранимых данных, и нагрузка на сервер.
Несмотря на то, что 3G считается надежной технологией, датчики довольно часто теряют связь с сервером, поэтому система написана с учетом возможных сетевых проблем. Есть также возможность с сервера запросить все данные с датчика.
Серверная часть написана на Java. Основная его задача — принимать данные с датчиков. Также есть REST API для GUI, через который можно управлять системой и добавлять новые датчики. Предусмотрена система отчетов.
Для удобства и гибкости все данные хранятся в сыром формате, без предварительного агрегирования. На данный момент система только «обкатывается» и никто пока не знает, какие именно отчеты смогут понадобиться. Система работает в трех дата-центрах.
Авторы проекта используют ElasticSearch как основное хранилище данных. Знают, что так не советуют делать, читали результаты Jepsen-теста по ElasticSearch и знают, что он может терять данные в случае, если происходит netsplit, но реально данные еще не теряли.
Позже автора доклада спросили, почему он уверен, что они не теряли данные. На это он ответил, что каждый датчик, отсылая новое событие, отсылает новый ID с auto_increment-ом, и вроде бы при проверке они не нашли промежутков с утерянными ID.
Эволюция архитектуры:
1. Переход с Play на Embedded Jetty + Akka.
2. Переход с MongoDB на ElasticSearch.
3. Переход от одного датацентра к трем.
В целом доклад получился очень грамотный; впечатляет размах проекта и то, сколько Норвегия тратит на дороги.
Очень хотелось больше подробностей про Akka, но автор лишь сказал, что они очень довольны его внедрением, без каких либо подробностей.
Доклады. День #2
Cluster management at Google (John Wilkes)
Слайды
Доклад начался с вопроса: «Есть ли в зале люди, которые пользовались хотя бы одним сервисом Google?» :)
Автор доклада работает в Infrastructure Team. Задача этой команды состоит в том, чтобы предоставить возможность программистам Google запускать свои приложения дата-центрах Google.
На скриншоте ниже показана конфигурация для запуска простенького приложения в дата-центре Google:

Здесь стоит уточнить что в Google кластер серверов называют cell, и размер типичного такого кластера — около 10 000 серверов. Итого в данном примере автор запускает 10 000 копий приложения hello_world в cell=ic с указанием, сколько памяти, диска и CPU он собирается использовать.
Простое приложение Hello, world! после сборки будет занимать примерно 75 мегабайт. Потому что оно автоматически включает в себя веб-сервер, систему для сбора отладочной информации и многое другое.
После написания вышеприведенного конфигурационного файла и запуска специальной утилиты приложение будет собрано, выложено на указанный кластер и запущено.
Все это в Google может сделать сам программист, без привлечения администраторов или релиз-инженеров.
Несмотря на то, что мы запросили 10 000 копий, обычно запускается немного меньше. Это происходит из-за поломок серверов и плановых технических работ. И это нормально. Приложения в Google изначально рассчитаны на то, что часть серверов будут недоступны. Поэтому в Google при обсуждении технических вопросов прежде всего обсуждают, что делать в случае «падения» того или иного сервиса, а производительность имеет более низкий приоритет чем масштабируемость.
Когда приложение начинает работать стабильно, они приступают к изучению его производительности. Собирается очень много статистики о производительности веб-приложений и ищутся способы утилизировать ресурсы каждого физического сервера на полную мощность. То есть если сервер в Google не использует все свои ресурсы — это тоже плохо.
В Google проводят много экспериментов, нацеленных на то, чтобы нагрузка на сервера распределялась более плотно.
Например, на одном сервере они запускают как обычные веб-приложения, так и обычные background-задачи, типа map-reduce задач. И это очень сильно повысило эффективность использования их серверов.
Также они собрали статистику, сколько ресурсов приложение требует (см. пример «конфига» для Hello, world!) и сколько ресурсов оно реально использует. И обнаружилось, что программисты почти всегда запрашивают больше ресурсов, чем им надо. Поэтому было решено запускать на одном сервере больше приложений, тем самым еще больше увеличив эффективность использования ресурсов
Google очень активно используют Linux-контейнеры, которые обеспечивают изоляцию ресурсов и изоляцию выполнения. Каждую неделю в Google запускается около двух миллиардов контейнеров. Все приложения запускаются внутри контейнера. Для управления кластером Linux-контейнеров Google использует свою внутреннюю разработку, написанную на Go и выпущенную в OpenSource http://kubernetes.io/.
Доклад получился очень интересным. Многие его детали я намеренно упустил и рекомендую его полностью посмотреть.
CloudFlare's fourth year of using Go (John Graham-Cumming)
Слайды
CloudFlare — это сервис, который фактически является reverse-proxy между пользователем и сайтом. Суть в том, что у CloudFlare дата-центры раскиданы по всему миру, и когда пользователь заходит на сайт их клиента, то на самом деле он попадает на ближайший дата-центр СloudFlare. И уже CloudFlare занимается доставкой контента этому пользователю. В дополнение к основной задаче доставки контента они также предоставляют другие услуги, такие как защита от DDoS, анализ трафика на попытки взлома, поддержка протоколов, которые не поддерживаются сайтом клиента (например, SPDY), кеширование и прочее.
Сначала CloudFlare использовал PHP, nginx и модули на Cи, C++. Но постепенно они заменили PHP и C++ на GO, PHP оставили только для показа сайта. А модули nginx переписали на LuaJIT, но некоторые nginx-модули на Си всё еще остались.
На вопрос, как докладчику удалось убедить CloudFlare начать использовать GO, автор ответил, что соврал начальству, а в самый последний момент сообщил, что программу он написал на языке GO.
Первый проект на GO была штука под названием railgun. Суть в том что CloudFlare нужно часто между дата-центрами передавать какие-то html-страницы. Они посчитали и поняли, что если взять 2 разные страницы с одного сайта, сделать между ними diff и передать только diff, то получается быстрее, чем передавать целую страницу. Таким образом, они между дата-центрами просто передают diff-ы, и тем самым очень сильно ускорив доставку контента.
Также на GO они написали:
- свой DNS сервер с поддержкой DNS Proxying и DNSSEC;
- TLS / SSL / PKI toolkit;
- систему для пересжатия картинок (их система смотрит, какие дата-центры в данный момент времени не нагружены, и запускает пересжатие картинок на этих дата-центрах);
- агрегирование и анализ логов (используют https://capnproto.org/ для сериализации данных. Анализ логов в частности используется для определения распределенных атак);
- разные задачи, которые запускаются через cron.
Основные проблемы с GO:
- сборка мусора;
- управление внешними зависимостями; для себя они эту проблему решили тем, что вручную указывают версию используемой библиотеки.
В целом они очень довольны GO, для их задач он идеально подходит
Building Functional Infrastructure with Mirage OS (Anil Madhavapeddy)
Слайды
Если кто читал про Еrlang on Xen, то Mirage OS — то же самое, только на OCaml.
Суть в том что Mirage OS позволяет на OCaml создавать так называемые unikernels — специально подготовленные образы виртуальных машин для гипервизора Xen. Разница между unikernels и контейнером типа Docker в том, что в unikernels включаются только те возможности OS, которые реально нужны, и такие образы стартуют очень быстро. Например, если приложение в unikernels не работает с файлами, то файловая система попросту не будет включена в образ unikernels. Благодаря этому unikernels имеют маленький размер (иногда всего несколько мегабайт) и повышенную безопасность, т. к. содержат в себе только необходимое для приложения.
Безопасность также повышается за счет тех гарантий, которые дает OCaml как язык. Благодаря размеру и скорости работы unikernels могут работать на небольших дешевых устройствах. По тем же причинам на современных серверах можно запускать десятки тысяч unikernels.
Доклад получился живым, интересным, с множеством примеров. Жаль только, что Mirage OS, скорее всего, не взлетит.
Доклады. День #3
Scaling Uber's Realtime Market Platform (Matt Ranney)
Слайды
На QCon London 2015 Uber впервые рассказали о своей архитектуре. В докладе была описана масса технических нюансов. Чтобы понимать, какие проблемы приходится решать в Uber, нужно немного понимать их бизнес и то, с кем они взаимодействуют.
Поведение поставщиков услуг (водителей) очень непредсказуемое, потому что они вольны делать то, что им пожелается. Они могут прервать свою работу в любой момент. Некоторые из них могут работать всего несколько часов в сутки. Клиенты (пассажиры) также непредсказуемы в своих потребностях. Еще нужно учитывать, что если сервис Uber недоступен, клиенты не будут ждать, пока он заработает — они просто позвонят в другую службу такси. Поэтому для Uber любое падение — это потеря денег.
Система, которая подбирает водителей для пассажиров и планирует маршрут, в Uber называется Dispatch System, и именно про эту часть Uber и был доклад.
У них используется 4 разных языка на backend-е: Node.js, Python, Java, GO. Dispatch System почти вся написана на Node.js. Очень большая часть бизнес-логики выделена в отдельные сервисы.
Также у них используются различные базы данных: PostgreSQL, Redis, MySQL, Riak.
Dispatch System совсем недавно был полностью переписан. Автор знаком со статьей Joel Spolsky «Things you should never do», но у них в коде было много проблем, которые их ограничивали:
- В коде подразумевалось, что один водитель везет одного пассажира — это ограничивало их в возможности экспериментировать.
- В коде подразумевалось, что водитель всегда везет человека — это ограничивало их в возможности выходить на смежные рынки грузоперевозок.
- Система «шардилась» по городу — были проблемы с производительностью в больших городах.
Все это ограничивало рост Uber, поэтому они проигнорировали совет Джоэла и полностью переписали эту схему.
В новой системе они сделали отдельный гео-индекс поставщиков услуг (водителей), отдельный гео-индекс потребителей и систему, которая вычисляет маршруты и пытается определить, где водитель окажется в будущем. Эта система не просто определяет физическое расстояние между клиентами, а может определить ситуацию, когда 2 объекта физически находятся недалеко друг от друга, но между ними есть, например, канал.
Для аэропортов была разработана специальная логика, т. к. зачастую такси там формируют очереди, и Uber симулирует подобную очередь у себя в системе.
Система ориентирована на уменьшение времени ожидания и уменьшение времени в дороге.
Они активно используют библиотеку https://code.google.com/p/s2-geometry-library/ для географических расчетов. Кроме всего прочего, эта библиотека позволяет разбить поверхность земли на ромбы с разным уровнем масштабирования. Фактически она позволяет представить любой квадратный сантиметр Земли в виде int64.

В этой системе вся поверхность земли разбита на клетки уровнем Level12, каждая такая клетка имеет свой ID и используется как ключ для шардинга.
Большая часть системы написана на Node.js. Поверх Node.js они написала свою библиотеку https://github.com/uber/ringpop. Эта библиотека позволяет расшардить сервис, написанный на Node.js, на несколько серверов. Также она позволяет работать прозрачно с удаленным процессом, как если бы он находился на локальном сервере. Автор признался, что они постепенно добавляют все особенности Erlang в Node.js.
Эта библиотека использует протокол Gossip и в терминах CAP является AP-системой.
Как Uber пишет систему, чтобы гарантировать доступность?
- Любую команду можно послать повторно. Если что-то не сработало, должна быть возможность попробовать выполнить эту команду еще раз.
- Любой процесс (и даже база данных) может быть убит в любое время. Приложение должно быть к этому готово.
- Аварийная остановка процесса используется как стандартный способ выключить что-то. Если система умеет справляться с этим, нет смысла тратить время на реализацию «плавного выключения».
- Вся система разбивается на маленькие части. Благодаря этому убийство отдельных процессов не повлияет на глобальный трафик.
Для снижения временных задержек, т. е. когда какой-то из сервисов тормозит, используется техника backup request with cross-server cancelation.
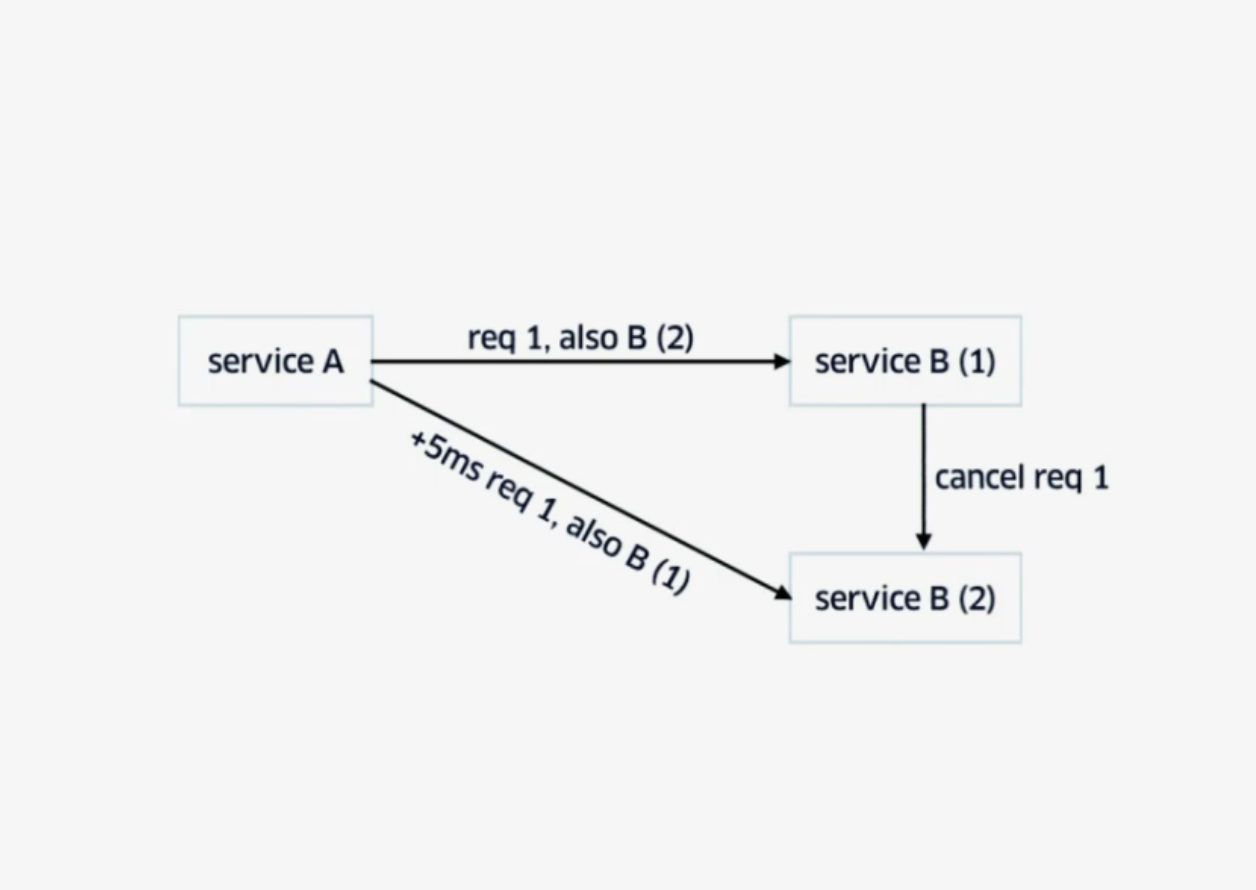
Клиент посылает запрос в сервис B1 и в самом запросе сообщает: «Кстати, я собираюсь послать такой же запрос сервису B2». Через какой-то небольшой промежуток времени, если ответ не пришел, клиент посылает этот же запрос сервису B2 и в самом запросе сообщает: «Кстати, я уже послал этот запрос в сервис B1». Первый сервис, который отработает запрос, затем свяжется со вторым командой «Отменить такой-то запрос».
Конечно же, это работает, если соблюдаются принципы Uber:
- любой запрос можно повторить;
- любой процесс можно убить.
Service Architectures at Scale: Lessons from Google and eBay (Randy Shoup)
Слайды
Автор доклада работал в Google и Ebay. Он попытался систематизировать свой опыт, дополнив его информацией о других крупных проектах, взятой из открытых источников. Его доклад мало затрагивает техническую область этих компаний, он более сконцентрирован на процессах внутри компаний, принципах и методиках. Думаю, он будет более интересен техлидам и тимлидам.
В целом все крупные системы движутся в таком направлении:
- Сначала пишется монолитное приложение, зачастую на скриптовом языке (Perl — в Ebay, Ruby — в Twitter).
- Потом все переписывается на более быстрый язык (Java,Scala, C++) но, опять-таки, с монолитной платформой.
- А затем всё переделывается на микросервисы.
Вообще, микросервисы — один из основных трендов на QCon. И в этом докладе автор много рассуждает о том, как построить процессы в компании, когда весь продукт разбит на множество микросервисов.
Зачастую в таких проектах у каждого микросервиса есть команда, которая за него отвечает. Она имеет полную свободу действий в плане того, как этот микросервис реализовывать, какой язык, БД, фреймворк использовать, как и когда выкладывать микросервис.
Но стандартизируется коммуникация между сервисами:
- сетевые протоколы;
- форматы данных;
- интерфейсы и схемы.
По этому поводу в докладе была хорошая цитата: «In a mature ecosystem of services, we standardize the arcs of the graph, not the nodes».
Также стандартизируется инфраструктура:
- система контроля версий;
- управление конфигурацией;
- управление кластером;
- мониторинг.
Зачастую в таких компаниях архитектура системы — это результат эволюции проекта, а не заранее продуманная и детально спланированная архитектура.
Например, в Google нет такой должности, как «архитектор», и нет какого-то центра принятия основных технических решений. Большинство решений принимаются локально внутри команды.
В качестве контраста автор приводит практику, которая применялась раньше в Ebay, где была Architecture review board, через которую проходили все большие проекты для утверждения. И хотя в компании было много опытных людей, они зачастую привлекались к обсуждению проекта, когда уже ничего нельзя было изменить. И эта доска часто становилась «бутылочным горлышком», в котором надолго застревали многие проекты.
Вместо того чтобы использовать опытных разработчиков для оценки чужих проектов, автор предлагает использовать их для написания библиотек, утилит, низкоуровневых сервисов или даже руководств, которые можно было бы использовать внутри компании во многих проектах.
Доклад получился очень толковый, всесторонний, но он больше для тех, кто руководит процессом, а не для обычных программистов.
Building a Modern Microservices Architecture at Gilt: The Essentials (Yoni Goldberg)
Слайды
Gilt.com продает брендовые вещи со скидками. В полночь у них запускаются очень большие скидки — в эти периоды очень сильно возрастает нагрузка и именно в это время они зарабатывают больше денег. Поэтому все их технические решения должны учитывать эти скачки нагрузки.
Изначально у компании было монолитное приложение на Ruby с использованием PostgreSQL и memcached, но однажды в продажу поступили Лабутены (знаменитые дизайнерские туфли с красной подошвой) и сайт не выдержал нагрузки.
После этого они начали всё переписывать на JVM (сейчас у них в основном Scala) с использованием микросервисов. В качестве БД используется Postgresql, H2 и Voldemort. Поначалу у них были даже не микросервисы, а «макросервисы». Фактически они разбили монолитное приложение на компоненты: платежи, продажи, пользователи. Но затем эти макросервисы были разделены на более мелкие сервисы.
Это решило большинство их проблем, особенно касавшихся масштабируемости и производительности. Но оставались проблемы со сложностью кода; многие сервисы оставались монолитными, выкладывать новую версию этой системы каждую неделю было тяжело.
По этой причине они продолжали разбивать свои сервисы на еще более мелкие микросервисы. В это же время начался переход на Scala и Play фреймворк, и они начали использовать LOSA — Lots Of Small Applications. Это как микросервисы но для веб-приложений. То есть каждая страница на сайте — это отдельный микросервис
Общая архитектура стала выглядеть примерно так:
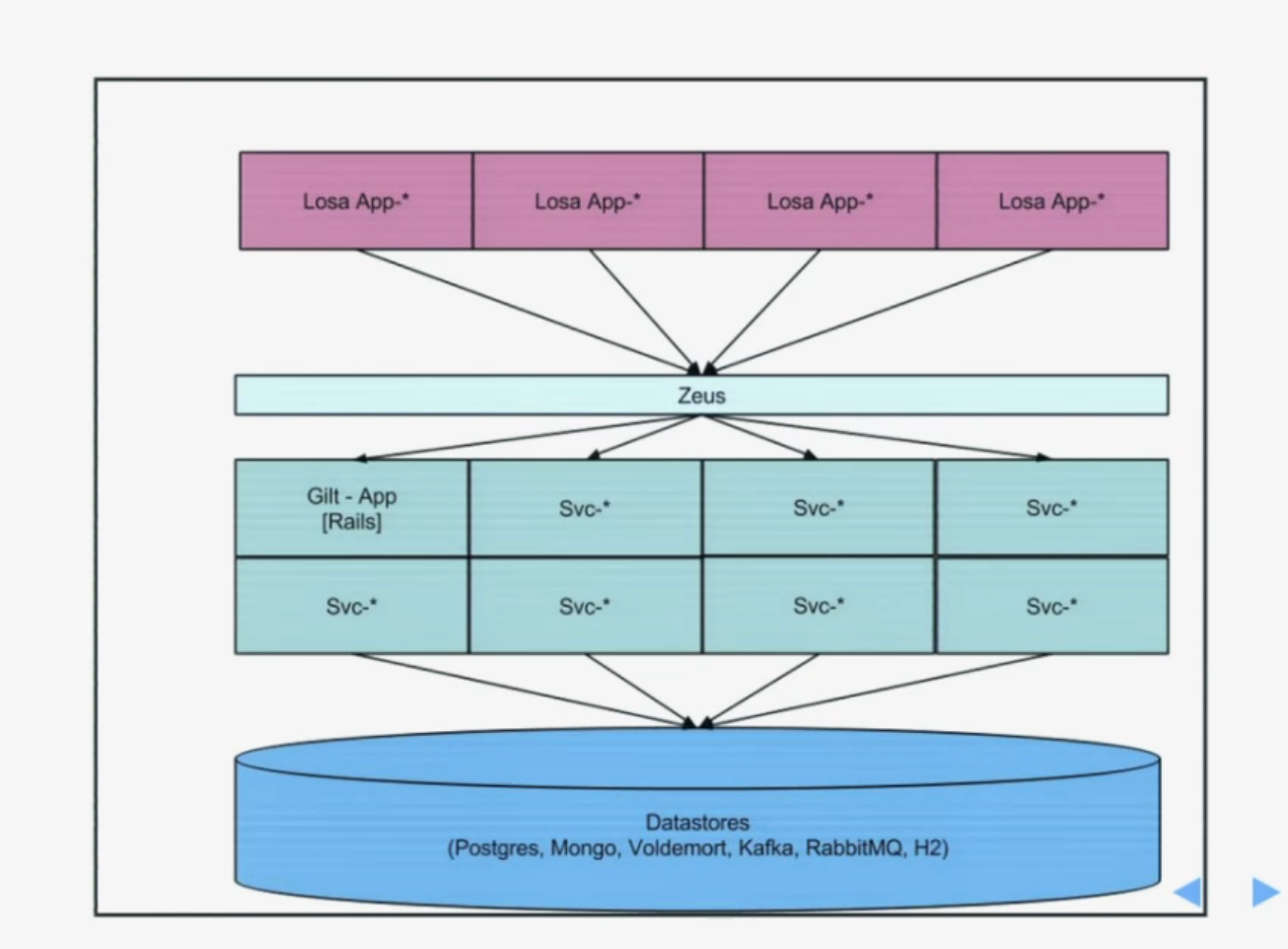
Сейчас у них примерно около 300 сервисов.
Все сервисы оборачиваются в Docker и работают на AWS. Каждая команда внутри AWS имеет свой аккаунт и бюджет. Поэтому каждая команда следит за тем, чтобы у них не были запущены сервисы, которые больше не используются, и, конечно же, заботится о производительности своих сервисов
Несмотря на то, что некоторые решения мне кажутся неоднозначными, доклад получился интересным. Автор поделился интересным опытом, проблемами и их решениями.
Spotify Audio Delivery at Scale (Niklas Gustavsson)
Слайды
Автор рассказывал о том, как устроен Spotify, какие проблемы приходится решать.
Одна из главных задач, которая стоит перед разработчиками в Spotify, состоит в том, чтобы выбранная пользователем композиция проигрывалась немедленно. По крайней мере, у пользователя должно складываться впечатление, что музыка стала проигрываться без задержки. И это накладывает определенные требованию на разработку backend-а.
Хотя в самой компании термин «микросервис» не используется, все же архитектура Spotify построена вокруг микросервисов, коих здесь сотни, а разрабатывается они примерно 40-50 командами.
Плюсы микросервисов:
- простота кода;
- надёжность системы;
- масштабирование.
Каждая команда работает независимо от других — разрабатывает и поддерживает свои микросервисы. Каждая команда сама решает, как она работает, устанавливает процесс разработки, процесс выкладки нового кода, определяет архитектуру своих микросервисов. В компании есть несколько архитекторов, которые оценивают архитектуру Spotify на очень высоком уровне, но они не участвуют в планировании архитектуры конкретных микросервисов. Если какой-то команде нужно изменение в микросервисе, за который отвечает другая команда, то они могут поставить задачу другой команде, а могут сделать изменение сами и отправить его на code review.
Внутри Spotify сервисы общаются по внутреннему асинхронному протоколу, построенному на основе ZeroMQ и Protobuf. Поначалу внутренние коммуникации сервисов основывались на HTTP, но с этим возникло много проблем. Раньше почти весь Spotify был написан на Python, у которого были проблемы с масштабируемостью. Сейчас почти весь backend написан на Java с использованием микросервисов.
В компании есть определенные руководства для команд, но в них минимум ограничений. Рекомендуется писать микросервисы на JVM или Python, есть рекомендации по поводу хранилища данных. Но в любом случае окончательные решения принимают команды, ответственные за микросервисы.
На примере рассматривалось, что происходит, если клиент выполняет поиск в Spotify. Сначала он устанавливает постоянное TCP-соединение с так называемым Perimeter service, который фактически является точкой доступа. Perimeter service отвечает за аутентификацию клиента, проверяет, что клиент не шлет слишком много запросов и вообще ограничивает backend Spotify от внешнего мира. Также Perimeter service по запросу понимает, на какой сервис нужно отправить запрос клиента.
Далее запрос попадает на один из View Services, в данном случае на SearchView. View Services адаптированы под специфику конкретного клиента. В Spotify не делают rendering на серверной стороне, но разные клиенты (iPad, iPhone, Android) могут требовать от сервера разные данные, и эта логика находится во View services. Затем SearchView посылает запрос в Search Service, который выполняет поиск, используя Lucene index. Такие сервисы они называют Data Services. Из поиска они получают лишь идентификаторы. И чтобы по ним получить данные, SearchView делает запрос в так называемый Metadata service (это не один сервис, а группа сервисов).
В данный момент у них 4 дата-центра. Если какой-то из них лежит, они перекидывают пользователей в другой. Выше было сказано, что Spotify-клиенты устанавливают постоянное соединение к Perimeter service. Когда надо перекинуть пользователя в другой дата-центр, сервер посылает специальную команду клиенту. Все данные пользователей реплицируются между дата-центрами, этим в Spotify занимается Cassandra.
Однако Spotify не может себе позволить строить дата-центры по всему миру, и многие их пользователи находятся довольно далеко от ближайшего дата-центра. Поэтому для раздачи аудио они пользуются услугами сразу нескольких CDN.
Заключение
Из неприятных нюансов могу разве что упомянуть некоторые недомолвки по поводу просмотра выступлений в записи. Дело в том, что с самого начала организаторы заявляют, что все доклады записываются и участники всегда смогут посмотреть их в записи. Но уже после конференции выяснилось, что доклады из спонсорских секций не записывались. Из-за этого я пропустил доклад от Aerospike. А вот доклад от Basho и bet365 про Riak я посетил, но не делал никаких пометок, надеясь потом посмотреть видео повторно.
Тем не менее, конференция мне понравилась. Очень порадовала секция про архитектуру больших систем. Судя по темам, основными трендами в современной разработке являются контейнеры (Docker в частности) и микросервисы.