

Всем привет! Я Игорь Гончаров — руководитель Службы управления данными Уралсиба. В этой статье я поделился нашим видением ответа на вопрос, который периодически слышу от коллег: зачем мы развиваем хранилище данных банка, когда есть технологии Data Lake?
Очевидно, что бизнес всё больше становится датацентричным. Раньше данные, необходимые для аналитической поддержки, группировались вокруг существующих процессов и продуктов. Теперь всё иначе — новые продукты и процессы возникают вокруг данных.
В таком случае на старте надо серьёзно подумать, как лучше организовать сбор, хранение и обработку данных из множества источников, а также какой вариант выбрать — DWH или Data Lake. Сначала это было проблемой для телекома, затем — для финансовых организаций. Сейчас такой же вопрос стоит и перед производственными компаниями.
Геометрический рост объёма окружающих нас данных и происходящий на глазах прорыв в технологиях машинного обучения показывают, что классические хранилища не в состоянии поддерживать идею, которая основана на росте вычислительных мощностей и технологий распределённых вычислений — чем больше данных, тем потенциально лучший результат может выдать модель машинного обучения.
И ещё надо помнить, что хранилища — это история про структурированные данные. А вот для хранения и обработки изображений, аудио и всех остальных видов так называемых NoSQL-данных DWH не предназначены. В ответ на новые требования возникли «озёра данных», основанные на технологиях Hadoop.
Преимущества Data Lake
Один из плюсов Data Lake в том, что они базируются на Open Source решениях и, как следствие, не требуют существенных инвестиций в ПО. Кроме того, «озёра данных» предполагают идею почти бесконечного горизонтального масштабирования, а значит, не надо вкладываться в дорогие серверные мощности.
После создания инфраструктуры Data Lake можно в максимально короткие сроки стартовать загрузку и начать использовать данные. И на первый взгляд, всё понятно: чем больше данных зальём, тем лучше, а что с ними делать дальше — разберётся искусственный интеллект.
А с хранилищами данных сложнее: это недёшево и строить такие вещи надо годами. К тому же появился негативный опыт — в банках не все смогли справиться. Требовалось разбираться с методологией, заниматься построением моделей, организовывать потоки трансформации данных по слоям DWH с использованием специализированного ПО.
Способных на это специалистов было мало и они шли буквально нарасхват. К тому же требовалось создавать команду поддержки, потому что волшебного AI здесь не было.
Могут ли «озёра» вписаться в тренд демократизации данных
«Озеро данных» — это в каком-то смысле дитя цифровой трансформации. А её обязательное свойство — демократизация данных. Поэтому в любой компании работать с данными должны буквально все, а не только специально обученные люди (аналитики, дата-сайентисты).
И даже у последних должна зеркально поменяться стандартная статистика работы с данными. Если раньше 80% времени уходило на поиск данных и 20% — на аналитику, то теперь всё должно было быть наоборот. Но по факту «озеро данных» только увеличило время на добычу информации: теперь у сотрудников 90% времени уходит на поиск.
Более того, принцип информатики, который по-русски звучит как «мусор на входе, мусор на выходе», стал как никогда актуальным. Выяснилось, что модели продвинутой аналитики, позволяющие строить предиктивный анализ, хорошо работают на консистентных, структурированных данных, и плохо — на несопоставимых и сильно прорежённых.
К тому же раньше набор данных (dataset) собирался буквально за часы с помощью SQL-запросов, теперь же на основе Hadoop приходится тратить в разы больше времени.

Важно не превратить озеро в болото
Сейчас на рынке наступило своего рода протрезвление: все чаще от коллег можно услышать, что вопрос правильной организации управления данными (Data Governance) важнее, чем их количество. Даже возник новый термин — «болото данных» (Data Swamp). Пришло понимание, что даже в «озёра» надо заливать не все подряд, а классифицированные и систематизированные данные.
Всё это говорит о том, что самоцель получить как можно больше данных ведёт в тупик. Пользователи в организации хотят, чтобы данные были описаны: откуда они приходят, как модифицируются, что означают и как правильно их интерпретировать.
К тому же полные и структурированные данные имеют высокую бизнес-ценность — речь идёт о том, какую добавленную стоимость в бизнесе они позволяют получить. И на практике такие данные дают свыше 90 процентов ценности в аналитике.
Я считаю, что правильно организованное корпоративное хранилище — оптимальный способ хранения и доступа к таким данным при условии, что концепция хранилища учитывает требования к максимальной демократизации данных.
BI и песочницы для демократизации данных
В Уралсибе хранилище играет роль единого источника данных организации. Однако есть ещё два критично важных элемента архитектурного ландшафта. Первый — это песочницы данных, которые по умолчанию организуются для каждого подразделения, оформляющего учётную запись для доступа к данным хранилища.
Если в хранилище всё пронизано идеей Data Governance, то песочницы — это «царство свободы», где пользователи вольны строить свои наборы данных, комбинировать информацию из слоя оперативных данных и витрин, обогащать внешними данными, а также тем, что получено в ходе построения моделей.
В свою очередь, BI позволяет максимально расширить круг пользователей, которые без специализированных ИТ-навыков могут формировать и проверять гипотезы, основанные на данных, а также разрабатывать и делиться оперативной отчётностью, которая автоматически обновляется при изменении данных в хранилище или песочницах.
Таким образом, это современный способ организации доступа к данным и их визуализации. Правильное использование всех перечисленных компонентов на основе хранилища данных и позволяет нам органично сочетать Data Governance и Data Democracy — устойчивость и гибкость.
Витрины данных: надёжно, долго и дорого
В самом же хранилище данных есть два слоя, к которым пользователи обычно получают доступ. Это сырые или оперативные данные, которые являются копиями данных, хранящихся в системах-источниках. А в другом слое находятся специализированные витрины. Они готовятся на основе бизнес-требований и являются квинтэссенцией концепции Data Governance.
Я часто слышу о том, что тщательно задокументированные и находящиеся на сопровождении витрины — это долго и дорого. Признаю, что это отчасти верно. Но в жизни есть вещи, которые не могут стоить дёшево и за которые мы готовы платить: к примеру, бизнес-задачи, требующие особого подхода к процессу подготовки данных. В таких случаях требования к качеству данных или регламенту их сборки оправдывают временные и финансовые затраты на создание таких специализированных витрин.
В первую очередь, речь идет об отчётности, будь то пруденциальная (которая особенно важна для банков), налоговая или управленческая — цена ошибок в таких кейсах слишком велика. Второй момент — жёсткие требования не только к качеству, но и к регламенту формирования наборов данных. Например, если речь идет о данных для маркетинговых кампаний и формирования предложений клиентам, либо мы говорим о формировании данных, на которых строятся ежедневные стратегии действий по взысканиям проблемной задолженности.
В Уралсибе данные по таким витринам за предыдущий день должны быть готовы к 8:00, при этом часть данных захватывается только после завершения процедуры закрытия предыдущего операционного дня. Без хранилища данных миссия становится невыполнимой, учитывая десятки миллионов счетов, сотни миллионов транзакций, а также то, что часть показателей необходимо рассчитать накопительным итогом или в виде усреднённых за период величин.
Как мы организовали слой оперативных данных
Формализованная отчётность — это наследие эпохи, предшествующей цифровой трансформации. А в нынешних условиях ключ к успеху — это скорость изменений и ранее упомянутая демократизация данных. В то же время витрины дорабатываются и меняются относительно медленно.
Как в таком случае хранилище данных может поддерживать постоянно меняющиеся потребности в ad hoc анализе, оперативных и гибких отчётностях по продажам, а также расширяющихся наборах данных для предиктивной аналитики? Здесь поможет правильная идеология организации слоя оперативных данных, представляющих по сути snapshot состояния систем источников.
Некоторые хранилища данных развиваются в парадигме, когда в слой оперативных данных загружаются только те данные, которые необходимы для загрузки в детальный слой или в витрины. Мы же изначально зафиксировали концепцию, согласно которой каждый день в слой оперативных данных загружаются не выборочные атрибуты, необходимые для построения витрин, а вся таблица целиком. Это первый столп, на котором базируется построение оперативного слоя хранилища данных в Уралсибе.
Второй элемент фундамента: спецификации для всех загружаемых таблиц. Они на языке бизнеса описывают виды данных, которые должны содержаться в загружаемой таблице. Это позволяет всем пользователям быстро разобраться, где лежат нужные им данные, существующие в системах-источниках, и тут же начать их использовать.
По сути, слой оперативных данных становится неким «озером» для внутренних систем источников организации. Обращаться в ИТ или в подразделение управления данными в таком случае не нужно. И ещё одна наша фишка — еженедельный релиз-процесс.
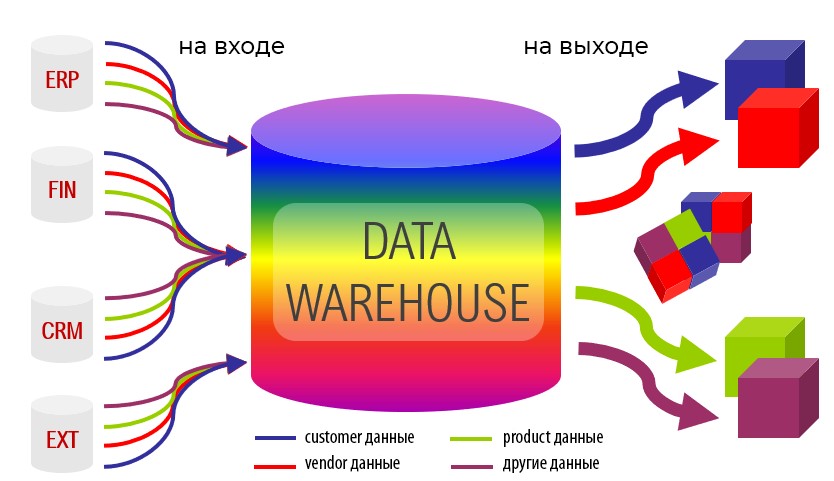
Так что же лучше: DWH или DataLake?
Всё написанное выше отражает наш опыт и убеждение в том, что начинать работу с построения хранилища данных нужно как финансовой, так и любой другой организации, для которой работа с данными — ключевой аспект развития и успешности в конкурентной борьбе. Это основа, то есть, образно говоря, базовый навык ходьбы.
Впрочем, неправильно будет утверждать, что Data Lake — это ошибочный путь развития. Противопоставление DWH и Data Lake в принципе не совсем правильно. Это не исключающие друг друга решения. Напротив, они способны отлично дополнять друг друга.
Если мы говорим про NoSQL-данные или модели машинного обучения, где оптимальное решение может быть выработано на основе факторов, которые мы не всегда сможем отследить и понять, то Data Lake — это правильный и оптимальный по стоимости инструмент.
Но перед тем, как начать бегать (в нашем случае это переход на машинное обучение и «озёра данных»), важно сначала научиться ходить: использовать внутренние данные организации, DWH и BI. И конечно же, следует ориентироваться на потребности бизнеса и монетизацию данных.
Комментарии (11)

kvsman
15.12.2021 23:35Интересный обзор практического опыта, спасибо.
Расскажите, если не секрет, используется ли у вас Data Lake при формировании отчетности для ЦБ РФ (4927-У)?

URS_CDO Автор
16.12.2021 09:00У нас пруденциальная отчетность формируется на основе данных Хранилища, ведь речь идет о структурированных и отнюдь не big data

Ninil
16.12.2021 09:16Была на Хабре статья про отчетность ЦБ на Data Lake - https://habr.com/ru/company/neoflex/blog/498200/
URS_CDO Автор
16.12.2021 10:38Для ЦБ в отличии от нас в масштабе всей банковской системы РФ, особенно принимая во внимание их планы получать raw data от банков, а не агрегаты как сейчас, это вполне по объемам потянет на термин BigData:)

Zlodeykin
16.12.2021 10:29"Один из плюсов Data Lake в том, что они базируются на Open Source решениях и, как следствие, не требуют существенных инвестиций в ПО. Кроме того, «озёра данных» предполагают идею почти бесконечного горизонтального масштабирования, а значит, не надо вкладываться в дорогие серверные мощности."
1) После того, как Cloudera купила Hortonworks и сделала свой дистрибутив платным, бесплатных осталось не очень много, например Arenadata. Также следует понимать, что любое бесплатное ПО в продукционной среде требует достаточно дорогих программистов и администраторов, которые будут его поддерживать (это могут быть очень серьезные инвестиции).
2) Современные DWH строятся на MPP реляционных базах данных, типа Vertica или Greenplum, которые также горизонтально масштабируются, как Hadoop.

2ANikulin
17.12.2021 06:43DataLake не обязательно на Хадупе строить, можно ведь Кассандру взять. Будет по проще
2ANikulin
17.12.2021 06:40+1Так и не понял суть проблемы. Все что есть льём в DataLake. Гоняем AdHoc выборки по всему пространству. То что надо для оперативной работы/витрин - аггрегируем/фильтруем/экспортируем в RDBMS/OLAP.
Ninil
Мне кажется, что уже как пару лет многие смотрят на «следующий уровень», объединяющий плюсы и хранилищ, и озёр — Data Platform
URS_CDO Автор
Если вы говорите о доступе к данным через виртуализацию в рамках единого каталога данных, то это все же надстройка над DWH и DataLake в попытке унифицировать понимание, какие данные доступны в организации. Это хороший следующий шаг, но под капотом должны быть все те же хранилище и озеро данных и без них надстройка бессмыслена. Ну и опять таки, все те преимущества и недостатки, которые изначально присущи последним, остаются:)
Ninil
Нет, я не про виртуализацию.
Если совсем грубо, то Data Platform = Data Lake + DWH. При таком подходе подготавливаются только действительно «ценные» данные (в "DWH-части"), при этом все данные доступны для использования (в "Data Lake-части"). Естественно, как вы и упомянули в статье, без Data Governance здесь не обойтись.