

Каждый знает мантру – найденный на проде баг – самый дорогой. В нашем случае он дорогой в квадрате, потому что мы делаем социально значимый портал – от стабильности Госуслуг во многом зависит благополучие наших сограждан.

Меня зовут Дмитрий Пирумов, я возглавляю команду автоматизированного и приемочного тестирования в РТЛабс. В этой статье я хочу поделиться опытом проведения тестирования на проде, внедренного у нас в компании, и попробовать показать профит и болевые точки такого подхода.
Определения
Функциональность – услуга/сервис или фича на Госуслугах;
Прод – продуктивная среда портала;
Стейдж (или препрод) - среда функционального тестирования максимально приближенная к прод;
ПТ – приемочное функциональное тестирование;
CR – change request;
СЭ – Служба эксплуатации – инженеры поддержки функциональности на продуктивной среде.
EGS – EgovDevSupport – тикет на группу поддержки от созданного инцидента на прод среде.
Как все начиналось
Наша компания сталкивается со сложными вызовами, многие задачи мы должны решать максимально оперативно – от социальных выплат на детей до проведения всероссийского голосования. В такой парадигме на первое место ставится не вопрос окупаемости продукта или его маржинальности, а качество и стабильность его работы.
Именно с целью повышения качества в июле 2020 года был сформирован наш Отдел приемочного и автоматизированного тестирования.
На текущий момент команда состоит из 24 человек:
13 инженеров по автоматизированному тестированию;
11 инженеров по функциональному тестированию
…и команда продолжает расти вместе с объемом задач.
В среднем, у каждого члена команды более 3-х лет опыта в тестировании.
И немного о нашей технике:
баги ведем в Jira, тест-кейсы там же, подключили плагин Zefir;
автотесты пишем на стеке Java+Selenium+testng;
для сборки используем maven, а запускаем автотесты из Jenkins;
сами тесты бегают на Selenoid;
отчетность живет в allure (планируем переехать в allureTestOps).
Ключевые задачи
В нашей компании несколько команд, отвечающих за свой продукт и его функциональность. Каждая продуктовая команда состоит из аналитиков, разработчиков, тестировщиков и тд. Такая «группировка» повышает компетенции команды, её сыгранность, что в свою очередь ускоряет TTM и качество выпускаемого командой продукта.
Но наша команда проводит не совсем привычное тестирование и не относится к «продуктовым» командам - мы тестируем на прод среде.
Наши ключевые поинты:
мы тестируем на прод среде новые релизы по критичным сервисам портала;
мы проводим регресс на прод среде важных сервисов и услуг;
мы подключаемся к срочным и «проблемным» релизам и помогаем с тестированием до вывода в прод – мы называем это «тестовый спецназ» ;
обеспечиваем смоук тестирование на проде после установки релизов;
предоставляем сервисные услуги по автоматизации тестирования – наш фреймворк автотестов используется в нескольких продуктовых командах.
Почему же именно тестирование на проде, а не на тест среде или на отдельной стейдж среде?
По нескольким причинам:
на тест и стейдж средах уже провели тестирование силами продуктовой команды, ретест скорее всего не выявит существенных отличий, но время и ресурсы будут потрачены;
обновление стейджа, ввиду масштабности портала и количества подсистем и релизов, повлечет увеличение сроков;
раскатка среды аналогичной прод среде потребует массу времени и ресурсов, а неминуемое различие стейдж среды от прод и тест внесет свои коррективы в результаты (например, консистентность БД и её «свежесть», влияние «соседних» доработок и тд);
на прод среде вся интеграция – полноценная (в отличии от теста или стейджа), все справочники актуальные, а бэк настроен так, как должен быть. Если нет – мы это увидим;
Взгляд со стороны пользователя – мы увидим, как услуга работает для пользователя, и скорее сможем столкнуться с проблемами аналогичными пользовательским.
В целом это задача не тривиальная и, скорее всего, не имеет решения а-ля «сделай как 100 человек до тебя», индивидуальна и завязана на ресурсы и процессы внутри компании.
Но вернемся к задаче и поговорим о каждом поинте поподробнее:
1. Тестирование критичных и важных релизов
Это авангард наших задач – тестирование новых услуг или изменений по существующим услугам. Наша задача проверить все тикеты в релизе (если нет ограничений, обусловленных средой). В состав релиза могут входить как задачи по выводу новой услуги, так CR и баги.
Наша команда находится в постоянном контакте с продуктовыми командами, мы знаем об их планах, сроках вывода или переносах фич/услуг, изменениях в реализации.
Начинать знакомство с новой услугой мы стараемся как можно раньше: по требованиям в Confluence и Figma, общаясь с аналитиками и РП по проекту. К моменту релиза мы уже хорошо знаем, как должна и как не должна работать услуга. Но написание тест-кейсов мы начинаем только с момента финальной реализации услуги – непосредственно с момента релиза (или близко к нему), так как за время пути до прода решения по реализации могут меняться, дизайн перерисовываться, а итоговый вариант отличаться от изначального (но только в лучшую сторону).
Важная особенность – это написание своих тест-кейсов. И главная причина – это свежий взгляд на процесс, его ключевые точки и особенности реализации. Используя те же сценарии, что и продуктовая команда, мы рискуем пропустить ошибки, которые не заметили на тесте.
Что касается багов и CR – информацию мы получаем из тикетов, в которых описаны ожидаемый и фактический результаты. А также используем информацию, полученную на тестовой среде, от продуктовой команды тестирования.
Тестированию подвергаются все тикеты новой услуги – критичные и важные сценарии проверяются сразу после установки, а менее приоритетные в течении следующего дня.
Тут важный момент: если сотрудник понимает, что какая-то услуга работает некорректно/нестабильно, он сообщает об этом в специальный телеграм-чат c описанием проблемы и пингом конкретных ответственных сотрудников. Далее в учетной системе заводится инцидент на прод среде соответствующей категории.
На основании инцидента создается EGS на группу поддержки и берется в работу.
Профит:
снижаем влияние на потребителя: вероятность, что пользователь столкнется с проблемой снижается и растет доступность сервисов.
Болевые точки:
тестовые данные – так как тестирование проводится на прод среде, подготовка тестовых данных может быть осложнена или вообще невозможна;
заблокированные для прохождения кейсы – еще одно ограничение прод среды. В некоторых процессах нельзя незаметно и без последствий пройти услугу, такие кейсы проверяются либо частично, либо выносятся в риски.
взаимодействие с ведомствами – не все ведомства готовы иметь на своей стороне тестовые УЗ для проверки интеграции, а значит не по всем услугам можно пройти E2E сценарий.

2. Регресс важных сервисов и услуг на проде
Вторая наша важная задача – проверка на проде критичных и самых популярных услуг. В целом этот процесс можно назвать глубоким мониторингом: мы проверяем более 100 услуг и сервисов, наиболее востребованных у пользователей (независимо от релизов по ним). Команда проходит до 850 кейсов каждый день. Количество кейсов на каждую услугу или сервис варьируется от 2 до 70.

Все найденные баги регистрируются в Jira, в чате информируются ответственные оунеры по услуге/сервису, регистрируются инциденты и EGS и передаются в продуктовую команду, аналогично процессу из п.1.
Так же мы отслеживаем работу с багами – на графике мы видим соотношение задач в работе и уже завершенных (исправленных). На 16 января 2022 г. в работе было 50 задач, а закрыто уже 185.

Такой набор в несколько потоков работает около 4-х часов и к 7 утра мы получаем результаты. Утром запускается реран failed тестов и результаты прогона анализируются: проводится ретест нерабочих услуг, выясняются причины падения и регистрируются соответствующие баги.
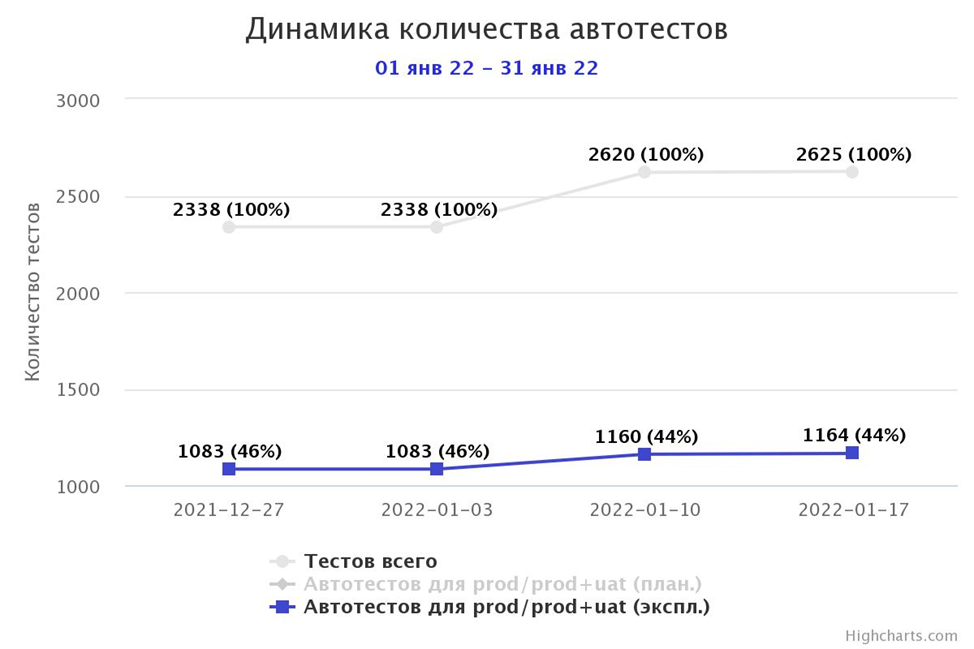
Мы также отслеживаем динамику состояния ТОП услуг – на графике отображается статус проверки услуги. Зеленая галочка – все кейсы пройдены успешно.
Информация агрегируется из Jira (плагин Zefir) на внутреннем портале и доступна любому сотруднику компании.

Профит:
повышаем скорость реагирования: автоматизированный регресс после релиза в сжатые сроки покажет проблемные места и влияние на смежные услуги/сервисы;
повышаем стабильность услуг: проблемы выявляются и устраняются раньше, чем пользователь с ними столкнется - растет доступность сервисов;
повышаем качество услуг: информированность по динамике состояния услуг, количеству проблем по каждой услуге и динамике их исправления – помогает отслеживать проблемные услуги и уделять им больше внимания.
Болевые точки аналогичны предыдущему пункту:
тестовые данные;
заблокированные для прохождения кейсы;
взаимодействие с ведомствами.
3. Задачи «спецназа»
Не первая в списке, но одна из важных задач – это «спецназ».
Само название в целом описывает главную задачу – прийти и помочь решить проблему (мы) для успешного внедрения в прод.
Объемы помощи зависят от количества и сложности проблем, а также от сложности тестируемых процессов.
Важная особенность спецназа – скорость погружения в задачу: нужно быстро разобраться в процессах, понять, где проблема и как ее решить.
Так как к услугам спецназа прибегают в самом конце, когда до релиза остается совсем ничего, а рук не хватает, скорость – главное требование.
В нашем спецназе только опытные инженеры – задачи разношерстные по сложности и технологиям – знания нужны в различных областях.
В этом году в рамках спецназа мы поучаствовали в таких проектах, как:
Расчет доступных слотов на вакцинацию;
Вывод цифрового ассистента - Робота Макса;
Регистрация sim-карт;
Вывод мобильного приложения «Госуслуги.Решаем вместе»;
Проведение электронного голосования;
Перепись населения.
Процесс в общих чертах выглядит так:
-
К проектной команде подключается тимлид, задачи которого:
понять технологический стек, объем работы и сроки, кто ответственные разработчики/РП, есть ли штатные тестеры, где и как ведутся задачи и регистрируются баги, кто разбирает бэклог, определить поинты в тестировании, на которые нужно больше ресурсов/времени;
выделить подходящих инженеров, объяснить задачи и обозначить главные поинты – определенные на предыдущем шаге. Познакомить с командой;
мониторить процесс, пушить исполнителей, предоставлять отчеты.
Выделенные инженеры подключаются к команде, берут на себя часть их задач. На данном этапе важным является обратная связь – инженеры не просто тыкают кнопки и пишут кейсы – они общаются с командой, понимают технические особенности и видят свежим взглядом тонкие места в процессах и технологиях. Именно поэтому широкий спектр знаний вовлеченных инженеров – ключ к успеху.
-
Тимлид в конце дня предоставляет отчет в котором указывает:
примерный % прохождения;
количество и критичность багов;
прирост или убыль багов (успевают ли их исправлять);
риски;
экспертное заключение о состоянии услуги: рекомендовано к внедрению или нет.
Далее отчет передается заинтересованным лицам.
Профит:
ускоряем работу продуктовой команды: помогаем внедриться в срок и минимизировать риски проблем на проде для сложных релизов;
свежий взгляд со стороны: посмотреть на процесс под иным углом, выявить узкие места и помочь с их устранением – повышаем качество услуги.
Болевые точки:
время, его почти всегда не хватает. Приходится четко определять ключевые точки за которые нужно браться в первую очередь. Если неверно рассчитать силы и точки их приложения – рискуем на проде получить ошибки или не внедриться в срок.
скорость – она влияет на человеческий фактор и несет опасность пропуска ошибки.
4. Смоук тестирования на проде после установки релизов
Непосредственно после установки релиза необходимо проверить, что релиз ничего не сломал и портал работает корректно. Для это используется набор автоматизированных смоук-тестов, который прогоняет дежурный после установки релиза. Он доступен для запуска из телеграм-бота, Jenkins и allureTestOps, а работает быстро – 5 минут. Включает в себя минимально-базовый набор проверок критичных услуг и интеграций, определенный с инженерами службы эксплуатации на этапе его формирования. Информация возвращается дежурному в чат в виде краткого отчета:
Также дежурному доступен отчет в allure со скриншотами и технической информацией: к каждому результату аттачится скриншот, source page станицы с ошибкой и куки; плюс есть HTML-отчет, удобный для рассылки.
При наличии ошибок портала релиз-менеджер проверяет эти кейсы вручную и принимает решение об откате или об успешном завершении установки (если, например, «моргнул» тест).
Стоит добавить, что сейчас смоуки проводятся по десятку различных систем и подсистем, часть в разработке и отладке и в скором времени поступит на вооружение.
Смоук тесты – это часть нашего фреймворка Госуслуг, обеспечивающий быстрое и результативное тестирование.
Профит:
повышаем скорость информирования: результат смоук тестов дает понимание, есть ли глобальные проблемы в релизе или ошибки установки.
Болевые точки:
тестовые данные – так как тестирование проводится на прод среде, подготовка тестовых данных может быть осложнена или вообще невозможна.
5. Сервисные услуги по автоматизации тестирования
Это, конечно, не основная задача нашего подразделения, но она помогает смежным подразделениям проще решать свои задачи.
Мы выделили в нашем фреймворке независимую core-часть, которую можно использовать на различных проектах. Отдельно хранятся в nexus библиотеки, расширяющие возможности фрейма: библиотеки отчетов, работы с багами и ошибками и так далее.
Такой подход позволяет командам не изобретать велосипед, а использовать готовое решение, сократив издержки на внедрение автоматизации на своих проектах. А масштабируемость позволяет настраивать фрейм под нужды каждого отдела.
По пп. 4 и 5 планируется дополнительная, более детальная, статья с описание технических решений.
Итог
За 2021 год мы:
выявили 328 проблем на прод среде в рамках регресса и тестирования новых услуг;
провели 7 срочных тестирований (тот самый спецназ);
покрыли регрессионными проверками 123 услуги/сервиса;
написали 2581 тест-кейс и 1360 автотестов (API+web+mobile).
Много это или мало – вопрос вторичный, главное, что эти 328 багов не попадут к большинству наших пользователей, а портал станет еще чуть-чуть доступнее и стабильнее.
Внедрять тестирование на прод среде или нет – это решение, направленное на повышение качества продукта. Вопрос целесообразности этого с финансовой точки зрения здесь специально не затрагивался, так как для многих коммерческих организаций успех определяется цифрами прибыли и качество продукта сознательно отодвигается на второй план. Мы в компании РТЛабс, в первую очередь, заботимся о качестве нашего продукта и считаем, что в нашем случае тестирование на проде полностью оправдано. И на 2022 год ставим перед собой еще более масштабные и объемные задачи.
А как по-вашему – тестирование на проде излишне или это важный этап в процессе повышения качества конечного продукта?
Спасибо за внимание!
Комментарии (8)

amedvedjev
21.01.2022 15:12Некоторые фирмы просто делают зеркало прода, только с обфускацией данных пользоветелей. Тоже выход.

Pirum1ch Автор
21.01.2022 20:49Согласен, но раскатать такую среду, а главное поддерживать далее и сохранять релевантное наполнение достаточно трудоемко.
amedvedjev
21.01.2022 20:51Так они регулярно каждую неделю новый слепок в staging делают.
Pirum1ch Автор
22.01.2022 10:48Хорошо если размер базы и их количество позволяют это делать. В нашем случае количество систем для общего stage и размер баз достаточно велик.

NeverIn
21.01.2022 18:54А как насчет конфиденциальности данных?
Pirum1ch Автор
21.01.2022 20:36Мы используем неперсонифицированные тестовые учетные записи не связанные с пользователями портала.
В отдельных случая мы можем использовать личные учетные записи, но т.к. в итоге услуга не подается в ведомство, то данные туда не попадают.
lxsmkv
Было бы классно если бы приложение на проде имело встроенную возможность работы со специальными учетными записями в "теневом" режиме. Т.е функцие все те же, но данные и процессы полностью изолированы и "обезврежены". И можно было бы тогда поставить своего человека (или машину) на обработку заявлений и проводить полный цикл тестирования на проде. Но такие штуки надо закладывать в архитектуру. Может вам удастся уговорить заказчика захотеть добавитьв систему такую возможность для повышения тестового покрытия и качества.
Pirum1ch Автор
В целом да, согласен. Но как всегда есть подводные камни - это точки интеграции со смежными системами, куда будут улетать тестовые данные и конечные ведомства, которые на своей стороне тоже должны иметь тестовые учетки.
В любом случае идея стоящая, обсудим в команде. Спасибо!