
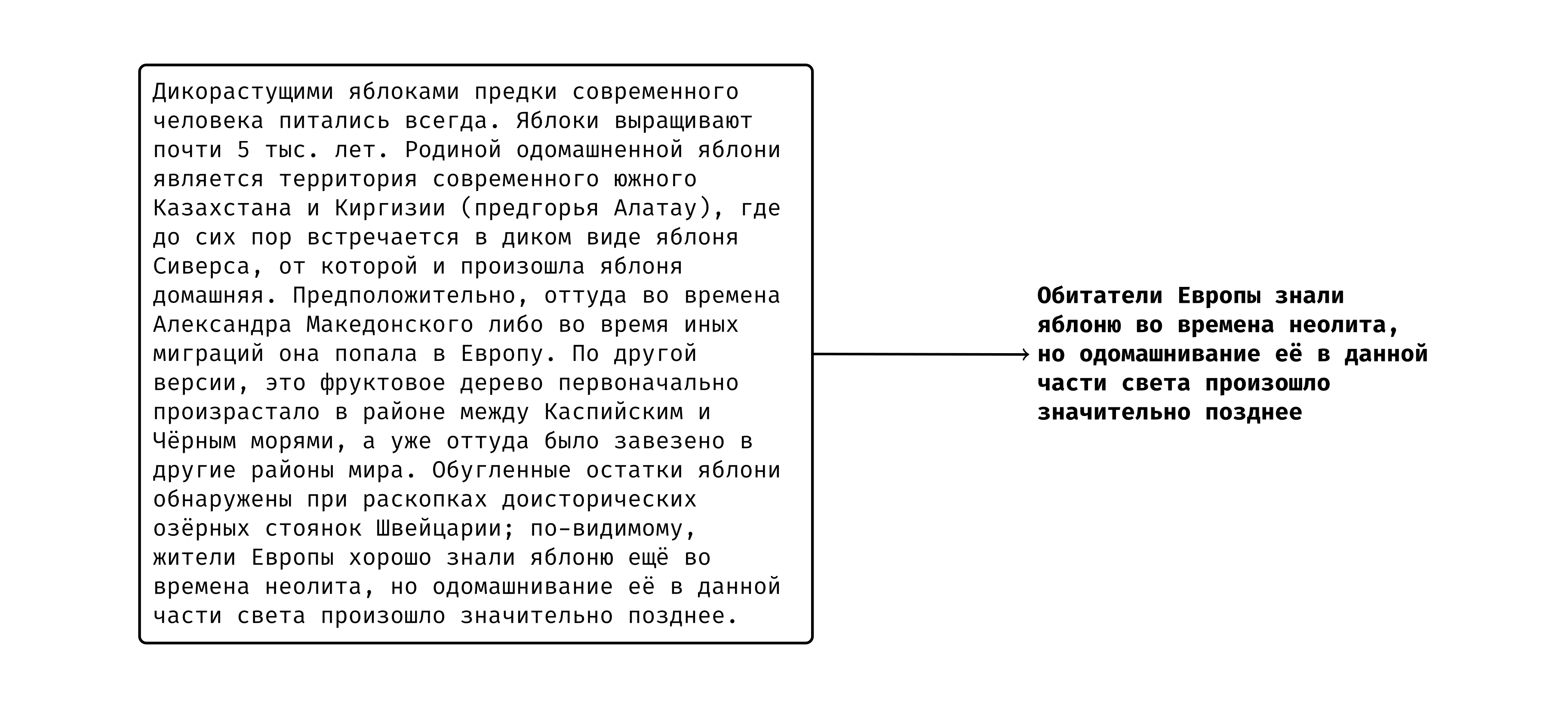
Наше семейство моделей ruGPT-3 уже нашло множество применений у сообщества: кто-то генерирует гороскопы, кто-то — факты о лягушках, статьи нейроуголовного кодекса, нейроновости и прочее. Модели накопили в себе массу знаний о нашем мире и способны подстроиться практически под любую задачу. Тем не менее, в данный момент подобная подгонка (fine-tuning) часто требует значительных вычислительных затрат, что не всегда позволяет использовать достаточно большие модели. В этом посте мы предлагаем сообществу новый инструмент для того, чтобы дообучать ruGPT-3 под свои нужды и делиться своими результатами с другими.
Традиционные подходы
Обычно для адаптации предобученной модели к конкретной задаче используется файн-тюнинг, то есть полное дообучение модели на новых данных. Несмотря на хорошее качество, этот метод обладает целым рядом недостатков:
вычислительная ресурсоёмкость из-за обучения всех весов;
неэффективность по памяти, поскольку после дообучения меняются все веса и для каждой задачи нужно хранить отдельную модель, по размеру равную предобученной;
высокие требования к размеру датасета;
в некоторых случаях потеря генерализации, то есть возможности решать ту же задачу в других доменах.
С появлением GPT-3 также получили распространение few-shot и zero-shot методы, основанные на подаче текстовых инструкций в модель. Почитать об их применении к русскоязычным моделям можно в нашем посте.
Несмотря на то, что few-shot и zero-shot методы позволяют решать сразу несколько задач одной моделью без изменения её весов, у них тоже есть серьёзные недостатки. Подбор правильной затравки – это тяжёлый ручной труд, и даже если затравка найдена, мы не можем быть уверены в её оптимальности. Очень часто бывает, что если чуть-чуть её поменять, можно существенно улучшить качество. Например, в задаче распознавания эмоциональной окраски твитов с помощью zero-shot мы столкнулись с тем, что формат затравки Весёлый твит: {text} давал точность 70%, а его изменение на Весёлый твит: {text}))), то есть добавление трёх скобочек, повысило точность до 90%. Безусловно, логично, что грустный текст с тремя скобочками модель посчитает маловероятным, но чтобы до этого додуматься, нужно действовать с фантазией. И это ещё был простой пример. Попробуйте, например, вручную придумать затравку, которая понятнее всего попросит модель детоксифицировать текст, то есть переписать его из грубой формы в приличную. В общем, если становиться «оператором GPT-3» не входит в ваши планы, нужно думать над способом находить затравки автоматически.
Поиск затравки градиентным спуском
А теперь посмотрим, как мы можем это сделать. Допустим, у нас есть очень эффективный и по вычислениям, и по памяти zero-shot, но нам трудно найти затравку вручную. Тогда почему бы не обучить её градиентным спуском?
На основе примерно таких рассуждений и был придуман метод, который называется prefix tuning, p-tuning или prompt tuning (далее будем придерживаться последнего названия). Он был предложен одновременно в нескольких статьях, вот некоторые из них: Prefix-Tuning: Optimizing Continuous Prompts for Generation, GPT Understands, Too, The Power of Scale for Parameter-Efficient Prompt Tuning. Общая идея следующая: поскольку все слова, а точнее токены, переводятся в эмбеддинги (векторы фиксированной размерности; подробнее почитать о том, как работает трансформер, можно здесь), то эмбеддинги, соответствующие затравке, можно напрямую обучить градиентным спуском.
Prompt Format
Обучаемая затравка (trainable prompt) логично разбивается на два компонента: формат (prompt format) и провайдер (prompt provider). Поясним на примере. Допустим, мы хотим обучить нейросеть отвечать на вопрос после прочтения текста. В случае, если мы решаем задачу методом zero-shot, формат затравки, скорее всего, будет примерно таким:
Текст:
{passage}
Вопрос: {question}
Ответ:Например, этот обучающий пример:
{
"passage": "GPT-3 устроена следующим образом: [...]",
"question": "Как устроен self-attention?"
}будет отформатирован и подан в модель в следующем виде:
Текст:
GPT-3 устроена следующим образом: [...]
Вопрос: Как устроен self-attention?
Ответ:Сгенерированные моделью следующие токены мы и будем считать ответом.
Если же мы не уверены в том, что текстовые инструкции (Текст:\n, \nВопрос:, \nОтвет:) достаточно хорошо подходят к задаче, то prompt tuning позволяет нам заменить их на обучаемые токены (<P>) и контролировать только их количество. Таким образом, формат затравки примет следующий вид:
<P><P><P><P>{passage}<P><P><P><P>{question}<P><P><P><P>Prompt Provider
После того, как мы определились с позициями и количеством обучаемых токенов, остаётся только подставить на их позиции обучаемые эмбеддинги. Для этого и нужен провайдер – модуль, выдающий дифференцируемую матрицу формы [количество обучаемых токенов, размерность эмбеддинга]. Возвращённые им эмбеддинги и будут поочерёдно подставлены на позиции токенов <P>.
На самом деле, получить обучаемые эмбеддинги можно огромным количеством способов: например, напрямую обучать эмбеддинги или репараметризировать их с помощью LSTM, чтобы они могли обмениваться информацией, как это описано в статье GPT Understands, Too. Именно поэтому провайдер — это, скорее, интерфейс: на эту роль подойдёт любой модуль, возвращающий матрицу правильной формы.
При переводе токенов в эмбеддинги вместо словарных токенов подставляются их обычные эмбеддинги, а вместо обучаемых токенов (<P>) последовательно подставляются дифференцируемые эмбеддинги из провайдера:

ruPrompts
С помощью ruPrompts компоненты обучаемой затравки задаются следующим образом:
from ruprompts import Prompt, PromptFormat, TensorPromptProvider
prompt_format = PromptFormat("<P*4>{passage}<P*4>{question}<P*4>")
prompt_provider = TensorPromptProvider()
prompt = Prompt(
format=prompt_format,
provider=prompt_provider,
)В простейшем случае форматирование текста будет практически идентично встроенному методу str.format:
>>> prompt_text = prompt(passage="Земля круглая.", question="Круглая ли Земля?")
>>> print(prompt_text)
<|P|><|P|><|P|><|P|>Земля круглая.<|P|><|P|><|P|><|P|>Круглая ли Земля?<|P|><|P|><|P|><|P|>Однако просто токенизировать отформатированный текст и подать его в модель не получится: если токенизатор и модель ничего не будут знать об обучаемой затравке, то обучаемые токены обработаются токенизатором и моделью как обычные бессмысленные последовательности символов. Для того, чтобы произошла магия, нужно добавить обучаемые токены в словарь токенизатора и подменить слой входных эмбеддингов на более умный — такой, который правильно подставит обучаемые эмбеддинги из провайдера на места обучаемых токенов. Всё это можно сделать с помощью одного метода:
prompt.patch(model, tokenizer)Обучение
Теперь поговорим о том, как обучать провайдер. Снова проиллюстрируем на примере. Prompt tuning работает с произвольным лоссом, так что рассмотрим простейшую задачу бинарной классификации. Для этого будем подавать в модель обучаемую затравку (prompt_text) и смотреть на логиты последнего токена – если применить к ним softmax, они будут отражать вероятности следующего токена. Среди них нас интересуют только компоненты, соответствующие словам «Да» и «Нет». При обучении мы будем считать кросс-энтропию только между ними и прокидывать градиенты до весов провайдера, а шаг оптимизатора будет делаться только по весам провайдера:

Аналогичным образом можно обучить затравку и для задач, где таргетом является не класс, а текст. Процесс обучения практически тот же, меняется только лосс – теперь мы кроме затравки подаём на вход целевую последовательность токенов (например, краткое изложение текста при решении задачи суммаризации) и считаем от неё лосс (потокенную кросс-энтропию):

Предобученные затравки
Мы выкладываем несколько затравок, обученных на задачах обработки текста (text-2-text) и генерации в определённом стиле. Все затравки обучены для модели ruGPT-3 Large, но мы планируем расширять как список задач, так и список моделей. Следить за актуальным списком предобученных затравок можно в разделе документации.
Генерация
Анекдоты

Для того, чтобы обучиться генерировать текст в стиле анекдотов, мы обучали префикс из 60 токенов. Для простоты можно считать, что обученная затравка выполняет примерно ту же функцию, что и Расскажи анекдот, который начинается со слов:, только лучше. Поскольку мы никак не меняем саму нейросеть, то она не затачивается под стандартную анекдотную лексику и не теряет знаний о мире, как это бывает при файн-тюнинге. В результате можно генерировать более разнообразные анекдоты, пользуясь эрудицией модели.
Датасет: для обучения мы использовали 27мб анекдотов.
Использование:
import ruprompts
from transformers import pipeline
ppln = pipeline("text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_joke")
ppln("Заходят как-то в бар")Пословицы

Датасет: для обучения мы использовали 4000 пословиц.
Использование:
ppln = pipeline("text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_proverb")
ppln("Сколько бы")Обработка текста
Суммаризация
Датасет: для обучения мы использовали датасет mlsum.
Использование:
ppln = pipeline("text2text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_summarization_mlsum")
ppln("Млекопитающее - это ...")Генерация заголовков

Датасет: для обучения мы использовали датасет mlsum.
Использование:
ppln = pipeline("text2text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_title_mlsum")
ppln("Млекопитающее - это ...")Детоксификация

Датасет: для обучения мы использовали обучающие данные с недавно начавшегося соревнования по детоксификации текстов в рамках RUSSE 2022.
Использование:
ppln = pipeline("text2text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_detox_russe")
ppln("Ублюдок, мать твою, а ну иди сюда")Вопросно-ответная система

Датасет: для обучения мы использовали вторую версию датасета SberQuAD.
Использование:
ppln = pipeline("text2text-generation-with-prompt", prompt="konodyuk/prompt_rugpt3large_sberquad")
ppln(context="В 1997 году Шмидхубер ...", question="Совместно с кем Шмидхубер опубликовал работу?")Ресурсы
Все затравки обучались на одной видеокарте V100. Длительность обучения сильно зависит от размера датасета, длины текстов в нём и гиперпараметров обучения и может занимать от нескольких минут до пары суток. На практике prompt tuning чаще всего применяется к датасетам маленького и среднего размера, так что при параметрах по умолчанию средняя длительность обучения редко превосходит 8 часов.
Что дальше?
Все предобученные затравки доступны в нашем Telegram-боте. Исходный код ruPrompts выложен на GitHub, установить библиотеку можно с помощью
pip install rupromptsПочитать о том, как обучать затравки и делиться ими через HuggingFace Hub, можно в документации. Потрогать ruPrompts можно в Colab-ноутбуках и там же при желании – обучить затравку на собственных данных.
Комментарии (6)

logran
17.12.2021 15:41Потрогать ruPrompts можно в Colab-ноутбуках
Нельзя. На обоих Not Found.
janvarev
17.12.2021 16:25Надо сначала установить:
!pip install ruprompts
Только что проверил, примеры работают.logran
17.12.2021 18:50Библиотека работает. Ссылки на ноутбуки в Google Colab не работают. По ссылкам not found. Локальные библиотеки к этому отношения не имеют.
P.S не работали. Уже починили.

konodyuk Автор
17.12.2021 21:58Спасибо за внимательность, в данный момент все ссылки на ноутбуки рабочие
Rybolos
Спасибо за библиотеку!
Есть ли смысл решать ей задачи классификации, например, а не seq2seq?
konodyuk Автор
В первую очередь нам было интересно попробовать подбор затравки для генеративных задач, но, как показывают статьи, для классификации метод тоже работает хорошо. В будущем мы, возможно, добавим в библиотеку поддержку большего числа задач.